深度学习课程实验四训练和测试循环神经网络
一、 实验目的
1、学会搭建、训练和测试循环神经网络,并掌握其应用。
2、深入研究和理解该模型,并寻找适用于不同任务和场景的最佳配置和结构。这对于推动神经网络的发展和应用具有重要意义。
3、对比和研究不同的RNN变种:RNN模型有很多变种,如长短时记忆网络(LSTM)、门控循环单元(GRU)等。进行实验,比较不同变种的性能和效果,有助于了解它们在不同任务中的优缺点,进一步改进模型和算法。
4、研究RNN模型的性能和效果:通过训练和测试RNN,可以评估其在特定任务上的表现如何。这有助于了解RNN模型的优势、限制以及在不同领域中的可应用性。
二、 实验步骤
Building your Recurrent Neural Network - Step by Step
1、导入实验所需要的所有软件包
2、循环神经网络的正向传播
⑴RNN单元
⑵RNN正向传播
3、长短期记忆(LSTM)
⑴关于”门“
⑵LSTM单元
⑶LSTM的正向传播
4、循环神经网络中的反向传播(可选练习)
⑴基础RNN的反向传播
⑵LSTM反向传播
⑶反向传播LSTM RNN
Improvise a Jazz Solo with an LSTM Network
1、导入实验所需要的所有软件包
2、问题陈述
⑴加载数据集
⑵模型概述
3、建立模型
4、生成音乐
⑴预测和采样
⑵生成音乐
Emojify
1、基准模型:Emojifier-V1
⑴加载EMOJISET数据集
⑵Emojifier-V1概述
⑶实现Emojifier-V1
⑷检查测试集表现
2、Emojifier-V2:在Keras中使用LSTM
⑴模型概述
⑵keras和小批量处理
⑶嵌入层
3、构建Emojifier-V2
三、 实验代码分析
1、a_next = np.tanh(np.dot(Waa, a_prev) + np.dot(Wax, xt) + ba:计算当前时刻的隐藏状态a_next。通过使用np.dot函数来执行矩阵乘法运算,它将上一时刻的隐藏状态和输入xt与相应的权重进行相乘。然后,将这些结果与偏置ba相加,并应用tanh激活函数。
2、yt_pred = softmax(np.dot(Wya, a_next) + by):计算输出yt_pred。通过使用np.dot函数来执行矩阵乘法运算,它将下一个隐藏状态a_next与输出的权重Wya相乘,然后加上偏置by,并应用softmax函数。
3、cache = (a_next, a_prev, xt, parameters):创建一个元组cache,其中包含了当前的隐藏状态a_next、上一个隐藏状态a_prev、输入xt和所有的参数。
4、n_x, m, T_x = x.shape :将输入x的维度信息解包到变量n_x、m和T_x中。其中,n_x是输入特征的数量,m是训练样本的数量,T_x是时间步的数量。
5、n_y, n_a = parameters[“Wya”].shape:将输出矩阵Wya的维度信息解包到变量n_y和n_a中。其中,n_y是输出特征的数量,n_a是隐藏状态的数量。
6、a = np.zeros([n_a, m, T_x]):初始化一个全零数组a,用于存储每个时间步的隐藏状态。它的维度为(n_a, m, T_x),其中n_a是隐藏状态的数量,m是训练样本的数量,T_x是时间步的数量。
7、y_pred = np.zeros([n_y, m, T_x]):初始化一个全零数组y_pred,用于存储每个时间步的输出预测值。它的维度为(n_y, m, T_x),其中n_y是输出特征的数量,m是训练样本的数量,T_x是时间步的数量。
8、for t in range(T_x):
9、a_next,yt_pred,cache=rnn_cell_forward(x[:,:,t], a_next, parameters):在每个时间步t,调用rnn_cell_forward函数来计算下一个隐藏状态a_next和预测输出yt_pred。其中,输入x[:, :, t]是第t个时间步的输入。
10、a[:,:,t] = a_next:将计算得到的下一个隐藏状态a_next存储在数组a的第t个时间步。
11、y_pred[:,:,t] = yt_pred:计算得到的输出预测值yt_pred存储在数组y_pred的第t个时间步。
12、caches.append(cache):将本次时间步的cache添加到caches列表中。
13、concat = np.zeros([n_a + n_x, m]):创建一个全零数组concat,用于存储组合输入和前一个隐藏状态的向量。它的维度为(n_a + n_x, m),其中n_a是隐藏状态的数量,n_x是输入特征的数量,m是训练样本的数量。
14、concat[: n_a, :] = a_prev:将a_prev的值复制到concat的前n_a行。
15、concat[n_a :, :] = xt:将xt的值复制到concat的第n_a行及以后的行。
16、ft = sigmoid(np.dot(Wf, concat) + bf):计算遗忘门ft。通过使用np.dot函数进行矩阵乘法运算,将权重矩阵Wf与concat向量相乘并加上偏置bf。然后应用sigmoid激活函数。
17、it = sigmoid(np.dot(Wi, concat) + bi):计算输入门it。通过使用np.dot函数进行矩阵乘法运算,将权重矩阵Wi与concat向量相乘并加上偏置bi。然后应用sigmoid激活函数。
18、cct = np.tanh(np.dot(Wc, concat) + bc):计算候选细胞状态cct。通过使用np.dot函数进行矩阵乘法运算,将权重矩阵Wc与concat向量相乘并加上偏置bc。然后应用tanh激活函数。
19、c_next = ft * c_prev + it * cct:计算下一个细胞状态c_next。它基于遗忘门ft和输入门it的组合,以及前一个细胞状态c_prev和候选细胞状态cct的乘积。
20、ot = sigmoid(np.dot(Wo, concat) + bo):计算输出门ot。通过使用np.dot函数进行矩阵乘法运算,将权重矩阵Wo与concat向量相乘并加上偏置bo。然后应用sigmoid激活函数。
21、a_next = ot * np.tanh(c_next):计算下一个隐藏状态a_next。它基于输出门ot和细胞状态c_next的乘积,并应用tanh激活函数。
22、yt_pred = softmax(np.dot(Wy, a_next) + by):计算预测输出yt_pred。通过使用np.dot函数进行矩阵乘法运算,将权重矩阵Wy与a_next向量相乘并加上偏置by。然后应用softmax函数。
23、cache = (a_next, c_next, a_prev, c_prev, ft, it, cct, ot, xt, parameters):创建一个元组cache,包含了下一个隐藏状态a_next、下一个细胞状态c_next、前一个隐藏状态a_prev、前一个细胞状态c_prev、遗忘门ft、输入门it、候选细胞状态cct、输出门ot、当前输入xt和所有的参数。
24、a_next, c_next, yt, cache = lstm_cell_forward(x[:, :, t], a_next, c_next, parameters):在每个时间步t,调用lstm_cell_forward函数来计算下一个隐藏状态a_next、下一个细胞状态c_next、预测输出yt和cache。其中,输入x[:, :, t]是第t个时间步的输入。
25、a[:,:,t] = a_next:计算得到的下一个隐藏状态a_next存储在数组a的第t个时间步。
26、y[:,:,t] = yt:计算得到的预测输出yt存储在数组y的第t个时间步。
27、c[:,:,t] = c_next:计算得到的下一个细胞状态c_next存储在数组c的第t个时间步。
28、X = Input(shape=(Tx, n_values)):创建一个输入层X,其形状为(Tx, n_values),表示接受形状为(Tx, n_values)的输入数据。
29、a0 = Input(shape=(n_a,), name=‘a0’):
30、c0 = Input(shape=(n_a,), name=‘c0’):这两行代码创建两个输入层a0和c0,其形状为(n_a,),分别代表初始的隐藏状态a和细胞状态c。name参数用于给输入层命名。
31、a = a0、c = c0:将初始的隐藏状态a0和细胞状态c0赋给变量a和c。
32、outputs = []:这行代码创建一个空列表outputs,用于存储每个时间步的输出。
33、for t in range(Tx):这行代码表示一个for循环,用于遍历从0到Tx-1的时间步。
34、x = Lambda(lambda x: X[:,t,:])(X):将输入层X的第t个时间步的数据提取出来,并赋值给变量x。这里使用Lambda层来实现。
35、x = reshapor(x):对变量x进行形状重塑操作,以确保它与LSTM单元的输入形状匹配。
36、a, _, c = LSTM_cell(x, initial_state=[a, c]):调用LSTM_cell函数来计算下一个隐藏状态a和细胞状态c。将变量x作为输入,并使用前一个时间步的隐藏状态a和细胞状态c作为初始状态。
37、out = densor(a)使用densor层,将计算得到的隐藏状态a转换为输出。
38、model = Model(inputs=[X,a0,c0],outputs=outputs):这行代码创建一个模型model,它有三个输入:X、a0和c0,并且有多个输出,即outputs列表中的各个时间步的输出。
39、x0 = Input(shape=(1, n_values)):这行代码创建一个输入层x0,其形状为(1, n_values),表示接受形状为(1, n_values)的输入数据。在音乐生成中,一次只生成一个音符。
40、a0 = Input(shape=(n_a,), name=‘a0’)和c0 = Input(shape=(n_a,), name=‘c0’):这两行代码创建两个输入层a0和c0,其形状为(n_a,),分别代表初始的隐藏状态a和细胞状态c。name参数用于给输入层命名。
41、a, _, c = LSTM_cell(x, initial_state=[a, c]):调用LSTM_cell函数来计算下一个隐藏状态a和细胞状态c。将当前时间步的输入x以及前一个时间步的隐藏状态a和细胞状态c作为初始状态。
42、x = Lambda(one_hot)(out):将输出out通过Lambda层使用one_hot函数进行独热编码,并赋值给变量x。one_hot函数用于将输出转换为适合作为下一个时间步输入的形式。
43、inference_model = Model(inputs=[x0,a0,c0],outputs=outputs):这行代码创建一个推理模型inference_model,它有三个输入:x0、a0和c0,并且有多个输出,即outputs列表中的各个时间步的输出。
44、return inference_model:返回创建的推理模型inference_model。推理模型接受初始输入和状态,然后生成音乐的序列作为输出。
45、pred=inference_model.predict([x_initializer,a_initializer,c_initializer]):使用推理模型inference_model对给定的初始输入和状态(x_initializer、a_initializer和c_initializer)进行预测。它返回一个预测结果,即预测输出的概率分布。
46、测输出的概率分布。
47、indices = np.argmax(pred, axis = -1):通过使用np.argmax函数,沿着最后一个维度(axis=-1)找到预测结果中概率最大的索引。这些索引表示模型在每个时间步预测的最可能的音符。
48、results= to_categorical(indices,num_classes=78:这行代码使用to_categorical函数将预测得到的索引转换为独热编码形式。num_classes参数指定了独热编码的维度,这里是78,代表78种不同的音符。结果是一个二维数组,其中每行表示一个时间步的独热编码向量。
49、sentence.lower()).split(): 使用lower()方法将句子转换为小写,并使用split()方法将句子分割成单词列表。目的是保持单词的一致性,并方便后续处理。
50、avg = np.zeros(50): 初始化一个长度为50的零向量avg,用于存储句子的平均向量表示。使用numpy库中的zeros()函数创建一个全零向量。
51、for w in words:对句子中的每个单词进行迭代。
52、avg += word_to_vec_map[w]: 将字典word_to_vec_map中对应单词w的向量加到avg上。假设字典中包含了所有句子中可能出现的单词的向量表示。
53、avg = avg/len(words): 将avg除以单词数量,求得句子的平均向量表示。
54、W = np.random.randn(n_y, n_h) / np.sqrt(n_h):初始化权重矩阵W为一个服从标准正态分布的随机矩阵,除以n_h的平方根进行归一化。
55、b = np.zeros((n_y,)):初始化偏置b为全零矩阵,形状为(n_y, )。
56、Y_oh = convert_to_one_hot(Y, C = n_y):将标签Y转换为one-hot编码形式,存储在Y_oh中。其中convert_to_one_hot()函数将Y转换为独热编码,C为类别数量。
57、sentence_to_avg(X[i],word_to_vec_map):根据词向量映射word_to_vec_map计算输入数据X中第i个样本的平均词向量。
58、z = np.dot(W,avg) + b:计算样本i通过隐藏层的输出结果。这里使用的是线性变换操作。
59、a = softmax(z):对输出结果进行softmax操作,得到样本i的预测概率分布。
60、cost = -np.sum(Y_oh[i]*np.log(a)):计算损失函数值,采用负对数似然损失函数。
61、dz = a - Y_oh[i]:计算损失函数的梯度。
62、W = W - learning_rate * dW:根据梯度下降算法更新权重矩阵W,b = b - learning_rate * db:根据梯度下降算法更新偏置向量b。
63、if t % 100 == 0:如果当前迭代次数是100的倍数,则打印损失函数的值。
64、vocab_len = len(word_to_index) + 1:这行代码计算了词汇表的大小。word_to_index是一个字典,它将单词映射到对应的索引。通过计算字典的长度,我们可以得到词汇表中单词的数量。
65、emb_dim = word_to_vec_map[“cucumber”].shape[0]:这行代码计算了词向量的维度。word_to_vec_map是一个字典,将单词映射到对应的词向量。这里选择了一个单词 “cucumber” 来获取其对应的词向量,并通过查看该词向量的形状来获取词向量的维度。
66、emb_matrix = np.zeros((vocab_len, emb_dim)):这行代码创建了一个全零的矩阵,形状为 (词汇表大小, 词向量维度)。这个矩阵用来存储所有单词的词向量。
67、For word, index in word_to_index.items():emb_matrix[index,:]= word_to_vec_map[word]:这个循环会遍历word_to_index字典中的每一个 (word, index) 键值对。对于每一个单词,它会使用word_to_vec_map字典找到对应的词向量,并将词向量赋值给emb_matrix矩阵的对应行。
68、embedding_layer = Embedding(vocab_len, emb_dim, trainable=False): 这行代码创建了一个词嵌入层。vocab_len参数指定了词嵌入层所能处理的最大整数(即词汇表的大小),emb_dim参数指定了每个词嵌入的维度大小,trainable参数指定是否在训练过程中更新词嵌入矩阵的权重。
69、embedding_layer.build((None,)):这行代码构建了词嵌入层的内部变量。参数 (None,)指定了输入的形状,其中None表示可以接受任意长度的输入序列。
70、embedding_layer.set_weights([emb_matrix]):这行代码设置了词嵌入层的权重。参数emb_matrix是一个包含词向量的矩阵,它会被设置为词嵌入层的权重。
四、 运行结果
Building your Recurrent Neural Network - Step by Step
1、RNN单元的前向传播

2、RNN正向传播

3、LSTM单元的前向传播
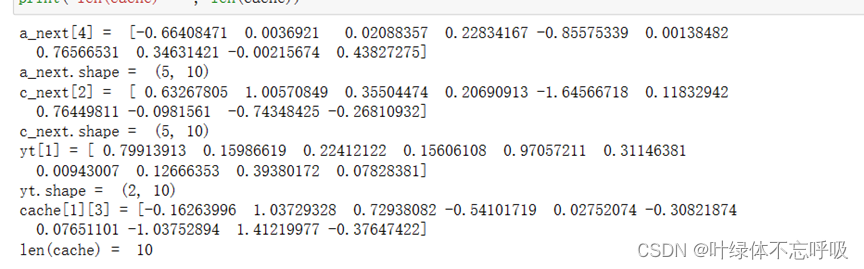
4、LSTM前向传播
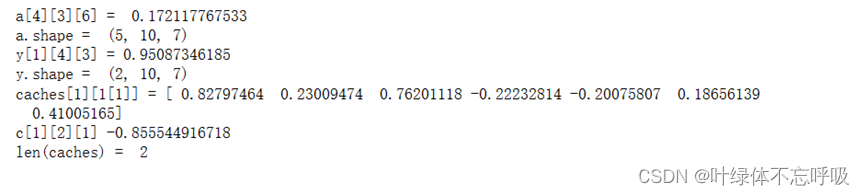
5、RNN单元的前向传播
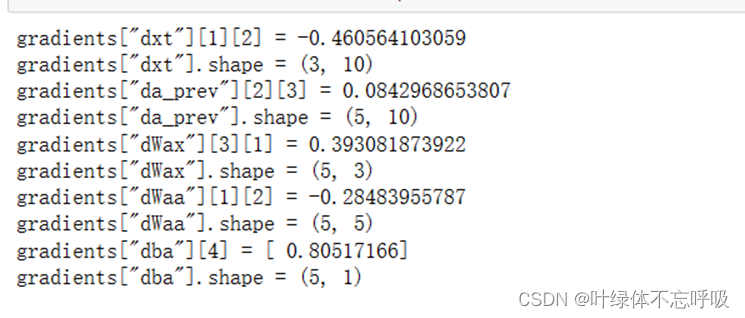
5、RNN反向传播
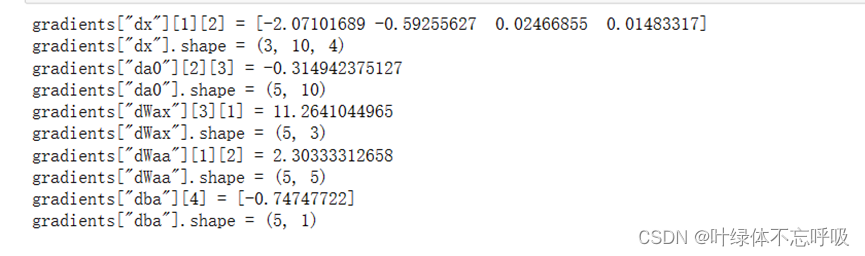
6、LSTM单元的反向传播
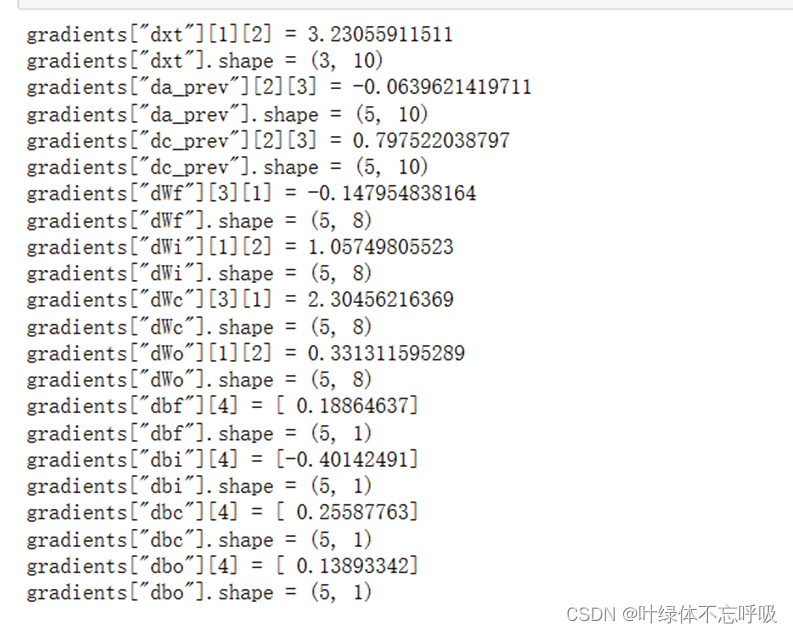
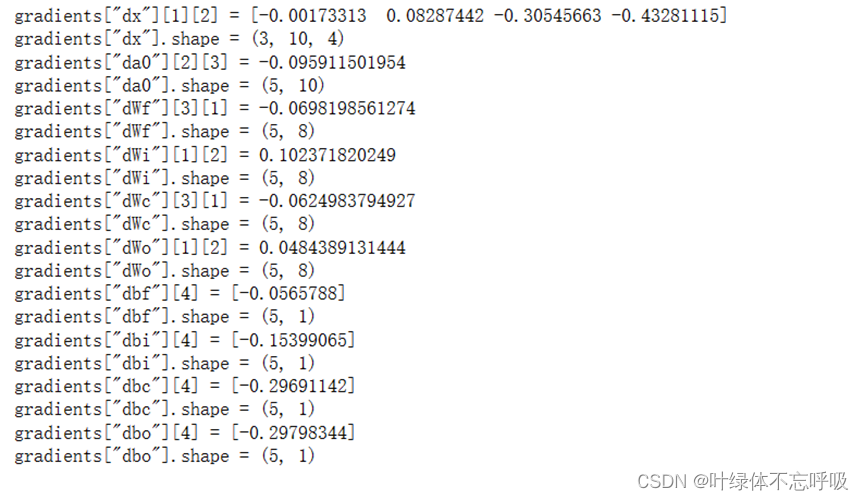
7、LSTM反向传播
Improvise a Jazz Solo with an LSTM Network
1、加载数据集

2、根据输入集,使用模型预测输出

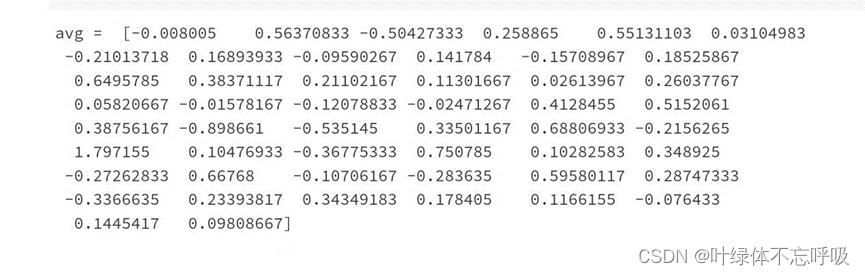
Emojify
1、加载数据集

2、converted_to_one_hot,随意更改index以输出不同的值

3、加载word_to_vec_map
4、实现sentence_to_avg()后使平均值通过正向传播,计算损失,然后反向传播更新softmax的参数

5、训练模型并学习softmax参数(w,b)
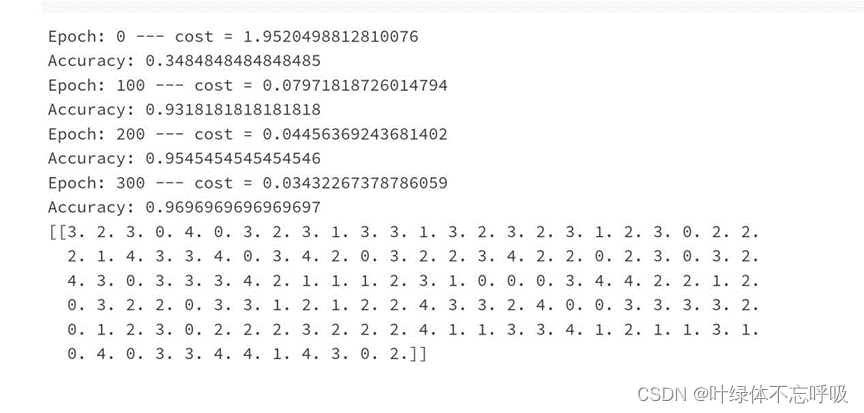
6、检查测试集表现

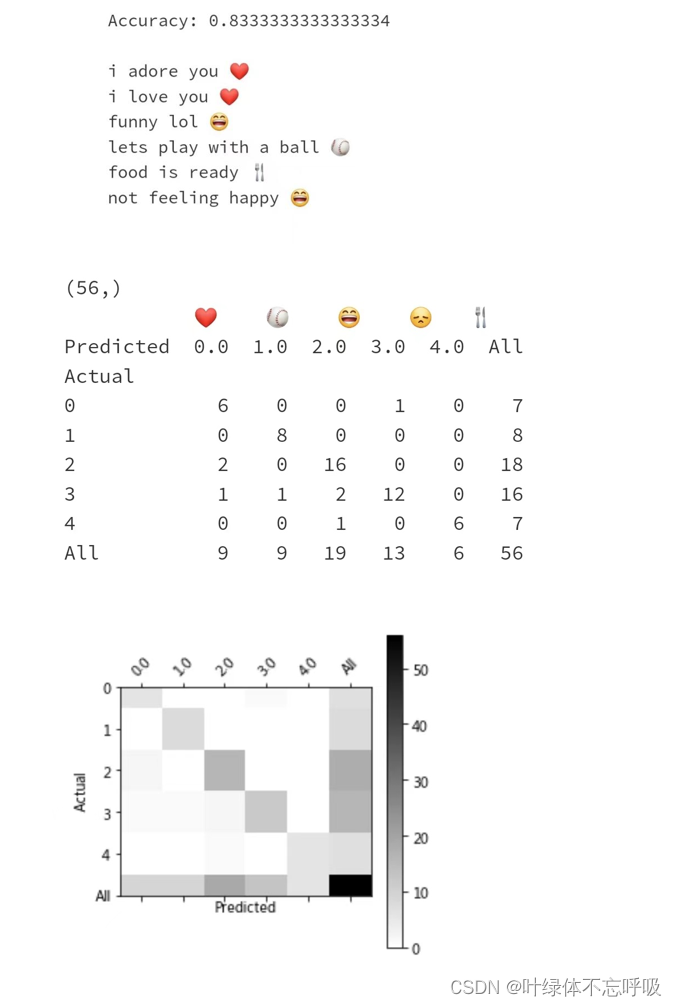
五、 实验结果分析、体会
循环神经网络(RNN)在解决自然语言处理和其他序列任务上非常有效,因为它们具有“记忆”,可以一次读取一个输入(例如单词),并通过从一个时间步传递到下一个时间步的隐藏层激活来记住一些信息/上下文。这使得单向RNN可以提取过去的信息以处理之后的输入。双向RNN则可以借鉴过去和未来的上下文信息循环神经网络在情感分类任务上表现良好,能够有效地捕捉文本序列中的上下文信息。通过合理的参数设置和训练轮次,能够使模型取得较高的准确率。
选择合适的模型架构,如LSTM或GRU,可以根据任务的特点进行调整。
LSTM:LSTM通过引入了一个特殊的记忆单元和三个门来解决梯度消失和长期依赖的问题。LSTM的记忆单元有一个称为“单元状态”的持久记忆,并且由输入门、遗忘门和输出门来控制信息的流动。输入门决定了新的输入将如何影响单元状态,遗忘门决定了旧的单元状态会被多大程度上遗忘,输出门则决定了基于当前输入和单元状态的输出。
GRU:GRU相较于LSTM模型稍微简化了架构,在一些任务中可以保持和LSTM相似的性能。与LSTM类似,GRU也有候选更新和候选重置门。其中,候选更新门决定是否将前一时刻的记忆传递给当前时刻,而候选重置门决定保留多少前一时刻的记忆。相比LSTM,GRU合并了遗忘门和输入门,并且只使用了一个隐藏状态,使得计算复杂度和存储开销都比LSTM低。
如果我们的NLP任务的训练集很小,则使用单词嵌入可以大大帮助你的算法。词嵌入功能使你的模型可以在测试集中甚至没有出现在训练集中的词上使用。
Keras(和大多数其他深度学习框架)中的训练序列模型需要一些重要的细节:
要使用小批量,需要填充序列,以使小批量中的所有示例都具有相同的长度。可以使用预训练的值来初始化Embedding()层。这些值可以是固定的,也可以在数据集中进一步训练。但是,如果我们标记的数据集很小,则通常不值得尝试训练大量预训练的嵌入。
LSTM()具有一个名为return_sequences的标志,用于确定我们是要返回每个隐藏状态还是仅返回最后一个状态。我们可以在LSTM()之后紧接使用Dropout()来规范我们的网络。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- vim一般使用
- # 和 $ 的区别①
- Redis高并发分布式锁
- ZZ014城市轨道交通运营与维护赛题第6套
- 构建、管理和部署基础设施的多种选择 | 开源专题 No.53
- java实现分布式锁
- Linux网络引导自动安装centos7
- node.js(expree.js )模拟手机验证码功能及登录功能
- Lambda表达式??项目中的常见使用方式,通过具体案例总结Lambda的常用写法
- (十一)IIC总线-AT24C02-EEPROM