【损失函数】Cross Entropy Loss 交叉熵损失
发布时间:2024年01月03日
?1、介绍
????????主页介绍的几种损失函数都是适用于回归问题损失函数,对于分类问题,最常用的损失函数是交叉熵损失函数 Cross Entropy Loss。它用于测量两个概率分布之间的差异,通常用于评估分类模型的性能。
2、公式
对于二分类问题,交叉熵损失的一般形式为:
其中, 是样本数量,
?是实际标签,
?是模型的预测概率。
对于多分类问题,交叉熵损失的一般形式为:
其中, 是样本数量,
?是类别数量,
?是实际标签的独热编码(one-hot encoding),
? 是模型对类别
的预测概率。
3、图像
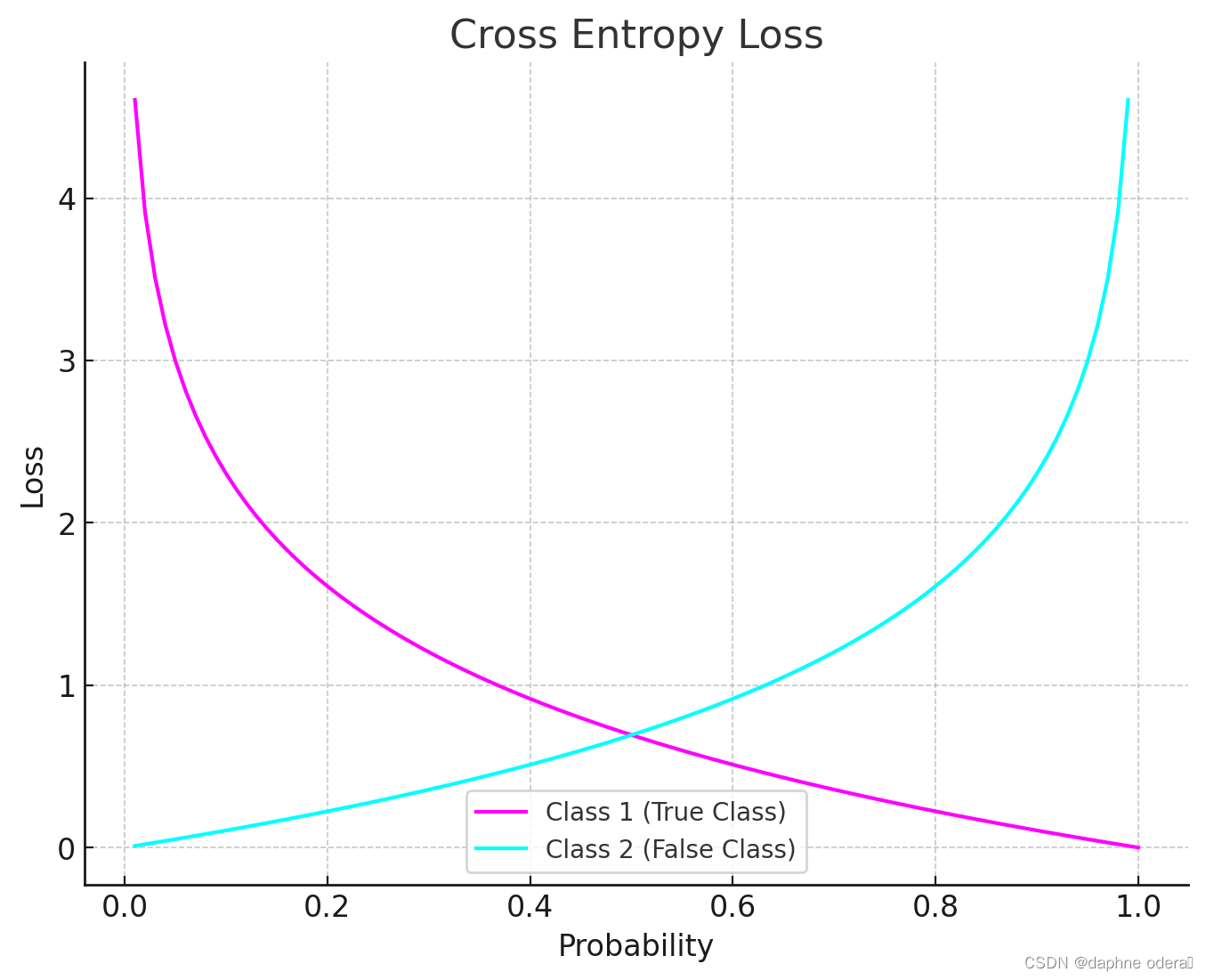
? ? ? ? 上图是交叉熵损失(Cross Entropy Loss)的图像。图中展示了两个类别(真实类别和错误类别)的概率与损失之间的关系,可以看到约接近目标值损失越小,随着误差变差,损失呈指数增长。
4、实例
假设我们有以下情况:我们正在训练一个模型来进行三种实例的分类,此时有100个待测样本。
我们使用?CrossEntropyLoss?作为损失函数:
import torch
import torch.nn as nn
# 示例数据
torch.manual_seed(42)
num_classes = 3
num_samples = 100
y_true = torch.randint(0, num_classes, (num_samples,))
y_pred_logits = torch.randn(num_samples, num_classes)
# 定义交叉熵损失函数
criterion = nn.CrossEntropyLoss()
# 计算损失
loss = criterion(y_pred_logits, y_true)
print(f'Cross Entropy Loss: {loss.item()}')??????在这个例子中,y_pred_logits 是模型的输出,它包含了对每个类别的未归一化的预测值。y_true 是实际标签。通过传递这两者给 CrossEntropyLoss,可以计算交叉熵损失。在实际训练中,您可能需要结合优化器来更新模型的权重以减小损失。
5、参考
文章来源:https://blog.csdn.net/Next_SummerAgain/article/details/135372528
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!