第六课:Prompt
文章目录
第六课:Prompt
1、学习总结:
Prompt介绍
- Fine-tuning Recap and its Drawbacks:
- Fine-tuning 指的是在一个已经预训练好的模型基础上,使用特定任务的数据进行额外的训练,以使模型适应该任务。
- Fine-tuning 的优点是能够在已有知识的基础上,更好地适应特定任务,提高性能。
- 缺点可能包括过度拟合(Overfitting):模型在训练数据上表现很好,但在新数据上的泛化能力较差。
- Prompt Learning Introduction:
- Prompt learning 涉及使用自然语言提示(prompt)来引导模型执行特定任务。
- 这种方法通常用于零样本学习,其中模型需要在没有大量示例的情况下执行任务。
- Prompt learning 的优势在于可以通过简洁的指令来完成复杂的任务,而无需大量标注的训练数据。
- 挑战可能包括设计合适的提示,以确保模型准确执行任务。

Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing
预训练和微调
模型回顾
- BERT
- bidirectional transformer,词语和句子级别的特征抽取,注重文本理解
- Pre-train: Maked Language Model + Next Sentence Prediction
- Fine-tune: 根据任务选取对应的representation(最后一层hidden state输出),放入线性层中
例:Natural Language Inference
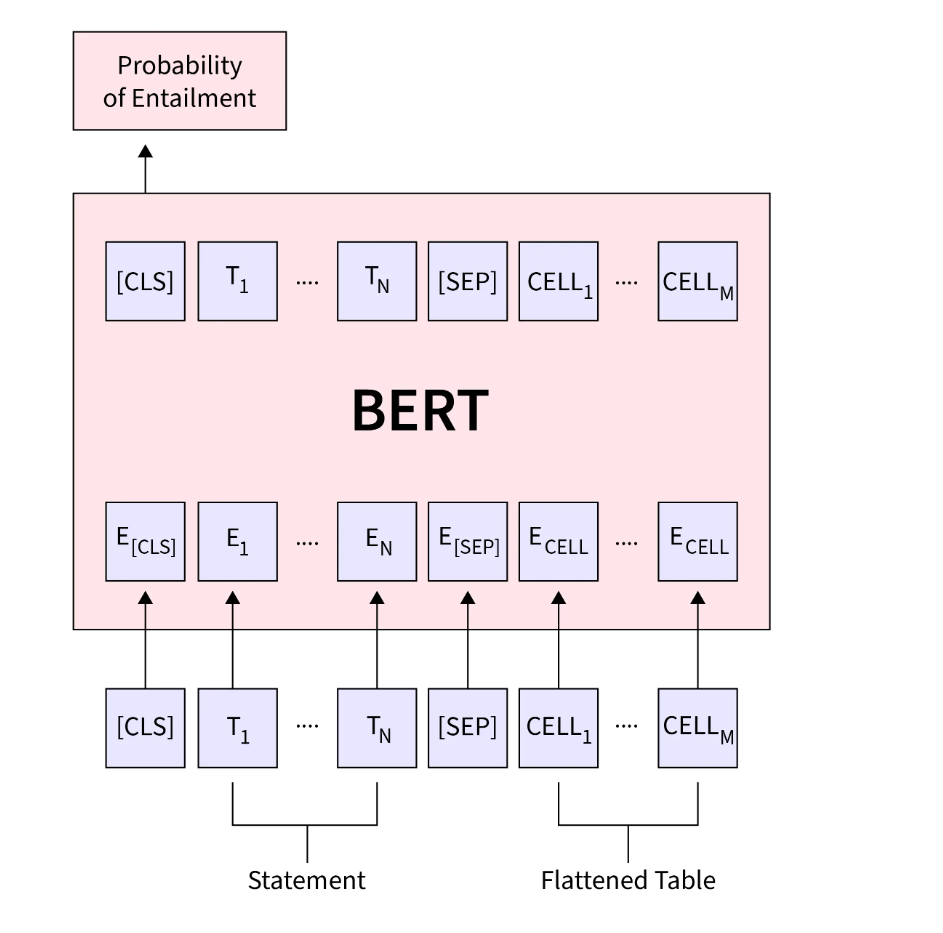
- GPT
- auto-regressive model,通过前序文本预测下一词汇,注重文本生成
- Pre-train: L 1 ( U ) = ∑ i log ? P ( u i ∣ u i ? k , … , u i ? 1 ; Θ ) L_1(\mathcal{U})=\sum_i \log P\left(u_i \mid u_{i-k}, \ldots, u_{i-1} ; \Theta\right) L1?(U)=∑i?logP(ui?∣ui?k?,…,ui?1?;Θ)
- Fine-tune: task-specific input transformations + fully-connected layer

挑战
- 少样本学习能力差、容易过拟合

- 微调上的损失较大
现在的预训练模型参数量越来越大,为了一个特定的任务去 finetuning 一个模型,然后部署于线上业务,也会造成部署资源的极大浪费
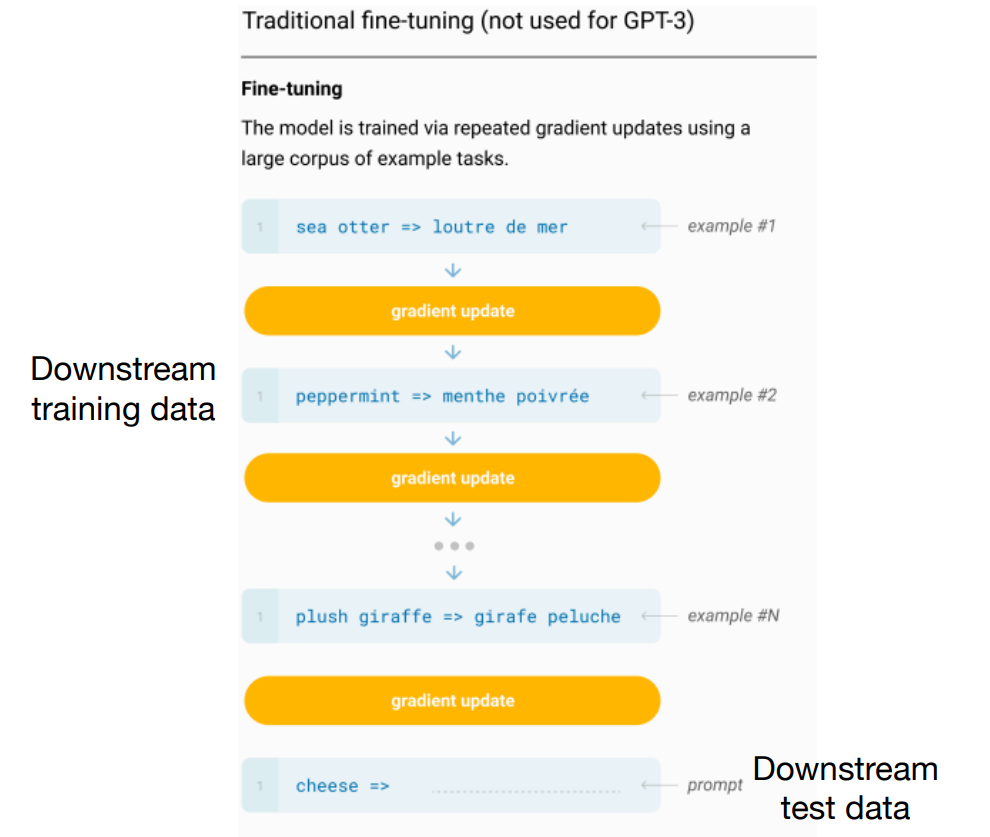
Pre-train, Prompt, Predict
Prompting是什么?
- Prompting是一种利用自然语言提示来引导模型执行特定任务的方法。通过为模型提供简短的任务描述,模型能够理解并生成相应的输出。
- Fine-tuning通过改变模型结构或调整参数,使其适应下游任务。这包括在预训练模型的基础上,使用特定任务的数据进行额外的训练,以提高性能。
- Prompt Learning是一种方法,其中模型结构保持不变,而是通过重新构建任务描述(prompt)来使下游任务适配模型。这可以用于零样本学习或在有限数据情况下进行任务适应。
- Zero-shot Learning
零样本学习是一种模型在没有任何先前示例的情况下执行任务的方法。模型通过提示或任务描述来学习如何处理没有先验训练数据的新任务。
- One-shot Learning
一样本学习是指模型通过很少量的示例(通常是一个样本)来学会执行任务。这可以通过提示来实现,使模型能够从有限的数据中学到新任务。
- Few-shot Learning
少样本学习是介于零样本学习和传统的训练方法之间。模型通过少量的示例(通常是少于常规训练所需的数量)进行学习,以适应新任务。
prompting流程
- Template: 根据任务设计prompt模板,其中包含 input slot[X] 和 answer slot [Z],后根据模板在 input slot 中填入输入
- Mapping (Verbalizer): 将输出的预测结果映射回label

prompt设计
Prompting 中最主要的两个部分为 template 与 verbalizer 的设计。
他们可以分别基于任务类型和预训练模型选择(shape)或生成方式(huamn effort)进行分类。
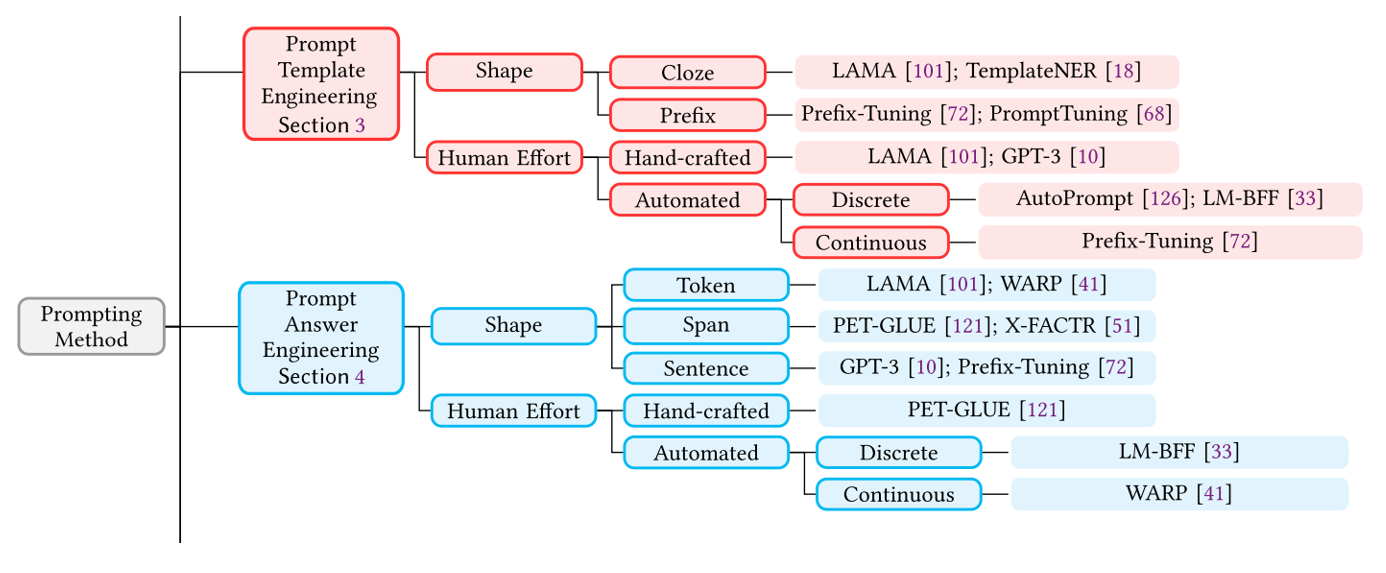
课程ppt及代码地址
2、学习心得:
? 通过本次学习,更加熟悉了华为Mindspore这个国产深度学习框架,同时也对Prompt学习有所了解,后面又通过GPT-2预训练模型的prompt learning来完成情感分类任务,更加加深了对Prompt学习的理解,
3、经验分享:
? 在启智openI上的npu跑时记得使用mindspore1.7的镜像,同时安装对应mindnlp的版本,不然可能会因为版本不兼容而报错。另外就是给出的代码示例都要跑一跑,结合视频去加深理解。
4、课程反馈:
? 本次课程中的代码串讲我觉得是做的最好的地方,没有照着ppt一直念,而是在jupyter lab上把代码和原理结合到一块进行讲解,让学习者对代码的理解更加深入。我觉得内容的最后可以稍微推荐一下与Mindspore大模型相关的套件,让学习者在相关套件上可以开发出更多好玩和有趣的东西!
5、使用MindSpore昇思的体验和反馈:
MindSpore昇思的优点和喜欢的方面:
- 灵活性和可扩展性: MindSpore提供了灵活的编程模型,支持静态计算图和动态计算图。这种设计使得它适用于多种类型的机器学习和深度学习任务,并且具有一定的可扩展性。
- 跨平台支持: MindSpore支持多种硬件平台,包括CPU、GPU和NPU等,这使得它具有在不同设备上运行的能力,并能充分利用各种硬件加速。
- 自动并行和分布式训练: MindSpore提供了自动并行和分布式训练的功能,使得用户可以更轻松地处理大规模数据和模型,并更高效地进行训练。
- 生态系统和社区支持: MindSpore致力于建立开放的生态系统,并鼓励社区贡献,这对于一个开源框架来说非常重要,能够帮助用户更好地学习和解决问题。
一些建议和改进方面:
- 文档和教程的改进: 文档和教程并不是很详细,希望能够提供更多实用的示例、详细的文档和教程,以帮助用户更快速地上手和解决问题。
- 更多的应用场景示例: 提供更多真实场景的示例代码和应用案例,可以帮助用户更好地了解如何在实际项目中应用MindSpore。
6、未来展望:
? 大模型的内容还是很多的,希望自己能坚持打卡,将后面的内容都学习完,并做出一些有趣好玩的东西来!最近准备尝试做做社区大模型相关的代码迁移+精度验证任务了,希望能够学以致用,提高自己的技术水平!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 剑指YOLOv8独家原创改进:即插即用|原创新颖共享Sep检测头ShareSepHead,更省参数量,更高效,打造新型YOLOv8检测器,精度高效涨点
- 针对远程40G网络的DWDM解决方案
- 京东tp26旋转验证
- Airtest-Selenium实操小课:爬取新榜数据
- vue2移动端网页图片触摸滑动改变top和left以及双指对图片进行缩放
- 可免费下载的 10 款安卓手机数据恢复软件
- java实现时间轮算法
- 基于遗传算法改进的核极限学习机轴间偏离预测,基于ELM的轴间偏离预测,基于极限学习机的轴故障分类
- less基础介绍
- windows 部署zlm