MYSQL高级语句
Mysql高阶语句
数据库的权限一般是很小的,我们在工作使用最多的场景就是查
排序 分组 查询 视图 多表连接查询(左连接 右连接 内连接)别名
使用select语句,用order by来对表进行排序。
ASC:升序排列,默认就是升序,可以不加
desc:降序排列,需要添加
升序

降序

order by结合where条件过滤


例题:
查id 姓名 成绩 根据性别=女,按照id进行降序排列

只有第一个参数出现相同值时,第二个才会按照要求排序
select id,name,score from info where sex='女' order by score desc,id desc;

区间判断查询和去重查询
and/or
且 ??或
且:select * from info where score >70 and score <=90;
或:select * from info where score >80 or score < 90;


嵌套条件:
select * from info where score >70 and (score >75 and score <90)

select * from info where score >70 or (score >75 and score <90)
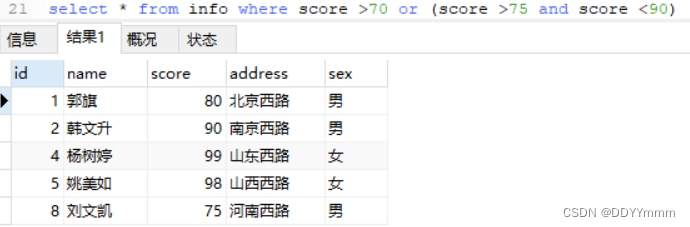
例题:
嵌套条件:满足性别是男,然后进行筛选成绩80-90之间

去重查询:
select distinct address from info;
select distinct sex from info;

对结果进行分组查询group by语句
一般是结合聚合函数一块
count()统计有多少行
sum()列的值相加,求和
avg()列的值求平均数
max()过滤出列的最大值
min()过滤出列的最小值
分组的时候可以按照一个字段,也可以按照多个字段对结果进行分组处理
select count(name),sex from info group by sex;

例题:
根据where条件筛选,男和女的成绩大于等于80
select count(name),sex,score from info where score >=80 group by sex;

求和:
以地址为分组,对score求和
select sum(score),address from info group by address;

平均值:
算出男生和女生的平均成绩
select avg(score),sex from info group by sex;

最小值:
分别求出男生组和女生组的成绩最低的姓名
select min(score),name,sex from info group by sex;

group by实现条件过滤(后面不能跟where语句,后面跟上的是having语句实现条件过滤)
select avg(score),address from info group by address having avg(score) >60;

例题:
按照地址分组,求成绩的平均值,然后成绩要大于50,按照id的降序排列
select avg(score),address,id from info group by address having avg(score) >50 order by id desc;

统计name的行数,计算出学生的个数,把成绩也查出来,然后按照统计出来的学生个数,升序排列,按照地址分组,学生的成绩大于等于70
select count(name),score,address,name from info group by address having score >=70 order by count(name);

按照性别分组,求出男生和女生的最大成绩,最大成绩是否超过75分,满足条件的过滤出来
select max(score),sex from info group by sex having max(score) >75;

使用聚合函数必须要加group by
分组的条件,要选用有多个重复值的列。
过滤条件要用having语句过滤
limit 限制输出的结果记录,查看表中的指定行
只看前三行
select * from info limit 3;
看2-5行
select * from info limit 1,4;
快速查看后几行
快速查看后三行
select * from info order by id desc limit 3;

通配符:
主要用于替换字符串中的部分字符,通过部分字符的匹配将相关的结果查询出来
通配符和like一起使用,使用where语句一起来完成查询
%:表示0个,1个,或者多个
_:表示单个字符
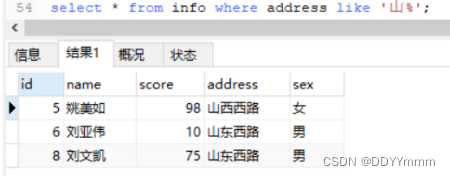
以山为开头
select * from info where address like '山%';
通配符可以结合一块使用
以山开头,匹配后面两个字符:
select * from info where address like '山%__';

设置别名: alias >> AS
在mysql查询时,表的名字或者字段名太长,可以使用别名来进行替代,方便书写,增加可读性
as可加可不加
select name as 姓名,score as 成绩 from info;
(select name 姓名,score 成绩 from info;)
给表起名
select name as 姓名,score as 成绩 from info?as a;
使用as复制表,约束不会被复制过来
创建了一个表test,test的数据结构从info复制过来,但是约束不会被复制。
create table test as select * from info;

可以给表起别名,但是要注意别名不能和数据库中其他的表名冲突
列的别名在结果中可以显示,但是表的别名在结果中没有显示,只能用于查询
子查询:内查询,嵌套查询
select ......(select)
括号里面的查询语句会先与主查询语句执行,然后再把子查询的结果作为条件返回给主查询条件进行过滤
子查询返回的结果只能是1列
where条件in什么,子查询的列就是什么
多表联查不要超过三张
子查询语句还可以用在insert update delete
插入数据,要求按地址,包含南京插入到test
修改info表score=100,not in子查询的条件是id > 1
update info set score=100 where id not in (select id from ky32 where id >1 );
exists:关键字在子查询时,主要用于判断子查询的结果集是否为空,不为空返回true,为空,false
根据info表,查询出大于80分的同学,然后统计有多少个
select count(*) from info a where exists (select id from info where score >80 and info.id=a.id);
根据info表,查询出小于80分的同学,然后统计有多少个
select count(*) from info a where exists (select id from info where score <80 and info.id=a.id);
视图:mysql当中的视图 view
视图在mysql当中是一个虚拟表。基于查询结果得出的一个虚拟表
在工作当中,我们查询的表未必是真表。有可能是基于真表查询结果的一个虚拟表
可以简化负载的查询语句,隐藏表的细节。提供安全的数据访问。
创建视图表可以是一张表的结果集,也是多个表共同的查询的结果集
视图表和真表之间的区别:
- 存储方式不一样的,真表存储实际数据,真正写在磁盘当中的。视图不存储任何数据仅仅是一个查询结果集的虚拟表
- 表可以增 删 改 查,但是视图一般情况只能用于查,展示数据
- 占用空间,真表真实占用空间,视图不占用数据库空间
创建视图
create view test2 as select * from info where score >=80;
查看视图
show full tables in test where table_type like 'view';
删除视图
drop view test2;
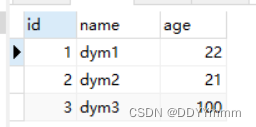
Info和test01
根据info的id,name,score加上test01的age?
create view v_info(id,name,score,age) as select a.id,a.name,a.score,b.age from info a,test01 b where a.name=b.name;
原表的数据发生变化,视图表数据同步更新
update info set score=90 where name ='dym2';
select * from v_info;

修改了视图表,原表的数据也会发生变化。一般情况我们是不对视图表进行改的操作
update v_info set age=100 where name ='dym3';
select * from test01
真表占了80%,视图适用于安全性要求比较高的场景。对外访问,基本都是视图
Null值和空值
Null就是空
空值:没有值的空格
Null是不被统计的,空值可以被统计

连接查询:
内连接:
是把两张表或者多张表(三张),同时符合特定条件的数据记录的组合。
一个或者多个列相同值才会有查询的结果
![]()
左连接:
左外连接,在left join关键字来表示。在左连接当中,左侧表示基础表,接受左边的所有行,然后和右表(参考表)记录进行匹配。
匹配坐标当中的所有行,以及右表中符合条件的行,不匹配的部分记录null值

右连接:
右外连接,right join以右侧表为基础。接受右侧表的所有记录,匹配的记录,不匹配的记录null值。
![]()
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【算法】串联所有单词的子串【滑动窗口】
- RNN梯度爆炸实验
- SQL优化小技巧
- FileZilla工具的使用以及主动模式与被动模式
- 聚道云软件连接器带给服装行业客户的业务革新
- idea自动部署springboot项目到linux服务器
- java 13 练习题:基本数据类型与变量
- 数字孪生在区块链的应用
- 防止企业办公终端文件数据资料外泄 | 中科数安,透明加密防泄密软件系统
- 上海亚商投顾:三大指数续创新低 券商、传媒股集体下挫