YOLOv5改进 | 2023Neck篇 | CCFM轻量级跨尺度特征融合模块(RT-DETR结构改进v5)
?一、本文介绍
本文给大家带来的改进机制是轻量级跨尺度特征融合模块CCFM(Cross-Scale Feature Fusion Module)其主要原理是:将不同尺度的特征通过融合操作整合起来,以增强模型对于尺度变化的适应性和对小尺度对象的检测能力。我将其复现在YOLOv5上,发现其不仅能够降低GFLOP,同时精度上也有很大幅度的提升mAP大概能够提高0.05左右,相对于BiFPN也有一定幅度的上涨。
适用检测目标:所有的目标检测均有一定的提点
推荐指数:?????
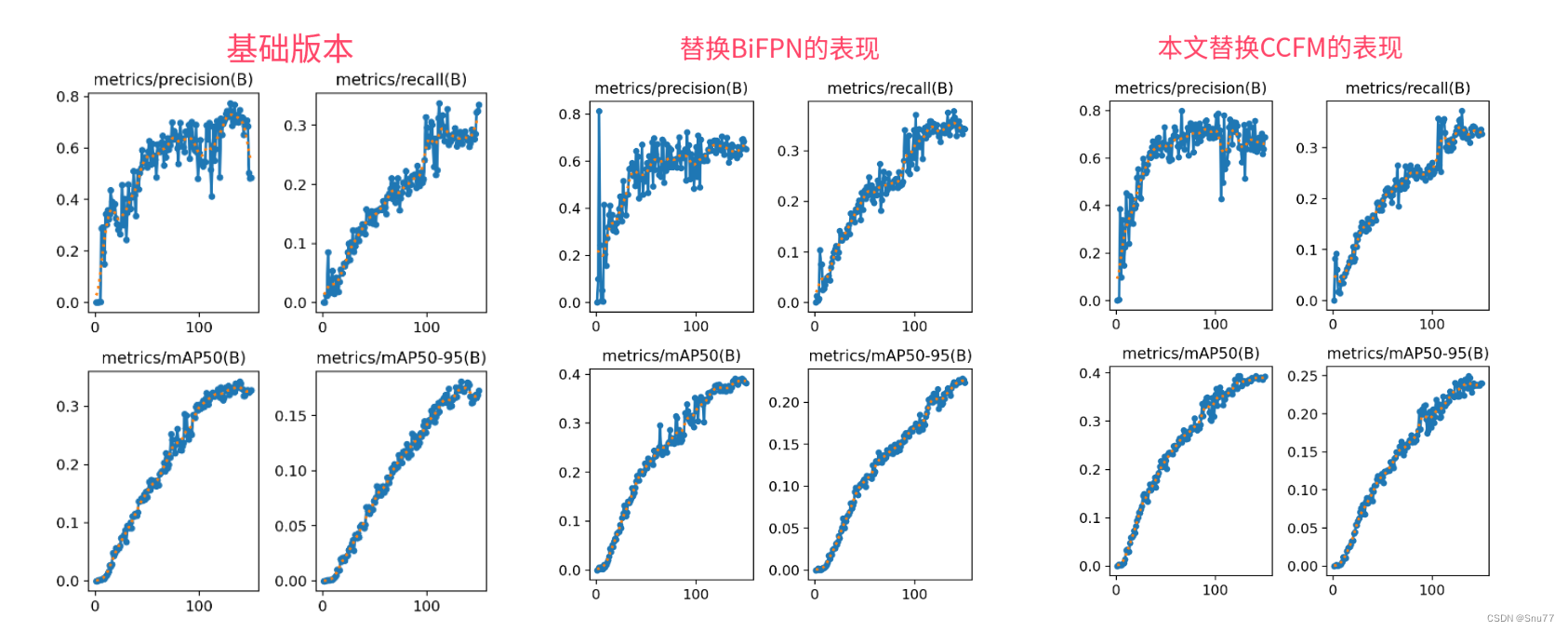
效果回顾展示->
图片分析->在我的数据集上大家可以看到mAP50大概增长了0.05左右这个涨点幅度还是可以的,同时该模块是有二次创新的机会的,后期我会在接下来的文章进行二次创新(进行一个融合性的创新),同时希望大家能够尽早关注我的专栏。
目录
二、CCFM的框架原理

论文地址:RT-DETR论文地址
代码地址:RT-DETR官方下载地址

?
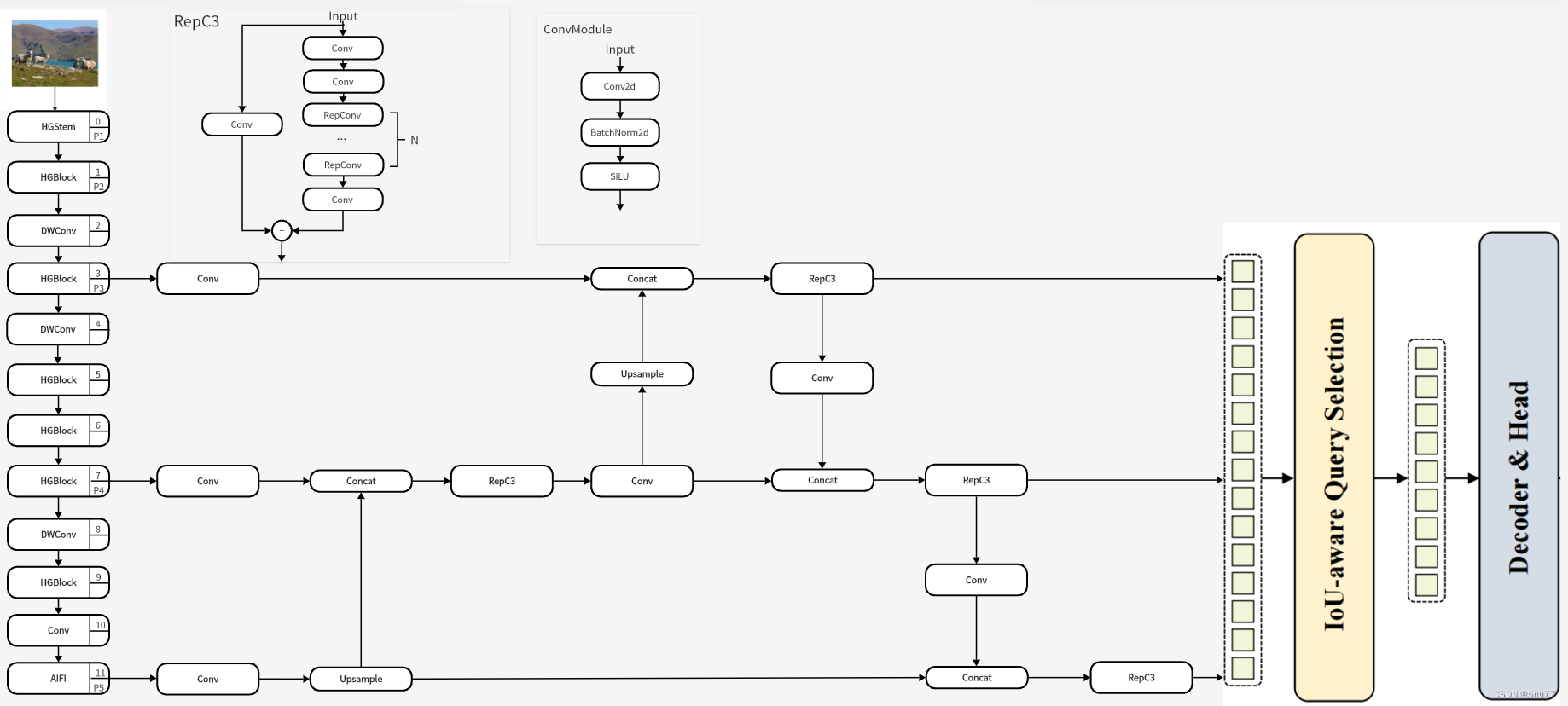
CCFM(Cross-Scale Feature Fusion Module)即为跨尺度特征融合模块。这个模块的作用是将不同尺度的特征通过融合操作整合起来,以增强模型对于尺度变化的适应性和对小尺度对象的检测能力。CCFM可以有效地整合细节特征和上下文信息,从而提高模型的整体性能。其是在RT-DETR中提出的,所以其并没有什么原理结构一说,下面附上我个人手撕的CCFM结构图供大家参考。
这里没什么讲的,给大家说一下RT-DETR吧,也是新出的模型,我已经投出一篇一区目前在外审的状态啦,所以给大家介绍一下该模型,该模型目前在实时监测的领域非常的好发论文,当然不感兴趣的读者直接略过下面的部分即可,直接看第三章和第四章。
?
2.1、模型概览
我们提出的RT-DETR包括一个主干网络(backbone)、一个混合编码器(hybrid encoder)和一个带有辅助预测头的变换器解码器(transformer decoder)。模型架构的概览如下面的图片3所示。

具体来说,我们利用主干网络的最后三个阶段的输出特征 {S3, S4, S5} 作为编码器的输入。混合编码器通过内尺度交互(intra-scale interaction)和跨尺度融合(cross-scale fusion)将多尺度特征转换成一系列图像特征(详见第4.2节)。随后,采用IoU感知查询选择(IoU-aware query selection)从编码器输出序列中选择一定数量的图像特征,作为解码器的初始对象查询(详见第4.3节)。最后,带有辅助预测头的解码器迭代优化对象查询,生成边框和置信度分数。

?
2.2、高效混合编码器
为了加速训练收敛和提高性能,Zhu等人提出引入多尺度特征,并提出变形注意力机制来减少计算量。然而,尽管注意力机制的改进减少了计算开销,但输入序列长度的显著增加仍使编码器成为计算瓶颈,阻碍了DETR的实时实现。如[21]所报告,编码器占了49%的GFLOPs,但在Deformable-DETR中仅贡献了11%的AP。为了克服这一障碍,我们分析了多尺度变换器编码器中存在的计算冗余,并设计了一系列变体来证明内尺度和跨尺度特征的同时交互在计算上是低效的。
高级特征是从包含图像中对象丰富语义信息的低级特征中提取出来的。直觉上,在连接的多尺度特征上执行特征交互是多余的。为了验证这一观点,我们重新思考了编码器结构,并设计了一系列具有不同编码器的变体,如下图所示。

?
这一系列变体通过将多尺度特征交互分解为内尺度交互和跨尺度融合的两步操作,逐渐提高了模型精度,同时显著降低了计算成本(详细指标参见下表3)。
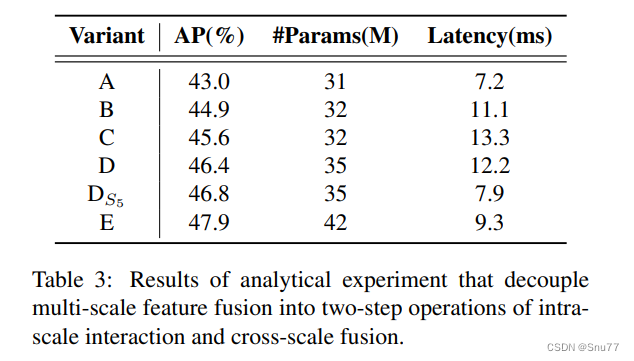
我们首先移除DINO-R50中的多尺度变换器编码器作为基线A。接下来,插入不同形式的编码器,基于基线A生成一系列变体,具体如下:
- A → B:变体B插入了一个单尺度变换器编码器,它使用一个变换器块层。每个尺度的特征共享编码器进行内尺度特征交互,然后连接输出的多尺度特征。
- B → C:变体C基于B引入了跨尺度特征融合,并将连接的多尺度特征送入编码器进行特征交互。
- C → D:变体D将内尺度交互和跨尺度融合的多尺度特征解耦。首先使用单尺度变换器编码器进行内尺度交互,然后使用类似PANet的结构进行跨尺度融合。
- D → E:变体E在D的基础上进一步优化了内尺度交互和跨尺度融合的多尺度特征,采用了我们设计的高效混合编码器(详见下文)。
基于上述分析,我们重新思考了编码器的结构,并提出了一种新型的高效混合编码器。如图3所示,所提出的编码器由两个模块组成,即基于注意力的内尺度特征交互模块(AIFI)和基于CNN的跨尺度特征融合模块(CCFM)。AIFI基于变体D进一步减少了计算冗余,它只在S5上执行内尺度交互。我们认为,将自注意力操作应用于具有更丰富语义概念的高级特征,可以捕捉图像中概念实体之间的联系,这有助于后续模块检测和识别图像中的对象。同时,由于缺乏语义概念,低级特征的内尺度交互是不必要的,存在与高级特征交互重复和混淆的风险。为了验证这一观点,我们仅在变体D中对S5执行内尺度交互,实验结果报告在表3中,见DS5行。与原始变体D相比,DS5显著降低了延迟(快35%),但提高了准确度(AP高0.4%)。这一结论对于实时检测器的设计至关重要。CCFM也是基于变体D优化的,将由卷积层组成的几个融合块插入到融合路径中。融合块的作用是将相邻特征融合成新的特征,其结构如图4所示。融合块包含N个RepBlocks,两个路径的输出通过逐元素加法融合。我们可以将此过程表示如下:
式中,Attn代表多头自注意力,Reshape代表将特征的形状恢复为与S5相同,这是Flatten的逆操作。
?

2.3、IoU感知查询选择
DETR中的对象查询是一组可学习的嵌入,由解码器优化并由预测头映射到分类分数和边界框。然而,这些对象查询难以解释和优化,因为它们没有明确的物理含义。后续工作改进了对象查询的初始化,并将其扩展到内容查询和位置查询(锚点)。其中,提出了查询选择方案,它们共同的特点是利用分类分数从编码器中选择排名靠前的K个特征来初始化对象查询(或仅位置查询)。然而,由于分类分数和位置置信度的分布不一致,一些预测框虽有高分类分数,但与真实框(GT)不接近,这导致选择了分类分数高但IoU分数低的框,而丢弃了分类分数低但IoU分数高的框。这降低了检测器的性能。为了解决这个问题,我们提出了IoU感知查询选择,通过在训练期间对模型施加约束,使其对IoU分数高的特征产生高分类分数,对IoU分数低的特征产生低分类分数。因此,模型根据分类分数选择的排名靠前的K个编码器特征的预测框,既有高分类分数又有高IoU分数。我们重新制定了检测器的优化目标如下:
?其中,和
分别代表预测和真实值,
?和
,
?和
?分别代表类别和边界框。我们将IoU分数引入分类分支的目标函数中(类似于VFL),以实现对正样本分类和定位的一致性约束。
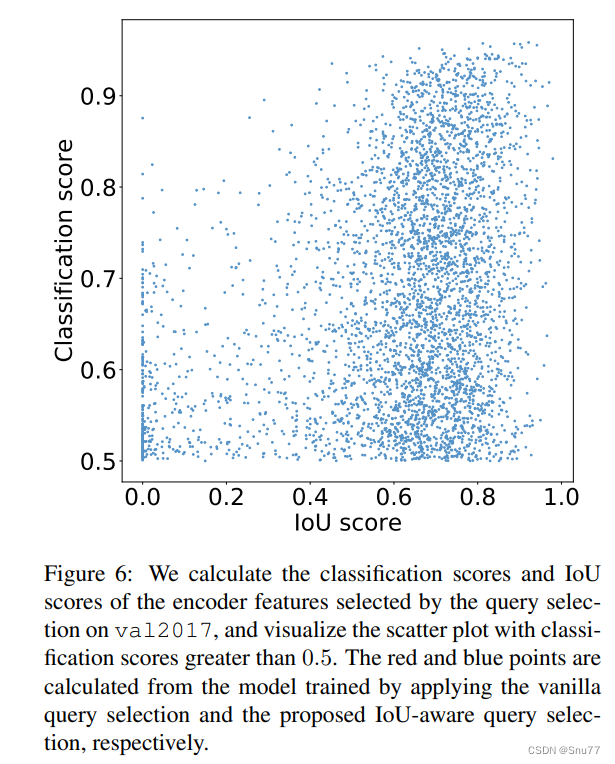
为了分析所提出的IoU感知查询选择的有效性,我们可视化了在val2017数据集上,由查询选择选出的编码器特征的分类分数和IoU分数,如图6所示。具体来说,我们首先根据分类分数选择排名靠前的K(实验中K=300)个编码器特征,然后可视化分类分数大于0.5的散点图。红点和蓝点分别计算自应用传统查询选择和IoU感知查询选择的模型。点越接近图的右上方,相应特征的质量越高,即分类标签和边界框更有可能描述图像中的真实对象。根据可视化结果,我们发现最显著的特点是大量蓝点集中在图的右上方,而红点集中在右下方。这表明,经IoU感知查询选择训练的模型可以产生更多高质量的编码器特征。
此外,我们对两种类型点的分布特征进行了定量分析。图中蓝点比红点多138%,即更多的红点的分类分数小于或等于0.5,可以被认为是低质量特征。然后,我们分析了分类分数大于0.5的特征的IoU分数,发现有120%的蓝点比红点的IoU分数大于0.5。定量结果进一步证明,IoU感知查询选择可以为对象查询提供更多具有准确分类(高分类分数)和精确位置(高IoU分数)的编码器特征,从而提高检测器的准确度。
三、CCFM的核心代码
下面的代码是RepC3的代码,感兴趣的同学可以用其替换C3试一试,但是本文介绍的CCFM结构,所以用不到如下的代码,仅供感兴趣的同学使用,该结构的计算量可能很大,我目前还没有尝试在YOLOv5中使用该模块。
import torch
import torch.nn as nn
import numpy as np
def autopad(k, p=None, d=1): # kernel, padding, dilation
"""Pad to 'same' shape outputs."""
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-size
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class Conv(nn.Module):
"""Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)."""
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
"""Initialize Conv layer with given arguments including activation."""
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
"""Apply convolution, batch normalization and activation to input tensor."""
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
"""Perform transposed convolution of 2D data."""
return self.act(self.conv(x))
class RepConv(nn.Module):
"""
RepConv is a basic rep-style block, including training and deploy status.
This module is used in RT-DETR.
Based on https://github.com/DingXiaoH/RepVGG/blob/main/repvgg.py
"""
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=3, s=1, p=1, g=1, d=1, act=True, bn=False, deploy=False):
"""Initializes Light Convolution layer with inputs, outputs & optional activation function."""
super().__init__()
assert k == 3 and p == 1
self.g = g
self.c1 = c1
self.c2 = c2
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
self.bn = nn.BatchNorm2d(num_features=c1) if bn and c2 == c1 and s == 1 else None
self.conv1 = Conv(c1, c2, k, s, p=p, g=g, act=False)
self.conv2 = Conv(c1, c2, 1, s, p=(p - k // 2), g=g, act=False)
def forward_fuse(self, x):
"""Forward process."""
return self.act(self.conv(x))
def forward(self, x):
"""Forward process."""
id_out = 0 if self.bn is None else self.bn(x)
return self.act(self.conv1(x) + self.conv2(x) + id_out)
def get_equivalent_kernel_bias(self):
"""Returns equivalent kernel and bias by adding 3x3 kernel, 1x1 kernel and identity kernel with their biases."""
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.conv1)
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.conv2)
kernelid, biasid = self._fuse_bn_tensor(self.bn)
return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
def _pad_1x1_to_3x3_tensor(self, kernel1x1):
"""Pads a 1x1 tensor to a 3x3 tensor."""
if kernel1x1 is None:
return 0
else:
return torch.nn.functional.pad(kernel1x1, [1, 1, 1, 1])
def _fuse_bn_tensor(self, branch):
"""Generates appropriate kernels and biases for convolution by fusing branches of the neural network."""
if branch is None:
return 0, 0
if isinstance(branch, Conv):
kernel = branch.conv.weight
running_mean = branch.bn.running_mean
running_var = branch.bn.running_var
gamma = branch.bn.weight
beta = branch.bn.bias
eps = branch.bn.eps
elif isinstance(branch, nn.BatchNorm2d):
if not hasattr(self, 'id_tensor'):
input_dim = self.c1 // self.g
kernel_value = np.zeros((self.c1, input_dim, 3, 3), dtype=np.float32)
for i in range(self.c1):
kernel_value[i, i % input_dim, 1, 1] = 1
self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std
def fuse_convs(self):
"""Combines two convolution layers into a single layer and removes unused attributes from the class."""
if hasattr(self, 'conv'):
return
kernel, bias = self.get_equivalent_kernel_bias()
self.conv = nn.Conv2d(in_channels=self.conv1.conv.in_channels,
out_channels=self.conv1.conv.out_channels,
kernel_size=self.conv1.conv.kernel_size,
stride=self.conv1.conv.stride,
padding=self.conv1.conv.padding,
dilation=self.conv1.conv.dilation,
groups=self.conv1.conv.groups,
bias=True).requires_grad_(False)
self.conv.weight.data = kernel
self.conv.bias.data = bias
for para in self.parameters():
para.detach_()
self.__delattr__('conv1')
self.__delattr__('conv2')
if hasattr(self, 'nm'):
self.__delattr__('nm')
if hasattr(self, 'bn'):
self.__delattr__('bn')
if hasattr(self, 'id_tensor'):
self.__delattr__('id_tensor')
class RepC3(nn.Module):
"""Rep C3."""
def __init__(self, c1, c2, n=3, e=1.0):
"""Initialize CSP Bottleneck with a single convolution using input channels, output channels, and number."""
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c2, 1, 1)
self.cv2 = Conv(c1, c2, 1, 1)
self.m = nn.Sequential(*[RepConv(c_, c_) for _ in range(n)])
self.cv3 = Conv(c_, c2, 1, 1) if c_ != c2 else nn.Identity()
def forward(self, x):
"""Forward pass of RT-DETR neck layer."""
return self.cv3(self.m(self.cv1(x)) + self.cv2(x))
四、手把手教你添加CCFM
CCFM无需要添加任何代码,只需要复制粘贴我的yaml文件运行即可。
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [256, 1, 1]], # 10, Y5, lateral_convs.0
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[6, 1, Conv, [256, 1, 1, None, 1, 1, False]], # 12 input_proj.1
[[-2, -1], 1, Concat, [1]],
[-1, 3, C3, [256]], # 14, fpn_blocks.0
[-1, 1, Conv, [256, 1, 1]], # 15, Y4, lateral_convs.1
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[4, 1, Conv, [256, 1, 1, None, 1, 1, False]], # 17 input_proj.0
[[-2, -1], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [256]], # X3 (19), fpn_blocks.1
[-1, 1, Conv, [256, 3, 2]], # 220, downsample_convs.0
[[-1, 15], 1, Concat, [1]], # cat Y4
[-1, 3, C3, [256]], # F4 (22), pan_blocks.0
[-1, 1, Conv, [256, 3, 2]], # 25, downsample_convs.1
[[-1, 10], 1, Concat, [1]], # cat Y5
[-1, 3, C3, [256]], # F5 (25), pan_blocks.1
[[19, 22, 25], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
五、完美运行截图?
六、本文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv5改进有效涨点专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,(目前本专栏免费阅读(暂时,大家尽早关注不迷路~),如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- google 内购记录
- JoySSL免费证书的优势
- 2024年,软件测试未来可期?
- 2 微信小程序
- 【LeetCode】203. 移除链表元素
- 大话 JavaScript(Speaking JavaScript):第三十一章到第三十三章
- Kettle Local引擎使用记录(基于Kettle web版数据集成开源工具data-integration源码)
- 苹果电脑Dock栏优化软件 mac功能亮点
- 固定翼无人机入门(二)
- Java中HashSet如何检查重复