重学MySQL之关系型数据库和非关系型数据库
1 关系型数据库
1.1 关系型数据库的特性
1.1.1 事务的特性
事务,是指一个操作序列,这些操作要么都执行,或者都不执行,而且这一序列是无法分隔的独立操作单位。也就是符合原子性(Atomicity)、 一致性(Consistency)、 隔离性(Isolation)和持久性(Durability)的一组操作。
- 原子性:指一个事务中的所有操作全部提交成功,或者全部失败。不存在中间过程。
- 一致性:指的是在一个事务执行前后中,读取的数据都是一致相同的。
- 隔离性:指一个事务与另外的事物操作过程中的相互隔离的,其他事务无法查看其中间过程。
- 持久性:指一个事务一旦提交,哪怕是系统故障,所做的修改将会永远保存在数据库中。
其中一致性是事务实现的目标,其他特性相当于是为了保证事务一致性的手段,比如原子性是保证事务执行操作不存在中间过程,无法分隔,保证事务的一致性;隔离性指在并发时防止事务之间相互干预影响,确保最后事务执行前后的一致性;持久性是哪怕系统崩溃出现故障时,数据修改也永远保存在数据库中,也确保了事务执行前后的一致性。
1.1.2 事务的隔离
上面说到事务的隔离性,就是为了防止在并发时事务之间相互影响,那么如果没有事务之间的隔离,会发生哪些现象呢?
- 丢失更新
一个事务的撤销操作覆盖了另一个事务已提交的更新数据,比如有两个事务对统一账户进行操作,如下图所示:
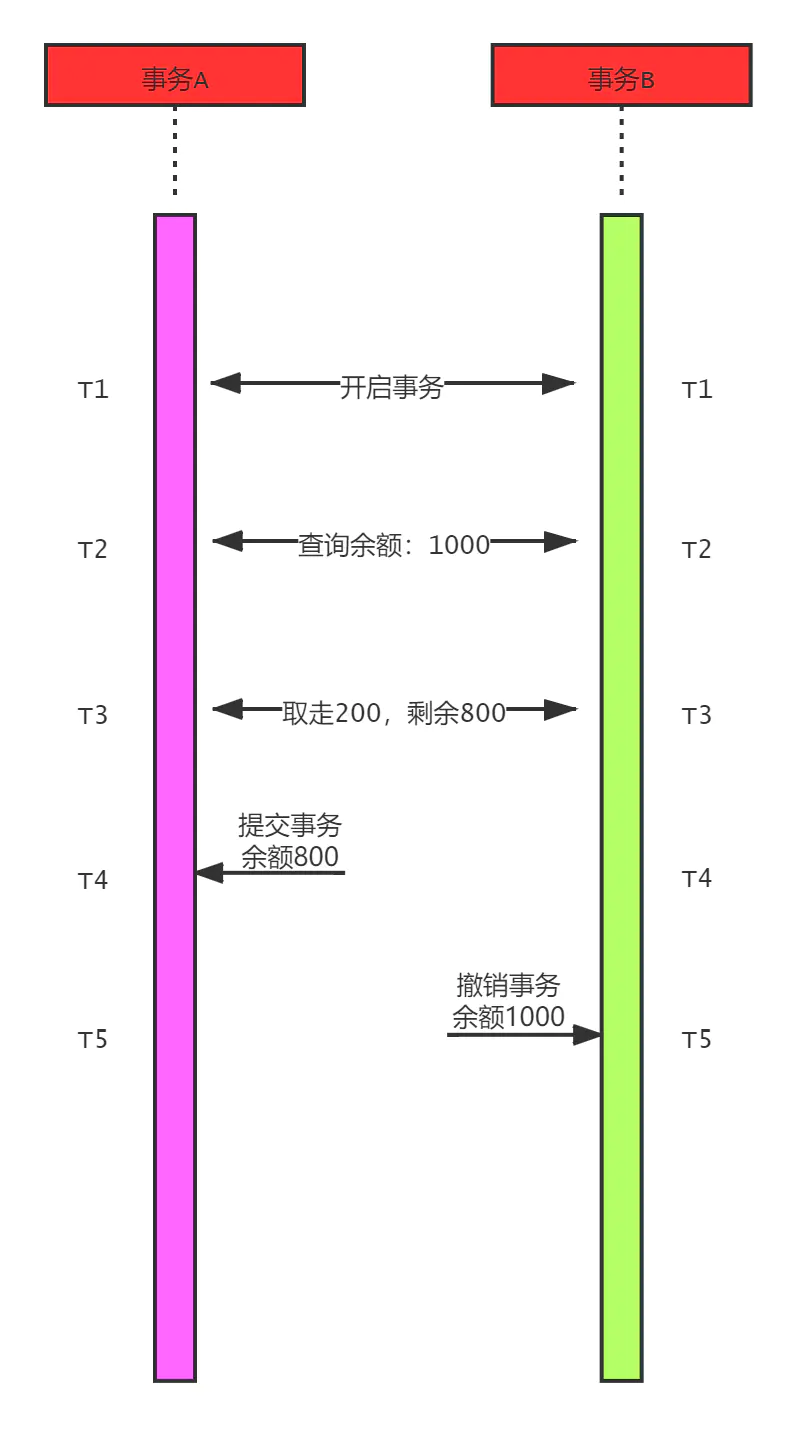
在T3时刻两个事务都完成了取走200的操作,在T4时刻事务A提交余额,但是在T5时刻事务B撤销事务,如果没有隔离,那么会发生账户金额不变,却取走200的事情发生。
- 脏读
脏读指的是一个事务读取到另一个事务未提交的数据,如下图所示:

在T3时刻事务A取走200,但是在事务A提交撤销前,事务B在T4时刻对账户进行查询操作会读取到错误的信息。比如某人从账户中取出200,没有提交不想取了,提交撤销命令,如果这个时候在提交前有另一事务对该账户进行查询,会发现账户没取到钱却少200。
- 幻读(虚读)
虚读其实也是一种不可重复读的现象,是指一个事务读到了另一个事务已经提交的新增数据,重点是新增或者删除,读取前后数据量不一致。如图:

比如事务A在新增数据后提交,在T2、T5时刻事务B的两次查询就会不一样,好像发生了幻觉一样。这就是幻读,发生了不存在的事情
- 不可重复读
一个事务读取到了另一个事务已经提交的更新数据,重点是修改,读取前后数据量一致,内容不一致。如图:
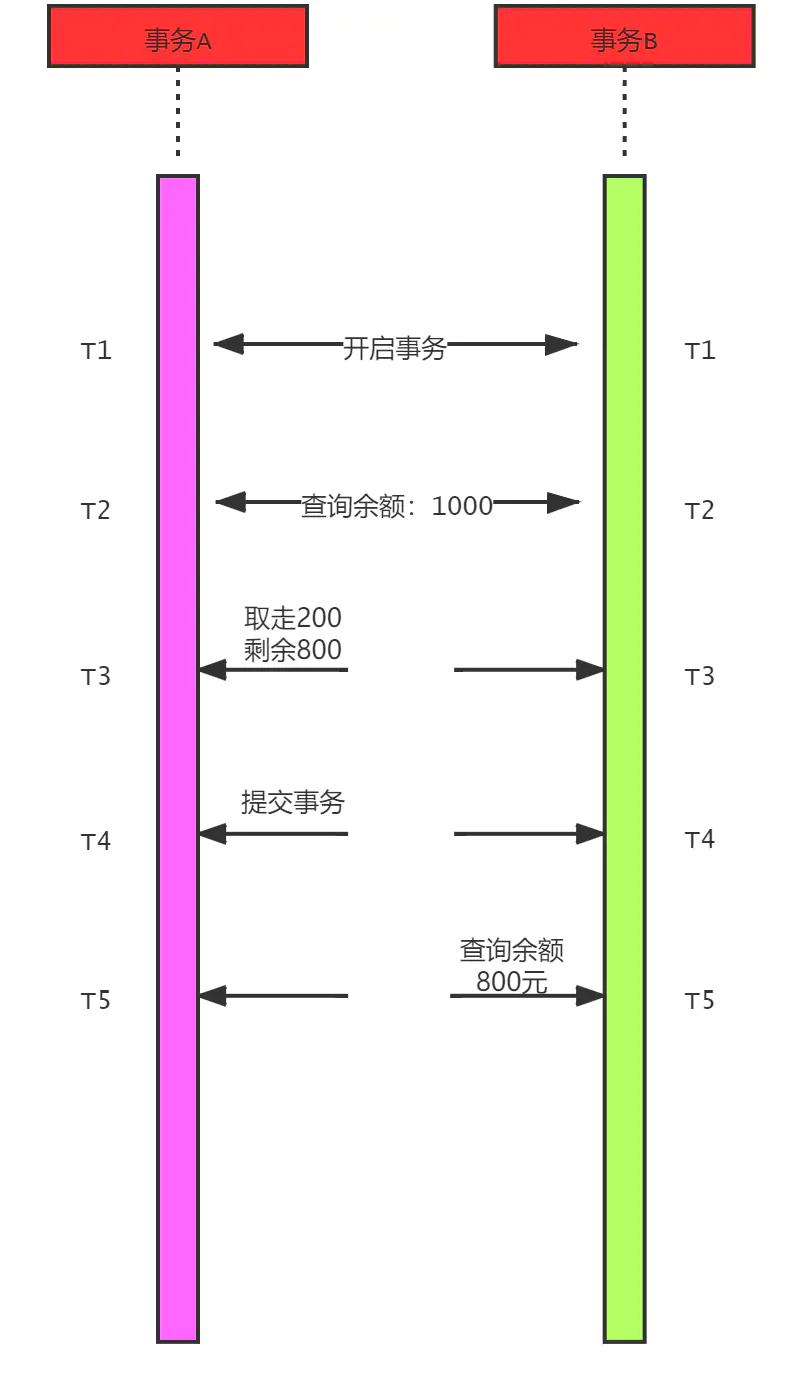
事务B在两次查询中发现数据库结果不一样
幻读和不可重复读的区别?
幻读重点是操作的新增或删除,不可重复读的重点是操作的修改。在读取上两者类似
但是在隔离控制上,针对于两种情况,对于不可重复读,只需要锁住满足条件的记录(如出现内部不一致的哪一行数据即可);对于幻读,因为出现了数据量不一致,不仅需要所著满足条件的记录,甚至于要锁住相近的记录或者(多行数据或者整个表)
1.1.3 隔离级别
- 1.读未提交(Read Uncommited)
一个事务可以读到另一个事务未提交的数据
- 2.读已提交(Read Commited )
一个事务可以读到另一个事务提交到的数据
- 3.可重复读(Repeatable Read)
一个事务中相同的查询会看到同样的数据行,也就是事务在执行期间看到的数据前后必须是一致的。是MySQL默认的隔离级别
- 4.串行化(Serializable)
事务之间以一种串行的方式执行,安全性非常高
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交 | 否 | 否 | 否 |
| 读已提交 | 是 | 否 | 否 |
| 可重复读 | 是 | 是 | 否 |
| 串行化 | 是 | 是 | 是 |
1.1.4 范式
关系型数据库一般遵循三范式设计思想
- 第一范式
要求对属性的原子性,也就是数据库中的字段要具备原子性,不能再被拆分。
- 第二范式
在满足第一范式的前提下,要保证数据表中的实例或行必须可以被唯一区分。
- 第三范式
在满足第一、二范式的前提下,保证数据表中的所有非主键字段必须直接依赖主键,每个表中不包含其他表中已经包含的非主键关键字段的信息。
1.2 MySQL索引
数据库索引是数据库管理系统中的一个排序的数据结构,用于协助快速查询、更新数据库表中的数据。通常使用B树或B+树来实现
1.2.1 B+ 树索引
是大多数MySQL存储引擎的默认索引类型,而且因为B+树的有序性,除了用于查找,还可以用于排序和分组,同时可以指定多个列作为索引列,多个索引列共同组成键。
InnoDB 的 B+ 树索引分为主索引和辅助索引。主索引的叶子节点data 域记录着完整的数据记录,一个表只能有一个聚簇索引。辅助索引的叶子节点的data域记录着主键的值,在使用辅助索引进行查找时,需要先查到主键值,然后再到主索引中进行查找。
1.2.2 哈希索引
能以O(1)时间进行查找,但是失去了有序性,只能支持精确查找,无法用于排序和分组
1.2.3 全文索引
MyISAM 存储索引支持全文索引,用于查找文本中的关键词,不是直接比较是否相等
1.2.4 空间数据索引
MyISAM存储引擎支持空间数据索引,可以用于地理数据存储。空间数据索引会从所有维度来索引数据,可以有效地使用任意维度来进行组合查询
MySQL 的优化方案有哪些?
(1)SQL和索引优化
- 适当使用前缀索引,减少索引长度他,提高查询效率
- 查询具体字段非全部字段
- 优化子查询
- 尽量使用小表驱动大表的方式查询
- 不要再列字段上进行运算操作
- 适当增加冗余字段,以减少多张表的关联查询,以空间换时间的优化策略
(2)数据库结构优化
- 最小数据长度,如将表的字段设置的尽可能小,提高表的效率
- 使用最简单的数据类型,比如int就要比varchar查询效率快
- 尽量少定义text类型
- 适当分表(当一张表中的字段更多时,可以尝试将大表拆分成多张子表,高频的主信息放入主表中,其他放入子表),分库(将一个数据库拆分成多个数据库,主数据库用于写入和修改数据,其他的用于同步主数据并提供给客户端查询)
(3)硬件优化
- 硬盘,使用高性能的磁盘
- 网络,保证网络带宽
- 内存,提高 MySQL 服务器的内存
1.3 MySQL存储引擎
在选择数据库引擎时要从实际业务出发,比如是否需要支持事务、外键、持久化等等。
1.3.1 InnoDB
InnoDB 是MySQL 5.5.5后的默认数据引擎,优点是支持事务和四种隔离级别,此外还支持外键、崩溃后的快速回复、支持全文检索、集群索引以及地理位置类型的存储和索引等功能。在MySQL8.0前重启服务InnoDB自增索引会丢失,无法自增。MyISAM引擎可以自增ID
1.3.2 MyISAM
它是 MyISAM 原生引擎,不支持事务功能,有独立的索引文件,对比InnoDB不支持外键
2.非关系型数据库(NoSQL)
非关系型数据库(NoSQL)不同于传统的关系型数据库,通常用于超大规模数据的存储,因为这些数据存储不需要固定的模式,无需多余操作就可以横向扩展。
2.1 NoSQL的相关特性
2.1.1 CAP定理
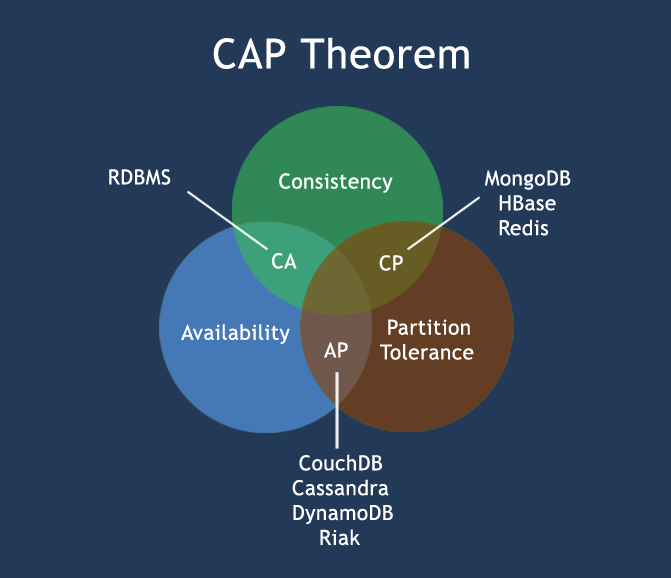
在计算机科学中, CAP定理(CAP theorem), 又被称作 布鲁尔定理(Brewer’s theorem), 它指出对于一个分布式计算系统来说,不可能同时满足以下三点:
- 一致性(Consistency) (所有节点在同一时间具有相同的数据)
- 可用性(Availability) (保证每个请求不管成功或者失败都有响应)
- 分隔容忍(Partition tolerance) (系统中任意信息的丢失或失败不会影响系统的继续运作)
CAP理论的核心是:一个分布式系统不可能同时很好的满足一致性,可用性和分区容错性这三个需求,最多只能同时较好的满足两个。
因此,根据 CAP 原理将 NoSQL 数据库分成了满足 CA 原则、满足 CP 原则和满足 AP 原则三 大类:
- CA - 单点集群,满足一致性,可用性的系统,通常在可扩展性上不太强大。
- CP - 满足一致性,分区容忍性的系统,通常性能不是特别高。
- AP - 满足可用性,分区容忍性的系统,通常可能对一致性要求低一些。
2.1.2 BASE特性
BASE:Basically Available, Soft-state, Eventually Consistent。 由 Eric Brewer 定义。
CAP理论的核心是:一个分布式系统不可能同时很好的满足一致性,可用性和分区容错性这三个需求,最多只能同时较好的满足两个。
BASE是NoSQL数据库通常对可用性及一致性的弱要求原则:
- Basically Available --基本可用
- Soft-state --软状态/柔性事务。 “Soft state” 可以理解为"无连接"的, 而 “Hard state” 是"面向连接"的
- Eventually Consistency – 最终一致性, 也是 ACID 的最终目的。
ACID vs BASE
| ACID | BASE |
|---|---|
| 原子性(Atomicity) | 基本可用(Basically Available) |
| 一致性(Consistency) | 软状态/柔性事务(Soft state) |
| 隔离性(Isolation) | 最终一致性 (Eventual consistency) |
| 持久性 (Durable) |
2.2 NoSQL 数据库分类
| 类型 | 部分代表 | 特点 |
|---|---|---|
| 列存储 | Hbase Cassandra Hypertable | 顾名思义,是按列存储数据的。最大的特点是方便存储结构化和半结构化数据,方便做数据压缩,对针对某一列或者某几列的查询有非常大的IO优势。 |
| 文档存储 | MongoDB CouchDB | 文档存储一般用类似json的格式存储,存储的内容是文档型的。这样也就有机会对某些字段建立索引,实现关系数据库的某些功能。 |
| key-value存储 | Tokyo Cabinet / TyrantBerkeley DB MemcacheDB Redis | 可以通过key快速查询到其value。一般来说,存储不管value的格式,照单全收。(Redis包含了其他功能) |
| 图存储 | Neo4J FlockDB | 图形关系的最佳存储。使用传统关系数据库来解决的话性能低下,而且设计使用不方便。 |
| 对象存储 | db4o Versant | 通过类似面向对象语言的语法操作数据库,通过对象的方式存取数据。 |
| xml数据库 | Berkeley DB XML BaseX | 高效的存储XML数据,并支持XML的内部查询语法,比如XQuery,Xpath。 |
| 全文搜索数据库 | ElasticSearch solr | 它们的出现解决了关系型数据库全文搜索功能较弱的问题 |
2.2.1 文档型数据库
文档型数据库通常以 JSON 或者 XML 为格式进行数据存储,主要以 MongoDB 和 Apache CouchDB 为代表。适用于敏捷开发、日志系统和社交系统等
MongoDB
MongoDB 是由 C++ 语言编写的基于分布式文件存储的开源数据库系统。在高负载的情况下,能添加更多的节点,可以保证服务器性能。MongoDB 将数据存储为一个文档,数据结构由键值(key => value)对组成。MongDB 文档类似于 JSON 对象。字段值可以包含其他文档,数据以及文档数组。其结构类似如下:
{
id: 123,
name: "wang",
sex: "male",
group: [ "news", "sports" ]
}
MongoDB 是以 JSON 格式存储数据,它对 JSON 做了一些优化能支持更多的数据类型,称为 BSON 。BSON 具有三个特点: 轻量、可遍历以及高效, 他的缺点是空间利用率不是很高。但是它拥有比关系型数据库更快的开发速度。
MongoDB 在 4.0 前是不支持事务,在 4.2 中实现了分布式事务的功能。
2.2.2 全文搜索型数据库
传统的关系型数据库主要依赖索引来实现快速查询功能,但是在全文搜索的业务下,索引很难满足查询的需求。关系型数据库的模糊匹配在数据量较大的情况下查询的效率是很低的。需要创建大量的索引,因此也需要专门的全文搜索引擎及相关的数据库来实现
2.2.3 键值型数据库
键值型数据库通常被当作非持久化的内存型数据库缓存来使用,典型代表数据库是 Redis 和 Memcached 。此类数据的优点是性能比较高,但是对事务的支持不是很好。
Redis 介绍
见
参考博文:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- C++大整数类/高精度类(上万位数秒算)
- 大面积太阳能光伏组件紫外预处理试验箱模拟器
- AIGC|一文梳理「AI视频生成」技术核心基础知识和模型应用
- 实习知识整理7:SpringBoot和html+thymeleaf模板的项目的相关配置文件
- Constellation: Chainlink 黑客马拉松的获奖者
- 微调(fine-tuning)
- 蓝桥杯2024/01/18 小结
- 插件和工具汇总
- Java设计模式:状态模式
- 一天吃透SpringMVC面试八股文