强化学习:PPO
PPO简介
我们在之前的项目中介绍了基于价值的强化学习算法DQN,基于策略的强化学习算法REINFORCE,基于价值和策略的组合算法Actor-Critic. 对于基于策略分方法:参数化智能体的策略,并设计衡量策略好坏的目标函数,通过梯度上升的方法来最大化这个目标函数,使得策略最优。但是这种算法有一个明显的缺点:当策略网络是深度模型时,沿着策略梯度更新参数,很有可能由于步长太长,策略突然显著变差,进而影响训练效果。一种有效的解决方法是信任区域策略优化(trust region policy optimization,TRPO);然而TRPO的计算过程非常复杂,每一步更新的运算量非常大,进而其改进版算法PPO被提出。主流的PPO有两种,PPO-Penalty和PPO-Clip,但大量的实验表明PPO-Clip要更优秀一些,因此本项目采用PPO-Clip方法。
PPO算法
PPO算法用到了两个网络:策略网络,价值网络(actor-critic)。PPO是on-policy,交互的策略由我们的策略网络直接生成。需要注意的是,在训练时,我们仅使用上一轮策略的交互信息而不是过去所有的交互信息。具体的算法如下(来自论文《Proximal Policy Optimization Algorithms》):?
1.导入依赖包
- paddle框架
- gym环境库
- matplotlib画图工具
- tqdm进度条显示
- numpy科学计算库
- random随机操作库
In [1]
import paddle
import paddle.nn.functional as F
import paddle.nn as nn
import gym
import matplotlib.pyplot as plt
from matplotlib import animation
from tqdm import tqdm
import numpy as np
import random/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/__init__.py:107: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import MutableMapping
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/rcsetup.py:20: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import Iterable, Mapping
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/colors.py:53: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import Sized2.定义策略网络、价值网络
- 策略网络:两个全连接层,最后的输出经过softmax函数处理(因为是动作是离散的)
- 价值网络:两个全连接层,输出是维度是1,表示'价值'
In [2]
class PolicyNet(paddle.nn.Layer):
def __init__(self, state_dim, hidden_dim, action_dim):
super(PolicyNet, self).__init__()
self.fc1 = paddle.nn.Linear(state_dim, hidden_dim)
self.fc2 = paddle.nn.Linear(hidden_dim, action_dim)
def forward(self, x):
x = F.relu(self.fc1(x))
return F.softmax(self.fc2(x))
class ValueNet(paddle.nn.Layer):
def __init__(self, state_dim, hidden_dim):
super(ValueNet, self).__init__()
self.fc1 = paddle.nn.Linear(state_dim, hidden_dim)
self.fc2 = paddle.nn.Linear(hidden_dim, 1)
def forward(self, x):
x = F.relu(self.fc1(x))
return self.fc2(x)3.定义PPO智能体
- 首先定义优势计算函数compute_advantage
- 定义PPO算法类
- init:初始化函数,包括策略网络,价值网络,两个网络的优化器,折扣因子等参数
- take_action:动作抽样函数,使用分类分布函数Categorical
- update:网络的更新操作,clip方式
- save:保存网络,仅保存了策略网络
- load:加载网络,仅加载了策略网络
In [3]
# 计算优势advantage
def compute_advantage(gamma, lmbda, td_delta):
td_delta = td_delta.detach().numpy()
advantage_list = []
advantage = 0.0
for delta in td_delta[::-1]:
advantage = gamma * lmbda * advantage + delta
advantage_list.append(advantage)
advantage_list.reverse()
return paddle.to_tensor(advantage_list, dtype='float32')In [4]
class PPO:
''' PPO-clip,采用截断方式 '''
def __init__(self, state_dim, hidden_dim, action_dim, actor_lr, critic_lr,lmbda,
epochs, eps, gamma):
self.actor = PolicyNet(state_dim, hidden_dim, action_dim)
self.critic = ValueNet(state_dim, hidden_dim)
self.actor_optimizer = paddle.optimizer.Adam(parameters=self.actor.parameters(),
learning_rate=actor_lr)
self.critic_optimizer = paddle.optimizer.Adam(parameters=self.critic.parameters(),
learning_rate=critic_lr)
self.gamma = gamma
self.lmbda = lmbda
self.epochs = epochs # 一条序列的数据用于训练轮数
self.eps = eps # PPO中截断范围的参数
def take_action(self, state):
state = paddle.to_tensor(state, dtype='float32')
probs = self.actor(state)
action_dist = paddle.distribution.Categorical(probs)
action = action_dist.sample([1])
return action.numpy()[0]
def update(self, transition_dict):
states = paddle.to_tensor(transition_dict['states'],dtype='float32')
actions = paddle.to_tensor(transition_dict['actions']).reshape([-1, 1])
rewards = paddle.to_tensor(transition_dict['rewards'],dtype='float32').reshape([-1, 1])
next_states = paddle.to_tensor(transition_dict['next_states'],dtype='float32')
dones = paddle.to_tensor(transition_dict['dones'],dtype='float32').reshape([-1, 1])
td_target = rewards + self.gamma * self.critic(next_states) * (1 -dones)
td_delta = td_target - self.critic(states)
advantage = compute_advantage(self.gamma, self.lmbda,td_delta)
old_log_probs = paddle.log(self.actor(states).gather(axis=1,index=actions)).detach()
for _ in range(self.epochs):
log_probs = paddle.log(self.actor(states).gather(axis=1, index=actions))
ratio = paddle.exp(log_probs - old_log_probs)
surr1 = ratio * advantage
surr2 = paddle.clip(ratio, 1 - self.eps,1 + self.eps) * advantage # 截断
actor_loss = paddle.mean(-paddle.minimum(surr1, surr2)) # PPO损失函数
critic_loss = paddle.mean(F.mse_loss(self.critic(states), td_target.detach()))
self.actor_optimizer.clear_grad()
self.critic_optimizer.clear_grad()
actor_loss.backward()
critic_loss.backward()
self.actor_optimizer.step()
self.critic_optimizer.step()
def save(self):
paddle.save(self.actor.state_dict(),'net.pdparams')
def load(self):
layer_state_dict = paddle.load("net.pdparams")
self.actor.set_state_dict(layer_state_dict) 4.参数定义
In [5]
actor_lr = 1e-3 #策略网络的学习率
critic_lr = 1e-2 #价值网络的学习率
num_episodes = 100 # 训练的episode,不宜训练太长,否则性能下降
hidden_dim = 128 #网络隐藏层
gamma = 0.98 # 折扣因子
lmbda = 0.95 # 优势计算中的参数
epochs = 10 #每次更新时ppo的更新次数
eps = 0.2 # PPO中截断范围的参数
env_name = 'CartPole-v0'
env = gym.make(env_name)
# env.seed(100)
# paddle.seed(100)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
5.训练
on-policy的训练方式,每次更新网络仅使用该轮的交互信息。我们使用tqdm来显示训练进度,并绘制奖励曲线图。
In [6]
def train_on_policy_agent(env, agent, num_episodes):
return_list = []
maxre=0
for i in range(10):
with tqdm(total=int(num_episodes/10), desc='Iteration %d' % i) as pbar:
for i_episode in range(int(num_episodes/10)):
episode_return = 0
transition_dict = {'states': [], 'actions': [], 'next_states': [], 'rewards': [], 'dones': []}
state = env.reset()
done = False
while not done:
action = agent.take_action(state)
next_state, reward, done, _ = env.step(action)
transition_dict['states'].append(state)
transition_dict['actions'].append(action)
transition_dict['next_states'].append(next_state)
transition_dict['rewards'].append(reward)
transition_dict['dones'].append(done)
state = next_state
episode_return += reward
# 保存最大epoisde奖励的参数
if maxre<episode_return:
maxre=episode_return
agent.save()
return_list.append(episode_return)
agent.update(transition_dict)
if (i_episode+1) % 10 == 0:
pbar.set_postfix({'episode': '%d' % (num_episodes/10 * i + i_episode+1), 'return': '%.3f' % np.mean(return_list[-10:])})
pbar.update(1)
return return_list
ppo_agent = PPO(state_dim, hidden_dim, action_dim, actor_lr, critic_lr, lmbda,epochs, eps, gamma)
return_list = train_on_policy_agent(env, ppo_agent, num_episodes)
W0907 13:17:20.133046 220 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 10.1
W0907 13:17:20.138145 220 device_context.cc:465] device: 0, cuDNN Version: 7.6.
Iteration 0: 0%| | 0/10 [00:00<?, ?it/s]/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/tensor/creation.py:130: DeprecationWarning: `np.object` is a deprecated alias for the builtin `object`. To silence this warning, use `object` by itself. Doing this will not modify any behavior and is safe.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
if data.dtype == np.object:
Iteration 0: 100%|██████████| 10/10 [00:00<00:00, 30.27it/s, episode=10, return=17.200]
Iteration 1: 100%|██████████| 10/10 [00:00<00:00, 33.77it/s, episode=20, return=12.700]
Iteration 2: 100%|██████████| 10/10 [00:00<00:00, 32.58it/s, episode=30, return=14.800]
Iteration 3: 100%|██████████| 10/10 [00:00<00:00, 27.85it/s, episode=40, return=25.100]
Iteration 4: 100%|██████████| 10/10 [00:00<00:00, 19.99it/s, episode=50, return=51.500]
Iteration 5: 100%|██████████| 10/10 [00:00<00:00, 13.89it/s, episode=60, return=94.300]
Iteration 6: 100%|██████████| 10/10 [00:00<00:00, 12.93it/s, episode=70, return=105.400]
Iteration 7: 100%|██████████| 10/10 [00:00<00:00, 12.35it/s, episode=80, return=112.400]
Iteration 8: 100%|██████████| 10/10 [00:00<00:00, 11.47it/s, episode=90, return=125.500]
Iteration 9: 100%|██████████| 10/10 [00:00<00:00, 13.76it/s, episode=100, return=97.400]In [7]
def moving_average(a, window_size):
cumulative_sum = np.cumsum(np.insert(a, 0, 0))
middle = (cumulative_sum[window_size:] - cumulative_sum[:-window_size]) / window_size
r = np.arange(1, window_size-1, 2)
begin = np.cumsum(a[:window_size-1])[::2] / r
end = (np.cumsum(a[:-window_size:-1])[::2] / r)[::-1]
return np.concatenate((begin, middle, end))
episodes_list = list(range(len(return_list)))
mv_return = moving_average(return_list, 19)
plt.plot(episodes_list, mv_return)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('PPO on {}'.format(env_name))
plt.show()/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/cbook/__init__.py:2349: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
if isinstance(obj, collections.Iterator):
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/cbook/__init__.py:2366: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
return list(data) if isinstance(data, collections.MappingView) else data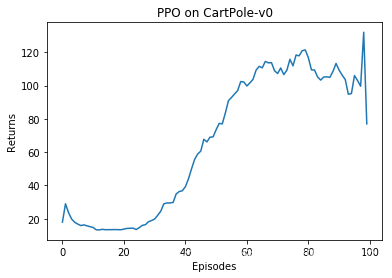
<Figure size 432x288 with 1 Axes>
6.验证
我们使用保存的网络参数初始化一个新的策略网络,并用这个新的策略网络在CartPole环境上进行实验。我们可以通过打印环境回合是否结束来大致判断策略网络的好坏(done=false的回合数越大说明策略学习的越好)。由于ai studio好像不支持gym环境的可视化,运行'''env.render(mode="rgb_array")'''会报错,因此我们仅展示但不运行可视化的代码,可在本地进行运行。我们将本地运行结果附在下方直观的展示PPO的训练结果。?

打印环境回合是否结束:
In [8]
actor=PolicyNet(4,128,2)
layer_state_dict = paddle.load("net.pdparams")
actor.set_state_dict(layer_state_dict)
env=gym.make('CartPole-v0')
state=env.reset()
frames = []
for i in range(200):
state=paddle.to_tensor(state,dtype='float32')
action =actor(state).numpy()
#action=action.numpy()[0]
#print(action)
next_state,reward,done,_=env.step(np.argmax(action))
if i%10==0:
print(i," ",reward,done)
state=next_state
env.close()
0 1.0 False 10 1.0 False 20 1.0 False 30 1.0 False 40 1.0 False 50 1.0 False 60 1.0 False 70 1.0 False 80 1.0 False 90 1.0 False 100 1.0 False 110 1.0 False 120 1.0 False 130 1.0 False 140 1.0 False 150 1.0 False 160 1.0 False 170 1.0 False 180 1.0 False 190 1.0 False
可视化代码,可在本地运行
actor=PolicyNet(4,128,2)
layer_state_dict = paddle.load("net.pdparams")
actor.set_state_dict(layer_state_dict)
def save_frames_as_gif(frames, filename):
#Mess with this to change frame size
plt.figure(figsize=(frames[0].shape[1]/100, frames[0].shape[0]/100), dpi=300)
patch = plt.imshow(frames[0])
plt.axis('off')
def animate(i):
patch.set_data(frames[i])
anim = animation.FuncAnimation(plt.gcf(), animate, frames = len(frames), interval=50)
anim.save(filename, writer='pillow', fps=60)
env=gym.make('CartPole-v0')
state=env.reset()
frames = []
for i in range(200):
#print(env.render(mode="rgb_array"))
frames.append(env.render(mode="rgb_array"))
state=paddle.to_tensor(state,dtype='float32')
action =actor(state).numpy()
#action=action.numpy()[0]
#print(action)
next_state,reward,done,_=env.step(np.argmax(action))
if i%50==0:
print(i," ",reward,done)
state=next_state
save_frames_as_gif(frames, filename="CartPole.gif")
env.close()
7.总结
本项目是基于策略的强化学习算法PPO。受于本人认知水平等因素影响,在该项目中可能存在不严谨、甚至错误的地方,还请大家批评指正。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- LearnDash LMS ProPanel在线学习系统课程创作者的分析工具
- SD-WAN满足企业不断增长的网络需求
- ST工具Flash Loader烧写STM32
- 代码随想录算法训练营第二十五天 | 216.组合总和III、 17.电话号码的字母组合
- 水库大坝安全监测的技术手段及方法
- 使用 JSON 文件保存标签对应的索引是为了方便数据的加载和处理
- 【WPF.NET开发】将字体与应用程序一起打包
- Flex布局下居中滚动溢出
- kotlin的接口详解
- 抖店选品渠道,带货直播间、同行店铺、多多平台,具体方法如下