目标检测-Two Stage-SPP Net
发布时间:2023年12月26日
前言
SPP Net:Spatial Pyramid Pooling Net(空间金字塔池化网络)
SPP-Net是出自何凯明教授于2015年发表在IEEE上的论文-《Spatial Pyramid Pooling in Deep ConvolutionalNetworks for Visual Recognition》
前文目标检测-Two Stage-RCNN中提到RCNN的主要缺点如下:
- 2000候选框都需要进行CNN提特征+SVM分类,计算量很大
- 所有候选框在输入CNN前都裁剪/缩放(crop/warp)成统一大小,会造成变形失真等问题,从而影响精度(见下图)

SPP Net 针对上述缺点做了改进
提示:以下是本篇文章正文内容,下面内容可供参考
一、SPP Net 的网络结构和流程
- 使用EdgeBoxes提取2,000个候选窗口(candidate windows)
- 预训练CNN模型(ZF)+ 微调(fine-tuning) / 从头开始训练模型
- 调整图像的大小,使min(w,h)=s,并使用CNN网络从整个图像中提取特征图(feature maps)
ps:输入影像大小可以是任意的,因此feature map的大小也是任意的
- 使用线性模型将候选窗口在原图的位置映射到卷积层特征图,以获取每个候选窗口的特征图(feature maps)
- 通过空间金字塔池化层(Spatial Pyramid Pooling Layer)将每个候选窗口feature map转化为固定大小
ps:以下图举例来说,SPP以3级空间金字塔(4×4,2×2,1×1)来提取特征,就可以得到16+4+1=21种不同的块(Spatial bins),对每个块进行池化操作,最终得到固定大小为21×256的输出
实际使用了4级空间金字塔(1×1, 2×2, 3×3, 6×6),这会为每个候选窗口生成12800d(256×50)的表示
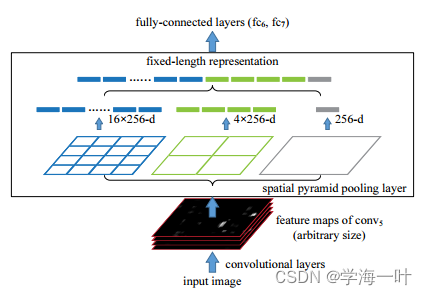
- 将经过SPP Layer层的得到的候选窗口的表示(12800d)输入全连接网络
- 训练一个SVM分类器,根据全连接网络输出特征进行分类,利用非极大值抑制(NMS)去除冗余候选区
- 训练一个回归模型,精修正确的候选框位置及大小

二、SPP的创新点
- 相比于RCNN先提特征后卷积,SPP Net先卷积后提特征,因此只需要一次卷积,相比于RCNN节省了大量计算时间
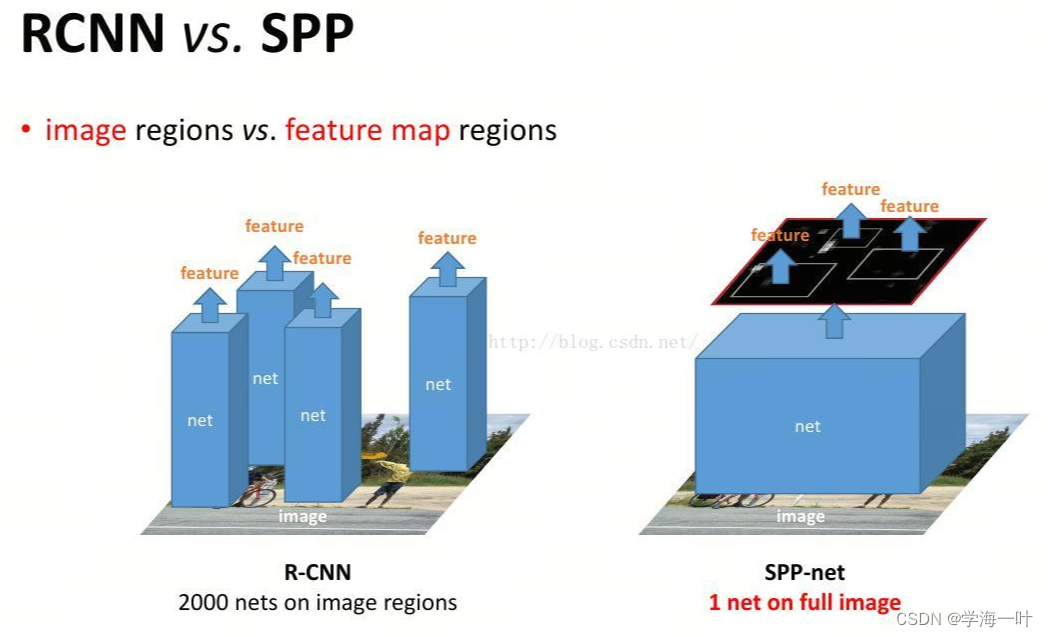
- 使用SPP Layer固定输出大小,改善了warp/crop这种预处理方法可能造成的图像失真从而导致识别精度下降的问题
- 使用了多尺度训练(224和180)提高了精度
ps:输入的大小可以是任意的,使得网络可用于多尺度训练
总结
尽管相比于RCNN,SPP Net提高了精度和速度,但是仍然是分开训练多个模型,模型训练难度大且繁杂。
尽管比RCNN快10-100倍,但仍然很慢
SPP Net无法更新空间金字塔池化层以下的权重,根本原因是,当每个训练样本来自不同影像时,通过SPP层的反向传播效率很低
文章来源:https://blog.csdn.net/long11350/article/details/135205440
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章