机器学习(八) — K-means
model 5 — K-means
1 definition
- randomly initialize K cluster centroids μ 1 , μ 2 , ? \mu_1, \mu_2, \cdots μ1?,μ2?,?
- repeat:
- assign each point to its closest centroid μ \mu μ
- recompute the centroids(average of the closest point)
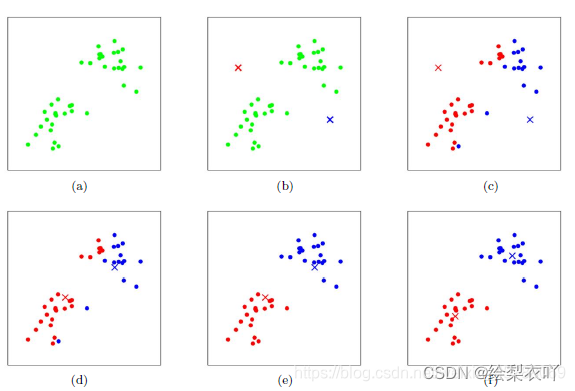
2 optimazation objective
- c ( i ) c^{(i)} c(i) = index of cluster to which example x ( i ) x^{(i)} x(i) is currently assigned
- μ k \mu_k μk? = cluster centroid k
- μ c ( i ) \mu_{c^{(i)}} μc(i)? = cluster centroid of cluster to which example x ( i ) x^{(i)} x(i) has been assigned
J = 1 m ∑ i = 1 m ∥ x ( i ) ? μ c ( i ) ∥ J = \frac{1}{m} \sum_{i=1}^m \| x^{(i)} - \mu_{c^{(i)}} \| J=m1?i=1∑m?∥x(i)?μc(i)?∥
3 randomly initialization
for i = 1 to n(usually 50 to 1000)
randomly initialize K-means
run K-means
compute cost function
pick set of clusters that give the lowest cost
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Mysql5.7版本中,查询分组GROUP BY通过子查询中ORDER BY进行排序无效的问题解决办法
- 牛客周赛 Round 22 解题报告 | 珂学家 | 思维构造 + 最小生成树
- 【深度学习】序列生成模型(四):评价方法
- 【笔记】关于期刊
- HTTP协议
- T+1 到秒级实时性提升,Apache Doris 在中国邮政储蓄银行金融反欺诈领域的应用探索
- 数据结构——双链表
- ABAP IDOC 相关报表
- ubuntu图形化登录默认只有guest session账号解决方法
- Springboot整合MQ学习记录