Python - 中文文本相似度计算与模糊匹配
发布时间:2023年12月27日

目录
一.引言
日常工作中需要计算文本之间的匹配程度,获取最匹配、相近的台词,下面介绍几种常见的文本相似度计算方法以及模糊匹配计算相似文本的方法。
二.文本相似度计算
Tips:
由于中文分词与英文分词不同,这里中文相似度计算统一采用 jieba 分词作为分析结果并计算。
import jieba
# Jieba 分词
def chinese_tokenizer(text):
return jieba.cut(text, cut_all=False)1.Jaccard 相似度
◆ 定义
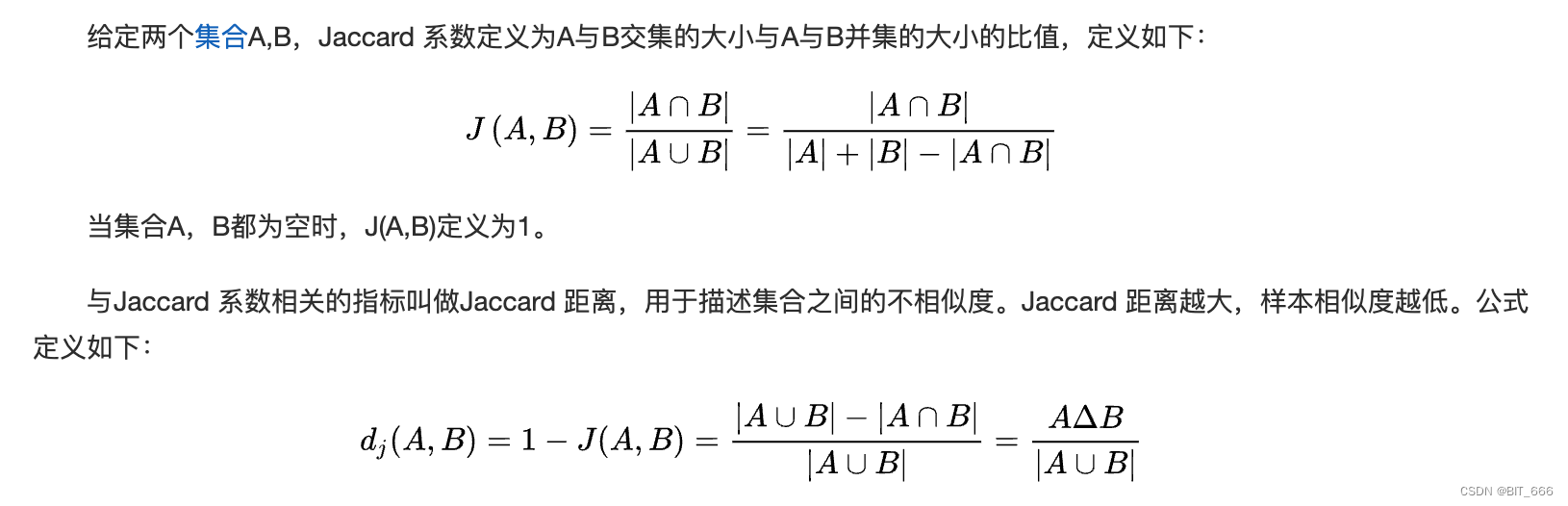
最基础的文本相似度计算,基于统计学寻求两个字符串的交集与并集,距离越大二者相似度越小。?
◆ 实现
def jaccard_similarity(str1, str2):
words1 = chinese_tokenizer(str1)
words2 = chinese_tokenizer(str2)
set1 = set(words1)
set2 = set(words2)
return len(set1.intersection(set2)) / len(set1.union(set2))text1 = "酒要一口一口喝"
text2 = "要一口一口喝"
set1 = {'喝', '酒要', '一口'}
set2 = {'喝', '一口', '要'}
Jaccard 相似度: 0.52.Cosine?相似度
◆ 定义

通过? Sklearn 库的 TfidVectorizer 将文本向量化,随后调用 cosine_similarity 计算相似度。
◆ 实现
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
def cosine_similarity_text(str1, str2):
words1 = ' '.join(chinese_tokenizer(str1))
words2 = ' '.join(chinese_tokenizer(str2))
vectorizer = TfidfVectorizer()
tfidf = vectorizer.fit_transform([words1, words2])
return cosine_similarity(tfidf)[0][1]words1: 酒要 一口 一口 喝
words2: 要 一口 一口 喝
Cosine 相似度: 0.81818020736671973.Levenshtein 距离
◆ 定义

莱文斯坦距离 (LD) 用于衡量两个字符串之间的相似度,其被定义为' 将字符串 str1 变换为字符串 str2 所需的删除、插入、替换操作的次数
◆ 实现
import Levenshtein
def levenshtein_distance(str1, str2):
words1 = ''.join(chinese_tokenizer(str1))
words2 = ''.join(chinese_tokenizer(str2))
return Levenshtein.distance(words1, words2)words1: {'一口', '要', '喝', '美酒'}
words2: {'一口', '要', '喝'}
Levenshtein 距离: 2三.模糊匹配
◆ 定义
Fuzzywuzzy 是一款可以对字符串模糊匹配的工具, 它使用上面提到的?Levenshtein Distance 来计算出那些易用包中序列之间的差异。
◆ 实现
from fuzzywuzzy import process
subs = ["你好", "在干嘛", "吃饭了吗", "好的"]
text = "你好吗"
best_match = process.extractOne(text, subs)
print(f"Ori: {text} Best match: {best_match[0]} (Score: {best_match[1]})")我们可以构建 subs 子集,并传入目标字符,寻找相似度最高的文本。?
Ori: 你好吗 Best match: 你好 (Score: 90)四.总结
这里介绍了几种相似度的计算方法,基于每一种相似度其实都可以定义自己的模糊匹配算法,只需寻找相似度最高的匹配字符即可。还有一种模糊匹配的数据结构是 Trie 树,之前介绍过,有兴趣的同学可以参考:?Trie 树简介与应用实现。
文章来源:https://blog.csdn.net/BIT_666/article/details/135195314
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!