Inception Transformer
Inception Transformer
摘要
最近的研究表明,Transformer具有构建远程依赖关系的强大能力,但是在捕获主要传递本地信息的高频率方面却无能为力。为了解决这个问题,我们提出了一种新颖的通用Inception Transformer(简称iFormer),它可以有效地学习视觉数据中高频和低频信息的综合特征。具体来说,我们设计了一个先启混频器,明确地将卷积和最大池化的优势嫁接到变压器中,以捕获高频信息。与最近的混合框架不同,Inception混频器通过通道分裂机制,采用并行卷积/最大池化路径和自关注路径作为高低频混频器,提高了效率,同时具有对分散在宽频率范围内的判别信息建模的灵活性。考虑到底层更多的是捕获高频细节,而顶层更多的是建模低频全局信息,我们进一步引入频率斜坡结构,即逐渐减少高频混频器的输入维数,增加低频混频器的输入维数,从而有效地权衡不同层之间的高频和低频分量。我们在一系列视觉任务上对iFormer进行了基准测试,并展示了它在图像分类,COCO检测和ADE20K分割方面取得了令人印象深刻的性能。例如,我们的iFormer-S在ImageNet-1K上达到了83:4%的前一准确率,比DeiT-S高出了3:6%,甚至比大得多的swing - b(83:3%)略好,只有1/4的参数和1/3的FLOPs。代码和模型将在https://github.com/sail-sg/iFormer上发布。
介绍
Transformer[1]席卷了自然语言处理(NLP)领域,在许多NLP任务中取得了令人惊讶的高性能,例如机器翻译[2]和问答[3]。
这在很大程度上归功于它通过自关注机制对数据中的远程依赖关系进行建模的强大能力。它的成功使得研究人员开始研究它在计算机视觉领域的适应性,视觉变压器(vision Transformer, ViT)[4]是一个先驱。该架构直接继承自NLP[1],但将其应用于以原始图像patch为输入的图像分类。后来,许多ViT变体[5-13]被开发出来,以提高性能或扩展到更广泛的视觉任务,例如,目标检测[10,11]和分割[12,13]。
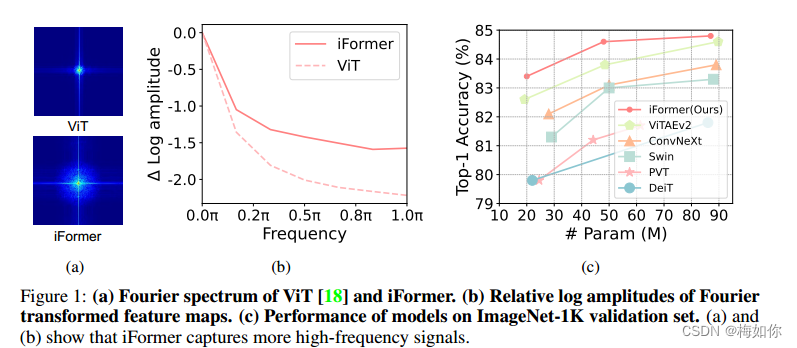
ViT及其变体在视觉数据中具有很强的低频捕获能力[14],主要包括场景或物体的全局形状和结构,但在高频学习方面不是很强大,主要包括局部边缘和纹理。这可以直观地解释:自关注是vit中用于在非重叠补丁令牌之间交换信息的主要操作,它是一个全局操作,并且更有能力捕获全局信息(低频)数据比本地信息(高频)。如图1(a)和1(b)所示,傅里叶频谱和傅里叶相对对数幅值表明,ViT往往能很好地捕获低频信号,但很少捕获高频信号。这一观察结果也与文献[14]的经验结果相吻合,表明ViT具有低通滤波器的特性。这种低频偏好损害了vit的性能,因为1)在所有层中填充低频信息可能会使高频成分(如局部纹理)劣化,削弱了vit的建模能力;2)高频信息也是有区别的,可以有利于许多任务,例如(细粒度)分类。实际上,人类视觉系统在不同频率下提取视觉基本特征[15-17]:低频提供视觉刺激的全局信息,高频传递图像的局部空间变化(如局部边缘/纹理)。因此,有必要开发一种新的ViT架构来捕获可视化数据中的高频和低频。
cnn是一般视觉任务的最基本的骨干。与vit不同的是,它们通过接受域内的局部卷积覆盖更多的局部信息,从而有效地提取高频表征[19,20]。最近的研究[21-25]考虑到cnn和ViTs的互补优势,将它们整合在一起。一些方法[21,22,24,25]将卷积和注意层以串行方式叠加,将局部信息注入全局上下文。不幸的是,这种串行方式只在一个层中建模一种类型的依赖,无论是全局的还是局部的,并且在局部建模期间丢弃了全局信息,反之亦然。其他作品[23,26]采用并行关注和卷积同时学习输入的全局和局部依赖关系。然而,在[27]中发现,部分通道用于处理局部信息,另一部分用于全局建模,这意味着当前的并行结构如果处理每个分支中的所有通道,则存在信息冗余。
为了解决这个问题,我们提出了一种简单高效的Inception Transformer (iFormer),如图2所示,它将cnn捕获高频的优点嫁接到vit中。iFormer中的关键组件是一个Inception token mixer,如图3所示。这个Inception token mixer旨在通过捕获数据中的高频和低频来增强vit在频谱中的感知能力。为此,Inception混频器首先沿通道维度拆分输入特征,然后将拆分的分量分别馈送到高频混频器和低频混频器中。
这里的高频混频器由最大池化操作和并行卷积操作组成,而低频混频器由ViTs中的香草自关注实现。通过这种方式,我们的iFormer可以有效地捕获相应通道上的特定频率信息,从而在较宽的频率范围内学习到比普通ViTs更全面的特征,这可以从图1(a)和1(b)中清晰地观察到。
此外,我们发现低层往往需要更多的局部信息,而高层则需要更多的全局信息,这也与文献[27]的观察结果一致。这是因为,与人类视觉系统一样,高频成分中的细节有助于较低层次捕捉视觉基本特征,并逐渐收集局部信息,以便对输入进行全局理解。受此启发,我们设计了一个频率斜坡结构。特别是,从低层到高层,我们逐渐向低频混频器提供更多的通道尺寸和更少的通道尺寸为高频混频器。这种结构可以在所有层之间权衡高频和低频组件。第四节的实验结果验证了该方法的有效性。
实验结果表明,iFormer在图像分类、目标检测和分割等多个视觉任务上都优于最先进的ViTs和cnn。例如,如图1?所示,在不同的模型尺寸下,iFormer在ImageNet-1K[28]上对流行的框架进行了一致的改进,如DeiT[29]、Swin[5]和ConvNeXt[30]。同时,iFormer在COCO[31]检测和ADE20K[32]分割方面优于最近的框架。
相关工作
变形算法[1]最初是针对机器翻译任务提出的,随后在自然语言处理领域的自然语言理解[33-35]和生成[36,37],以及计算机视觉领域的图像分类[18,29,38]、目标检测[6,39,40]和语义分割[41,42]等任务中得到广泛应用。变形金刚中的注意力模块具有捕获全局依赖性的出色能力,但它使模型跨层产生相似的表示[27]。此外,自注意主要捕获低频信息,容易忽略与详细信息相关的高频成分[14]。
cnn[43-47]是视觉任务事实上的模型,因为它具有出色的局部依赖建模能力[47-49]以及提取高频的能力[19]。由于这些优点,cnn以串联或并联的方式被迅速引入变压器中[23 - 26,50 - 52]。对于串行方法,在Transformer的不同位置应用卷积。CvT[25]和PVT-v2[53]用一层重叠卷积代替硬块嵌入。LV-ViT[50]、LeViT[54]和ViTC[21]进一步叠加了几层卷积作为模型的干,这有助于训练和获得更好的性能。除茎外,viti -hybrid[18]、vCoAtNet[24]、Hybrid-MS[55]和UniFormer[22]还设计了带有卷积层的早期阶段。
然而,卷积和注意力的串行组合意味着每一层只能处理高频或低频,而忽略了其他部分。为了使每一层能够处理不同的频率,我们采用并行的方式将卷积和注意结合在一个令牌混频器中。
与串行方法相比,文献中将注意与卷积并行结合的方法并不多见。CoaT[26]和ViTAE[23]引入卷积作为与注意力平行的分支,并利用元素求和来合并两个分支的输出。然而,Raghu等人发现,一些通道倾向于提取局部依赖关系,而另一些通道则用于建模全局信息[27],这表明当前并行机制在处理不同分支中的所有通道时存在冗余。相反,我们将信道分成高频和低频的分支。GLiT[52]也采用并行方式,但直接将卷积和注意分支的特征拼接为混频器输出,缺乏不同频率特征的融合。相反,我们设计了一个明确的融合模块来合并来自低频和高频支路的输出。
Method
Revisit Vision Transformer
我们首先回顾一下Vision Transformer。对于视觉任务,Transformers首先将输入图像分割成一系列标记,每个patch标记被投影到具有更精简层的隐藏表示向量中,表示为fx1;x2;:::;xng或x2r N×C,其中N为补丁令牌个数,C为特征维度。然后,将所有令牌与位置嵌入结合起来,并将其馈送到包含多头自关注(MSA)和前馈网络(FFN)的Transformer层中。
在MSA中,基于注意力的混合器在所有补丁令牌之间交换信息,因此它强烈关注聚合所有层的全局依赖。然而,过度的全局信息传播会加强低频表征。从图1(a)的傅里叶谱可视化可以看出,低频信息在ViT的表示中占主导地位[18]。这实际上损害了vit的性能,因为它可能会破坏高频成分,例如局部纹理,并削弱vit的建模能力[14]。在视觉数据中,高频信息也具有区别性,可以用于许多任务(19、20)。因此,为了解决这个问题,我们提出了一个简单而有效的盗梦变压器,如图2所示,具有两个关键的新颖之处,即盗梦混频器和频率斜坡结构。
Inception token mixer
我们提出了一个盗梦混频器,将cnn提取高频表示的强大能力嫁接到变压器上。
其详细架构如图3所示。我们使用“盗梦空间”的名称,因为令牌混合器受到盗梦模块[46,56 - 58]的高度启发,具有多个分支。Inception混频器不是直接将图像令牌馈送到MSA混频器中,而是首先沿着通道维度拆分输入特征,然后分别将拆分的分量馈送到高频混频器和低频混频器中。这里,高频混频器由最大池化操作和并行卷积操作组成,而低频混频器由自关注实现。
技术上,给定输入特征映射x2r N×C,将X沿通道维度分解为xh2r N×Ch和Xl 2r N×Cl,其中Ch + Cl = c,然后将Xh和Xl分别分配给高频混频器和低频混频器。
高频机。考虑到最大滤波器的高灵敏度和卷积运算的细节感知,我们提出了一种并行结构来学习高频分量。我们沿着通道将输入的Xh分成xh2rnxch2和xh2rnxch2。如图3所示,Xh1嵌入了一个最大池化层和一个线性层[46],Xh2被馈送到一个线性层和一个深度卷积层[59]
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Install Freeipa-container On Kubernetes
- 前端使用a标签下载非同源文件(备选方案)
- 寒假学习打字:提前实现弯道超车
- spring中的方法调用重试机制
- Linux - 记录问题:怎么通过安装包的方式安装gRPC
- diffusers加速文生图速度;stable-diffusion、PixArt-α
- Java 图片文件上传下载处理
- k8s------Pod、Label、NameSpace
- 【计算机毕业设计】SSM企业OA管理系统
- 如何使用Plex在Windows系统搭建个人媒体站点公网可访问