spark介绍及简单使用
简介
????????Spark是由加州大学伯克利分校AMPLab(AMP实验室)开发的开源大数据处理框架。起初,Hadoop MapReduce是大数据处理的主流框架,但其存在一些限制,如不适合迭代算法、高延迟等。为了解决这些问题,Spark在2010年推出,提供了高效的内存计算和更灵活的数据处理方式。
使用场景:
????????批处理:
????????Spark支持大规模的批处理任务,通过弹性的分布式计算能力,能够处理海量数据。
????????交互式查询:
???????? Spark提供了Spark SQL,使得用户能够使用SQL语言进行交互式查询,方便数据分析师和数据科学家进行数据探索。
????????流处理:
???????? Spark Streaming模块允许实时处理数据,支持复杂的流处理应用。
????????机器学习:
???????? MLlib是Spark的机器学习库,支持分布式机器学习,适用于大规模数据集的训练和预测。
????????图处理:
???????? GraphX是Spark的图处理库,用于处理图数据结构,支持图算法的并行计算。
????????技术竞品:
????????Hadoop MapReduce:Spark的前身,仍然是大数据领域的主流框架之一,但相对而言,Spark更灵活、性能更好。
????????Apache Flink: 与Spark类似,是另一个流处理和批处理框架,强调事件时间处理和精确一次性语义。
????????Apache Storm: 专注于实时流处理,适用于需要低延迟的应用场景。
????????Apache HBase: 针对NoSQL存储,适用于需要实时读写的大数据场景。
优劣势:
????????Spark的优势:
????????高性能: Spark的内存计算引擎可以显著提高计算速度,特别适用于迭代算法和复杂的数据处理任务。
????????易用性: 提供了丰富的API,包括Java、Scala、Python和R等,使得开发者能够使用熟悉的编程语言进行大数据处理。
????????统一的处理框架: Spark支持批处理、交互式查询、流处理、机器学习和图处理等多种数据处理模式,为用户提供了统一的编程接口。
????????生态系统: Spark生态系统包括Spark SQL、MLlib、GraphX等库,丰富的生态系统支持广泛的数据处理应用。

????????Spark的劣势:
????????资源消耗: 由于使用内存计算,Spark对内存的需求较大,需要足够的硬件资源支持。
????????学习曲线: 对于初学者而言,学习Spark可能需要一定的时间,尤其是对于复杂的数据处理任务。
????????实时性: 尽管Spark Streaming支持实时处理,但相较于专注于实时处理的框架,实时性可能稍逊一筹。
在选择大数据处理框架时,需要考虑具体的业务需求和场景,综合考虑各个框架的优劣势来做出合适的选择。
spark的shell使用
? ? ? ? 本文在hadoop for spark 集群环境下进行演示,当你启动集群的所有工作程序包括spark程序在内,可以使用spark-shell指令在任意一个节点进入到spark交互命令行中
? ? ? ? spark-shell 后置参数解释
- -I <file>:预加载<file>,强制逐行解释。
- --master MASTER_URL:指定Spark的主节点URL,可以是spark://host:port, mesos://host:port, yarn, k8s://https://host:port, 或者 local。
- --deploy-mode DEPLOY_MODE:指定驱动程序的部署模式,可以是本地("client")或者集群中的工作节点("cluster")。
- --class CLASS_NAME:指定应用程序的主类(适用于Java / Scala应用程序)。
- --name NAME:指定应用程序的名称。
- --jars JARS:指定要包含在驱动程序和执行器类路径中的jar文件,用逗号分隔。
- --packages:指定要包含在驱动程序和执行器类路径中的maven坐标的jar文件,用逗号分隔。
- --exclude-packages:指定在解析--packages提供的依赖项时要排除的groupId:artifactId,用逗号分隔。
- --repositories:指定要搜索--packages给出的maven坐标的额外远程仓库,用逗号分隔。
- --py-files PY_FILES:指定要放在PYTHONPATH上的.zip, .egg, 或 .py文件,用逗号分隔。
- --files FILES:指定要放在每个执行器的工作目录中的文件,用逗号分隔。
- --archives ARCHIVES:指定要解压到每个执行器的工作目录中的归档文件,用逗号分隔。
- --conf, -c PROP=VALUE:指定Spark的配置属性。
- --properties-file FILE:指定要从中加载额外属性的文件路径。
- --driver-memory MEM:指定驱动程序的内存(例如1000M, 2G)。
- --driver-java-options:指定要传递给驱动程序的额外Java选项。
- --driver-library-path:指定要传递给驱动程序的额外库路径。
- --driver-class-path:指定要传递给驱动程序的额外类路径。
- --executor-memory MEM:指定每个执行器的内存(例如1000M, 2G)。
- --proxy-user NAME:指定提交应用程序时要模拟的用户。
- --help, -h:显示帮助信息并退出。
- --verbose, -v:打印额外的调试输出。
- --version:打印当前Spark的版本。????????进入spark交互页面,这里有三个方法进入spark的交互环境,不同的语言环境,其提示符也有所不同。
##默认scala语言环境
spark-shell --master local
##使用python语言环境
pyspark
##使用R语言环境
sparkR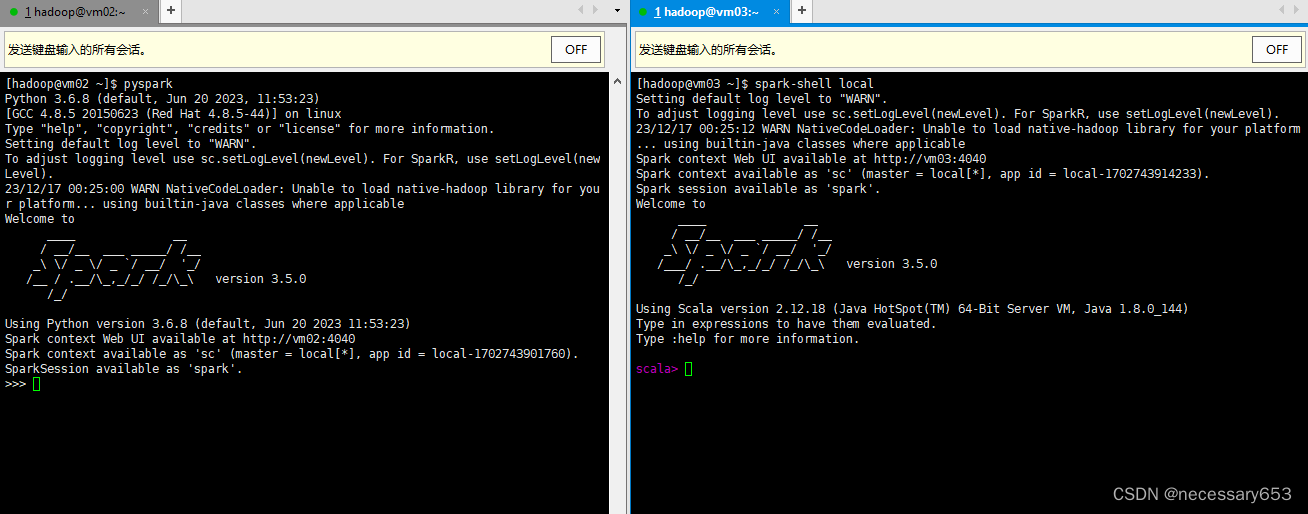
spark-shell中的使用范例?
? ? ? ? 在/home/hadoop 目录下创建一个wordcount.txt,文件内容如下。
????????
spark-shell进入scala交互页面
读取文件内容、统计内容行数、取首行数据。
scala> val textFile = sc.textFile("file:///home/hadoop/wordcount.txt")
textFile: org.apache.spark.rdd.RDD[String] = file:///home/hadoop/wordcount.txt MapPartitionsRDD[1] at textFile at <console>:23
scala> textFile.count()
res0: Long = 3
scala> textFile.first()
res1: String = hello you
?????????scala在使用方法上还是和java有几分类似。在linux的交互行上,也可以实现像idea上的联想功能
scala> val textFile = sc.textFile("file:///home/hadoop/wordcount.txt")
textFile: org.apache.spark.rdd.RDD[String] = file:///home/hadoop/wordcount.txt MapPartitionsRDD[3] at textFile at <console>:23
scala> textFile.
++ countApprox getCheckpointFile mapPartitionsWithEvaluator reduce toDebugString
aggregate countApproxDistinct getNumPartitions mapPartitionsWithIndex repartition toJavaRDD
barrier countAsync getResourceProfile max sample toLocalIterator
cache countByValue getStorageLevel min saveAsObjectFile toString
canEqual countByValueApprox glom name saveAsTextFile top
cartesian dependencies groupBy partitioner setName treeAggregate
checkpoint distinct id partitions sortBy treeReduce
cleanShuffleDependencies filter intersection persist sparkContext union
coalesce first isCheckpointed pipe subtract unpersist
collect flatMap isEmpty preferredLocations take withResources
collectAsync fold iterator productArity takeAsync zip
compute foreach keyBy productElement takeOrdered zipPartitions
context foreachAsync localCheckpoint productIterator takeSample zipPartitionsWithEvaluator
copy foreachPartition map productPrefix toDF zipWithIndex
count foreachPartitionAsync mapPartitions randomSplit toDS zipWithUniqueId ? ? ? ? 定义好一个参数的路径时,可以使用TAB键进行联想,后面就会弹出可使用的相关函数。函数的命令及其功能,在博主看来甚至和SQL相似,只是使用方法上不同。
????????Spark在ideal中的使用
????????先创建一个maven
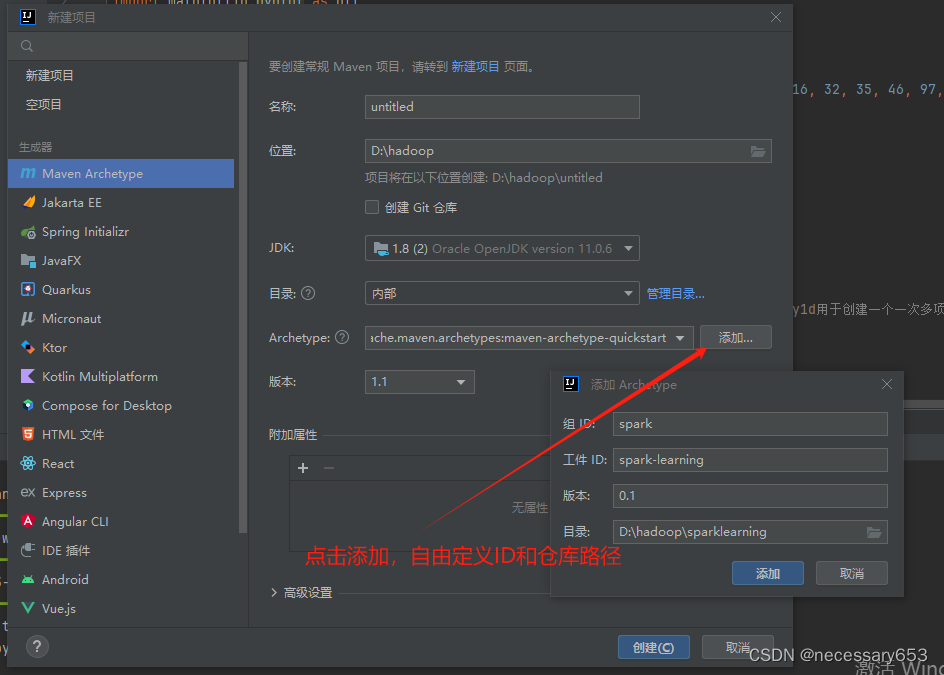
pom.xml添加spark相关依赖(<groupId>org.apache.spark</groupId>)groupID为spark的项目即可,以下为博主的依赖选择。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>hadooplearn</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>11</maven.compiler.source>
<maven.compiler.target>11</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.3</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.4.3</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.4.3</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>2.4.3</version>
</dependency>
</dependencies>
</project>?spark的使用范例
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 我的创作纪念日
- 拍立淘API:电商搜索引擎进入图像识别新时代
- WPF HandyControl 界面交互反馈:对话框+加载框+列表选择
- 10 大优秀好用的文件恢复软件
- 微擎模块 出现Error: template source ‘common/message’ is not exist!解决方法
- 你好2024!
- (8-5-5)制作美股交易策略模型:使用有效前沿技术优化投资组合
- 魅族MX4pro系统升级、降级
- 大干100天,0基础自学转行软件测试,我整理的超全学习指南!
- Inverse Factorial