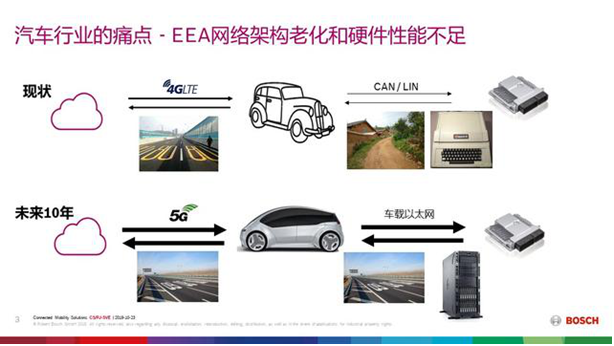
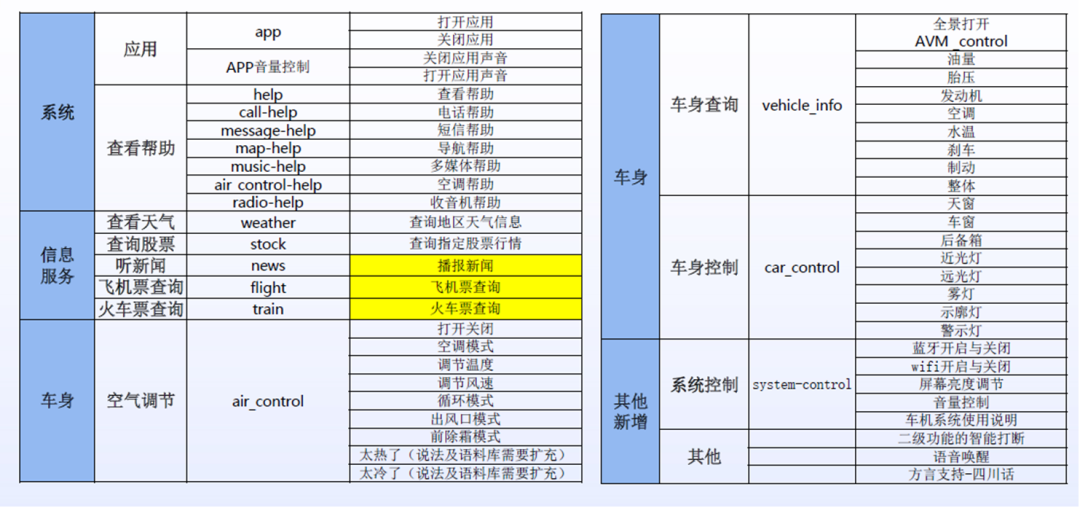
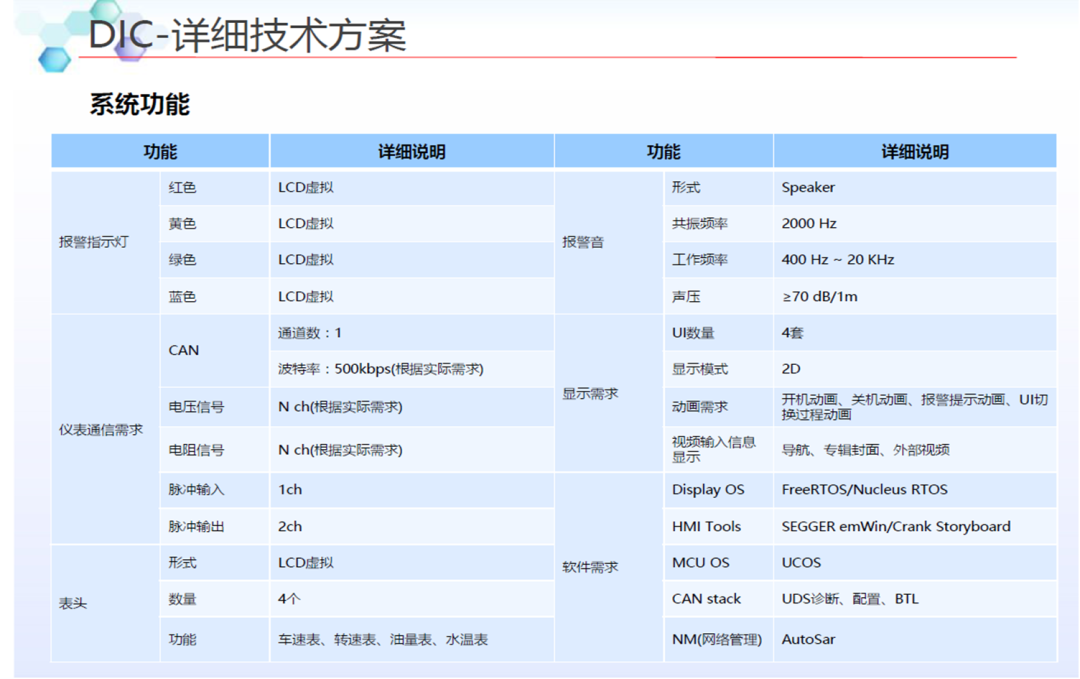
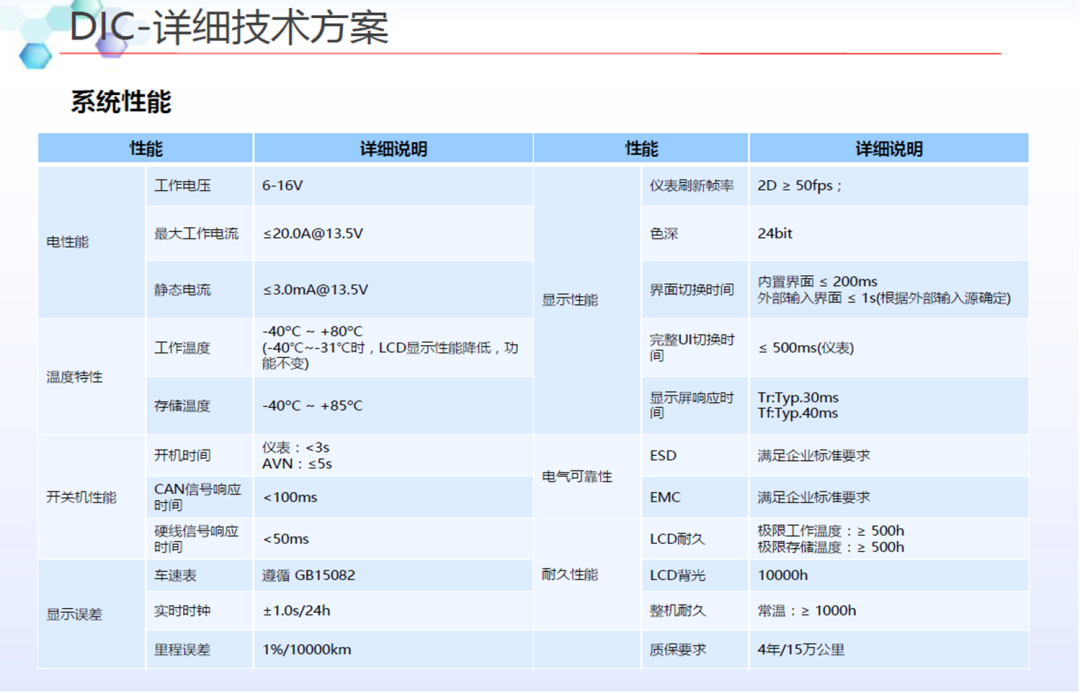
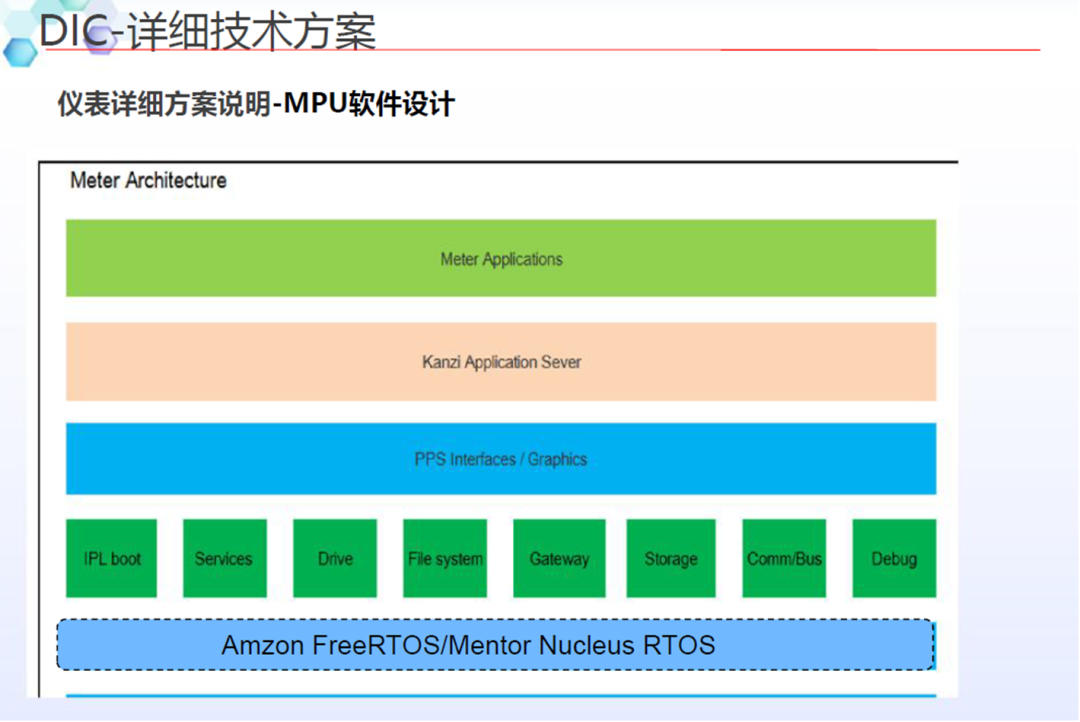
4W字一文带你看懂 智能座舱域控制 主流芯片及平台架构
德国人卡尔·本茨(1844-1929年)于1885年10月成功研制世界上第一辆汽车,采用一台两冲程单缸0.9马力的汽油机。此车具备了现代汽车的一些特点,如火花点火、水冷循环、钢管车架钢板弹簧悬架、后轮驱动、前轮转向和制动把等机械部件。在后续的很长时期内,汽车的发展和革新主要集中在发动机、底盘车身等机械和电气领域。
1、从博世发展看汽车架构变化起源
汽车的起源来自于机械工业的发展,早期的车型是一个纯机械产物。汽车脱胎于马车,真正开始大规模的普及起源于1908年福特采用流水线生产T型车,将汽车从作坊产品带代入流水线工业化时代。

20世纪初的整车,电器部件主要是电磁点火系统。当时的整车按照部件可以分成四个部分:1、引擎+启动部分;2、传动系统;3、悬挂系统与车轮;4、车身。整车里面最主要的电气元件是电磁点火系统,采用干电池系统点火,火花由通过一个安装在引擎前方凸轮轴端部的低电压“计时器”分配到火星塞产生,这种“计时器”就是现代的电器化的前身。

国际Tier1 博世的起步就是伴随整车最原始电气化产品的普及。博世成立于1890年,成立之初做的是精密机械器件和电气工程工作,如安装电话系统和电铃。1897年根据客户要求,生产出了汽车磁力发电机点火装置,并成为唯一的点火设备供应商,以此为起点,正式切入汽车领域。
随着对于汽车功能要求的提升,机械部件逐步被功能更为完善的电气部件取代。在这个过程中,由于电气化是渐进式替代原有机械部件,因此引入的电气化产品都相互独立。随着汽车开始普及,出于高速安全角度,汽车上原本使用的乙炔灯逐步开始被电子照明系统所取代。

1954年,斯图加特车队中博世研究用车搭载不同的大灯和喇叭
博世于1914 年左右推出了电子照明系统,由车头灯、发电机、电压调整器和电池组成的电子照明系统,这也是整车开始开始步入电气化时代最为明显的特征。随后在1915-1940年期间,博世陆续推出了启动电机、车载喇叭、柴油喷射系统、车载收音机等量产产品,持续完善车载电器功能。

1913年,梅赛德斯10/25HP 搭载的博世照明系统,配备发电机、大灯和电压调整器

1927年,博世研发柴油喷射系统

1932年博世首款量产车载收音机
自1960年代中期开始,博世开始专注于开发汽车电子产品,并在内部称为“电子零件时代的来临”。在1970年,电子产品正式成为博世关键产品,从最初的未知领域,摇身一变缔造整个公司延续至今的成功。最经典的例子就是1978 年推出的ABS 防锁死刹车系统,凭借在数个电子元件领域的专业知识,让该系统成为汽车技术工程领域的标准化技术。?

1967年,博世在测试电动车动力电子元件。
从二十世纪90年代开始,博世进一步推动整车架构中电子产品的比例,并开始推出辅助驾驶产品。1990年,博世开发了加速度等矢量传感器,1995年,推出了ESP,奠定了博世在底盘控制领域的地位,2000年推出了ACC、夜视系统等辅助驾驶功能。
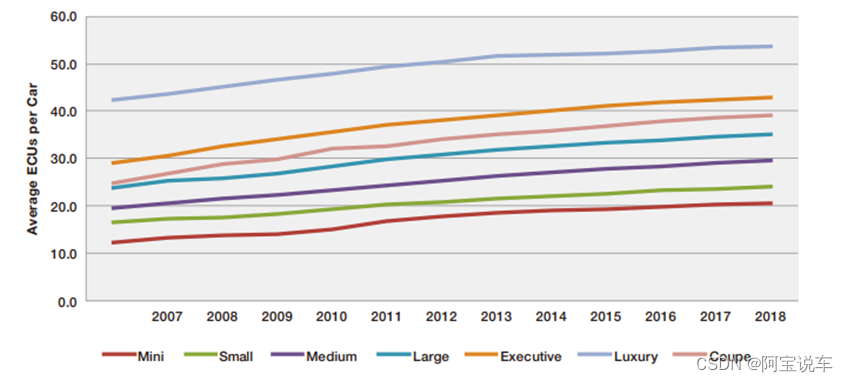
从博世的发展历程可以看到,过去的汽车电子占比提升很大程度由Tier 1来主导,并且是对机械件的替代补充。过去十年,单车的ECU数量接近翻倍增长,高端车型ECU数量由40个增长到55个左右,低端车型中ECU数量由12个增长到21个左右,高端车型超100个。
2、博世提出新的E/E架构
CAN通讯是一个伟大创新
现在大家一提到CAN通讯,都摇头,谁还学这个,随口就是车载以太网,传输速度快,双向通讯,感觉CAN就是上世纪通讯的老古董,就是落后的代名词,如果说汽车的十大伟大发明排序的话,除了发动机,CAN应该能排第二,如果没有CAN通讯,现在的汽车的排放量非常非常大,因为整车的重量太重了。
我们先来看看最原始的发动机和变速箱的交互。
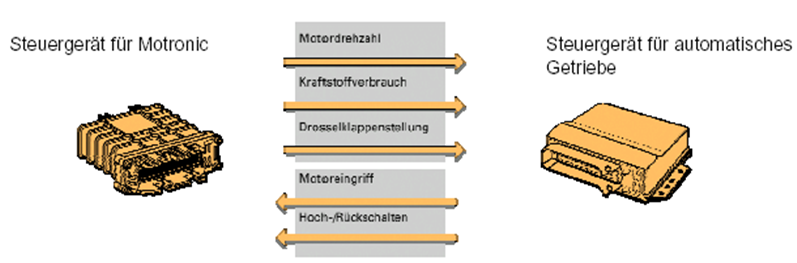
还是以我们的发动机控制单元和变速箱控制单元为例子,这个如果两个控制单元要通讯,发动机把转速、转矩、油门、三个信号给到变速箱,变速箱把提速请求、档位反馈给发动机;
每条信息都需要各自的线路,因此随着信息量的不断加大,所需的线路以及控制单元上的插头数目也随之增加。因此这种数据传输模式仅适用于信息量数目有限的情况下。
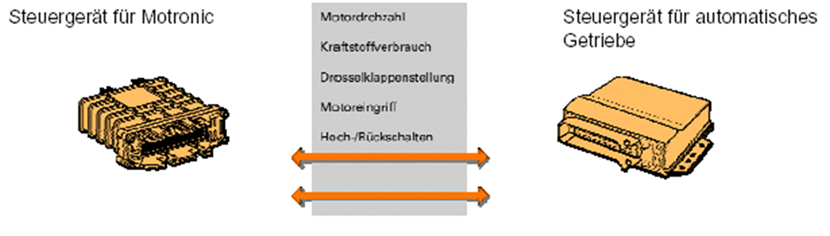
与第一种方法不同,CAN数据总线中,所有信息沿两条线路传输。这两条双向传递的线路中所传递的数据是相同的。在这种传输方式中,线路数与控制单元以及所传递的信息量的数量是无关的。因此当控制单元间需要交换大量信息时,CAN-Bus的优越性就体现出来了。
吃瓜群众:这两个ECU之间也就5根线不多啊,不就比CAN BUS多了3根线么?
机哥:不着急,我给你看看4个ECU之间的通讯是怎么样的。
进入20世纪80年代,汽车逐渐电子化、智能化,新兴的电子技术取代汽车原来单纯的机电液操纵控制系统以适应对汽车安全,排放、节能日益严格的要求。例如,最初由电子控制的燃油喷射、点火、排放、防抱死制动区动力防滑、灯光、故障诊断及报警系统等。
到20世纪90年代以后,陆纱出现了智能化的发动机控制、自动变速、动力转向、电子稳定程序、主动悬架、座椅位置、空调、刮水器、安全带、安全气囊、防碰撞、防盗、巡航行驶、全球卫星定位等智能化自动控制系统,以及车载音频、视频数字多媒体娱乐系统,无线网络和智能交通等车辆辅助信息系统。
欢迎关注我的微信公众号:阿宝1990,每天给你汽车干货,我们始于车,但不止于车。
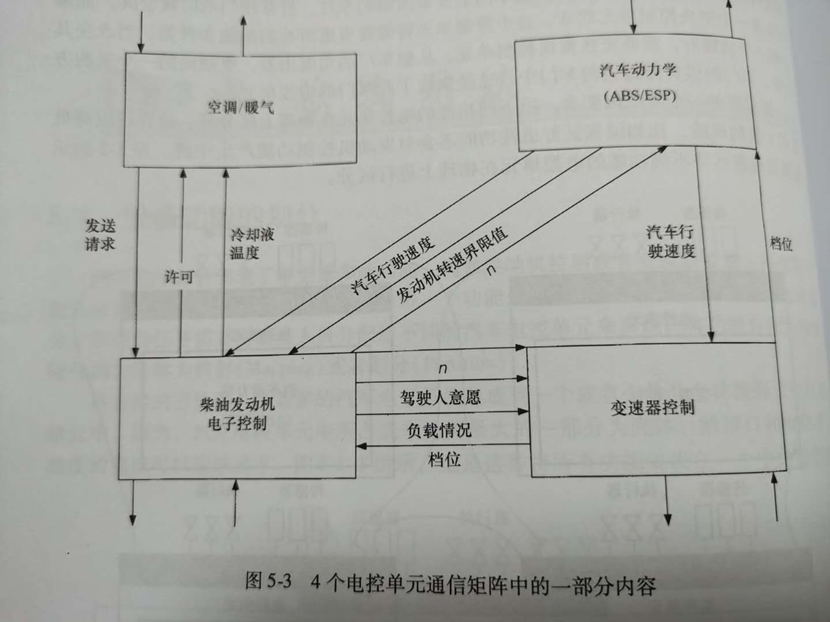
我们来看看汽车底盘中最常见的几个控制器,空调、柴油发动机电子控制、变速器控制、汽车动力学(ABS/ESP),这简单的四角恋关系,需要通信的数据就非常多。
1、首先空调和柴油发动机这块相对简单一些,空调请求发动的命名,然后柴油机发动机会许可给到空调控制器,同时把冷却液温度传递给空调这边。
2、柴油发动机和变速箱的控制就有许多通讯的内容,比如变速箱需要把负载情况档位传递给发动机,发动机需要把驾驶人的控制逻辑传递给变速箱。
3、汽车ABS这块要动作,需要把行驶速度给到发动机,发动机需要把转速界限值给到ABS这块,同时ABS这块也要同变速箱纠缠不清,需要变速箱把档位信息给到ABS,ABS把速度信息给到变速箱,最终综合各方面的因素限定调节,在决策是否输出ABS动作。
虽然这些信息传递的内容并不多,如果没两个器件要把传递的信息都通过线来进行连接,光这几个器件的线束就得20多条,在车里面有100多个ECU,这样如果每个ECU直接都用线缆来连接,估计整车的线束重量比车的支架重量还大。
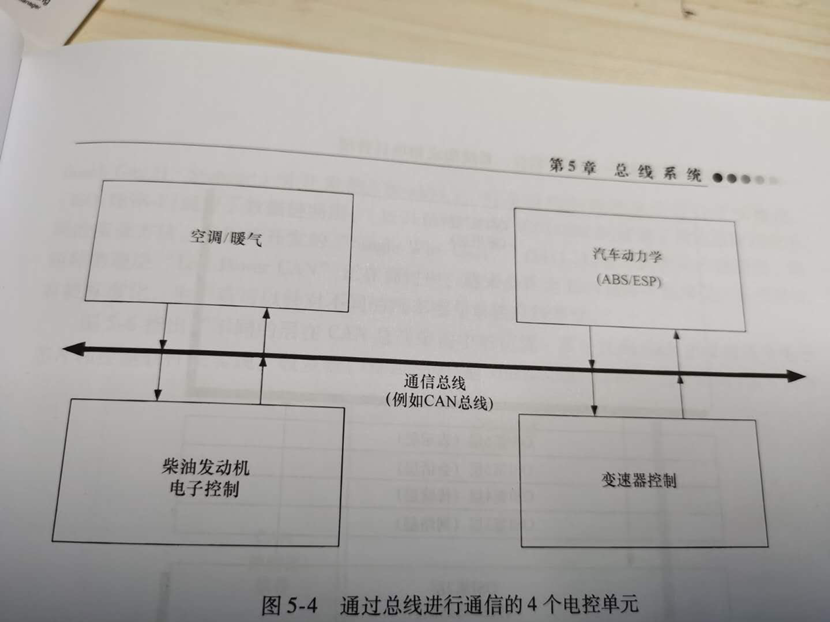
此处用CAN BUS总线来进行通讯,就会发现少了很多接头,而且线束也会少很多,通讯起来非常方便。具体好处如下:
总线功能有较高的可靠性和功能安全性,能大大减少因插头连接和导线所引起的故障。因敷设导线减少而降低装配成本,并减轻线束重量。因采用较小的控制单元和插头而使空间节约下来,并使安装和修改更加容易。控制器之间的数据传输较快。系统诊断能力更强。
越来越多的电子电气系统出现后,相互间的通信冗杂、线束的难度快速提升,新的架构呼之欲出。比如,如何完成这些系统内 ECU 之间的通信成为挑战。为解决这个问题,博世在 1986 年开发出了 CAN 总线,用来对 ECU 的数据进行传输,1991年世界上首款基于 CAN 总线系统的量产车型奔驰 500E 正式亮相。
什么是汽车电子电气架构
汽车电子电气架构,是指集合汽车的电子电气系统原理设计、中央电气盒的设计、连接器的设计、电子电气分配系统等一体的整车电子电气解决方案的概念,基本流程如下图所示
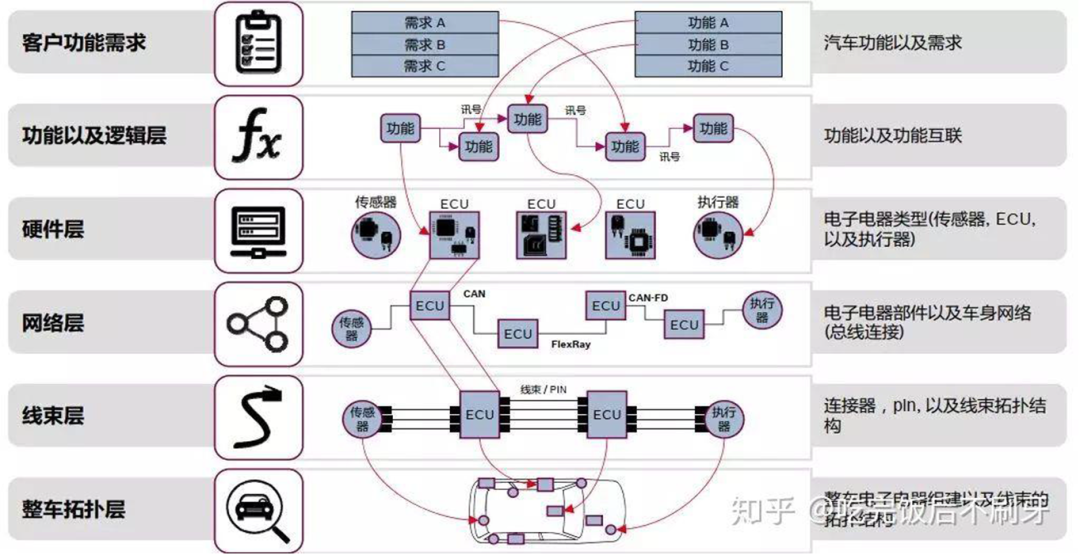
在2007年,德尔福首次提出 E/E 架构的概念,对发动机系统、车窗控制、车载娱乐系统等一切需要电力控制的软硬件进行系统设计和不断优化。通过EEA的设计,可以将动力总成、驱动信息、娱乐信息等车身信息转化为实际的电源分配的物理布局、信号网络、数据网络、诊断、容错、能量管理等的电子电气解决方案
对于架构的讨论,可能最多的就是网络拓扑图,觉得网络拓扑图就是架构。其实网络拓扑图仅是一个表象,就像一栋楼盖地好不好,不能只从外表去看,其实里面看不到的东西才是决定好与坏、先进与否的关键。还有一个是所谓的电气架构,指的是车上电器分布。
一个电气架构需要考虑的不仅是控制器,还要考虑线速、电源分配,包括这些控制器在车上分布位置,还有如保险丝盒是什么样子的,这些都是电气架构需要整体考虑的。至于控制器里面的细节,如使用什么样的处理器,反倒不是电气架构优先考虑的。电气架构更像一张设计图纸,是顶层设计的工作。
而真正影响电气架构本质的东西,也就是冰山以下的东西,首先是功能架构
。也就是这个电气架构要承载多少功能,比如所谓的L3/L4,不仅仅是等级的区别,更是它的功能和安全角度上不一样。还如一个普通的机械式的汽车仪表和一个12.3寸的全液晶的仪表,它们也不仅是表面上的不一样,更是本质上的功能不一样,12.3寸可以显示各种各样的信息,这是普通仪表不具备的。把这些功能搞清楚了,你想要做什么样子的功能,然后这些功能在整个架构下如何分配,他们之间如何关联,这些才是架构设计要优先考虑和解决的问题。随着功能的不断增加,电气架构也需要与之匹配地不断演进。
新的E/E架构
出现背景
为了统筹考虑汽车的电子电气系统原理设计、中央电器盒的设计、连接器的设计、电子电气分配系统等设计,德尔福公司首先提出了整车电子电气架构(EEA)的概念。传统的电子电气架构是一种分布式方案,根据汽车功能划分成不同的模块,如动力总成、信息娱乐、底盘和车身等。这种分布式方案最大的特点是功能划分明确,可以通过预先的设计来严格明确界限,所有历史工作的继承性也很强。
由于划分后的每个模块相对独立,如果需要做出改变,那么选出一部分东西进行更新即可。然而,这种模式的缺点也很明显,那就是容易导致模块太多且可控性不强。传统汽车EE架构下, ECU难以统一, 无法进行OTA, 无法实施软件定义新功能。
1) 传统EE架构中, 当增加一个新功能, 只是简单地添加一个ECU, 增加电线和线束布线, 加大系统复杂性, OEM集成验证更困难。如果需要实现较为复杂的功能,需要许多个控制器同时开发完成才能进行验证,如果其中任意一个控制器出现问题,可能导致整个功能全部失效。
2) 在传统分布式EE架构之下, ECU由不同的供应商开发, 框架无法复用, 无法统一, 同时OTA外部开发者无法对ECU进行编程, 无法由软件定义新的功能,无法进行硬件升级;
3) 基于传统分布式架构, 主机厂只是架构的定义者, 核心功能是由各个ECU完成, 其软件开发工作主要是由Tier 1完成, 主机厂只做集成的工作, 这也是为什么大部分主机厂基本没有软件开发能力的原因, 就靠DRE搞定供应商就能集成一辆车, 为什么还要花成本养一个软件团队。
正式提出
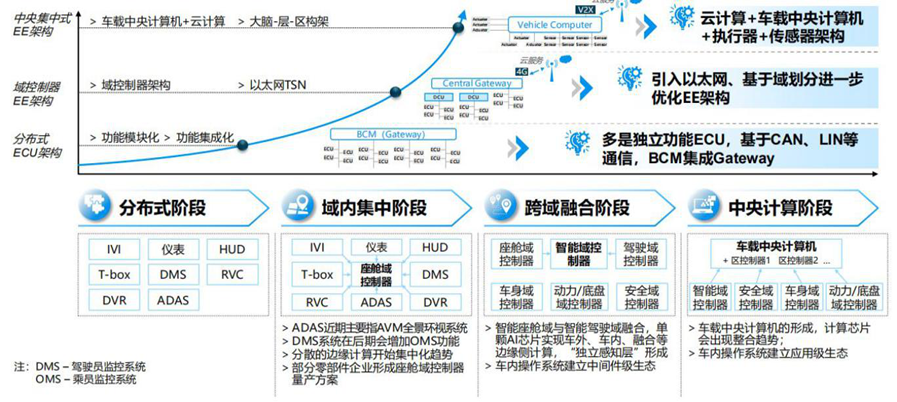
博世于2017年提出了新的电气架构演化图,整车的架构将从离散的分布式架构逐步集成为几个域控制器。
博世将整车电子电气架构发展分为6 个阶段:模块化阶段、功能集成阶段、中央域控制器阶段、跨域融合阶段、车载中央电脑和区域控制器阶段、车载云计算阶段,目前大多数整车厂商开始从模块化向功能集成阶段迈进,而特斯拉已经达到了第五个车载中央电脑和区域控制器阶段。目前汽车的电气架构绝大部分都是处于第一阶段,模块化的阶段。
汽车电子电气架构从分布式向域集中变化
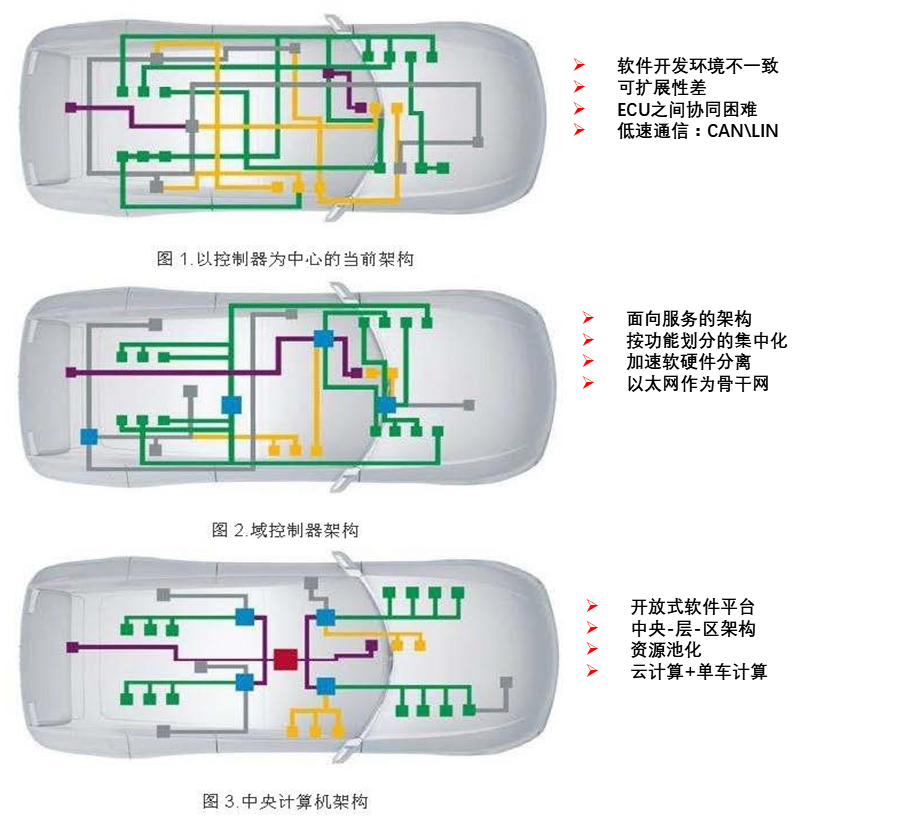
当前,车企正在应用的第一类 E/E 架构,采用分布式设计,分为模块化和集成化两个阶段:
a、模块化阶段,汽车的每个功能拥有独立 ECU,现在大多数汽车处于该阶段;
b、集成化阶段,车辆的设计开始进行功能集成,进而带来 ECU 的被集成。
今后,车企将采用第二类 E/E 架构,采用(跨)域集中式设计,分为集中化和域融合两个阶段,如大众由搭载来自200个不同供应商的70个ECU“减少到三台中央车载电脑”来减少整车软件的复杂性:
a、集中化阶段,指开始出现了域中心控制器;
b、域融合阶段,对应地开始出现跨域中心控制器。特斯拉 Model 3 正是域融合阶段的代表车型。
未来,E/E 架构将发展为第三类架构,即车辆集中 E/E 架构,分为车载电脑和车-云计算:
a、车载电脑阶段,采用的是车载电脑和区域导向架构;
b、车-云计算阶段,车辆功能在云端。
2021年汽车电子电气架构从分布式向域集中变化
博世认为汽车电子电气架构演变路径为分布式、域集中、中央集中式。传统汽车分布式架构缺点越来越明显,高档车使用100~200种不同ECU,汽车的 EEA中搭载了各种功能不同的 ECU 进行协同运作为驾驶员提供各种功能,打造中央集中式EEA架构的车载计算平台,面临“功能安全、实时性、带宽瓶颈、算力黑洞”等多种挑战,所以还得一步一个脚印的发展。
目前车厂逐步将一些ECU功能合并到一个ECU中,减少控制节点,控制器向“域”集成方向发展,目前车辆上主要有动力域、车身域、自动驾驶域、底盘域和信息娱乐域。
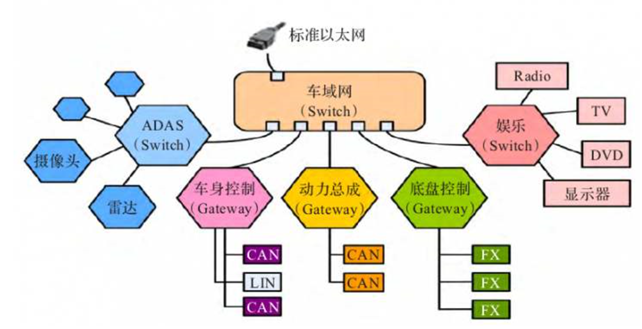
如果我们按照整车三大架构来进行分析:
根据安全性排序:车身底盘动力域>自动驾驶域>座舱域,
从产品形态变化、产业链格局演变情况来看:座舱域>自动驾驶域>车身底盘动力域。由于目前座舱域在硬件上与底层的控制和算法做了物理隔离,能够看到主机厂在座舱方面的尝试最为激进,最典型的代表就是车内大屏与液晶仪表盘的渗透率快速提升。
而车身动力域由于安全性要求最高,并且和底层控制深度耦合,因此无论是产品形态还是产业链的格局,相对变化都较小。而自动驾驶域因为对算力要求远超从前,因此产业链逐步增加了新的供应商。
而这五个域里面,驾驶辅助/自动驾驶域、智能座舱域为汽车未来核心,因为这些域是直接关联用户体验感受的,目前提升空间最大的,动力和车身这部分发展几十年已经非常完善了,特别是电动车以后,这部分对于用户的感受不是特别深,但是自动驾驶和智能座舱就不同,完全给用户全新的体验。
计算集中化后的优势:
1)硬件架构升级:
a.减少内部算力的冗余,避免ECU数量膨胀,减少设计算力总需求;
b.传统分布式架构难以实现实时交互,集中式架构可以统一交互,并实现整车功能协同;
c.集中式架构后,线束缩短,整车质量减轻。
2)软件架构升级:
a.分布式架构软硬一体,整车企业并没有权限去维护和更新ECU,因此无法通过后续OTA更新解决问题。变成集中式架构后,软硬解耦,可以通过系统升级(OTA)持续地改进车辆功能,软件一定程度上实现了传统4S店的功能,可以持续地为提供车辆交付后的运营和服务;
b.整体形成感知层后,采集的数据信息可共用。软硬解耦后,可实现多个应用共用一套硬件装置,有效减少硬件数量。
3)通信架构升级:采用高速以太网取代CAN总线,为未来汽车添加更多车联网、ADAS功能提供支撑。
一句话总结就是既降低了成本,又提升了效果。电子架构变迁的核心驱动力是降本,毕竟都是商人,无利不起早。
车载以太网
CAN 网络无法满足目前车载智能化的一个信息传递的需求,举一个最简单常见的例子,现在的车载普通导航地图一般都需要1-2个月更新一下数据,因为地图厂家会根据目前的数据进行更新,比如某个地段新修了一条道路等等,那么整个全国高清地图包的数据基本上是8G,因为地图不像其他数据可以差分包更新,也就是这个道路更新了这一条,我就把这条道路的信息传递过来,是整个地图包是一体的数据,所以数据量不少。
比如要通过CAN网络更新车载导航的地图,CAN传输速度也就500KB/S,8个G的地图数据需要更新5个小时,这个谁也受不了,当然这个栗子可能不太合适,比较中控导航有WIFI和蓝牙等传输模式,其他的模块就不一定有蓝牙和wifi,只能通过CAN通讯,此时无论是传输信息还是下载更新都是满足不了需求的,所以车身出现了车载以太网。
汽车总线技术解决各个控制器之间信息交互问题,目前汽车总线技术以CAN总线为主,LIN总线为辅,CAN总线具有多主仲裁的特点,但是它在每个时间窗口里只能一个节点赢得控制权发送信息,其他节点都这个时候都要变为接收节点,因此CAN总线只能实现半双工通讯,最高传输速度1Mbps(40m)。为了获得更大的传输速度,BOSCH,freescale等公司开发了Flexray总线用作线控系统的数据传输,宝马、戴姆勒公司开发了MOST (多媒体传输系统)总线用作娱乐系统数据传输。
但随着汽车“新四化”的发展,ECU数量,ECU的运算能力需求都呈现爆发式增长,尤其是ECU与ECU之间对全双工通讯有了强烈需求,继续使用CAN总线连接不仅将造成汽车电子系统成本大增,更无法满足高性能处理器实时高速双向数据交互的需求。
车载以太网使用单对非屏蔽电缆以及更小型紧凑的连接器,使用非屏蔽双绞线时可支持15m的传输距离(对于屏蔽双绞线可支持40m),这种优化处理使车载以太网可满足车载EMC要求。可减少高达80%的车内连接成本和高达30%的车内布线重量。100M车载以太网的PHY采用了1G以太网的技术,可通过使用回声抵消在单线对上实现双向通信,满足智能化时代对高带宽的需求。
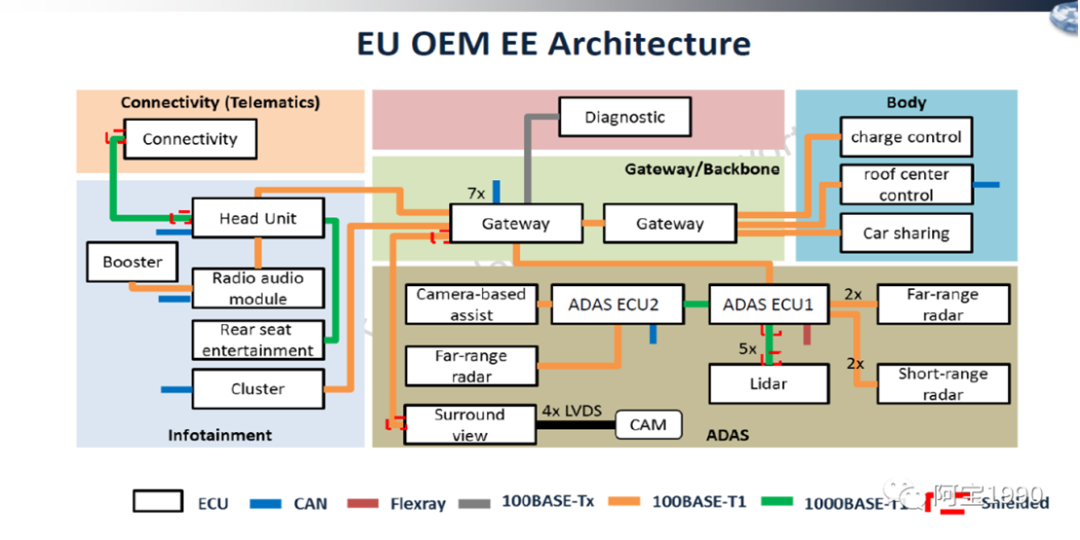
下图就是目前最新使用车载以太网的架构,是不是有疑问,为什么还有can网络,不是所有的地方都是以太网呢?
比如车窗控制,这些非常简单的控制单元,也没有音视频大量数据传输,就是简单信号控制类的,当然车载以太网也可以实现,就有点大材小用了,用can或者lin网络非常低成本,高性价比就可以解决的方案,就没有必要为了高大上去上以太网,毕竟成本才是王道。
车载以太网短期内无法全部取代现有CAN网络,其在汽车行业上的应用需要一个循序渐进的过程,大致可分为 3 个阶段:局部网络阶段、子网络阶段多子网络阶段。:
1)局部网络阶段,可单独在某个子系统上应用车载以太网技术,实现子系统功能,如基于 DoIP 协议的 OBD 诊断、使用IP 协议的摄像头等;
2)子网络阶段,可将某几个子系统进行整合,构建车载以太网子系统,实现各子系统的功能,如基于 AVB 协议的多媒体娱乐及显示系统、ADAS 系统等;
3)多子网络阶段,将多个子网络进行整合,车载以太网作为车载骨干网,集成动力、底盘、车身、娱乐等整车各个域的功能,形成整车级车载以太网络架构,实现车载以太网在车载局域网络上的全面应用。
3、特斯拉的电子电气架构变化?
域控制器可以完成各自域内协调工作,便于软件管理和车辆变形。域集中和中央计算平台架构使原来分散的算力集中化,在降低架构复杂度同时提高了系统算力,软硬件解耦让汽车软件实现即插即用,具备可持续迭代升级的能力。
在电子电气架构方面,目前特斯拉发展最为领先,其新一代集中式 E/E 架构达到车载中央电脑和区域控制器阶段,配合自研的操作系统,可实现整车 OTA。目前相对传统车企E/E架构,特斯拉领先五年以上。其他主机厂如大众、奥迪、通用、丰田等车企都在加快部署全新 E/E 架构,量产时间大概在 2021-2025 年。比如大众 ID.3 将搭载名为 E3的 E/E 架构,并将出现跨域中心控制器,实现域融合架构;通用新一代 E/E 架构 Global B,将搭载在全新凯迪拉克 CT5 上;丰田则将采用 Central & Zone 的 E/E 架构。
我们就来看看特斯拉的电子电气架构的变化。
欢迎关注我的微信公众号:阿宝1990,每天给你汽车干货,我们始于车,但不止于车。
MODEL S电气电子电气架构
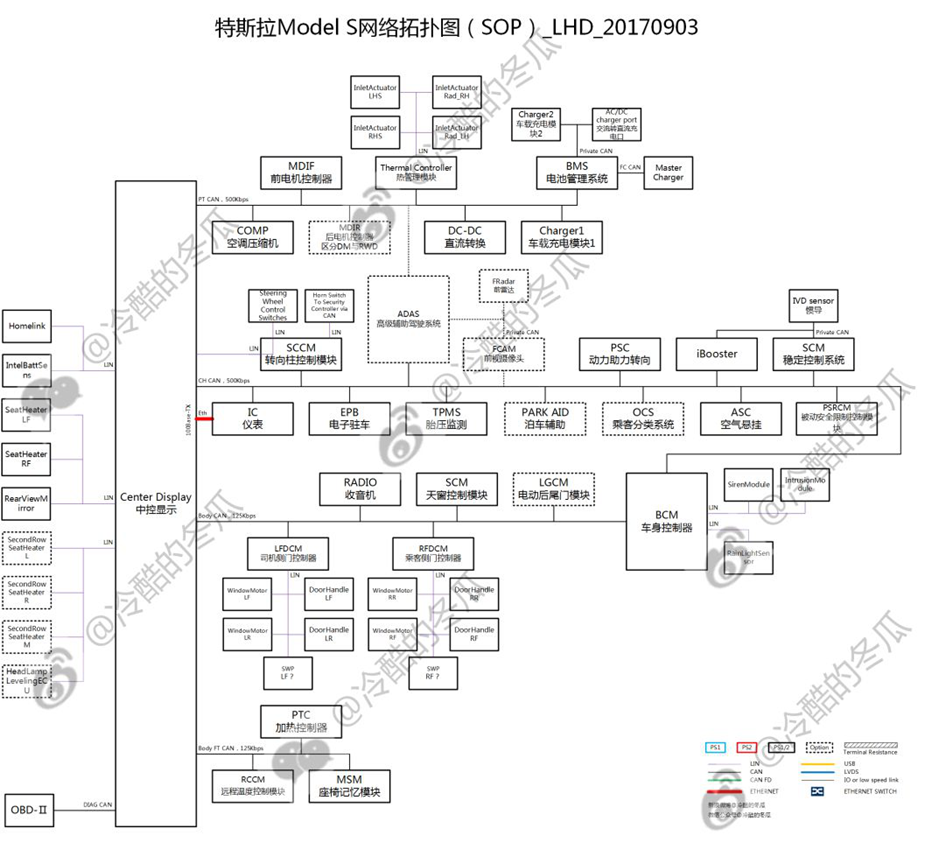
我们先看下基本面
1、大量使用CAN/LIN用作主干网、支干网,速率包括125kbps、500kbps;Ethernet也有使用,但仅用于IC与Center Display之间以及诊断接口;
2、较为明显的域划分,包括动力域PowerTrain、底盘域Chassis、车身域Body以及一路低速容错Body FT;
3、72个控制器ECU节点,其中44个CAN节点、28个LIN节点与中大型豪华电动轿车相符。
...如果只有上面这些是不是有点平平无奇?我们继续。
4、ADAS模块横跨PT与CH,因为高级辅助功能对动力和制动转向的实时性需求;
5、天窗模块SCM为CAN节点,2014年6月特斯拉曾经通过OTA更新了天窗舒适停止的位置“Comfort setting on pano roof has changed from 80% to 75%”,可能与节点选型相关;另外一方面也看出来供应链的区别:目前国内该类控制器多选型为LIN节点;
6、量产车型仍留下诊断接口???调试接口在试制、下线以及售后都可以发挥不小的作用,特斯拉为了追求极致的效率可以说是...很棒了;
说到以太网,我们有注意到特斯拉使用的是传统以太网,可能是Center Display投射到IC地图的需求,而较短的走线则抵消了EMC干扰及价格重量的劣势。
7、Center Display横跨多个网段,充分接入更多节点,集成了GW、HU、T-BOX...等诸多功能,俨然汽车大脑级的存在;这种设计理念搁现在可能没啥,但是别忘了,这是6年前横空出世的Model S!加上2~3年的车型开发周期也就是说至少8年前特斯拉的设计!而自行开发的决定则和创始灵魂艾伯哈德、施特劳贝尔的背景一脉相承。
按照博世的EEA(Electric Electronic Architecture,电子电气架构)进化,针对Center Display来说Model S可是一步跨到了Vehicle Computer的层级!
当然特斯拉愿不愿意往上靠是另外一回事了。
MODEL X电气电子电气架构
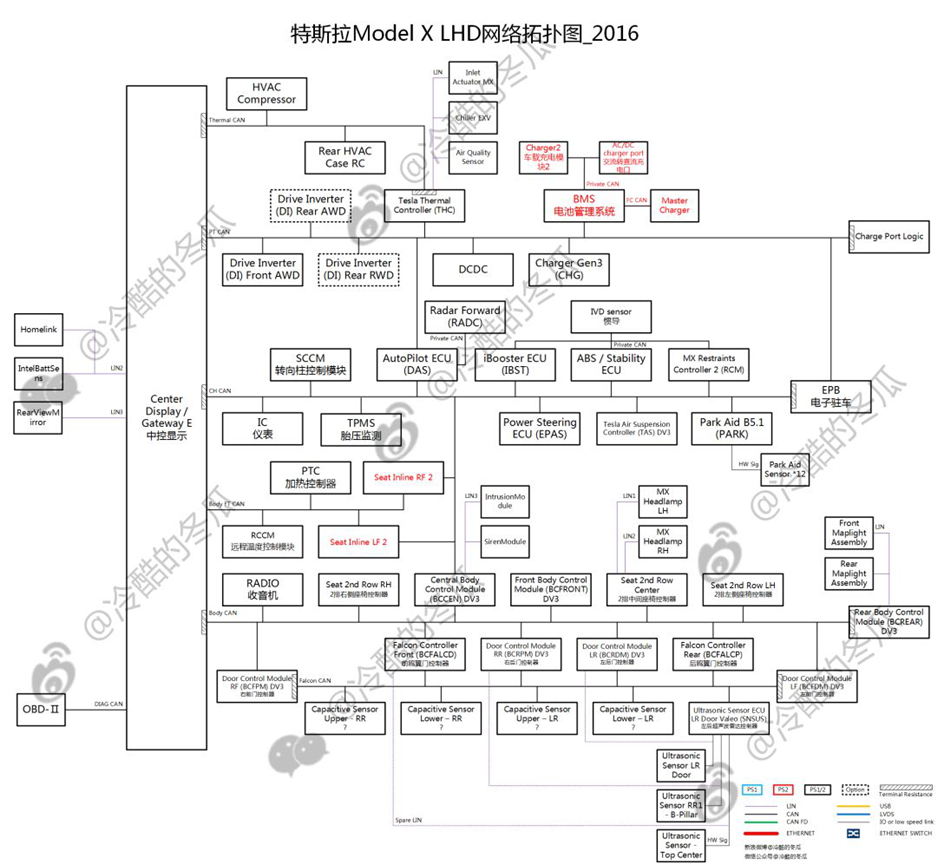
...不知道大家看到Model X的拓扑与Model S对比什么感觉?
在我看来就一个感觉:这就是一个模子里面出来的呀!
我们来看下,
1、4个网段、主要通信类型CAN/LIN都没变吧;
2、主要节点都没变化吧(这个是废话了...);
3、增加的Falcon CAN(鸥翼门相关功能)还是挂在Body CAN下面也是憋屈的没谁了...
4、Thermal CAN单独接入一路到Center Display&Gateway;
5、其他的诸如座椅控制器、车门控制器的增多主要用于二排联动、主驾电吸门等控制逻辑;
6、诊断接口继续发扬...增加了Thermal CAN与Falcon CAN;
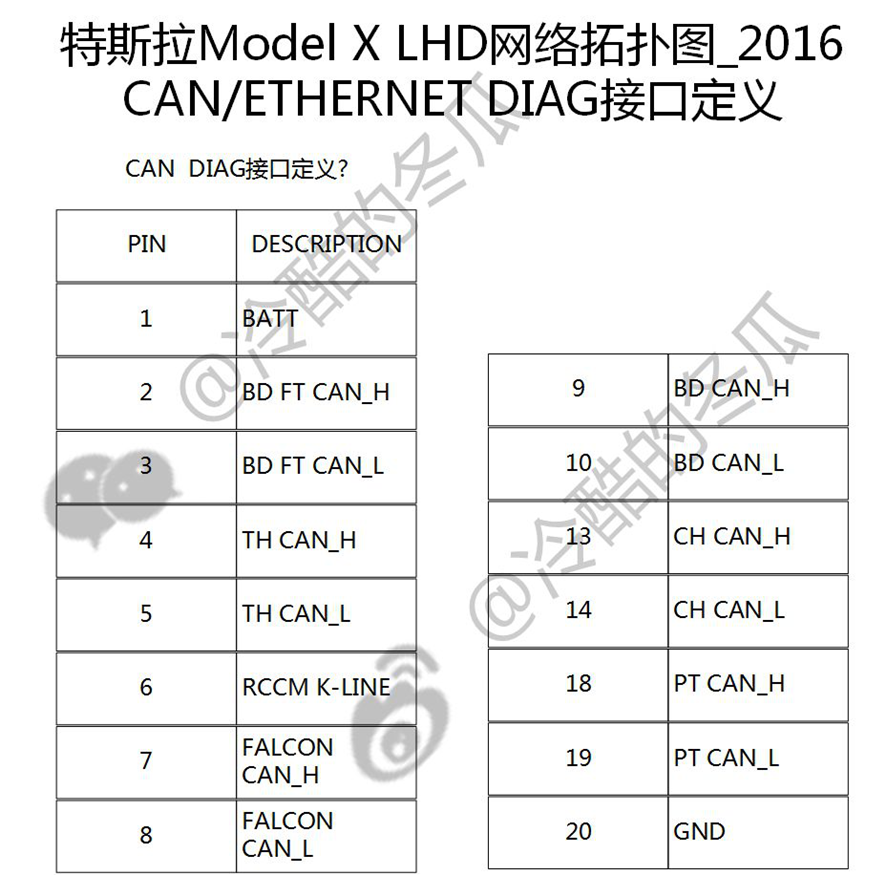
7、注意跨网段的趋势,比如中央车身控制器Central Body Control Module横跨底盘Chassis、车身低速容错Body FT以及车身Body,这一点在Model 3上面会大爆发。
总体来说虽然Model X相比Model S车型有跨越,但是针对电子电气架构来说没有太大的变动,可以说是平台的变种。
MODEL 3电气电子电气架构
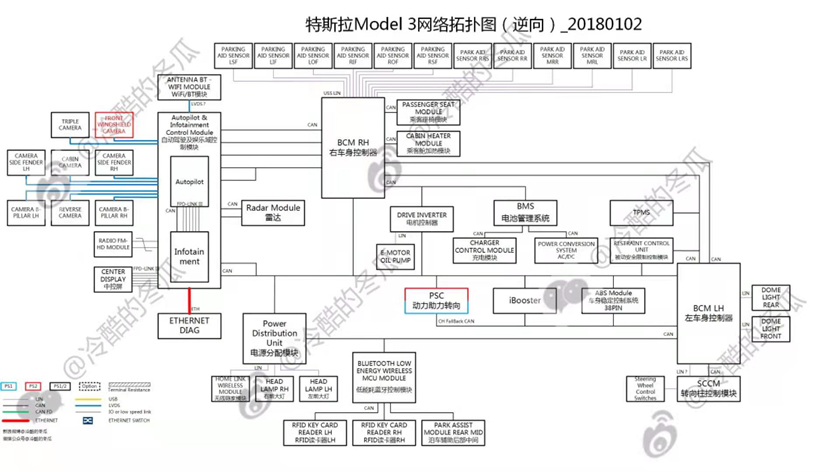
Model 3的拓扑...我是谁?我在哪儿???
1、动力域?车身域?娱乐域?不存在的,映入眼帘...emmm夺人眼球的是3大块:一个是自动驾驶及娱乐控制模块Autopilot & Infotainment Control Module,二个是右车身控制器BCM RH,三个是左车身控制器BCM LH;
2、...你们猜的没错,这三个控制器都是特斯拉自行开发;
3、自动驾驶及娱乐控制模块Autopilot & Infotainment Control Module这次彻底接管了所有辅助驾驶相关的sensor,摄像头camera、毫米波雷达Radar,超声波雷达除外,主要用于泊车为低速场景由右车身控制器BCM RH完成;注意了浓眉大眼的特斯拉也是有车内摄像头Cabin Camera的嗷,虽然没启用但是大概率为驾驶员监测系统(DMS,Driver Monitor System)做预留(责任评判...);
4、右车身控制器BCM RH,初步判断集成了自动驶入驶出AP(Automatic Parking/Autonomous Pull Out)、热管理、扭矩控制等;事实上,这里正是特斯拉厉害的地方:硬件抽象(硬件和软件的分离)。我们回头看下S和X:热管理几乎都是独立的控制器模块,扭矩控制几乎都运行在Center Display中,也就是说之前的code完美地移植到了3的右车身控制器BCM RH中!
有没有似曾相识的感觉?
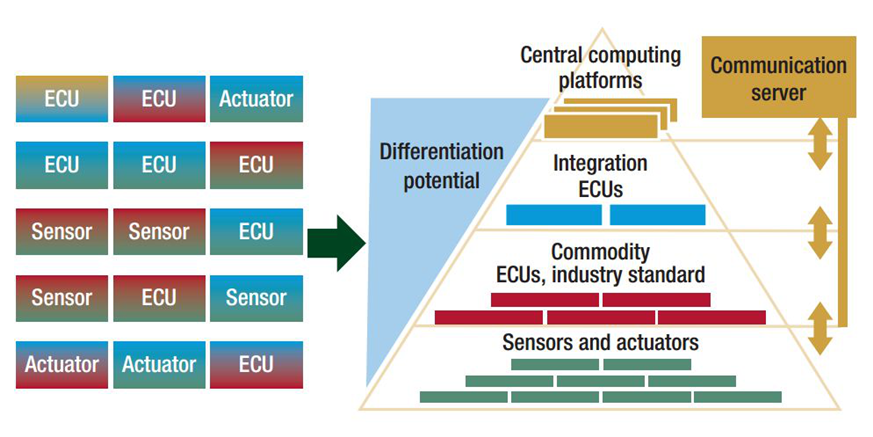
上图是在电子电气架构方面一向激进、开放的宝马规划的下一代EE架构。殊途同归。
5、左车身控制器BCM LH,与右模块相同的是横跨多个网段,不同的是左模块负责了内部灯光、进入部分;事实上这里面有个特斯拉的思考那就是分区域的控制模块,举个典型的例子:驻车卡钳(没错EPB的功能...由左右车身控制器瓜分了);
6、还有一个特立独行的模块:低压电源分配模块Power Distribution Unit,48个PIN脚(除去CAN/LIN/GND),其中Sensor供电6个,包含各种液位、温度等传感器;Actuator/Drv供电/驱动30个,覆盖各种锁、电机、泵、电磁阀等阀门以及灯光;ECU供电12个,包含主要控制器,其余部分由主控制器分级供电。目测其功能一是实现用电器更精准的供电管理,二是可控的供电时序…如果能够干掉保险丝盒...那可能会是一大收益;
7、右车身控制器BCM RH横跨Drive Inverter与底盘Chassis,为刚升级的赛道模式「Track Mode」提供了架构支撑;
8、关于冗余设计,可以先看下特斯拉自动驾驶技术路线,基于视觉的渐进式路线,传感器方面没有选择LiDAR、更多的毫米波雷达,而在底盘域的关键传感器除了扭矩(疑似)有双路采集,其他的都没有;事实上其电子转向助力模块Power Steering ECU像极了博世华域的PP3.2平台;再加上iBooster、ABS的通信备份...往大了可以说特斯拉Model 3做好了制动、转向的冗余设计;
9、关于星型网络,我的看法是单从架构拓扑无法评判,得看具体的功能分配;事实上,自动驾驶及娱乐控制模块Autopilot & Infotainment Control Module、右车身控制器BCM RH以及左车身控制器BCM LH亦可以看做网状网络,而在接口都具备的情况下功能的分配(互为备份)则仅仅是软件的问题,而软件正好是特斯拉的强项;
9、胎压监测模块TPMS,一个接收端居然没集成到车身控制器中与遥控钥匙共用RF模块,这个是我比较疑惑的地方;至于诊断接口,Model 3则只剩下...Ethernet。
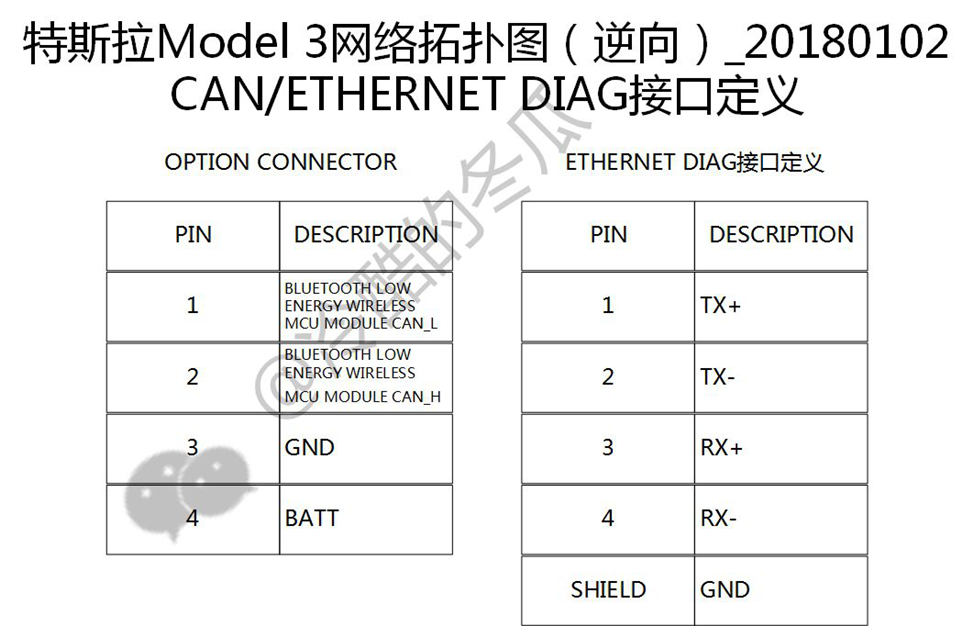
前面说了特斯拉的电气电子架构,我们再来看看model3 的特点:
Model 3的第一大特点那就是高集成度。无论是前车身控制器还是左车身控制器抑或是右车身控制器,其PCBA上的元件铺贴密度都非常高,右车身控制器的PIN脚数量甚至达到了277的惊人数量。
这三个车身控制器,相当于传统车的车身控制器、座椅控制器*2、门控制模块*4、方向盘位置记忆控制器、电子驻车控制器、自动泊车辅助控制器、空调控制器、智能电池传感器的集合,并且还同时取代掉了传统车上的发舱保险丝盒及驾仓保险丝盒,这么算下来是14 IN 3,基本上把能集成的硬件全部集成起来了,集成度着实是高。
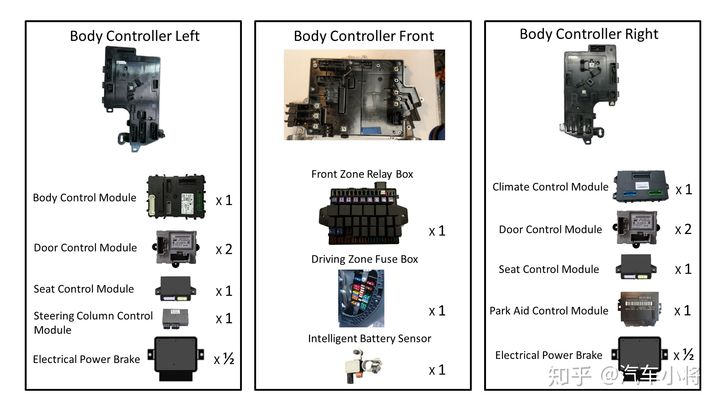
Model 3车身控制器方案的第二大特点是一板多芯,也就是在一块PCBA上设计了多颗控制器。前车身控制器中有4颗MCU,而左车身控制器与右车身控制器中各有3颗MCU。一板多芯本质上是由于第一个特点也就是高集成度所带来的一个结果,当然多MCU冗余设计也可以为部分功能的功能安全级别提供有力保障。但这也同时带来了诸多挑战,控制功能的任务拆解与分配、MCU间的板级通讯、多MCU的诊断刷新以及OTA升级等等问题都需要多重考量测试与论证,方能落地实施。

Model 3车身控制器方案的第三大特点是去保险丝化和去继电器化。Model 3在电气设计上,取消了传统车的保险丝及继电器盒,全车除了电池内部控制器外已经全部取消了继电器和可熔断保险,取而代之的是在车身控制器内部集成了电子保险丝盒的功能,通过MOSFET控制不同的负载的供电并检测每一路的电流抒情情况。
前车身控制器作为一级配电单元,直接从蓄电池取电并进行分配;左右车身控制器分别作为二级配电单元,对不同的负载进行电源配给。猜想之所以特斯拉放弃了继电器有如下原因:
①继电器体积大,不容易提升集成度;
②长远来看,半导体的成本会越来越低,而继电器在保证品质的情况下成本几乎没有压缩空间,因此继电器相对于MOSFET没有成本优势;
③继电器是机械件,相对于MOSFET故障率更高;
④继电器需要搭建额外的电路进行输出电流的诊断,而MOSFET不需要;
⑤继电器在接通和断开时会有声响,对整车的NVH会造成一定影响;
⑥继电器在触点老化后容易出现拉弧,致使其EMC性能也不如MOSFET。
综上,可以看出特斯拉摒弃了继电器也有相对充分的理由,继电器也可能真的从Model 3开始,逐渐退出汽车电控的舞台。另外,使用MOSFET除了可灵活的控制每一路负载的配电外,还可以进行开路诊断以及过流保护,也就兼具了保险丝的作用,因此特斯拉索性将熔断式保险丝一并去掉了。
Model 3车身控制器方案的第四大特点是淡化了专用控制器的概念,使控制器渐趋于标准化。在此之前,汽车行业内的主流发展方向是域控制器,及动力、底盘、驾驶辅助、娱乐、车身这五大域各有一个大脑,起到中枢运算的作用,称之为域控制器,该域内所有的运算逻辑均由域控制器完成,其下面通过CAN或LIN总线连接各种传感器和执行器,换句话说,域控制器下所有的子控制器只负责信号采集或负载驱动,不再具有运算功能,因此可以把子控制器标准化,只要接口定义好,子控制器可以做成标准件,这样后续的车型开发只演变域控制器,因此可大大降低新车型开发的成本。
而model 3的设计思路与此并不相同,其采用了大集成的概念,即把一个区域范围内可见到的控制器都集成在一起,也就是主控制器把小控制器统统吃掉,融合成一个超大控制器。这样做的好处也很明显,就是大大降低了单车成本。传统车中虽然子控制器被标准化了,子控制器确实也在新车型上省掉了开发成本,但单车的成本并没有被压缩;而特斯拉的思路是把子控制器融合掉了,因此可以把子控制器在MCU、SBC、Housing等方面的单车成本节约下来。所以传统车思路省下来的是新车型的开发费用,而Model 3省下来的是单车成本,各有优劣势。
Model 3车身控制器方案的第五大特点是敢于打破常规。在传统汽车人的眼中,控制器一定是方形的,是规则形状的。很显然,特斯拉不这么想。按照传统车的设计思路,汽车设计时,每个控制器先设计好形状,然后由总布置工程师进行布置,可以说是哪塞得下就放在哪。
而Model 3的思路并不是这样的,从其控制器的形状及布置位置可以看出,特斯拉采用的是布置优先的策略,即控制器的工程师确定控制器所需要的面积和高度,由总布置工程师进行分配,因地制宜,只要面积够用,方便布置,不管其形状被分配成什么样子,因此可以看到Model 3很多控制器都是不规则形状的,这样做大大提升了整车集成度,虽然控制器的形状个性,但却与车辆结构整齐划一。
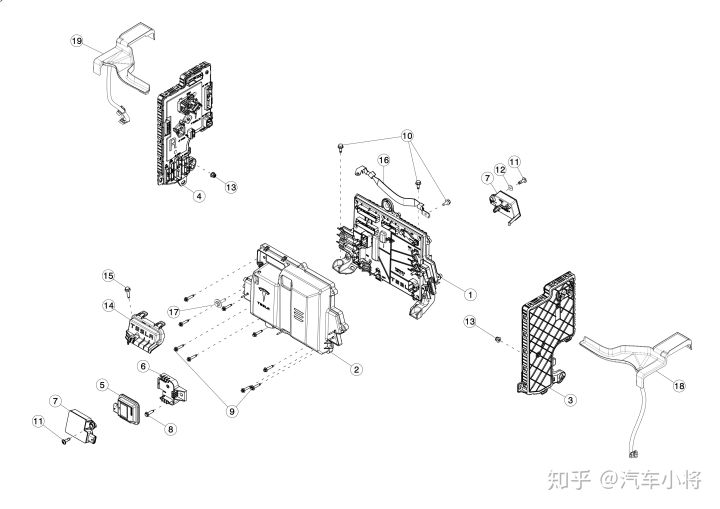
Model 3 车身控制器方案的第六大特点是控制器为线束让路,一切为了线束,为了一切线束,为了线束的一切。Model 3的车载线束总长度,从Model S的3km缩减了一半,变成了1.5km。我们可在控制器的原理图上看到有很多的Passthrough,让人非常困解,但如果你了解特斯拉线束的模块化,你变可以知晓,控制器的Passthrough是为了线束模块化服务的。
简而言之,就是不同区域的线束通过控制器不同的PIN针连接或耦合在一起,比如座椅线束中的某根线要和仪表台的某根线连接在一起,二者属于不同的线束模块,但却都和左车身控制器相连,因此左车身控制器就会做一对Passthrough,将这两个线束模块中需要连在一起的线束最终连在一起。
特斯拉电子电气架构变化总结:
从Model S的中规中矩、软件的纵向整合能力初露头角,到Model X的负重前行,再到Model 3的全面放飞;纵观特斯拉三代车型,Model S、Model X再到Model 3的演变,实质是功能的重分配,不断把功能从供应商手中拿回来自行开发的过程。从电池管理系统到热管理、从Center Display到Autopilot、从AP到驻车制动、从电源分配到扭矩控制...特斯拉深刻诠释了什么TMD叫“软件定义汽车”
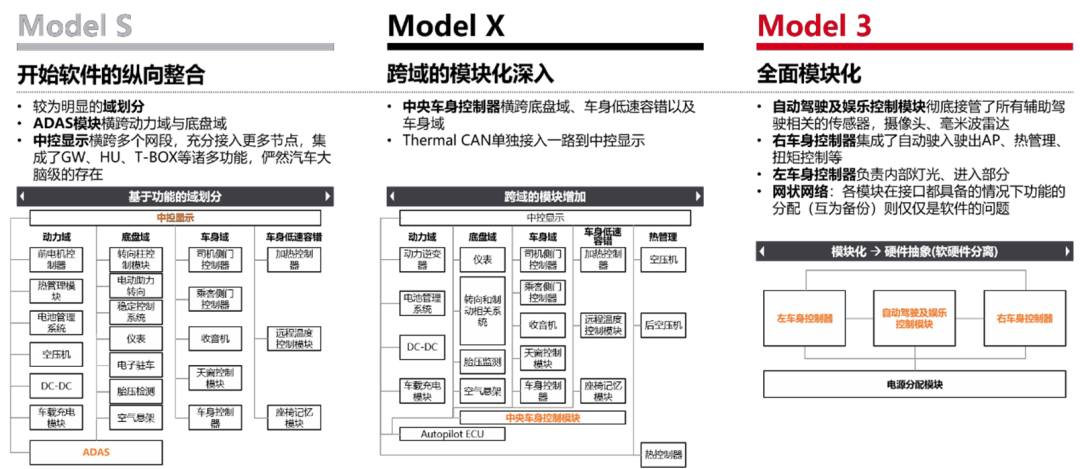
汽车电子电气E/E架构加速向域控制、中央计算平台架构迁移。博世认为汽车电子电气架构演变路径为分布式、域集中、中央集中式。传统汽车分布式架构缺点越来越明显,高档车使用100~200种不同ECU,汽车的 EEA中搭载了各种功能不同的 ECU 进行协同运作为驾驶员提供各种功能,打造中央集中式EEA架构的车载计算平台,面临“功能安全、实时性、带宽瓶颈、算力黑洞”等多种挑战。目前车厂逐步将一些ECU功能合并到一个ECU中,减少控制节点,控制器向“域”集成方向发展,目前车辆上主要有动力域、车身域、自动驾驶域、底盘域和信息娱乐域。
域控制器可以完成各自域内协调工作,便于软件管理和车辆变形。域集中和中央计算平台架构使原来分散的算力集中化,在降低架构复杂度同时提高了系统算力,软硬件解耦让汽车软件实现即插即用,具备可持续迭代升级的能力。在电子电气架构方面,目前特斯拉发展最为领先,其新一代集中式 E/E 架构达到车载中央电脑和区域控制器阶段,配合自研的操作系统,可实现整车 OTA。
5、智能座舱域控制器技术驱动因素
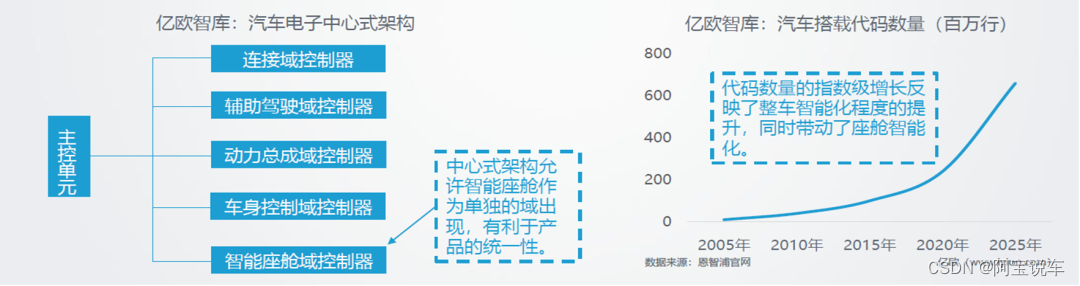
1、新能源汽车以及动力电池技术发展迅猛。
车身电子电气架构正在进行深度升级,由传统的分布式架构向中心式架构演变,不同操作系统之间通过虚拟机打通;同时三元锂离子电池能量密度已经突破300wh/kg,为智能座舱各功能提供能量基础。
在新能源车的发展过程中你会看到很多同传统车不一样的先进技术在这方面使用,由于新能源车本身的架构和传统燃油就有很大的不同,对比于燃油车,新能源汽车的结构更简单。目前的燃油车结构比新能源汽车更复杂,特别是动力总成系统部分,要比新能源汽车复杂得多。新能源汽车的车辆结构较为简单,主要部件为动力电池组、电机和EMS组成的三电系统,因此在新能源汽车上开发或者使用自动驾驶技术,那么出现概率的情况要比燃油车低得多。
与此同时,从操控上来说,新能源汽车也要比燃油车更好操控——控制电压电流的大小以及输出,远比控制传统内燃机来得容易得多。所以比如一些ADAS的设备、TBOX、以太网、还有一些域控制器都是在优先在新能源车上出现,然后逐步使用到燃油车上。
2、芯片的运算能力呈指数级提升,自动驾驶逐渐成熟。
目前一辆智能汽车搭载的代码行数超过一亿,自动驾驶软件的平均运算量达到10个TOPS(Tera Operations Per Second,万亿次操作每秒)量级,各大芯片厂商都推出了与算力匹配的主控芯片。同时,自动驾驶技术的成熟使得人们从驾驶场景解放出来,更多注意力得以放在其他场景上。
3、云计算和5G的铺设速度加快。
云平台的计算、存储能力和5G的传输速度为智能座舱大数据量、低延时的需求提供了保障。主流云计算厂商均针对车企推出了车联网解决方案;芯片厂商、通信运营商等各方则积极推行C-V2X相关技术,以期在未来向车用5G平滑演进。
6、智能座舱域控制器不是融合功能越多越好
智能座舱域控制器行业发展历程及里程碑事件
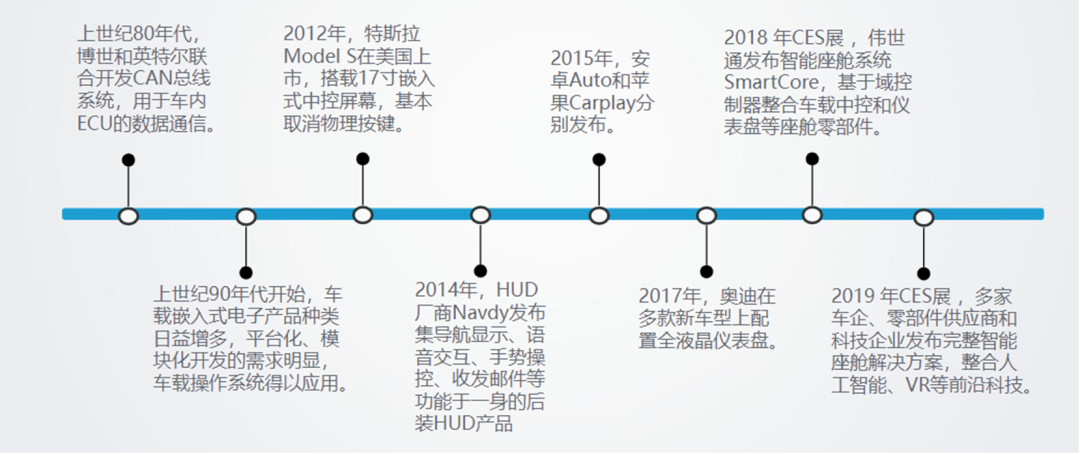
智能座舱发展经历了整体基础 智能座舱发展经历了整体基础 -细分产品 细分产品 -融合方案的格局变化。先是整体电子器架构和操作系统出现,随后各细分产品逐渐装载到车上,如今的趋势是各产品的协同整合。
可以看到2018年伟世通才出现基于座舱产品的域控制器,主要是整合了车载中控和仪表,还没有整合更多的ADAS功能的产品,比如360环视、LDWS等功能进去,说明这个域控制器有一定的难度。
域控制融合功能越多,功能安全越复杂

上图是中央控制器会遇到的问题,这个和域控制面临的问题是一样的,主要还是很多功能性安全,实时性安全的技术要求还不成熟。不是像我们想的这么简单,把能融合的就融合在一起,从功能安全的角度出发,反而并不一定好,我们以视频感知系统为例讲解。
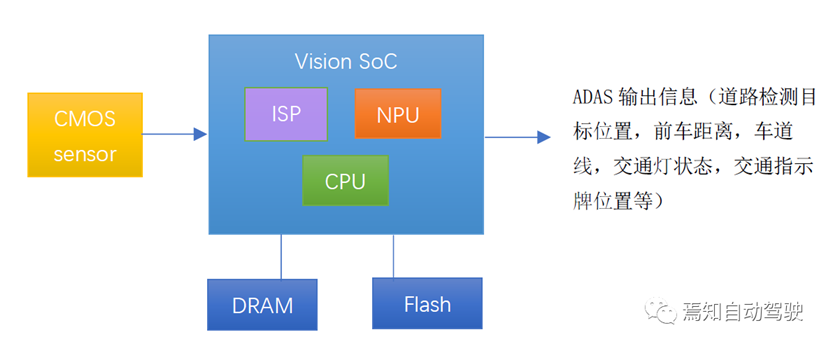
在以上的模块内,CMOS sensor提供图像采集,输出给视觉感知SoC。ISP模块负责图像处理包括色彩空间转换,Tone mapping, 降噪,图像缩放等,输出图像给NPU。NPU模块负责运行基于神经网络的ADAS(高级辅助驾驶)算法,输出结果到内存。CPU模块负责整个算法和流程的调度。
这个系统通常很难做到ASIL-B或者更高的功能安全等级,这是因为这些模块有着复杂的数据处理过程,并包含多种失效模式。CMOS sensor首先要保证选用ASIL-B或者以上级别的。视觉SoC的内部多个单元模块也要实现各种错误检测和汇报机制,以实现ASIL级别的需要。如果其CPU使用ARM A系列的处理器,除非进行锁步执行,很难达到ASIL-B功能安全等级。
至于视觉算法所使用的神经网络技术,因为其结构设计并不容易用逻辑推断来描述,其参数比如分类器是基于训练得到而不是确定性逻辑得出,无法用形式化方法分析其失效率(不能计算SPF, LF, PMHF),所以也无法得到ASIL级别。即使采用传统的机器视觉算法,手动设定分类器加上训练,也一样存在大量经验性而不可以保证其对未知场景有正确响应。
基于Mobileye EyeQ3和EyeQ4设计的ADAS处理器在行业已经广泛应用,但据悉,也并不能独立实现视觉感知功能的ASIL-B。
那么如何提升视觉感知系统的功能安全呢?行业里的较为普遍的做法,是使用ASIL-B级别以上的安全岛,或者独立的ASIL-B以上级别的Safety MCU,来实现系统级功能安全。
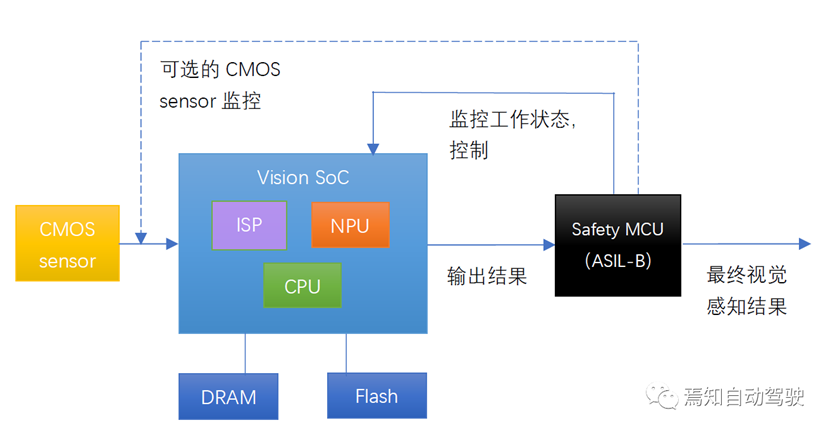
通过增加一个具有ASIL-B或更高安全等级的MCU,并且软件实现视觉感知SoC向Safety MCU输出结果,并且接收Safety MCU的监控和控制,这样这个系统就有可能实现“系统级功能安全”,最终视觉感知结果,具备功能安全ASIL-B或更高等级。这个系统也相当于:
系统级ASIL-B? = QM (Vision SoC)? +? ASIL-B (Safety MCU)
要证明这个ASIL分解成立,我们首先要看这两个子系统是否存在共因失效。如果Safety MCU的电源设计具备冗余,并且其和视觉SoC之间的I/O具有Failsafe保护,那么并不存在一种外部故障,可以让Safety MCU和Vision SoC同时失效。
其次因为Vision SoC的失效如果不被Safety MCU检查出来,则会被传导到最终输出,这种将会导致ASIL分解不成立。如果Vision SoC的失效是可以被Safety MCU检查出来的,那么Safety MCU可以在最终信息输出标识系统进入安全状态,并且可以控制包括重置Vision SoC子系统进行错误修复,这时Vision SoC的失效不会导致系统失效,ASIL分解成立。所以关键点在于Vision SoC的失效是否可以被检查出。
为了更好地检查Vision SoC的失效,我们可以采用ISO26262推荐的方法,包括但不限于:启动时自检,运行时的周期性自检,程序流监控,和视觉感知关键数据时间检测,硬件和软件出错汇报,监测CPU异常,操作系统异常,内存数据异常,I/O报错,中断异常,状态偏离(比如CPU越来越忙,空闲内存逐渐减少),CMOS传感器数据校验,周期任务执行超时,输出数据超时等。这些监测的目标是使得Vision SoC尽可能汇报可以检测到的各种错误,包括图像输入故障,卡滞和处理错误,如果因为异常而停止向Safety MCU输出,则会产生超时错误也一并被监测到。
经过上述的努力,我们有希望把视觉感知系统提到接近于ASIL-B的安全目标。但这样的系统通常也被认为不能达到ASIL-B,其主要原因是其采用的视觉感知算法目前尚不能被ISO26262认可。也有观点认为单独使用ASIL-B Safety MCU不能做到充分的冗余,但通过增加一条数据通路,使得Safety MCU也可以监控CMOS sensor的输出状态和信息,可以实现更为充分的冗余而达到系统级ASIL-B。这种设计在Veoneer的Traffic Jam Pilot系统里已经实现量产 (视觉SoC QM级别 + Safety MCU ASIL-B级别)。
那么,如果要达到更为严格意义上的ASIL-B,是否可以做到呢?市场现行的解决方案是增加可替代视觉感知的冗余,特别是增加毫米波雷达感知系统。增加了雷达以后,以上的系统框图变为:
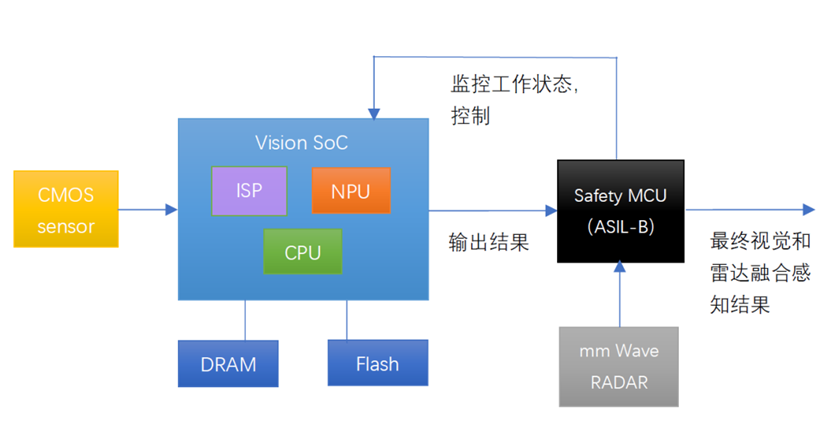
这个系统需要摄像头的覆盖角度的关键部分如当前车道,和毫米波雷达的覆盖角度相重叠,这样来自两个不同传感器的异构冗余可以改善系统的功能安全。毫米波雷达系统可以做到符合ASIL-B,随后在ASIL-B或更高级别的Safety MCU进行视觉+雷达做数据融合,并根据融合数据做出算法判断,最终的输出结果可达到ASIL-B或更高级别。
选择安全MCU扩展还是单芯片
这里我们可能面临一个问题,如果有一颗SoC能够把Vision SoC和Safety MCU合并进去,是不是等价方案?既可以实现高性能的算法,同时又可以做到功能安全需求。
这样系统的框图类似下面。Performance core是性能核,也就是原来Vision SoC的部分,Safety Core就是原来的Safety MCU的部分。现在放到一起以后,两部分可以通过共享内存和相互发送中断进行通信。
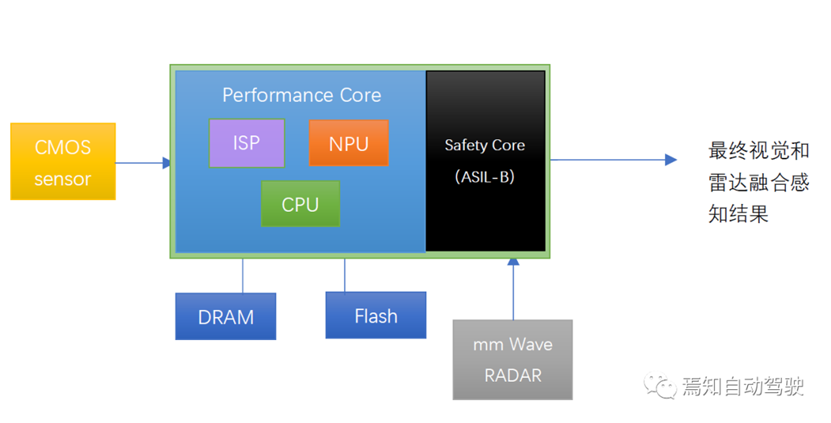
上面这种SoC集成了安全岛的设计,在车用智能驾驶SoC里越来越流行,但我们并不能得出这种集成设计一定好于前面的分离设计,其原因在于:
集成设计的两个部分在一个芯片内部,根据不同芯片设计的差异,可能存在相互影响和资源依赖,而产生共因失效,比如电源和重置部分是否可以做到完全独立。
性能可能相互影响而造成风险,如果Performance Core过于繁忙,占用内存带宽过多,可能影响Safety Core上运行融合算法的时间确定性。反过来也是一样。如果Safety Core也运行安全性要求非常高的任务比如AEB控制,则时间确定性变得更为重要。
Safety Core部分的CPU运算性能,功能安全等级不一定好于分离式里的单独的Safety MCU。同样,Performance Core部分的视觉感知性能,也不一定好于分离式里单独的Vision SoC。
所以在实际系统设计的时候,需要根据需求进行分析,并不能得出分离式系统的功能安全不如集成式系统这一结论。
下图是能够支持L3级别自动驾驶的奥迪A8的智能驾驶域控制器的设计:

其中包含四个主要芯片:NVIDIA Tegra K1, ?Mobileye EyeQ3, Altera Cyclone FPGA, Infineon Aurix Tricore MCU。其中TK1和EyeQ3负责自动驾驶中的视觉感知,包括交通标识牌识别,行人检测,碰撞预警,光线检测,车道线检测,360度环视等功能。Altera FPGA负责目标融合,地图融合,停车辅助,碰撞预防,图像前处理等功能。
而Infineon Aurix负责交通拥堵导航,辅助系统,矩阵大灯,路线图等功能,并且负责系统的安全监控和底盘控制。也就是说,这个四个芯片的复杂系统是TK1和EyeQ3两颗QM芯片加上一颗ASIL-B等级的Altera FPGA,再加上一颗ASIL-D等级的Infineon Aurix Tricore来共同实现。
这个例子很好的说明了如果设计合理的话,分离式功能安全设计是可行的,同时也说明了单颗甚至两颗芯片实现这样复杂的系统功能是非常困难的。再反过来看看前面提到的特斯拉FSD的完全双重冗余,也许特斯拉的设计更清晰明朗,虽然其并不是典型的ISO26262设计理念。
7、智能座舱产品形态发展及重要性?
显示屏和主机分离是成为一个趋势
大家都知道汽车开发一个车型涉及大量的技术集成、零部件设计、试验验证等,所以汽车开发具有耗资大、周期长,开发风险高等特点。以往的汽车厂家推出一款新车至少需要5-10年,周期很长、工作量很大。但此一时彼一时,如今的车企,车型更迭的速度非常快,这个都是得益于底盘平台化。
如宝马的UKL前驱平台、CLAR后驱平台,丰田的TNGA架构、吉利的CMA平台,奔驰的MFA、MRA、MHA、MSA平台等,以丰田的TNGA平台架构为例,初期使零部件通用比例达到20%-30%,最终将达到70%-80%,这对于企业节约成本,降低研发周期起到关键作用。
而现在一个平台车型的迭代周期是3-4年,车型小改款是1年左右,越来越多的车厂选择把显示屏部分进行标准化,这样IP造型、显示屏的成本都能固定下来,而每次升级改款只需要修改主机,因为现在域控制或者单芯片的算力越来越强,主机升级换代的需求是必然,显示屏是显示内容部分,这部分相对简单一些,只要规划好对应的造型、尺寸、分辨率是可以做到平台化共用的,节省成本。
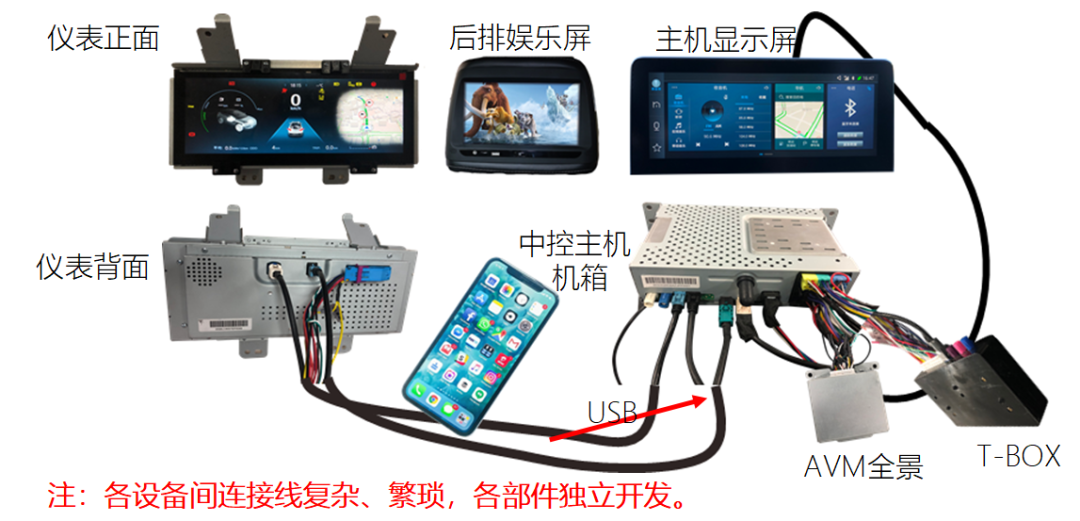
原来的座舱里面的控制器基本上是分开的,导航主机是一家,液晶仪表是一家,同时还有一个AVM全景一家,还有TBOX等,这里线束连接就非常复杂,而且不同供应商直接的协调调试也非常复杂。

上图是域控制产品形态,这样无论是走线,还是调试都非常方便,最关键就是OTA非常好做,而且降低成本。
以智能座舱为切入点提升用户体验成为企业制胜的关键点:

一方面,“一芯多屏”成为趋势热点。车载显示屏从单一、小型的平面矩形屏幕逐步向多个、大型曲面屏转变。因为传统分离式的座舱集成,多个座舱系统之间如“孤岛”一般相互独立导致通信成本高,而“一芯多屏”的智能座舱解决方案以通信成本低、时延短, 可以更好地支持多屏联动、多屏驾驶等复杂电子座舱功能;
另一方面,汽车企业在追求炫酷科技带来的震撼感、科幻感的同时,开始围绕改善用户体验密集发力,更加强调用户的便捷度、舒适感、娱乐性,从消费者观感体验以及心理体验出发进行产品开发和服务设计,更加增 进用户黏性。
未来,随着无人驾驶技术的成熟以及出行方式的革命性变革,消费者对汽车的认知将逐渐从“单一的交通工具”向“移动空 间”转变,而座舱则是实现空间塑造的核心载体。如何根据用户的个性化需求,为乘客提供专属出行方案成为产业应用落地的主攻方向。
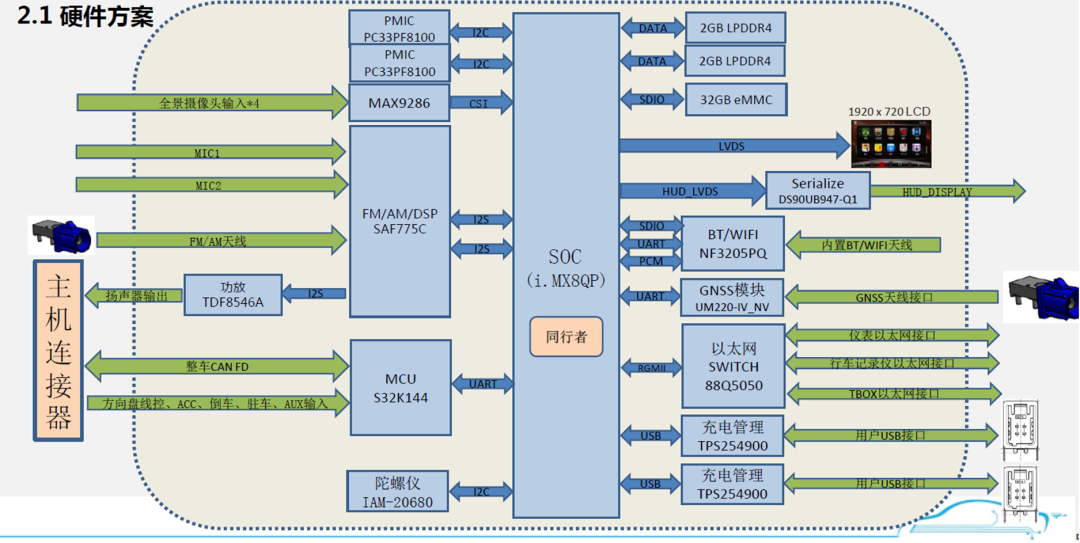
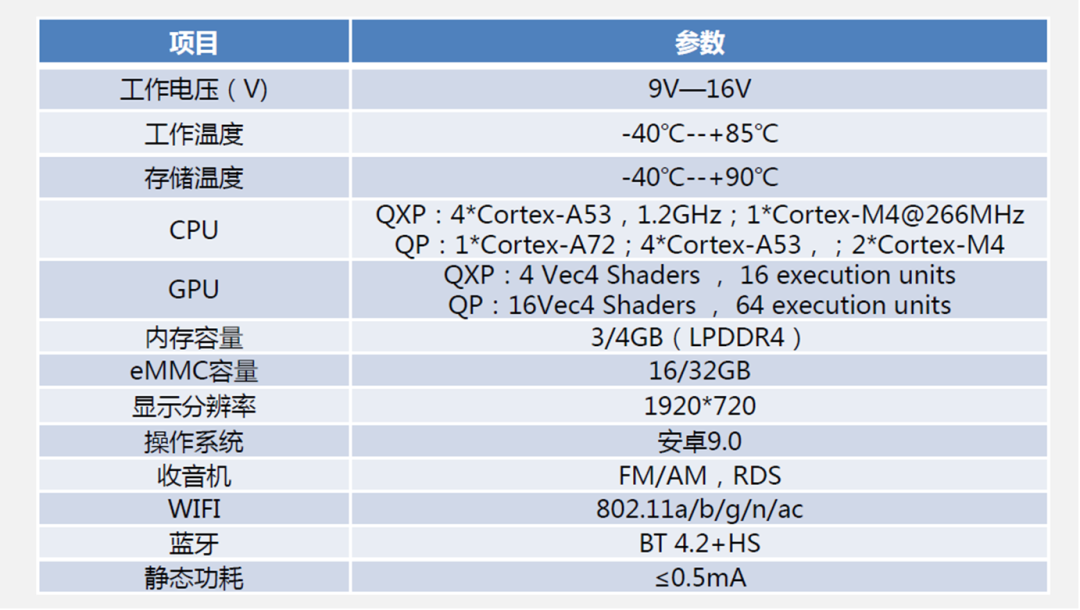
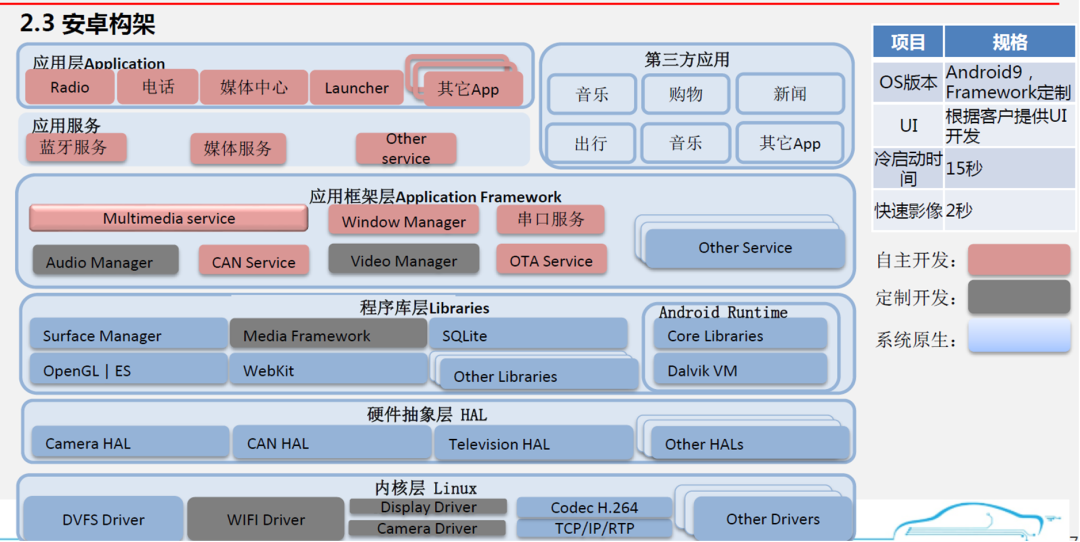
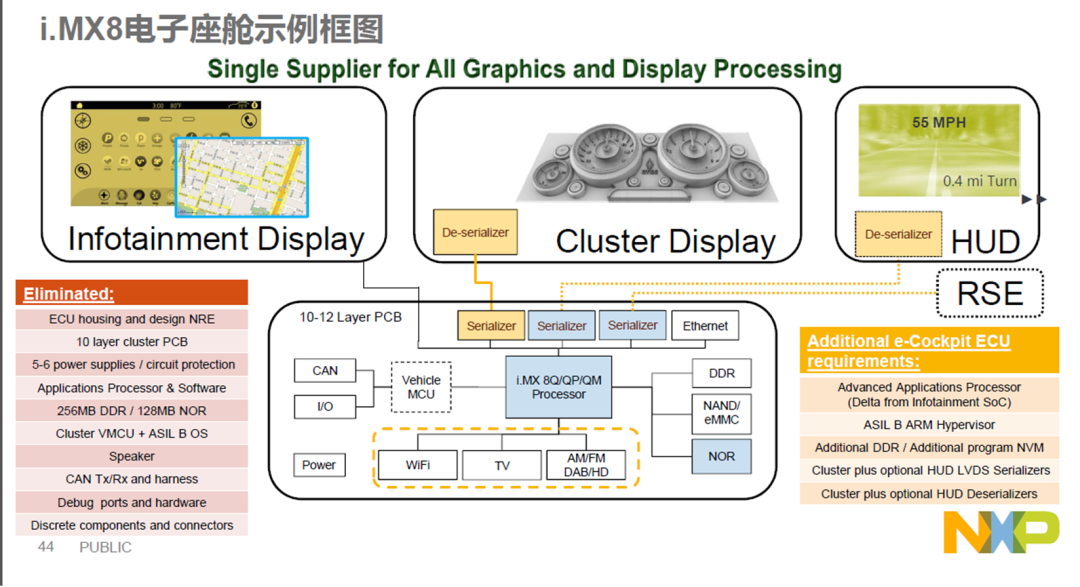
本章内容主要是讲解智能座舱域控制芯片的相关重要指标,在讲解芯片指标之前,我们看看域控制芯片有哪些
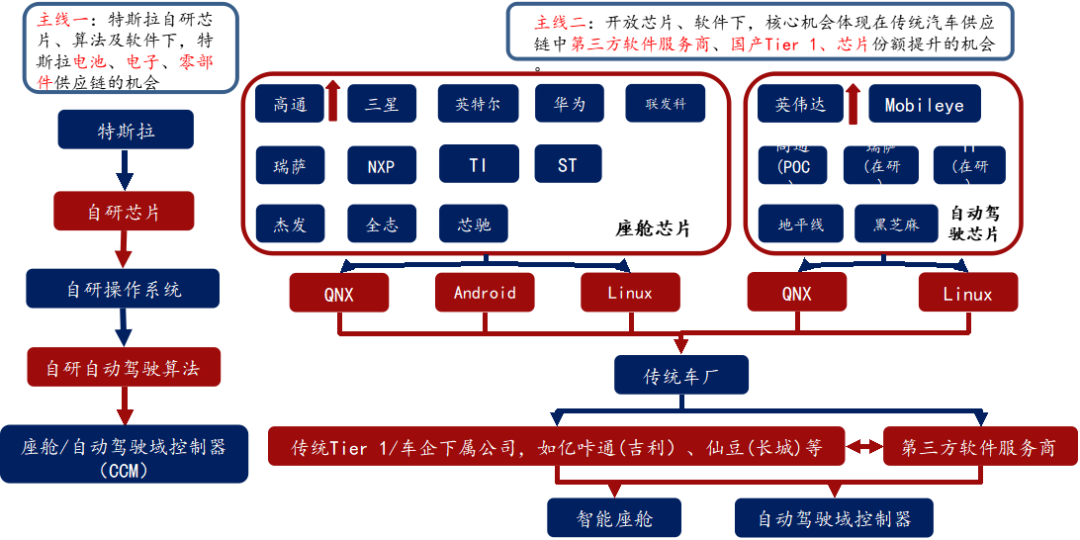
半导体、能源革命驱动的此轮汽车智能化、电动化浪潮,半导体格局反应产业链格局
座舱芯片:高通算力高、集成度高、性价比高,份额提升明显。
自动驾驶芯片
封闭生态战胜开放生态
L3+:英伟达>高通>华为
L3以下:Mobileye市占率最高,但黑盒子交付模式越来越不受车厂喜欢,未来开放模式将更受大家欢迎;地平线、黑芝麻等国产厂商有机会
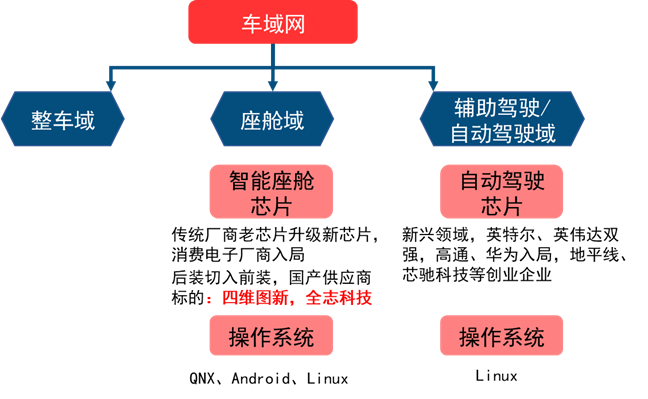
智能汽车芯片目前主要变化出现在座舱域、辅助驾驶/自动驾驶两大域控制器上。
智能座舱芯片是由中控屏芯片升级而来,目前主要参与者包括传统汽车芯片供应商以及新入局的消费电子厂商,国产厂商正从后装切入前装,包括:四维图新(杰发科技)和全志科技。
自动驾驶域控制器为电子电气架构变化下新产生的一块计算平台,目前占主导的是英特尔Mobileye和英伟达,高通、华为重点布局领域,同时也有地平线、芯驰科技等创业企业参与。
8、CPU芯片性能相关基本概念
计算机体系
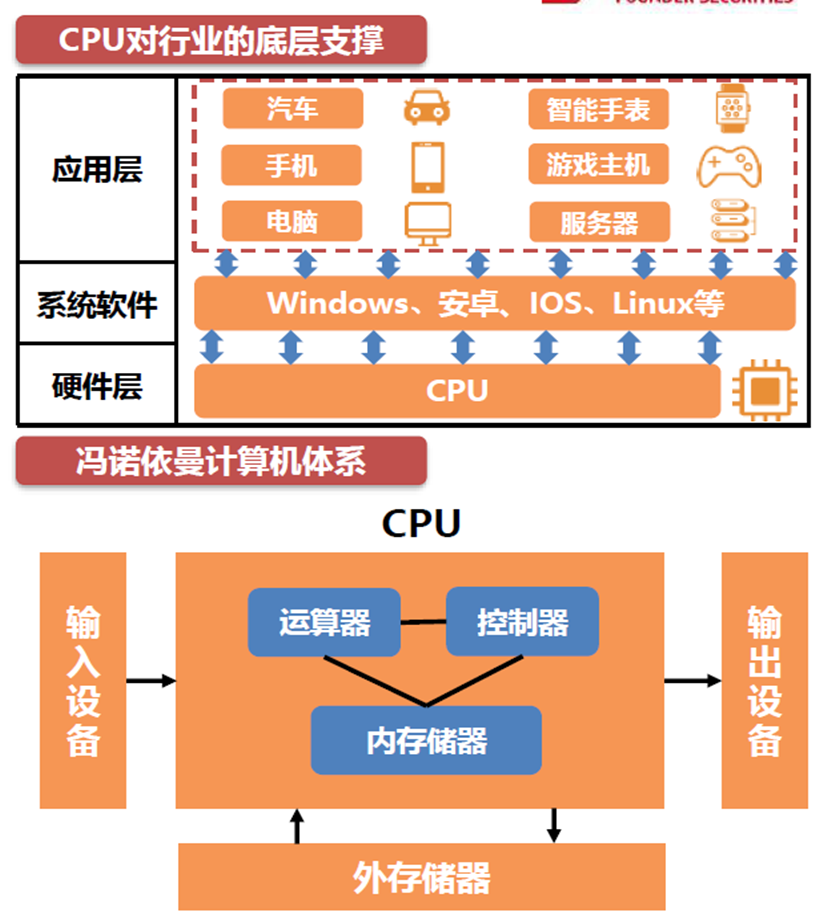
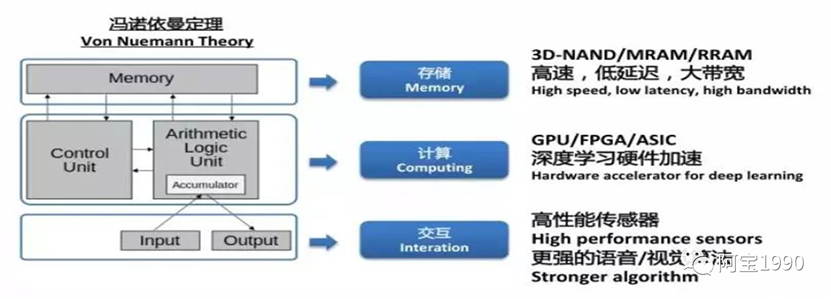
冯诺依曼于1945年发表了《FirstDraft of a Report on the EDVAC》(EDVAC初稿),在这篇报告中,冯诺依曼提出了“冯诺依曼体系结构”,明确指出了计算机必须具备的5大部件:运算器、控制器、存储器、输入设备、输出设备。
CPU作为控制器、运算器、存储器的结合体,提供通用算力,能处理不同的数据类型,成为了计算机的刚需。
CPU作为硬件层,支撑着Windows、IOS、安卓等系统软件层的启动,进而推进汽车电子、服务器、PC等应用层的发展,所以CPU的价值不可取代。
?各个应用领域的CPU标准是不同的。例如,在一些高可靠性应用场景,如汽车电子的CPU需要满足AEC-Q100车规认证;服务器的CPU特别看重多核表现和并行处理的能力;个人电脑的CPU注重单核表现,同时需要平衡体积、性能、效能表现;移动设备和智能穿戴的CPU把便携和节能放在第一位。
CPU内部组成和工作原理:
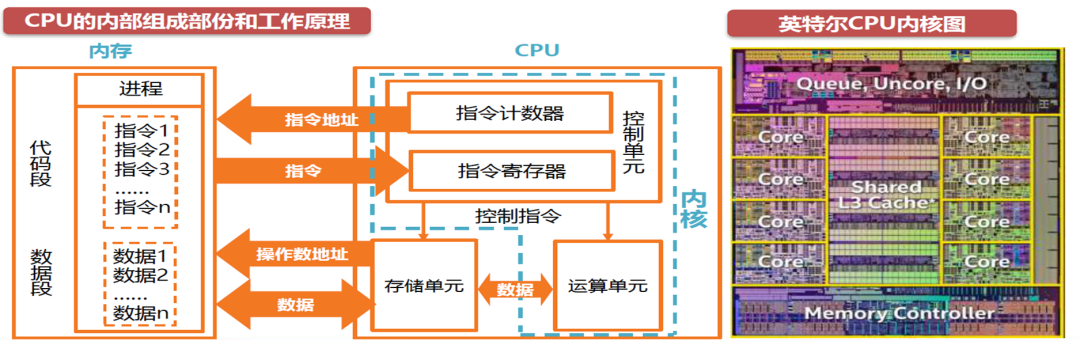
中央处理器(Central Processing Unit)作为计算机系统的运算和控制核心,是信息处理、程序运行的最终执行单元。CPU核心主要是由大量的运算器、控制器、寄存器组成。
运算器负责算术运算和逻辑运算。控制器负责应对所有的信息情况,调度运算器把计算做好。寄存器既要承接控制器的命令,传达命令给运算器;还要帮运算器记录已处理或者将要处理的数据。
几乎所有的CPU的运作可以简要概括为“取”,“解码”和“执行”三大步骤,此三个步骤统称为指令周期。通常,CPU核心从存储单元或内存中提取指令。然后,根据指令集由指令解码器执行解码,将指令转换为控制CPU其他部份的信号。最后通过运算器中的微架构进行运算得到结果。CPU内核的基础就是指令集和微架构。
1、CPU芯片性能相关基本概念--指令集
CPU指令集(Instruction Set)是CPU中计算和控制计算机系统所有指令的集合。
指令集包含了基本数据类型,指令集,寄存器,寻址模式,存储体系,中断,异常处理以及外部I/O,一系列的opcode即操作码(机器语言),以及由特定处理器执行的基本命令。
指令集一般被整合在操作系统内核最底层的硬件抽象层中。指令集属于计算机中硬件与软件的接它向操作系统定义了CPU的基本功能。
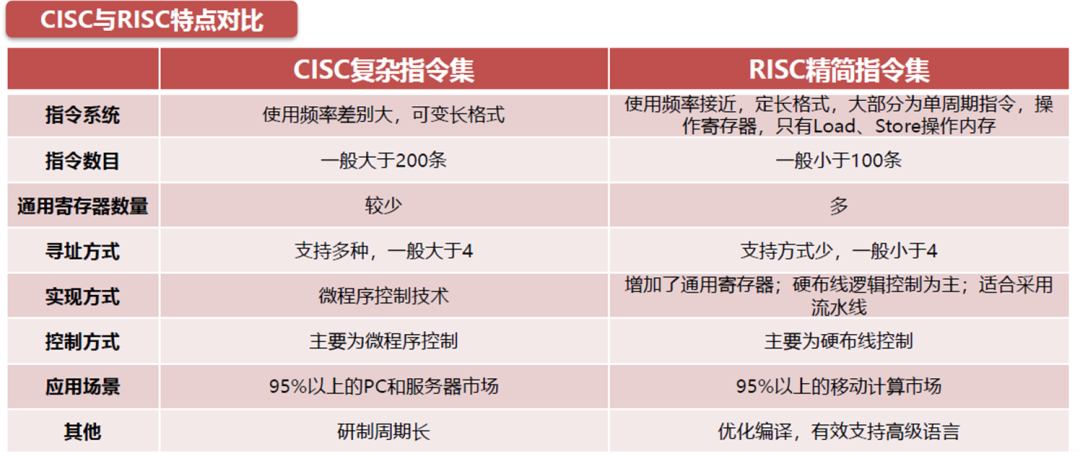
现阶段的指令集可以被划分为复杂指令集(CISC)与精简指令集(RISC)两类。

CCISC与RISC无论哪一方都没有绝对的优势或劣势。
从硬件角度分析:CISC采用的是不等长指令集,因此在执行单条指令时需要较多的处理工作,但是它的优势往往在于部份特定专业领域的应用。而RISC执行的是等长精简指令集,CPU在执行指令的时候速度较快且性能稳定,因此RISC适合采用流水线方式运作,且在并行处理方面明显优于CISC。
从性能角度分析:CISC阵营的Intel和AMD在提升芯片性能上做出了持续的努力,CISC芯片的功耗被放在了性能后的第二位;而RISC-ARM本身出现时间较CISC-X86晚十年左右(ARM诞生于1985年,X86诞生于1978年),ARM、MIPS在创始初期缺乏与Intel产品对抗的实力,专注于以低功耗为前提的高性能芯片。
CCISC与RISC从上世纪后期已经在逐步走向融合,并且该趋势持续至今。例如2005年苹果通过引入Rosetta将原先IBM的Power PC指令集转译为英特尔处理器接受的X86指令集。2020年苹果发布基于ARM指令集的M1处理器后,将Rosetta更新为Rosetta2以便将原英特尔的X86指令集快速转译为M1的ARM指令集。
整体来看,以高通骁龙,联发科,三星Exynos,苹果A系列为代表的ARM架构RISC处理器占据了移动处理器的市场。而在个人电脑领域以Wintel联盟为基础的X86架构CISC处理器占据了该市场。MIPS,Power,Alpha等架构虽然已经不是市场的主流,但在特定领域内仍然在被使用。

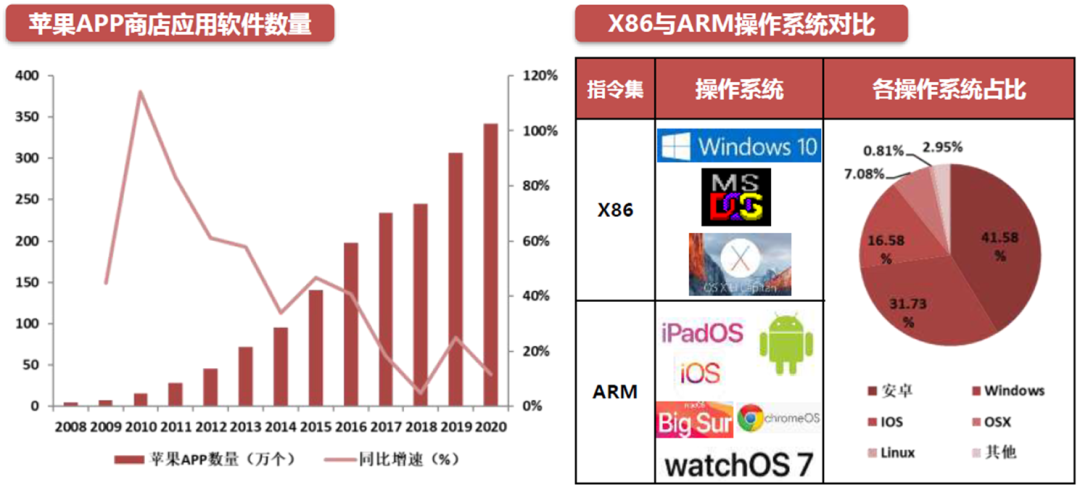
软件生态方面,X86运行的主要为DOS,非ARM版Windows,旧版MacOS等操作系统,起步早,基于Wintel联盟,生态完善。全世界有65%以上的软件开发商都为X86提供生态服务。
ARM方面运行的主要有安卓,iOS,iPadOS,Windows10移动版,MacOS Big Sur等。原先适应X86指令集的软件需要经过翻译后才可运行,如苹果的Rosetta2可以将X86指令转换为ARM指令,所以运行速度会减慢。
ARM成本低,迭代快,其软件生态正在加速追赶X86的软件生态。苹果应用商店软件数量从2008年7月的5万个发展到2020年的342万个。同年Google Play商店有270万款可供下载的软件。
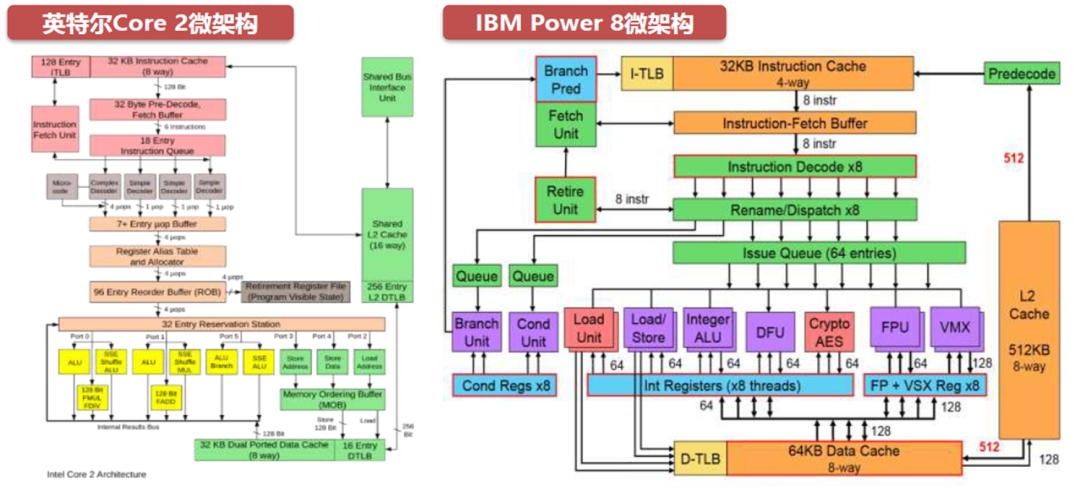
2、CPU芯片性能相关基本概念--CPU微架构
微架构是(Micro Architecture)一种给定的指令集架构在处理器中执行的方法。相同的指令集可以在不同的微架构中执行,但实施的目的和效果可能不同。优秀的微架构对CPU性能和效能提升发挥着至关重要的作用。计算机体系是微架构和指令集的结合。
众多的算数单元、逻辑单元和寄存器文件在三态总线和单向总线,以及各个控制线的连接下组成了CPU的微架构。计算机的总线组织由CPU的复杂程度决定,二者常同向变化。
CPU微架构中常见的单元有执行端口、缓冲单元、整数运算单元、矢量运算单元等。
存储相关的介绍:
CPU内部单元有存储单元,外面又有EMMC和DDR,为什么需要这么多存储呢,这里简单介绍一下。
1)内存又称主存,是 CPU 能直接寻址的存储空间,由半导体器件制成
2)内存的特点是存取速率快
内存的作用
1)暂时存放 cpu 的运算数据
2)硬盘等外部存储器交换的数据
3)保障 cpu 计算的稳定性和高性能
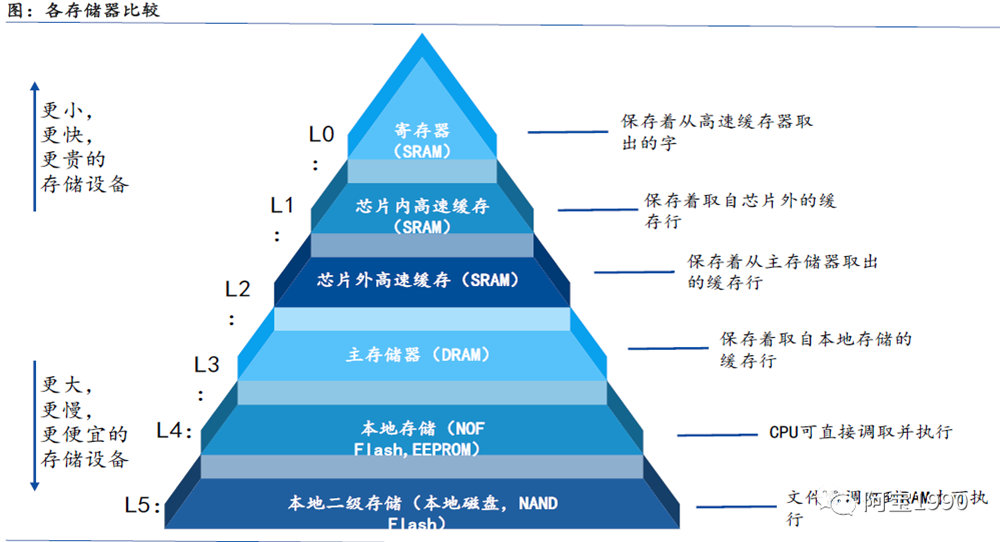
上图非常清楚的看到不用的存储的大小不同,而且速度不同,越上面的存储器容量越小,比如L1和L2 cache这部分容量非常小,但是速度非常快,而且价格比较贵。

往下面的DDR、NOR、NAND、硬盘等等,你会发现容量越来越大,但是通讯速率会更慢,你从一个硬盘里面拷贝资料一般达到50MB/S就谢天谢地了,但是DDR可以达到2133MHZ的速率。同等容量下,越往下面的存储设备的价格也就越便宜。
芯片内部高速缓存介绍:
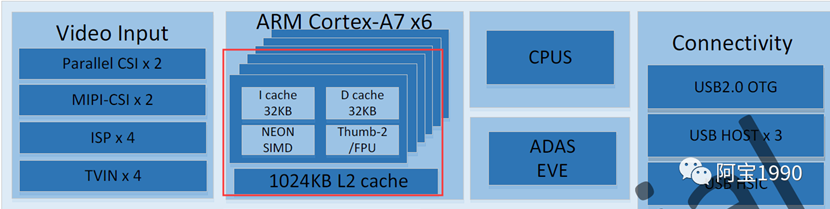
上图是全志T7的芯片内部手册图,可以从很多芯片手册上面看到有I cache和D cache 和L2 cache。这个就是上图中的L1和L2 cache 芯片内部高速缓存。
Cache,是存储器子系统的组成部分,存放着程序经常使用的指令和数据,这就是Cache的传统定义。从广义的角度上看,Cache是快设备为了缓解访问慢设备延时的预留的Buffer,从而可以在掩盖访问延时的同时,尽可能地提高数据传输率。
高速缓冲存储器Cache是位于CPU与内存之间的临时存储器,它的容量比内存小但交换速度快。在Cache中的数据是内存中的一小部分,但这一小部分是短时间内CPU即将访问的,当CPU调用大量数据时,就可避开内存直接从Cache中调用,从而加快读取速度。
由此可见,在CPU中加入Cache是一种高效的解决方案,这样整个内存储器(Cache+内存)就变成了既有Cache的高速度,又有内存的大容量的存储系统了。Cache对CPU的性能影响很大,主要是因为CPU的数据交换顺序和CPU与Cache间的带宽引起的。
3、CPU芯片性能相关基本概念--CPU微架构工作流程
CPU的每个核心有独占的L1指令缓存、L1数据缓存和L2缓存,多数核心共享L3缓存。所有缓存中L1缓存通过虚拟地址空间寻址,L2/L3通过线性地址空间寻址。
CPU非核心部分主要是System Agent(系统代理):包含PCU(电源控制单元)、DMI控制器与ICH连接、QPI控制器与其他CPU连接、内存控制器。
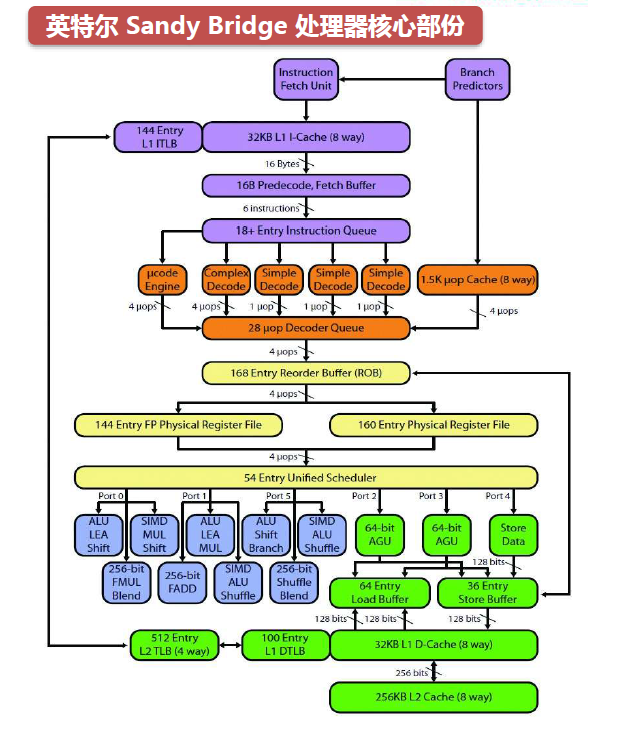
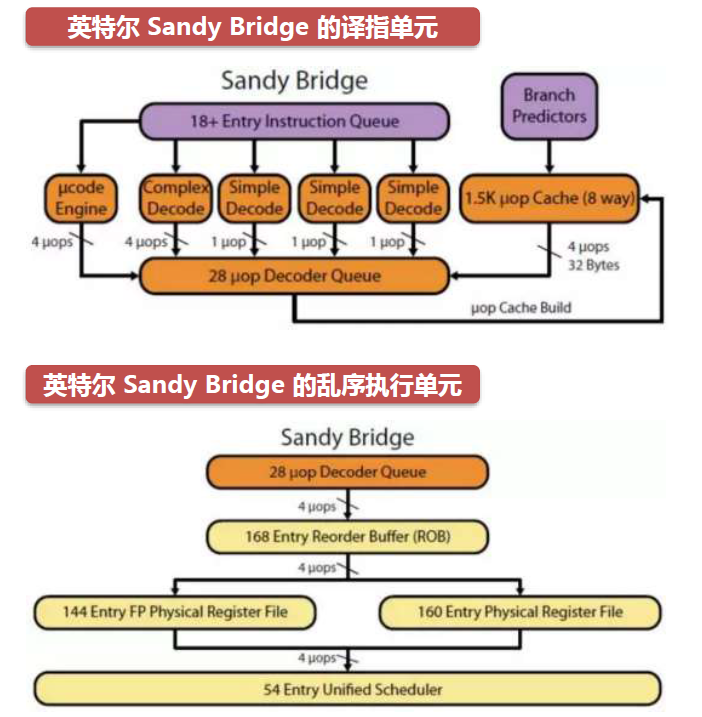
微架构工作流程概述:以英特尔的Sandy?Bridge(下图)为例,CPU先使用取指令单元(下图紫色部份),将代码段从内存中取出;通过解码单元(下图橘色部份),将机器码按序转化为定长的uop(微操作),发射到uop Decoder Queue(微操作解密等候区);乱序单元(下图黄色部份)从微操作解密等候区中取出微操作,根据执行条件,依赖关系,重新排序后,发送到Scheduler(调度器);调度器将计算指令发送到计算单元(下图蓝色部份),得到计算结果;将内存读写指令发送给访存单元(下图绿色部份),完成内存读写。
编译和取指过程
微架构通过执行指令“exec()“,执行某个二进制数时, 该二进制数首先被kernel(核心)从硬盘加载到内存。
n Instruction Fetch Unit (执行获取单元)会按照执行顺序将bin的代码段,从内存中读入到CPU。当遇到分支代码时, 需要查询BranchPredictors(分支预测)。执行获取单元增加访问电路,可以并发地访问内存、寄存器,解决流水线气泡问题。
在Precoded(预解码)中解码的X86指令集,会被保存到Instruction Queue(指令等候区),等待解码。
现在的CPU均使用超标量的结构。例如Sandy Bridge是16条。每个CPU cycle有16个操作在并行执行,需要一系列设计来保证流水线不被中断。
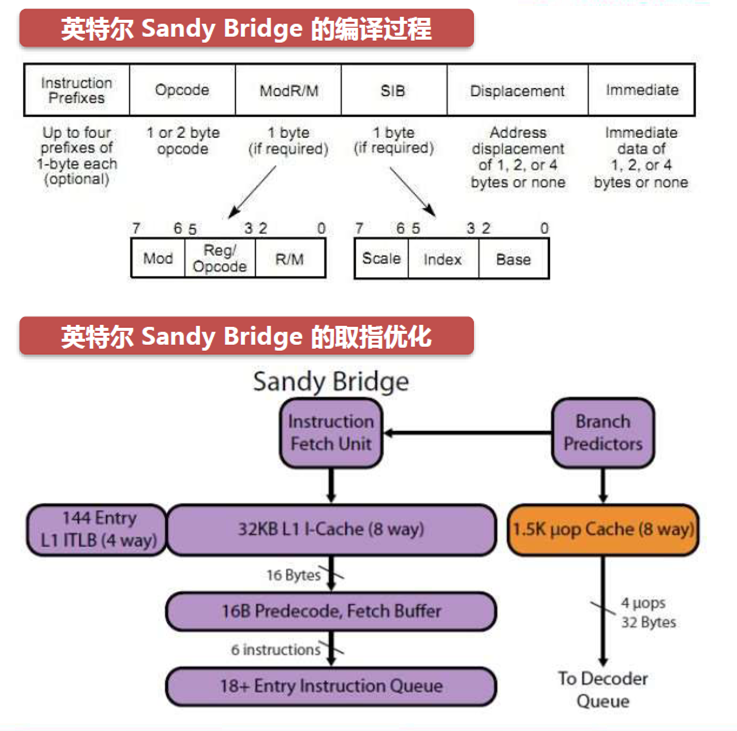
译指和乱序执行单元
Instruction Queue(执行等候区)中取指单元获得的x86 CISC指令,会通过译指单元翻译,以提高CPU流水的整体能力。
一个周期有4条指令进入译指单元不同的模块,Complex Decode(复杂解码器)翻译单指令多数据流指令,一个周期最大可以产生4个uops(微操作),Simple Decode(简单解码器)翻译普通指令,一个周期产生1个微操作,得到的微操作会保存到uopDecoder Queue(微操作解码等候区)中。
微架构的乱序执行会选择当前可执行的指令优先执行,减少处理器闲置。
译指单元每个周期发送4个微操作到乱序执行单元。乱序执行单元使用Register Alias Table(虚拟寄存器到物理寄存器的映射表)修改微指令,把修改后的指令部分保存。
Scheduler(调度器)会将整数操作数和浮点操作数分别保存,把映射表存入Reorder Buffer(重新编序缓存)。最后统一调度器选择有执行条件的微操作发送给执行单元,没有执行能力的微操作先缓存,待条件具备后发送。
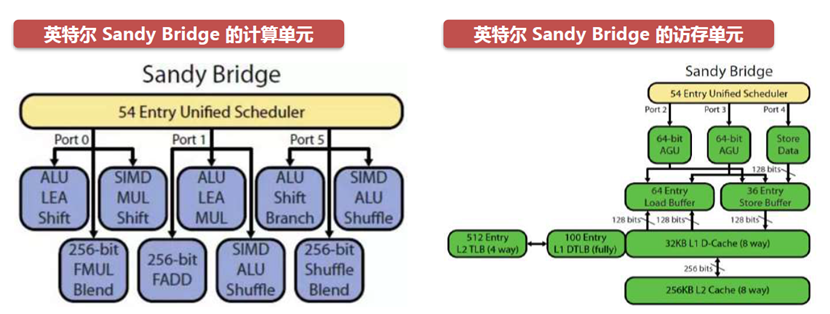
计算单元和存储单元
乱序执行单元每个周期发送4个微操作到计算单元。port0、port5可以执行整数、浮点数、整数SIMD(单指令多数据流)所有指令,port1只能执行整数、整数SIMD乘法、移位指令,每个周期最多执行3条指令。port2,port3,port4每个周期可以执行2个load(读取),1个store(存储)指令。
?Sandy Bridge在运算单元上,通过AVX指令,大幅提升了浮点数以及SIMD的效率。
Address Generation Unit(地址产生单元)产生读写内存的虚拟地址;Load Store Unit(存取单元)通过地址,实现读取、存储。
存取单元包含Load buffer(读取缓冲)、Store buffer(存储缓冲)、prefetch(预读逻辑)、一致性的逻辑。存取单元读内存时,先要查询缓冲中的是否有缓存,如果命中,直接返回。当不命中时,需要发起对内存的读取,由于读取内存大概需要200周期,代价很高,存取单元实现了预读逻辑。
4、CPU的发展历程
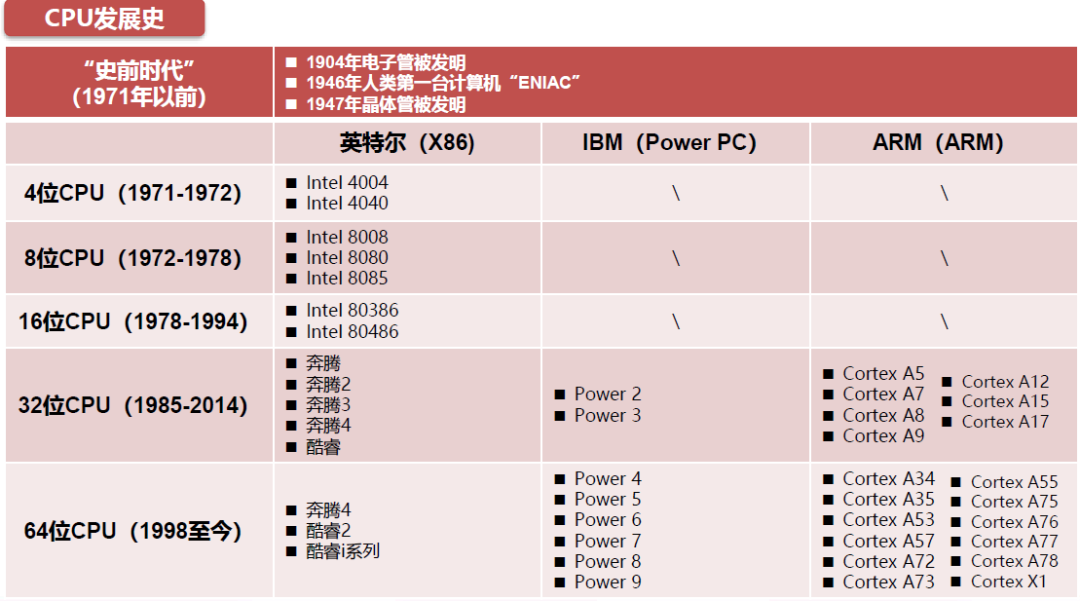
CPU发展史简单来说就是Intel、IBM、ARM的发展历史,CPU已经有四十多年的发展历史。
CPU的发展史,按照其处理信息的字长,可以分为:四位微处理器、八位微处理器、十六位微处理器、三十二位微处理器以及六十四位微处理器等等。英特尔在大部分时间处于领先地位。
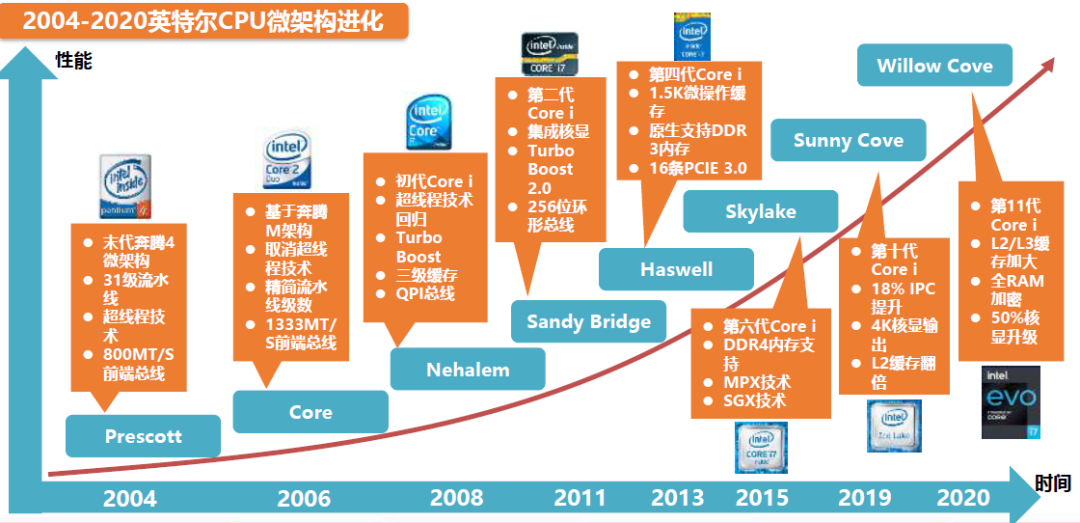
随着2005年以Prescott为内核的奔腾4处理器在性能和效能上被AMD的K8速龙超越,英特尔采取了“Tick-Tock”的钟摆模式,“Tick”年升级处理器的制程,“Tock”年升级处理器的微架构。以两年为周期的钟摆模式,从“Nehalem”开始让CPU交替发展,一方面避免了同时革新可能带来的失败风险,同时持续的发展也可以降低研发的周期,并可以对市场造成持续的刺激,并最终提升产品的竞争力。
?2008-2015年的钟摆模式使英特尔CPU年均有15%左右的提升,维护了英特尔X86领域的霸主地位,并诞生了诸如Skylake这样经典的架构,沿用至今。
9、智能座舱域控制器芯片选择维度
1、内核角度
CPU核心是指控制和信息处理功能的核心电路,把一个CPU核心和相关辅助电路封装在一个芯片中,即为传统的单核心CPU芯片,简称单核CPU。把多个CPU核心和相关辅助电路封装在一个芯片中,为多核心CPU芯片,简称多核CPU。
下图即为ARM的单核心CPU和多核心CPU。图中红色虚线框标出的部分为CPU核心,分别为基于ARMv7微架构的单核心CPU芯片以及ARM Cortex-A9 MPCore用2个和4个Cortex-A9构成的2核心和4核心CPU芯片。
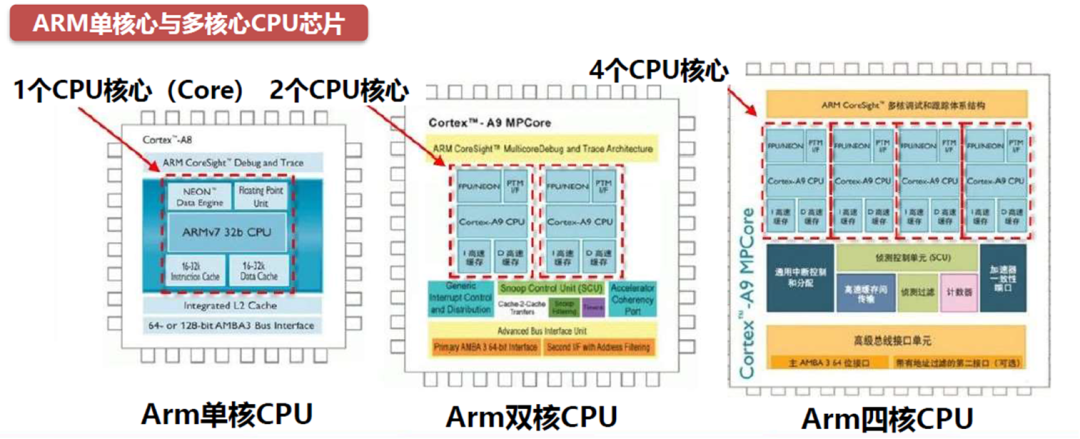
目前我们能见到的4核心CPU大多都是属于Cortex-A9系列。ARM Cortex-A9的应用案例有联发科MT6577、三星Exynos 4210、华为K3V2等,另外高通APQ8064、MSM8960、苹果A6、A6X等都可以看作是在A9架构基础上的改良版本。
从ARM 内核的发展架构来看,从单SOC多核变化到单SOC多核异构
ARM-V7?单SOC多核

ARM-V8?单SOC多核异构(大小核)
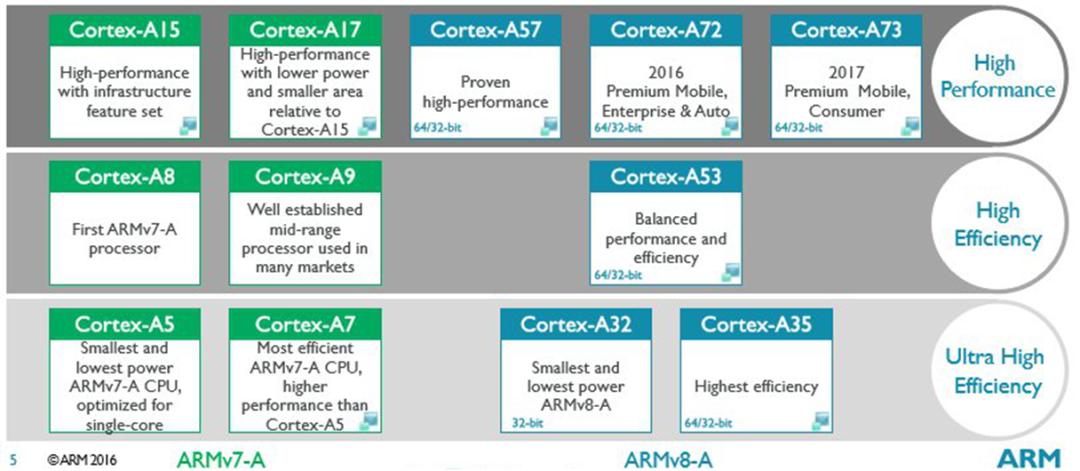
一体化程度更高
单SOC多系统共存技术趋于成熟
智能驾驶舱的集成了DIC、HUD、IVI和RSE等等多屏融合
为汽车带来更为智能化和安全性的交互体验,同时也是高级辅助驾驶 (ADAS)、自动驾驶和人工智能等新时代技术的关键接口,智能驾驶舱在新能源汽车中将成为标配。
2、市场成熟度角度
智能座舱域控制器的CPU芯片市场组成:传统汽车芯片厂+消费级芯片巨头

智能座舱域控制器芯片市场主要玩家:
1.传统汽车芯片厂商,主打中低端市场:NXP、德州仪器、瑞萨电子等;
2.手机领域的厂商,主打高端市场:联发科、三星、高通等。
由于域控制器芯片市场仍处于行业萌芽期,目前国内搭载座舱域控制器芯片的车型绝大部分仍然采用的是德州仪器的Jacinto6 和 NXP 的 i.mx6 等上一代产品。国内竞争者主要有杰发、芯驰等。
竞争格局:以2015年为时间节点,传统的汽车芯片厂家遇到消费领域巨头芯厂家的挑战,
2015年前:以瑞萨、NXP、TI等传统汽车芯片主导市场,这三家占据市场60%的份额。
2015年开始:越来越多的消费级芯片巨头参与汽车片芯片生产商重组并购。
智能座舱域控制器的CPU芯片市场-车规级芯片VS消费级芯片( 相对于消费级芯,车规级芯片对于可靠性、安全性的要求更高)

验收条件更苛刻,且周期长:车规级芯片在温度、湿度、碰撞等多个维度范围更宽,需要承受的极限条件更苛刻
更新换代速度更慢,升级动力不足:由于开发需求的复杂化,在芯片设计、测试等环节投入更高的成本和时间,车机芯片的更新换代速度相对较慢(有的车型一卖就是七八年),车机芯片升级的动力不足,态度更加谨慎。
趋势变化,这两年车机芯片的运行速度已经和消费级芯片的运行速度差距大幅度减小。
参照手机,汽车座舱领域迭代速度加快,车机芯片的运行速度已经和消费级芯片大幅缩小,产品的生命周期越来越短。
市场竞争越来越激烈,玩家格局也发生变化:原本手机领域的厂家如联发科、三星、高通都加入阵营,未来华为、紫光展锐也会加入。
手机领域的厂家主要着眼点在于研发成果的最大限度利用。而原本传统的汽车SoC芯片厂家NXP、瑞萨和德州仪器压力大增。
智能座舱(中控屏)芯片发展情况
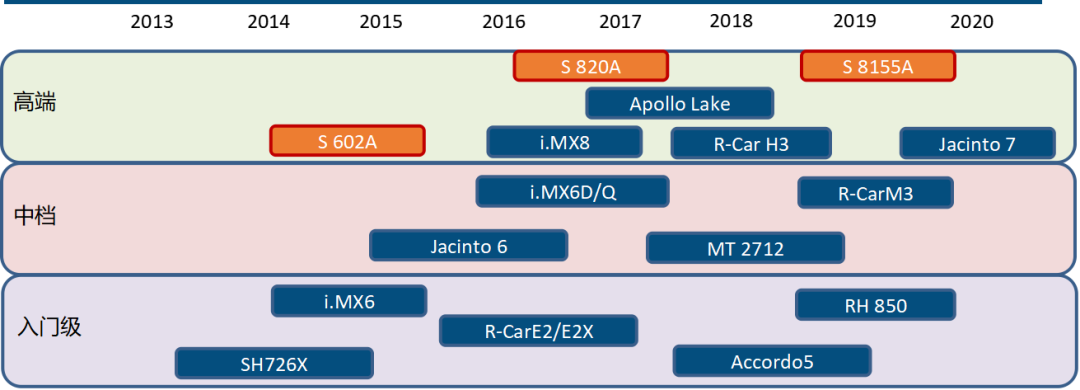
智能座舱域控制器芯片未来3-5年的玩家
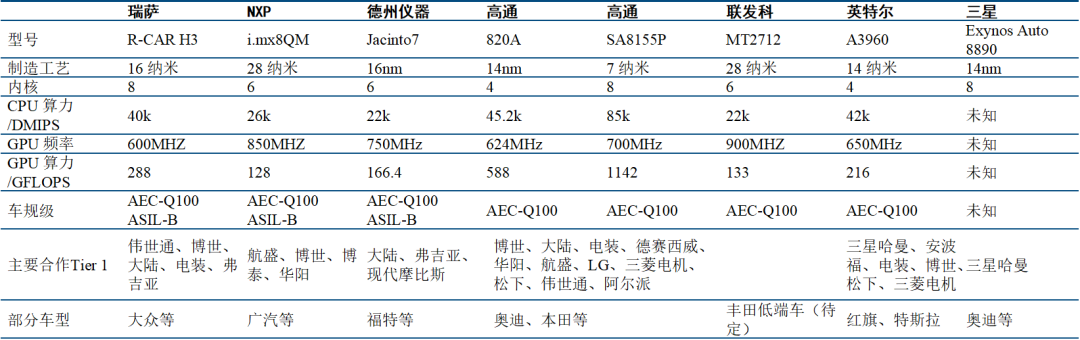
智能座舱芯片:高端以高通、英特尔、瑞萨为主(还要看其第四代产品竞争力),高通领先
CPU性能对比:高通820A CPU性能与英特尔、瑞萨基本一致。但8155具备全方面的性能优势,8.5万DMIPS同代产品领先。
GPU性能:目前浮点性能上,高通相比于瑞萨、英特尔领先较多,比如820A的GPU性能为588GFLOPS,而英特尔为 216GFLOPS,瑞萨为115.2GFLOPS。
中低端玩家:恩智浦(i.MX6/i.MX8)、德州仪器(Jacinto 6/ Jacinto 8)
低端产品:意法半导体(A5/A6)
待进入玩家:华为、三星、联发科。
3、芯片算力角度
CPU的通用计算性能是由IPC、主频、指令数三者共同决定。IPC的提升是CPU通用性能提升的必要条件。主频的提升通常由CPU制程的进步产生,越小nm的制程主频越高,一般A53可以跑1.2G,A72可以跑1.6GHZ。

CPU性能评估采用综合测试程序,较流行的有Whetstone和Dhrystone两种。Dhrystone主要用于测整数计算能力,计算单位就是DMIPS。Whetstone主要用于测浮点计算能力,计算单位就是MFLOPS。一个表示整数运算能力,一个表示浮点数运算能力,二者不能完全等同。
DMIPS:Dhrystone Million Instructions executed Per Second,主要用于测整数计算能力;
MFLOPS:Million Floating-point Operations Per Second,主要用于测浮点计算能力;
D是Dhrystone的缩写,表示的是基于Dhrystone这样一种测试方法下的MIPS。Dhrystone是于1984年由Reinhold P. Weicker设计的一套综合的基准程序,该程序用来测试CPU(整数)计算性能。Dhrystone所代表的处理器分数比MIPS(Million Instructions executed Per Second,每秒钟执行的指令数)更有意义。
一般芯片都有DMIPS/MHz信息(参见下面的图片)
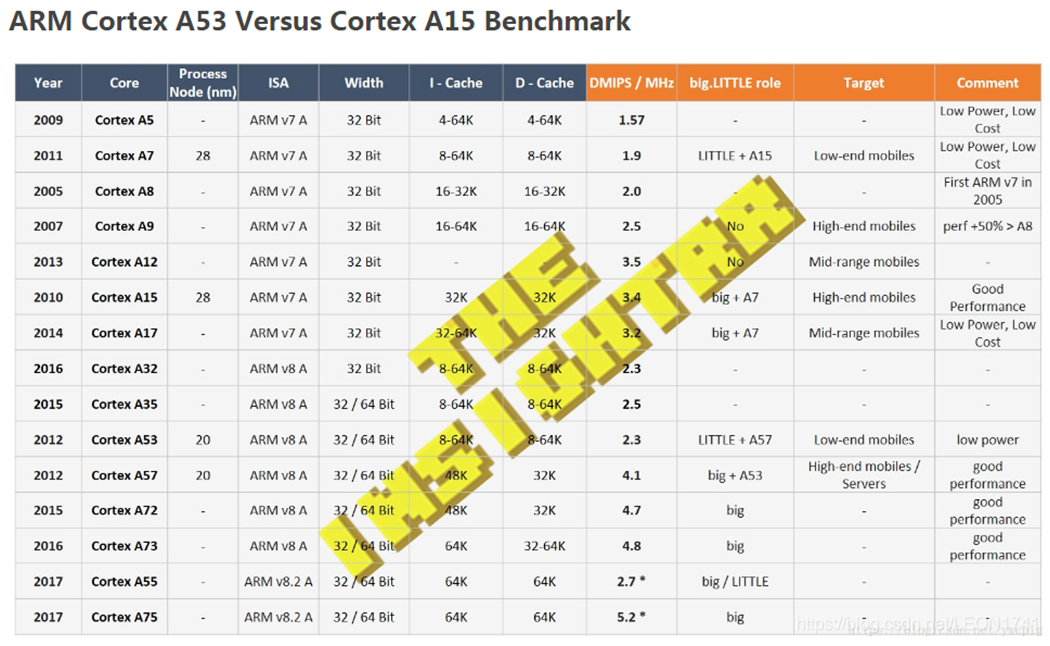
比如ARM Cortex-A53架构为2.3DMIPS/MHz,那么可以计算出:
双核A53架构,主频为1.6GHz的CPU,DMIPS为:2 * 1600MHz * 2.3 DMIPS/MHz = 7360 DMIPS;
四核A53架构,主频为1.6GHz的CPU,DMIPS为:4 * 1600MHz * 2.3 DMIPS/MHz = 14720 DMIPS;
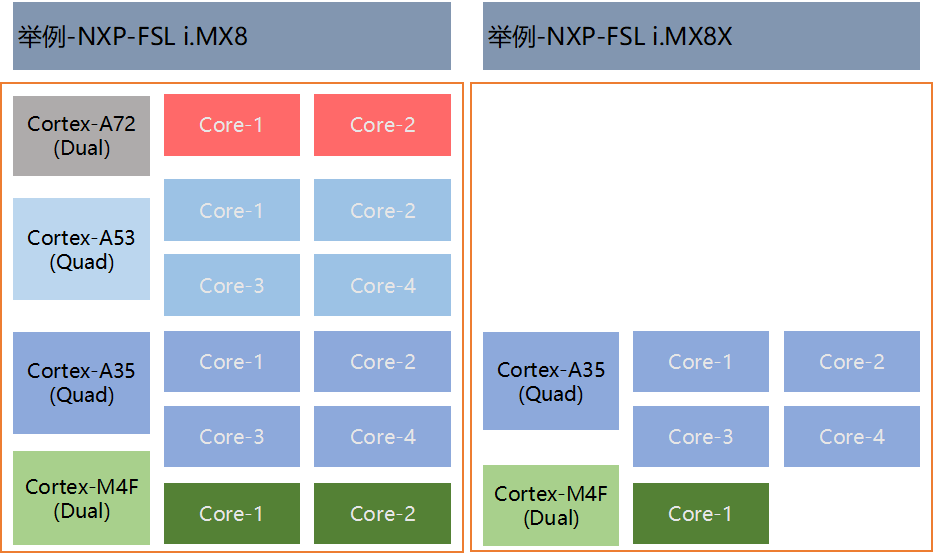
我们来算下NXP ?i.mx8 QuadMax ?,ARM(2*A72+4*A53)?,4核A53架构,主频为1.2GHz的CPU,DMIPS为:4 * 1200MHz * 2.3 DMIPS/MHz = 11040DMIPS;
2核A72架构,主频为1.6GHz的CPU,DMIPS为:2 * 1600MHz * 4.7 DMIPS/MHz = 15040 DMIPS;最终IMX8Q的CPU计算性能 15040+11040=26080,所以是26K DMIPS;
4、芯片SOC的GPU算力能力
人工智能的发展也带动了汽车智能化发展,过去的以CPU为核心的处理器越来越难以满足处理视频、图片等非结构化数据的需求,同时处理器也需要整合雷达、视频等多路数据,这些都对车载处理器的并行计算效率提出更高要求,而GPU同时处理大量简单计算任务的特性在自动驾驶领域取代CPU成为了主流方案。为什么AI算法大部分都使用GPU,自动驾驶计算目前来看也是GPU是一个潮流?
我们这次就讲一个故事的形式来讲解会更清楚一些,当你驾驶一辆具有自动驾驶L3级别的车辆,你下高速后,在没有路标的地方发现100米前有一条河,此时由于车辆图像库里面没有河这个资源,需要快速的图像识别并决策。
AI算法,在图像识别等领域,常用的是CNN卷积网络,语音识别、自然语言处理等领域,主要是RNN,这是两类有区别的算法。但是,他们本质上,都是矩阵或vector的乘法、加法,然后配合一些除法、指数等算法。
假设此时你车上的AI图像算法是YOLO-V3,它是一种使用深度卷积神经网络学得的特征来检测对象的目标检测器,直白点就是照片识别器,在机场地铁都有批量使用,就是大量的卷积、残差网络、全连接等类型的计算,本质是乘法和加法。对于YOLO-V3来说,如果确定了具体的输入图形尺寸,那么总的乘法加法计算次数是确定的。比如一万亿次。(真实的情况比这个大得多的多),用算力表示就是TOPS为单位。
那么要快速执行一次YOLO-V3,就必须执行完一万亿次的加法乘法次数。
这个时候就来看了,比如IBM的POWER8,最先进的服务器用超标量CPU之一,4GHz,SIMD,128bit,假设是处理16bit的数据,那就是8个数,那么一个周期,最多执行8个乘加计算。一次最多执行16个操作。这还是理论上,其实是不大可能的。
那么CPU一秒钟的巅峰计算次数=16* 4Gops =64Gops,当然,以上的数据都是完全最理想的理论值。因为,芯片上的存储不够大,所以数据会存储在DRAM中,从DRAM取数据很慢的,所以,乘法逻辑往往要等待。另外,AI算法有许多层网络组成,必须一层一层的算,所以,在切换层的时候,乘法逻辑又是休息的,所以,诸多因素造成了实际的芯片并不能达到利润的计算峰值,而且差距还极大,实际情况,能够达到5%吧,也就3.2Gops,按照这个图像算法,如果需要执行YOLO-V3的计算,1W除以3.2=3125秒,也就是那么需要等待52分钟才能计算出来。
如果是当前的CPU去运算,那么估计车翻到河里了还没发现前方是河,这就是速度慢,对于ADAS产品而言,时间就是生命。
此时我们在回过头来看看高通820A芯片的算力,CPU的算力才42K,刚刚那个是基于最先进的服务器IBM的POWER8 CPU计算力是是3.2GPOS,车载算的上最先进的域控制器才42K的CPU计算力,所以不能用于AI的计算。此时需要使用GPU来计算,看看GPU的算力是320Gops,此时算这个YOLO-V3图像识别的算法需要32秒,这个成绩还是非常不错的。
此时可以看到高通820A芯片的CPU算力是不能够用于AI的计算,GPU的算力是可以满足一些不需要那么实时性比较高的一些AI处理。
如果是一些简单的ADAS功能是没有问题,比如车内的人脸识别,这部分的算法就不要那么多资源,该产品运行了820A神经网络处理引擎(SNPE),这里的引擎也就是AI加速的一些算法,有兴趣单独来讲怎么实现加速。这里高通820A能实现对车辆、行人、自行车等多类物体识别,以及对像素级别可行驶区域的实时语义分割,当然离商用应该还有一定距离。总的来说,高通骁龙产品策略应该还是以车载娱乐信息系统为主,逐步向更专业的ADAS拓展。
这样你就不会问为什么GPU这么厉害,AI识别为什么不全部使用GPU得了,那就需要继续看CPU和GPU的区别了。
从芯片设计思路看,CPU是以低延迟为导向的计算单元,通常由专为串行处理而优化的几个核心组成,而GPU是以吞吐量为导向的计算单元,由数以千计的更小、更高效的核心组成,专为并行多任务设计。
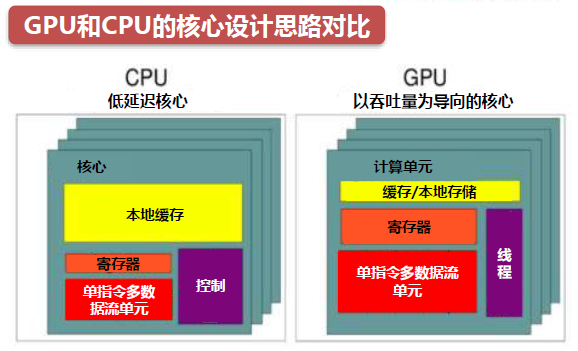
CPU的核心运算ALU数量只有几个(不超过两位数),每个核都有足够大的缓存和足够多的数字和逻辑运算单元,并辅助很多复杂的计算分支。而 GPU的运算核心数量则可以多达上百个(流处理器),每个核拥有的缓存大小相对小,数字逻辑运算单元也少而简单。
CPU和GPU最大的区别是设计结构及不同结构形成的不同功能。CPU的逻辑控制功能强,可以进行复杂的逻辑运算,并且延时低,可以高效处理复杂的运算任务。而 GPU逻辑控制和缓存较少,使得每单个运算单元执行的逻辑运算复杂程度有限,但并列大量的计算单元,可以同时进行大量较简单的运算任务。

CPU是根据冯诺依曼的架构进行设计,所以存储、计算、交互都有,GPU本来是从CPU中分离出来专门处理图像计算的,也就是说,GPU是专门处理图像计算的。包括各种特效的显示。这也是GPU的天生的缺陷,GPU更加针对图像的渲染等计算算法,所以这里的天生两个缺陷是不能进行复杂的逻辑控制,而且GPU没有cache单元,也没有复杂的逻辑控制电路和优化电路,所以不能单独像CPU那样进行单独的控制,你看机顶盒芯片都是CPU里面内含GPU的架构,GPU主要用来做图像的渲染方面,工具就是Open CL图像编辑器来编译。
CPU和GPU设计思路的不同导致微架构的不同。CPU的缓存大于GPU,但在线程数,寄存器数和SIMD(单指令多数据流)方面GPU远强于CPU。
微架构的不同最终导致CPU中大部分的晶体管用于构建控制电路和缓存,只有少部分的晶体管完成实际的运算工作,功能模块很多,擅长分支预测等复杂操作。GPU的流处理器和显存控制器占据了绝大部分晶体管,而控制器相对简单,擅长对大量数据进行简单操作,拥有远胜于CPU的强大浮点计算能力。
CPU和GPU的不同的通俗解释:
GPU的工作大部分就是这样,计算量大,但没什么技术含量,而且要重复很多很多次。就像你有个工作需要算几亿次一百以内加减乘除一样,最好的办法就是雇上几十个小学生一起算,一人算一部分,反正这些计算也没什么技术含量,纯粹体力活而已。而CPU就像老教授,积分微分都会算,就是工资高,一个老教授能顶二十个小学生,你要是富士康你雇哪个?
GPU就是这样,用很多简单的计算单元去完成大量的计算任务,纯粹的人海战术。这种策略基于一个前提,就是小学生A和小学生B的工作没有什么依赖性,是互相独立的。很多涉及到大量计算的问题基本都有这种特性,比如你说的破解密码,挖矿和很多图形学的计算。这些计算可以分解为多个相同的简单小任务,每个任务就可以分给一个小学生去做。但还有一些任务涉及到“流”的问题。比如你去相亲,双方看着顺眼才能继续发展。总不能你这边还没见面呢,那边找人把证都给领了。这种比较复杂的问题都是CPU来做的。
总而言之,CPU和GPU因为最初用来处理的任务就不同,所以设计上有不小的区别。而某些任务和GPU最初用来解决的问题比较相似,所以用GPU来算了。GPU的运算速度取决于雇了多少小学生,CPU的运算速度取决于请了多么厉害的教授。教授处理复杂任务的能力是碾压小学生的,但是对于没那么复杂的任务,还是顶不住人多。当然现在的GPU也能做一些稍微复杂的工作了,相当于升级成初中生高中生的水平。但还需要CPU来把数据喂到嘴边才能开始干活,究竟还是靠CPU来管的。
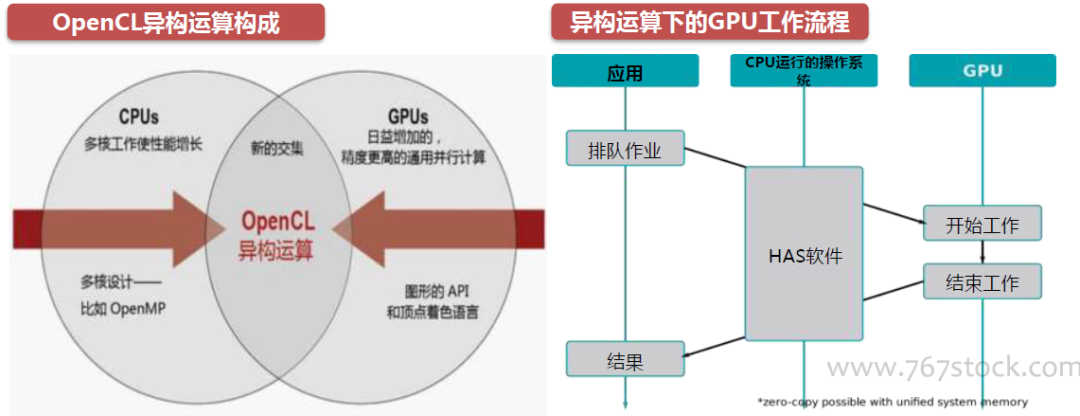
后摩尔时代,随着GPU的可编程性不断增强,GPU的应用能力已经远远超出了图形渲染,部份GPU被用于图形渲染以外领域的计算成为GPGPU。与此同时,CPU为了追求通用性,只有少部分晶体管被用于完成运算,而大部分晶体管被用于构建控制电路和高速缓存。但是由于GPU对CPU的依附性以及GPU相较CPU更高的开发难度,所以GPU不可能完全取代CPU。我们认为未来计算架构将是GPU+CPU的异构运算体系。
在GPU+CPU的异构运算中,GPU和CPU之间可以无缝地共享数据,而无需内存拷贝和缓存刷新,因为任务以极低的开销被调度到合适的处理器上。CPU凭借多个专为串行处理而优化的核心运行程序的串行部份,而GPU使用数以千计的小核心运行程序的并行部分,充分发挥协同效应和比较优势。
异构运算除了需要相关的CPU和GPU等硬件支持,还需要能将它们有效组织的软件编程。OpenCL是(OpenComputing Language)的简称,它是第一个为异构系统的通用并行编程而产生的统一的、免费的标准。OpenCL支持由多核的CPU、GPU、Cell架构以及信号处理器(DSP)等其他并行设备组成的异构系统。
什么类型的程序适合在GPU上运行?
?(1)计算密集型的程序。所谓计算密集型(Compute-intensive)的程序,就是其大部分运行时间花在了寄存器运算上,寄存器的速度和处理器的速度相当,从寄存器读写数据几乎没有延时。可以做一下对比,读内存的延迟大概是几百个时钟周期;读硬盘的速度就不说了,即便是SSD, 也实在是太慢了。
(2)易于并行的程序。GPU其实是一种SIMD(Single Instruction Multiple Data)架构, 他有成百上千个核,每一个核在同一时间最好能做同样的事情。
??满足以上两点,就可以用GPU做运算了。不过你还得先用CUDA或者Open CL 把能在GPU上运行的程序写出来, 这也是很麻烦的,写一下就知道了。而且GPU的架构比较特殊,要想写出高效率的程序,要花很多很多时间。所以说写GPU程序是一件很蛋疼的事情。
座舱的域控制器GPU算力的需求:
前面聊了GPU对于3D图像处理。一些简单的图像算法都需要涉及GPU,而智能座舱域控制器主要是输出给液晶仪表和中控导航,所以首先图像处理部分肯定是必不可少的,这个就跟图像显示需要做到的效果有关了,如果仅仅是普通的2.5D的效果,这个时候对于GPU的算力就不高,如果是3D的高级的图像效果,这个时候就需要GPU的算力比较大,基本上200 GFLOPS以上就能满足3个屏以上的图像效果了。
如果还需要GPU进行相关的图像算法处理,这个时候GPU的能力至少需要500G GFLOPS以上。
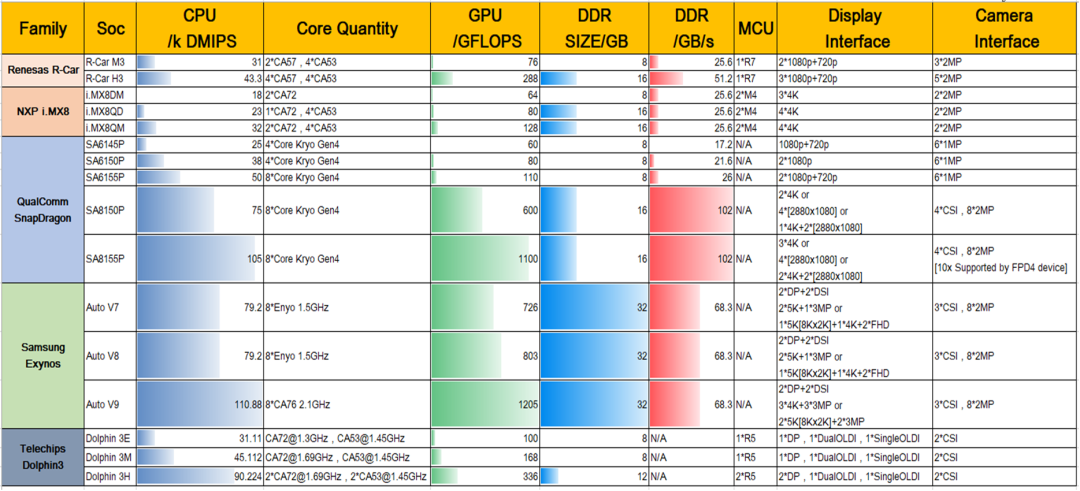
智能座舱的域控制综合考虑因素
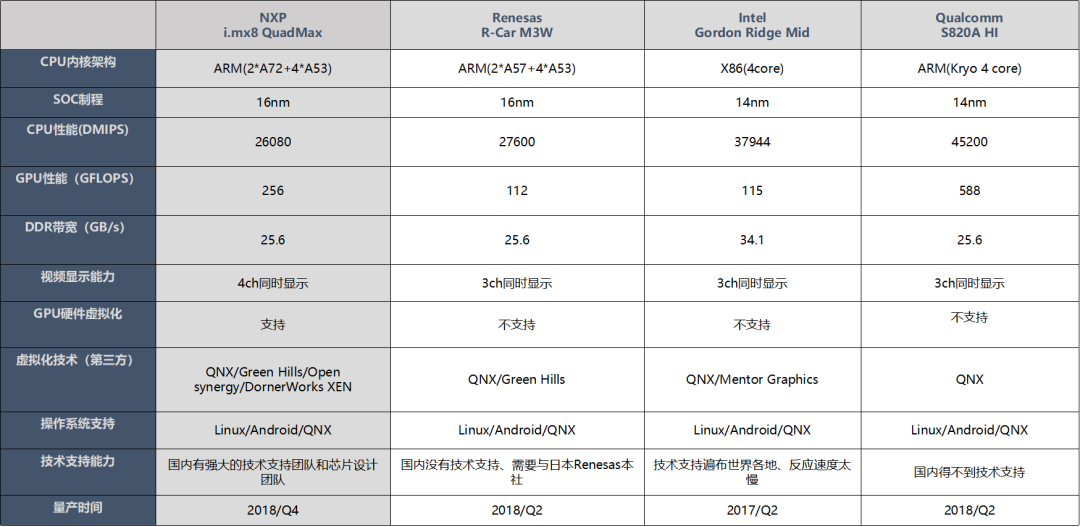
这个是目前主流的NXP、R-Car、高通、Intel等几个厂家的主流芯片方案,可以看到NXP支持最大的4个显示屏显示,其他的芯片方案都只支持3个显示屏,还有一个就是GPU硬件虚拟化,这部分就是硬件上的隔离,基本上很少有芯片厂家能做到硬件隔离,这个隔离后非常有好处,防止某个部分死机后导致整体的GPU会挂掉,而且GPU需要单独的存储去分配,这样也会导致外挂的存储芯片会多一些,毕竟涉及功能安全,这样也是一个冗余措施保护。
想想如果处理不压缩的图像数据,我们来看看4K的图像数据有多少,3840*2160*24bit*60fps=11943936000bits= 1.39GB/s ,处理一个4K的图像数据就需要这多大的数据量,而且允许占的内存带宽还会更大。
可以看到CPU的算力至少都是26K DMIPS,最大的算力芯片就是高通芯片,DDR的带宽这部分要求也不是那么高,25.6G的带宽完全能够满足座舱的需求。
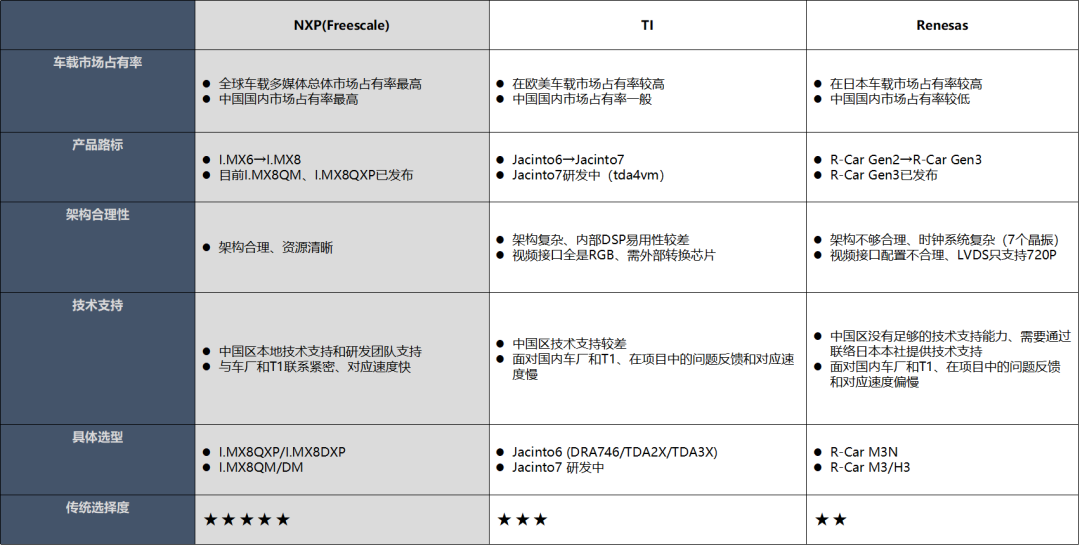
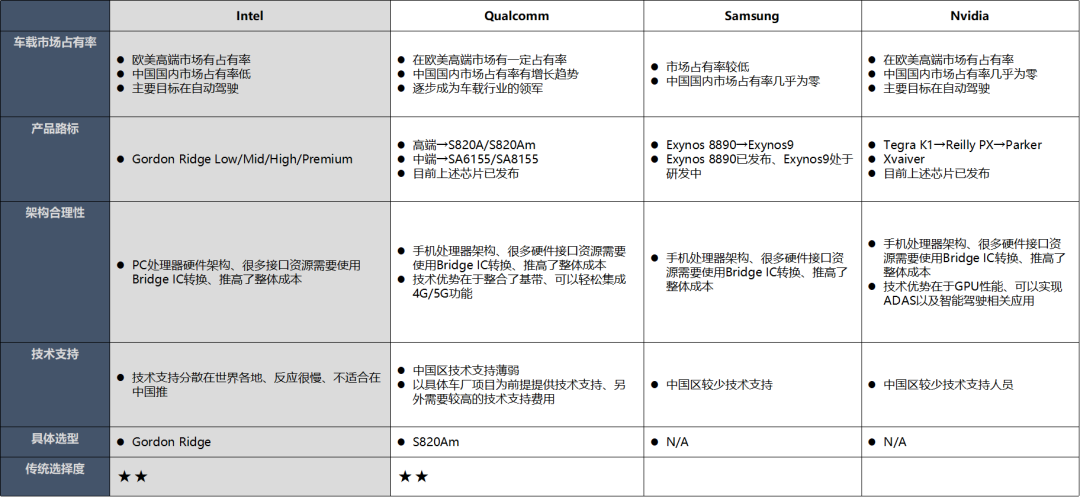
在选择芯片平台的时候,还需要考虑以下因素
1、车载市场占有率 这个占有率越高,整体后面的成本才具有优势,同时采购周期或者调货的时候也比较方便,当然大家都用,就需要考虑到后面的技术支持的力度,从目前来看高通芯片的占有率非常高,其次是NXP和瑞萨。
2、还需要考虑芯片架构的合理性,特别是很多芯片公司都是手机处理器的架构,手机处理器架构、很多硬件接口资源需要使用Bridge IC转换、推高了整体成本,有的只有RGB接口,而一般车载显示屏都是LVDS接口,需要增加视频转换芯片,高通芯片比较好的地方是融合了基带信号,这个可以节省很大比射频芯片的成本,只需要外围增加射频天线即可。
3、产品路标和技术支持也是需要考虑的一个维度,比如瑞萨在国内的技术支持力度就不大,中国区没有足够的技术支持能力、需要通过联络日本本社提供技术支持面对国内车厂和T1、在项目中的问题反馈和对应速度偏慢。而且需要看该产品路线后续的芯片规划,有的可能规划了这两代后,后面基本上就放弃了智能座舱的芯片了,比如TI芯片。
10、主流座舱芯片的高通的发展路线
高通芯片的市占率
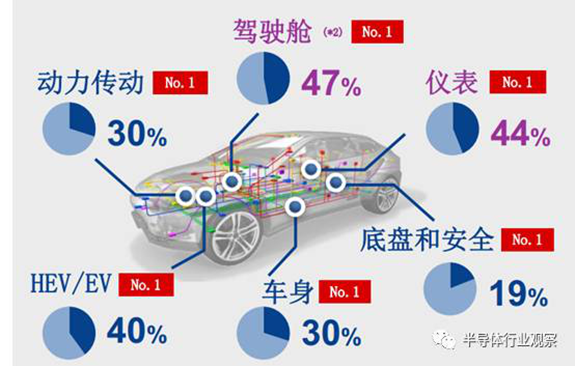
根据Strategy Analytics数据,2015年瑞萨、恩智浦合计占据整个车机芯片市场份额的六成以上,其中瑞萨在驾驶舱、仪表份额达到47%、44%;
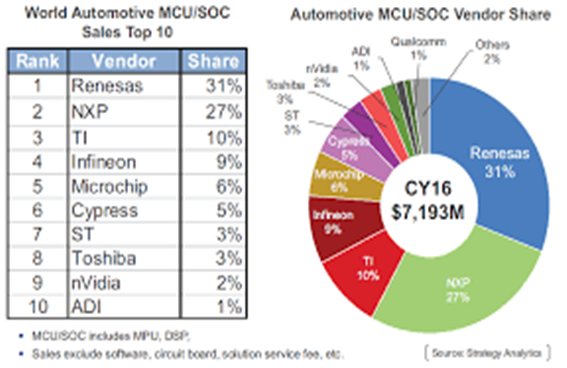
车用MCU/SOC市场规模约为60-70亿美元,2016年之前高通市占率为1%以下;2019、2020财年高通来自汽车业务收入(包含通信、座舱芯片)收入分别为6.4、6.44亿美金。
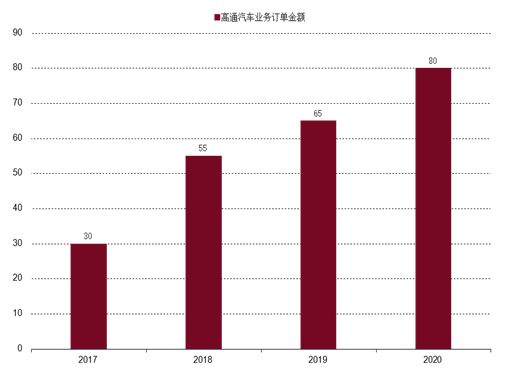
公司预期汽车芯片在2022年的TAM为180亿美元,对应三年CAGR为 12%。
推算2020年TAM约为140亿美元,公司收入6.44亿美元,市占率约4.6%。
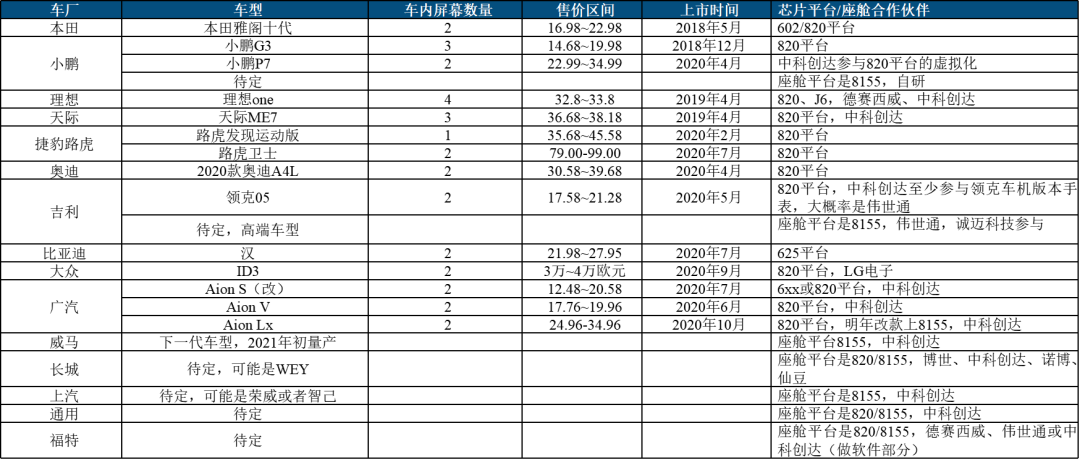
高通座舱芯片渗透率不断走高。其中2020年是高通座舱出货大年,核心出货量比较大的车型包括奥迪改款A4L、本田雅阁十代等,并且大部分新能源车型都选择高通820A作为座舱芯片。
高通芯片roadmap
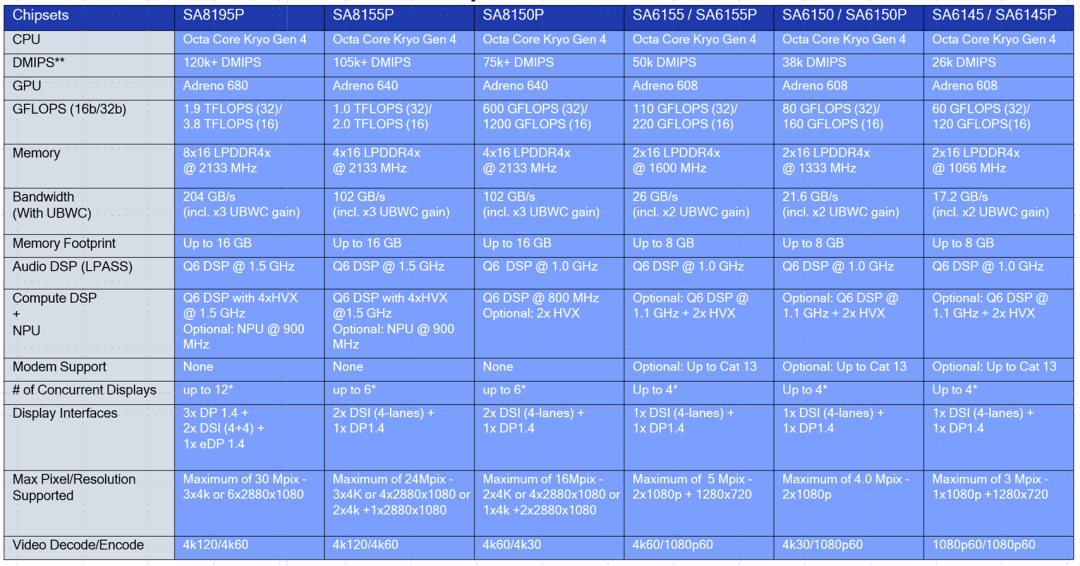
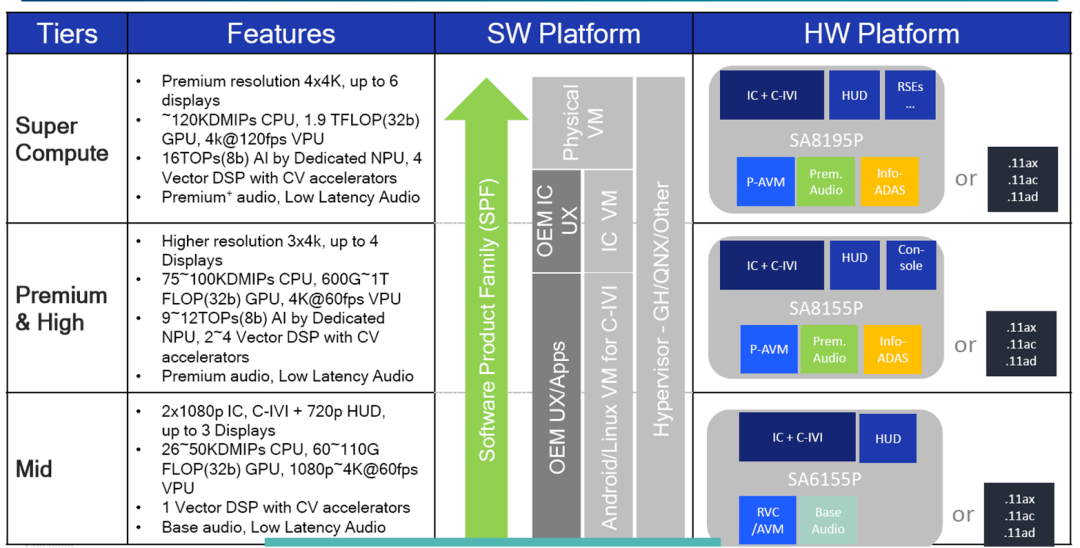
从性能参数可以看到最强的8195P,现在最前沿马上量产的是8155,吉利的极克01就是这个芯片,当然小鹏的P5也是这个芯片,都还没有量产,比8155低一个档位的是820A芯片,前面有可以看到有接近20款车型使用这个座舱芯片,当然也有低端的座舱芯片,比如带动一个中控导航和副驾驶娱乐屏的需求,这个时候就可以使用6155P的芯片。
11、自主平台的芯片发展
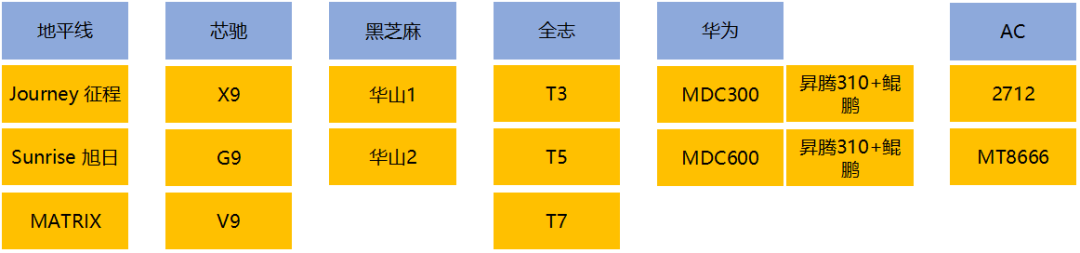
自主平台在座舱里面发力比较多的是芯驰,地平线和黑芝麻主要是做自动驾驶的芯片,比如地平线的征程5已经在很多车上做自动驾驶平台方案了。
全志的T7也有在东南汽车、北京现代、长安汽车上使用,但是做座舱芯片还是很吃力,基本上只能做中控导航的驱动。目前看到的自主座舱芯片平台比较有潜力的是芯驰。
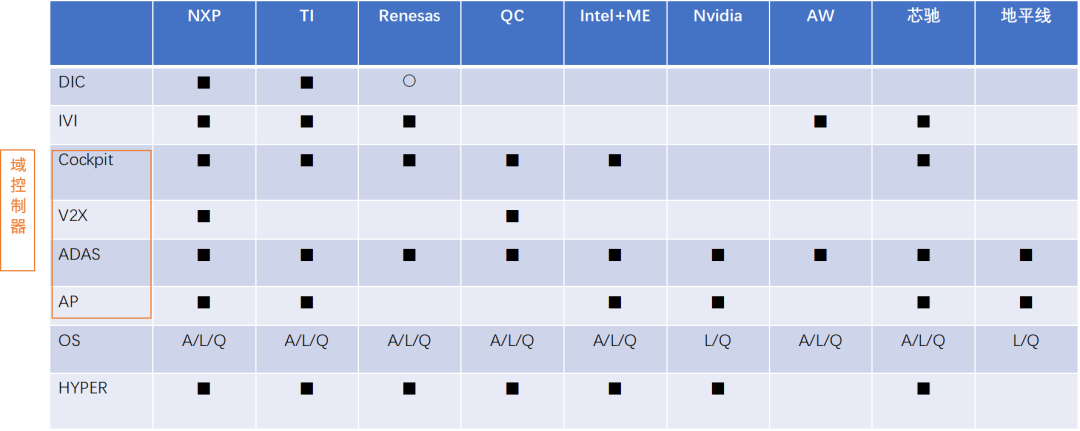
可以看到越来越多的芯片公司选择来做智能座舱的芯片,NXP\TI\瑞萨传统三杰,高通,intel、芯驰、全志等厂家也进入来做座舱芯片,单芯片多系统为代表的“域控制器”,已经成为智能汽车的必选项目之一。
12、传统多芯片架构
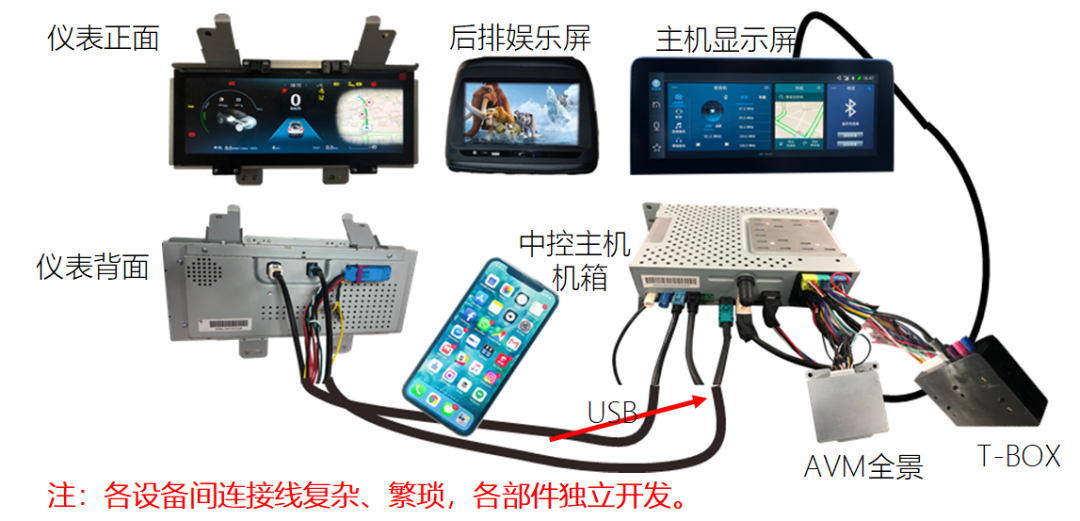
原来的座舱里面的控制器基本上是分开的,导航主机是一家,液晶仪表是一家,同时还有一个AVM全景一家,还有TBOX等,这里线束连接就非常复杂,而且不同供应商直接的协调调试也非常复杂。
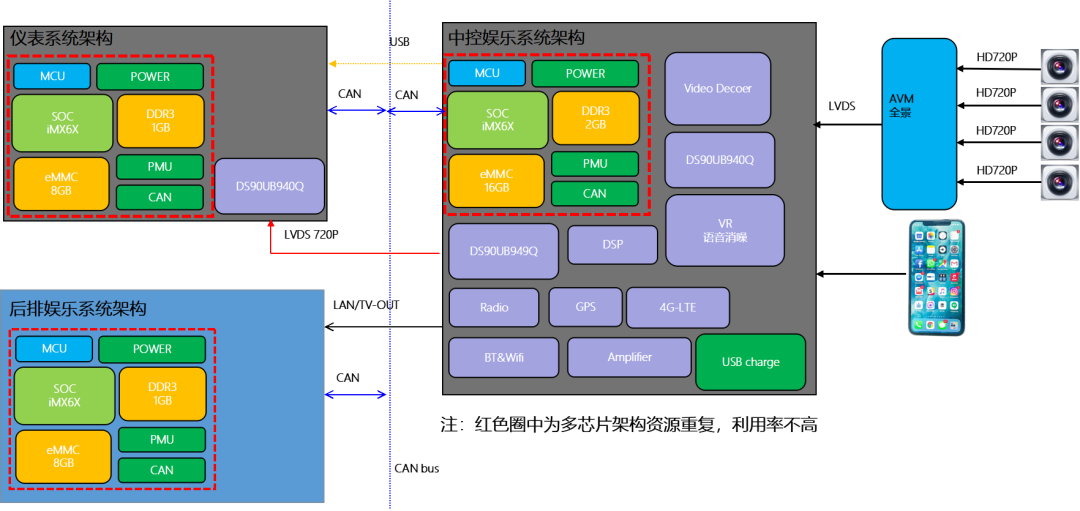
上图是IMX6 的多芯片方案,液晶仪表、中控导航、后排娱乐都使用了IMX6最小系统,这样上图黄色框里面的内容就资源重复了,但是如果只用一颗IMX6又不能带动三个显示屏,所以利用率不高。
单SOC智能座舱系统框架
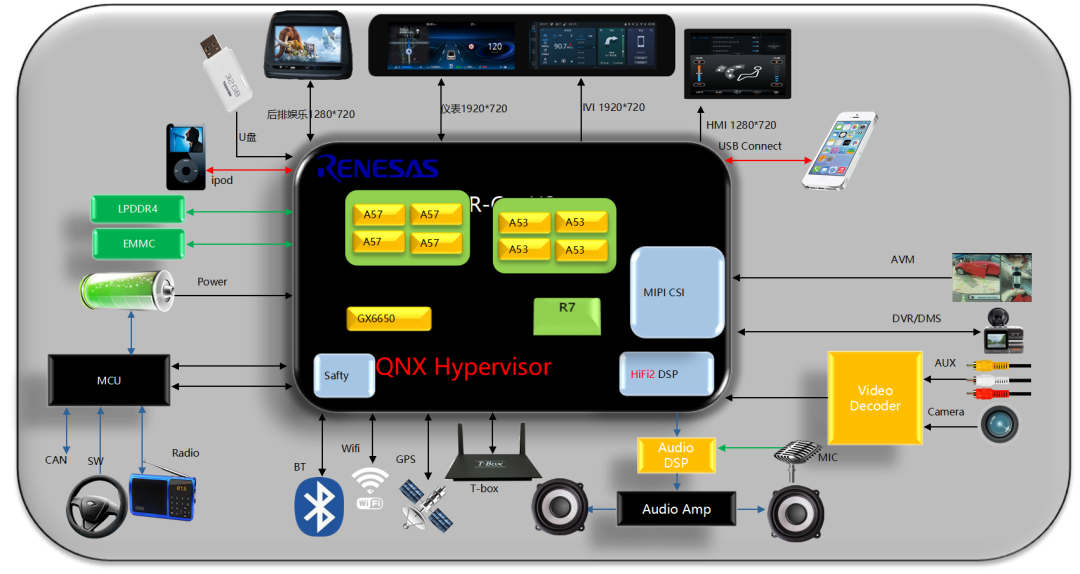
上图是RCAR-H3的单SOC智能座舱的方案,可以看到这部分最小核心系统的器件只需要一份,就可以驱动中控导航、液晶仪表、后排娱乐显示屏、还有副驾驶娱乐屏,多个显示屏的不同内容。
单SOC 的方案的优点非常多? ???? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ???
车身:设备单一,布线方便,成本低,可靠性好。
系统硬件资源:
Hypervisor 技术系统硬件资源最大化利用, DDR/EMMC/PMIC/MCU/CAN单套系统配置即可满足产品需求
产品开发:
独家设备供应商,独立设备开发,独立样件制作,无须定制复杂协议,多个设备无须联调,开发进度容易把控,开发成本可控。
信息安全:
独家供应商,设备间通讯在芯片内部完成,信息安全得到有效保护。
整套成本:
硬件资源利用率高,独家供应商,生产,包装,运输可控整套成本可控。
体验:
设备单一,整套设备方案受限因素小,多屏娱乐互动性好,体验佳
13、域控制器设计方案-RCAR-H3
1、方案概述
新推出的R-Car H3具备比前一代R-Car H2更强大的汽车计算性能,可充分满足系统制造商对汽车处理平台的要求。为了提供准确、实时的信息处理能力,R-Car H3基于ARM? Cortex?-A57/A53核构建,采用ARM的最新64位CPU核架构,实现了40000 DMIPS(Dhrystone百万指令/每秒(注1))的处理性能。
此外,R-Car H3采用PowerVR? GX6650作为3D图形引擎,可为驾驶员提供及时可靠的信息显示。基于ImaginaTIon Technologies提供的最新架构,R-Car H3的着色计算(注2)性能约是R-Car H2的三倍。
除了CPU和GPU以外,片上并行可编程引擎IMP-X5也提供了先进的图像识别技术。IMP-X5是瑞萨电子独有的识别引擎,专门为与CPU配合处理而进行了优化。它的识别性能是第二代R-Car系列内置的IMP-X4的四倍。
R-Car H3是业界首款采用16纳米工艺的汽车SoC,具有卓越的处理能力,符合ISO26262 (ASIL-B)汽车功能安全标准,是先进安全驾驶辅助系统和车载信息娱乐系统等应用的优秀汽车计算平台。
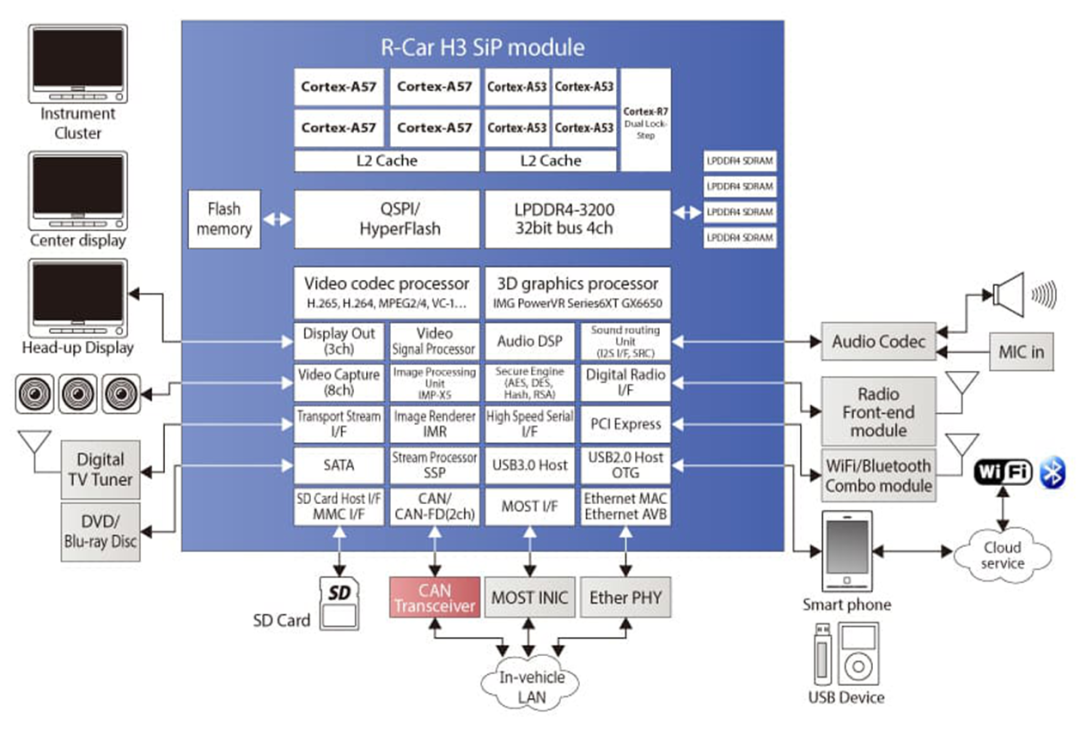
R-Car H3 R8A77951(SoC)关键参数:
CPU core:Cortex-A57 Quad@1.5Ghz+Cortex-A53 Quad@1.2Ghz +Cortex-R7@800Mhz
DDR:LPDDR4/DDR3/DDR3L SDRAM Up to 1600 MHz,32bits x4ch ?Up to ?8GB
GPU:IMG PowerVR Series6XT GX6650 Max 600Mhz
Video input:MIPI-CSI2 3ch(4lane x 2channels, 2lane x 1channel)+ ITU-R BT.601/656 /RGB888 24 bit 2ch
Video output:4 display controllable(HDMI 2ch+LVDS 1ch+RGB888 1ch
Video Codec:H.262/H.263/H.264/H.265/Real Video8/9/10/VP8/VC-1SP/MP/AP/MPEG-4ASP
Storage :USB 3.0 Host 1ports /USB 2.0 Host/OTG 4ports/SD x2ch/SATA 1ch/
OthersI2Cx7ch/PWMx7ch/Audio-DMACx32ch/QSPIx2ch/SCIF 1ch/Ethernet /DRIFx4ch/INTC/CPG
芯片制程? ? 16nm
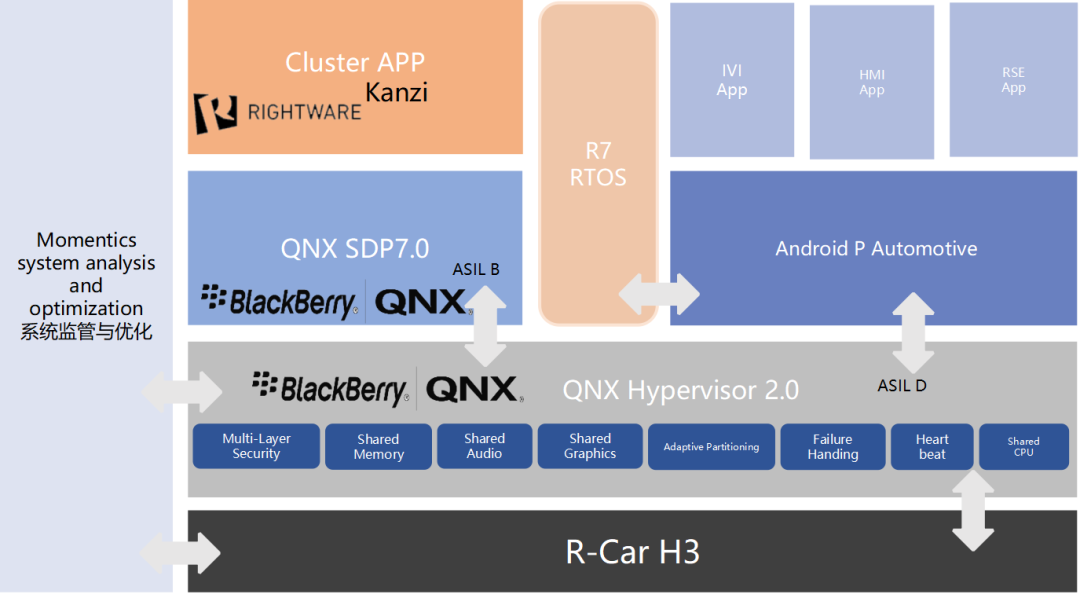
R-CAR H3系统框图
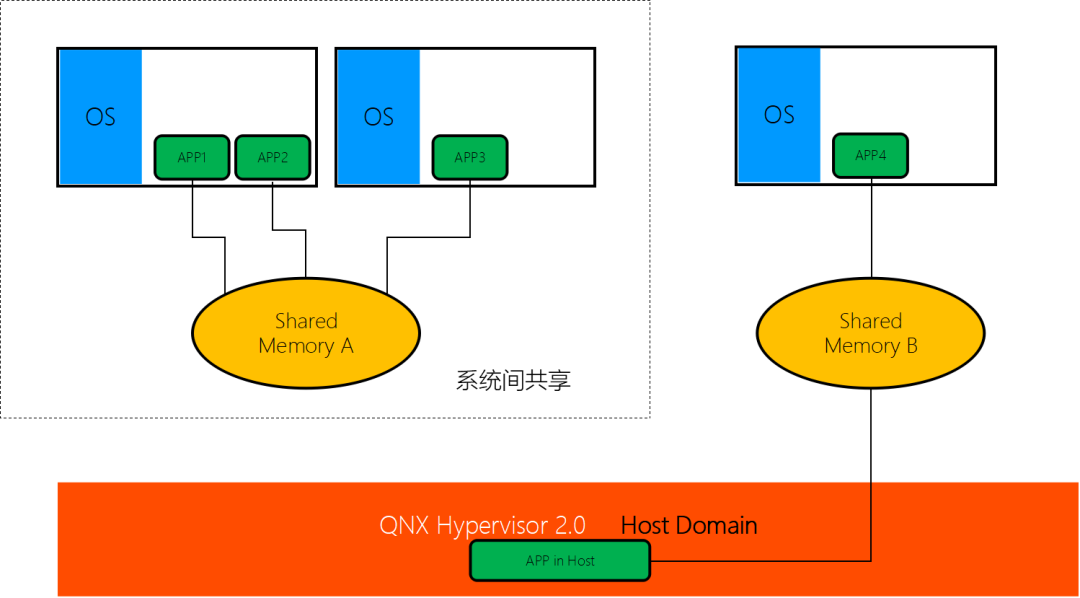
基于1颗SOC,搭载QNX Hypervisor 2.0 运行QNX SDP 7.0+RTOS +Android P Automotive?
CPU及外部硬件资源通过QNX Hypervisor虚拟化共享。
Android P实现IVI+HMI+RSE三屏,QNX SDP 7.0+Kanzi 实现仪表。
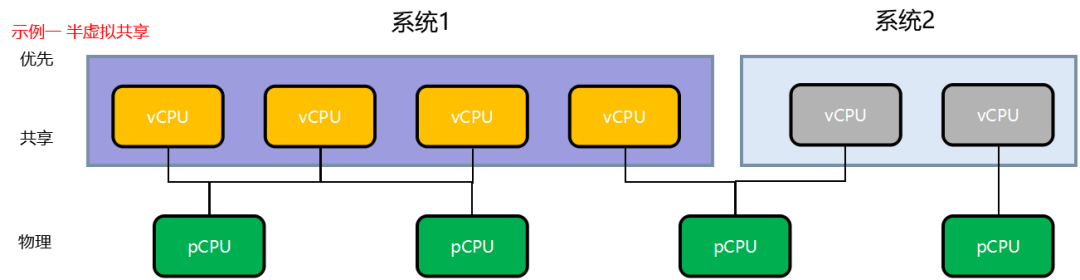
RCAR-H3 QNX 共享CPU
半虚拟化是通过事先经过修改的用户操作系统内核共享底层物理硬件来实现的。
优点:是半虚拟化的虚拟机操作系统内核能够直接管理底层物理硬件,实时性好,性能比全虚拟化技术更强。
缺点:是用户操作系统内核需要事先进行修改,部署的便利性和灵活性不够好。
全虚拟化是通过用户操作系统和物理层的虚拟化逻辑层hypervisor来完全模拟底层物理硬件细节。
优点:是用户的操作系统内核不需要做特殊配置,部署便利,灵活,兼容性好。
缺点:是用户操作系统的内核不能够直接管理底层物理硬件,内核通过hypervisor系统管理模块管理底层物理硬件需要有转换,性能比半虚拟化弱。实时性不好。
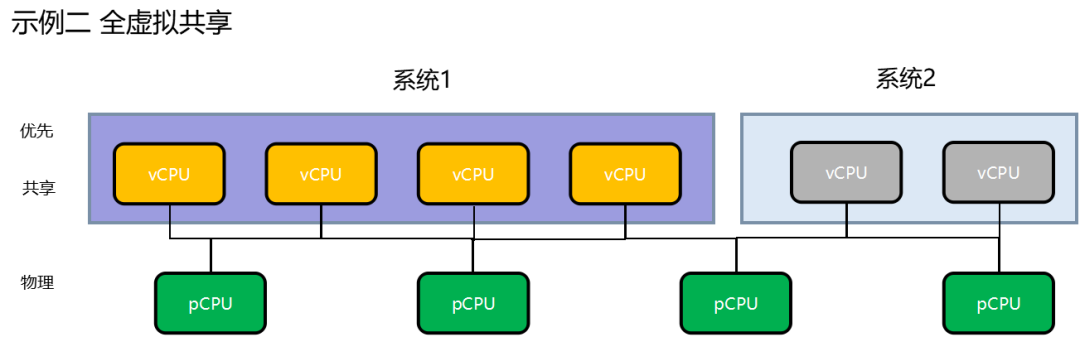
RCAR-H3是使用全虚拟化的设计,共享内存,零拷贝,速度非常快。
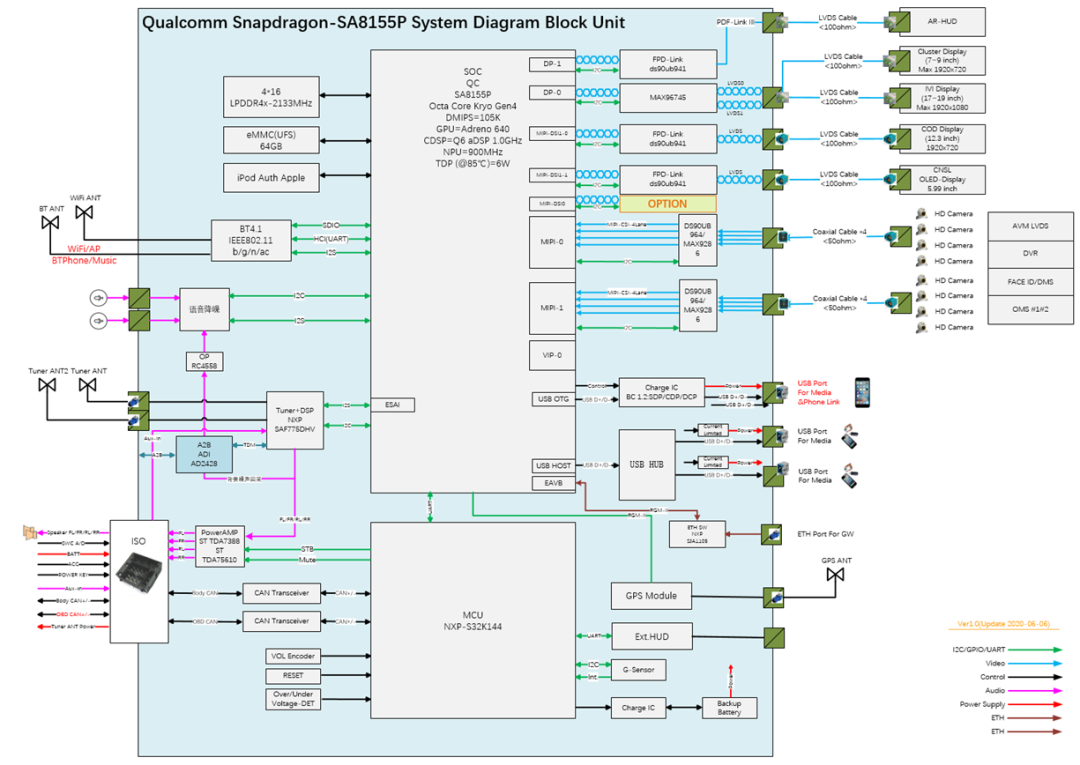
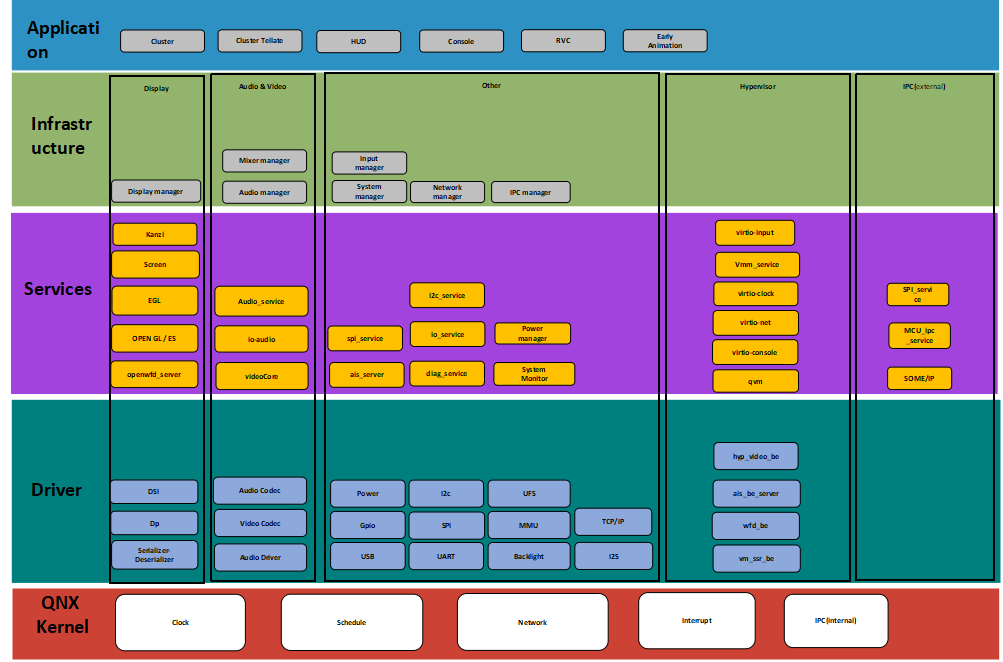
14、域控制器设计方案-高通SA8155P
方案概述

系统框图概要:
系统主要器件List:
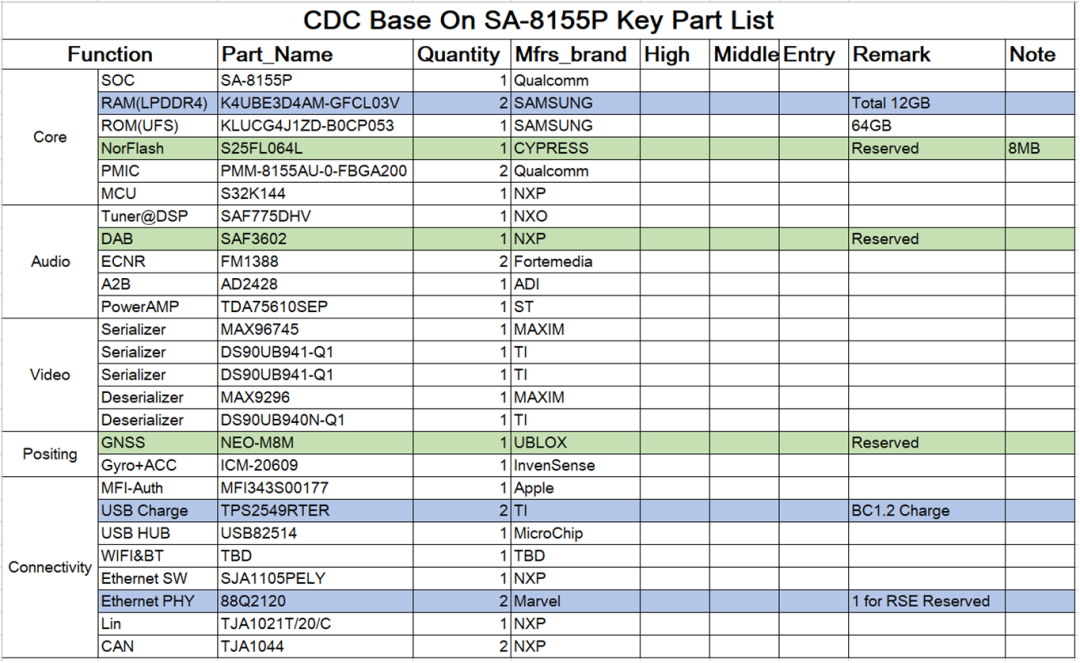
系统主SOC选型说明:
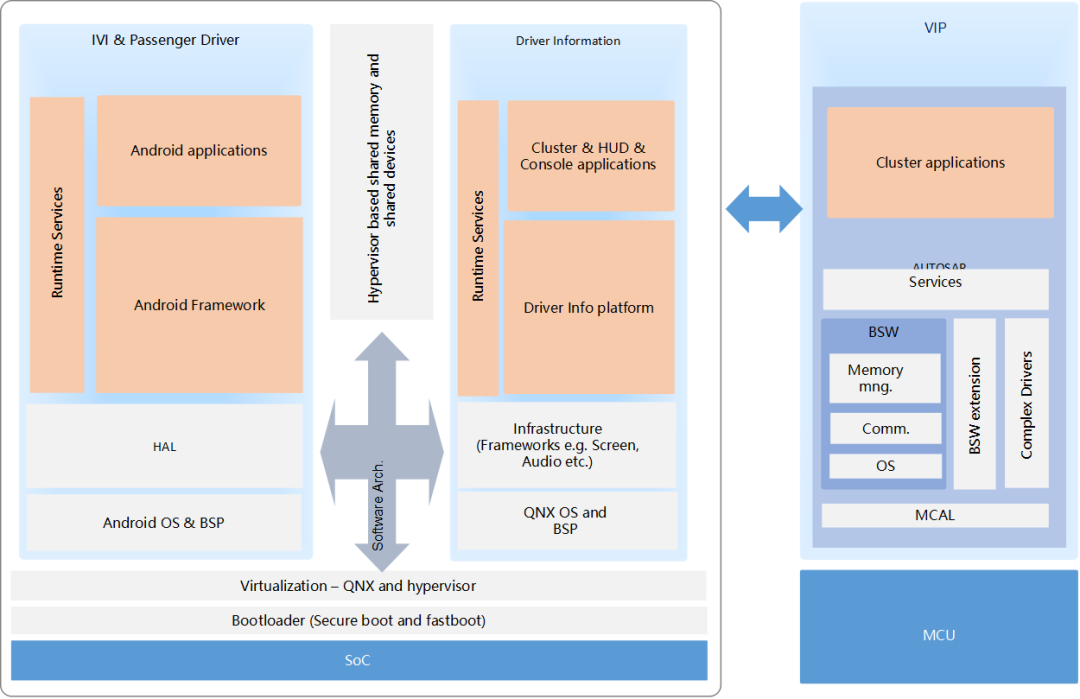
系统软件架构:
座舱系统包含三部分,具体如下:
MCU运行AUTOSAR系统,用于CAN/LIN唤醒/通讯/电源管理等
SoC运行QNX Hypervisor,包含两个操作系统,其中QNX运行对实时性和安全性要求高的功能,比如仪表/HUD
Android系统运行娱乐域相关的功能,比如导航/音乐等应用
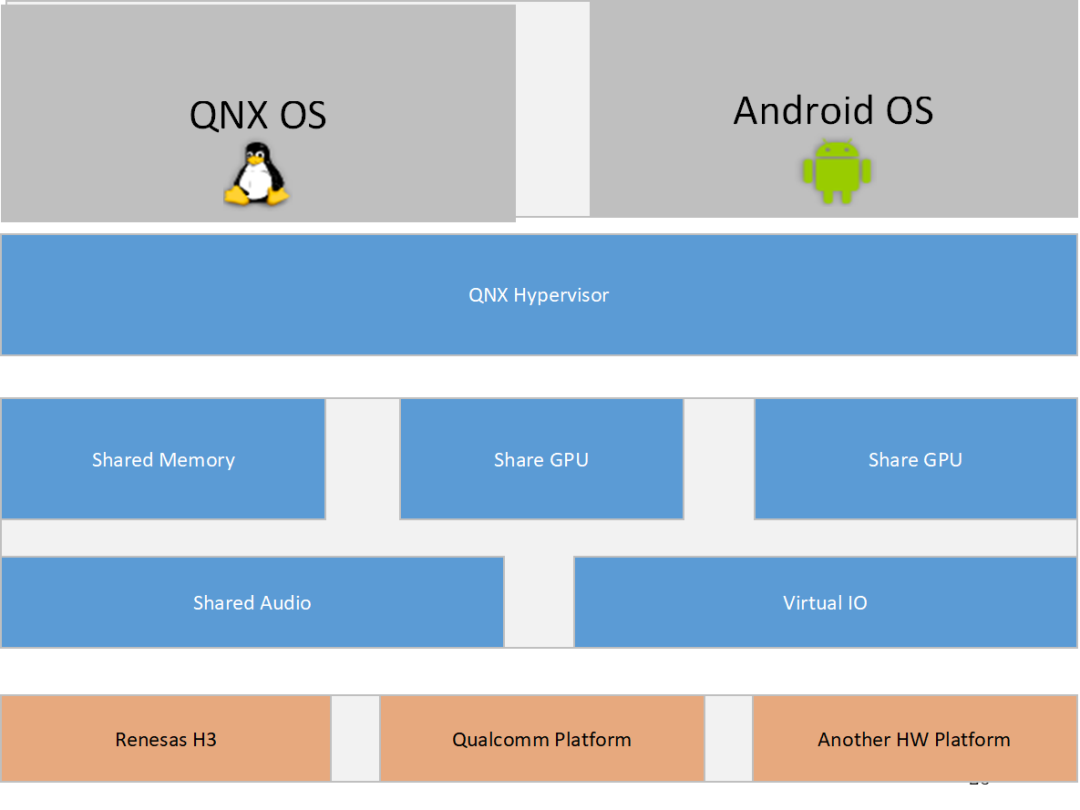
QNX 虚拟化方案支持:
运行Guest OS系统,可以在虚拟机上运行Android系统
QNX系统达到ASIL-D等级,同时具备高实时性,可以运行仪表/HUD等功能
GPU以及CPU的资源可以共享,可以通过配置优先级确保QNX系统的资源
支持Qualcomm平台/Renesas平台/Intel以及其他座舱域控硬件平台
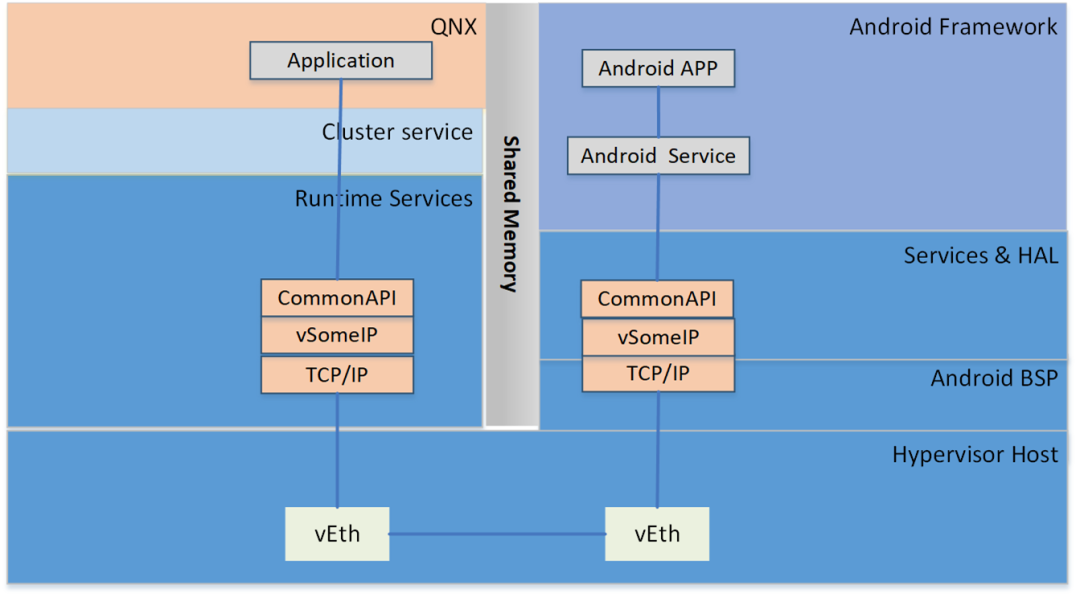
QNX和Android之间的进程间通讯包含两部分
系统间的控制命令/数据通讯(不包含音频视频)可以通过SomeIP协议来实现
系统间的大数据量数据通讯(比如图像/音频)可以通过共享内存的方式实现数据通讯
安卓端框架介绍
应用层:运行自研应用及第三方应用
Framework层:支持上层android应用运行的框架,比如音频/媒体类/连接类等框架
安卓服务层:支持应用运行的功能,以android服务的形式运行
硬件抽象层:对上提供统一的接口,屏蔽底层驱动的不同,对下适配底层驱动
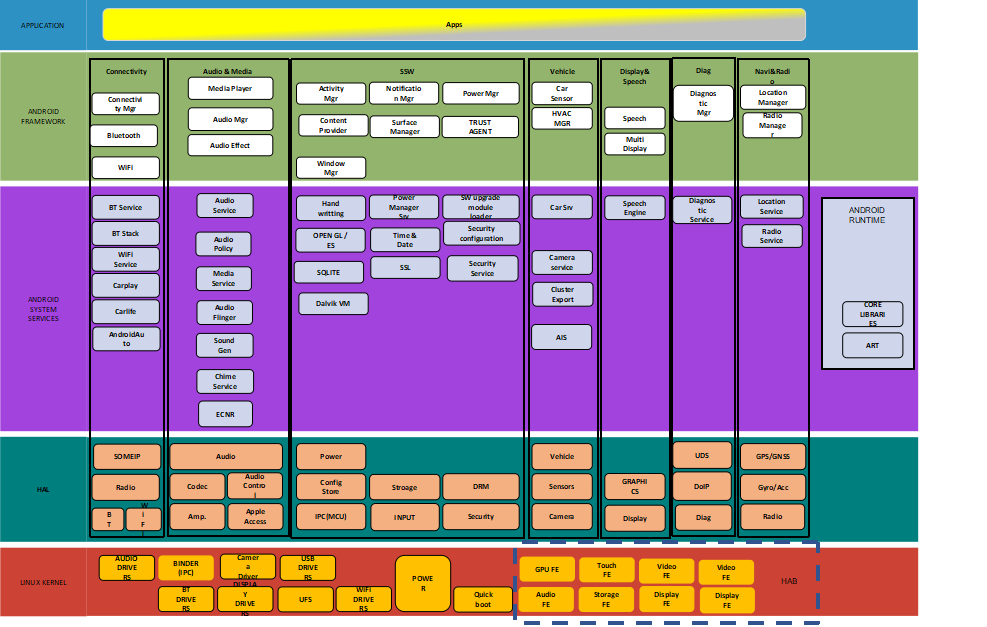
QNX软件主要分为如下几层:
应用层:主要运行仪表速度/转速/报警灯/快速RVC/动画等上层应用
架构层:主要运行图形处理/音频处理/网络管理/进程间通讯框架
服务层:主要运行进程间通讯,虚拟IO口的访问/音频服务/屏幕管理的逻辑
驱动层:负责屏幕串行解串/USB/摄像头等驱动调试
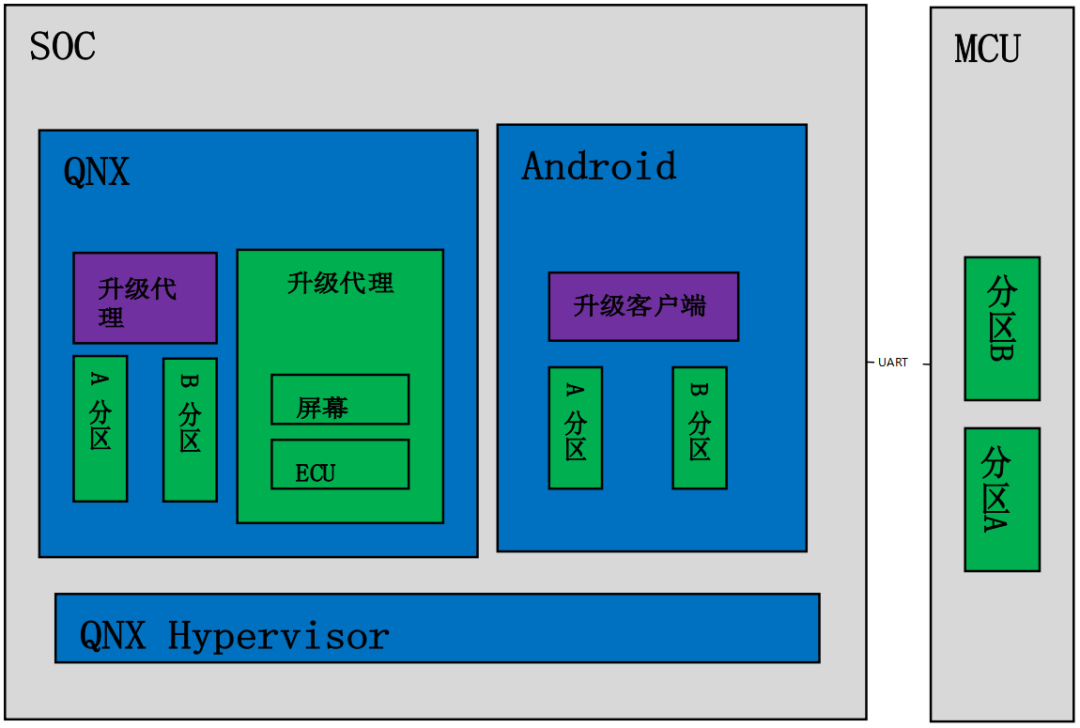
软件升级相关
支持A/B分区升级,在升级主机过程中不影响用户使用
支持集成车厂的FOTA方案,目前FOTA方案的集成一般包含两部分
升级客户端:与升级服务器交互,下载升级包,与后台的升级服务器同步主机版本信息。
升级代理:负责升级主机和MCU软件;可以通过DOIP协议发起刷新其他模块
支持对屏幕的升级
升级模块支持车厂的PKI策略集成,可以支持证书的生成和校验
视频输入相关
Camera 框架使用AIS框架,图像数据的采集在QNX端完成
Android端可以通过AIS框架获取到Camera图像数据,界面的处理需要靠图层叠加来完成
Camera的接口是CSI接口,每个CSI接口可以支持4个摄像头接入。不同高通平台的CSI接口数目不同
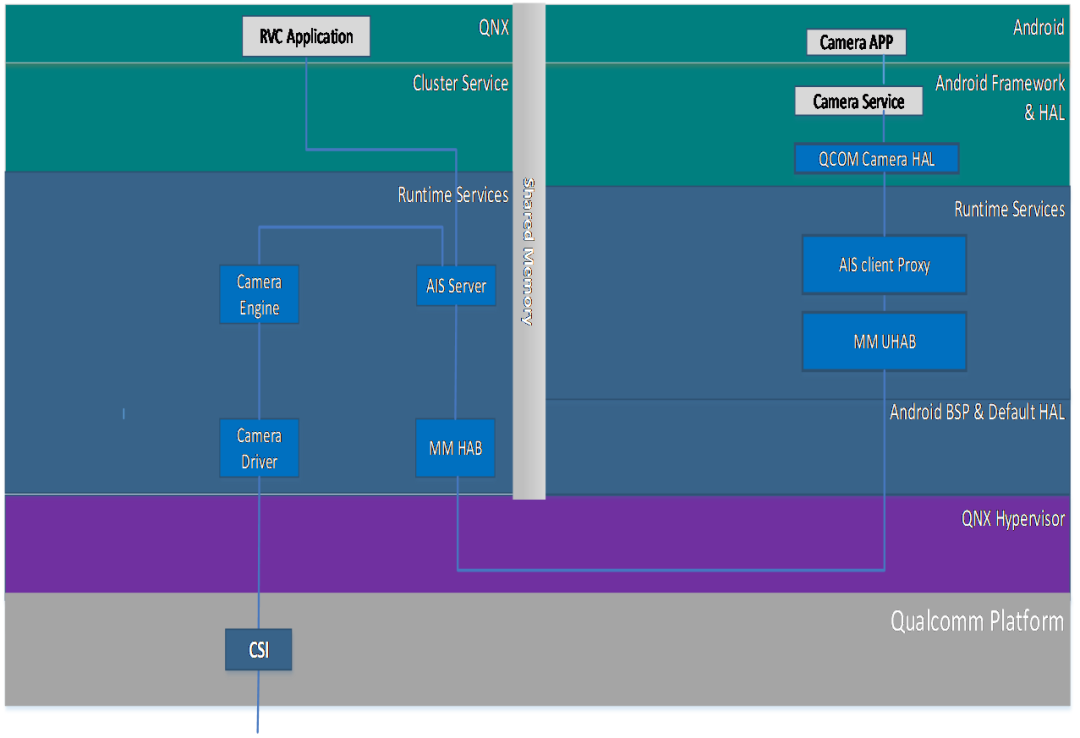
视频输出相关
屏幕的输出使用WFD框架
屏幕的输出接口控制在QNX端。Android端使用代理与QNX端通讯
屏幕的输出接口有DP和DSI两种,具体的接口数目不同的项目不一样
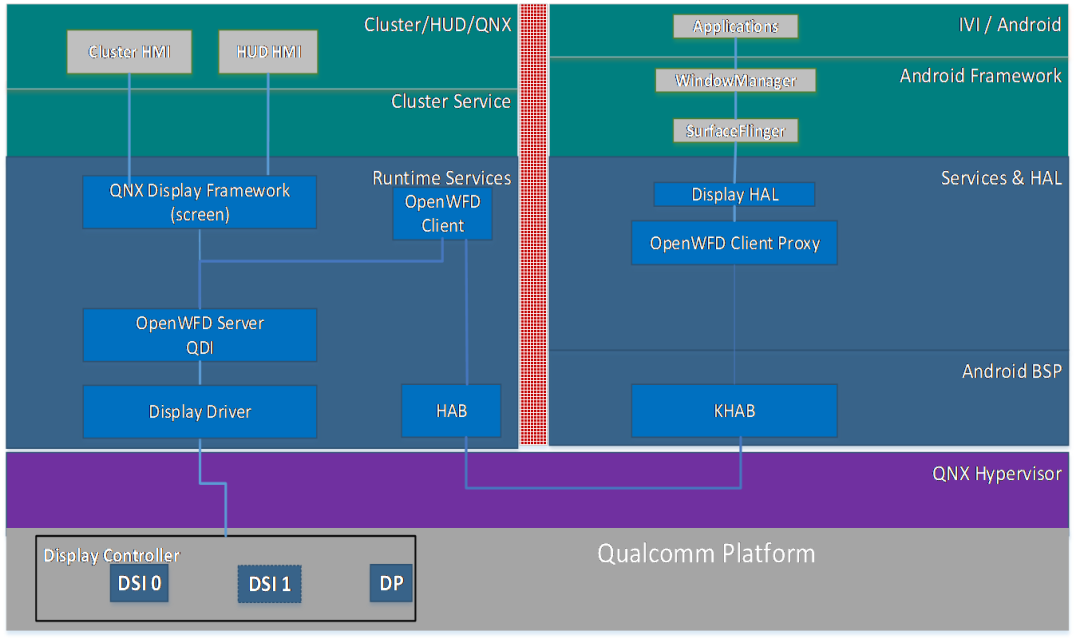
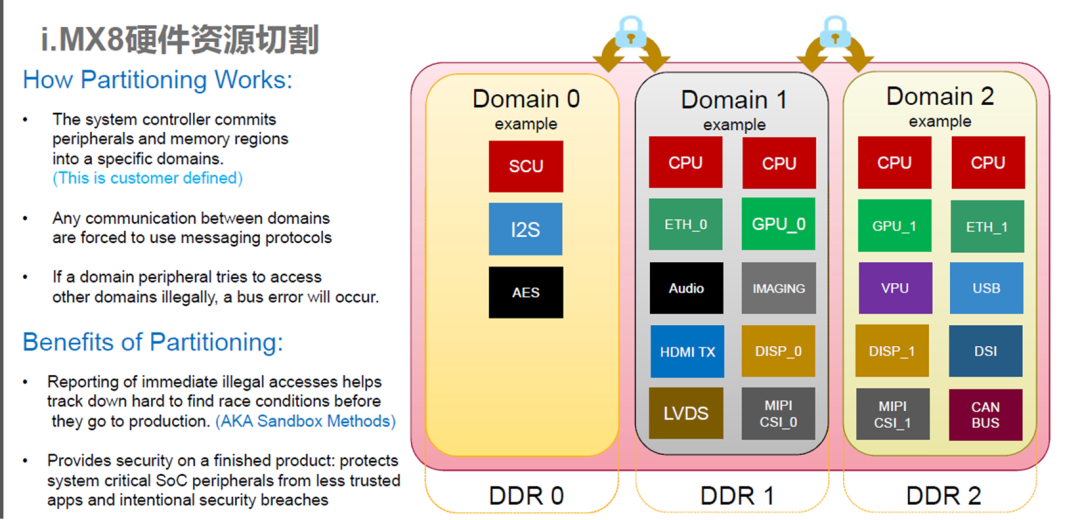
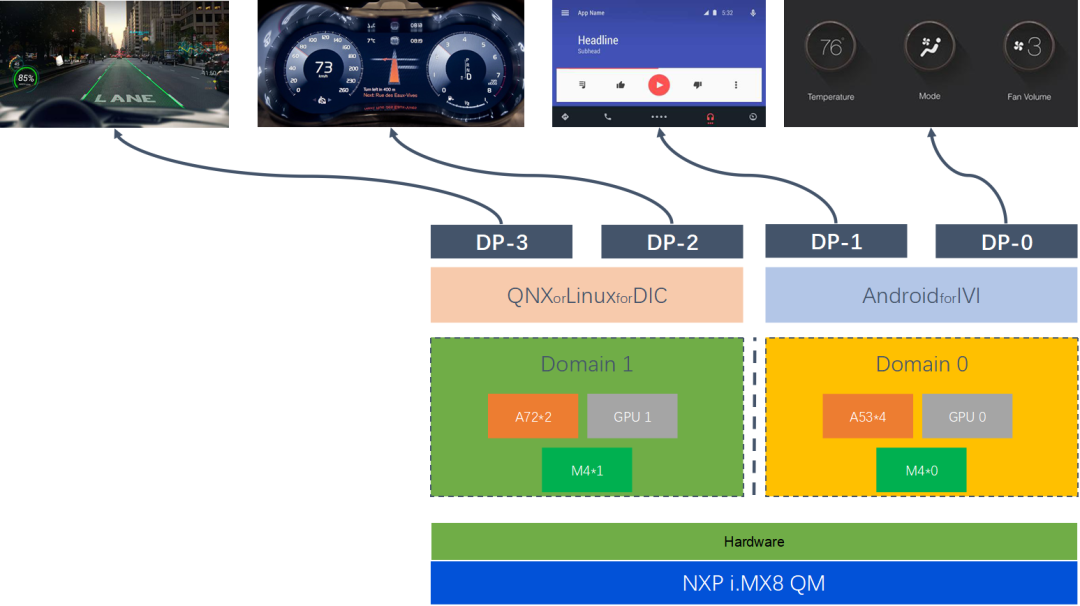
15、域控制器设计方案-NXP iMX8QM
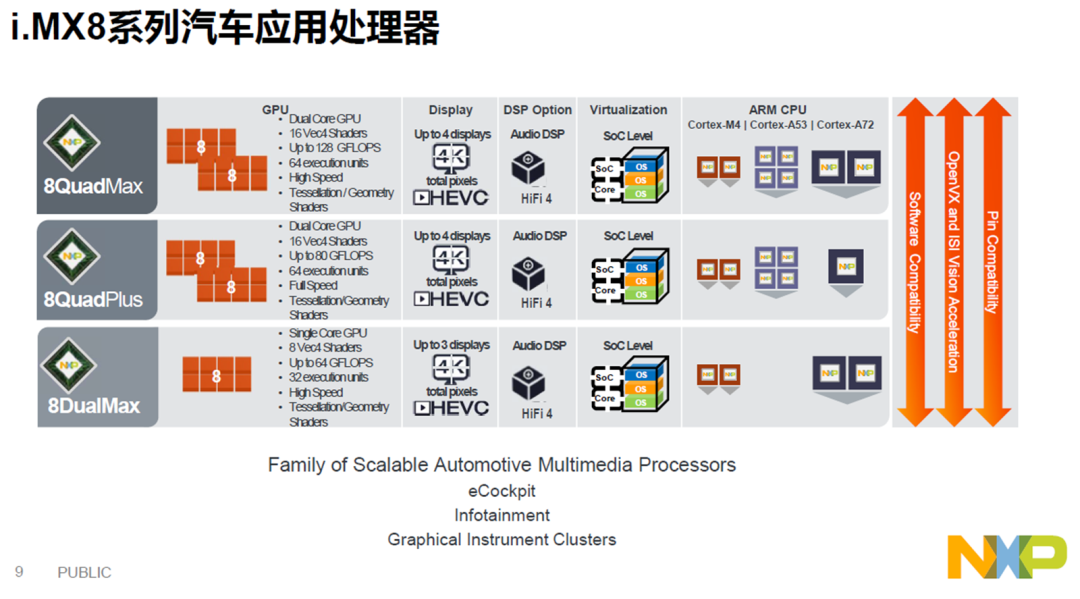
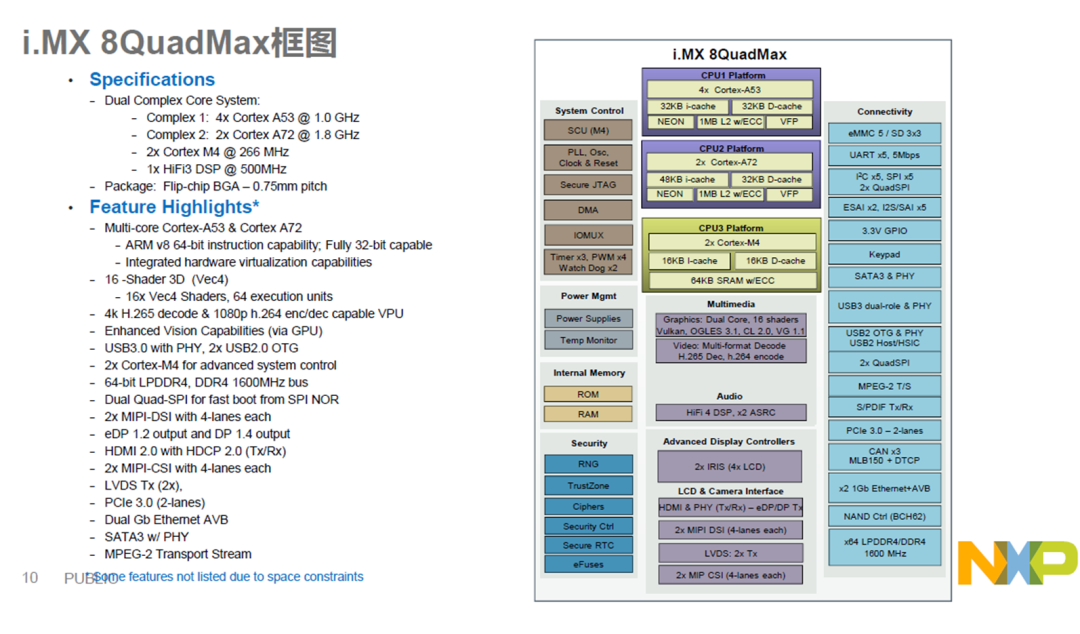
NXP座舱芯片的roadmap


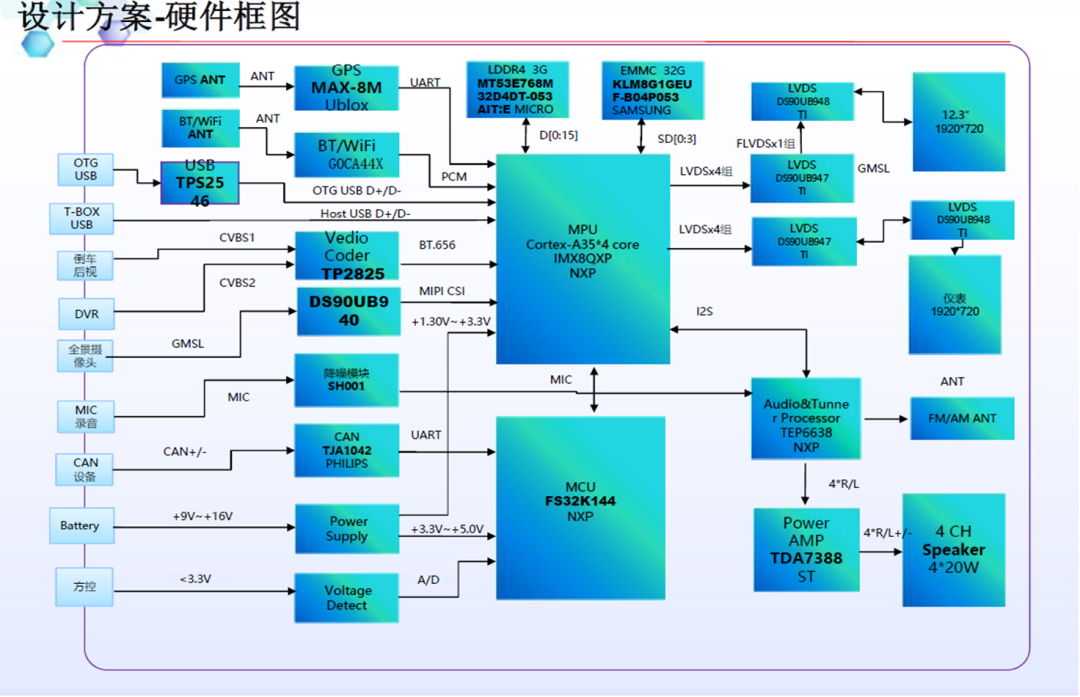
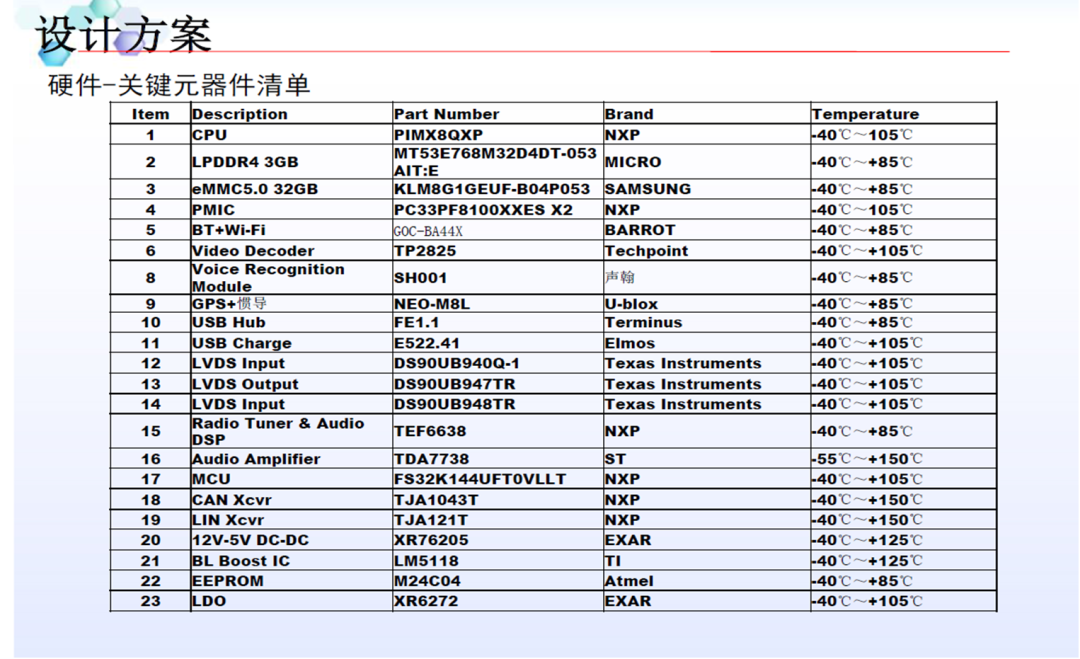
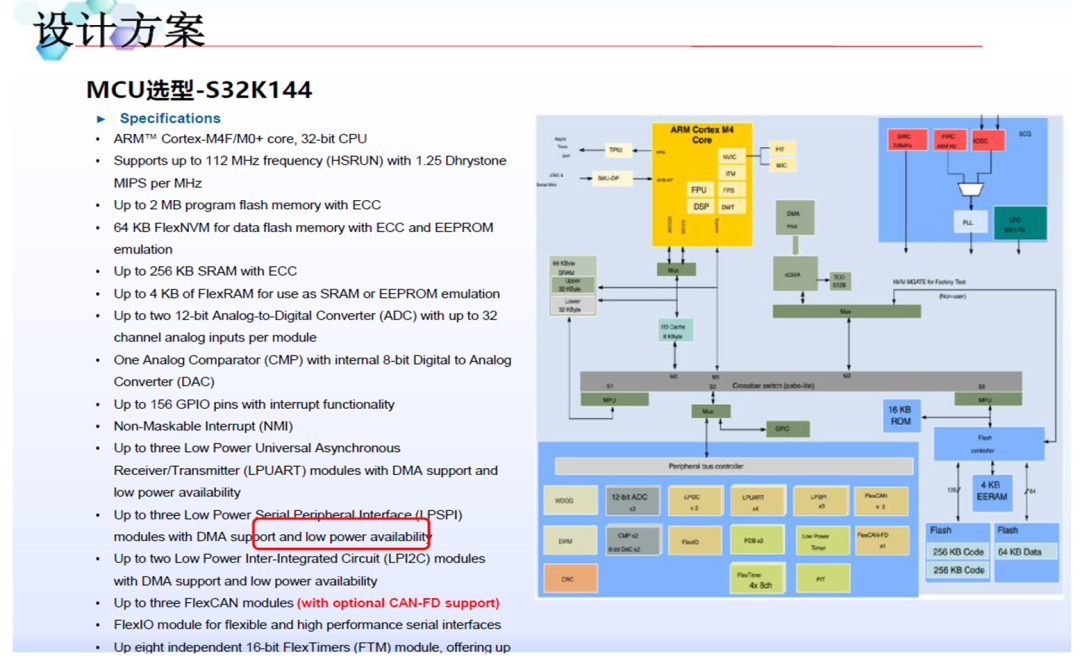
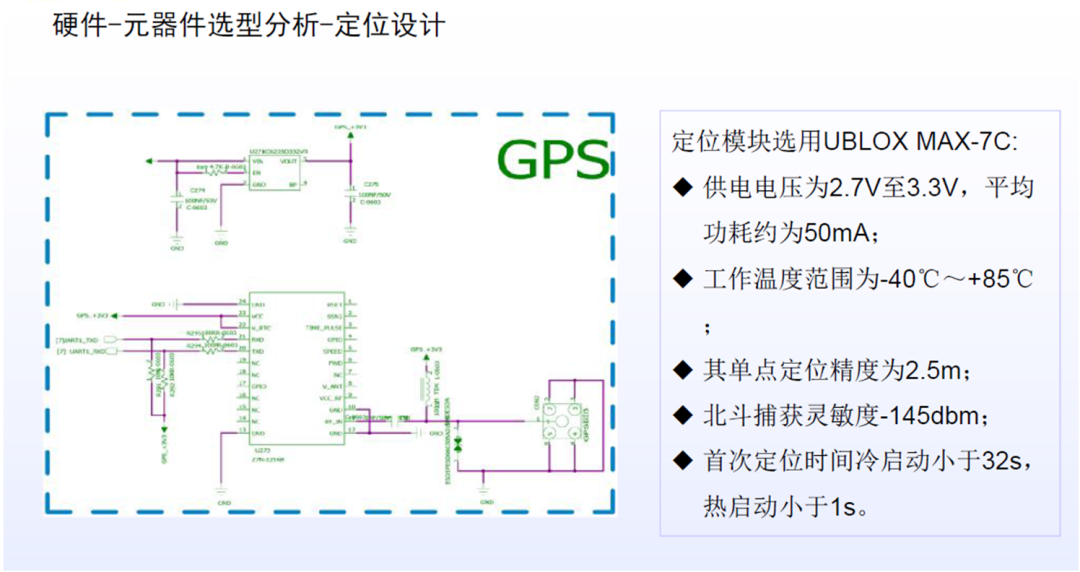

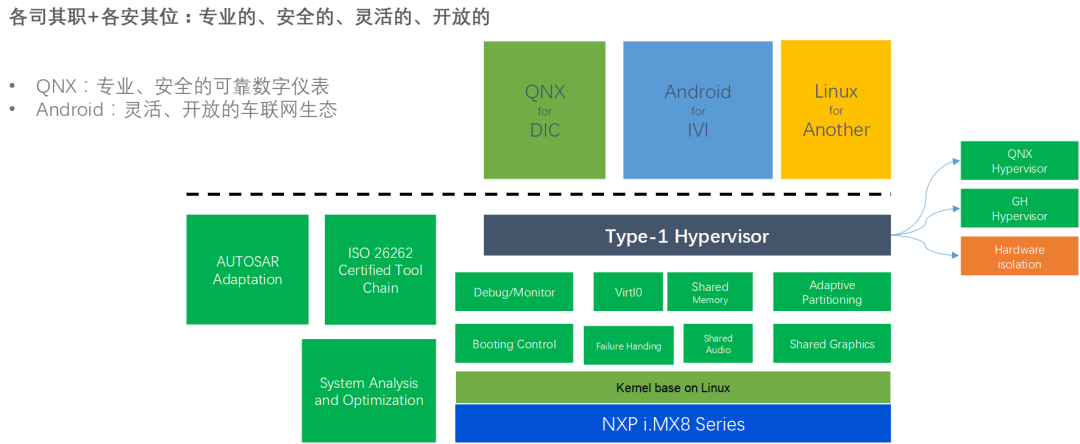

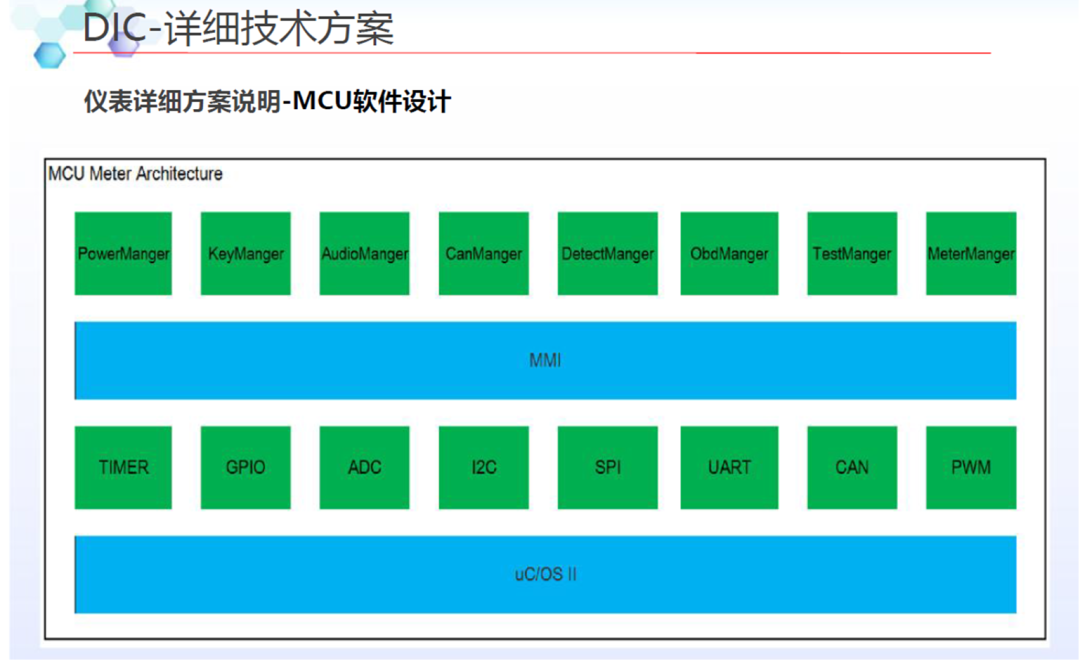
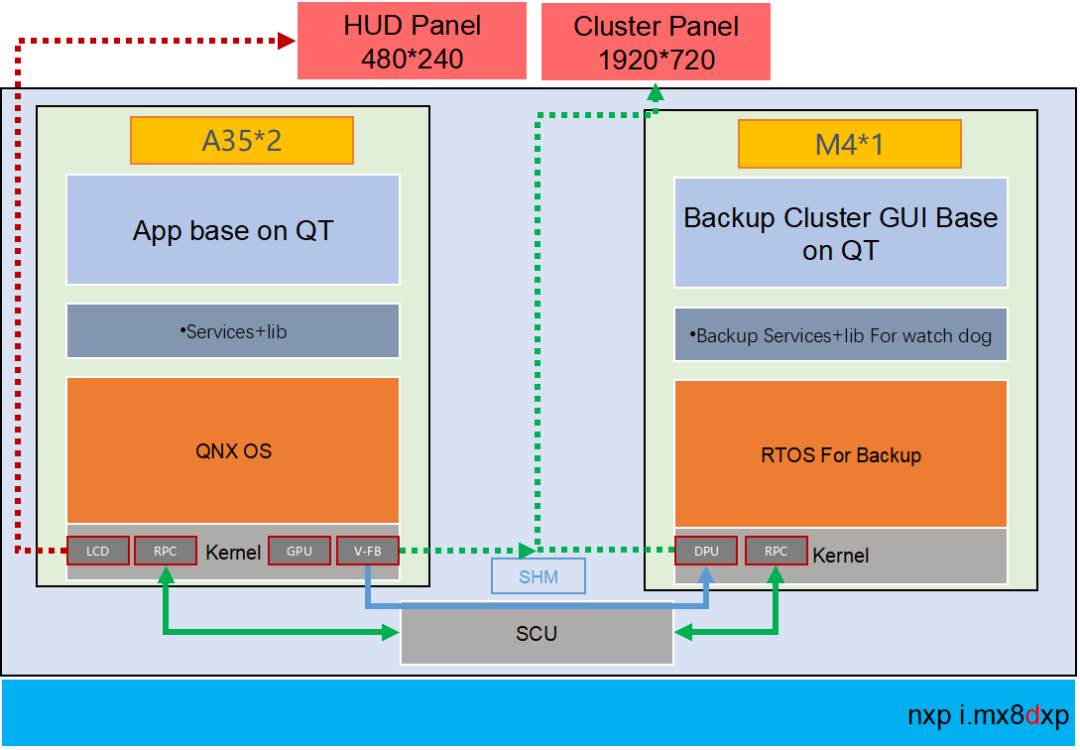
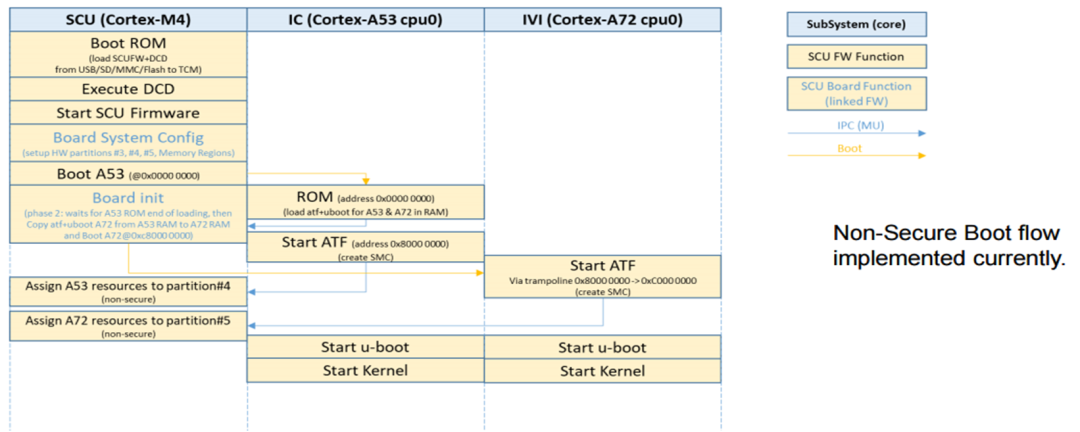
在新一代的iMX8QM和iMX8QXPBSP中,它实现了硬件分区以划分资源和内存区域。默认的Android Auto BSP给出了M4和A内核之间共享内存的示例,这被用于RPMSG。
2.在L4.14.78 GA1.0.0 BSP中,MU_5用于M4的FreeRTOS和A35 Linux之间的RPMSG,SC_R_MU_5B是M4端,而SC_R_MU_5A是A35端。用于A35与M4之间的相互唤醒。
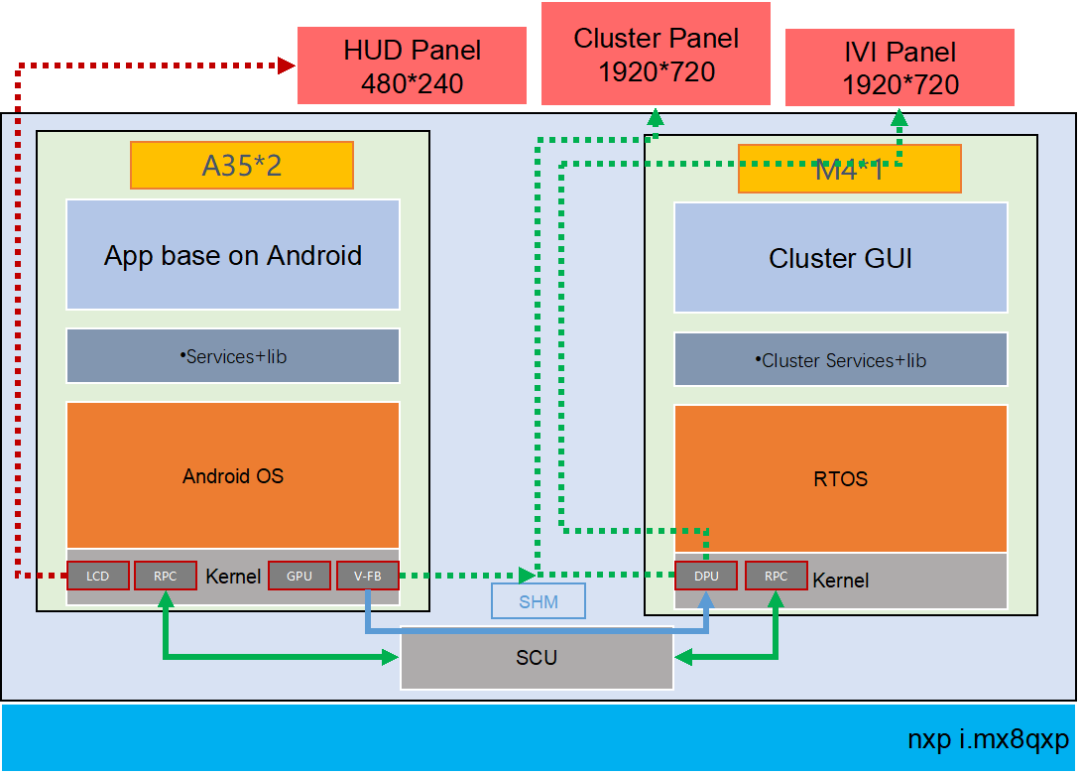
QNX基于A35运行;
QNX本身自有的图形监视子系统用于保证正常图形绘制的安全性以及可靠性;
借助QNX的微内核系统和分布式系统,可以动态加载和升级指定的驱动、应用、协议栈等,当有一个CPU失效时,剩余的CPU可以同时承担冗余工作和平衡负载的能力;
同时界面工具QT(或者KANZI)有完整的安全渲染机制(Qt Safe Renderer version 1.1.),通过工具所提供的安全渲染引擎(Safe Renderer Engin),能够对安全要求最高图层进行渲染(警告图标等等);
上述A35核本身借助符合ISO26262-ASIL-B的QNX+QT的工具集来保证系统和功能的安全性和稳定性
借助QNX的POSIX –API接口,与M4核进行通讯(SCU+PRC)
M核基于RTOS,M核端运行Watch dog;
实现由M核对A核的服务与消息机制的监管;
当A核出现彻底的失效或者需要软件重启的时候,提示相关的Warning等相关信息;?
建议:
QNX符合ASIL-B的显示子系统安全机制;
HMI图形工具QT的安全渲染机制,保证失效机制下的最高等级图层显示(FB0)。M4核是冗余设计出来的。

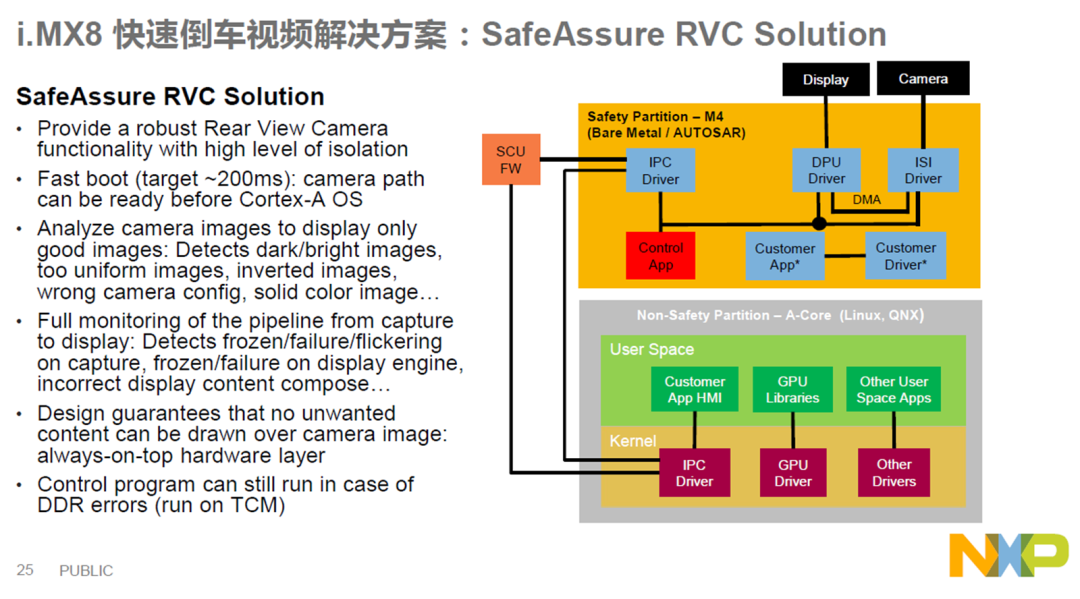
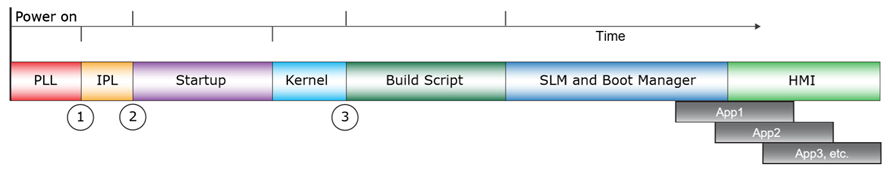
The QNX CAR platform boots in several stages, as illustrated in the following diagram:
QNX的安全启动流程参考如下:引用QNX Boot_Optimization_Guide
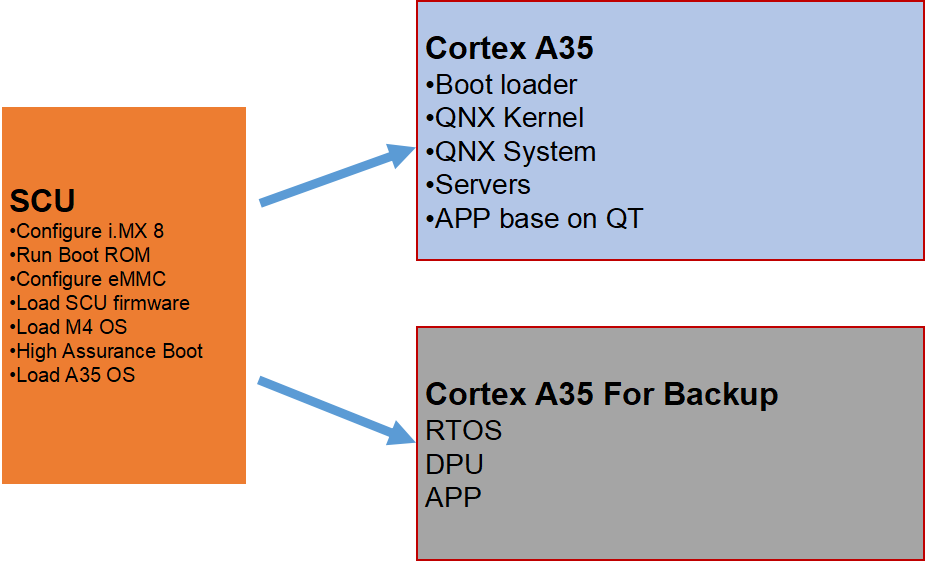
NXP的imx8芯片是基于硬件虚拟化设计实现,具有以下功能:
双系统独立启动,双系统为LINUX+ANDROID
崩溃检测
硬件资源划分
共享内存
使用NXP硬隔离方案,在两个Domain之间通过MU和Share Memory的方式进行信息通讯和数据共享
欢迎关注我的微信公众号:阿宝1990,每天给你汽车干货,我们始于车,但不止于车。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- python实现图像的二维傅里叶变换——冈萨雷斯数字图像处理
- 倚力未来:人工智能智能辅助医疗的前景与挑战
- 技术博客官网也是一个不错的学习平台(第411篇)
- C++使用HTTP库和框架轻松发送HTTP请求
- 七个Python可视化界面设计器简介(不是GUI库)
- Linux5.3、进程替换
- Windows 2012 R2 单网卡安装 PPTPVP*
- Unity 点击对话系统(含Demo)
- 集合类:List、Set、Map超详细讲解并附带代码块
- 【Linux】线程的概念理解,从感知理解到全面深入