43 tmpfs/devtmpfs 文件系统
前言
在 linux 中常见的文件系统 有很多, 如下?
基于磁盘的文件系统, ext2, ext3, ext4, xfs, btrfs, jfs, ntfs?
内存文件系统, procfs, sysfs, tmpfs, squashfs, debugfs?
闪存文件系统, ubifs, jffs2, yaffs ?
文件系统这一套体系在 linux 有一层 vfs 抽象, 用户程序不用关心 底层文件系统的具体实现, 用户只用操作 open/read/write/ioctl/close 的相关 系统调用, 这一层系统调用 会操作 vfs 来处理响应的业务?
vfs 会有上面各种文件系统对应的 读写 相关服务, 进而 将操作下沉到 具体的文件系统?
我们这里 来看一下 tmpfs?文件系统, 这是一个 基于 内存的文件系统, 读写的都是 基于内存页?
tmpfs/devtmpfs?可能使用 shmem 相关操作, 也可能使用 ramfs 相关操作, 取决于配置?
rootfs 的部分和?rootfs 文件系统?部分一致, 这里 我们不多赘述, 我们这里主要关心 shmem 的部分
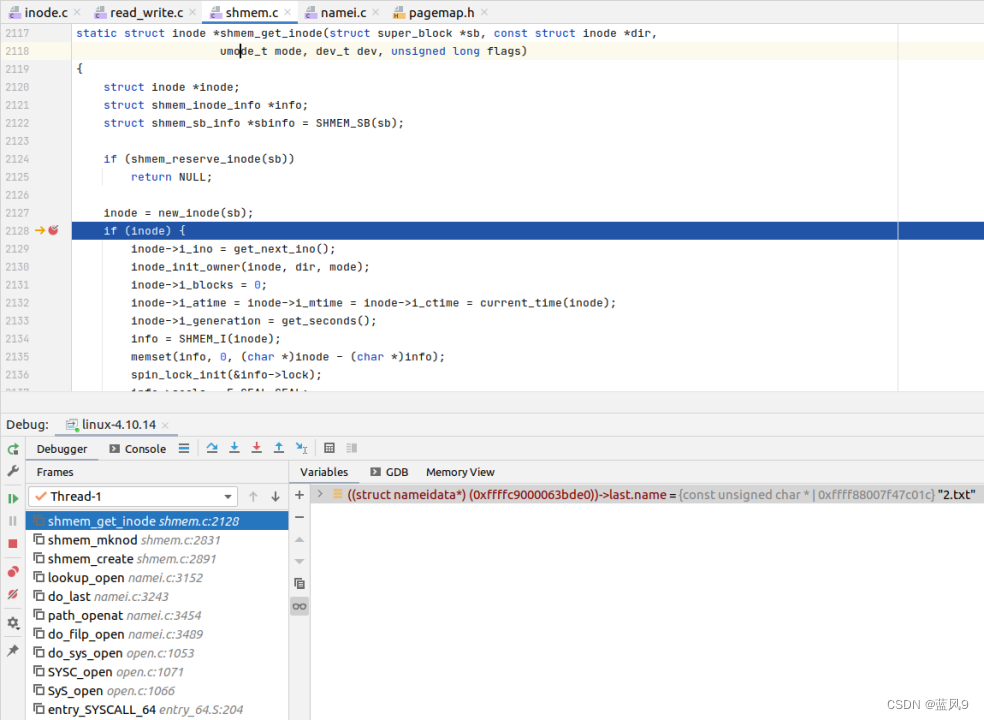
如何分配inode ?
在创建该文件的时候,?tmpfs 会创建对应的?inode, 并将改?inode?添加到?dcache
创建?inode 操作来自于,?父级目录的?i_op->create, tmpfs 中对应于?shmem_get_inode
这里主要是基于?tmpfs 的?super_block 新建?inode, 初始化?i_no, i_mapping, i_op, i_fop 什么的?
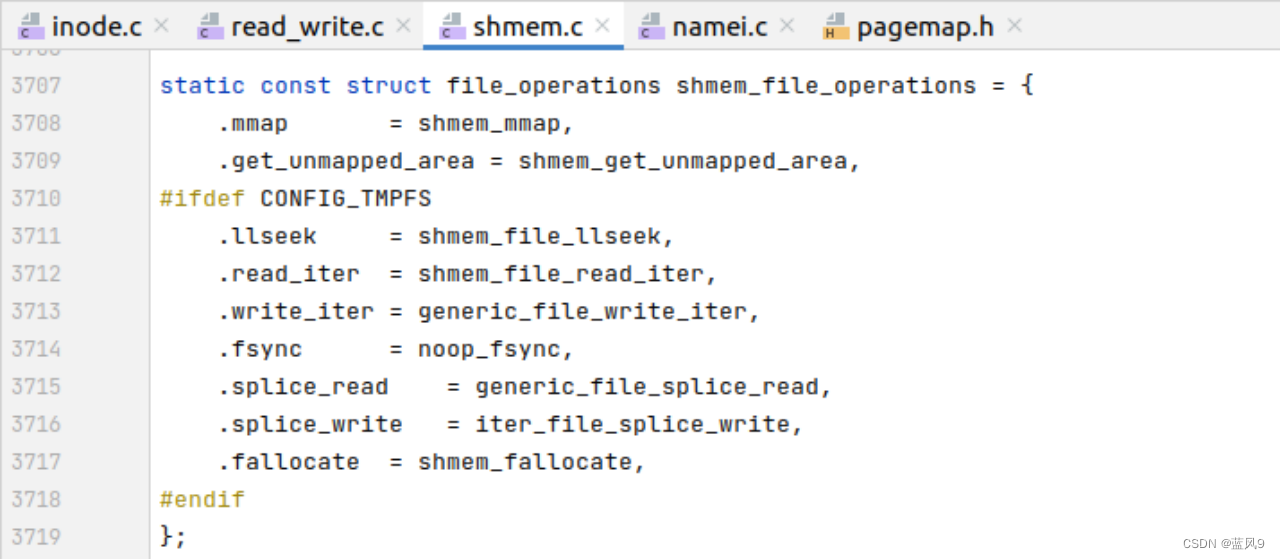
普通文件的?i_fop 为?shmem_file_operations
/run/xx 是在哪里创建的???
这个创建取决于实际的业务,?业务/内核 代码向 tmpfs?中写出具体的数据到具体的文件?
那么执行?该代码的时候 就会创建对应的文件
如何分配存储空间???
存储空间是来自于 新分配的物理页??

如何读写数据 ?
a_ops->write_begin 会回去?maping, pos 对应的物理页,?如果不存在?则向 系统?进行申请?
然后?iov_iter_copy_from_user_atomic 的实现是将?用户空间待写出的数据 写出到给定的 物理页

执行命令为 ‘echo “4” >> 4.txt ‘, 这里?i->iov->iov_base 中即为待输出的内容,?这里是?一个字符 4, 和一个回车

copy_page_to_iter 即为读取的操作,?将物理页的数据拷贝到?buf 中

如何根据?path?获取到上下文的数据??
上面在?i_op->create 中创建了?inode, 但是并没有提到将?inode 注册到?dir?中或者怎么怎么样?
那么?读取文件的时候怎么关联找到这个 inode 呢??
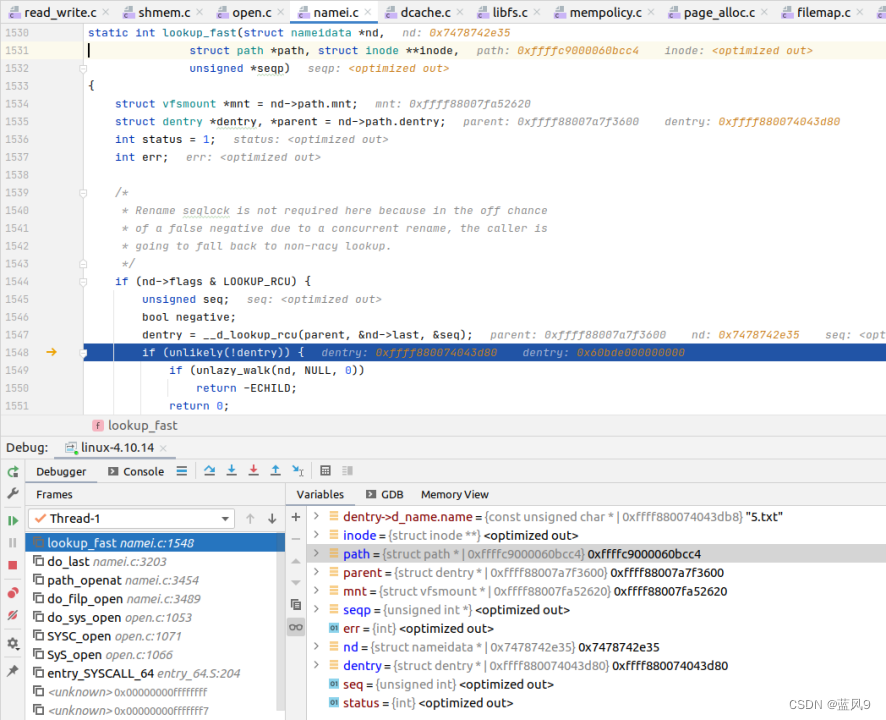
该文件对应的dentry 在?i_op->lookup 的时候,?将 dentry 放到了?dcache_hashtable 中?
然后?之后才是走的上面的 i_op->create 来创建文件对应的?inode, 然后将?dentry?关联上 inode

然后?在之后 读取该文件的时候,?lookup_fast 的时候去?dcache_hashtable 中查询对应的?dentry?的信息?
进而拿到?inode, 以及?inode 相关附加信息
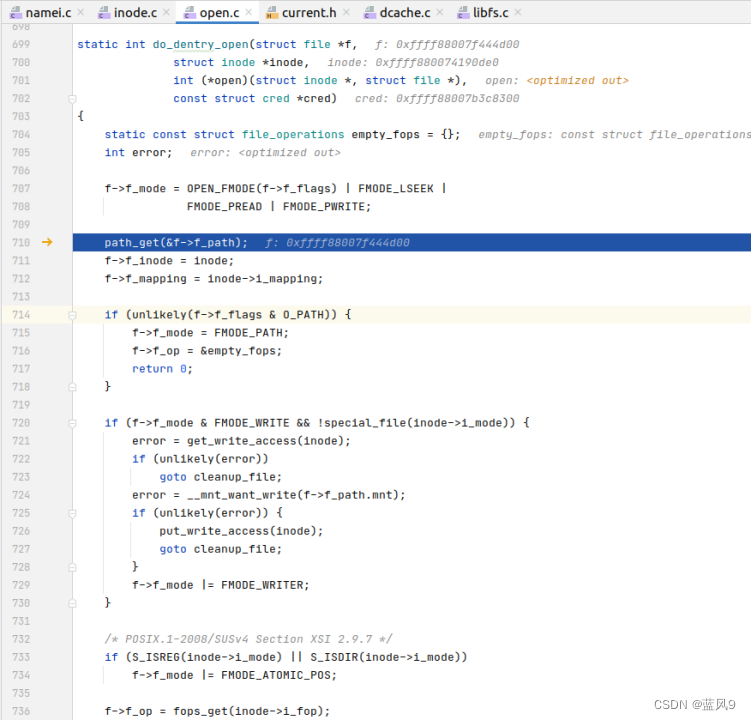
进而是根据?inode, 以及上下文,?封装?file?对象?
?完
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 网络市场中的品牌推广:面向新一代数字原住民的挑战与机遇
- [HFSS]一些使用心得
- 互联网加竞赛 python 爬虫与协同过滤的新闻推荐系统
- 前端性能优化十三:提升CSS渲染性能
- Redis使用场景(五)
- 飞凌嵌入式全志T113-i开发板的休眠及唤醒操作
- 【代码随想录算法训练营-第七天】【哈希表】454,383,15,18
- Hypervisor Display架构
- Spring Cloud+SpringBoot b2b2c:Java商城实现一件代发设置及多商家直播带货商城 免 费 搭 建
- python常用笔记记录(持续更新)