string类详解
1.为什么要学习string
C语言中,字符串是以'\0'结尾的一些字符的集合,为了操作方便,C标准库中提供了一些str系列的库函数,但是这些库函数与字符串是分离开的,不太符合OOP的思想,而且底层空间需要用户自己管理,稍不留神可能还会越界访问。
2.标准库的string类
2.1string介绍
1. string是表示字符串的字符串类
2. 该类的接口与常规容器的接口基本相同,再添加了一些专门用来操作string的常规操作。
3. string在底层实际是:basic_string模板类的别名,typedef basic_string<char, char_traits, allocator> string;
4. 不能操作多字节或者变长字符的序列。
在使用string类时,必须包含#include头文件以及using namespace std;
2.2 string类的常用接口说明
2.2.1常见构造

例子如下:
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
using namespace std;
int main()
{
//string的常见构造函数
//1
string s1;
//2
string s2 = "abcde";
//3
string s3(5, 'x');
//4
string s4(s3);
}2.2.2. string类对象的容量操作
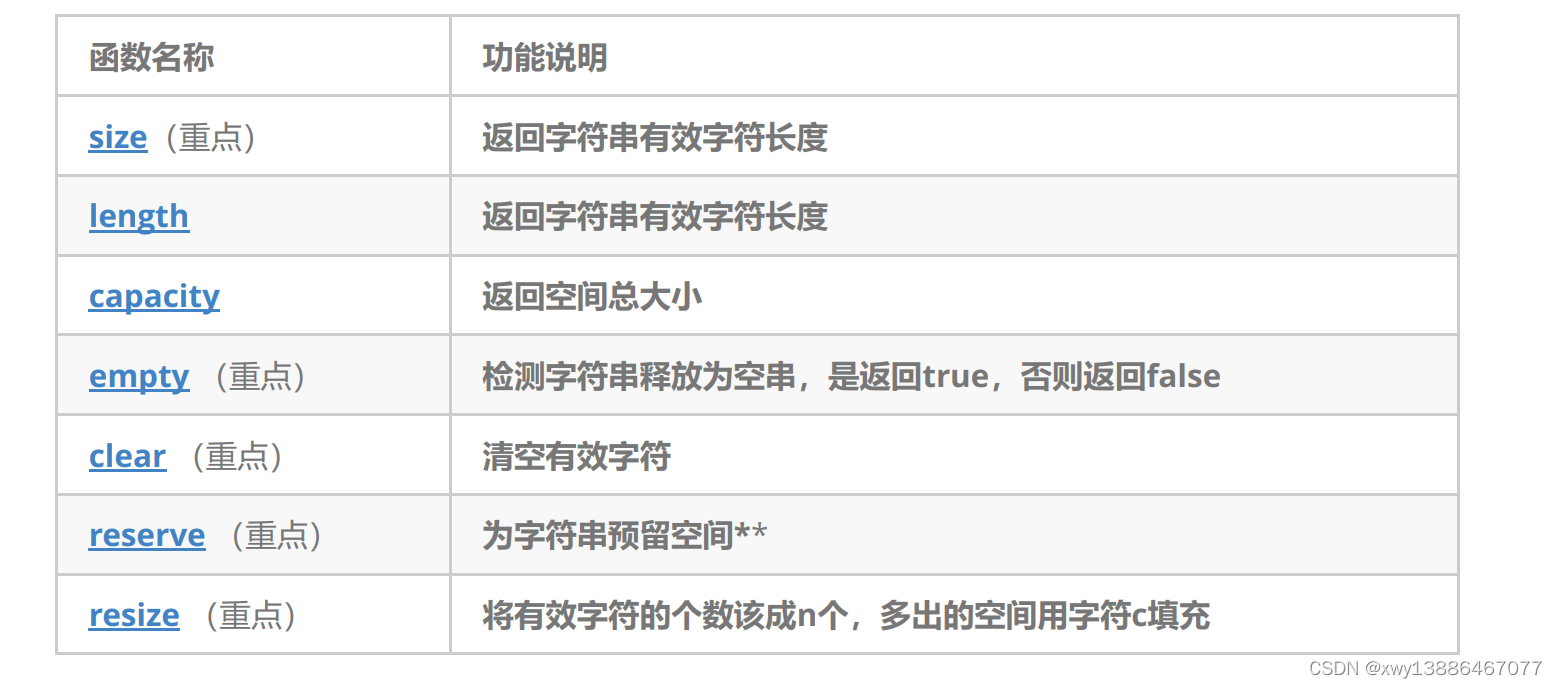
注意事项:
1. size()与length()方法底层实现原理完全相同,引入size()的原因是为了与其他容器的接口保持一
致,一般情况下基本都是用size()。size会显示有效字符个数,不包含最后的\0,capacity也是显示有效空间大小,不包含最后的\0.
2. clear()只是将string中有效字符清空,不改变底层空间大小。clear后size()变为0,capcity()不变。
3. resize(size_t n) 与 resize(size_t n, char c)都是将字符串中有效字符个数改变到n个,不同的是当字符个数增多时:resize(n)用0来填充多出的元素空间,resize(size_t n, char c)用字符c来填充多出的元素空间。
n>capacity:扩容加尾插,容量变大
size<n<capacity:尾插,容量不变
n<size:size变小,容量不变
4. reserve(size_t res_arg=0):为string预留空间,不改变有效元素个数,即为不改变size,当reserve的参数小于string的底层空间总大小时,reserver不会改变容量大小。
int main()
{
//string的常见构造函数
//1
string s1;
//2
string s2 = "abcde";
//3
string s3(5, 'x');
//4
string s4(s3);
//string容量和大小测试
cout <<"最开始s1的size: "<< s1.size() <<" 最开始s1的capacity:" << s1.capacity()<<endl;
s1.reserve(20);
cout << "reserve(20)后s1的size: " << s1.size() << " reserve(20)后s1的capacity:" << s1.capacity() << endl;
s1.resize(10);
cout << "resize(10)后s1的size: " << s1.size() << " resize(10)后s1的capacity:" << s1.capacity() << endl;
s1.clear();
cout << "clear后s1的size: " << s1.size() << " clear后s1的capacity:" << s1.capacity() << endl;
return 0;
}最后,以上代码的运行结果是:

2.2.3. string类对象的访问及遍历操作

上面的调用都重载了两个版本,一个是给const string对象使用的,不能修改s[i]的值,一个是给普通string对象用的,可以随意修改。
void test2()
{
string s1("abcdef");
s1[0] = 'g';
const string s2("ABCDEF"); // 报错
s2[0] = 'G';
}
上面代码中s2就是一个const对象,他的调用返回了const char的引用类型,因此不能修改,会报错,表中方法其余几个也是这样。
string中迭代器实际是一个char *的指针,在内部typedef一下。
如下:
class string
{
public:
typedef char* iterator;
typedef const char* const_iterator;
}而我们对其遍历操作如下:
string str = "hello word";
string::iterator it = str.begin();//得到一个指向首元素的指针
while (it != str.end())//str.end()得到一个指向'\0'的指针
{
cout << *it << endl;
it++;
}
// 顺序打印hello worldstr.begin返回一个指向字符串头的指针,end方法返回指向字符串结尾的/0的指针。
而反向遍历的方法如下:
string str = "hello word";
string::reverse_iterator it = str.rbegin();//得到一个指向最后一个有效元素的指针
while (it != str.rend())//str.rend()得到一个指向首元素前一个的指针
{
cout << *it << endl;
it++;
}
// 逆序打印hello world其需要用到反向迭代器,同时其++其实指针是往后走的。
而范围for中遍历:
string str = "hello word";
for (auto e : str)
{
cout << e << endl;
}
//顺序打印hello world范围for的底层是傻瓜式的替换这个代码为正向迭代器,然后进行正向迭代器的遍历。
2.2.4. string类对象的修改操作

其中前三个为一组,push_back可以往后面加一个字符,append可以加入字符串或者string类型,而我们常用的是+=,可以在字符串结尾加入单个字符或者字符串。
c_str是返回string的const char*形式,为了支持string到const char*的转换,在使用C语言的一些函数时候会更加的方便。
find匹配字符和字符串在原来string中出现的第一个位置,当找不到时返回-1. rfind则是从后往前查找,我们还可以传入参数pos指定从哪个位置开始往前查找
void test()
{
string s("abcdef");
size_t i = s.find("bcf");
cout << i << endl; //i为1,第二个位置完全匹配,返回第二个位置的下标
}substr(size_t pos = 0, size_t len = npos)返回一个新构造的字符串,第一个参数是开始位置,第二个参数是构造新字符串的长度。
2.2.5. string类非成员函数
前面三个都是运算符重载,我们可以便捷的使用string,getline是从缓冲区提取一行字符到string类型变量中,最后一个是==,!=,>这些运算符的重载,也比较简单。
2.2.6. vs和g++下string结构
下述结构是在32位平台下进行验证,32位平台下指针占4个字节
vs下string的结构:
string总共占28个字节,内部结构稍微复杂一点
先是一个虚基类指针:4个字节.
再是有一个联合体,联合体用来定义string中字符串的存储空间:当字符串长度小于15(数组尾部存储一个\0字符)时,使用内部固定的字符数组来存放当字符串长度大于等于16时,从堆上开辟空间。故其一共16个字节.
大多数情况下字符串的长度都小于16,那string对象创建好之后,内部已经有了16个字符数组的固定空间,不需要通过堆创建,效率高
union _Bxty
{ // storage for small buffer or pointer to larger one
value_type _Buf[_BUF_SIZE]; // 16字节缓冲区,当string长度小于15,用这个字符数组保存string
pointer _Ptr;
char _Alias[_BUF_SIZE]; // to permit aliasing
} _Bx;最后还有一个size_t字段保存字符串长度,一个size_t字段保存从堆上开辟空间总的容量。
一共就是4+16+4+4=28.,所以我们vs平台下我们sizeof一个string对象的大小是28
而g++下string的结构:
G++下,string是通过写时拷贝实现的,string对象总共占4个字节,内部只包含了一个指针,该指针将来指向一块堆空间,内部包含了如下字段:
1.空间总大小? ? ? ? 2.字符串有效长度? ? ? ? 3.引用计数 ????????4.指向堆空间的指针,用来存储字符串
struct _Rep_base
{
size_type _M_length;
size_type _M_capacity;
_Atomic_word _M_refcount;
};所以我们linux平台下gcc编译器我们sizeof一个string对象的大小是4.
还有一些关于string中拷贝的话题,等string模拟实现时再讲。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 张驰课堂:激发学员兴趣,打造六西格玛绿带培训的互动学习环境
- EAO-SLAM运行踩坑解决方案汇总
- 大容量磁盘parted分区,格式化及开机自动挂载
- 【教学类-43-20】20240113 数独(二)4宫格、9宫格 无空行A4模板
- DT浏览器浏览网页的技巧
- 计算机视觉(CV)技术的优势
- ECharts实现饼图径向渐变、线性渐变坐标计算
- SpringIOC之SimpleTimeZoneAwareLocaleContext
- 《数据结构》学习笔记
- Mac M1 Parallels Debian10 Install Gitlab