SPDK As IPU Firmware
对于不熟悉术语Infrastructure Processing Unit (IPU, 基础设施处理器)的同学,IPU是PCIe形态的卡,连接到主机系统后可以卸载主机的“基础设施”工作。它通常是面向云服务商或者超融合服务提供商的。对于熟悉SPDK的开发人员来理解,这些卡通常具有一些能够向主机系统呈现看似物理NVMe或virtio-blk/scsi设备,但实际上IPU随后基本会通过网络将发送到该设备的任何I/O转发出去。
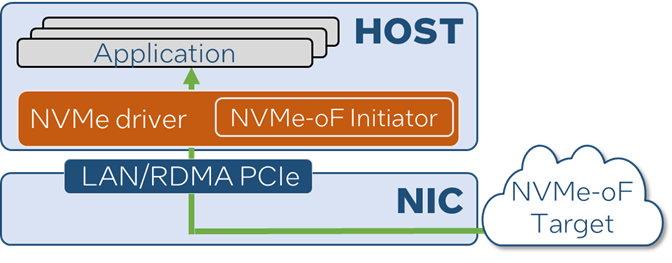

图1? From standard NIC to IPU
这类IPU通常作为某些硬件或基于FPGA的PCI Endpoint, 并与SoC结合来实现。它具有多种Physical Function或支持SR-IOV。其上的SoC通常运行Linux或至少一些类似于POSIX的操作系统。为了使这类卡具有好的灵活性,通常大多数决策类的逻辑是在该SoC上运行的软件(“固件”)中完成,同时仅让数据搬移由硬件处理。

图2? IntelIPU ES2000 ASIC
这意味着SoC上必须运行一些代码来实现这些硬件Endpoint的“后端”。这种代码需要能够处理从设备BAR空间来的对寄存器读写操作,并使设备展现为符合某种规范的物理设备。例如,如果PCI Endpoint声称是一个NVMe设备,那么主机驱动程序将建立一个管理队列,写入EN位,并等待RDY位翻转为 1。SoC上的软件必须能够执行所有这些仿真,此时卡上硬件通常只是在主机和SoC之间开辟寄存器访问的通道,但很少,甚至没有它自己的处理逻辑。
NVMe设备上线后,主机驱动会提交管理命令来创建I/O队列的命令。I/O队列位于主机内存中,对应的Doorbell是BAR中的寄存器。一些实现可能会让硬件自动处理Doorbell的写入硬件,并通过某种队列机制,传递传入的命令给SoC。但有些实现可能只是通知SoC,Doorbell被写入,需要软件去启动DMA来传输最新的命令记录。但无论如何,命令都会到达SoC的内存,SoC软件必须解析它并决定采取什么行动。
OK,可是SPDK从哪里登场呢?
一些IPU供应商决定从头开始编写自己的固件。但有人做到了一个关键的调研 - NVMe-oF Targets已经模拟了大多数的寄存器读写,以及基本上所有的管理和 I/O命令处理。通过做一些简单的调整,NVMe-oF Target除了现有的几种Fabric Transport,是否能够也将“PCIe” Transport也适配为一种前端机制。(“Transport”泛指一种传输机制,“Fabric Transport”指跨网络传输机制)。
随着NVMe 2.0规范的推出,围绕此的术语一切都变得更加清晰了,所以请让我稍微偏一下话题。当NVMe最初创建时,只有PCIe。然后随着NVMe-oF的加入,引入了 “Transport”的概念 – 作为PCIe外的可选方案 ,如TCP或RDMA。它们可以 在两个系统之间传递NVMe命令。但这些Fabric Transport确实表现的与PCIe Transport不同。为了解决这个问题,NVMe 2.0规范了两个Transport类别 - “基于内存”和“基于消息”。请参阅NVMe 2.0 Spec中的“Theory of Operation”一章, 来了解对此更清晰的描述。在某些情况下,这两个类别具有不同的语义,特别是围绕管理队列的建立和寄存器的读写,但至少一切都被正式化并记录下来。

图3? SPDKNVMe-oF Target for IPU
回到问题 - 现有的设计用于 “基于消息”Transport的NVMe-oF Target是否可以支持“基于内存”的Transport?事实证明,这个问题已经有了答案。SPDK添加了一个 “基于内存”的Transport,来模拟PCIe设备给虚拟机,它就是vfio-user。并且它已经完成了对现有NVMe-oF Target代码的所有适配工作来处理这两类Transport。这正是IPU供应商现在正在采用的方式——他们可以相对简单的编写一个基于内存的Transport,从IPU内部与其硬件设备交互,然后使用SPDK NVMe-oF Target处理所有寄存器模拟和命令处理。
棒极了!我们完活了吗?
设备供应商可以在SPDK上编写一个Transport插件,就能很快地拥有完整的 NVMe设备模拟工作。但现实是我们还远未完成。事实证明,SPDK还需要启用大量很酷的卸载功能 来高效地移动数据。
比如我们想从 主机系统的NVMe驱动程序做一次WRITE操作,数据从主机系统内存开始,在通过网络发送之前可能会以多种方式进行转换。任意类型的后端远程服务器都能真正处理它。这些转换包括加密和压缩等内容,还包括 DIF/DIX、校验和,甚至更多。通常硬件能够内联进行这些转换,当数据从主机移动到 SoC 内存时,或者当数据直接从主机通过线路发送走时。
这样看来,SPDK该如何形容和操作主机内存呢?现在,我们将了解这一系列帖子真正要讨论的内容。
一个例子
让我们深入研究一个向主机呈现NVMe设备的例子。这个例子里IPU需要对静态数据进行加密,并通过NVMe-oF/TCP转发给一个远端Target。假设IPU本身运行着Linux并且包含三个独立的PCI设备 - 一个是将NVMe设备呈现给主机系统的设备(我们称之为NVMe Endpoint),一个可以在主机和IPU的内存上执行复制和加密的设备(我们称之为DMA引擎),以及一张网卡。

图4
以下是基本数据流:
-
主机NVMe驱动程序要在NVMe queue pair上发出NVM WRITE命令, 则将其写入提交队列并按门铃(Doorbell)。
-
NVMe Endpoint硬件通知IPU软件一个NVMe命令已 到达。该命令是一个NVM WRITE,它描述了命令对应的数据在主机系统内存的位置。
-
IPU软件对DMA引擎进行编程,以将数据从主机传输到IPU-本地内存中。
-
然后,IPU软件再用DMA引擎对本地 内存中的数据进行加密操作。
-
最后,IPU软件通过NVMe-oF/TCP将加密数据发送到远端Target。
假如我们在现有SPDK框架内实现了此数据路径。同时假设NVMe Endpoint硬件相当“愚蠢”,仅在主机和IPU之间传递命令。如上所述,我们添加自定义Target来用硬件NVMe Endpoint向SPDK NVMe-oF Target收发命令,就设好了寄存器和命令的处理。
我们可以为DMA引擎硬件编写一个加速模块以适配进SPDK Accel框架用于加密和复制操作。SPDK将Bdev分层来 构建 它的数据处理流水线,并且已经有一个我们可以利用的加密Bdev,能将请求路由到Accel框架。
为了与卡上的NIC通信,假设网卡有Linux驱动程序,我们将使用Linux内核网络堆栈。前面我们已经构建了一个处理流水线:在前是带自定义Transport的NVMe-oF Target,命令给到加密Bdev,再交给NVMe Bdev去做NVMe-of/TCP。我们已经在IPU上加好了驱动,除此以外,我们还在使用普通的SPDK作为完整数据路径。我们要记住这个例子用以后续的讨论。
从主机传输数据
虽然将驱动程序插入现有SPDK做扩展十分直接,但尚不清楚我们应该如何指示 DMA引擎将数据从主机复制到IPU系统内存(上例中的第三步)。现有的 Accel框架API仅需要拿到源地址和目标地址,但是 在这种情况下,源地址却不是本地的。我们将其称为驻留在非本地内存域的内存 - 在本例中是在 “主机”域里。将这个信息穿透到Accel框架是必要的,去操作DMA引擎以从正确的源地址进行传输。
SPDK现在有一个用于声明和枚举内存域的框架,它定义引用这些域中内存的内存描述符。这个接口函数可以在include/spdk/dma.h中找到。我要感谢Alexey Marchuk和Konrad Sztyber为实现这一目标所做的一切努力。
在我们的示例中,将有一个主机内存域和本地系统内存域(它是始终存在的)。为了使整个示例流程正常工作,我们定制了NVMe-oF Transport来解析传入的NVM ?WRITE命令以提取主机内存地址,创建一个内存描述符,指出它位于另外一个内存域,并将其传递给accel框架进行数据复制操作。这样,我们就可以让整个示例流程正常工作了。
下一步
这使我们的基本数据流正常工作,并且我们可以处理读取和写入。下一篇文章我们将围绕加密功能讨论如何提升效率。然后在本系列第三篇文章中,我们将讨论更高阶的卸载,包括链式卸载,和框架的最终设计。
欢迎来到我们关于SPDK作为IPU固件系列文章的第二篇。上一篇文章为在IPU上使用SPDK奠定了基础。现在我们将专注于以更有效的方式启用内联的块层加密。如果您对此不熟悉,请花点时间回顾一下上一篇文章中的示例场景。我们将从那里开始。
消除数据拷贝
现在我们已经有了基本的流程,我们进行一个简单的观察。DMA引擎执行加密和复制操作,并且它知晓有两个内存域。那么,我们能不能要求DMA引擎将加密作为从主机复制操作的一部分?当然可以了!但要做到这一点需要违反分层。自定义NVMe-oF Transport负责触发从主机侧的复制,加密Bdev模块决定数据需要加密。这是SPDK架构中的两个不同的层,那么我们如何才能将它们结合起来而不跨越边界呢?
为了解决这个问题,我们允许到达SoC上SPDK Bdev层的请求关联主机内存域的内存地址。NVMe-oF自定义Transport只是构造主机内存域中内存的描述,然后将请求转发到Bdev层,但它不触发复制。Bdev加密模块获取请求后,使用当前在主机域中的内存位置作为加密操作的源地址,并使用IPU本地内存作为目的地址。就这样,我们可以出发了!
除此之外,如果我们的示例流程里在静态加密Bdev上没有数据,会发生什么情况?内存位于主机上,请求将遍历Bdev层,最终到达NVMe Bdev模块,在该模块中它将作为NVMe-oF/TCP请求发送。但我们只是使用标准Linux套接字进行网络处理,没有机会直接从主机内存执行特殊的TCP发送操作。除非有创造性的方法来解决这个问题,我们需要一种通用的方法让 SPDK中的组件能够触发两个域之间的复制。这正是我们所做的 - 每个内存域都有push和pull函数指针,这些指针在启动时创建内存域的时候被填充。任何软件都可以请求将远程域中的内存拉到本地缓冲区,或将本地缓冲区推送到远程内存域,这都会触发对应的回调函数。对于我们的示例,这些回调将围绕对DMA引擎硬件的调用进行包装。
因此,我们的DMA框架允许执行以下操作:
-
使用该域中适当的地址来描述远程内存域中的内存。
-
在系统内存域(即我们的SoC的常规内存)和远程内存域之间启动数据传输,而无需了解执行传输的硬件机制。
-
枚举系统中已注册的内存域。
这都已经合入SPDK主线,在当前的SPDK版本中支持。相关API定义在include/spdk/dma.h.
地址翻译
对于我们的特定示例,“主机”内存域有push和pull函数指针向我们的硬件DMA引擎发出请求。该API还支持其他简单的操作,例如归零,这也很明显。然而,每个内存域都支持一个额外的、有些棘手的操作 - translate。
一个IPU可以向主机提供多个PCI“Function”设备。事实上,它们几乎都有——网络Function和NVMe Function。当主机操作系统初始化这些设备时,它很可能将它们配置为在IOMMU之下运行。这意味着这些设备用于DMA的地址是I/O虚拟地址,而不是物理地址。最重要的是,不能保证两个Function使用相同的I/O虚拟地址页表。例如,主机可以配置NVMe Function,使地址16映射到物理地址64,但配置NIC Function,使地址16映射到物理地址1024。
这为什么重要呢?如果我们想完全避免将数据复制到SoC内存,而直接发送到在网络上该怎么办?这对于TCP来说不太可能,但对于RDMA网络后端来说似乎很可能。不过,在一些设计中,此时执行DMA的是NIC,而不是NVMe设备。因此,我们需要将地址从NVMe Function视角下的主机内存做翻译(这是NVMe命令到达时得到的地址),转换到主机内存的NIC视角!该translate函数就是做这个的 - 如果可能,它将地址从一个内存域转换到另一个内存域上。这都是作为指定给内存域的回调函数来实现的,因为所有这些转换都必须是特定于平台的。
下一步呢?
这就是我们在第2篇文章中介绍的全部内容。本系列的第3篇文章将处理执行“链式”操作 - 特别是“加密” +“DIF插入 ”- 它无需额外的数据拷贝。文章也将描述框架所采用的最终形式。
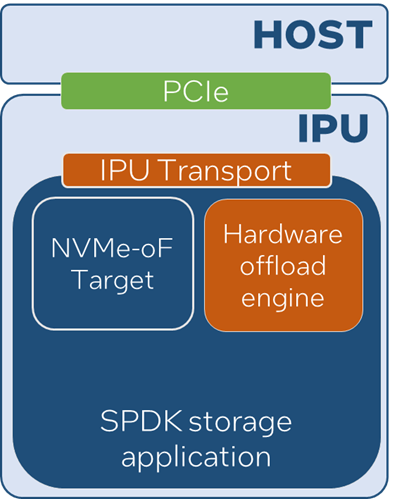
图1??Hardware Offload Engine Module In SPDK
紧接着我们来到关于SPDK作为IPU固件系列文章中的第三篇也是最后一篇文章!在 第1部分中,我们讨论了内存域的添加,在第2部分中,我们重点讨论了加密如何避免数据复制,并由此引出了地址转换。那么让我们接着从那里开始吧。
链式
请允许我对我们一直使用的示例提出另一个问题。假设我们希望IPU执行静态数据加密并且计算每个块上的T10 DIF校验和。此外,假设我们的IPU有一个DMA引擎,能够将这两个任务作为单个操作执行。我们怎样才能做到这一点?
在SPDK模型中,我们对Bdev进行分层来构建数据处理流水线,并且我们已经在NVMe Bdev之上有一个加密Bdev。理想情况下,我们会在加密Bdev和NVMe Bdev之间插入一个DIF Bdev(目前不存在,但让我们想象一下)来添加此功能。让我们写出步骤,看看最终结果如何。
-
NVM WRITE命令到达自定义NVMe-oF Transport。它被打包上一个内存描述符,指示数据位于远程内存域中并发送到Bdev层。
-
Crypto Bdev接收请求并设置从源地址(主机内存)到本地缓冲区的加密操作。完成后,它将请求转发给下一个Bdev。
-
DIF Bdev接收加密数据并设置从本地IPU内存到另一个本地缓冲区的DIF INSERT操作。完成后,它将请求转发给下一个Bdev。
-
NVMe Bdev获取数据缓冲区并使用NVMe-oF/TCP发送它。
但这样我们无法利用我们组合的Crypto+DIF硬件卸载。这根本不是我们想要的。我们该怎么做呢?

图2? Accelerator Framework in SPDK
为了解决这个问题,Accel框架加入了一个名为spdk_Accel_sequence的新原语?。现在,每个Bdev 请求都可以与一个序列对象关联,并且如果要执行该序列,可以询问该序列,数据会在哪里。让我们写出相同的一组步骤,但使用序列原语:
-
NVM写入命令到达自定义NVMe-oF Transport。它被打包上一个内存描述符,指示数据位于远程内存域中。创建一个序列对象,它意为将数据从主机内存复制到系统内存中的本地缓冲区。
-
Crypto Bdev接收请求并将一个加密的操作附加到序列后,从源内存(序列末尾的本地缓冲区)到新分配的本地缓冲区。然后它将请求转发给下一个Bdev。请注意,加密操作还尚未执行。
-
DIF Bdev接收请求并将一个DIF INSERT的操作附加到序列后,从源内存(本地加密缓冲区)到新分配的本地缓冲区的序列。然后它将请求转发给下一个Bdev。请注意,DIF INSERT操作也尚未执行。
-
NVMe Bdev接收请求并希望通过TCP套接字发送该请求出去。为此,数据必须位于本地内存中,因此它请求执行序列。这会触发整个链的 3 个步骤 - 复制、加密、DIF插入。序列完成后,数据位于序列中的最后一个缓冲区中,并且 NVME Bdev会发送该数据。
但这实际上比之前更糟糕 - 我们添加了额外的数据复制并分配了更多的临时缓冲区。还有两个基本问题需要解决:
我们需要某种方法来全面审视序列并将其优化为组合操作。
我们需要避免分配如此多的临时缓冲区,特别是如果优化器稍后会优化掉对它们的使用,那就没有必要去分配这些临时缓冲区了。
添加优化通道
在执行序列之前,会运行两个优化过程。首先,执行通用优化过程以消除不必要的数据复制。通过修改源地址和目的地址,可以省略大多数常规数据复制操作。剩下的优化过程通常需要了解硬件知识,我们无法将这些知识融入到SPDK等通用框架中。为了解决这个问题,Accel框架现在具有可以注册的平台驱动程序的概念,该驱动程序负责执行第二次优化。如果不存在平台驱动程序,则简单地跳过第二次优化。在我们的示例中,第一次优化足以去掉第一次数据复制,从而产生一个新序列。这个序列要从主机内存到临时缓冲区进行一次加密,然后在最终内存位置进行DIF生成。
假设我们为SoC产品编写了一个平台驱动程序,该驱动程序了解我们的DMA引擎可以在单个操作中完成加密和DIF INSERT。该平台驱动程序检查序列,发现它包含两个可以组合的操作,并将其作为单个操作传送到硬件。现在我们确实取得了进展——这比以前更有效率。
避免不必要的暂存缓冲区
对于上述场景,在本地IPU内存中分配了三个缓冲区 - 一个作为从主机做数据复制的目的地址和加密的源地址,一个作为加密的目的地址和DIF INSERT源地址,另一个用于DIF INSERT的目的地址。但平台驱动程序运行后,我们只需要最终的目标缓冲区。另外两个根本不需要存在。虽然它们未使用并且不会影响软件的性能,但它们确实需要分配额外的内存,这是一种浪费。我们应该摆脱他们。
除此之外,为了将一个数据操作附加到序列中,还必须提供出数据输出位置。毕竟,它可能最终成为序列的最后一步,或者对优化过程可能没有可用的链式操作。为了解决这个问题,Accel框架自己创建了一个内存域!该内存域不受任何实际内存的支持 - 它只是一个地址空间 - 并且Accel框架的用户可以从中“分配”内存以用作添加到序列的操作的目的地。因此,让我们使用这个暂存空间重写上述步骤序列:
-
NVM WRITE命令到达自定义NVMe-oF Transport。它被打包上一个内存描述符,指示数据位于远程内存域中。创建一个序列对象,它意为将数据从主机内存复制到这个新的加速内存域中的区域。
-
Crypto Bdev接收请求并将一个加密的操作附加到序列后,从源内存(Accel内存域中的区域)到Accel内存域中的另一个区域。然后它将请求转发给下一个Bdev。
-
DIF Bdev接收请求并将DIF INSERT操作的操作附加到序列后,从源内存(Accel 内存域中的一个区域)到Accel内存域中的另一个区域。然后它将请求转发给下一个Bdev。
-
NVMe Bdev接收请求并希望通过TCP套接字发送该请求。为此,数据必须位于本地内存中。因此它再在序列后附加一个copy操作,将Accel内存域内的区域复制到本地缓冲区,并请求执行序列。这会触发整个步骤链 - 复制、加密、DIF插入、复制。序列完成后,数据位于序列中的最后一个缓冲区中,并且NVMe Bdev会发送该数据。
当序列执行时,首先运行省略复制的通用优化。它消除了从主机到Accel域的第一次数据复制,并使加密步骤使用主机内存作为源。它还通过将DIF INSERT的目的地址设置为最后那个复制操作的目的地址来消除最终的数据复制。然后平台驱动程序运行并识别出这是两个操作 - 加密然后DIF,并且这可以作为单个操作完成,因此它会这样做。
所有这一切的结果是,在 IPU内存中仅分配了一个数据缓冲区,并通过一个硬件操作来执行从主机到IPU 内存的数据移动和转换,但我们保留了SPDK的所有分层和可组合性。
为了结束这个问题,让我们再想象一个场景,其中我们没有可以执行这种组合加密和DIF INSERT的硬件。在这种情况下,我们确实需要在两个步骤之间,在IPU上有一个临时缓冲区,但我们拥有的只是Accel内存域中的伪内存区域。为了解决这个问题,Accel框架可以访问全局SPDK内存池资源,它只是代表你分配一个临时缓冲区并释放它。这很简单,并且它促进了这些临时缓冲区的重用,以将它们保留在缓存中。问题就解决了。
总结一下
我们认为这个框架是一种非常具有表现力、强大且清晰的机制,用于给 IPU 编写软件。我们希望看到它能得到充分利用。当然也承认,对于大多数在常规服务器上使用SPDK的软件开发人员来说,完全不涉及这个问题才是最好的。
因此,我们小心翼翼地使所有这些都是可选项,当不使用它时,一切都会完好地回退到所有数据位于本地系统内存中的假设上。一如既往,很乐意听到SPDK在各种平台和即将上市的IPU产品上如何工作的反馈,请在我们的Slack频道或邮件列表中找到我们!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Python基础之文件操作(I/O)
- HACKTHEBOX通关笔记——wifinetic靶机(已退役)
- Linux: dev: glibc: 里面有很多的关于系统调用的函数
- 利用前缀和求解的lc题目汇总
- 连锁电商管理系统门店拓客+门店进销存管理+门店进货+总部进销存管理 整体系统搭建设计
- 亚信安慧AntDB数据库:赋能行业数智化转型
- JAVA:面向对象1
- 性能测试之使用Jemeter对HTTP接口压测
- 深信服AF防火墙配置SSL VPN
- 制定螺栓扭矩标准时,需要考虑哪些因素?——?SunTorque智能扭矩系统?