transformer优化(二)-DETR 学习笔记
论文地址:https://arxiv.org/pdf/2005.12872.pdf
代码地址:https://github.com/bubbliiiing/detr-pytorch
https://github.com/facebookresearch/detr
1.是什么?
DETR(Detection Transformer)是一种基于Transformer的目标检测模型。它采用了一种全新的思路,将目标检测问题转化为一个集合预测问题。相比传统的目标检测方法,DETR不需要使用锚框或者候选框,而是直接从输入图像中预测出一组目标的边界框和类别。
DETR的整体结构如下:
- 编码器(Encoder):使用一系列的Transformer编码器层来提取输入图像的特征表示。
- 解码器(Decoder):使用一系列的Transformer解码器层来生成目标的边界框和类别预测。
- 多头自注意力机制(Multi-Head Self-Attention):用于捕捉目标之间的关系和上下文信息。
- 线性层和位置编码:用于将特征映射到目标的边界框和类别预测。
DETR的实现思路是通过Transformer模型来实现目标检测任务。它将目标检测问题转化为一个集合预测问题,通过直接从输入图像中预测出一组目标的边界框和类别来完成目标检测任务。
2.为什么?
提出了一种将目标检测视为直接集预测问题的新方法。我们的方法简化了检测管道,有效地消除了许多手工设计的组件,如非最大抑制过程或锚生成,这些组件显式地编码了我们对任务的先验知识。新框架的主要组成部分,称为检测变压器或DETR,是一个基于集合的全局损失,通过二部匹配强制进行唯一预测,以及一个变压器编码器-解码器架构。给定一组固定的小学习对象查询,DETR对对象和全局图像上下文的关系进行推理,以直接并行输出最终的预测集。新模型在概念上很简单,不像许多其他现代探测器那样需要专门的库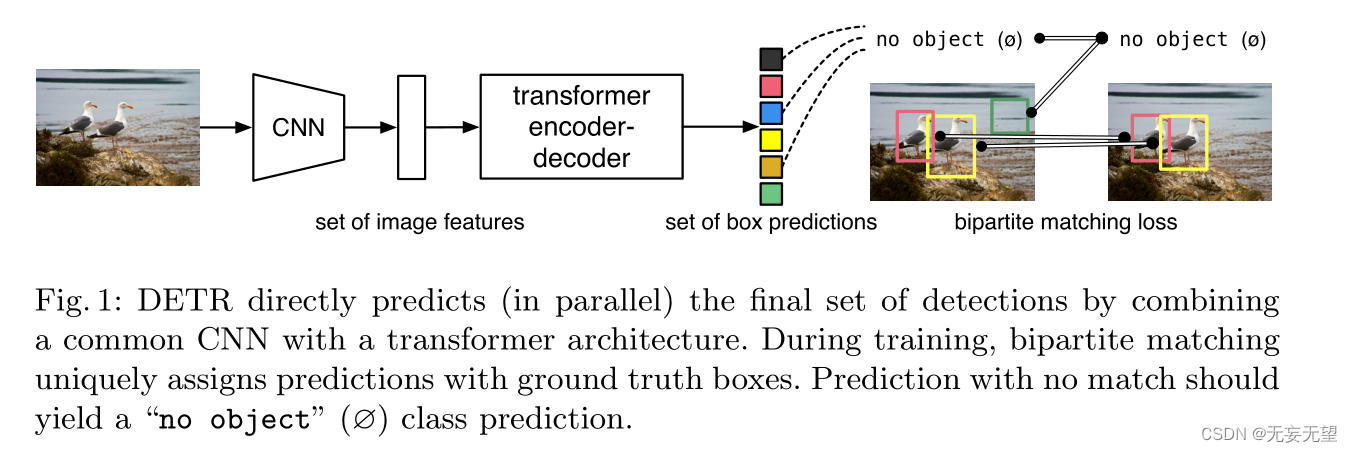
3.怎么样?
3.1网络结构
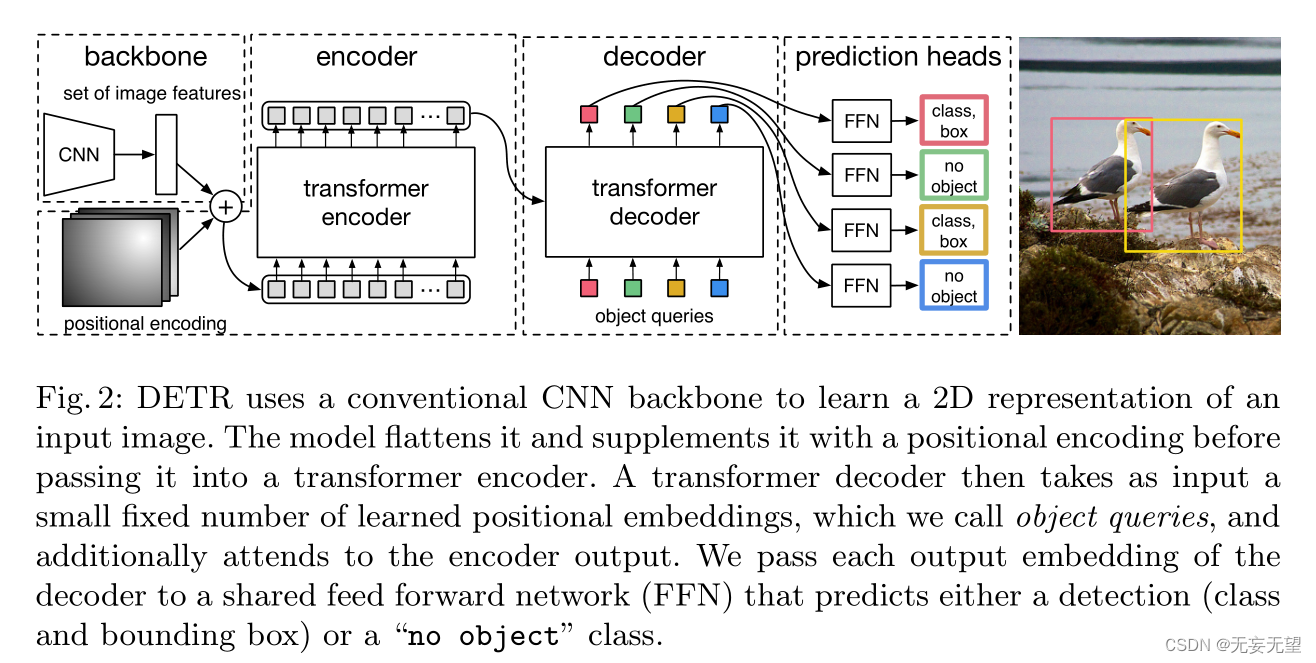
DETR的网络结构如图1所示,从图中可以看出DETR由四个主要模块组成:backbone,编码器,解码器以及预测头。
DETR使用传统的CNN主干来学习输入图像的二维表示。在将其传递到变压器编码器之前,模型将其扁平化并使用位置编码进行补充。然后,转换器解码器将少量固定数量的学习到的位置嵌入(我们称之为对象查询)作为输入,并额外关注编码器输出。我们将解码器的每个输出嵌入传递给一个共享前馈网络(FFN),该网络预测检测(类和边界框)或“无对象”类。
3.2原理分析
3.2.1?骨干网络
DETR的骨干网络是经典的卷积网络,它的输入定义为:?,它的输出是降采样?32?倍的Feature Map,表示为:
,其中?C=2048?,?H=
?以及?W=
。在实验中作者使用的是ResNet-50或者ResNet-101作为基础网络。
3.2.2?Transformer编码器
Transformer编码器的详细结构如图2左侧部分所示。在得到Feature Map之后,DETR首先通过一个?1×1?卷积将其通道数调整为更小的?d?,得到一个大小为?d×H×W?的新的Feature Map。DETR的下一步则是将其转换为序列数据,这一步是通过reshape操作完成的,转换之后的数据维度是?d×(HW)?。因为Transformer是与输入数据的顺序无关的,因此它需要加上位置编码加入位置信息。这一部分会作为编码器的输入。DETR的编码器的Transformer使用的是多头自注意力模型加上一个MLP。
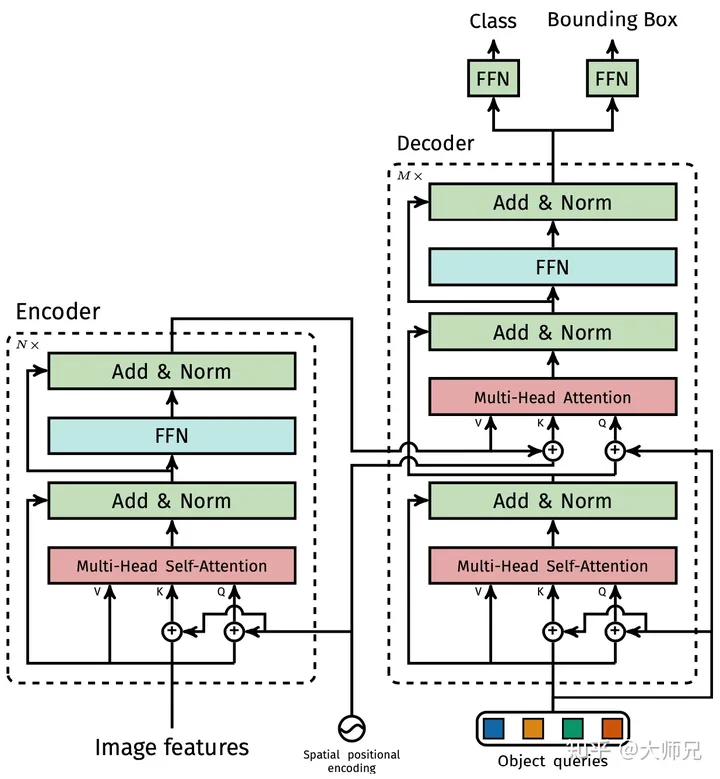
DETR的位置编码是分别计算了两个维度的位置编码,然后将它们拼接到一起。其中每个维度的位置编码使用的是和Transformer相同的计算方式。?
3.2.3 Transformer解码器
DETR的解码器如图2右侧部分所示,它有两个输入,一个是编码器得到的特征,另外一个是object queries。这里我们重点讲一下object queries。
在DETR中,object queries的作用类似于基于CNN的目标检测算法中的anchor boxes。它共有?N?个(N?是一个事先设定好的超参,它的值远大于一个图片中的目标数)。N?个不同的object queries输入的解码器中便会得到?N?个decoder output embedding,它们经过最后的MLP得到?N?个预测结果。不同的N?个Object queries保证了?N?个不同的预测结果,Object queries是一个可以训练的嵌入向量,它通过和ground truth的匈牙利匹配(附件A)来向不同的ground truth进行优化。
注意这?N?个结果不是顺序得到的,而是一次性得到?N?个结果,这点和原始的Transformer的自回归计算是不同的。
3.2.4?MLP预测头
预测头是一个3层的Perceptron,激活函数使用的是ReLU,隐层节点数是d?。每个Object queries通过预测头预测目标的bounding box和类别,其中bounding box有三个值,分别是目标的中心点以及宽和高。DETR共预测?N?个bounding box,?N?是一个远大于图片中目标个数的值,超过目标个数的ground truth使用背景元素来作为负样本。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!