[笔记]深度学习入门 基于Python的理论与实现(四)
4. 神经网络的学习
这里说的‘学习’就是指从训练数据中自动获取最优权重参数的过程。为了进行学习,将导入损失函数这一指标。而学习的目的就是以该损失函数为基准,找出能使它的值达到最小的权重参数。为此,我们介绍利用了函数斜率的梯度法。
4.1 从数据中学习
神经网络的特征就是可以从数据中学习。所谓‘从数据中学习’,是指可以由数据自动决定权重参数的值。在实际的神经网络中,参数的数量成千上万,甚至可以达到亿级,如果全部人工指定,那是几乎不可能的。
- 对于线性可分问题,第 2 章的感知机是可以利用数据自动学习的。根据‘感知机收敛定理’,通过有限次数的学习,线性可分问题是可解的。但是,非线性可分问题则无法通过(自动)学习来解决
4.1.1 数据驱动
数据是机器学习的核心。通常要解决某个问题,特别是需要发现某种模式时,人们一般会综合考虑各种因素后再给出回答。人们以自己的经验和直觉为线索,通过反复试验推进工作。而机器学习的方法则极力避免人为介入,尝试从收集到的数据中发现答案(模式)。

我们来思考从零构建一个能将 5 正确分类的程序,会发现是一个很难的问题。人可以简单地识别出 5,但是却很难明确说出是基于何种规律识别出来的。
与其从零开始想一个算法,不如考虑通过有效利用数据来解决这个问题。一种方案是,先从图像中提取特征量
,再用机器学习技术学习这些特征量的模式。这里说的‘特征量’是指可以从输入数据(输入图像)中准确地提取本质数据(重要的数据)的转换器。图像的特征量通常表示为向量的形式。在计算机视觉领域,常用的特征量包括
SIFT、SURF 和 HOG 等。使用这些特征量将图像数据转换为向量,然后对转换后的向量使用机器学习中的 SVM、KNN 等分类器进行学习。
需要注意的是,将图像转换为向量时使用的特征量仍是由人设计的。对于不同的问题,必须使用合适的特征量(必须设计专门的特征量),才能得到好的结果。比如,为了区分狗的脸部,人们需要考虑与用于识别
5 的特征量不同的其他特征量。即使使用特征量和机器学习的方法,也需要针对不同的问题人工考虑合适的特征量。
而神经网络则直接学习图像本身。在神经网络中,图像中包含的重要特征量也都是由机器来学习
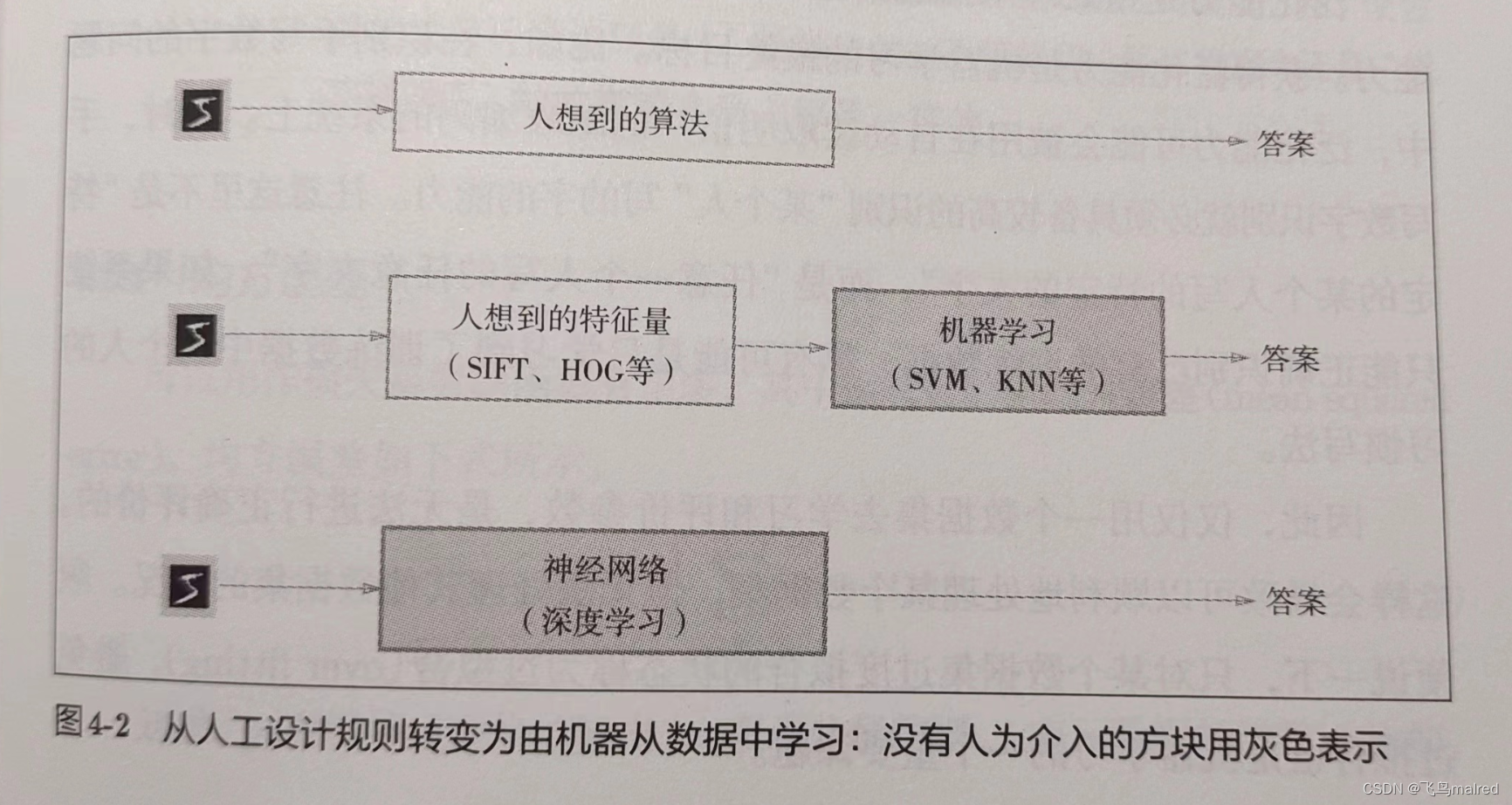
- 深度学习有时也称为端到端机器学习(end-to-end machine learning)。端到端指的是从一端到另一端的意思,也就是从原始数据(输入)中获得目标结果(输出)的意思
神经网络的优点是对所有的问题都可以用同样的流程来解决。都是通过不断学习所提供的数据,尝试发现待求解的问题的模式。也就是说,与待处理的问题无关,神经网络可以将数据直接作为原始数据,进行‘端到端’的学习
4.1.2 训练数据和测试数据
机器学习中,一般将数据分为训练数据和测试数据
两部分来进行学习和实验等。首先,使用训练数据进行学习,寻找最优的参数;然后,使用测试数据评价训练得到的模型的实际能力。而分为两部分数据是因为我们追求的是模型的泛化能力。为了正确评价模型的
泛化能力,就必须划分训练数据和测试数据。另外,训练数据也可以称为监督数据
泛化能力是指处理未被观察过的数据(不包含在训练数据中的数据)的能力。获得泛化能力是机器学习的最终目标。
仅仅用一个数据集去学习和评价参数,是无法进行正确评价的,这样会导致可以顺利处理某个数据集,但无法处理其他数据集的情况。只对某个数据集过度拟合的状态称为
过拟合(over fitting)。避免过拟合也是机器学习的一个重要命题
4.2 损失函数
神经网络的学习通过某个指标表示现在的状态,然后,以这个指标为基准,寻找最优权重参数。这个指标称为损失函数(loss
function)。这个损失函数可以使用任意函数,但一般用均方误差和交叉熵误差等。
- 损失函数是表示神经网络性能的‘恶劣程度’的指标,即当前的神经网络对监督数据在多大程度上不拟合,在多大程度上不一致。
4.2.1 均方误差
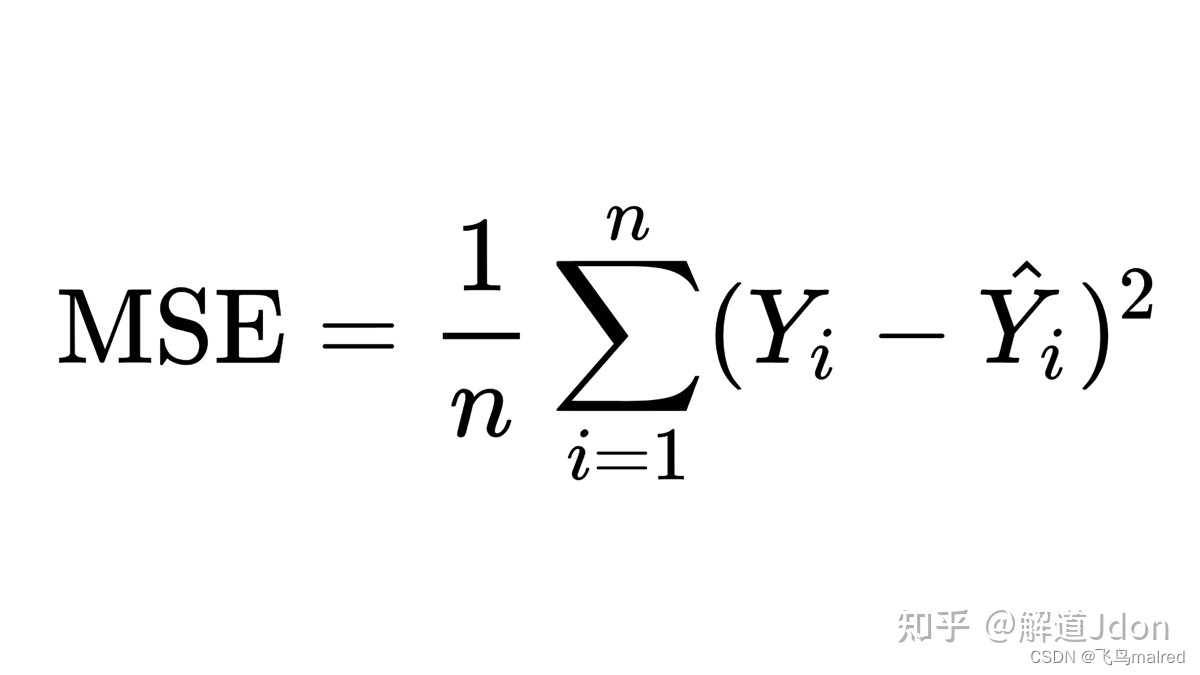

yk 表示神经网络的输出,tk 表示监督数据,k 表示数据的维数。、
比如在之前手写数字识别的例子中,yk、tk 是由如下 10 个元素构成的数据。
y = [0.1, 0.05, 0.6, 0.0, 0.05, 0.1, 0.0, 0.1, 0.0, 0.0]
t = [0, 0, 1, 0, 0, 0, 0, 0, 0, 0]
这里的 y 是神经网络的输出,是 softmax 函数的结果,可以理解为每个不同分类的概率。而 t 是监督数据,正确标签的值为 1,其他均为
0,这种表示方法称为 one-hot 表示。
均方误差会计算神经网络的输出和正确解监督数据的各个元素之差的平方,再求总和。
def mean_squared_error(y, t):
return 0.5 * np.sum((y - t) ** 2)
我们来测试一下
# 设'2'为正确解
t = [0, 0, 1, 0, 0, 0, 0, 0, 0, 0]
# 例1: '2'的概率最高的情况
y = [0.1, 0.05, 0.6, 0.0, 0.05, 0.1, 0.0, 0.1, 0.0, 0.0]
mse = mean_squared_error(np.array(y), np.array(t))
# 0.09750000000000003
print(mse)
# 例2: '7'的概率最高的情况
y = [0.1, 0.05, 0.1, 0.0, 0.05, 0.1, 0.0, 0.6, 0.0, 0.0]
mse = mean_squared_error(np.array(y), np.array(t))
# 0.5975
print(mse)
4.2.2 交叉熵误差(cross entropy error)
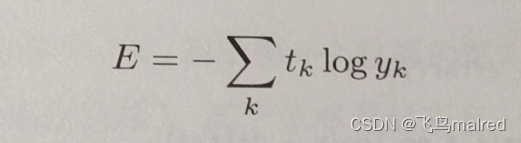
这里,log 表示以 e 为底数的自然对数(log e)。yk 是神经网络的输出,tk 是正确解标签。并且,tk 只有正确解标签的索引为 1,其他均为
0(one-hot 表示)。因此,该式实际上只计算对应正确解标签的输出的自然对数。比如,假设正确解标签的索引是‘2’,对应的神经网络输出是
0.6,则交叉熵误差为-log 0.6 = -0.51。也就是说,交叉熵误差的值是由正确解标签所对应的输出结果决定的。
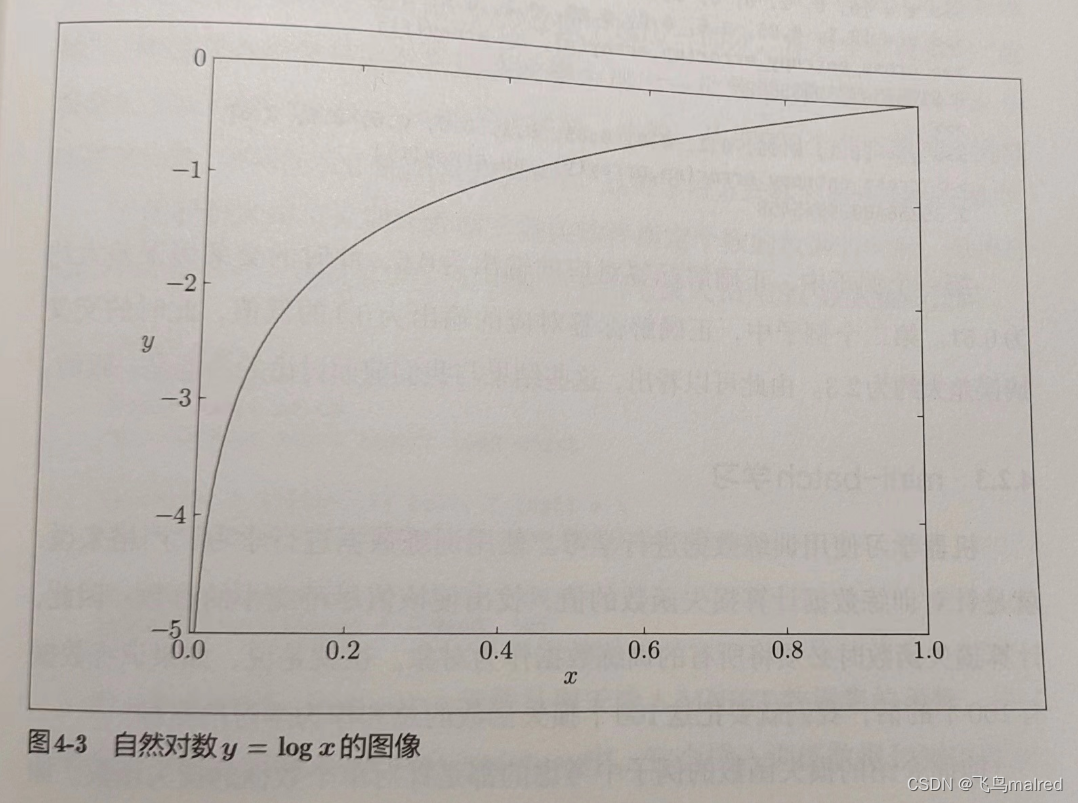
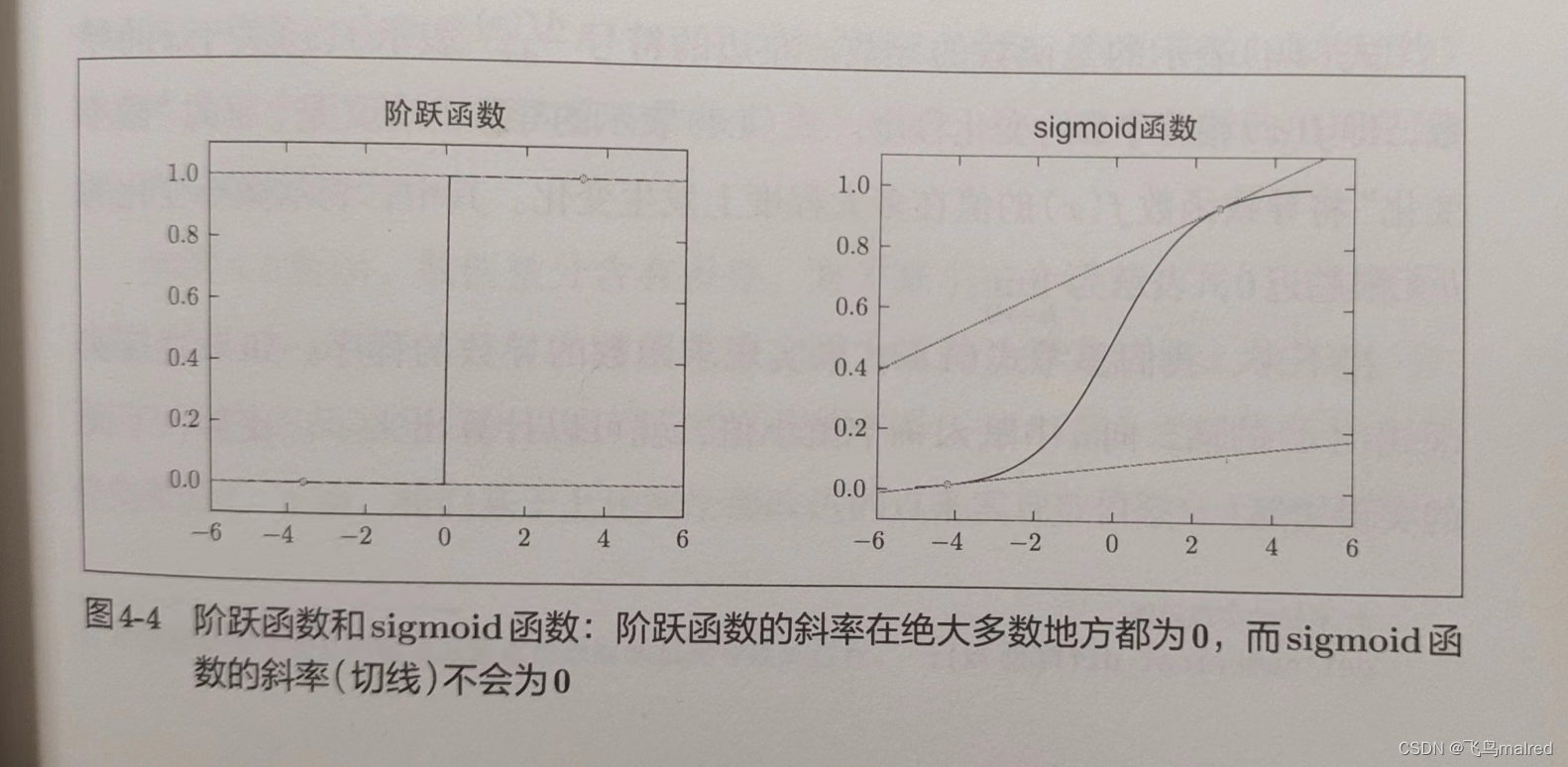
如图所示,x 等于 1 时,y 为 0;随着 x 向 0 靠近,y 逐渐变小。因此,正确解标签对应的输出越大,y 的值越接近 0;当输出为 1
时,交叉熵误差为 0。如果正确解标签对应的输出越小,y 的值就越大
def cross_entropy_error(y, t):
delta = 1e-7
return -np.sum(t * np.log(y + delta))
这里在计算 log 时,加上了一个微小值 delta,这是因为,当出现 np.log(0)时,会得到负无限大-inf,作为保护性对策,添加一个微小值可以防止负无限大的发生
t = [0, 0, 1, 0, 0, 0, 0, 0, 0, 0]
y = [0.1, 0.05, 0.6, 0.0, 0.05, 0.1, 0.0, 0.1, 0.0, 0.0]
cee = cross_entropy_error(np.array(y), np.array(t))
# 0.510825457099338
print(cee)
y = [0.1, 0.05, 0.1, 0.0, 0.05, 0.1, 0.0, 0.6, 0.0, 0.0]
cee = cross_entropy_error(np.array(y), np.array(t))
# 2.302584092994546
print(cee)
4.2.3 mini-batch 学习
机器学习使用训练数据进行学习,严格地说,就是针对训练数据计算损失函数的值,找出使值尽可能小的参数。因此,计算损失函数时必须将所有的训练数据作为对象。如果有
100 个训练数据,就要把 100 个损失函数的总和作为学习的指标。
前面的例子都是针对单个数据的损失函数。如果要求所有训练数据的损失函数的总和,以交叉熵误差为例,可以改写为:
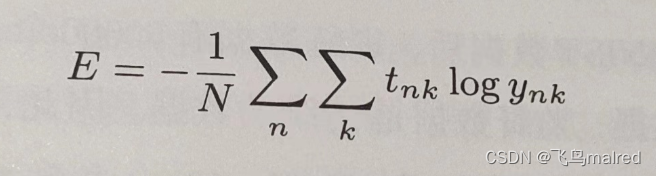
假设数据有 N 个,tnk 表示第 n 个数据的第 k 个元素的值(ynk 是神经网络的输出,tnk 是监督数据)。这里其实是把求单个数据的损失函数的式子扩大到了
N 份数据,最后还要除以 N 进行正规化。通过除以 N,可以求单个数据的‘平均损失函数’。通过这样的正规化,可以获得和训练数据的数量无关的统一指标。即使有
1000、10000 个数据,也能求单个数据的平均损失函数。
MNIST 数据集的训练数据有 60000
个,如果以全部数据为对象求损失函数的和,则计算过程需要花费较长的时间(大数据集同理)。这种情况下,以全部数据为对象计算损失函数是不现实的。因此,我们从全部数据中选出一批数据(称为
mini-batch,小批量),然后对每个 mini-batch 进行学习。这种方式称为mini-batch学习
下面编写从训练数据中随机选择指定个数的数据的代码
import sys, os
sys.path.append(os.pardir)
import numpy as np
from dataset.mnist import load_mnist
(x_train, t_train), (x_test, y_test) = \
load_mnist(normalize=True, one_hot_label=True)
# (60000, 784)
print(x_train.shape)
# (60000, 10)
print(t_train.shape)
使用 np.random.choice()随机抽取 10 笔数据
train_size = x_train.shape[0]
batch_size = 10
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
使用 np.random.choice 可以从指定的数字中随机选择想要的数字。比如 np.random.choice(60000,10)会从 0~59999 之间随机选择 10
个数字。我们可以得到一个包含被选数据的索引的数组。
print(np.random.choice(60000, 10))
# [13591 30046 50818 9014 19622 34605 3242 19230 41399 14322]
我们只需指定这些随机选出的索引,取出 mini-batch,然后使用 mini-batch 计算损失函数即可。
- mini-batch 的损失函数也是利用一部分样本数据来近似地计算整体。也就是说,用随机选择的小批量数据作为全体训练数据的近似值
4.2.4 mini-batch 版交叉熵误差的实现
def cross_entropy_error(y, t):
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
batch_size = y.shape[0]
return -np.sum(t * np.log(y + 1e-7)) / batch_size
y 是神经网络的输出,t 是监督数据。y 的维度为 1 时,即求单个数据的交叉熵误差时,需要改变数据的形状。并且,当输入为 mini-batch
时,要用 batch 的个数进行正规化,计算单个函数的平均交叉熵误差
当监督数据是标签现实(非 one-hot 表示,而是像‘2’、‘7’这种标签),交叉熵误差函数可以改为:
def cross_entropy_error(y, t):
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
batch_size = y.shape[0]
return -np.sum(np.log(y[np.arange(batch_size), t] + 1e-7)) / batch_size
实现的要点是,由于 one-hot 表示中 t 为 0 的元素的交叉熵误差为 0,因此针对这些元素的计算可以忽略。换言之,如果可以获得神经网络在正确解标签的输出,就可以计算交叉熵误差。因此,t
为 one-hot 表示时通过 t*np.log(y)计算的地方,在 t 为标签形式时,可用 np.log(y[np.arange(batch_size), t])实现相同的处理。
np.arange(batch_size)会生成一个从 0 到 batch_size-1 的数组。比如当 batch_szie 为 5,则生成[0,1,2,3,4],而 t
中标签是以[2,7,0,9,4]的形式存储的,所以 y[np.arange(batch_size), t]会生成 numpy 数组[y[0,2],y[1,7],y[2,0],y[3,9]
,y[4,4],]
4.2.5 为何要设定损失函数
以数字识别任务为例,为什么我们要引入一个损失函数,而不是直接以识别精度为指标呢?
可以根据‘导数’在神经网络学习中的作用来回答。寻找最优参数时(权重和偏置)时,要寻找使损失函数的值尽可能小的参数。为此,需要计算参数的导数(确切地讲是梯度),然后以这个导数为指引,逐步更新参数的值。
假设有一个神经网络,对于其中的某一个权重参数。此时,对该权重参数的损失函数求导,表示的是‘如果稍微改变这个权重参数的值,损失函数的值会如何变化’。如果导数的值为负,通过使该权重参数向正方向改变,可以减小损失函数的值;反过来,如果导数的值为正,则通过使该权重参数向负方向改变,可以减小损失函数的值。不过,当导数的值为
0 时,无论权重参数向哪个方向变化,损失函数的值都不会改变,此时该权重参数的更新会停在此处
之所以不能用识别精度作为指标,是因为这样一来绝大多数地方的导数都会变为 0,导致参数无法更新。
在进行神经网络的学习时,不能讲识别精度作为指标。因为如果以识别精度为指标,则参数的导数在绝大多数地方都会变为0
假设某个神经网络正确识别了 100 笔训练数据中的 32 笔,此时识别精度为 32%。如果以识别精度为指标,即使稍微改变权重参数的值,识别精度也仍将保持在
32%,不会出现变化。也就是说,仅仅微调参数,是无法改善识别精度的。即使有所改善,也不会像 32.0123…%这样连续变化,而是变为
33%、34%这样的不连续的、离散的值。而如果把损失函数作为指标,则当前损失函数的值可以表示为
0.92543…这样的值。并且,如果稍微改变一下参数的值,对应的损失函数也会像 0.93432…这样发生连续的变化。
识别精度对微小的参数变化基本上没有什么反应,即便有反应,它的值也是不连续地、突然地变化。作为激活函数的阶跃函数也有同样的情况。如果使用了阶跃函数,那么即便将损失函数作为指标,参数的微小变化也会被阶跃函数抹杀,导致损失函数的值不会产生任何变化。
4.3 数值微分
梯度法使用梯度的信息决定前进的方向
4.3.1 导数
加入你十分钟内跑了 2 千米。如果要计算此时的奔跑速度,则为 2/10 = 0.2[千米/分]。也就是说,以 1 分钟前进 0.2 千米的速度(变化)奔跑
这个例子中,我们计算了‘奔跑的距离’相对于‘时间’发生了多大变化。但是,严格地说,这个计算方式计算的是 10
分钟内的平均速度。而导数表示的是某个瞬间的变化量。因此,将 10 分钟的这一时间段尽可能地缩短,比如计算前 1 分钟奔跑的距离、前
1
秒钟奔跑的距离、前 0.1 秒奔跑的距离……就可以获得某个瞬间的变化量(某个瞬间速度)
综上,导数就是表示某个瞬间的变化量。
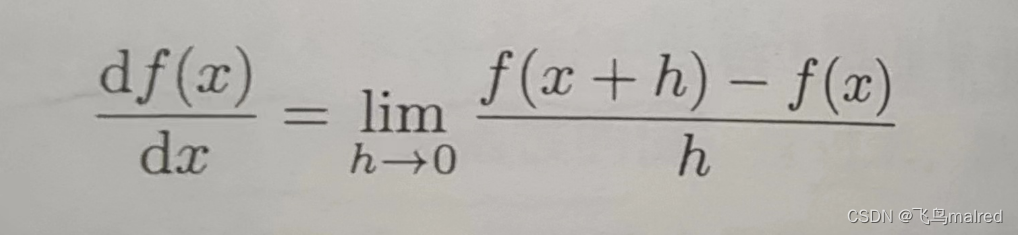
d f(x) / dx 表示 f(x)关于 x 的导数,即 f(x)相对于 x 的变化程度。这个式子表示的导数的含义是,x 的‘微小变化’将导致函数 f(x)
的值在多大程度上发生变化。其中,表示微小变化的 h 无限趋近 0。
# 不好的实现
def numerical_diff(f, x):
h = 10e-50
return (f(x + h) - f(x)) / h
该函数的名称来源于数值微分的英文 numerical differentiation。这个函数有两个参数,即‘函数 f’和‘传给函数 f 的参数
x’。看似没问题,实际上有两处需要改变的地方
在上面的实现中,因为想把尽可能小的值赋给 h(无限接近 0),所以使用了 10e-50 这个微小值。但是,反而产生了舍入误差
。舍入误差就是指,因为省略小数的精细部分的数值(比如,小数点后第 8 位以后的数值)而造成最终的计算结果上的误差。
print(np.float32(1e-50)) # 0.0
如果用 float32 类型(32 位的浮点数)来表示 1e-50,就会变成 0.0,无法正确表示出来。也就是说,使用过小的值会造成计算机出现计算上的问题。所以这里进行改进,将微小值
h 改为 10^-4
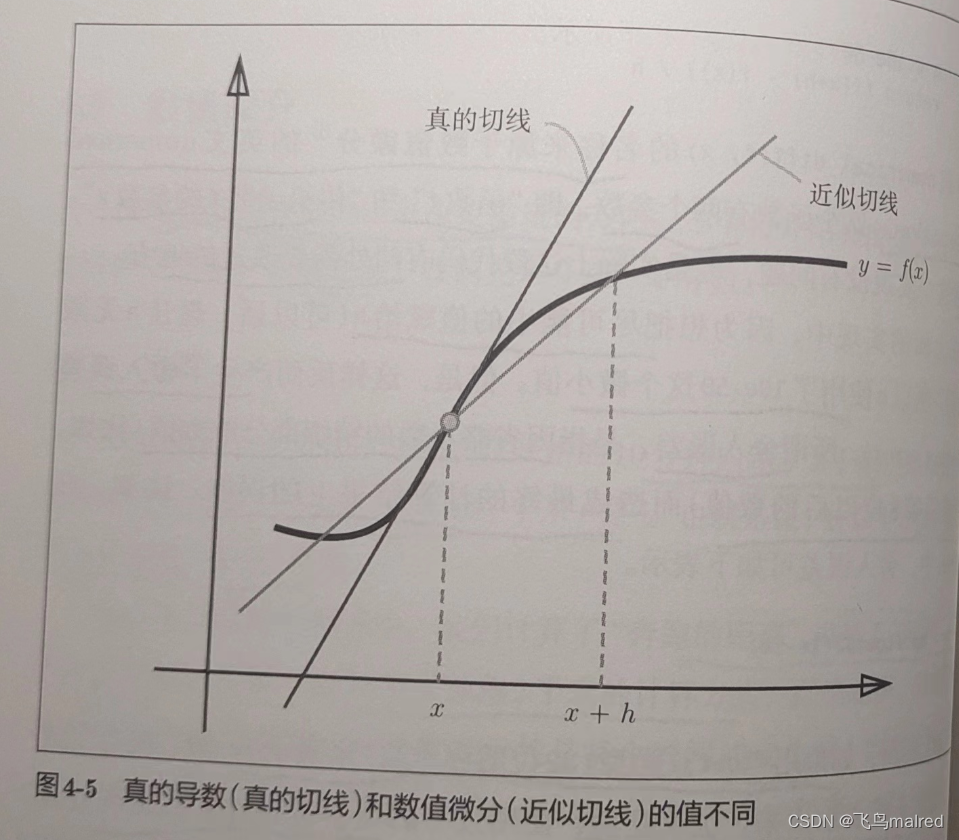
第二个要改进的地方和函数 f 的差分有关。虽然上述实现中计算了函数 f 在 x+h 和 x 之间的差分,但是,这个计算从一开始就有误差。如图
4-5 所示,‘真的导数’对应函数在 x 处的斜率(称为切线),但是上述实现中计算的是(x+h)和 x
之间的斜率。因此,真的导数(真的切线)和上述实现中得到的导数的值在严格意义上并不一致。这个差异的出现是因为 h 不可能无限接近
0
为例减少这个误差,我们可以计算函数 f 在(x+h)和(x-h)之间的差分。因为这种计算方法以 x 为中心,计算它左右两边的差分,所以也称为
中心差分(而(x+h)和 x 之间的差分称为前向差分)。
def numerical_diff(f, x):
h = 1e-4 # 0.0001
return (f(x + h) - f(x - h)) / (2 * h)
- 利用微小的差分求导数的过程称为数值微分(numerical_differentiation)。而基于数学式的推导求导数的过程,则用解析性
(analytic)一词,称为‘解析性求解’或‘解析性求导’。比如 y=x^2 的导数,可以通过 dy/dx=2x 解析性地求出来。解析性求导得到的导数是不含误差的‘真的导数’
4.3.2 数值微分的例子
试着用数值微分对简单函数进行求导。
def function_1(x):
return 0.01 * x ** 2 + 0.1 * x
import numpy as np
import matplotlib.pylab as plt
plt.switch_backend('TkAgg')
x = np.arange(0.0, 20.0, 0.1) # 以0.1为单位,从0到20的数组x
y = function_1(x)
plt.xlabel('x')
plt.ylabel('f(x)')
plt.plot(x, y)
plt.show()
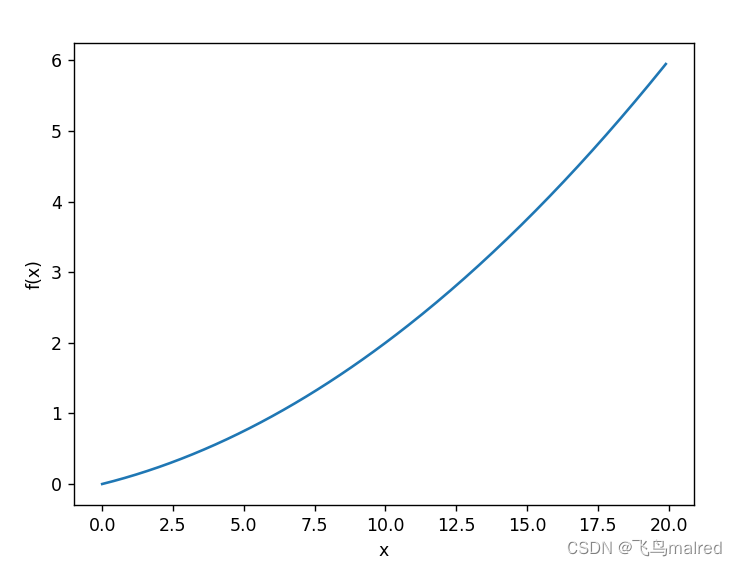
计算它在 x=5 和 x=10 处的导数
# 0.1999999999990898
print(numerical_diff(function_1, 5))
# 0.2999999999986347
print(numerical_diff(function_1, 10))
这里计算的导数是 f(x)相对于 x 的变化量,对应函数的斜率。另外 f(x)=0.01x^2+0.1x 的解析解是 d f(x) / dx = 0.02x + 0.1。因此,在
x=5 和 x=10 处,‘真的函数’分别为 0.2 和 0.3,我们计算的结果和它不一致,但是误差非常小,可以看作相等
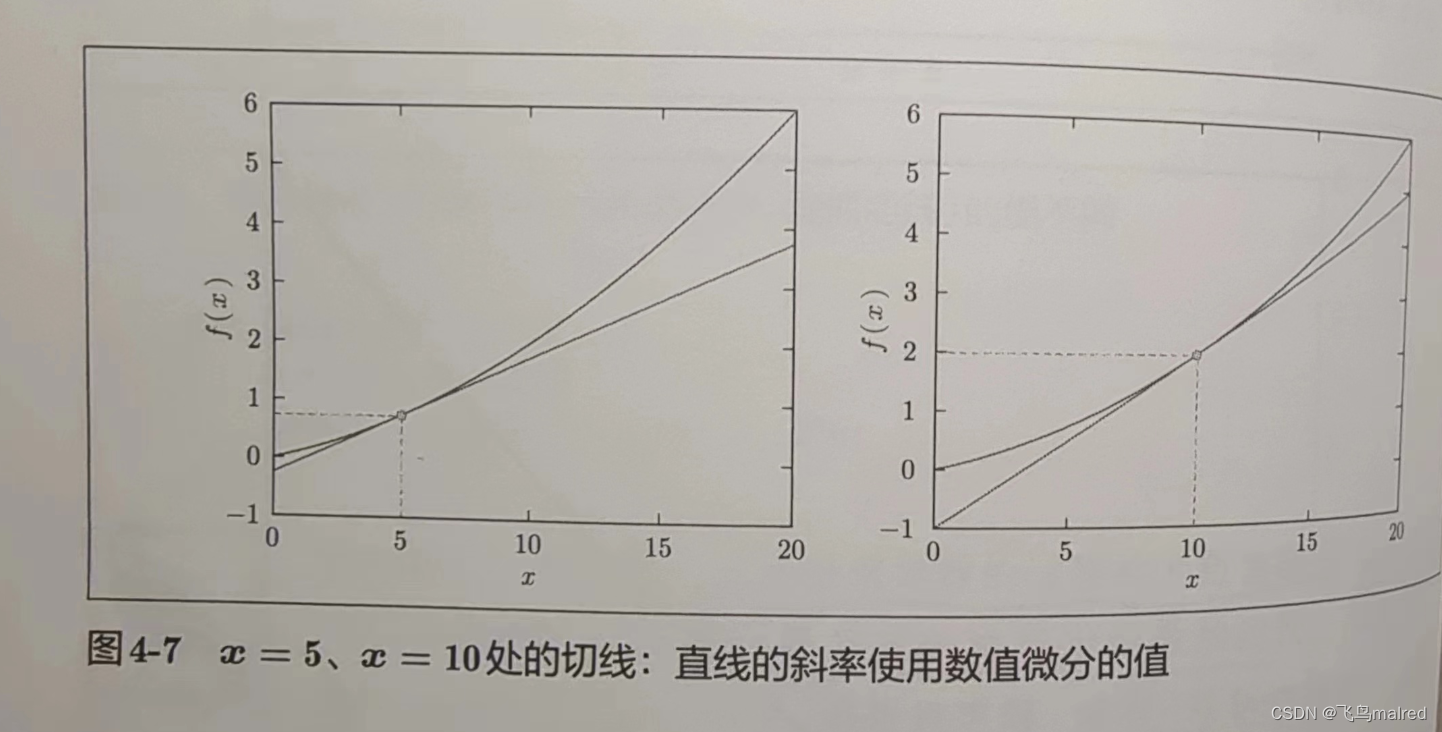
用上面的数值微分的值作为斜率,画一条直线。可以确认这些直线确实对应函数的切线
# coding: utf-8
import numpy as np
import matplotlib.pylab as plt
def numerical_diff(f, x):
h = 1e-4 # 0.0001
return (f(x+h) - f(x-h)) / (2*h)
def function_1(x):
return 0.01*x**2 + 0.1*x
def tangent_line(f, x):
d = numerical_diff(f, x)
print(d)
y = f(x) - d*x
return lambda t: d*t + y
x = np.arange(0.0, 20.0, 0.1)
y = function_1(x)
plt.xlabel("x")
plt.ylabel("f(x)")
tf = tangent_line(function_1, 5)
y2 = tf(x)
plt.plot(x, y)
plt.plot(x, y2)
plt.show()
4.3.3 偏导数
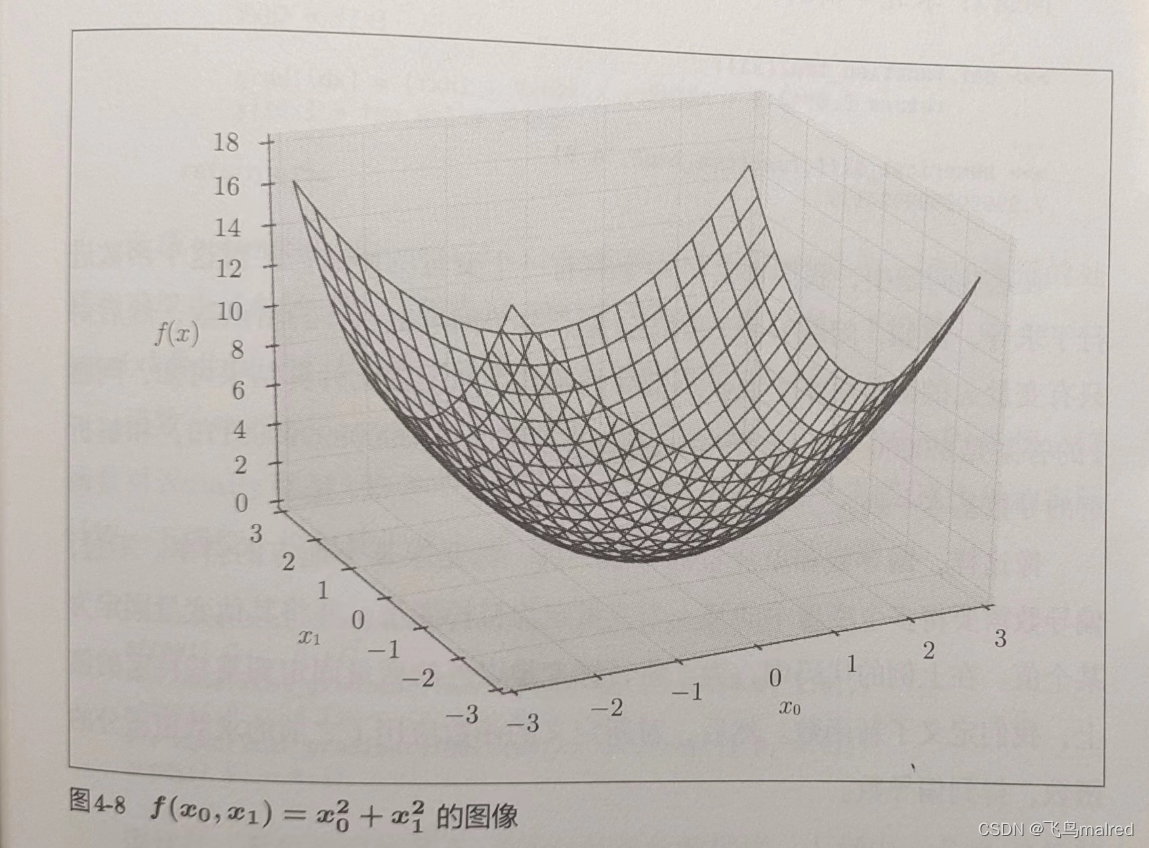
下面看一个计算参数的平方和的简单函数
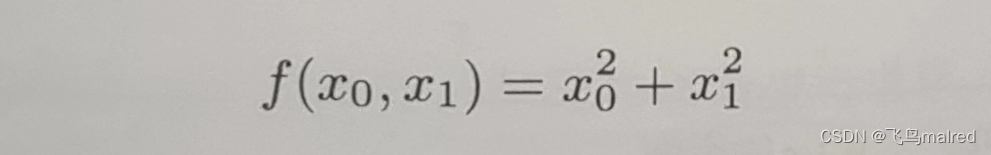
我们假定向参数输入了一个 Numpy 数组,画一下图像。
因为该函数有多个变量,所以求导时要区分对哪个变量求导数,有多个变量的函数的导数称为偏导数。数学表式可以写成
?f/?x0、?f/?x1
# x0=3 x1=4 求关于x0的偏导
def function_tmp1(x0):
return x0 * x0 + 4.0 ** 2.0
# 6.00000000000378
print(numerical_diff(function_tmp1, 3.0))
# x0=3 x1=4 求关于x1的偏导
def function_tmp2(x1):
return 3.0 ** 2.0 + x1 * x1
# 7.999999999999119
print(numerical_diff(function_tmp2, 4.0))
偏导数额和单变量的导数一样,都是求某个地方的斜率。不管,偏导数需要将多个变量中的某一个变量定为目标变量,并将其他变量固定为某个值。上述代码中,为了将目标变量以外的变量固定到某些特定的值上,我们定义了新的函数。如何,对新定义的函数应用了之前的求数值微分的函数,得到偏导数。
4.4 梯度
上面我们分别计算了 x0 和 x1 的偏导数。现在,考虑求 x0=3、x1=4 时(x0,x1)的偏导数(?f/?x0,?f/?x1)。像这样由全部变量的偏导数汇总而成的向量称为
梯度(gradient)。
def numerical_gradient(f, x):
h = 1e-4 # 0.0001
grad = np.zeros_like(x) # 生成和x形状相同的数组
for idx in range(x.size):
tmp_val = x[idx]
# 分别对x[idx]+h和x[idx]-h进行求导(x其他项不变)
# f(x+h)
x[idx] = tmp_val + h
fxh1 = f(x)
# f(x-h)
x[idx] = tmp_val - h
fxh2 = f(x)
grad[idx] = (fxh1 - fxh2) / (2 * h)
x[idx] = tmp_val # 还原值
return grad
下面用该函数计算梯度
# [6. 8.]
print(numerical_gradient(function_2, np.array([3.0, 4.0])))
# [0. 4.]
print(numerical_gradient(function_2, np.array([0.0, 2.0])))
# [6. 0.]
print(numerical_gradient(function_2, np.array([3.0, 0.0])))
这些梯度意味着什么呢?为了理解,我们将 f(x0,x1)=x02+x12 的梯度画在图上。不过这里画的是元素值为负梯度的向量
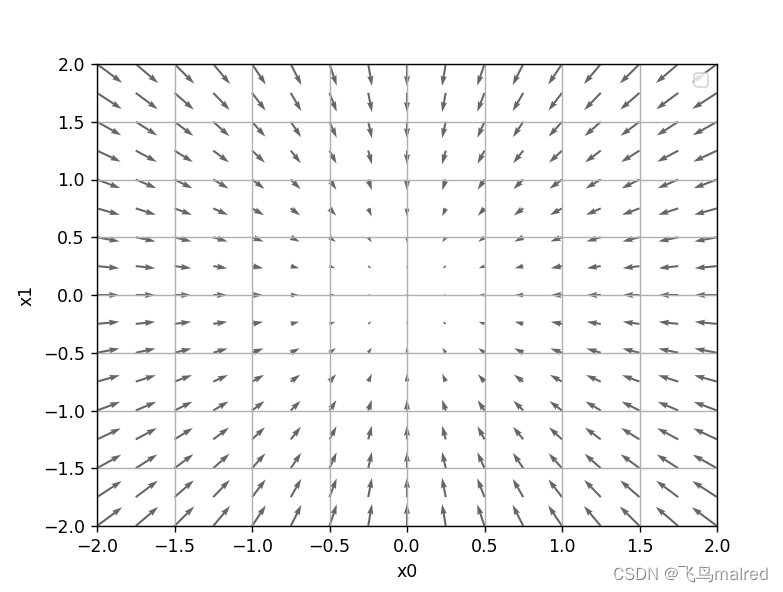
可以看到,该函数的梯度呈现为有向向量(箭头)。并且梯度指向函数的最低处(最小值),所有的箭头都指向同一点。其次,我们发现,离‘最低处’越远,箭头越大
实际上,梯度会指向各点处的函数值降低的方向。更严格地讲,梯度指示的方向是各点处的函数值减小最多的方向。这是一个非常重要的性质
4.4.1 梯度法
机器学习的主要任务是在学习时寻找最优参数。同样地,神经网络也必须在学习时找到最优参数(权重和偏置)。这里说的最优参数是指损失函数取最小值的参数。一般而言,损失函数很复杂,参数空间庞大。不知道何处能取得最小值。而通过巧妙地使用梯度来寻找函数最小值(或者尽可能小的值)的方法就是梯度法。
需要注意的是,梯度表示的是各点处的函数值减小最多的方向。因此,无法保证梯度所指的方向就是函数的最小值或真正应该前进的方向。实际上,复杂的函数中,梯度指示的方向基本上都不是函数值最小处
- 函数的极小值、最小值以及被称为鞍点(saddle point)的地方,梯度为
0。极小值是局部最小值,是限定在某个范围内的最小值。鞍点是从某个方向上看是极大值,从另一个方向上看则是极小值的点。梯度法就是要寻找梯度为
0 的地方,当不一定会找到最小值(也可能是极小值或鞍点)。此外,当函数很复杂且呈扁平状的时候,学习可能会进入一个(几乎)平坦的地区,陷入被称为‘学习高原’的无法前进的停滞期。
虽然梯度的方向不一定指向最小值,但沿着它的方向能够最大限度地减小函数的值。因此,在寻找函数的最小值时,要以梯度的信息为线索,决定前进的方向。
梯度法中,函数的取值从当前位置沿着梯度方向前进一定距离,然后在新的地方重新求梯度,再沿着新梯度方向前进,如此反复,不断沿着梯度方向前进。像这样,通过不断地沿梯度方向前进,逐渐减小函数值的过程就是
梯度法(gradient method)。梯度法是解决机器学习中最优化问题的常用方法,特别是在神经网络中经常使用。
- 根据目的是寻找最小值还是最大值,梯度法分为:寻找最小值的梯度下降法(gradient descent method),寻找最大值的梯度上升法
(gradient ascent method)。但是通过反转损失函数的符号,求最大或最小值的问题可以变成一样的问题,上升或下降的差异本质上不重要。一般来说,在神经网络(深度学习)中,梯度法主要是指梯度下降法
用数学式表示梯度
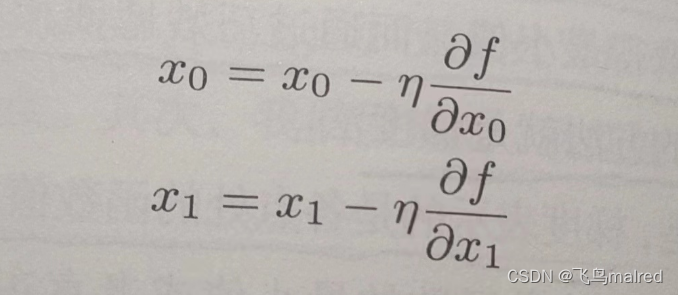
η 表示更新量,在神经网络中,称为学习率(learning rate)。学习率决定在一次学习中,应该学习多少,以及在多大程度上更新参数
该式是表示更新一次的式子,这个步骤会反复执行。每一步都按该式更新变量的值,通过反复执行此步骤,逐渐减少函数值。即使是多个变量,也可以通过类似的式子(各个变量的偏导数)进行更新
学习率需要事先确定为某个值,一般而言,这个值过大或过小,都无法抵达一个‘好的位置’。在神经网络学习中,一般会一边改变学习率的值,一边确定学习是否正确进行了
def gradient_descent(f, init_x, lr=0.01, step_num=100):
x = init_x
for i in range(step_num):
grad = numerical_gradient(f, x)
x -= lr * grad
return x
参数 f 是要进行最优化的参数,init_x 是初始值,lr 是学习率,step_num 是梯度法的重复次数
def function_2(x):
return x[0] ** 2 + x[1] ** 2
init_x = np.array([-3.0, 4.0])
res = gradient_descent(function_2, init_x=init_x, lr=0.1, step_num=100)
# [-6.11110793e-10 8.14814391e-10]
print(res)
这个结果非常接近真实的最小值(0,0)。如果用图来表示梯度法的更新过程,可以发现,原点处是最低的地方,函数的取值一点点在向其靠近。
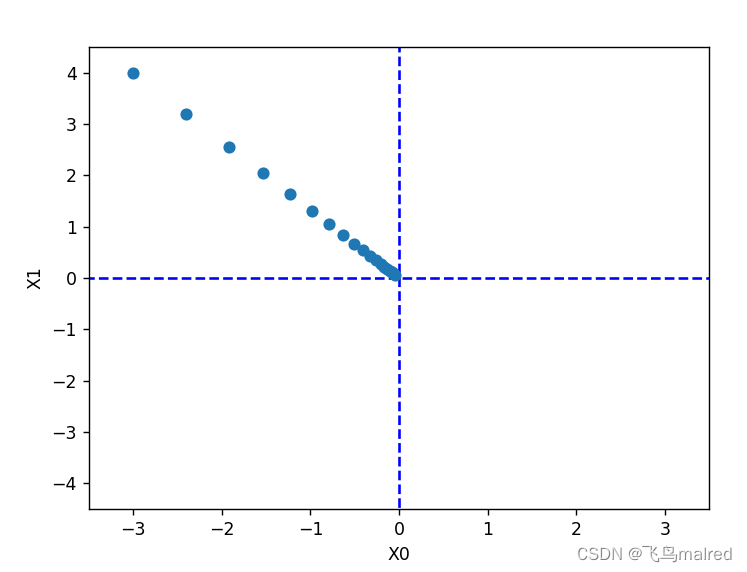
学习率过大或过小都无法得到好的结果。下面实验一下
# 学习率过大的例子 lr=10.0
init_x = np.array([-3.0, 4.0])
res = gradient_descent(function_2, init_x=init_x, lr=10.0, step_num=100)
# [-2.58983747e+13 -1.29524862e+12]
print(res)
# 学习率过小的例子
init_x = np.array([-3.0, 4.0])
res = gradient_descent(function_2, init_x=init_x, lr=1e-10, step_num=100)
# [-2.99999994 3.99999992]
print(res)
实验结果表明,学习率过大的话,会发散成一个很大的值;反过来,学习率过小的话,基本上没怎么更新就结束了
- 像学习率这样的参数称为超参数。和神经网络的参数(权重和偏置)性质不同。神经网络的参数是通过训练数据和学习算法自动获得的,学习率这种超参数则是人工设定的。
4.4.2 神经网络的梯度
神经网络的学习也要求梯度。这里说的梯度是指损失函数关于权重参数的梯度。
损失函数用 L 表示,权重用 W 表示,则梯度用 ?L/?W 表示

?L/?W 的元素由各个元素关于 W 的偏导数构成。表示当 W 变化时,损失函数 L 会发生多大变化,重点是,?L/?W 的形状和 W 相同。
class simpleNet:
def __init__(self):
# 高斯分布进行初始化
self.W = np.random.randn(2, 3)
def predict(self, x):
return np.dot(x, self.W)
def loss(self, x, t):
z = self.predict(x)
y = softmax(z)
loss = cross_entropy_error(y, t)
return loss
simpleNet 类只有一个实例变量,即 2x3 的权重参数,有两个方法,一个用于预测,一个用于计算损失函数。参数 x 接收输入数据,参数 t
接收正确解标签
net = simpleNet()
# [[-0.26117395 0.46609188 0.42375899]
# [ 0.57508072 -0.74113595 -0.15255521]]
print(net.W) # 权重参数
x = np.array([0.6, 0.9])
p = net.predict(x)
# [ 0.36086827 -0.38736723 0.11695571]
print(p)
max = np.argmax(p) # 最大值索引
# 0
print(max)
t = np.array([0, 0, 1])
# 1.0578410655701647
print(net.loss(x, t))
接下来求梯度。这里定义的函数 f(W)的参数 W 是一个伪参数。因为 numerical_gradient(f,x)会在内部执行 f(x),为了与之兼容而定义
f(W)包裹实际要算的 net.loss(x,t)和 W 的偏导
def f(W):
return net.loss(x, t)
dW = numerical_gradient(f, net.W)
# [[ 0.41552689 0.01403747 -0.42956436]
# [ 0.62329034 0.0210562 -0.64434654]]
print(dW)
观察 ?L/?W 中的 ?L/?W11 的值大概是 0.4,这表示,如果 w11 增加 h,则损失函数的值会增加 0.2h。再看 ?L/?W23 大概是-0.6,这表示,如果
w23 增加 h,则损失函数的值会减少 0.6h。从减小损失函数值的观点来看,w23 应向正方向更新,w11 应向负方向更新。至于更新的程度,w23
比 w11 的贡献大
上述代码定义函数使用了 def f(x)…,在 python 中,如果定义的是简单的函数,可以使用 lambda 表示法。
f = lambda w: net.loss(x, t)
dW = numerical_gradient(f, net.W)
求出神经网络的梯度后,接下来只需根据梯度法,更新权重参数即可。
- 为了对应形状为多维数组的权重参数 w,这里使用的 numerical_gradient 和之前的实现稍有不同。
def numerical_gradient(f, x):
h = 1e-4 # 0.0001
grad = np.zeros_like(x)
it = np.nditer(x, flags=['multi_index'], op_flags=['readwrite'])
while not it.finished:
idx = it.multi_index
tmp_val = x[idx]
x[idx] = float(tmp_val) + h
fxh1 = f(x) # f(x+h)
x[idx] = tmp_val - h
fxh2 = f(x) # f(x-h)
grad[idx] = (fxh1 - fxh2) / (2*h)
x[idx] = tmp_val # 还原值
it.iternext()
return grad
4.5 学习算法的实现
神经网络的学习步骤
-
前提
神经网络查找合适的权重和偏置,调整权重和偏置以便拟合训练数据的过程称为‘学习’。神经网络的学习分为下面 4 个步骤: -
步骤 1(mini-batch)
从训练数据中随机选出一部分数据,这部分数据称为 mini-batch。目标是减少 mini-batch 的损失函数的值。 -
步骤 2(计算梯度)
为了减少 mini-batch 的损失函数的值,需要求出各个权重参数的梯度。梯度表示损失函数的值减少最多的方向。 -
步骤 3(更新参数)
将权重参数沿梯度方向进行微小更新。 -
步骤 4(重复)
重复步骤 1、2、3
神经网络的学习按照上面四个步骤。这个方法通过梯度下降法更新参数,因为这里使用的数据是随机选择的 mini batch 数据,所以又称为
随机梯度下降法(stochastic gradient descent)。‘随机’是随机选择的意思,随机梯度下降就是‘对随机选择的数据进行梯度下降法’。深度学习的很多框架中,实现随机梯度下降法的函数一般用名为
SGD。
4.5.1 2 层神经网络的类
import sys, os
# 拼接父目录,接下来就可以从父目录导入python依赖
# sys.path.append(os.pardir)
import numpy as np
from common.functions import *
from common.gradient import numerical_gradient
class TwoLayerNet:
def __init__(self, input_size, hidden_size,
output_size, weight_init_std=0.01):
# 初始化权重
self.params = {}
self.params['W1'] = weight_init_std * \
np.random.randn(input_size, hidden_size)
self.params['b1'] = np.zeros(hidden_size)
self.params['W2'] = weight_init_std * \
np.random.randn(hidden_size, output_size)
self.params['b2'] = np.zeros(output_size)
def predict(self, x):
W1, W2 = self.params['W1'], self.params['W2']
b1, b2 = self.params['b1'], self.params['b2']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
y = softmax(a2)
return y
# x:输入数据,t:监督数据
def loss(self, x, t):
y = self.predict(x)
return cross_entropy_error(y, t)
def accuracy(self, x, t):
y = self.predict(x)
y = np.argmax(y, axis=1)
t = np.argmax(t, axis=1)
accuracy = np.sum(y == t) / float(x.shape[0])
return accuracy
# x:输入数据,t:监督数据
def numerical_gradient(self, x, t):
loss_W = lambda W: self.loss(x, t)
grads = {}
grads['W1'] = numerical_gradient(loss_W, self.params['W1'])
grads['b1'] = numerical_gradient(loss_W, self.params['b1'])
grads['W2'] = numerical_gradient(loss_W, self.params['W2'])
grads['b2'] = numerical_gradient(loss_W, self.params['b2'])
return grads

net = TwoLayerNet(input_size=784, hidden_size=100, output_size=10)
print(net.params['W1'].shape) # (784, 100)
print(net.params['b1'].shape) # (100,)
print(net.params['W2'].shape) # (100, 10)
print(net.params['b2'].shape) # (10,)
params 变量中保存了该神经网络所需的全部参数。并且这些权重参数会用在推理处理(前向处理)中。推理处理的实现如下:
x = np.random.rand(100, 784) # 伪输入数据(100笔)
y = net.predict(x)
grads 变量中保存了各个参数的梯度。计算完梯度后,梯度的信息将保存在 grads 变量中。
x = np.random.rand(100, 784) # 伪输入数据(100笔)
t = np.random.rand(100, 10) # 伪正确解标签(100笔)
grads = net.numerical_gradient(x, t) # 计算梯度
print(grads['W1'].shape) # (784, 100)
print(grads['b1'].shape) # (100,)
print(grads['W2'].shape) # (100, 10)
print(grads['b2'].shape) # (10,)
hidden_size 是隐藏层的神经元数,设置为一个合适的值即可。input_size=784 是因为 MNIST 数据集的图像是 28x28 像素的,输出是
10 个类别,所以 output_size=10
初始化方法会对权重参数进行初始化。如何设置权重参数的初始值是关系到神经网络能否成功学习的重要问题。这里使用符合高斯分布的随机数初始化权重参数,使用
0 初始化偏置
numerical_gradient 方法基于数值微分计算各个参数相对于损失函数的梯度。gradient(self,x,t)是下一章要实现的算法,使用误差反向传播法高效地计算梯度
4.5.2 mini-batch 的实现
mini batch 方法是从训练数据中随机选择一部分数据,再以这些 mini-batch 为对象,使用梯度法更新参数的过程。
import numpy as np
from dataset.mnist import load_mnist
from two_layer_net import TwoLayerNet
(x_train, t_train), (x_test, t_test) = \
load_mnist(normalize=True, one_hot_label=True)
train_loss_list = []
# 超参数
iters_num = 10000
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.1
network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
for i in range(iters_num):
# 获取mini-batch
# 从train_size中随机选batch_size个数字
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
# 计算梯度
grad = network.numerical_gradient(x_batch, t_batch)
# grad = network.gradient(x_batch, t_batch) # 高速版
# 更新参数
for key in ('W1', 'b1', 'W2', 'b2'):
network.params[key] -= learning_rate * grad[key]
# 记录学习过程
loss = network.loss(x_batch, t_batch)
train_loss_list.append(loss)
用图像来表示损失函数的值的推移
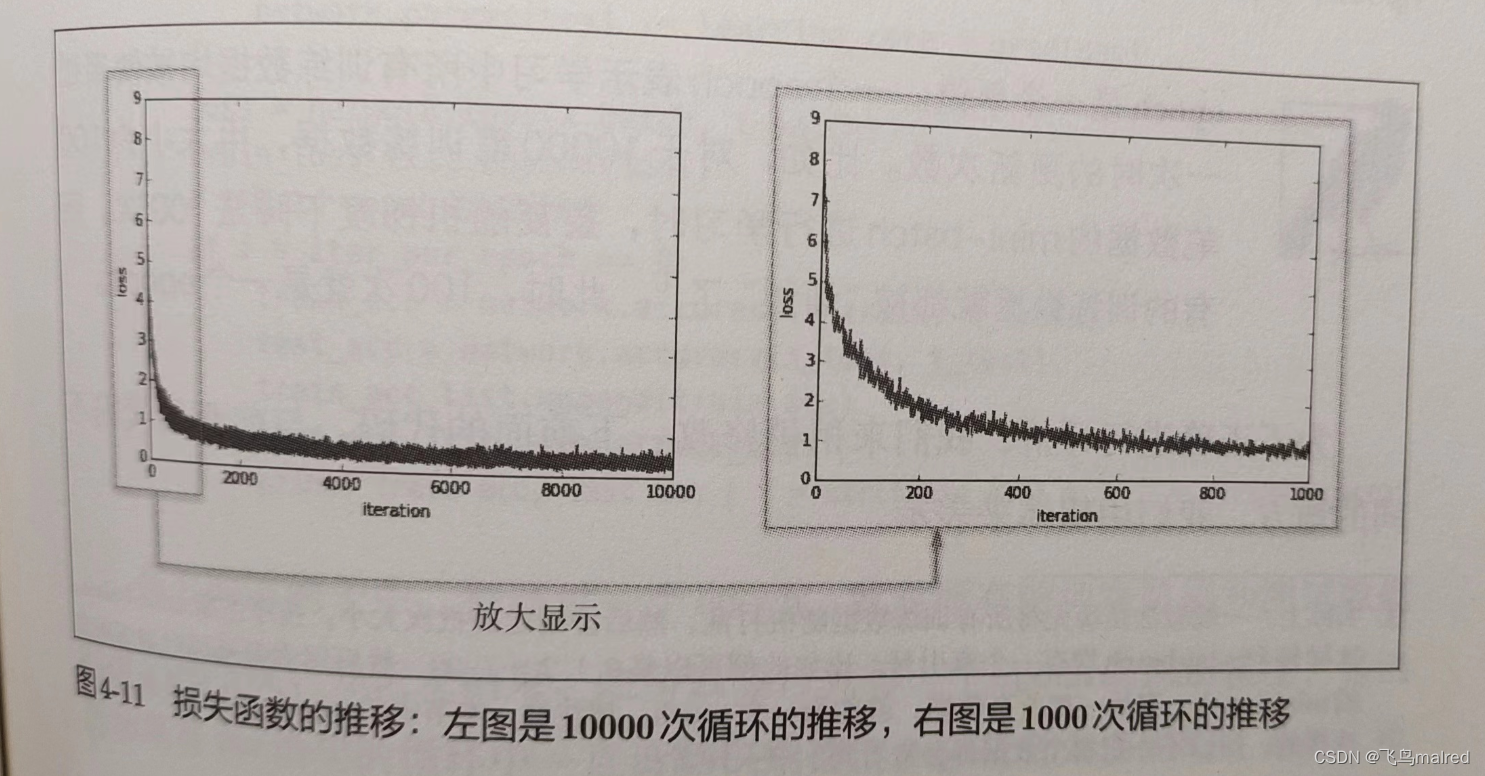
可以看出,随着学习的进行,损失函数的值在不断减小,这是学习正常进行的信号,表示神经网络的权重参数在逐渐拟合数据。
4.5.3 基于测试数据的评价
之前的学习,计算了损失函数,但是严格地说是‘对训练数据的某个 mini-batch
的损失函数’的值。训练数据的损失函数值减小,光看这个结果还不能说明该神经网络在其他数据集上也一定能有同等程度的表现。
神经网络的学习中,必须确认是否能够正确识别训练数据以外的其他数据,即确认是否会发生过拟合。过拟合是指,虽然训练数据中的数字图像能够正确识别,但是不在训练数据中的数字图像却无法被识别的现象。
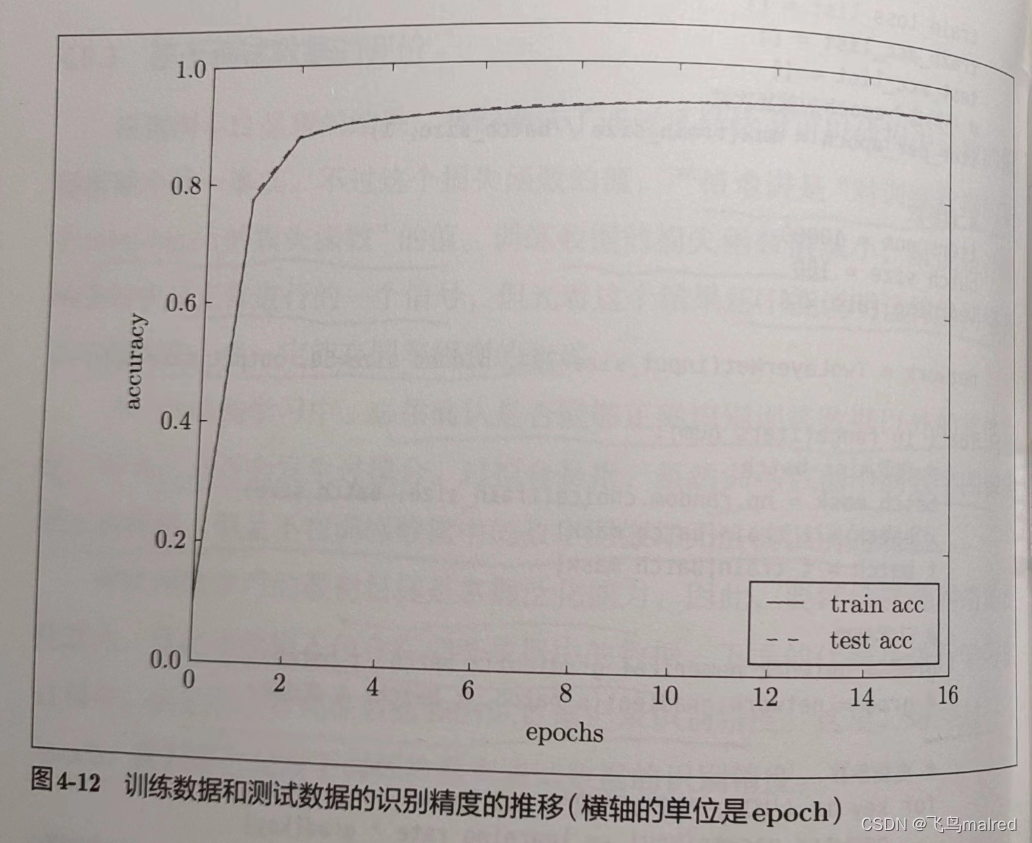
神经网络学习的最初目标是掌握泛化能力,为此,需要使用不包含在训练数据中的数据。下面的代码在进行学习的过程中,会定期对训练数据和测试数据记录识别精度。这里,每经过一个
epoch,都会记录下训练数据和测试数据的识别精度。
- epoch 是一个单位。一个 epoch 表示学习中所有训练数据均被使用过一次的更新次数。比如 10000 笔训练数据,用大小为 100 笔数据的
mini-batch 进行学习时,重复随机梯度下降法 100 次,所有的训练数据就都被‘看过’了。此时,100 此就是一个 epoch
import numpy as np
from dataset.mnist import load_mnist
from two_layer_net import TwoLayerNet
(x_train, t_train), (x_test, t_test) = \
load_mnist(normalize=True, one_hot_label=True)
train_loss_list = []
# 训练和测试时的识别精度
train_acc_list = []
test_acc_list = []
# 平均每个epoch的重复次数
iter_per_epoch = \
max(train_size / batch_size, 1) # 1和train_size / batch_size中最大的那个
# 超参数
iters_num = 10000
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.1
network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
for i in range(iters_num):
# 获取mini-batch
# 从train_size中随机选batch_size个数字
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
# 计算梯度
grad = network.numerical_gradient(x_batch, t_batch)
# grad = network.gradient(x_batch, t_batch) # 高速版
# 更新参数
for key in ('W1', 'b1', 'W2', 'b2'):
network.params[key] -= learning_rate * grad[key]
# 记录学习过程
loss = network.loss(x_batch, t_batch)
train_loss_list.append(loss)
# 计算每个epoch的识别精度
if i % iter_per_epoch == 0:
train_acc = network.accuracy(x_train, t_train)
test_acc = network.accuracy(x_test, t_test)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
print(f'train acc, test acc | {str(train_acc)}, {str(test_acc)}')
之所以计算的是每个 epoch 的精度,是因为如果每个 for 都计算,会消耗很多性能,而且也没必要那么频繁地计算识别精度
4.6 小结
- 机器学习中使用的数据集分为训练数据和测试数据
- 神经网络用训练数据进行学习,并用测试数据评价学习到的模型的泛化能力
- 神经网络的学习以损失函数为指标,更新权重参数,以使损失函数的值减小
- 利用某个给定的微小值的差分求导数的过程,称为数值微分
- 利用数值微分,可以计算权重参数的梯度
- 数值微分虽然费时间,但是实现起来很简单。下一章中要实现的稍微复杂一些的误差反向传播法可以高速地计算梯度
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【并发编程篇】源码分析,手动创建线程池
- PostgreSQL基础
- 前端上传大文件使用分片上传
- 第15课 SQL入门之插入数据
- Linux miniGUI移植分析
- java minio通过getPresignedObjectUrl设置(自定义)预签名URL下载文件的响应文件名之minio源码改造方案
- 《剑指 Offer》专项突破版 - 面试题 11 : 0 和 1 个数相同的子数组(C++ 实现)- 前缀和 + 哈希表
- 1DCNN和CNN的区别?
- 缓存雪崩问题与应对策略
- Java小案例-Synchronized真的很重量级吗?