ReTree:扩散模型 + 视网膜图像生成
?
核心思想
论文链接:https://arxiv.org/abs/2308.08339
代码链接:https://github.com/AAleka/retree
在视网膜图像合成方面表现优于传统的生成对抗网络(GAN)。

- EyeQ数据集中的真实视网膜图像(左侧)
- 生成的视网膜图像(右侧)
模型 分为两阶段。
- 第一阶段是生成血管树,它基于标准正态分布的随机数。
- 第二阶段是引导模型根据给定的血管树和随机分布来生成眼底图像。
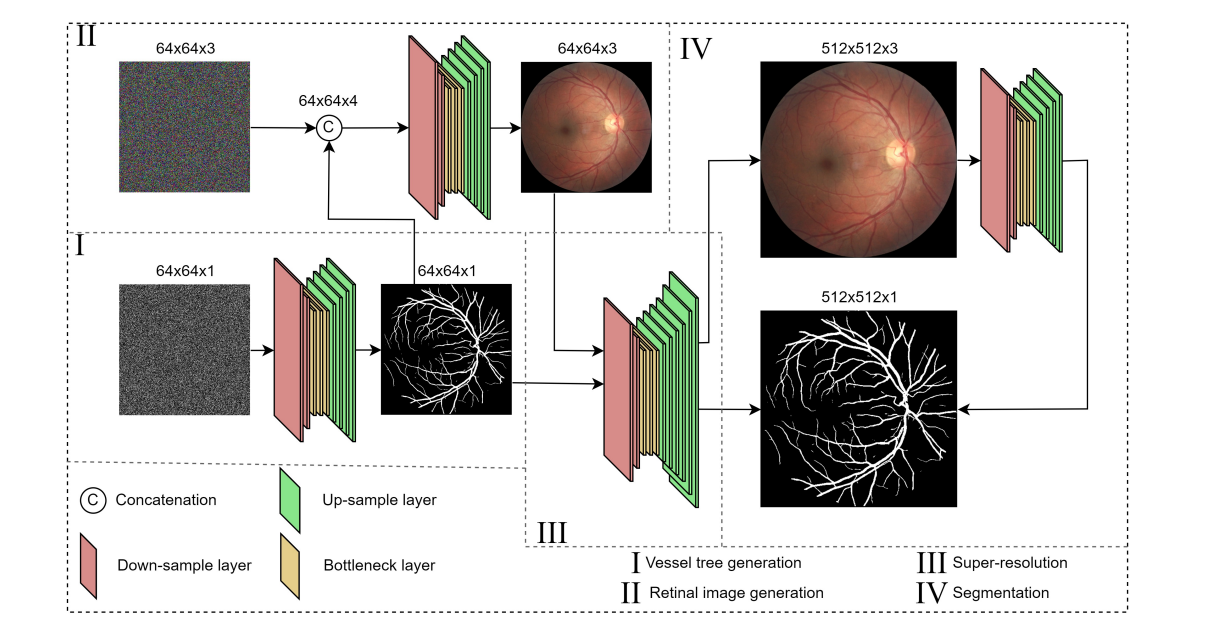
- 血管树生成:首先,利用去噪扩散概率模型(DDPM)从噪声中生成血管树。
- 视网膜图像生成:接着,另一个DDPM学习如何根据血管树和相应的语义标签图来生成视网膜图像。
- 超分辨率:然后,对生成的血管树图像执行超分辨率处理,以增加图像的分辨率。
- 分割:最后,利用生物医学分割模型对生成的并经过上采样的视网膜图像进行分割以进行验证。
网络结构
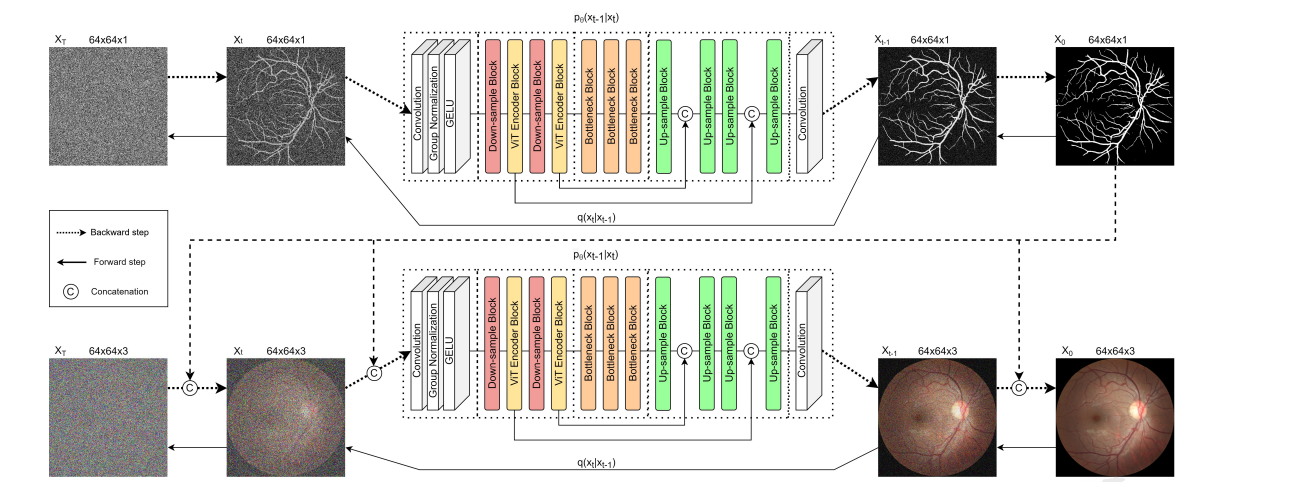
两个DDPM模型和ta们在生成视网膜图像过程中的作用:
- 第一个模型(上半部分):这个模型负责生成语义标签图。
- 它从包含噪声的图像XT开始,在给定的时间步长内通过添加高斯噪声模拟前向扩散过程(向左的箭头表示前向步骤),然后再通过DDPM去除噪声模拟后向过程(向右的箭头表示后向步骤),最终输出一个去噪后的血管树图X1。
- 第二个模型(下半部分):它采用第一个模型输出的血管树图X1和包含噪声的RGB图像XT,通过相同的前向扩散和后向去噪过程,生成最终的去噪后的彩色视网膜图X0。
每个模型都包含以下部分:
- 下采样层(Down-sample Block):用于减少图像的空间维度,从而在更小的维度上捕获特征。
- ViT编码器(ViT Encoder Block):利用Vision Transformer对特征进行编码。
- 瓶颈层(Bottleneck Block):在模型的中心点处理特征,可能是为了进一步提炼它们。
- 上采样层(Up-sample Block):将图像的空间维度增加回原始尺寸。
在每个扩散步骤t,模型都会预测给定扩散步骤t-1的输出。
每个DDPM模型的输出都用作下一步的输入。
在第一个模型中,血管树图像与带噪声的输入进行了连接(Concatenation),在第二个模型中,彩色视网膜图像与带噪声的输入进行了连接。
整个流程展示了一个完整的数据生成和处理流程:
- 从带有高斯噪声的图像开始,经过一系列的处理步骤,最终生成清晰的血管树图像和对应的彩色视网膜图像。
?
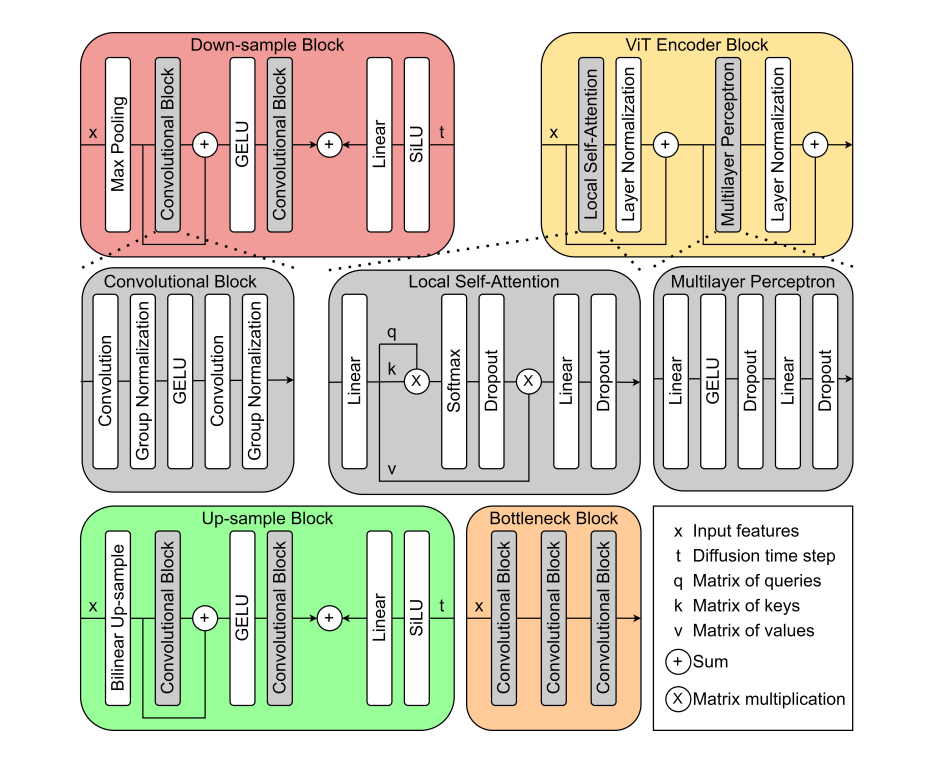
去噪扩散概率模型(DDPM)的架构,由四个主要部分组成:下采样块、ViT编码器块、上采样块和瓶颈块。
- 下采样块(红色区域):包括最大池化层(Max Pooling)、两个卷积层(Convolutional Block)、GELU激活函数、一个线性层(Linear),以及Sigmoid Linear Unit(SiLU)激活函数。
- 这个块的目的是减少输入特征的空间维度(即降低图像的分辨率),同时保留重要的特征信息。
- ViT编码器块(黄色区域):结合了局部自注意力机制(Local Self-Attention)、层归一化(Layer Normalization)和多层感知机(Multilayer Perceptron)。
- 这一部分的目的是捕捉输入特征之间的复杂关系,并增强模型对输入数据的理解。
- 上采样块(绿色区域):使用双线性上采样(Bilinear Up-sample)和两个卷积块,以及加法操作和SiLU激活函数。
- 这个块的作用是将降低分辨率后的特征图像恢复到更高的分辨率。
- 瓶颈块(蓝色区域):由三个连续的卷积块组成。
- 这个块位于模型的中心,用于进一步处理和提纯特征。
图中还展示了各个部分的输入和输出关系,以及其中使用的矩阵乘法(×)和加法(+)操作。
例如,在ViT编码器块中,q(查询矩阵)、k(键矩阵)和v(值矩阵)参与了矩阵乘法和Softmax操作以实现自注意力机制。
在整个模型中,t表示扩散时间步,它在模型的不同阶段被用来调整输入特征和生成的时间嵌入。
损失函数
-
DDPM的损失函数:DDPM使用了两种损失函数的组合,即L1损失(或称平均绝对误差MAE)和均方误差(MSE)。
这两种损失函数用于计算预测噪声和实际应用噪声之间的差异
GenLoss ( ? θ ( x t , t ) , z ) = 1 N ∑ i = 1 N ( ∣ ? θ ? z ∣ + ( ? θ ? z ) 2 ) \text{GenLoss}(\epsilon_{\theta}(x_t, t), z) = \frac{1}{N}\sum_{i=1}^{N}(|\epsilon_{\theta} - z| + (\epsilon_{\theta} - z)^2) GenLoss(?θ?(xt?,t),z)=N1?∑i=1N?(∣?θ??z∣+(?θ??z)2)
N是图像像素的总数, ? θ \epsilon_{\theta} ?θ? 是预测的噪声,z是实际应用的噪声。
-
超分辨率模型的损失函数:超分辨率模型使用了五种损失函数的组合,包括L1损失、结构相似性指数(SSIM)、对抗损失、二元交叉熵(BCE)和感知损失。
SSIM用于计算两幅图像之间的结构相似性:
SSIM ( X , Y ) = ( 2 μ X μ Y + C 1 ) ( 2 σ X Y + C 2 ) ( μ X 2 + μ Y 2 + C 1 ) ( σ X 2 + σ Y 2 + C 2 ) \text{SSIM}(X, Y) = \frac{(2\mu_X\mu_Y + C1)(2\sigma_{XY} + C2)}{(\mu_X^2 + \mu_Y^2 + C1)(\sigma_X^2 + \sigma_Y^2 + C2)} SSIM(X,Y)=(μX2?+μY2?+C1)(σX2?+σY2?+C2)(2μX?μY?+C1)(2σXY?+C2)?
μ \mu μ 是均值, σ \sigma σ 是方差,C1和C2是稳定除法的变量。
SSIMLoss ( X , Y ) = 1 ? SSIM ( X , Y ) 2 \text{SSIMLoss}(X, Y) = 1 - \frac{\text{SSIM}(X, Y)}{2} SSIMLoss(X,Y)=1?2SSIM(X,Y)?
-
对抗损失:对抗损失使用鉴别器模型的输出计算,鉴别器模型负责将输入图像分类为真实或伪造。
鉴别器模型的损失函数定义如下:
AdvLoss ( Y , X ) = ? E Y [ log ? ( 1 ? D ( Y , X ) ) ] ? E X [ log ? ( D ( Y , X ) ) ] \text{AdvLoss}(Y, X) = -\mathbb{E}_Y[\log(1 - D(Y, X))] - \mathbb{E}_X[\log(D(Y, X))] AdvLoss(Y,X)=?EY?[log(1?D(Y,X))]?EX?[log(D(Y,X))]
D ( x r , x f ) D(x_r, x_f) D(xr?,xf?) 是鉴别器模型给出的预测。
-
感知损失:感知损失使用VGG19网络测量激活特征之间的距离,并使用MSE损失函数最小化该距离。
-
分割模型的BCE损失:分割模型使用二元交叉熵损失训练。
BCELoss = ? 1 N ∑ i = 1 N ( x i t ? 1 log ? ( x θ i t ? 1 ) + ( 1 ? x i t ? 1 ) log ? ( 1 ? x θ i t ? 1 ) ) \text{BCELoss} = -\frac{1}{N}\sum_{i=1}^{N}(x_{it-1}\log(x_{\theta_{it-1}}) + (1 - x_{it-1})\log(1 - x_{\theta_{it-1}})) BCELoss=?N1?∑i=1N?(xit?1?log(xθit?1??)+(1?xit?1?)log(1?xθit?1??))
N代表图像中的像素数。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 外汇天眼:每一个骗局的背后,可能是倾家荡产!
- 一键在线获取APP公钥、包名、签名及备案信息方法介绍
- .nfsxxxxxx文件无法删除
- three.js: gltf模型设置发光描边
- [晓理紫]每日论文分享(有中文摘要,源码或项目地址)--大模型、扩散模型、视觉导航
- 数据结构-八大排序详解(动图+实现详解+总结)
- QVector应用大全
- SpringBoot连接mysql数据库相关配置(druid连接池)
- Jmeter 性能-监控服务器
- leedcode刷题笔记day1