flask_apscheduler源码分析
前言
? ? 遵循flask框架的标准的库,都称为flask扩展,flask_apscheduler是对apscheduler的扩展,也称为flask的扩展,最近使用flask_apscheduler遇到了一个job死亡的bug。现象:job平时是正常启动的,突然某个时刻全部挂了。。
环境介绍
官方文档:https://viniciuschiele.github.io/flask-apscheduler/
? ? 当前分析版本:1.12.4
? ? 安装方式:pip install Flask-APScheduler
? ? 源码位置:site-packages目录下
? ??
包结构介绍?

? ? flask_apscheduler是个包模块,包括__init__.py,共计6个模块
加载顺序
from flask_apscheduler import APScheduler
?一般情况下,我们会在flask程序中,写下如上一行,此时flask_apscheduler的__init__.py中没有缩进的代码开始执行
__init__.py分析
from apscheduler.schedulers.base import STATE_PAUSED, STATE_RUNNING, STATE_STOPPED
from .scheduler import APScheduler主要做了两件事
1、从标准库apscheduler下的base模块中,导入几个全局变量
2、从当前包下的scheduler模块中导入APScheduler类
scheduler模块分析
我们主要分析的是flask_apscheduler包模块下的scheduler.py模块

?看了下这个scheduler.py模块共计400多行,我觉得还行
scheduler分析过程一:模块导入
import flask import functools import logging import socket import warnings import werkzeug from apscheduler.events import EVENT_ALL from apscheduler.schedulers.background import BackgroundScheduler from apscheduler.jobstores.base import JobLookupError from flask import make_response from . import api from .utils import fix_job_def, pop_trigger
总体的导入分3部分
1、标准库的导入
functools、logging、socket、warnings、apscheduler(重点依赖这个标准库)
2、第三方库
flask、werkzeug
3、自己写的模块
api、utils
整体说明:作者同时使用了标准库、比如logging用于日志打印的标准库,还有地方依赖库,当然是flask和werkzeug(flask依赖的底层网络库)、还有自己写的两个模块,api和utils。。
最最最重要的apscheduler的使用,尤其是导入BackgroundScheduler这个类
scheduler分析过程二:创建日志分析对象
LOGGER = logging.getLogger('flask_apscheduler')
?scheduler分析过程三:创建APScheduler类
class APScheduler(object):? ? ? ? ?…………省略…………
?这个APScheduler创建的对象,是以后我们经常用的对象,作为整个模块的业务逻辑入口,后续单独开篇文章介绍这个类的封装。
初步总结
? ??scheduler就干了3件事、导入模块、创建日志分析对象、创建APScheduler类。
继续分析当前包模块

上面已经分析了__init__.py模块、还有scheduler.py模块,还记得scheduler.py下面这两句代码吗?
from . import api
from .utils import fix_job_def, pop_trigger
我们将继续分析api模块和utils模块,因为这俩模块先后加载到内存中了
api模块分析
scheduler.py模块加载的时候,导入了api.py模块,此时api.py模块没有缩进代码将会被执行
api模块分析过程一:模块导入
import logging from apscheduler.jobstores.base import ConflictingIdError, JobLookupError from collections import OrderedDict from flask import current_app, request, Response from .json import jsonify
?过程也是3部分
1、导入标准库(导入过的不会重复导入,所以这里写了也没事,内存中是同一个模块对象)
logging、apscheduler、collections模块
2、导入第三方库
flask
3、导入自己写的模块
json
api模块分析过程二:创建函数

1、连续创建了9个函数对象
2、且他们都与flask应用对象有所关联,我给找其中一个函数给大伙看看
def add_job():
"""Adds a new job."""
data = request.get_json(force=True)
try:
job = current_app.apscheduler.add_job(**data)
return jsonify(job)
except ConflictingIdError:
logging.warning(f'Job {data.get("id")} already exists.')
return jsonify(dict(error_message='Job %s already exists.' % data.get('id')), status=409)
except Exception as e:
logging.error(e, exc_info=True)
return jsonify(dict(error_message=str(e)), status=500)
add_job,通过找个函数我们随时向调度器中添加一个job,可以说是一种动态添加job的方式!!
current_app 表示当前flask对象
current.apscheduler表示与之关联的Scheduler对象
return jsonify(job) 最终竟然也返回了一个响应,这是为啥呢?原来是flask_apscheduler给我们留的后门!!
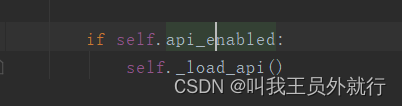
在Scheduler类中,有个方法,是在框架中唯一使用这些api模块中的函数的地方

开关在这里,原来我们可以通过SCHEDULER_API_ENABLED,这样的flask配置修改是否开启快捷开关,这里不看源码,是肯定不知道有这个后门的,看来我也要开启了

 ?
?
初步总结
? ? api模块中的函数,可以在当前flask应用注册路由,那样我们通过http请求,就能操作job了,非常的方便debug呀,爽..
utils模块分析
 ?
?
? ? 这个模块,看名字就知道是工具模块了,我们看看这个模块加载的时候干了什么
utils.py模块分析过程一:模块导入
import dateutil.parser import six from apscheduler.triggers.cron import CronTrigger from apscheduler.triggers.date import DateTrigger from apscheduler.triggers.interval import IntervalTrigger from collections import OrderedDict
?1、标准库
collections
apscheduler
2、第三方库
dateutil
six
utils.py模块分析过程二:创建几个函数

作者真是代码写的干净利索啊,牛逼,这几个函数要工具相关,比如job转为字典,看来是来兜底用的模块,厉害,抽空看看几个函数具体是干啥的
json模块分析

?
json模块分析过程一:模块导入
from __future__ import absolute_import import datetime import flask from apscheduler.job import Job from .utils import job_to_dict import json # noqa
1、标准库
__future__
datetime
apscheduler
json
2、 三方库
flask
看来这个模块主要是操作json格式的
json模块分析过程二:创建全局变量
loads = json.loads
?拿来注意体现的好啊,创建一个loads全局变量,指向的是json模块下的loads函数,这样以后用这个函数就轻松了……
json模块分析过程三:创建函数
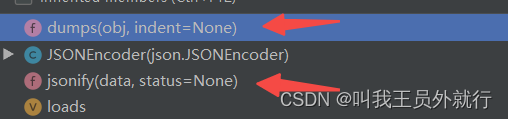
创建的dumps函数和jsonify函数?
json模块分析过程四:创建类
class JSONEncoder(json.JSONEncoder):
def default(self, obj):
if isinstance(obj, datetime.datetime):
return obj.isoformat()
if isinstance(obj, Job):
return job_to_dict(obj)
return super(JSONEncoder, self).default(obj)
创建了一个用于编解码json的类
剩下的auth.py模块分析
 ?
?
剩下一个auth.py模块,我没找到该模块加载的位置,不知道在哪用的。。。。
总结
1、flask_apschduler依赖标准库apschduler、只不过做了一个与flask对象上下文的结合
2、比如可以通过flask的路径,直接创建job、删除job、甚至查看job状态(但是感觉不安全啊)
3、可以继续深入到模块中的Scheduler类中继续分析,可以看到job是有挂掉的可能的。
4、看源码收获每次都是满满的,爽。。。?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 算法刷题——最大字符串配对数目(力扣)
- c 语言学习:输出阶乘的算式
- IDEA GitHub令牌原理(Personal Access Token)
- Java虚拟机中的垃圾回收
- 基于JAVA+SSM+VUE的前后端分离的大学竞赛管理系统
- 基于web的客户关系管理系统的设计与实现(论文+源码)_kaic
- MYSQL数据库的备份与恢复-数据库实验七
- 鸿蒙OS应用开发之时间选择
- Temporary failure in name resolution
- 【数据恢复篇】WinHex数据擦除功能