轻松获取CHATGPT API:免费、无验证、带实例
发布时间:2024年01月06日

免费获取和使用ChatGPT API的方法
快速开始:视频教程
章节一:GPT-API-Free开源项目介绍
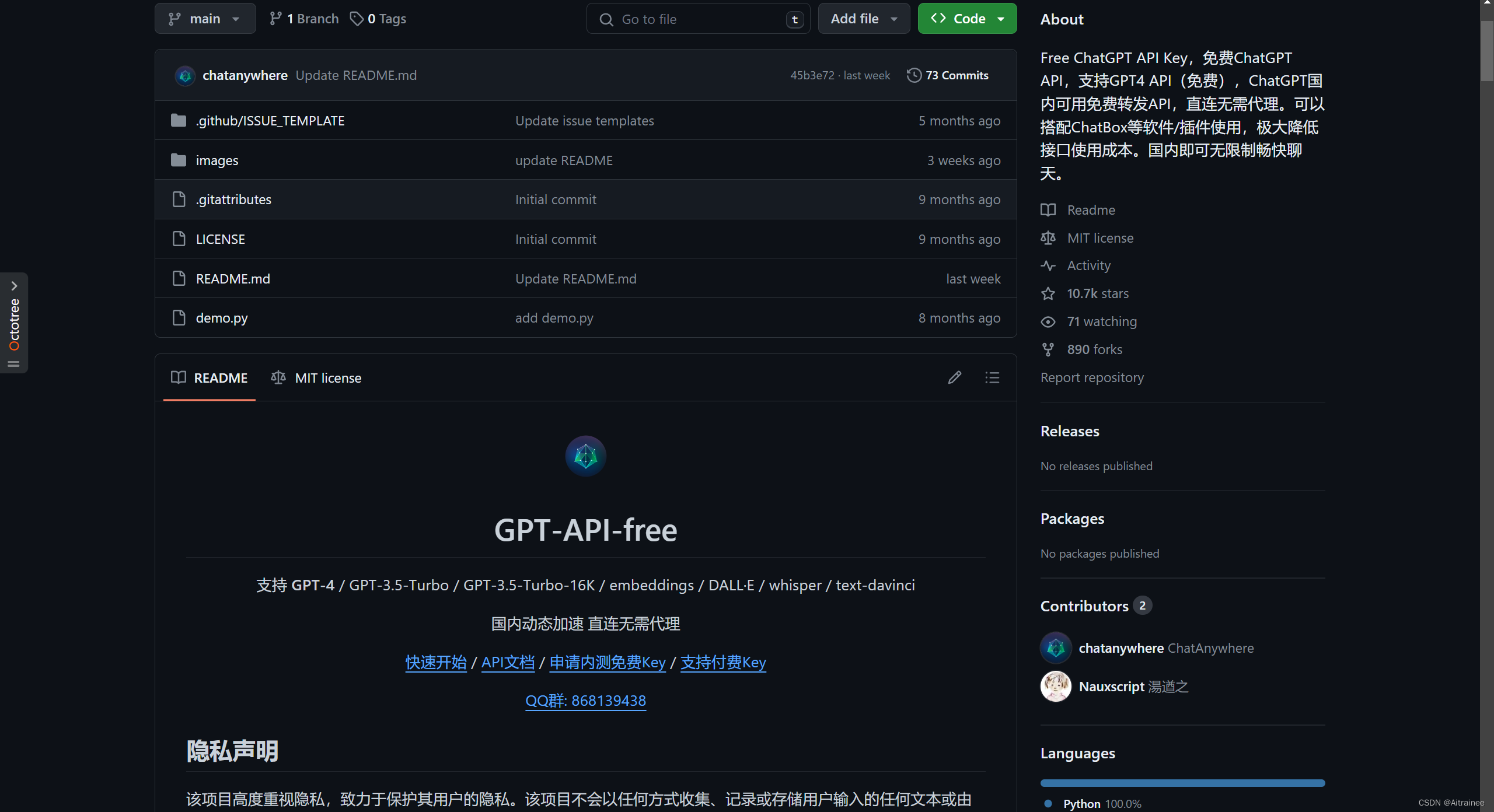
GPT-API-Free 是一个开源项目,它提供了一个中转API KEY,使用户能够调用多个GPT模型,包括gpt-3.5-turbo、embedding和gpt-4。这个项目的亮点在于:
- 模型调用限制:对于gpt-4模型,每24小时有10次调用限制。
- 付费升级选项:如果你需要更多服务,比如语音TTS(文字转语音)、视觉识别,或是最新的GPT-4模型,项目也提供了付费升级选项。
章节二:OPENAI账号注册和API调用变化
OPENAI为每个新账号提供5美元的免费API调用额度。但现在,注册和调用API的流程有所变化:
- 手机号验证:注册OPENAI账号不再需要美国手机号验证,但调用API时必须要有。
- 接码平台使用:在这个过程中,你可能需要使用接码平台,这可能会产生一些费用。
章节三:OPENAI KEY在特定场景下的应用
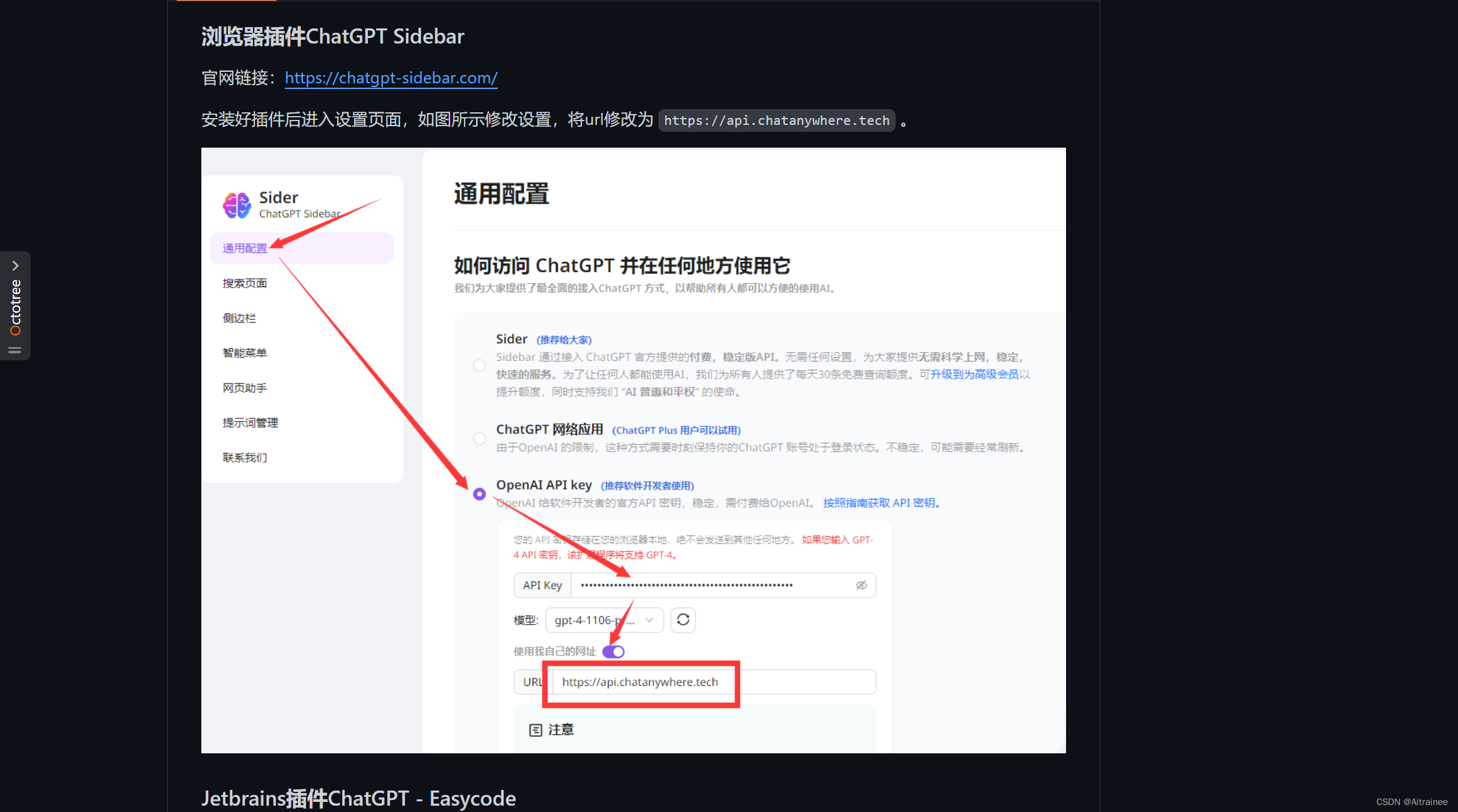
这个开源项目还介绍了在特定场景下使用OPENAI KEY的方法。例如:
- 第三方插件应用:你可以在多种第三方插件中使用它,如编程辅助、翻译工具,以及学术GPT插件。
- API密钥和中转站地址填写:在这些应用中,你只需要填入API密钥和中转站地址即可。
章节四:实例演示 - 调用语音TTS模型
最后,我将展示如何在自己的代码中调用语音TTS模型实现文字转语音。我们将参照OpenAI提供的官方调用示例,注意事项如下:
- Python库更新:使用Python调用最新的OpenAI时,该库已经更新。
- Key和中转网站填入:在OPENAI类里面填入自己的key以及中转网站。
from openai import OpenAI
import os
from datetime import datetime
from tqdm import tqdm
# 输入文本文件名
input_text_file = "path_to_your_output_folder/过滤.txt"
# 从文件中读取文本
with open(input_text_file, "r", encoding="utf-8") as file:
input_text = file.read()
# 初始化 OpenAI 客户端
client = OpenAI(api_key="sk-xxx", base_url="https://api.chatanywhere.tech")
# 使用 OpenAI API 生成语音
voice = "onyx" # 指定声音名称
response = client.audio.speech.create(
model="tts-1",
voice=voice,
input=input_text,
)
# 指定保存文件的文件夹路径
output_folder = "mp3"
os.makedirs(output_folder, exist_ok=True)
# 生成唯一的时间戳
timestamp = datetime.now().strftime("%Y%m%d%H%M%S")
# 根据输入文本文件名、声音名称和时间戳确定输出文件名
output_file_name = os.path.join(
output_folder,
f"{os.path.splitext(os.path.basename(input_text_file))[0]}_{voice}_{timestamp}_output.mp3"
)
# 将生成的语音保存到输出文件
with tqdm(total=len(response.content), unit='B', unit_scale=True, desc='Downloading') as pbar:
with open(output_file_name, 'wb') as f:
f.write(response.content)
pbar.update(len(response.content))
print(f"生成的语音已保存到 {output_file_name}")
通过以上章节,我们详细介绍了免费获取和使用ChatGPT API的方法,希望对你有所帮助。
文章来源:https://blog.csdn.net/lythinking/article/details/135350829
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 在别人发来的文章上修改时,出现红色且带下划线的情况
- 三菱plc仿真模拟软件FX-TRN-BEG-C学习资料从入门到精通视频教程
- Java常见原子性操作
- Mybatis 24_使用Mapper组件操作数据库 项目4MapperTest
- [c++] 意识需要转变的一个例子,全局变量的构造函数先于main执行
- SmartBI总结
- 你知道团队协作五大障碍吗?
- 目标检测YOLO实战应用案例100讲-树上果实识别与跟踪计数(续)
- java甜心驿站饮品信息管理(开题+源码)
- 在Linux中进行ZooKeeper集群搭建