XML解析神器:Apache Commons Digester

第1章:引言
大家好,我是小黑。今天咱们聊聊一个在现代编程中经常遇到的话题:XML解析。你可能知道,XML(可扩展标记语言)因其灵活性和可读性,在配置文件、数据交换等方面广泛使用。但是,XML解析有时候会让人头疼,尤其是当文件结构复杂或者数据量巨大时。这时候,一个好用的工具就显得尤为重要了。
在Java世界里,有很多工具可以用来解析XML,比如JAXP, JAXB, DOM4J等。但今天咱们要讨论的是Apache Commons Digester。为什么选择它呢?因为它既简单又强大,非常适合那些想要快速而又不失灵活性处理XML的场景。Commons Digester通过定义一系列的规则来解析XML,让整个过程变得直观且容易控制。这样一来,咱们就可以专注于业务逻辑,而不是被繁琐的XML解析细节困扰。
第2章:什么是Commons Digester?
先来简单介绍一下Apache Commons Digester。这是一个开源的Java库,属于Apache Commons项目的一部分。Commons Digester的设计初衷是简化XML到Java对象的映射过程。简单地说,它可以将XML文档转换成Java对象,而且这个过程完全基于你定义的规则。
那这个过程是怎样的呢?其实,Commons Digester工作原理非常直观。它读取XML文档,根据你提前定义的一组规则,触发相应的操作。这些操作通常包括创建对象、调用方法、设置属性等。通过这种方式,XML文档中的数据就被有效地映射到了Java对象上。
这听起来可能有点抽象,别急,咱们来看一个简单的例子。假设有这样一个XML文件:
<Person>
<Name>张三</Name>
<Age>30</Age>
</Person>
咱们想要将这个XML映射到一个Java的Person类上。这个类大概长这样:
public class Person {
private String name;
private int age;
// 省略构造函数、getter和setter方法
}
要实现这个映射,你只需要定义相应的规则即可。Commons Digester让这个过程变得异常简单。在后续的章节里,小黑会带大家一步步学习如何定义这些规则,并且掌握Commons Digester的使用技巧。
第3章:依赖配置
要使用Commons Digester,你的项目需要能够访问到它的库文件。如果你的项目是基于Maven的,那就简单多了。只需要在项目的pom.xml文件中添加相应的依赖即可。这里是一个标准的依赖配置示例:
<dependencies>
<!-- 添加Apache Commons Digester依赖 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-digester3</artifactId>
<version>3.2</version> <!-- 这里写上最新的版本号 -->
</dependency>
</dependencies>
添加完依赖后,Maven会自动下载并添加Commons Digester到你的项目中。这样一来,咱们就可以在代码里自由地使用它了。
第4章:理解XML解析的基础
XML(可扩展标记语言)是一种用于存储和传输数据的标记语言。它类似于HTML,但更加灵活,因为你可以自定义标签。XML被广泛用于配置文件、网络数据交换等场景。了解如何解析XML,对于一个Java开发者来说非常重要。
那么,XML解析到底是什么呢?简单来说,就是将XML文档转换成程序可以理解和操作的格式,比如Java对象。这个过程中,最核心的就是理解XML文档的结构。
来,咱们看一个XML的示例:
<Book>
<Title>Java编程思想</Title>
<Author>张三</Author>
<Price>99</Price>
</Book>
这是一个描述书籍信息的XML。它有一个根元素<Book>,里面包含了三个子元素:<Title>, <Author>, 和<Price>。
在Java中,要解析这样的XML,你可能会想到创建一个对应的Book类:
public class Book {
private String title;
private String author;
private int price;
// getter和setter方法省略
}
现在,咱们的任务就是将XML中的数据读取出来,填充到这个Book类的实例中。听起来是不是有点像魔法?但其实原理并不复杂。
XML解析通常有两种方式:DOM解析和SAX解析。DOM解析会将整个XML文档加载到内存中,形成一个树状结构。这样做的好处是可以随机访问文档的任何部分,但缺点是消耗内存较大。SAX解析则是顺序读取XML文档,边读边解析,内存消耗小,但不能随机访问。
Commons Digester提供了一种更加灵活的解析方式。它允许你定义一系列的规则,然后在解析XML文档时,根据这些规则来创建和填充Java对象。这种方式既节省内存,又相对直观。
第5章:Commons Digester的核心组件
Commons Digester的核心是Digester类。这个类是整个库的灵魂,负责读取XML文档,并根据定义的规则来操作XML数据。听起来很神奇对吧?别急,咱们来看看具体是怎么回事。
创建Digester实例
在开始解析XML之前,咱们首先需要创建一个Digester实例。这个过程非常简单:
Digester digester = new Digester();
有了这个实例,咱们就可以开始定义一些规则,告诉Digester如何从XML中提取数据,并将这些数据映射到Java对象中。
定义解析规则
这里是Commons Digester真正强大的地方。你可以定义各种各样的规则来指导解析过程。比如,咱们有这样一个XML:
<Person>
<Name>李四</Name>
<Age>25</Age>
</Person>
咱们想将这个XML解析到一个Person类的实例中。这个类可能长这样:
public class Person {
private String name;
private int age;
// getter和setter方法省略
}
为了完成这个映射,咱们需要定义一些规则:
// 创建Digester实例
Digester digester = new Digester();
// 当遇到<Person>标签时,创建一个Person类的实例
digester.addObjectCreate("Person", Person.class);
// 当遇到<Person>标签内的<Name>标签时,将其内容设置到Person实例的name属性上
digester.addBeanPropertySetter("Person/Name", "name");
// 同理,处理<Age>标签
digester.addBeanPropertySetter("Person/Age", "age");
这样,当Digester解析到<Person>标签时,它就会创建一个Person实例。然后,遇到<Name>和<Age>标签时,它会将这些标签的内容分别设置到Person实例的name和age属性上。
解析XML
定义好规则后,剩下的就是让Digester解析XML了。这个过程也很直接:
Person person = digester.parse(new StringReader(xmlString));
这里,xmlString就是包含XML内容的字符串。parse方法会根据前面定义的规则,解析这个字符串,并返回一个填充好数据的Person实例。
通过这些步骤,咱们就可以轻松地将XML数据映射到Java对象中了。看起来是不是很酷?但别忘了,这只是Commons Digester的冰山一角。它还有很多强大的功能等着咱们去探索。
第6章:实战演练:解析XML示例
假设咱们有这样一个XML文件,它描述了一本书的信息:
<Book>
<Title>Java编程指南</Title>
<Author>王五</Author>
<Price>88</Price>
</Book>
咱们的任务是把这个XML文件中的数据解析到一个Java对象中。首先,咱们需要定义一个对应的Java类:
public class Book {
private String title;
private String author;
private int price;
// getter和setter方法省略
}
接下来,就是使用Commons Digester来解析XML并填充这个Book类的实例了。
步骤1:创建Digester实例
Digester digester = new Digester();
步骤2:定义解析规则
咱们需要告诉Digester,当遇到哪些XML元素时,应该执行什么操作:
// 当遇到<Book>标签时,创建一个Book类的实例
digester.addObjectCreate("Book", Book.class);
// 当遇到<Book>下的<Title>标签时,将其内容设置到Book实例的title属性上
digester.addBeanPropertySetter("Book/Title", "title");
// 对<Author>和<Price>标签做同样的操作
digester.addBeanPropertySetter("Book/Author", "author");
digester.addBeanPropertySetter("Book/Price", "price");
这样,Digester就知道了如何根据XML元素来创建和填充Book对象。
步骤3:解析XML
最后,咱们来解析XML文件:
try {
Book book = digester.parse(new StringReader(xmlString));
// 这里的xmlString是包含上面XML内容的字符串
// 输出解析结果,检查是否正确
System.out.println("书名: " + book.getTitle());
System.out.println("作者: " + book.getAuthor());
System.out.println("价格: " + book.getPrice() + "元");
} catch (IOException | SAXException e) {
e.printStackTrace();
}
这个过程中,如果一切顺利,你会看到控制台输出了解析后的书籍信息。
通过这个实例,咱们可以看到,Commons Digester的确是一个非常强大且灵活的工具。它能够轻松地将XML文档中的数据映射到Java对象中,大大简化了XML处理的复杂性。
第7章:高级功能和技巧
条件解析
在一些复杂的场景中,咱们可能只想在满足特定条件时才解析某些部分的XML。Commons Digester提供了条件解析的功能,让这成为可能。
比如,假设咱们有一个包含多本书籍信息的XML,但只想解析价格超过100元的书:
<Library>
<Book>
<Title>Java编程指南</Title>
<Author>王五</Author>
<Price>88</Price>
</Book>
<Book>
<Title>高级Java技术</Title>
<Author>赵六</Author>
<Price>120</Price>
</Book>
<!-- 更多书籍... -->
</Library>
咱们可以使用Rule类和它的子类来定义更复杂的解析规则。例如:
digester.addRule("Library/Book", new Rule() {
@Override
public void begin(String namespace, String name, Attributes attributes) throws Exception {
// 只有当书的价格大于100时,才创建Book对象
if (Integer.parseInt(attributes.getValue("Price")) > 100) {
Book book = new Book();
digester.push(book);
}
}
});
// 其他规则定义...
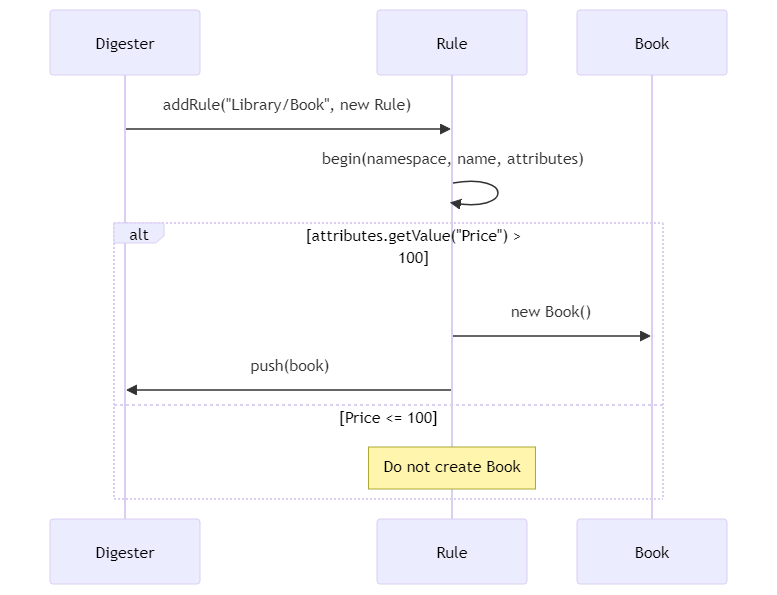
这样,只有价格超过100元的书才会被解析和创建。
使用XPath
有时候,XML结构可能非常复杂,使用传统的路径可能不够灵活。这时,XPath就能大放异彩了。Commons Digester支持XPath表达式,让你能够更精确地定位XML中的元素。
假设咱们的XML结构如下:
<Library>
<Section name="编程">
<Book>
<Title>Java编程指南</Title>
<!-- 省略其他信息 -->
</Book>
<!-- 更多书籍... -->
</Section>
<Section name="设计">
<!-- 设计相关的书籍... -->
</Section>
</Library>
如果咱们只想解析“编程”部分的书籍,可以这样使用XPath:
digester.addObjectCreate("/Library/Section[@name='编程']/Book", Book.class);
// 其他规则定义...
这样,只有位于“编程”部分的书籍才会被解析。
实用技巧和最佳实践
-
日志记录:在解析XML时,使用日志记录可以帮助你更好地调试和跟踪解析过程。确保你的项目中有配置日志系统。
-
异常处理:当解析XML时,可能会遇到各种异常。确保你的代码能够妥善处理这些异常,避免程序崩溃。
-
性能考虑:如果你正在处理非常大的XML文件,注意监控内存和性能。在可能的情况下,考虑使用流式解析。
-
规则复用:如果你在多个地方使用了类似的解析规则,考虑创建通用的规则类,以提高代码的复用性和清晰度。
第8章:XPath表达式
XPath是一种在XML文档中查找信息的语言,它可以用来定位和处理XML文档中的数据。当你的XML结构变得复杂,或者需要更精确的查询时,XPath就显得尤为重要了。
XPath表达式简介
XPath的全称是XML Path Language,即XML路径语言。它使用路径表达式来选取XML文档中的节点或节点集。这些路径表达式看起来有点像文件系统的路径,但用于定位XML文档中的元素。
基本的XPath语法
-
选取节点:XPath使用路径表达式来选取XML文档中的节点或节点集。比如,
/Bookstore/Book会选取根元素为Bookstore下所有的Book节点。 -
谓词:谓词用于查找特定的节点或包含特定值的节点。例如,
/Bookstore/Book[1]选取Bookstore下的第一个Book节点。 -
属性选择:可以使用
@符号选取属性。例如,/Bookstore/Book[@category='fiction']选取所有category属性为fiction的Book节点。 -
通配符:星号
*是一个通配符,匹配任何元素节点。例如,/Bookstore/*选取Bookstore下的所有子节点。
XPath与Java
在Java中使用XPath,你需要借助一些工具,比如Java的XPath API。让我们通过一个例子来看看如何在Java中使用XPath。
假设有这样一个XML:
<Bookstore>
<Book category="fiction">
<Title>哈利波特</Title>
<Author>JK.罗琳</Author>
<Price>68</Price>
</Book>
<Book category="education">
<Title>Java编程思想</Title>
<Author>Bruce Eckel</Author>
<Price>88</Price>
</Book>
<!-- 更多书籍... -->
</Bookstore>
如果我们想要选取所有类别为fiction的书籍标题,可以这样做:
XPathFactory xpathFactory = XPathFactory.newInstance();
XPath xpath = xpathFactory.newXPath();
String expression = "/Bookstore/Book[@category='fiction']/Title";
InputSource inputSource = new InputSource(new StringReader(xmlString));
NodeList nodes = (NodeList) xpath.evaluate(expression, inputSource, XPathConstants.NODESET);
for (int i = 0; i < nodes.getLength(); i++) {
System.out.println(nodes.item(i).getTextContent());
}
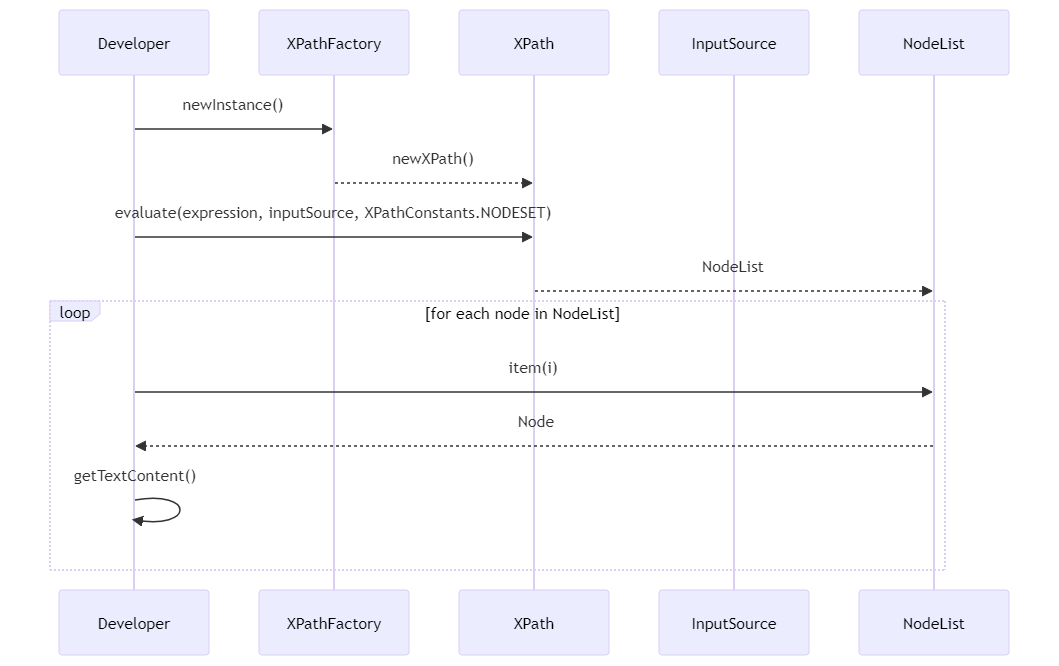
这段代码将输出所有类别为fiction的书籍的标题。
XPath的高级用法
XPath不仅限于基本的查询。它还支持更复杂的操作,比如选择特定属性的所有节点、使用运算符进行条件判断等。这使得XPath成为在处理复杂XML文档时非常强大的工具。
第9章:总结
解析规则的灵活性
Commons Digester的另一个亮点是它的解析规则。咱们可以定义非常具体的规则,来精确地控制解析过程。这些规则不仅包括基本的对象创建和属性设置,还可以扩展到条件解析和使用XPath等更高级的功能。
XPath的强大
咱们深入了解了XPath这个强大的XML路径语言。它提供了一种非常灵活和强大的方式来查询和处理XML文档。使用XPath,咱们可以轻松定位到XML文档中的特定节点,进行高效的数据提取和操作。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 网络安全好就业吗?会不会容易被淘汰
- spring的异常统一处理
- N-137基于springboot,vue运动会报名管理系统
- 论文选题一定要避免的误区!记住,千万不要去选这类题目!
- Linux iostat命令
- JavaWeb——后端之登录功能
- Java前端如何发送date类型的参数给后端
- 机场数据治理系列介绍(1):机场行业数据中台中的数据管理顶层设计方案
- 解决VNC连接Ubuntu服务器打开终端出现闪退情况
- 2023年PMP证书的含金量有多高?对于企业来说有多大的价值?