分支指令的方向预测
发布时间:2023年12月28日
对于分支指令来说,它的方向只有两个:发生跳转(taken)和不发生跳转(nottaken),因此可以用1 和0 来表示。
很多分支指令的方向是有规律可循的。
方式一:last-outcom prediction
? ? ? ? ? ? ? ?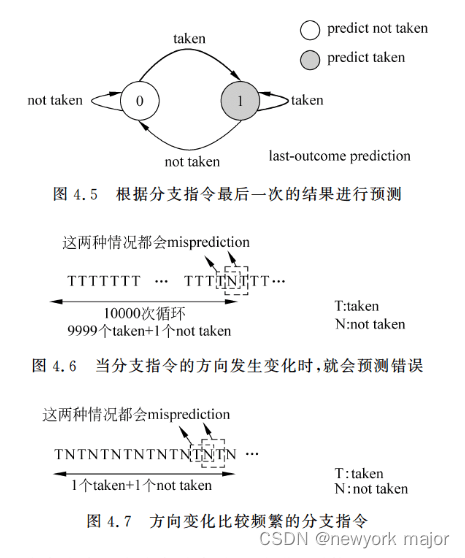
- 其准确度,无法接受;
方式二:基于两位饱和计数器的分支预测
????????基于两位饱和计数器的分支预测方法并不会马上使用分支指令上一次的结果,而是根据一条分支指令前两次执行的结果来预测本次的方向,这种方法可以用一个有着 4 个状态的状态机来表示。
? ? ? ?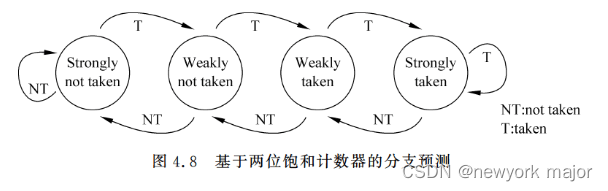
- 特点:状态机处于饱和状态时,只有两次预测失败,才会改变预测的结果;
- 初始状态,一般建议是strongly not taken, 或者是weakly not taken;
- 核心理念:
- 当一条分支指令连续两次执行的方向都一样时,那么该分支指令在第三次执行时也会有同样的方向;
- 如果一条分支指令只是偶尔发生了一次方向的改变,那么这条分支指令的预测值不会马上跟着改变;
- 因此这种方式的分支预测就好像是有一定时间的延迟一样,分支方向偶尔的变化将会被过滤掉。
- 为什么不继续扩大位宽?
- 2bits的正确率已经很高了;
- 增加位宽后,会引起复杂度的上升和更多的存储资源,开销要远大于精度的提高;
每个PC都应该有一个饱和计数器
- 因为每一条pc,都可能是分支指令;
- 如果是这样,那就需要2^30 * 2 bits的空间来存储;
- 考虑到肯定不是每条都是分支指令,因此做如下简化:?

- PHT: 记录每个PC对应的两位饱和计数器的值;其大小为:2^k * 2 bits;
- k值的大小,对预测准确度的影响:
- 上面的update, 有三个来源:
- 预测结果进行更新;
- 不行,此时的预测结果可能是错误的,不能进行更新;
- BRU执行结果出来后,进行更新;
- 不行,因为OOO, 可能处于在错误的分支上;
- commit阶段,进行更新;
- 只能在这个阶段进行更新,这个时候是最准确的;
- 不太会影响预测精度,因为两位饱和计数器,本身是有延迟的;
- 预测结果进行更新;
- 这种方式的问题:k bits相同的PC, 对应相同的两位饱和计数器,会互相干扰;
- 称之为:aliasing 问题;
- 自然有中立性的别名,和破坏性的别名;
- 虽然有问题,但是实现简单,轻微的预测准确度降低,可以接受;
- 如何解决aliasing问题?
- 可以使用hash的方式;
- hash算法,可以将32位的PC,压缩成固定长度的较小值;

? ? ? ? ? ? ? ? ? ? ?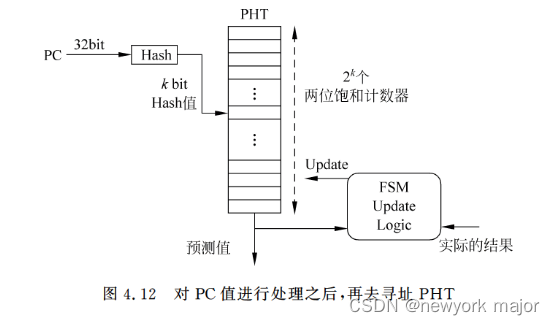
- 局限性:准确率很难达到98%以上,现在的处理器,已经不会直接使用这种方式了;?
?方式三:基于局部历史的分支预测
- ?上述方式的问题:对于很有规律的分支指令,预测准确率可能会很低;

- 上述pattern的预测准确率为0!!, 且该准确率和初始状态有关,但是也不是很高;
- 解决方式:增加分支历史寄存器(Branch History Register, BHR);
- 将branch inst每次的执行结果,移位到BHR中,记录其历史状态;
- 也称之为两级分支预测;
? ? ? ? ? ? ? ?? ?
?
- 从上图可以看出,可能某条PC,在真正执行的时候,只会用到PHT中的几个entry;
- 怎么知道BHR需要几个bits?
- --找循环周期,即连续相同的数有几个bits, 则循环周期就是几个bits;
- 11000_11000..., 循环周期为3;
- 这种方式需要训练时间:
- 使PHT中的饱和计数器到达饱和状态的这段时间称为训练时间(training time)
- 在这段时间内,由于计数器没有到达饱和状态,因此分支预测的准确度是比较低的,训练时间的长短取决于BHR寄存器的位宽,一个位宽很大的BHR寄存器需要更多的时间来找出规律。
- 这种方式的问题:
- 每条分支指令都有自己的BHR,PHT,n bits的BHR, 需要2^n x 2bits,需要极大的空间;
- 将每条pc的BHR组合在一起,称之为分支历史寄存器表(BHRT or BHR);
- 解决方式:
- 一般只使用PC的一部分来寻址BHT;
- 使用PC的一部分,来寻址PHT;
- ???????
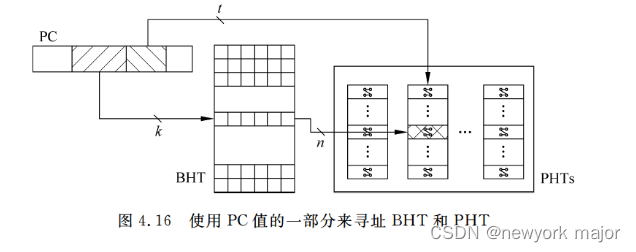
- 当然,这种方式,也会遇到aliasing问题;
- 极限情况下,可以将PHT简化成一个;
- ???????

- 上述会有两种冲突的情况:
- PC的k相同,此时两条PC对应同一个BHR, 也就对应同一个PHT的entry,会相互影响;
- PC对应的BHR不同,但是其BHR的内容是一样的,对应同一个PHT entry, 也会相互影响;
- 解决方式:对pc值做处理(可以有多种算法,此处仅举例一个);
- ???????

- ???????
- 总结:
- ?此种方式,仅考虑分支指令,自身在过去的执行情况;
- 如果分支指令的循环周期太长,可能需要很大的BHR,会导致很长的训练时间;PHT也会占用很多资源;
- 如果BHR太小,又会导致不能完全体现指令的规律性;
- 但是与基础的两位饱和计数器比较,已经是很大的进步了;
?方式四:基于全局历史的分支预测?
? ? ? ? 这种方式,是考虑到某条分支指令,其taken与否,是与前面的分支指令的执行结果相关联;
??????????????
????????上图中,b1,b2发生,则b3一定不会发生;???????????
- ?因此称之为基于全局历史的分支预测;
- 新增一个寄存器,全局历史寄存器,GHR;
- 用有限位宽的GHR, 记录最近执行的所有分支指令的结果;
- 每遇到一条分支指令,就在commit阶段,将分支指令的结果插入GHR右边,左边值抛弃;
?? ? ? ? ??
- 预测过程:
- 只使用一个GHR寄存器,记录最近所有的分支指令的结果;
- 给每个PC设置一个PHT;
- 执行时,根据PC,找到PHT, 再根据GHR, 找到该PHT中的entry, 得到预测结果;
- 在commit时,再根据GHR和PC,找到该entry, 根据实际结果,更新该entry;
- 实际情况中,无法使用,因为每个PC一个PHT,占用的空间太大了;?
- 一些解决方式:
- ???????


- 4.21中的PHTS中的很多entry都没用到,因此使用图4.22的方式处理;
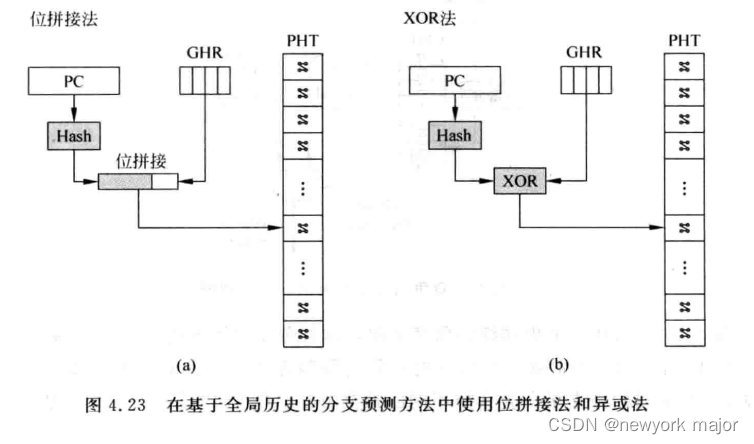
- 4.22中,不同PC,可能会对应相同的GHR,从而对应相同的PHT的entry,会相互影响,这里给出两种解决方式;
- ???????
文章来源:https://blog.csdn.net/zhangshangjie1/article/details/135261303
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 第11章 GUI Page489~494 步骤三十 保存画板文件02 实现存盘函数SaveFile
- MyBatis-Flex 常见问题
- Leetcode 剑指 Offer II 059. 数据流中的第 K 大元素
- VitulBox中Ubuntu虚拟机安装JAVA环境——备赛笔记——2024全国职业院校技能大赛“大数据应用开发”赛项
- 群狼调研开展某连锁火锅神秘顾客调研
- 【Spring之手写一个依赖注入容器】
- ImageKit10 VCL Crack
- “Tab键”强制转换为“空格键”
- css保留格式文本换行
- gRPC-Go基础(5)middleware