通过回答自然语言问题进行事件抽取(EMNLP2020)
发布时间:2024年01月04日

1、写作动机:
以往的事件抽取方法都基于神经网络模型抽取的密集特征和预训练语言模型的上下文表示。但是,它们(1)严重依赖实体识别进行事件论元抽取,特别是通常需要采用多步骤方法来进行事件论元抽取。(2)忽略了不同论元角色间的语义相似性。
2、主要贡献:
1)针对事件抽取任务首次提出了一种新的范式——将其表述为问答(QA)/机器阅读理解(MRC)任务。
2)设计了用于触发检测的固定问题模板和用于抽取每个论元角色的各种问题模板。
3、优点:
(1)该方法不需要实体标注(黄金信息或预测的实体信息)。更具体地说,它是采用端到端模型进行事件论元抽取,不需要实体识别的任何预处理步骤。
(2)问答范式能够学习不同模型中语义相似的论元角色而进行事件论元抽取。
4、模型:
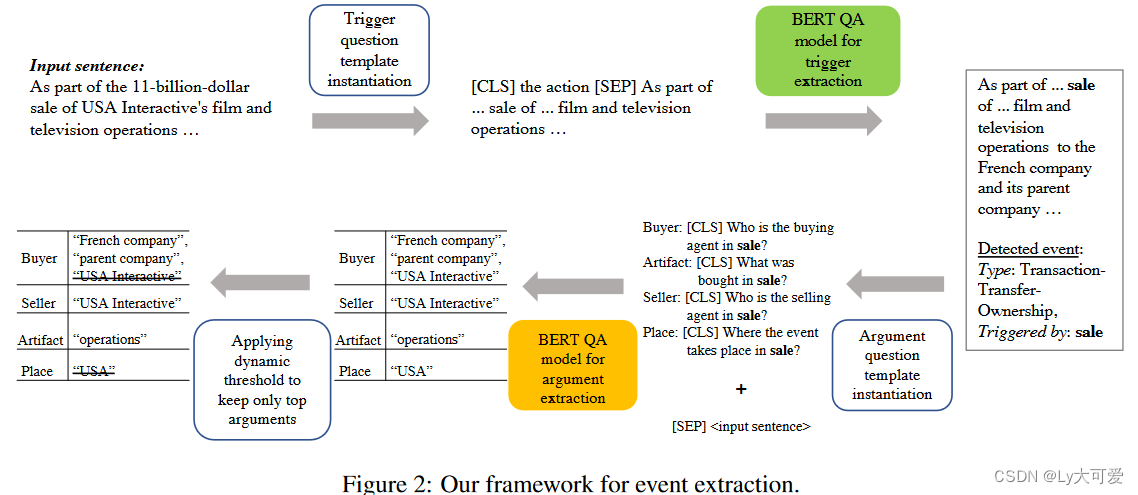
4.1提问策略:
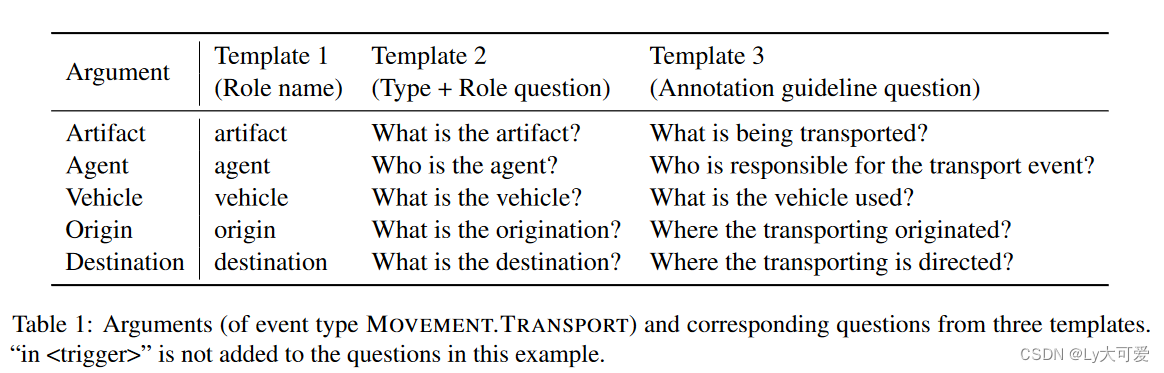
4.2问答模型:
使用BERT(Devlin et al., 2019)作为基础模型,BERT_QA_Trigger预测句子中每个token的类型,而BERT_QA_Arg预测论元范围的开始和结束偏移量。
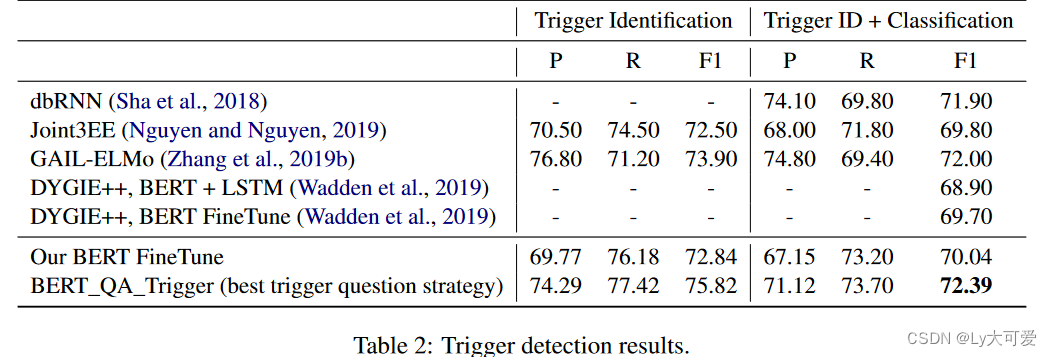
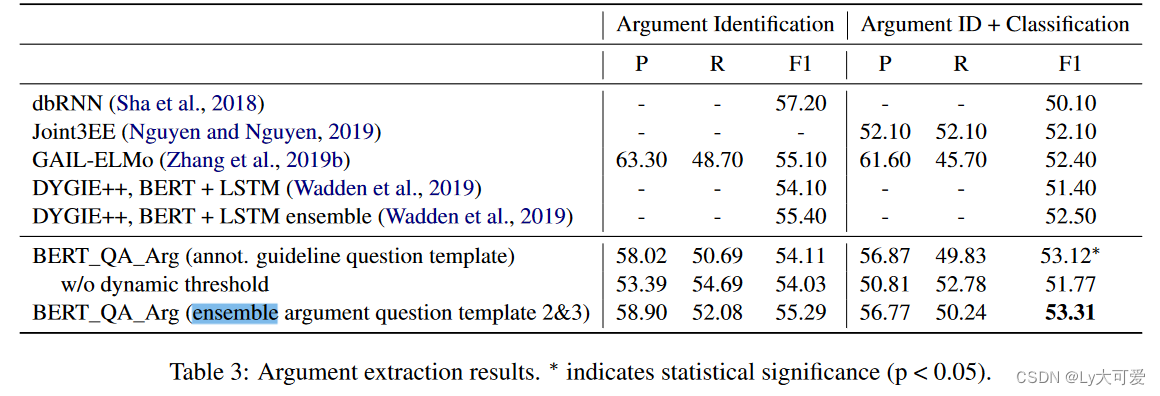
5、实验:
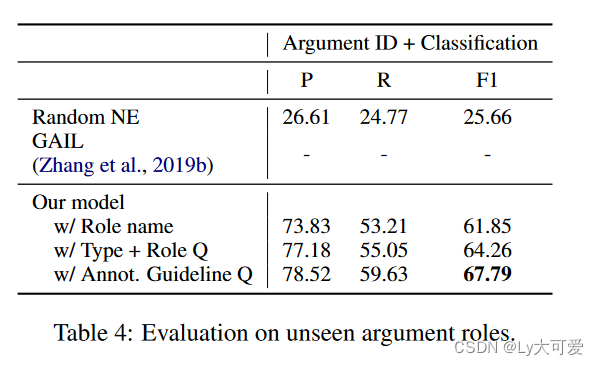
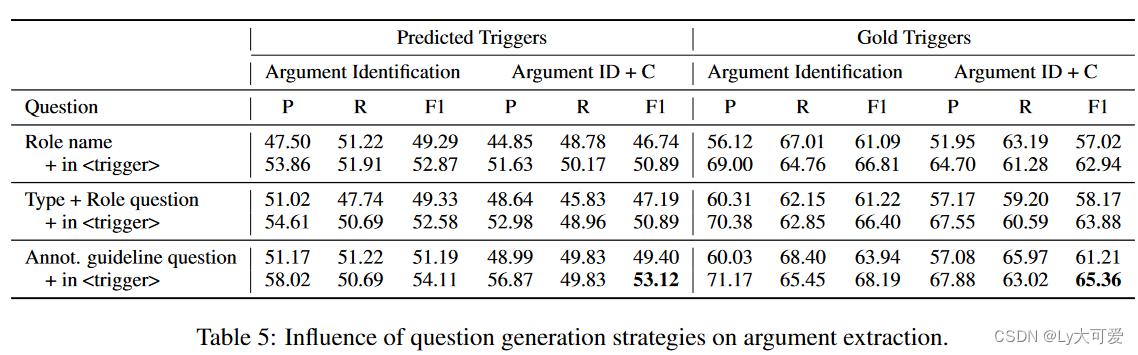
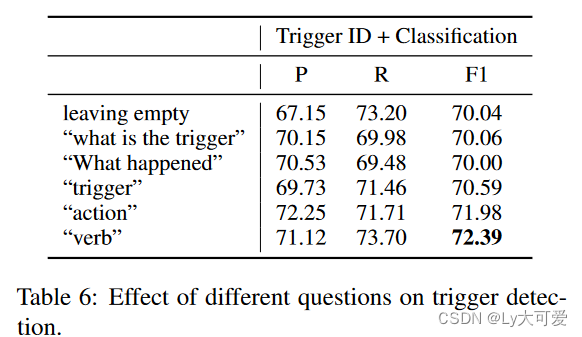
6、错误分析:
1)缺乏获取论元范围的精确边界的知识。例如,在“Negotiations between Washington and Pyongyang on their nuclear dispute have been set for April 23 in Beijing …”中,对于ENTITY角色,应抽取两个论点范围(“Washington”和“Pyongyang”)。
2)缺乏文档级上下文的推理。
3)数据和词汇稀疏性.
文章来源:https://blog.csdn.net/weixin_45785795/article/details/135352194
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【OSG案例详细分析与讲解】之十:【骨骼动画】
- vue3中使用elementplus中的el-tree-select,自定义显示名称label
- ELFK日志收集
- Todesk突然高速通道使用已结束
- Unity Shader 开发入门3 —— 坐标空间变换
- 请求转发和重定向的区别
- 校园全面圈子社交论坛系统------交友,刷题,二手,实名,陪玩,APP小程序H5三端源码交付,支持二开!
- Wilcoxon秩和检验-校正P值(自备)
- 一文搞懂 java8 reduce操作
- 喜闻蜚语获得数千万元Pre-A+轮融资