Spark运行架构以及容错机制
Spark运行架构以及容错机制
spark是一个开发框架,用于进行数据批处理,本文主要探讨Spark任务运行的的架构。由于在日常生产环境中,常用的是spark on yarn 和spark on k8s两种类型的模式,因此本文也主要探讨这两种类型的异同,以及不同角色的容错机制。
1. Spark的角色区分
1.1 Driver
Spark的驱动器节点,负责运行Spark程序中的main方法,执行实际的代码。Driver在Spark作业时主要负责:
- 将用户程序转化为作业(job)
- 负责跟RM(yarn)或者 Apiserver(k8s)申请资源,调度并拉起Excutor,协调和分配Executor之间的任务(task)
- 监控Executor的执行状态
- 通过UI展示运行情况。
1.2 Excuter
Executor是Spark程序中的一个JVM进程,负责执行Spark作业的具体任务(task),每个任务之间彼此相互独立。Spark应用启动时,Executor同时被启动,并且伴随着Spark程序的生命周期而存在。如果有Executor节点发生了故障,程序也不会停止运行,而是将出错的Executor节点上的任务调度到其他Executor节点运行。
Executor的核心功能:
- 运行Spark作业中具体的任务,并且将执行结果返回给Driver。
- 通过自身的块管理器(Block Manager)对用户要求缓存的RDD进行内存式存储。RDD式缓存在Executor进程内部的,这样任务在运行时可以充分利用缓存数据加速运算。
2. Spark-Cluster模式的任务提交流程
2.1 Spark任务简单开发
2.2 Spark On Yarn的任务提交流程
2.2.1 yarn相关概念
RM(ResourceManager):
即资源管理,在YARN中,RM负责集群中所有资源的统一管理和分配,它接收来自各个节点(NM)的资源汇报信息,并把这些信息按照一定的策略分配给各个应用程序(实际上是AM)
NM(NodeManager):
NM是运行在单个节点上的代理,它需要与应用程序的AM和集群管理者RM交互:
- 从AM上接收有关Container的命令并执行之(比如启动、停止Container);
- 向RM汇报各个Container运行状态和节点健康状况,并领取有关Container的命令(比如清理Container)执行之。
AM(ApplicationMaster):
用户提交的每个应用程序均包含一个AM,它可以运行在RM以外的机器上负责,主要负责
- 与RM调度器协商以获取资源(用Container表示),将得到的任务进一步分配给内部的任务(资源的二次分配)。
- 与NM通信以启动/停止任务。
- 监控所有任务运行状态,并在任务运行失败时重新为任务申请资源以重启任务。
注:RM只负责监控AM,并在AM运行失败时候启动它。RM不负责AM内部任务的容错,任务的容错由AM完成。
在Yarn任务的启动流程中,
- client优先跟RM获取NM资源并启动AM,在Cluster模式下,AM启动后client就可以退出了
- AM构建任务信息,并RM获取NM资源并启动Executor,并将task信息分配给Executor从而实现任务启动
- Executor需要跟AM进行心跳汇报,如果Executor异常,相关的拉起动作也是有AM来控制。
2.2.2 任务提交流程
Driver和AM是两个完全不同的东西,Driver是控制Spark计算和任务资源的,而AM是控制yarn app运行和任务资源的。在Spark On Yarn模式中,Driver运行在AM上,Driver会和AM通信,资源的申请由AppMaster来完成,而任务的调度和执行则由Driver完成,Driver会通过与AppMaster通信来让Executor的执行具体的任务。
任务提交流程图
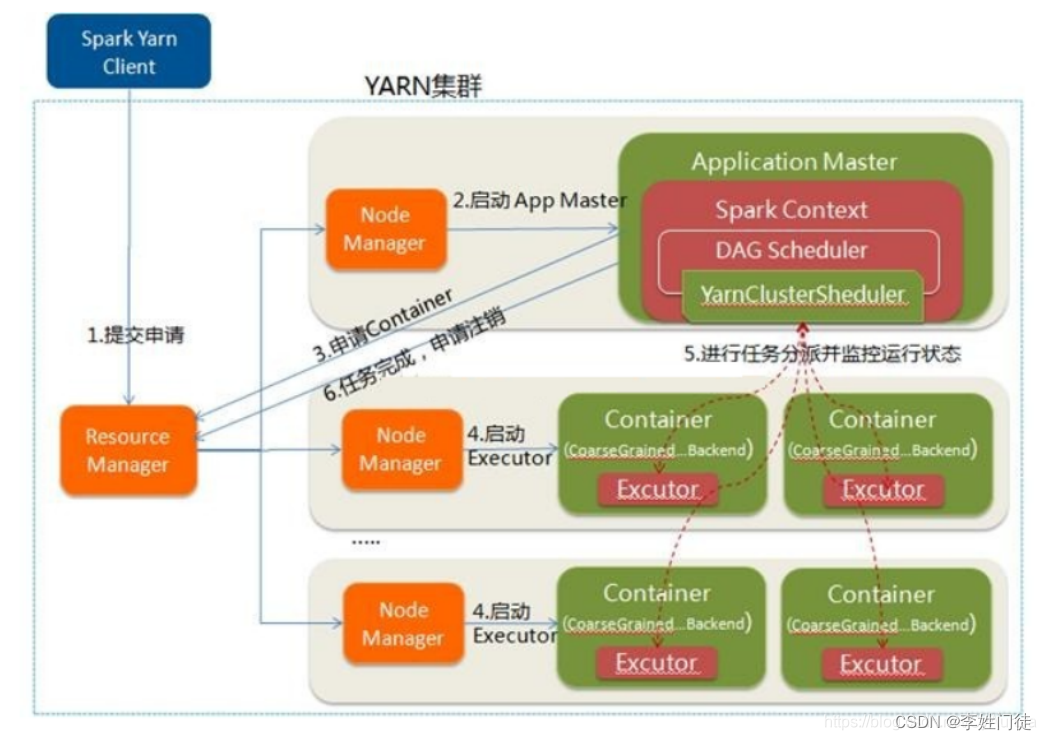
执行过程
- Client向YARN中提交应?程序,包括AM程序、启动AM的命令、需要在Executor中运?的程序等
- RM收到请求后,在集群中选择?个NM,为该应?程序分配第?个Container,要求它在这个Container中启动应?程序的AM,进行SparkContext(Driver)等的初始化
- AM向RM注册,这样?户可以直接通过RM查看应?程序的运?状态,然后它将采?轮询的?式通过RPC协议为各个任务申请资源,并监控它们的运?状态直到运?结束
- ?旦AM申请到资源(也就是Container)后,便与对应的NM通信,要求它在获得的Container中启动Executor,Executor启动后会向 AM中的SparkContext(Driver)注册并申请Task。
- AM中的SparkContext(Driver)分配Task给Executor执?,运?Task并向AM中的SparkContext(Driver)的汇报运?的状态和进度,以让 AM中的SparkContext(Driver)随时掌握各个任务的运?状态,从?可以在任务失败时重新启动任务应?程序运?完成后,AM中的SparkContext(Driver)向NM申请注销并关闭??
6.应?程序运?完成后,AM向NM申请注销并关闭??
YARN-Cluster的执行,需要安装spark 客户端,并执行如下命令提交任务
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn --deploy-mode cluster \
--num-executors 1 \
/Users/ly/apps/spark-2.2.0-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.2.0.jar 10
2.3 Spark On K8S的任务提交流程
Spark 2.3开始,Spark官方就开始支持Kubernetes作为新的资源调度模式。
2.3.1 k8s相关概念
Master:
Kubernetes里的Master指的是集群控制节点,每一个Kubernetes集群里都必须要有一个Master节点来负责整个集群的管理和控制,基本上Kubernetes的所有控制命令都发给它,它来负责具体的执行过程,我们后面执行的所有命令基本都是在Master节点上运行的
Node:
Node节点是Kubernetes集群中的工作负载节点,每个Node都会被Master分配一些应用程序服务以及云工作流。
2.2.2 任务提交流程
总体提交流程如下
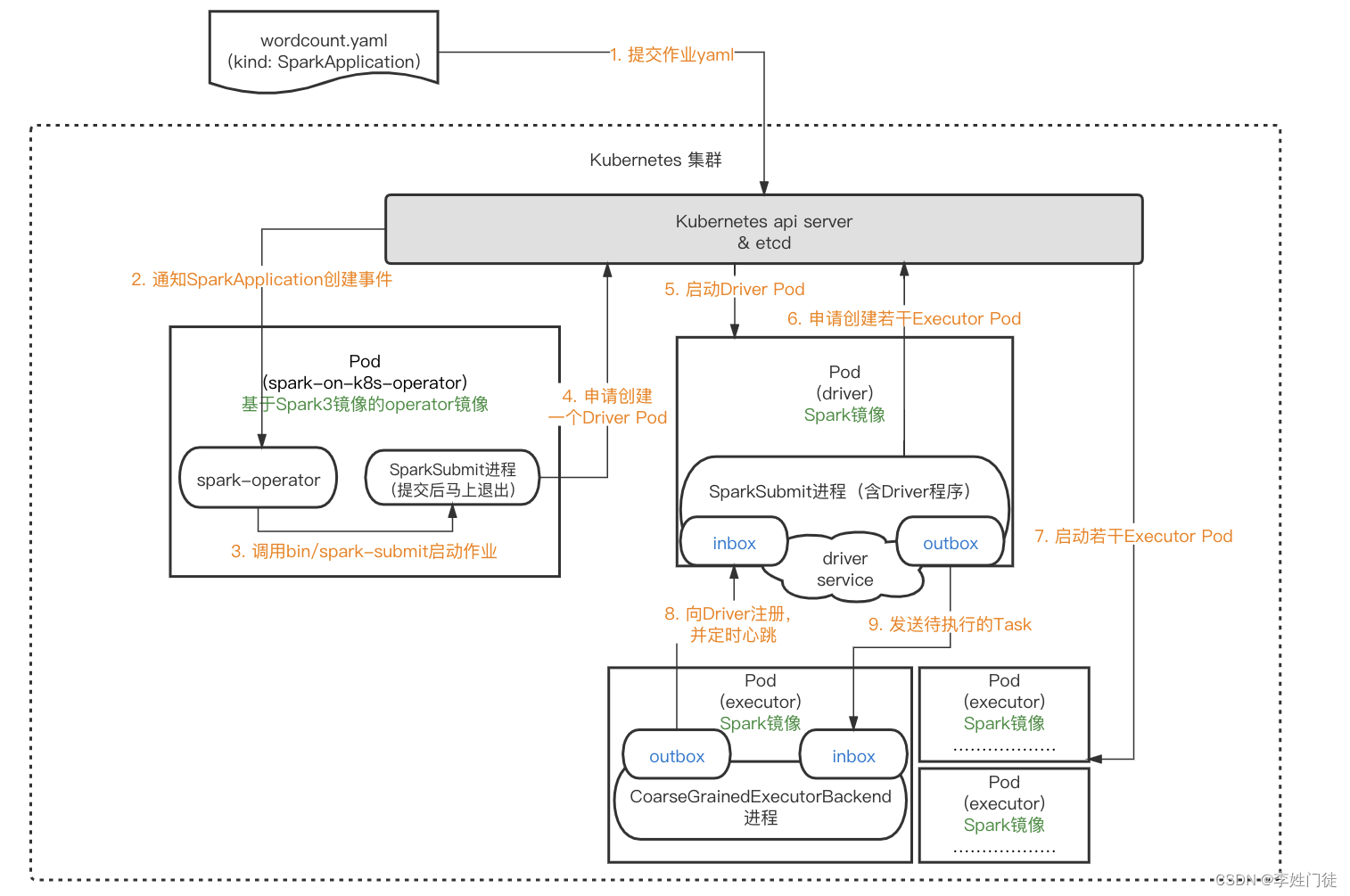
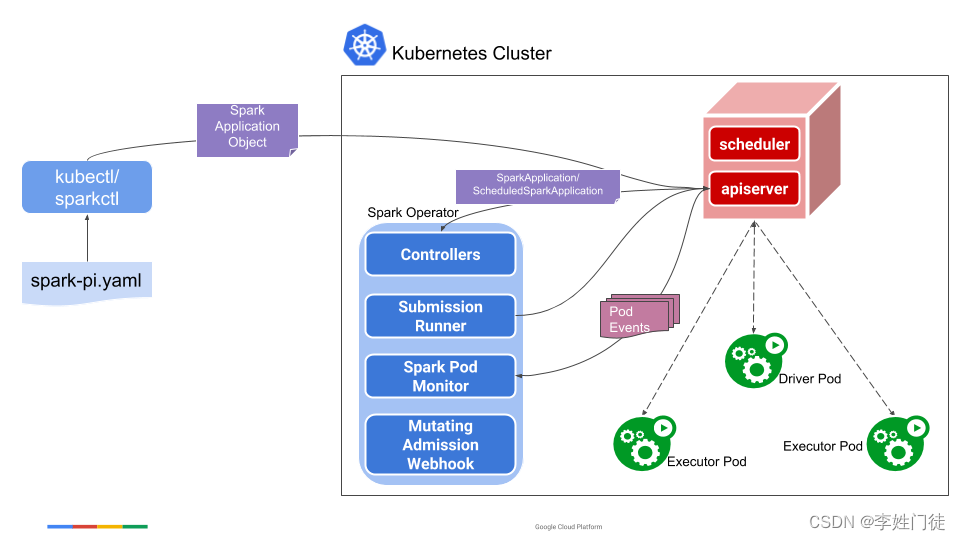
可以通过spark原生提交方式和 spark-on-k8s-operator提交 两种方式进行提交,两种方式实现上有些差异,但是总体流程是一致的。
1, spark原生提交方式
需要安装spark 客户端,并执行如下命令提交任务
bin/spark-submit \
--master k8s://https://{k8s-apiserver-host}:6443 \
--deploy-mode cluster \
--name spark-wordcount-example \
--class org.apache.spark.examples.JavaWordCount \
local:///opt/spark/examples/target/scala-2.11/jars/spark-examples_2.11-2.4.5.jar \
oss://{wordcount-file-oss-bucket}/
2, spark-on-k8s-operator提交
spark-on-k8s-operator[2],可以让用户以CRD(CustomResourceDefinition) [4] 的方式提交和管理Spark作业。这种方式能够更好的利用k8s原生的能力,具备更好的扩展性。并且在此之上增加了定时任务、重试、监控等一系列功能。具体的功能特性可以在github查看官方文档(kubernetes官方推荐)
需要
1, 需要提前在k8s集群中安装,此时会启动一个名为sparkoperator的pod
2,定义提交spark任务的相关CRD资源
3,提交作业时,无需准备一个具备Spark环境的Client,直接通过kubectl或者kubernetes api就可以提交Spark作业。
列入一个crd,命名spark.yaml
apiVersion: "sparkoperator.k8s.io/v1beta2"
kind: SparkApplication
metadata:
name: spark-wordcount-example
namespace: default
spec:
type: Java
sparkVersion: 2.4.5
mainClass: org.apache.spark.examples.JavaWordCount
image: {Spark镜像地址}
mainApplicationFile: "local:///opt/spark/examples/target/scala-2.11/jars/spark-examples_2.11-2.4.5.jar"
arguments:
- "oss://{wordcount-file-oss-bucket}/"
driver:
cores: 1
coreLimit: 1000m
memory: 4g
executor:
cores: 1
coreLimit: 1000m
memory: 4g
memoryOverhead: 1g
instances: 2
执行如下命令即可启动相关的pod,并进行提交任务
kubectl apply -f spark.yaml
3. Spark-Cluster模式的容灾模式
3.1 Driver容灾
Driver异常退出时,一般要使用checkpoint重启Driver,重新构造上下文并重启接收器。
第一步,恢复检查点记录的元数据块。
第二步,未完成作业的重新形成。由于失败而没有处理完成的RDD,将使用恢复的元数据重新生成RDD,然后运行后续的Job重新计算后恢复。
3.2 Executor容灾
Executor异常退出时,Driver没有在规定时间内收到执行器的状态更新,于是Driver会将注册的Executor移除,并通过调度器自动重新拉起Executor。
Executor分配到到来自Driver的Task,需要重checkpoint重新加载数据并继续执行计算。但是由于Spark运算数据行程DAG,如果遇到不同的Executor之间有数据交互时,不能简单的通过启动对应的Executor相关的数据进行恢复(可能会有数据紊乱)。
3.3 RDD容错
窄依赖
指父RDD的每一个分区最多被一个子RDD的分区所用,表现为一个父RDD的分区对应于一个子RDD的分区 或多个父RDD的分区对应于一个子RDD的分区,也就是说一个父RDD的一个分区不可能对应一个子RDD的多个分区。
宽依赖
指子RDD的分区依赖于父RDD的多个分区或所有分区,即存在一个父RDD的一个分区对应一个子RDD的多个分区。
checkpoint机制
是为了通过lineage做容错的辅助,lineage过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果之后有节点出现问题而丢失分区,从做检查点的RDD开始重做Lineage,就会减少开销。
注意
1, 在容错机制中,如果一个节点死机了,而且运算窄依赖,则只要把丢失的父RDD分区重算即可,不依赖于其他节点。
2, 而宽依赖需要父RDD的所有分区都存在,重算就很昂贵了。如果恢复的代价过于昂贵,就会通过checkpoints重新进行计算。
3,利用checkpoint机制,记载最新的数据计算点,重新拉起任务进行计算
4. 疑问和思考
4.1 是否可以部署多个Driver,形成HA模式,如果主Driver宕机,备Driver自动接替?
待整理
5. 参考文档
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【MATLAB】史上最全的17种信号分解+FFT+HHT组合算法全家桶
- Visual Studio(VS)常用快捷键(最详细)
- 最多购买宝石数目 - 华为OD统一考试
- diffusers 文成图AIGC常见pipeline参数介绍
- c# 使用Null合并操作符例子
- css做一条很细的分割线
- 讲解机器学习中的 K-均值聚类算法及其优缺点。
- C# 将 Word 转化分享为电子期刊
- 获取 VirtualBox COM 对象失败,应用程序被终端 0x80000405错误解决以及Virtualbox下载
- 20240102-持续低物欲