快速排序挖坑法
发布时间:2024年01月07日
我们先来感受一下挖坑法的思路:?
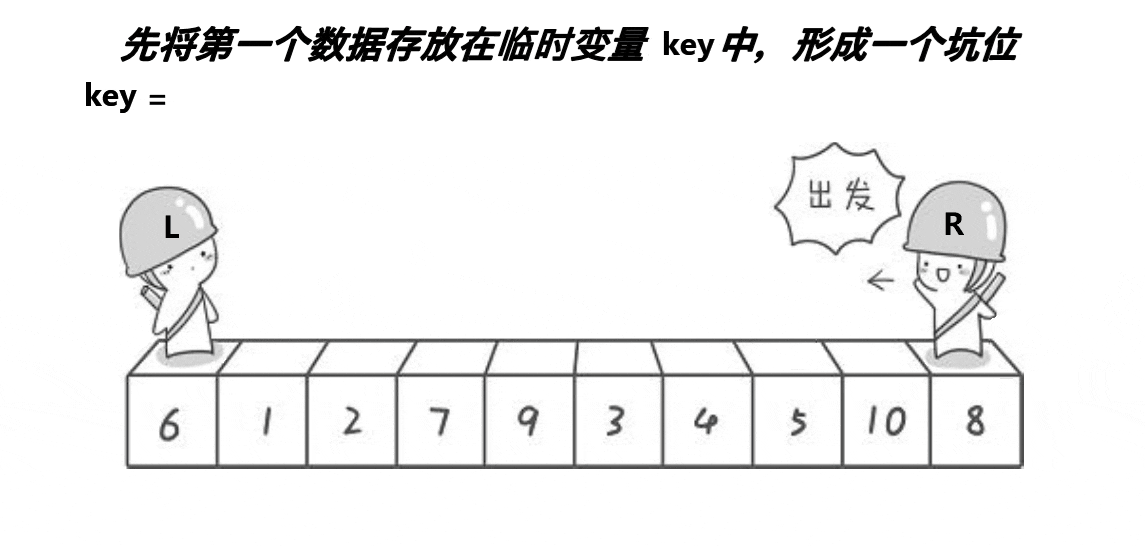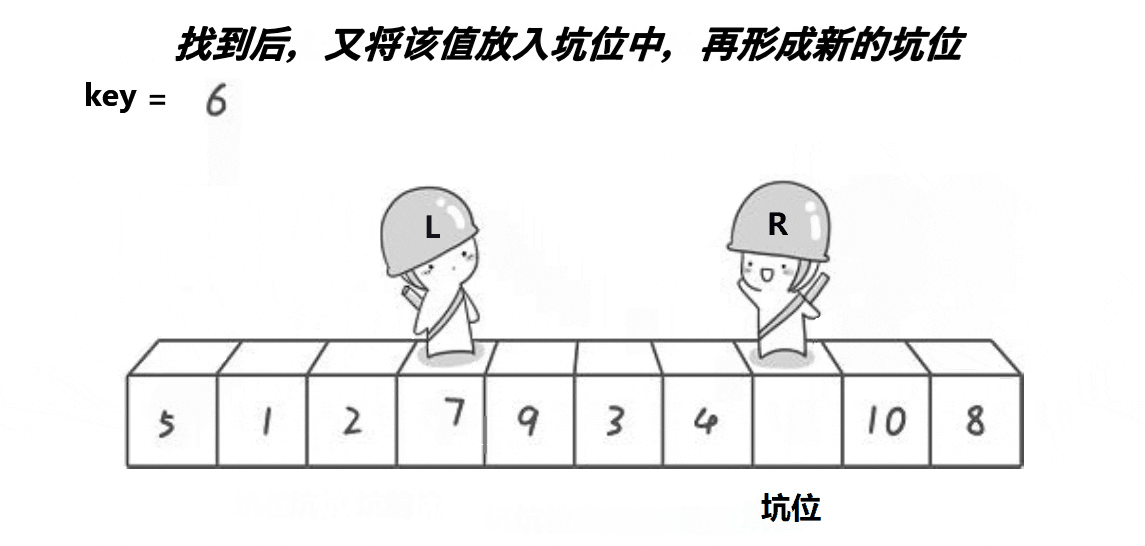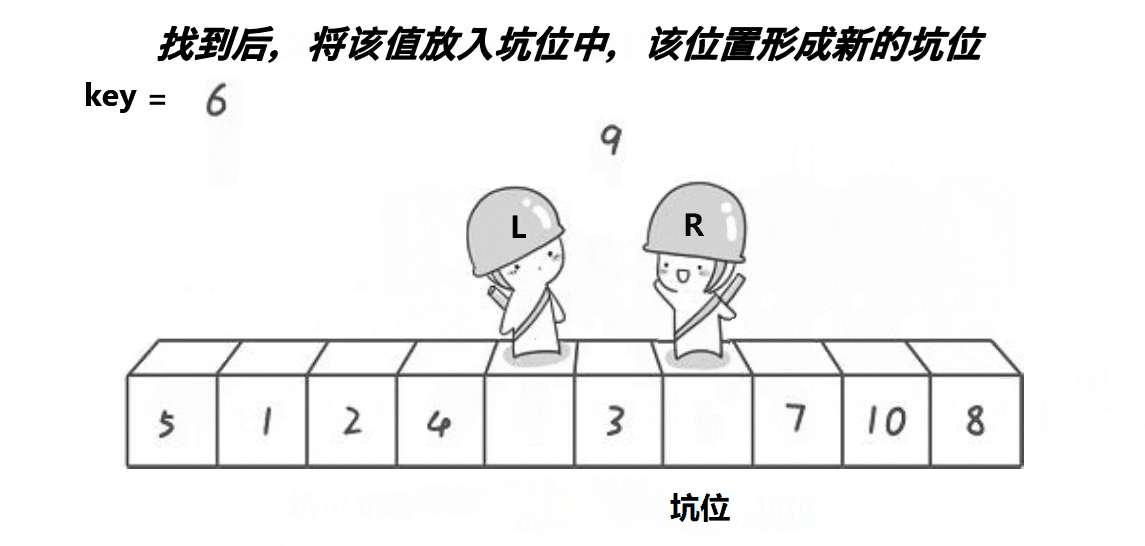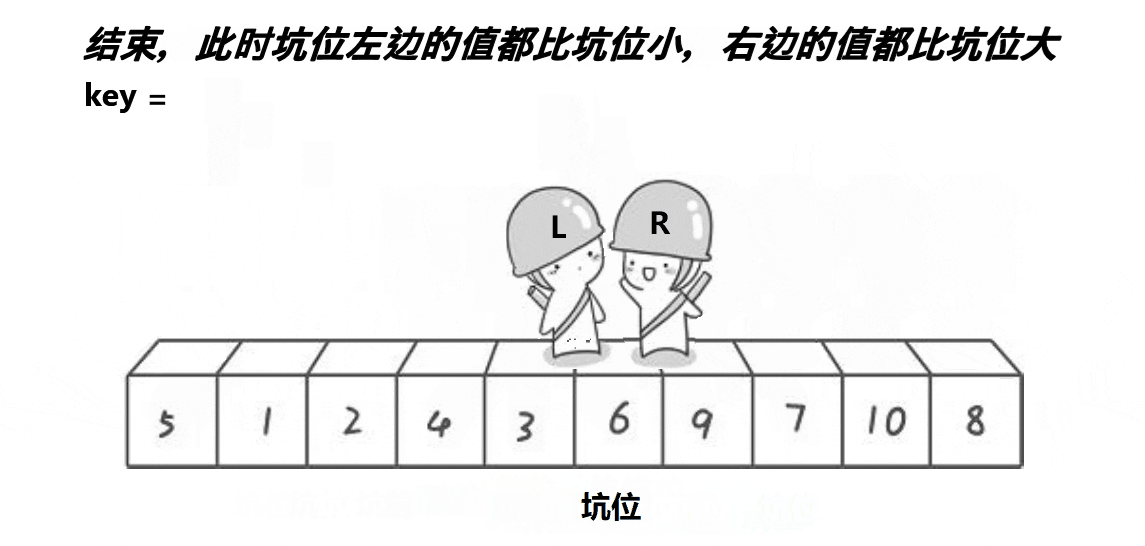
经过上面的图片分析,我们可以感受到挖坑法和hoare版本并没有太多本质上的区别(hoare版本的思路及代码在我的上一篇博客已经写过,这里我就不再赘述了),只不过挖坑法似乎更易理解,且我们在写代码的时候也会感觉到与hoare相比,它的坑会比较少,接下来我们来剖析代码加深理解。

这两张图片中第一张是挖坑法的核心,我们重点来讲第一张的核心部分(第二张图片的内容我也在上一篇博客中展示过了)。
不过在这里我们先穿插一个上次没有讲过的小模块,也算是一种小优化,就是GetMidi这个接口。
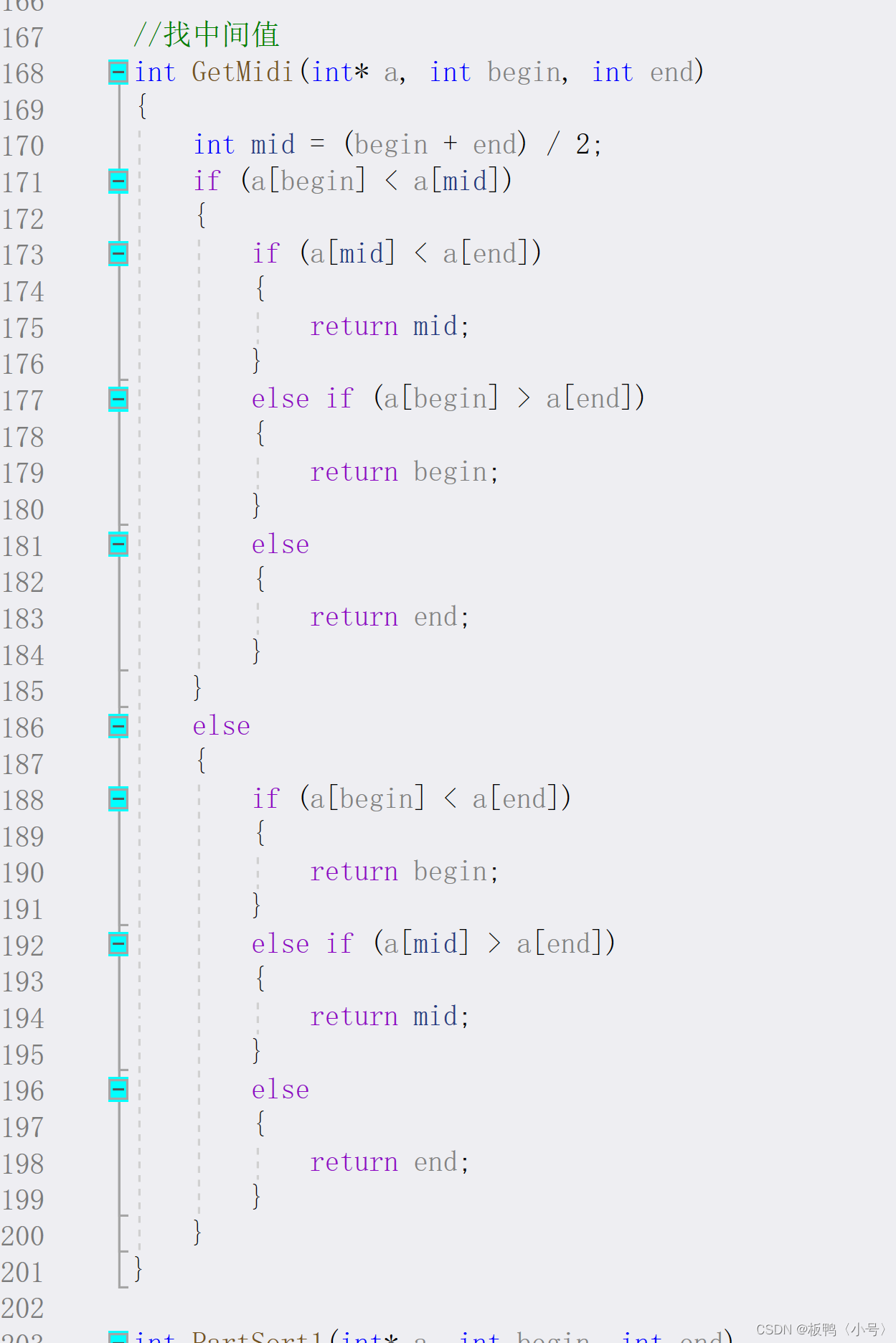
这个接口的作用就是找首元素、中间元素和尾元素的中间值,为什么要这么做呢?这是因为如果左边的值是最小值且较为有序,那么它的时间复杂度会很接近最坏的情况。为了尽量避免我们就可以来写一个小接口进行优化,找中间值的函数相信大家都会写,这里我就不过多讲解了。
挖坑法的形式还是采用类二叉树的思想去进行递归,那么单趟怎么来实现就是我们要思考的问题。
代码剖析
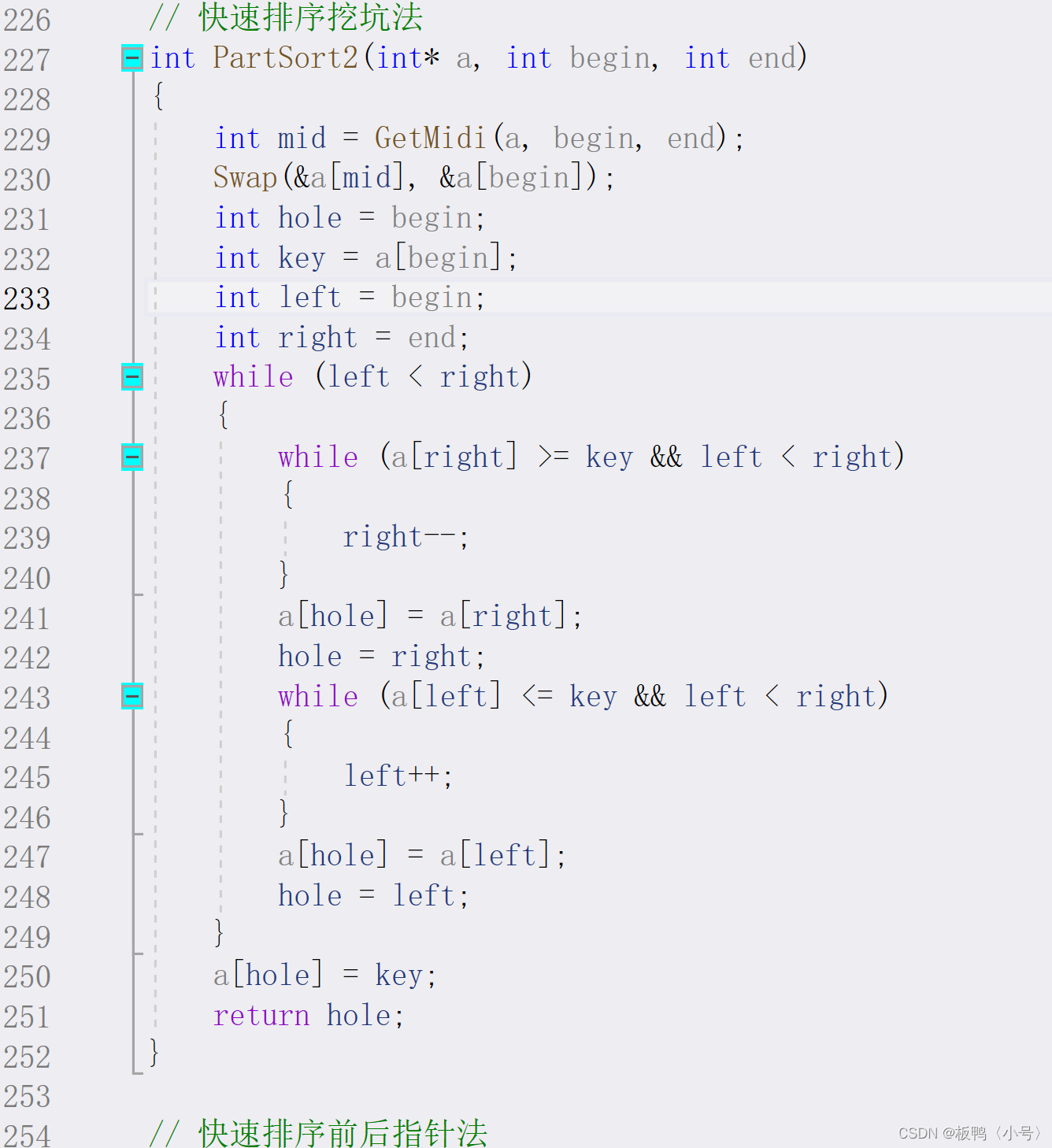
为了方便我把代码再放到这里来
首先,我们用mid来标记中间值的下标,然后将mid的数据跟首元素的数据进行交换,然后把我们的坑就设置在首元素的下标上,然后用key来存放最开始的坑位的值,left就是最左边的值,right就是最右边的值,然后让右边先走,找到比key小的值就停下来,将这个值给到挖好的坑中,这个时候按照我们的逻辑想象也能知道,新的坑位就形成了,所以我们这个时候就要把坑的下标更换过去;然后我们再让左边走,直到左边找到比key大的就停止,然后将这个值给到坑中,再将坑更新,重复进行下去直到把一趟都走完,再把key值给到我们的最后的坑位上去。跟hoare版的一样,每一趟都能确定一个key的最终位置,我们再以此进行递归。
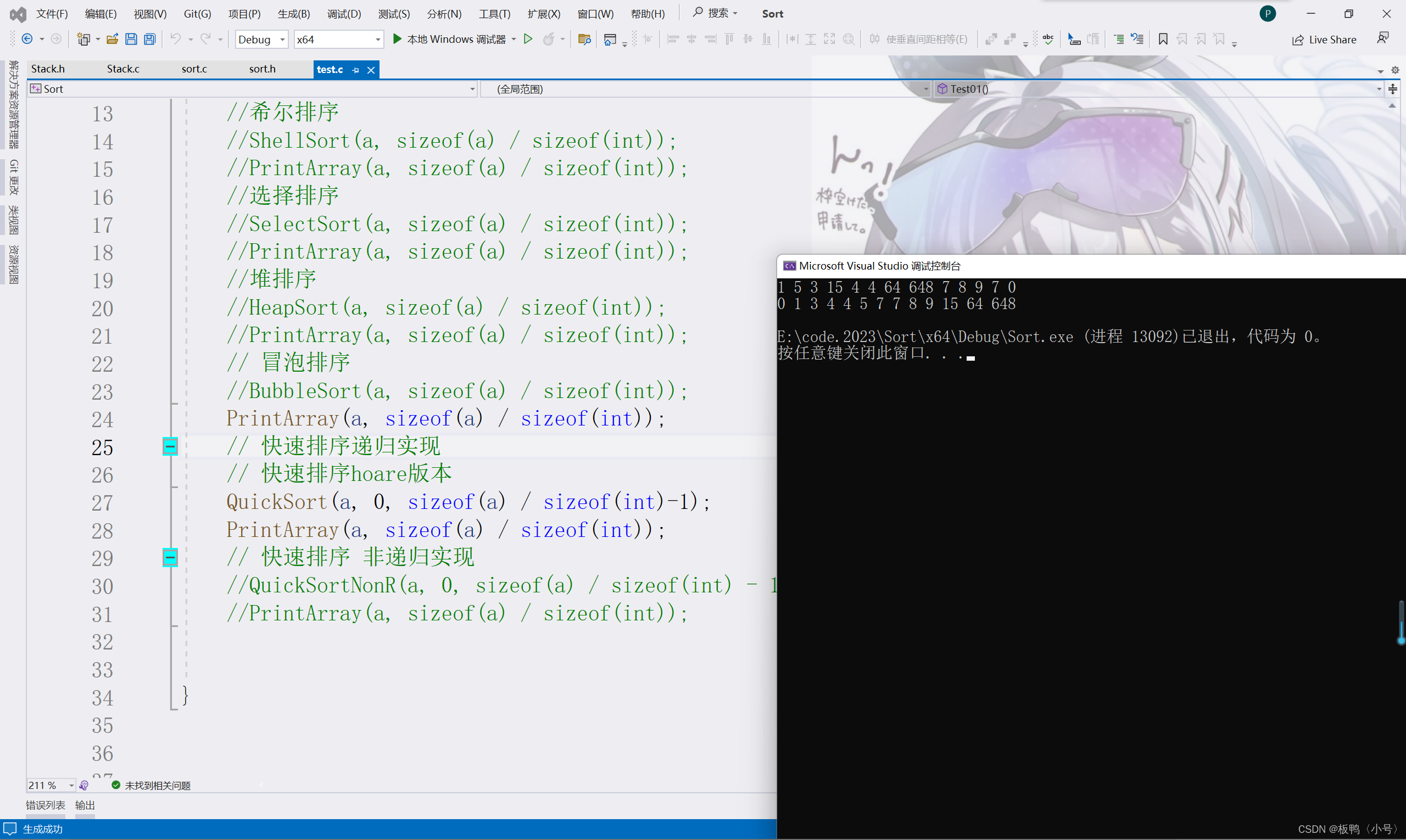
我们来看看结果:
这就是我们的快速排序挖坑法的部分啦。
文章来源:https://blog.csdn.net/sqm_C/article/details/135436404
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- ChatGPT开源项目精选合集
- 基于Java+SpringBoot+Vue前后端分离美妆购物网站设计和实现
- spark广播变量
- Vue高级(二)
- 【百面机器学习】读书笔记(一)
- node.js(express.js)+mysql实现注册功能
- Python文件操作与面向对象
- vue3使用vue-masonry插件实现瀑布流
- Prometheus 薪资翻倍的监控系统?
- 【ECMAScript笔记三】数组(创建 提取 长度 翻转)、函数、作用域(局部 全局)、函数预解析