【论文阅读+复现】SparseCtrl: Adding Sparse Controls to Text-to-Video Diffusion Models
SparseCtrl:在文本到视频扩散模型中添加稀疏控制。
(AnimateDiff V3,官方版AnimateDiff+ControlNet,效果很丝滑)
code:GitHub - guoyww/AnimateDiff: Official implementation of AnimateDiff.
paper:https://arxiv.org/abs/2311.16933
目录
文章
1 介绍
动机:不断调整文字prompt以达到理想效果非常耗时费力,作者希望通过添加额外输入条件(草图、深度和RGB图像)来控制T2V生成。
方法:提出SparseCtrl,通过带有附加编码器的临时稀疏条件映射,来控制T2V生成。具体地说,为了控制合成,应用ControlNet的理念,实现了一个辅助编码器,同时保留原始生成器的完整性。可以在预训练的T2V模型上训练编码器网络,来加入额外的条件,而不用对整个模型再训练。

图1。SparseCtrl,一个基于预训练文本到视频(T2V)扩散模型的附加编码器网络,以接受特定关键帧(例如草图/深度/RGB图像)的额外时间稀疏条件。通过与各种模态编码器的集成,SparseCtrl使预训练的T2V能够用于各种应用,包括故事板,草图到视频,图像动画,长视频生成等。结合AnimateDiff和增强的个性化图像主干,SparseCtrl也可以获得可控的高质量生成结果,如2/3/4-th行所示。
2 背景
目前的文本条件视频生成技术缺乏对合成结果的细粒度可控性。我们的工作旨在通过附加编码器增强对T2V模型的控制。
可控文本到视频的生成。鉴于文本提示通常会导致对视频运动、内容和空间结构的模糊引导,这种可控性成为T2V生成的关键因素。我们的目标是通过输入少量条件图,来控制时间稀疏条件下的视频生成,使T2V在更广泛的场景中更加实用。
用于附加控制的附加网络。训练基础T2I/T2V生成模型需要大量的计算量。因此,在这些模型中加入额外控制的首选方法是:在保持原始主干完整性的同时,训练一个额外的条件编码器。
ControlNet创建一个可训练的预训练层的副本,以适应条件输入。然后,编码器输出通过零初始化层重新集成到T2I模型中。twi - adapter利用轻量级结构注入控制。IP-Adapter通过将参考图像转换为补充嵌入来整合样式条件,随后将其与文本嵌入连接起来。我们的方法与这些工作的原理一致,旨在通过辅助编码器模块实现稀疏控制。
3 方法
为了增强预训练文本到视频(T2V)模型对于时间稀疏信号的可控性,引入了附加的稀疏编码器来控制视频生成过程,保持原始的T2V生成器不变。
3.1 T2V扩散模型的背景
最近的T2V模型在二维图像层之间引入时间层来扩展预训练的T2I生成器以生成视频,如图2(a)的下部所示。可以跨帧信息交换,有效地建模跨帧运动和时间一致性。
训练目标:预测添加到干净的RGB视频(或潜在特征)![]() 上的噪声尺度:
上的噪声尺度:

ct是文本描述的嵌入向量,?是与z 1:N 0 形状相同的采样高斯噪声,αt和σt是控制添加噪声强度的参数,t是均匀采样的扩散步骤,T是总步数。
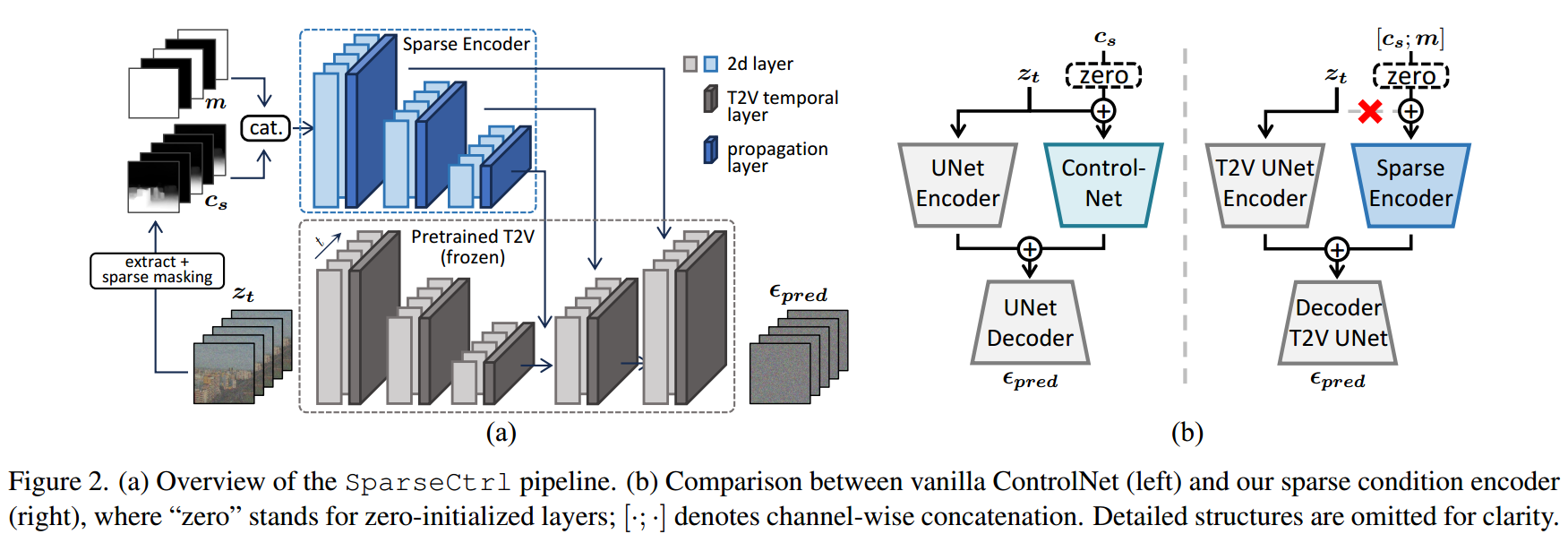
图2。(a) pipeline。(b) vanilla ControlNet(左)和稀疏条件编码器(右)的比较,“零”代表零初始化层;[·;·]表示通道级联。?
3.2 稀疏条件编码器的设计
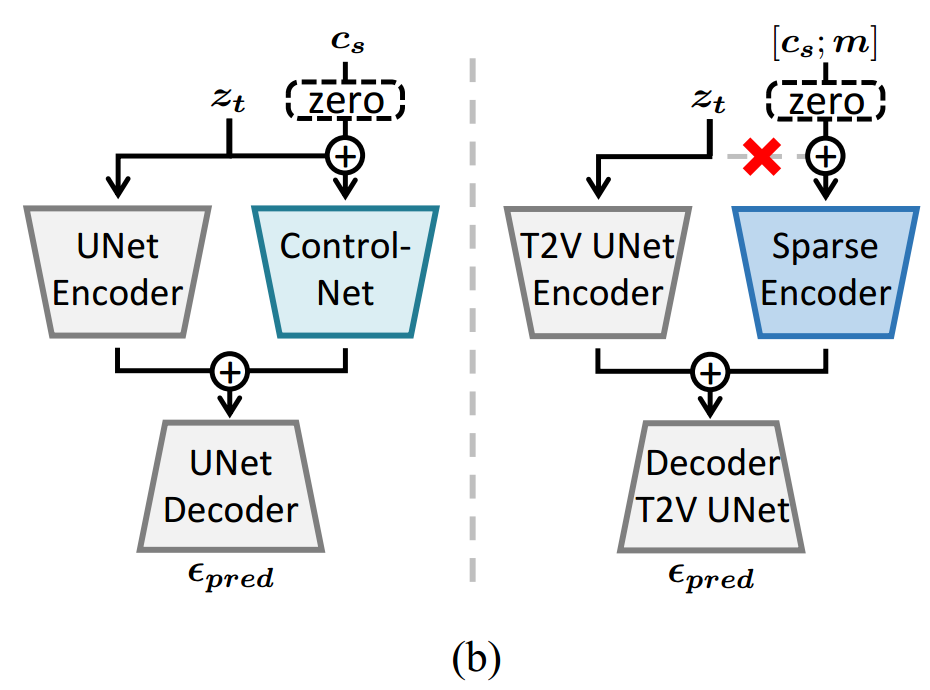
引入了一种能够接受稀疏条件图作为输入的附加编码器,称为稀疏条件编码器。T2I中,ControlNet 通过部分复制预训练的图像生成器模型及其输入,并添加条件后通过零初始化的层将输出重新整合到原始模型中,将结构控制添加到预训练的图像生成器中,如图2(b)左。我们设计类似的方法来实现T2V中的稀疏控制。
帧级编码器的受控性有限。首先尝试了一种简单直接的方案:训练一个类似ControlNet的帧级编码器,融入稀疏条件信号,沿时间维度复制。通过这个辅助结构,将条件加到关键帧上。对于没有直接被条件控制的帧,向编码器输入一个零图像,并通过额外的掩码通道,指示未被条件控制的状态。结果:实验显示这种帧级条件无法保持时间一致性,只有关键帧对条件做出反应,导致受条件控制和未受条件控制的帧之间,出现突然的内容变化。
跨帧条件传播。假设上述问题是由于T2V主干难以推断未受条件控制帧的中间条件状态引起的。因此,在稀疏条件编码器中添加时间层(例如带有位置编码的时间注意力),允许条件信号从帧到帧传播。结果:实验证实,这种设计提高了生成结果的鲁棒性和一致性。
人工噪声引起的质量下降。有时间层的稀疏条件编码器可以解决输入的稀疏性,但有时会导致生成的视频的质量下降。因为作者检查发现,本文不适合直接应用ControlNet,因为会复制带有噪声样本输入。如图2(b),原始ControlNet不仅复制了UNet编码器,还复制了带有噪声的样本输入zt。即,ControlNet编码器的输入是条件+带噪声样本的和。这种设计在原始情景中稳定了训练,并加速了模型的收敛。然而本文中,对于未受条件控制的帧来说,稀疏编码器的输入就只有带噪声的样本(因为没有条件嘛)。导致稀疏编码器忽视条件,并在训练过程中依赖于带噪声的样本zt,减弱了可控性。因此,如图2(b),稀疏编码器消除了带有噪声的样本输入,只接受拼接后的条件图[cs,m]。这种简单而有效的方法消除了实验中观察到的质量下降现象。
通过掩码统一稀疏性。为了能统一处理不同的稀疏性情况,用零图像作为未受条件控制的帧的输入占位符,并将二进制掩码序列与输入条件进行连接,这是视频重构和预测中常见的做法。如图2(a)所示,在每个帧的条件信号cs之外,我们以通道方式连接一个二值掩码m ∈ {0, 1} h×w,形成稀疏编码器的输入。m = 0时,表示当前帧未受条件控制。通过这种方式,可以用统一的输入格式表示不同的稀疏输入情况。

3.3 支持的模态和应用
本文中使用了三种模态实现SparseCtrl:草图、深度图和RGB图像。
草图到视频生成。可以提供任意数量的草图来塑造视频内容。例如,单个草图可以确定视频的整体布局,而第一帧、最后一帧和中间帧的草图可以定义粗略动作,该方法在故事板设计中非常有用。
深度引导生成。可以通过直接从引擎或3D表示中导出稀疏深度图来渲染视频,或者使用深度作为中间表示,进行视频转换。
图像动画和过渡。视频预测和插值。图像动画对应于以第一帧为条件的视频生成;过渡以第一帧和最后一帧为条件;视频预测以少量起始帧为条件;插值以均匀稀疏的关键帧为条件。
4 实验
4.1. 实现细节
文本到视频生成器。我们在AnimateDiff上实现了SparseCtrl,与预训练图像主干Stable Diffusion V1.5集成时,可以作为一个通用的T2V生成器,或者当与个性化图像主干如RealisticVision和ToonYou结合时,可以作为个性化的生成器。
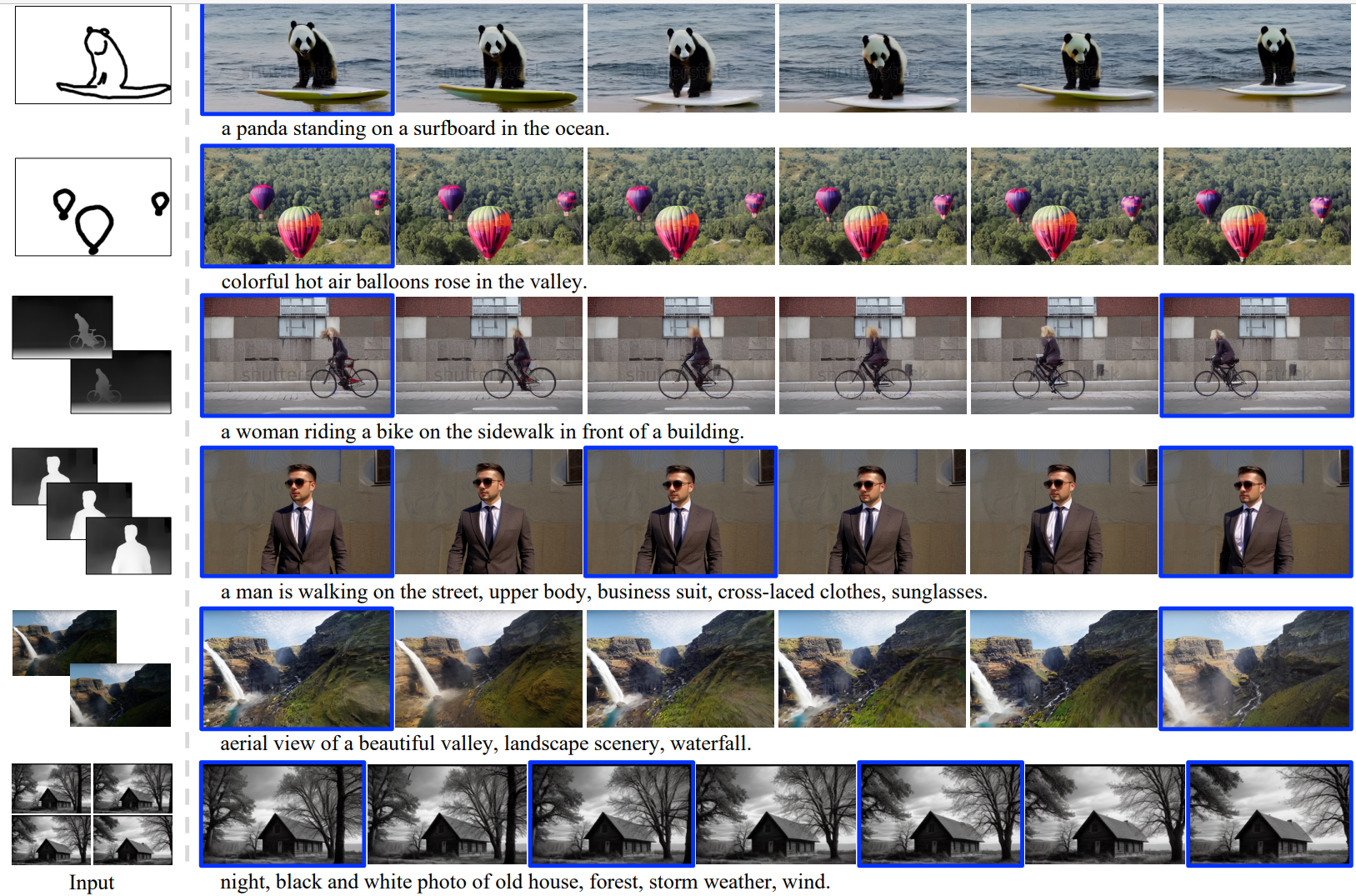
图3。素描/深度/RGB图像稀疏条件编码器的定性结果。4/6行视频由个性化主干RealisticVision生成。条件关键帧用蓝色边框表示。?

图4。网络设计的消融研究。左:预训练T2V野图动画结果。右:个性化t2i主干ToonYou的域内图像动画结果,其中输入图像由相应的图像模型生成。条件关键帧用蓝色边框表示。
三种情况下,生成的视频中的第一帧是对输入图像控制的保真度。在个性化生成设置下,帧编码器无法将控制传播到无条件帧(第一行,右),从而导致角色细节(例如头发和衣服颜色)随时间变化的时间不一致。在预训练T2V上,如第3.2节所述,具有传播层的编码器质量下降(第二行,左),假设这是因为输入到编码器的带噪样本为条件任务提供了误导性信息。最后,通过传播层和消除噪声样本输入,完整模型在两种设置(第三行)下,保持了对条件的保真度和时间一致性。

?
sketch-to-video设置中,构建三种类型的提示:(1)没有有用信息的不足提示(第4行),例如“优秀的视频,最好的质量,杰作”;(2)部分描述所需内容的不完整提示(第5行),例如,“大海,阳光,……”,忽略了中心物体“帆船”;(3)描述每个内容的完成提示(第六行)。如图5所示,在sketch条件下,需要完成提示才能正确生成内容,说明在提供的条件高度抽象,不足以推断内容的情况下,文本输入仍然发挥着重要作用。


?图5。不相关条件与文本提示反应的消融研究。第一行演示了模型如何处理不相关的条件,下面的五行显示了模型如何对不同的文本提示作出反应。条件关键帧用蓝色边框表示。
5 结论
SparseCtrl,一种通过附加编码器网络,向预训练的文本到视频生成器添加时间稀疏控制的方法。可以适应深度、草图和RGB图等各种模态,极大增强了视频生成的控制力。这种灵活性在草图到视频、图像动画、关键帧插值等各种应用中都非常有价值。
限制:生成结果的质量、语义组合能力和领域受预训练的T2V主干和训练数据的限制。实验中,失败案例主要来自于域外输入,例如动漫图像动画,因为这样的数据在T2V和稀疏编码器的预训练数据集WebVid10M中很少(其内容主要是真实世界的视频)。提高泛化能力的可能解决方案包括改善训练数据集的领域多样性,并利用一些特定领域的主干,例如将SparseCtrl与AnimateDiff集成。
复现
1 问题
问题1:TypeError: EulerDiscreteScheduler.__init__() got an unexpected keyword argument 'steps_offset'
解决:目前解决不掉
问题2:torch.cuda.OutOfMemoryError
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 1.25 GiB (GPU 0; 11.91 GiB total capacity; 8.99 GiB already allocated; 1.23 GiB free; 9.96 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF解决:调小参数
(为什么配置参数写在animate.py里,不写在yaml里,找了半天T T
问题3:AttributeError: 'Row' object has no attribute 'style'
这题我会,注释掉就行了
原因:默认安装的第三方库gradio最新版本,降低版本即可,pip install gradio==3.50.0,解决
2 结果
运行:
1.T2V常规设置
# under general T2V setting
python -m scripts.animate --config configs/prompts/v3/v3-1-T2V.yaml2.图像动画
# image animation (on RealisticVision)
python -m scripts.animate --config configs/prompts/v3/v3-2-animation-RealisticVision.yaml输入:

结果:

3.草图到动画和故事板
# sketch-to-animation and storyboarding (on RealisticVision)
python -m scripts.animate --config configs/prompts/v3/v3-3-sketch-RealisticVision.yaml我这里生成完1-sketch-to-video,再进行2-storyboarding时会爆显存,所以分开单独进行了,每次只保留一个任务在yaml里就可以,暂时注释掉另一个。我用的权重是lyriel_v16.safetensors,大小16x256x256或12x384x384,更大了不行
条件(草图):

结果:(图1:16x256x256;图2:12x384x384,感觉影响生成质量的主要是大小,height x width,图片越大,生成得越精细好看)


条件(故事版):



结果:

?自己生成的效果居然快赶上官方展示图了,真给力~(′▽`)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Oracle RAC 创建ADG database
- 使用AI大模型增强图像清晰度
- Feign远程调用丢失请求头问题处理
- LeetCode刷题--- 最小路径和
- 【无标题】
- 【PostgreSQL】数据查询-组合查询(UNION,INTERSECT,EXCEPT)
- opencv#29 图像噪声的产生
- MURD1060-ASEMI快恢复TO-252封装二极管MURD1060
- css linear-gradient和radial-gradient的区别
- C++用纯虚析构函数定义一个抽象类