jieba-fenci 结巴分词原理讲解 segment
拓展阅读
为了便于大家学习,项目开源地址如下,欢迎 fork+star 鼓励一下老马~
分词的必要性
我们平时做文本分析,或者我个人想做一个繁简体转换/同义词替换等工具,分词都是必须的。
对于文本的朗读,统计等等,都是需要基于分词实现。
算法
前缀树算法+DAG 算法 其实是非常有用的。
我们基于最基础的一点,就可以实现最简单的分词。
敏感词(其他词语匹配),也可以基于这种算法。
正则表达式+搜索引擎,也和这些东西是紧密相连的。
算法的重要性
单单就 DFA 算法,也有很多相关论文进行优化实现。
只不过开发很少看 paper,所以技术落地的很少。
以后可以尝试啃一些 paper,并将其实现。
结巴分词的算法
以下是作者说明文件中提到的结巴分词用到的算法:
-
基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG)
-
采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合
-
对于未登录词,采用了基于汉字成词能力的HMM模型,使用了Viterbi算法
因为最近有点兴趣想了解中文分词, 所以看了大量的资料, 对上面的三条有了一点点理解, 不再是两眼一抹黑了。
基础资料推荐
先推荐大家看 http://www.52nlp.cn/ (我爱自然语言处理)的一系列关于概率、中文分词、HMM隐马尔科夫模型的文章, 然后再回头看看结巴分词的代码。
然后推荐大家看看《解密搜索引擎技术实战:Lucene&Java精华版》(4.6 概率语言模型的分词方法)
看了这本书的第4章, 或者看了那个在线的那个章节的前后部分, 基本上可以说, 结巴分词, 在很大的程度上类似于书中说的例子。
(上面的链接,是作者算法的第2条, 动态规划查找最大概率路径),当然, 结巴分词使用了HMM模型对未登录词进行识别(上面的第3条)
至于第1条, 作者的trie树,可以看这篇文章对python中如何保存trie树结构的词典进行深刻理解:http://iregex.org/blog/trie-in-python.html Trie in Python 这篇写的很好, 主要分析 Trie 实现原理,并给出 Python 的实现,还和正则联系到一起了。
上面列出的三个链接, 里面讲到的知识, 基本上将结巴分词的算法都讲到了。
所以有兴趣的人, 一定要仔细看我上面给的三个链接。
下面, 结合自己看结巴分词的代码, 讲讲我自己看过资料和代码后的理解。
先从作者的三条说起。
源码实现
Trie 树
第一条:基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG)
这个看上面的trie树的python实现, 结巴分词自带了一个叫做dict.txt的词典, 里面有2万多条词, 包含了词条出现的次数(这个次数是于作者自己基于人民日报语料等资源训练得出来的)和词性. 这个第一条的trie树结构的词图扫描, 说的就是把这2万多条词语, 放到一个trie树中, 而trie树是有名的前缀树, 也就是说一个词语的前面几个字一样, 就表示他们具有相同的前缀, 就可以使用trie树来存储, 具有查找速度快的优势.
聪明的人可能会想到把 dict.txt 中所有的词汇全部删掉, 然后再试试结巴能不能分词, 结果会发现, 结巴依然能够分词, 不过分出来的词, 大部分的长度为2.这个就是第三条, 基于HMM来预测分词了.
ps: 这里我个人的敏感词就是基于这种 DFA 算法实现,中间也曾想到对于运算结果的浪费,其实利用 DAG 记录一下,简单点说,就是把说有的词都记录下来。
DAG
接着说DAG有向无环图, 就是后一句的 生成句子中汉字所有可能成词情况所构成的有向无环图, 这个是说的, 给定一个句子, 要你分词, 也就是给定一个待分词的句子, 对这个句子进行生成有向无环图。
如果对有向无环图理解不了可以百度或者google搜索, 也可以看这篇 http://book.51cto.com/art/201106/269048.htm 比较形象的用图来表示了一个待分词句子的切分情况。
作者是怎么切分的呢?
-
根据dict.txt生成trie树,
-
对待分词句子, 根据dict.txt生成的trie树, 生成DAG, 实际上通俗的说, 就是对待分词句子, 根据给定的词典进行查词典操作, 生成几种可能的句子切分.
DAG 是啥玩意?记录了啥呢?
作者的源码中记录的是句子中某个词的开始位置, 从0到n-1(n为句子的长度), 每个开始位置作为字典的键, value是个list, 其中保存了可能的词语的结束位置(通过查字典得到词, 开始位置+词语的长度得到结束位置)
例如: {0:[1,2,3]} 这样一个简单的DAG, 就是表示0位置开始, 在1,2,3位置都是词, 就是说0~1, 02,03这三个起始位置之间的字符, 在dict.txt中是词语.
动态规划
第二条: 采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合
关于动态规划查找最大概率路径, 这个在一些大学课程中讲的很多了, 不熟悉的或者忘记了的翻翻百度就行了。
上面给的那个在线书籍的链接中也说的很明白了, 我这里就说说作者的代码:
在jieba分词中的Tier树会标记每个词的频率(等于出现的次数除以总数,当总体样本很大时,可以近似的看做词的概率),在知道每个词出现的频率之后,就可以基于动态规划的方法来寻找概率最大的分词路径。
一般的动态规划寻找最优路径都是从左往右,然而在这里是从右往左去寻找最优路径。
这主要是因为汉语句子中的重心往往在后面,后面才是句子的主干,因此从右往左计算的正确率往往要高于从左往右的正确率。
词频
作者的代码中讲字典在生成trie树的同时, 也把每个词的出现次数转换为了频率。
关于频率和概率, 这里在啰嗦几句: 按照定义, 频率其实也是一个0~1之间的小数, 是 事件出现的次数/实验中的总次数, 因此在试验次数足够大的情况下, 频率约等于概率, 或者说频率的极限就是概率。
不过通常人们混淆的是频率和次数, 经常把频率等同于事件出现的次数, 比如这里就是某个词语出现的次数, 所以, 频率在引起混淆的时候, 对中国人来说, 还是先理解为出现次数, 然后理解发现有问题, 就理解为出现次数/总数这个比率吧。
动态规划中, 先查找待分词句子中已经切分好的词语, 对该词语查找该词语出现的频率(次数/总数), 如果没有该词(既然是基于词典查找, 应该是有的), 就把词典中出现频率最小的那个词语的频率作为该词的频率, 也就是说 P(某词语)=FREQ.get(‘某词语’,min_freq), 然后根据动态规划查找最大概率路径的方法, 对句子从右往左反向计算最大概率(一些教科书上可能是从左往右, 这里反向是因为汉语句子的重心经常落在后面, 就是落在右边, 因为通常情况下形容词太多, 后面的才是主干, 因此, 从右往左计算, 正确率要高于从左往右计算, 这个类似于逆向最大匹配), P(NodeN)=1.0, P(NodeN-1)=P(NodeN)*Max(P(倒数第一个词))…依次类推, 最后得到最大概率路径, 得到最大概率的切分组合。
def calc(sentence,DAG,idx,route): #动态规划,计算最大概率的切分组合
#输入sentence是句子,DAG句子的有向无环图
N = len(sentence) #句子长度
route[N] = (0.0,'')
for idx in xrange(N-1,-1,-1): #和range用法一样,不过还是建议使用xrange
#可以看出是从后往前遍历每个分词方式的
#下面的FREQ保存的是每个词在dict中的频度得分,打分的公式是 log(float(v)/total),其中v就是被打分词语的频数
#FREQ.get(sentence[idx:x+1],min_freq)表示,如果字典get没有找到这个key,那么我们就使用最后的frequency来做
#由于DAG中是以字典+list的结构存储的,所以确定了idx为key之外,
#仍然需要for x in DAG[idx]来遍历所有的单词结合方式(因为存在不同的结合方法,例如“国”,“国家”等)
#以(频度得分值,词语最后一个字的位置)这样的tuple保存在route中
candidates = [ ( FREQ.get(sentence[idx:x+1],min_freq) + route[x+1][0] , x ) for x in DAG[idx] ]
route[idx] = max(candidates)
ps: 这里其实是基于概率做一次最可能的推测。(最佳的切分组合)
当然比如敏感词就可以简单粗暴一些,直接贪心匹配即可。
HMM 模型
第三条, 对于未登录词,采用了基于汉字成词能力的HMM模型,使用了Viterbi算法
未登录词, 作者说的是什么意思? 其实就是词典 dict.txt 中没有记录的词。
上面说了, 把dict.txt中的所有词语都删除了, 结巴分词一样可以分词, 就是说的这个。
怎么做到的?
这个就基于作者采用的HMM模型了, 中文词汇按照BEMS四个状态来标记, B是开始begin位置, E是end, 是结束位置, M是middle, 是中间位置, S是singgle, 单独成词的位置, 没有前, 也没有后, 也就是说, 他采用了状态为(B,E,M,S)这四种状态来标记中文词语, 比如北京可以标注为 BE, 即 北/B 京/E, 表示北是开始位置, 京是结束位置, 中华民族可以标注为BMME, 就是开始, 中间, 中间, 结束.
经过作者对大量语料的训练, 得到了finalseg目录下的三个文件(来自结巴项目的issues):
要统计的主要有三个概率表:
prob_trans.py
1)位置转换概率,即B(开头),M(中间),E(结尾),S(独立成词)四种状态的转移概率;
{‘B’: {‘E’: 0.8518218565181658, ‘M’: 0.14817814348183422},
‘E’: {‘B’: 0.5544853051164425, ‘S’: 0.44551469488355755},
‘M’: {‘E’: 0.7164487459986911, ‘M’: 0.2835512540013088},
‘S’: {‘B’: 0.48617017333894563, ‘S’: 0.5138298266610544}}
P(E|B) = 0.851, P(M|B) = 0.149,说明当我们处于一个词的开头时,下一个字是结尾的概率要远高于下一个字是中间字的概率,符合我们的直觉,因为二个字的词比多个字的词更常见。
prob_emit.py
2)位置到单字的发射概率,比如P(“和”|M)表示一个词的中间出现”和”这个字的概率;
prob_start.py
- 词语以某种状态开头的概率,其实只有两种,要么是B,要么是S。这个就是起始向量, 就是HMM系统的最初模型状态
实际上, BEMS之间的转换有点类似于2元模型, 就是2个词之间的转移
二元模型考虑一个单词后出现另外一个单词的概率,是N元模型中的一种。
例如:一般来说,”中国”之后出现”北京”的概率大于”中国”之后出现”北海”的概率,也就是:中国北京 比 中国北海出现的概率大些, 更有可能是一个中文词语.
不过, 作者这里应该不是用的2元分词模型的, 这里的BEMS只提供了单个汉字之间的转换, 发射概率, 并没有提供粒度更大的, 基于词语的发射和转移概率, 当然, 也有可能我理解的不够深入。
viterbi 算法
给定一个待分词的句子, 就是观察序列, 对HMM(BEMS)四种状态的模型来说, 就是为了找到一个最佳的BEMS序列, 这个就需要使用viterbi算法来得到这个最佳的隐藏状态序列, 具体的python版的viterbi算法请看维基百科:http://zh.wikipedia.org/wiki/%E7%BB%B4%E7%89%B9%E6%AF%94%E7%AE%97%E6%B3%95 维特比算法
通过作者之前训练得到的概率表和viterbi算法, 就可以得到一个概率最大的BEMS序列, 按照B打头, E结尾的方式, 对待分词的句子重新组合, 就得到了分词结果。
比如 对待分词的句子 ‘全世界都在学中国话’ 得到一个BEMS序列 [S,B,E,S,S,S,B,E,S] 这个序列只是举例, 不一定正确, 通过把连续的BE凑合到一起得到一个词, 单独的S放单, 就得到一个分词结果了: 上面的BE位置和句子中单个汉字的位置一一对应, 得到全/S 世界/BE 都/S 在/S 学/S 中国/BE 话/S 从而将句子切分为词语.
以上, 就是作者这三条介绍的全部理解和分析, 对于其中任何术语不理解, 请使用搜索引擎。
结巴分词的过程
流程架构图
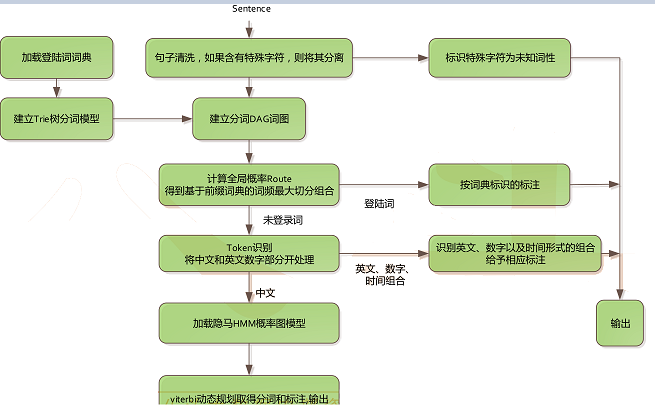
流程说明
-
加载字典, 生成trie树
-
给定待分词的句子, 使用正则获取连续的 中文字符和英文字符, 切分成 短语列表, 对每个短语使用DAG(查字典)和动态规划, 得到最大概率路径, 对DAG中那些没有在字典中查到的字, 组合成一个新的片段短语, 使用HMM模型进行分词, 也就是作者说的识别新词, 即识别字典外的新词.
-
使用python的yield 语法生成一个词语生成器, 逐词语返回. 当然, 我认为直接返回list, 效果也差不到哪里去.
for(int i=0;i<len;){
boolean match = dict.getMatch(sentence, i,
wordMatch);//到词典中查询
if (match) {// 已经匹配上
for (String word:wordMatch.values)
{//把查询到的词作为边加入切分词图中
j = i+word.length();
g.addEdge(new CnToken(i, j, 10, word));
}
i=wordMatch.end;
}else{//把单字作为边加入切分词图中
j = i+1;
g.addEdge(new CnToken(i,j,1,sentence.substring(i,j)));
i=j;
}
}
另外谈谈结巴分词的不足和局限:
-
在中文分词的时候, 字典起到的作用貌似不大, 因为基于单字的HMM(BEMS)模型貌似就可以分词了, 不管正确率如何, 总算能分了.字典起到的作用在后面说.说作用不大, 是因为没有字典也能分词. 另外, 生成了DAG之后, 又用动态规划, 觉得浪费步骤.小概率连乘下限可能溢出已修正, 就不多说了.
-
中文分词加载dict.txt这个字典后, 占用的内存为140多M, 觉得占用内存过多. 专业化的词典生成, 还不方便. 怎么训练自己的专用概率表, 就没有提供工具, 如果提供了训练自己的HMM模型工具, 估计更好.
-
没有那个字典的话, Trie和DAG都不起作用, 仅靠HMM模型的viterbi算法起作用, 因此看出词典的作用就是用来矫正HMM模型的分词结果, 但是HMM分词的结果生成方式是把B开始E结束的序列, 组合成一个词, 因此, 这种判断方法不一定正确, 比如BES能不能算作一个词的序列我觉得值得考虑.
-
HMM是不是真的能够识别新词呢? 我认为是肯定的, 但是是要打折扣的. 这个跟作者训练的词库有关系, 新词的字出现的概率在一段时间内会井喷, 但在长期的语言现象中, 应该还是平稳的, 除非这个词从一出现就很流行, 而且会流行很长的时间.因此HMM识别新词的功能在时效性上是不足的, 他只能识别2个字的词, 对于3个字的新词, 估计就能力有限了. 这个有待于BEMS序列组合成词的算法的改变和新词获取算法的改变, 才能得到改善.
-
引入二元分词的判断, 可能对词典的依赖会降低一点, 现在的词典的使用就是为了弥补HMM在识别多字词方面能力欠佳的问题, 所以词典中保存的是3 ,4 个字的词语.
-
词性标注的问题, 在分词的时候, 不能同时识别词性, 因为分词的时候没有处理词性, 也就是说分词的时候, 没有语义分析的.词性标注的部分, 是使用另外的posseg模块进行的.还有一个问题是新词的词性可能没法识别, 同样这个是说那些3, 4字词.
-
对专有名词比如人名 地名 机构名 的识别, 不能说好.
-
文档太少了, 关于词性标注, 得到的结果没有一点分析, 词性来源于哪里都没有说明. 不利于大家一起改进.句法分析, 语义分析都是没有的.
-
词性标注应该也是基于BEMS标注进行的. 不知道是不是可以独立出来.就是说基于语义来标示词性或者基于词语在句子中的位置来做推断进行标注词性.
-
分词过程中, 不能获得这个句子中出现的词的次数信息, 或者说出现频率高的词, 不能用于抽取文章的关键词.
拓展阅读
参考资料
http://www.mamicode.com/info-detail-2378307.html
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Java大师之路:从入门到精通的完整学习指南【文末送书-18】
- 前端八股文(性能优化篇)
- 打造出色的 Prometheus 监控系统,看完后薪资翻倍?
- 【粉丝福利社】互联网大厂推荐算法实战(文末送书-进行中)
- 电风扇目标检测数据集VOC格式1100张
- 现代密码学 补充1:两种窃听不可区分实验的区别
- Spring ApplicationEvent事件处理
- Flowable解读-序
- 桌面任务栏预览图问题分析
- leetcode 18 四数之和