Spark理论知识—1
1、Spark集群开发
spark集群运行时需要使用hdfs存储日志 9870端口
/export/server/hadoop/sbin/start-dfs.sh
# 手动退出安全模式
hdfs dfsadmin -safemode forceExit
使用yarn进行资源调度服务 8088端口
/export/server/hadoop/sbin/start-yarn.sh执行到这里我问一个问题
为什么不直接全部启动?
/export/server/hadoop/sbin/start-all.sh启动standalone进行资源调度 spark使用自带资源调度服务 8080端口
/export/server/spark/sbin/start-all.sh /export/server/spark/sbin/stop-all.sh注意这里是all.sh是把所有的都启动了。
问:
如何只启动spark计算引擎,而不启动spark自带的资源调度服务。
2、Anaconda
# 总结成两句话:
1、anaconda集成了python解释器和各种数据开发模块,服务器可以直接安装anaconda工具
2、anaconda引入虚拟环境,正常情况下一台电脑只能装一个python3的版本,不管你放C盘还是移动盘,但是anaconda虚拟环境可以让你一台电脑装python38,python39
# 操作
1、查看所有虚拟环境
2、创建新的虚拟环境
3、删除虚拟环境
4、进入虚拟环境
5、退出虚拟环境
查看当前有多少虚拟环境
conda info --envs
创建新的虚拟环境
conda create -n shaonianlu python=3.9
进入某个虚拟环境
conda activate shaonianlu
推出当前虚拟环境
conda deactivate
删除
conda remove -n shaonianlu --all
3、pycharm远程开发配置
远程开发需要用到什么?
-
ssh连接远程服务器,用以操作服务器
-
jdbc协议远程连接服务器的数据库
-
sftp服务,将本地目录和远程服务器上的目录做映射,将本地代码文件同步到远程服务器上
-
连接远程的python环境,可以使用远程python环境运行代码
SSH远程连接服务器
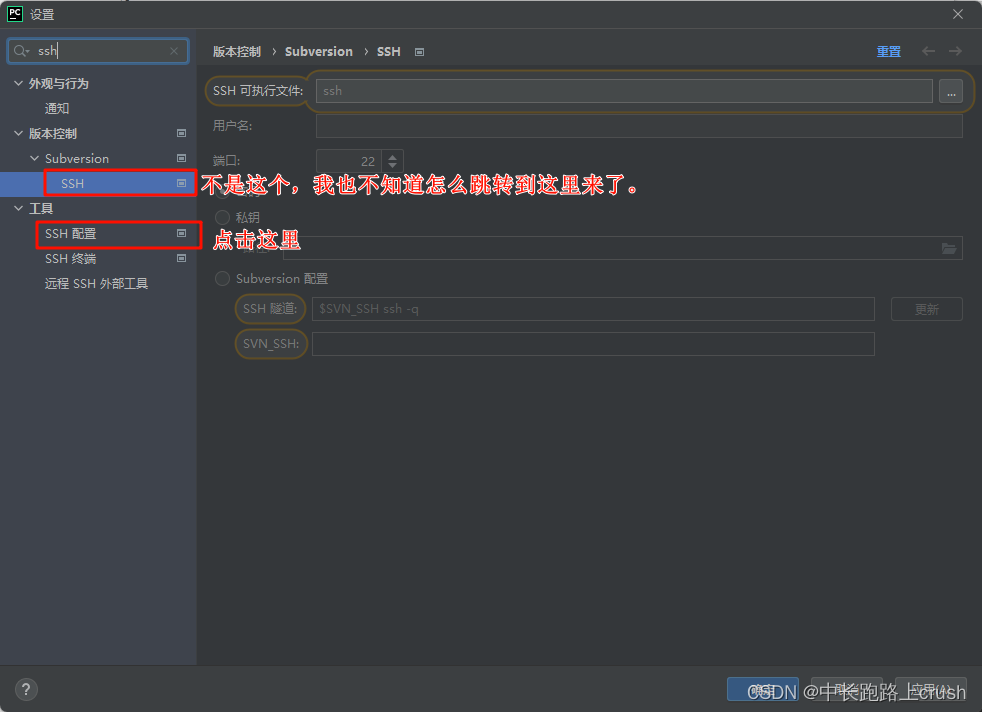
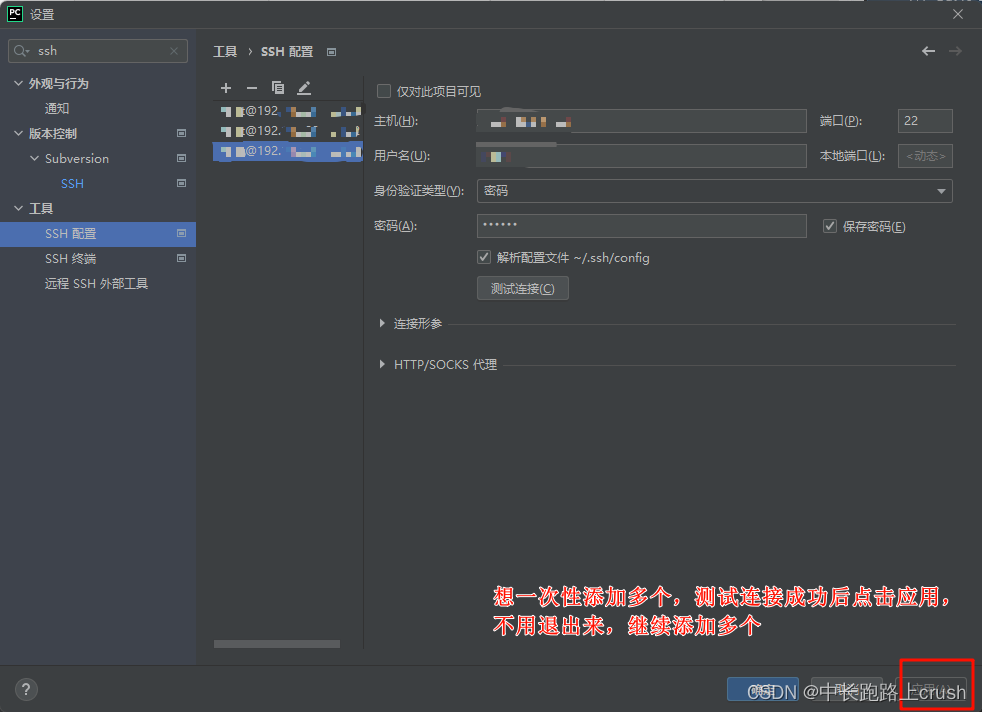
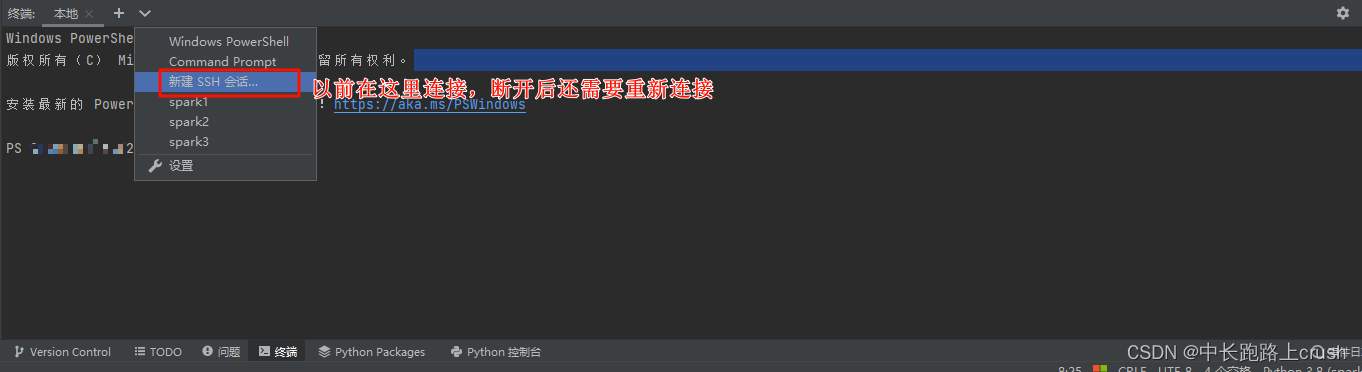
python配置远程Python环境和sftp映射
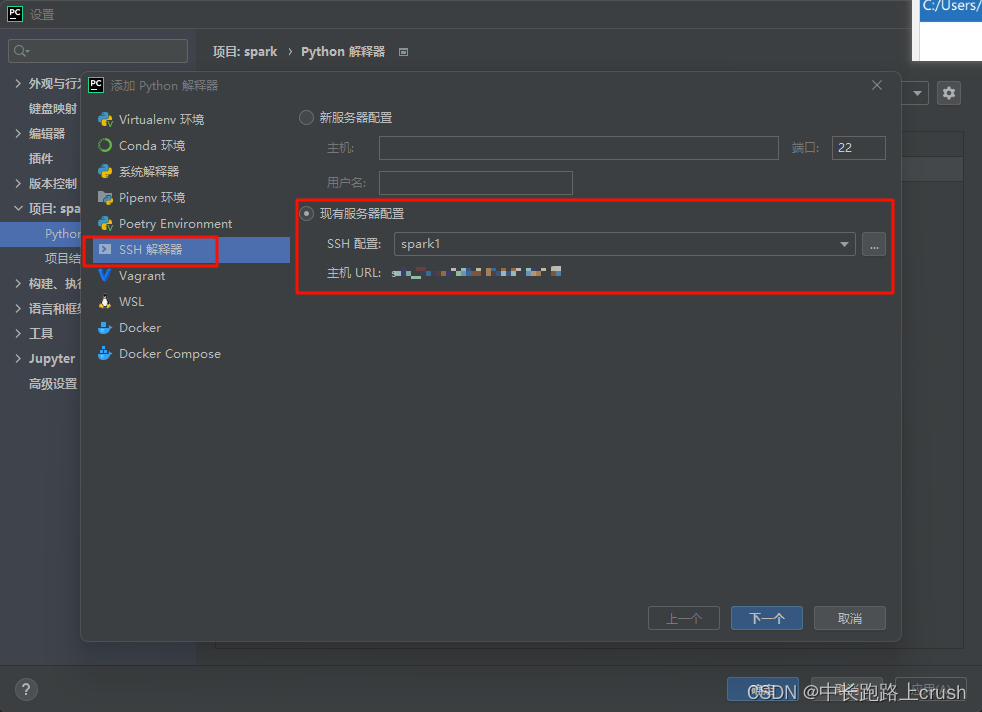
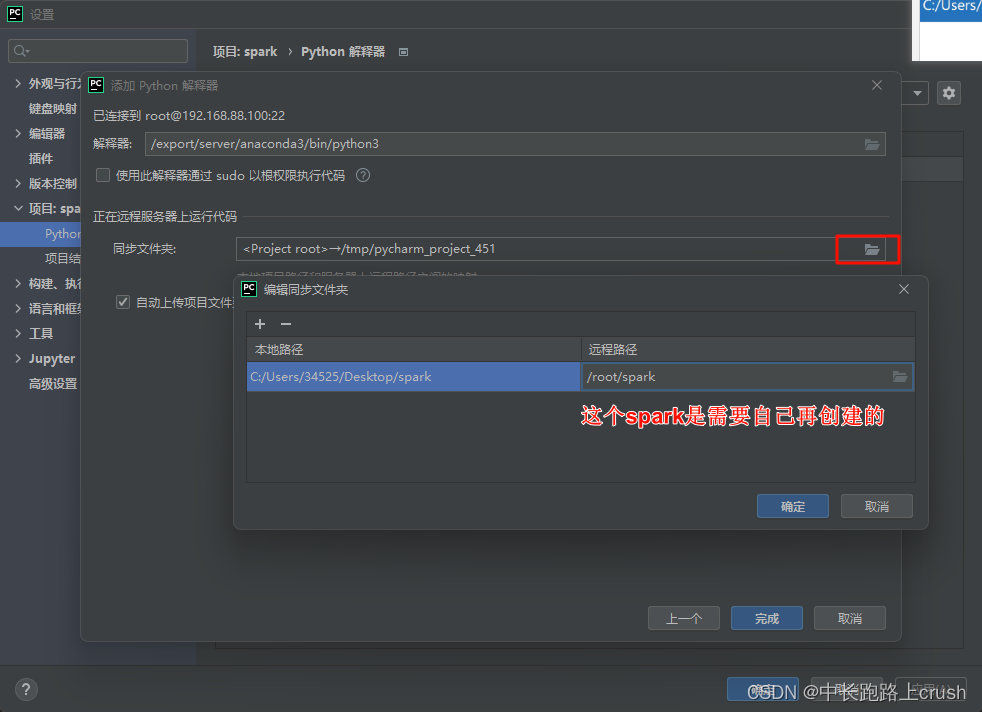
这个图要能看懂

报错
无法运行或者找不到,这俩种遇到任何一种都删除配置
删什么东西?
- sftp的remote host先删除掉
- 再删除远程python环境
集群模式下standalone高可用(这个是大前提,不少错误都是没开高可用)
交互式
(base)node1: 直接
pyspark进入的是本地模式 在node1上输入就使用node1的资源,在node2上输入就使用node2的资源[代码测试用]
(base)node1: pyspark --master spark://node1:7077standlaone
(base)node1: pyspark --master spark://node1:7077,node2:7077 但是你前提得开启zk服务,并在另一台服务器开启备用服务 高可用模式
(base)node1: pyspark --master yarn
脚本式
from pyspark import SparkContext
# 没有指定任何参数,使用本地local模式
sc = SparkContext()
# master参数可以指定调用的资源服务
# 使用standalone资源调度
sc = SparkContext(master='spark://node1:7077')
# 使用standalone高可用资源调度
sc = SparkContext(master='spark://node1:7077,node2:7077')
# 使用yarn资源调度
sc = SparkContext(master='yarn')
ssh连接慢或者sftp连接慢
vim /etc/ssh/sshd_config【哪台连接的慢,你就修改哪台的】
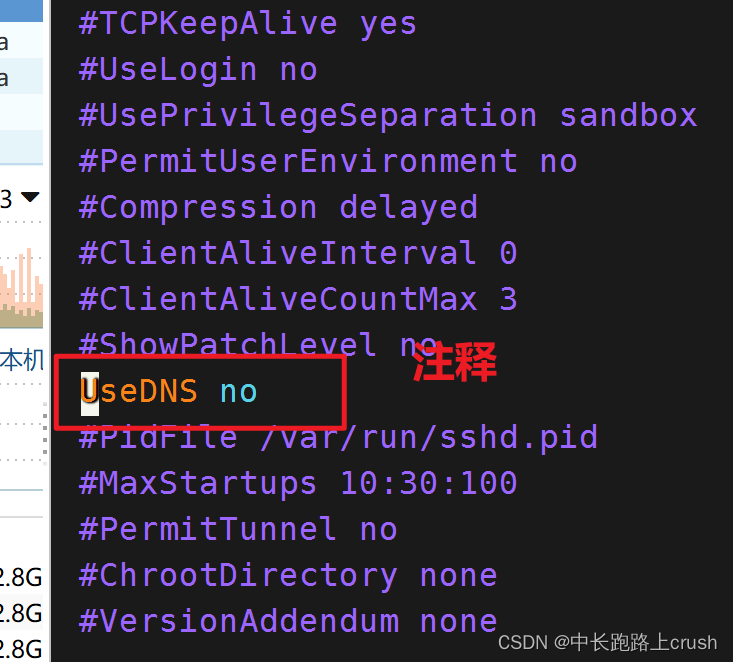
别忘记重启
systemctl restart sshd
单词
Proceed:继续进行
Remote:远程 -->remote host :远程主机
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 智能优化算法应用:基于鱼鹰算法3D无线传感器网络(WSN)覆盖优化 - 附代码
- 【计算机毕业设计】SSM垃圾分类管理系统
- PathWave Device Modeling (IC-CAP) 建模系统——IC-CAP概述
- 【Java并发编程的艺术学习】第四章摘要补全
- 特殊类设计
- MySQL经典面试题
- 怎么搭建实时渲染云传输服务器
- 1、Seaborn可视化库
- 使用ChatGPT前的 谷歌邮箱gmail注册 教程
- 【Python版】手把手带你如何进行Mock测试