LLM之RAG实战(二十)| RAG分块策略的五个level
? ? ? ?在RAG系统中,包括检索和生成两大组件,而检索的关键是对数据的分块策略,本文将根据Greg Kamradt的视频(https://www.youtube.com/watch?v=8OJC21T2SL4)整理如下五个分块级别策略,代码实现在参考文献[2]:
级别1:Fixed Size Chunking
? ? ? ?这是最粗糙和最简单的文本分割方法。它将文本分解为指定数量的字符块,而不考虑其内容或结构。
? ?Langchain和llamaindex框架为这种分块技术提供了CharacterTextSplitter和SentenceSplitter(默认为对句子进行拆分)类。需要记住的几个概念:
- 文本的拆分方式:按单个字符
- 区块大小的测量方式:按字符数
- chunk_size:块中的字符数
- chunk_overlap:在顺序块中重叠的字符数。跨块保留重复数据
- 分隔符:用于分割文本的字符(默认为“”)
级别2:Recursive Chunking
? ? ? ?虽然固定大小的分块更容易实现,但它不考虑文本的结构。递归分块使用一组分隔符,以分层和迭代的方式将文本划分为更小的块。如果最初分割文本的尝试没有产生所需大小的块,则该方法会使用不同的分隔符递归地调用结果块,直到达到所需的块大小。
? ? ? ?Langchain框架提供了RecursiveCharacterTextSplitter类,该类使用默认分隔符(“\n\n”, “\n”, “ “,””)分割文本
级别3:Document Based Chunking
? ? ? ?在这种分块方法中,我们根据文档的固有结构对其进行拆分。这种方法考虑了内容的流动和结构,但可能不是缺乏明确结构的文件。
- Document with Markdown:Langchain提供MarkdownTextSplitter类,以分隔符的方式分割Markdown文件。
- Document with Python/JS:Langchain提供了PythonCodeTextSplitter来根据类、函数等对Python程序进行拆分,我们可以将语言提供到RecursiveCharacterTextSplitter类的from_langage方法中。
- Document with tables:在处理表时,基于级别1和级别2的拆分可能会丢失行和列之间的表格关系。为了保持这种关系,以语言模型能够理解的方式格式化表内容(例如,使用HTML中的<table>标记、以“;”分隔的CSV格式等)。在语义搜索过程中,直接从表中匹配嵌入可能很有挑战性。开发人员可以在提取表格内容后进行摘要提取,然后针对该摘要生成嵌入,从而进行语义匹配。
- Document with images (Multi- Modal):图像和文本的嵌入内容可能不同(尽管CLIP模型支持这一点)。理想的策略是使用多模态模型(如GPT-4视觉)来生成图像的摘要并存储其嵌入。Unstructured.io提供了partition_pdf方法可以从pdf文档中提取图像。
第4级:语义块
? ? ? ?以上三个级别都处理文档的内容和结构,并且需要保持块大小的恒定值。这种分块方法旨在从嵌入中提取语义,然后评估这些分块之间的语义关系。核心思想是将语义相似的块放在一起。
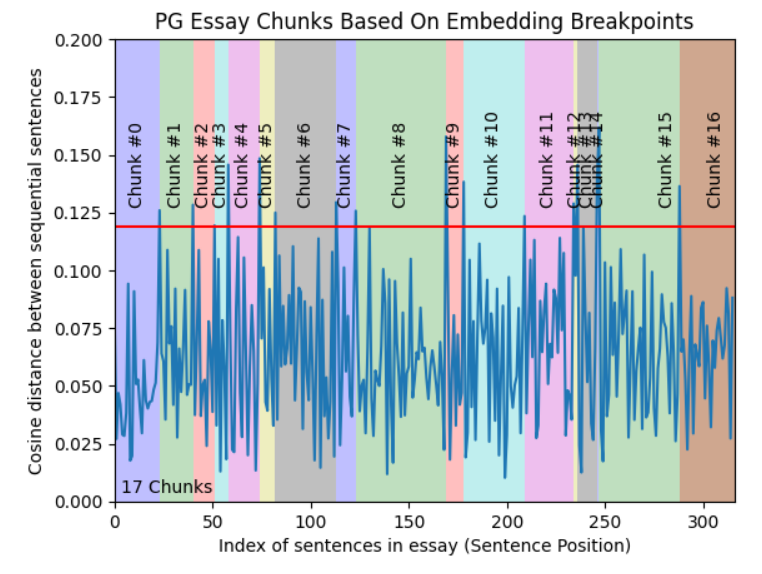
? ? ??LlamaIndex具有SemanticSplitterNodeParser类,该类允许使用块之间的上下文关系将文档拆分为块,使用嵌入相似性自适应地选择句子之间的断点。
SemanticSplitterNodeParser超参数介绍:
- buffer_size:配置块的初始窗口大小;
- breakpoint_percentile_threshold:决定在何处分割块的阈值;
- embed_model:使用的嵌入模型。
第5级:代理分块
? ? ? ?这种分块策略探索了使用LLM来根据上下文确定块中应包含多少文本以及哪些文本的可能性。
? ? ? ?为了生成初始块,参考论文《Dense X Retrieval: What Retrieval Granularity Should We Use?》,从原始文本中提取独立语句。Langchain提供了propositional-retrieval模板(https://templates.langchain.com/new?integration_name=propositional-retrieval)来实现这一点。
? ? ? ?在生成命题之后,这些命题输入到基于LLM的代理。该代理确定命题是否应包括在现有块中,或者是否应创建新块。

参考文献:
[1]?https://medium.com/@anuragmishra_27746/five-levels-of-chunking-strategies-in-rag-notes-from-gregs-video-7b735895694d
[2]?https://github.com/FullStackRetrieval-com/RetrievalTutorials/blob/main/5_Levels_Of_Text_Splitting.ipynb
[3]?https://docs.llamaindex.ai/en/stable/examples/node_parsers/semantic_chunking.html
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- C#实现基于Word保护性模板文件的修改
- elemeentui el-table封装
- SpringMVC:RestFul 风格、实现请求转发和重定向、乱码问题解决、前后端传递参数、JSON 字符串
- C语言程序入门设计编程练习代码分享
- SpringBoot对接支付宝当面付
- Python爬虫中文乱码处理实例代码解析
- 极智开发 | 解读英伟达软件生态 深度学习推理引擎TensorRT
- ruoyi-vue项目中当使用request.js请求后他时,返回非200状态码时request.js会抛出控制台异常导致后续逻辑不执行的解决办法
- Python——面向对象案列
- 把Windows系统装进U盘,到哪都有属于你自己的电脑系统