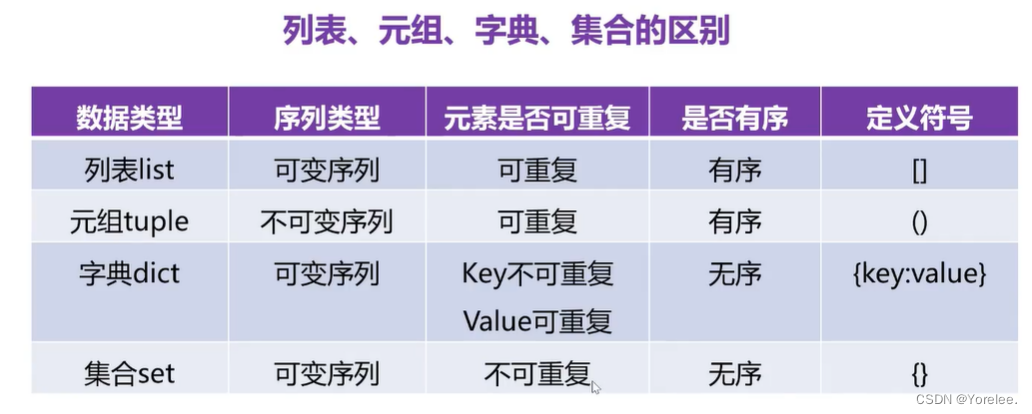
Python的组合数据类型
?一、序列
序列结构:字符串、列表、元组、集合和字典
组合数据类型:列表、元组、集合和字典
有序序列:列表、元组
无序序列:集合、字典
[]列表:可变数据类型(有序)
()元组:不可变数据类型(有序)(没有增、删、改,也不能修改元素的值)
{}集合:可变数据类型(无序)
{}字典:可变数据类型(无序)
????????注意,在使用tuple()、list()、set()时,传入类型都得是序列,如tuple([1,2,3])而不能是tuple(1,2,3)、tuple(1)。可以认为是它是一个函数,函数的输入类型是序列类型的。
集合中只能存储不可变数据类型、字典的键值只能是不可变数据类型。元组和列表可以存储任意数据类型。
s=tuple([1,'g',(1,2),[1,2],{1,5,8},{1:'dog'}]) s2= {(1,2),'asd'} s1={1:'dog',2:100,3:s,4:list(s),(1,2):s}

一、索引
字符串索引展示:
s='hello world' for i in range(len(s)): print(i,s[i],sep='',end='\t') #0h 1e 2l 3l 4o 5 6w 7o 8r 9l 10d print() for i in range(-len(s),0): print(i,s[i],sep='',end='\t') #-11h -10e -9l -8l -7o -6 -5w -4o -3r -2l -1d

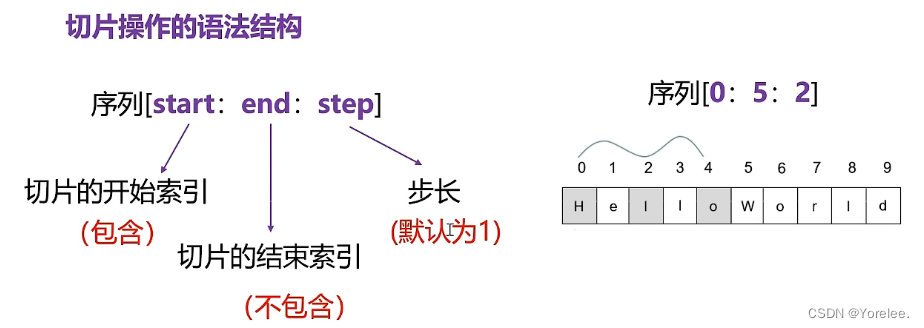
二、切片
所有序列结构都可以切片。
切片可以理解为,将序列中的部分内容拿出来,单独作为一个新的对象。
range(n,m)和s[n:m]?都是左闭右开,不包含最右边的m。
注意:
①省略开始位置,默认从0开始
②省略结束位置,默认截到最后
③开始位置和结束位置都省略的时候,就是从头截到尾
④不写步长的时候,默认步长为1,当省略步长的时候,第二个冒号可以省略,也可以不省略
⑤当步长为-1时,省略开始和结束会逆序输出
print(::-1)
⑥当使用反向递减索引时,使用负数步长,保证开始位置在结束位置右边,也可以从右往左切片
s='hello world' print(s[0:]) print(s[0::]) print(s[:])#hello world print(s[0::2])#hlowrd print(s[::2])#hlowrd print(s[-1:-10:-2])#drwol print(s[::-1])#dlrow olleh
三、相关操作
分解赋值:
a,b,c='123' a,b,c=(1,2,3) a,b,c=[1,2,3] a,b,c={1:'2ad',2:'asd',3:'asda'} print(a,b,c) #1 2 3 a,b={1:'2ad'} print(a,b) tp={1:'2ad',2:'asd',3:'asda'} for key,value in tp.items():#可以认为是返回的是一个元组,然后分解赋值 print(key)
相乘操作:
序列*n
对序列复制n次,变成顺序的n个原序列。
"--"*5? 等价于"----------"
s="Yorelee" if 'Y' in s: print(s*2) if 'wq' not in s: print(max(s)) else:s=s+'wq' for i in range(len(s)): print(s[i],end='')

二、列表
可变数据类型。列表中的元素的基本数据类型可以不一样。
为什么说是可变数据类型?
我们看一下整型、字符串类型
x=8,这个8在内存中是无法被修改的
x='123',这个'123'在内存中无法被修改,x=x+'1',这个字符串的内存地址会不一样,也就是不是同一个字符串了。
而列表是可以在原来的数据基础增删改的。

一、列表的创建和删除
内置函数list()可以认为是一个强制类型转换。比如list('Love U U')相当于把字符串这个序列,强制类型转换成一个列表,列表中的每一个元素对应字符串中的每一个字符。
列表很像C语言里面的联合体,每个元素的类型是不一样的,可以用数组的方式访问每一个元素。
lst1=['hello','world',52,0000,8,8]#0000的值是0 列表中也是0 print(lst1) #列表是一个数据类型,可变数据类型 #['hello', 'world', 52, 0, 8, 8] lst2=list('hello world1546') print(lst2) #['h', 'e', 'l', 'l', 'o', ' ', 'w', 'o', 'r', 'l', 'd', '1', '5', '4', '6'] lst3=list(range(1,10,2))#list()中可以放一个序列,让它变成一个列表 print(lst3) #[1, 3, 5, 7, 9] print(lst1+lst1) print(len(lst1)) print(lst1*3) #['hello', 'world', 52, 0, 8, 8, 'hello', 'world', 52, 0, 8, 8] #6 #['hello', 'world', 52, 0, 8, 8, 'hello', 'world', 52, 0, 8, 8] del lst1 del lst2 del lst3 #删除之后,不能再引用了,undifined

二、列表的遍历
①使用for循环直接遍历元素
for i in lst1: print(i) ''' hello world 52 0 8 8 '''②使用for循环用索引遍历元素
for i in range(0,len(lst1)): print(lst1[i])③使用enumerate()函数
enumerate(list)返回两个值序号和元素(这里的序号不是索引,默认从0开始,可以自己指定)
for index,item in enumerate(lst1): print(index,item) for index,item in enumerate(lst1,START): print(index,item) #START指明从哪个序号开始
三、列表的操作(专属于它的特殊操作)
lst.reverse()即可!
可以根据索引进行修改。

排序操作:列表中的元素必须能够比较大小才能排序。
reverse的值为False是升序,True是降序。没有返回值,返回值是None
reverse和key可以只指定一个
key用参数值指定:
参数str.lower表示字符串忽略大小写按小写字母ASCII码值比较大小。
sorted()和列表.sort()的区别在于,sorted()不改变原列表返回一个新列表?,而sort()改变原列表
内置函数sorted()的对象也可以是字符串。
lst1=[123,12,1534,7347,367,3] print(lst1) lst1.sort() print(lst1) lst1.sort(reverse=True) print(lst1) ''' [123, 12, 1534, 7347, 367, 3] [3, 12, 123, 367, 1534, 7347] [7347, 1534, 367, 123, 12, 3] ''' lst1=sorted(lst1) #返回值类型是排序对象的类型,而不更改原对象

?四、列表生成式和二维列表
①列表生成式
两种方式
lst=[表达式 for item in range] lst=[表达式 for item in range if 条件] ''' 每次循环将表达式的值插入放入列表尾部(如果满足条件的话) 即[表达式 for item in range]的返回值是一个列表 '''s='213894150' lst1=[s[i] for i in range(len(s)) if s[i]!='1'] print(lst1)②二维列表
?????相当于列表中的元素是一个一维列表
lst2 = [[j + i for j in range(5)] for i in range(7)] # [[0, 1, 2, 3, 4], [1, 2, 3, 4, 5], [2, 3, 4, 5, 6], [3, 4, 5, 6, 7], [4, 5, 6, 7, 8], [5, 6, 7, 8, 9], [6, 7, 8, 9, 10]] lst3 = [[0, 1, 2, 3, 4], [0, 1, 2, 3, 4], [0, 1, 2, 3, 4], [0, 1, 2, 3, 4], [0, 1, 2, 3, 4], [0, 1, 2, 3, 4], [0, 1, 2, 3, 4]] for row in lst2: # row是列表元素 for col in row: # col遍历 print(col, end=' ') print()
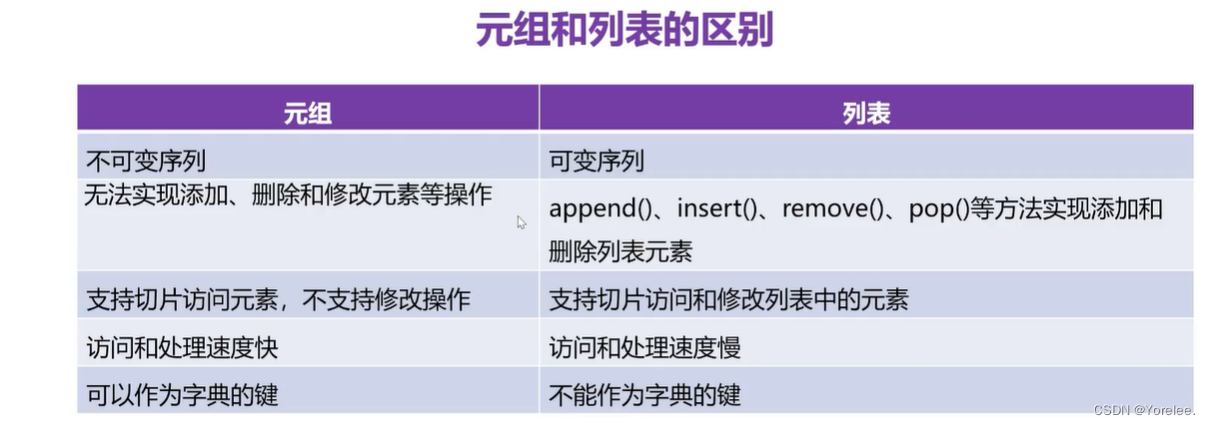
三、元组?
元组是Python中的不可变序列。对于同一个元组对象只可以使用索引去获取元素,用for循环去遍历元素,而不能增删改。同样的,tuple()可以认为是一个强制类型转换,可以将一个序列变成元组。(注意列表也是一个序列,注意必须是一个序列!!!)

一、元组的创建和删除
tp=('hello','world',[10,20,'Love'],3) tp=tuple(['hello','world',[10,20,'Love'],3]) tp=tuple('helloworld') ''' ('hello', 'world', [10, 20, 'Love'], 3) ('hello', 'world', [10, 20, 'Love'], 3) ('h', 'e', 'l', 'l', 'o', 'w', 'o', 'r', 'l', 'd') ''' ''' 如果元组中只有一个元素,逗号不能省,不然括号就变成了普通括号了,如(10)就表示10 ''' tp=(10,) print(len(tp))#1 del tp将序列中的每一个元素作为元组中的元素,字符串的每一个字符都是一个元素。
你会发现元组和列表在这里看,其实是没啥区别的呀,但实际上,元组是不可变类型,它只有序列的基本操作。序列是可变的。定长数组和vector的区别~?

二、元组的遍历和访问
①索引访问
tp=('hello',' ','is','me',88) tp2=tp[0:5:2] for i in tp: print(i) for i in range(len(tp)): print(tp[i])②enumerate()
tp=('i','老虎','油') for index,item in enumerate(tp): print(index,item) ''' 0 i 1 老虎 2 油 '''
三、元组生成式
i for i in range(0,8)是一个生成器对象。可以用生成器对象.__next__()依次取出生成器对象中的元组,取出之后就没了。
为什么列表可以直接用?因为列表是方括号[],直接就可以表示列表,但是()对于圆括号而言它,可以仅仅是一个普通的括号,因此要把生成器对象指定为元组,可以加上类型转换tuple()
tp=tuple(i for i in range(0,8)) tp1=(i for i in range(0,8)) print(tp) print(tp1) ''' (0, 1, 2, 3, 4, 5, 6, 7) <generator object <genexpr> at 0x00000206F0658040> ''' print(tp1.__next__())#0
四、字典
哈希表~字典的键必须是不可变类型,可以是元组,字符串,整型,浮点型,键值是唯一的。如果键值相同,后者会覆盖前者

一、字典的创建和删除
zip(lst1,lst2),序列lst1的每一个元素是不可变类型,lst1与lst2对其,lst1的元素作为键值,一直做到长度最小者。zip()返回的是一个zip对象,需要用dict来转换成字典。
dic={1:'asd',2:'12d',5:'x'} dic=dict(dog=1,cat=20) tp1=tuple([1,2,3,4]) tp2=tuple([5,1,6,7]) d=dict(zip(tp1,tp2))#{1: 5, 2: 1, 3: 6, 4: 7} del dic

二、字典的访问和遍历

①使用键值获取值
dic={1:'asd',2:'12d',5:'x'} print(dic[1])#asd print(dic.get(1))#asd print(dic.get(11,'不存在'))#不存在 ''' dic[key] key不存在会报错 dic.get(key) key不存在返回默认值None dic.get(key,默认值) key不存在返回默认值 '''②以元组形式遍历字典
dic={1:'asd',2:'12d',5:'x'} for item in dic.items(): print(item) ''' (1, 'asd') (2, '12d') (5, 'x') '''③拆开元组遍历
dic={1:'asd',2:'12d',5:'x'} for key,value in dic.items(): print(value,end=' ') print(key) ''' asd 1 12d 2 x 5 '''
三、字典的操作
添加元素:
dic[new_key]=new_value
d.keys()和d.values()返回的都是一个对象。
d.get(key),d.get(key,default)#如果没找到键值为key的值,返回的是值defalut
s={1:'dog',2:'cat'} for key in s.keys(): print(key,end=' ') for item in s.get(key): print(item,end='-') print() ''' 1 d-o-g- 2 c-a-t- '''合并字典的运算符:|? (Python 3.11引入)
s={1:'dog'} t={2:'cat'} print(s|t)#{1: 'dog', 2: 'cat'}

四、字典生成式
tp={1:'ada',2:'dd',3:'ada'} tp2=dict(item for item in tp.items()) #虽然item是一个元组,但是好像元组和一个key:value是可以对应的 print(tp2) #{1: 'ada', 2: 'dd', 3: 'ada'}

五、集合
集合中只能存储不可变数据类型、字典的键值只能是不可变数据类型。

一、集合的创建和删除
s={10,20,30,40,80} print(s) s=set()#空集合的创建方法,bool值是False print(s) s={}#字典! 输出set() s=set('helloo') #无序的集合,o只会有一个 s=set([10,20,30,40,50])#序列 s=set(range(10,51,10))#序列 s=set((10,20,30,40,50))#序列 s=set(s)#序列 s0={1:'dog',2:'cat'} s=set(s0)#序列 print(s)#输出{1, 2}

二、集合的操作符
A={1,20,30} B={20,50,100} print(A&B) #按位与也是& print(A|B) #按位或也是| print(A-B) print(A^B} #按位异或也是^ ''' {20} {1, 50, 20, 100, 30} {1, 30} {1, 100, 50, 30} '''

三、集合的相关操作
遍历:
s={50,4,98,0,'hell'} for i in s: print(i,end=' ') print() for index,item in enumerate(s): print(item,end=' ') ''' 0 98 50 4 hell 0 98 50 4 hell '''

四、集合的生成式
生成器对象,直接加上{}就可以转为集合。(只有元组无法直接转)
s={i for i in range(1,10)} s=set(i for i in range(1,10)) print(s) ''' {1, 2, 3, 4, 5, 6, 7, 8, 9} '''
?六、总结





本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- idea设置注释在鼠标当前位置,使其不从顶格位置添加注释
- 测试开发(实践总结)
- 电视网页适配大屏显示
- 学生公寓里如何进行安全用电管理
- Java实战:Swing版记事本
- 进阶学习——Linux网络
- 超详细 Centos7下Prometheus Alertmanager配置钉钉告警与邮箱告警(已亲手验证)
- 红日二靶场
- [足式机器人]Part2 Dr. CAN学习笔记-动态系统建模与分析 Ch02-7二阶系统
- MySQL 数据库操作指南:学习如何使用 Python 进行增删改查操作