二叉树简单OJ题(及其后续函数补充)
OJ题
单值二叉树
首先呢,我们还是把问题分化一下,求一棵二叉树是否为单值二叉树,还是可以分为几个部分:根节点 左子树 右子树
而我们向下遍历的时候,其实就是在这个节点以及其左子树和右子树中找,是否值都相同,这样一来,代码写出就十分明了了
bool isUnivalTree(struct TreeNode* root) {
if (root == NULL)
return true;//空节点
if (root->left && root->left->val != root->val ||
root->right && root->right->val != root->val)
return false;//(左右子树节点不为空且与根节点不相等)
return isUnivalTree(root->left) && isUnivalTree(root->right);
}
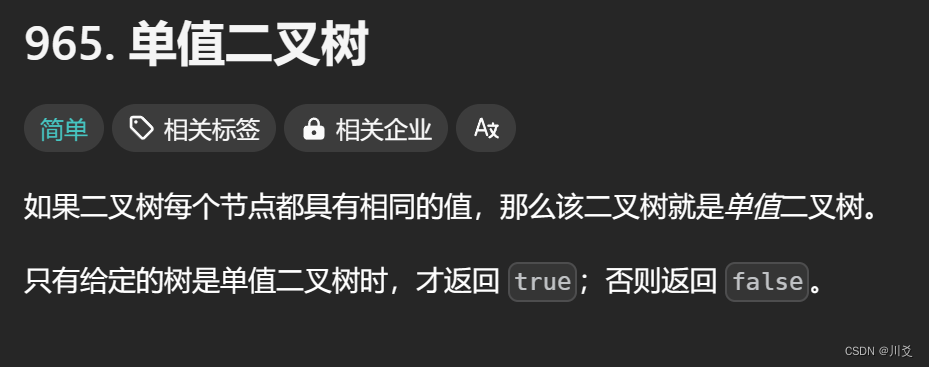
现在我们就对这段代码进行分析:假如图长这个样子:
首先从1开始,1不满足上面两个条件,递归到左右子树;假设1的左子树为“2”,右子树为“3”,那么“2”也不满足上述两个if语句的条件,递归到它的左右子树;“2”的左右子树,一个为空,直接返回true,另一个在不满足两个if语句,继续向下递归时,两个子树都为空,返回true,故“2”的两个子树的返回值均为true,导致’2"返回给1的bool值也为true。而“3”的分析则是与“2”的左子树相同,左子树右子树均为空,全部返回true,导致“3”返回给1的值也为true,最终1的两个返回值都为true,导致返回到外部main函数的值也为true
相同的树
跟上述题目一样,分析二叉树的OJ题,实际上就是要把递归的返回值和情况弄清楚
- 两个树的节点都为空
- 两个树的节点一个为空,一个不为空
- 两个树的节点都不为空,但是不相等
bool isSameTree(struct TreeNode* p, struct TreeNode* q) {
//都为空
if (!p && !q)
return true;
//一个为空另一个不为空
if (!p || !q)
return false;
if (p && q && p->val != q->val)
return false;
return isSameTree(p->left, q->left) && isSameTree(p->right, q->right);
}
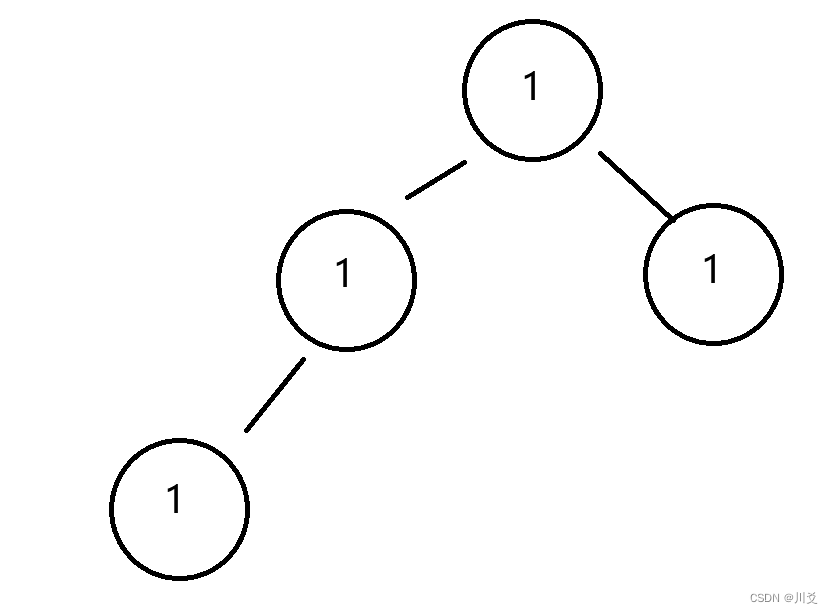
用一个简单的例子来说明一下
假如有这样一个二叉树,有两棵,那么首先遍历1,不为空且相等,向下递归到2和3;2的情况与1相同,所以继续向下递归,都为空,所以来返回真,而2返回给1的值也是真;而3与2的情况相同,是一样的递归过程
二叉树的先序遍历

这道题的难点不在于先序遍历,而是在于如何把先序遍历的结果放进一个数组并返回
//首先要找到节点的个数,为创建数组做准备
int TreeSize(struct TreeNode* root) {
return root == NULL ? 0 : TreeSize(root->left) + TreeSize(root->right) + 1;
}
//核心功能
void preorder(struct TreeNode* root, int* a, int* pi) {
if (root == NULL)
return;
a[(*pi)++] = root->val; //把值放进数组里
preorder(root->left, a, pi);
preorder(root->right, a, pi);
}
int* preorderTraversal(struct TreeNode* root, int* returnSize) {
int n = TreeSize(root); //先算出节点个数
int* a = (int*)malloc(sizeof(int) * n);
*returnSize = n; //因为它不知道这个数组有多大,要返回给系统看
int i = 0;
preorder(root, a, &i);
return a;
}
有同学肯定会疑惑为什么实现核心功能的函数要传递一个int*pi,其实这是有原因的,如果我们传入的是int pi,那么在出现一个节点有两个子树的时候,由于pi只是一个形参,所以在左子树使用了之后,右子树使用pi的时候,实际上pi并没有++,导致左子树和右子树遍历时所赋的值实际上都在一个地址上,从而出现错误。而用指针作为参数,就可以改变实参,从而不会出现这种状况
我们还有另外一种方法,那就是使用全局变量,但是其存在多线程问题,如果同时使用,即使在使用函数前置过0,也可能出现线程安全问题,所以不建议使用。
对称二叉树
其实这个就比较像两个相等二叉树的翻版,只不过,它是左子树的左节点跟右子树右节点相等,而左子树的右节点跟右子树的左节点相等
bool _isSymmetric(struct TreeNode* root1, struct TreeNode* root2) {
if (root1 == NULL && root2 == NULL)
return true;//两边都是空,就是相等的
if (!root1 || !root2)
return false;//有一个是空的,肯定不相等
if (root1->val != root2->val)
return false;//不为空但值不相等,也不可以
return _isSymmetric(root1->left, root2->right) &&
_isSymmetric(root1->right, root2->left);//其实就是上述写的原理
}
bool isSymmetric(struct TreeNode* root) {
return _isSymmetric(root->left, root->right); //根节点不用比,从根节点的左子树和右子树开始比
}
另一棵树的子树
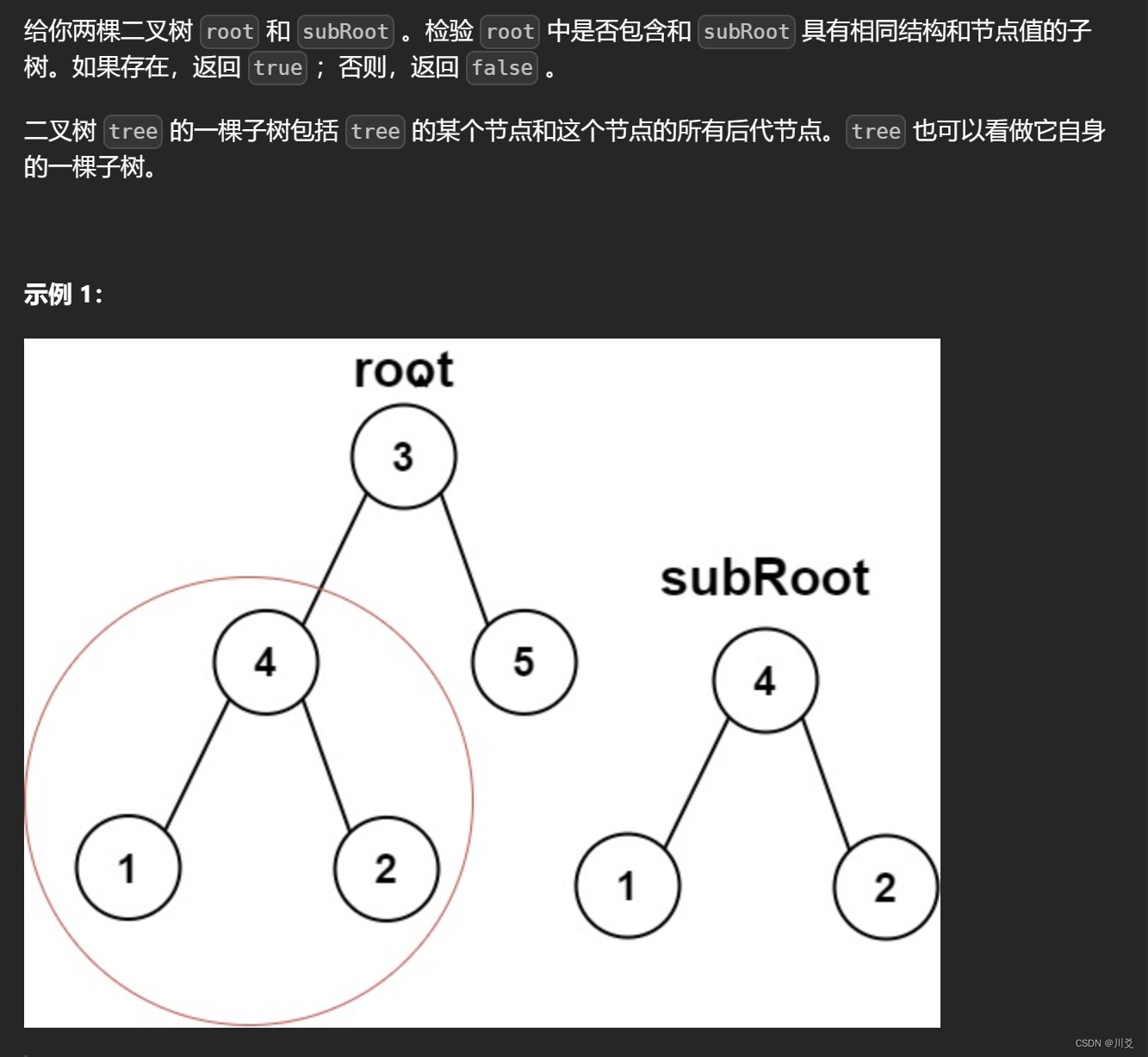
我们首先需要弄清题目的意思,其实就是在一个较大的二叉树中找到较小二叉树的部分,在没找到相同的部分之前,都是向下遍历,而找到之后,就开始比较这个整体是否相同,如果相同,就返回true,不然就继续向下遍历。
先给大家看一段错误代码
bool isSubTree(struct TreeNode* root,struct TreeNode* subRoot){
if(root==NULL)
return false;
if(root->val==subRoot->val)
return isSameTree(root->subRoot);
return isSubTree(root->left,subRoot)
||isSubTree(root->right,subRoot);
}
这段代码乍一看上去逻辑也没问题,但是给一个例子给大家看就懂了
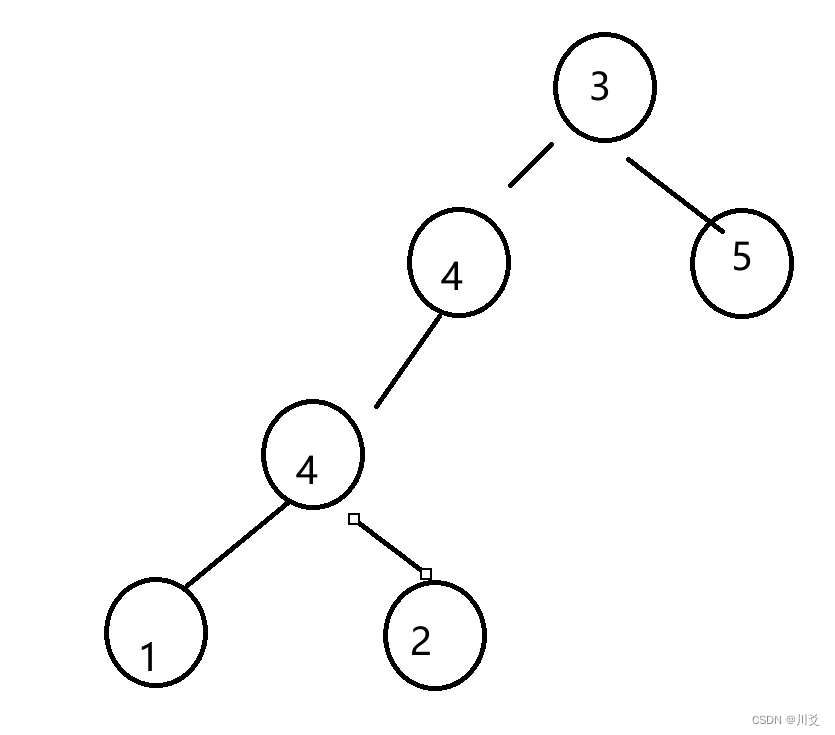
假设subRoot是4 1 2,那么首先从根节点3开始遍历,不满足条件,所以向下递归;左子树是4,满足条件,进入isSameTree函数:4的左子树4与1不相等,所以返回false,于是isSubTree(root->left,subRoot)返回的是false,而右子树5不满足条件,向下递归,左右子树都为空,返回false,导致5返回给3的结果也是false,两个false,导致最后isSubTree函数返回的就是false,显示的结果是没找到,但其实4 1 2就在下面,但是它在找到一个根节点一样的之后,只要后面不是,就会直接返回false,这样子就只能比较一个子树,而即使后面有也不会继续遍历,是错误的。
正确的应当是这样的:
bool isSubtree(struct TreeNode* root, struct TreeNode* subRoot) {
if (root == NULL)
return false;
if (root->val == subRoot->val) {
if (isSameTree(root, subRoot))
return true;
}
return isSubtree(root->left, subRoot) || isSubtree(root->right, subRoot);
}
这样子的话,当两个节点的值相等,它们会向下递归,看是否完全相同,如果不是完全相同,也不会返回false,而是继续向下遍历,就不会出现上述错误。
除了这个方式,还有一个更简洁的代码:
bool isSubtree(struct TreeNode* root, struct TreeNode* subRoot) {
if (root == NULL)
return false;
return isSameTree(root, subRoot) || isSubtree(root->left, subRoot) ||
isSubtree(root->right, subRoot);
}
一开始看可能会有点懵,但是其实就是要记住||符号的意义。首先诊断是否为空这个还是不变,然后如果值相等,isSameTree就来判断其是否左子树右子树也相等,如果为真就不用往下面继续遍历;如果值不相等,就会向左子树和右子树遍历,左子树找到了,就不用看右子树,左子树没找到就继续看右子树,其实逻辑理顺了之后还是比较清晰的。
函数补充
通过前序遍历的数组构建二叉树
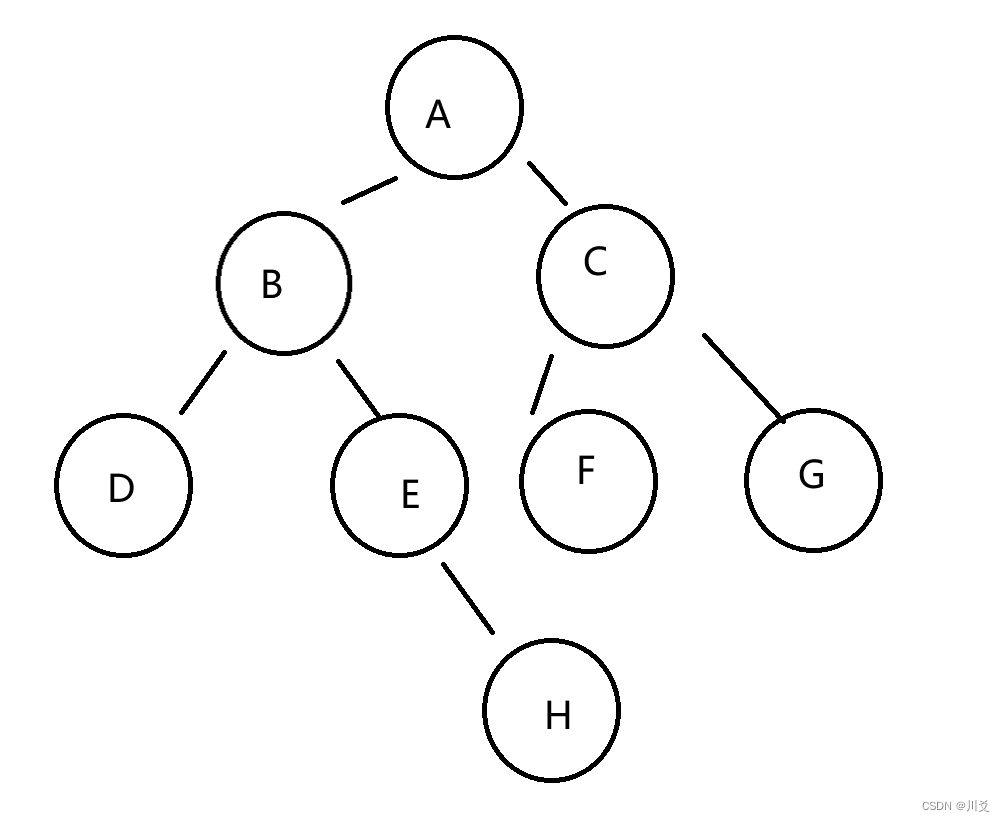
首先我们给一个例子,“ABD##E#H##CF##G##”,它构建出来的二叉树是这个样子的
我们讲解一下原理,首先直接的符号意思就是构建一个二叉树节点,而#意思就是这个节点没有,所以ABD的意思就是由A为根节点延伸出一条左子树,而后面的##则是指D没有左右子树,于是回到D,E表示其为D的右子树,而#H则表示E没有左子树,但是有右子树H。##表示H没有左右子树,返回到A,CF表示A的右子树为C,C的左子树为F,##G##表示F没有左右子树,C的右子树为G,且G没有左右子树,再次回到A,递归结束。
代码如下:
TreeNode* TreeCreate(char* a, int* pi)//a是给定数组,pi的意思是为了防止传入的是形参,在后续的递归中会导致当一个节点有两棵子树在同一层次时,pi值因为无法改变而相同,造成下标错误
{
if (a[*pi] == '#')
{
(*pi)++;
return NULL;
}
TreeNode* root = (TreeNode*)malloc(sizeof(TreeNode));
if (root == NULL)
{
perror("malloc fail");
exit(-1);
}
root->data = a[(*pi)++];//数组值传入节点,下标++
root->left_child = TreeCreate(a, pi);
root->right_child = TreeCreate(a, pi);//两次递归,每次递归*pi值是不同的
return root;//返回根节点
}
二叉树的销毁
这个比较简单,直接上代码,不过过程需要解释一下为什么使用后序遍历而不是前序或者中序
void DestroyTree(TreeNode* root)
{
if (root == NULL)
return;//为空就不需要销毁
DestroyTree(root->left_child);
DestroyTree(root->right_child);
free(root);
}

以这个图为例,从根节点A开始遍历,递归到B和C两棵子树,B递归到D和E两棵子树,D和E的两棵子树都为空,直接返回到D和E节点,于是D和E被free掉,之后返回到B,B也被free掉,然后右子树跟左子树是相同的,也是FGC顺序被free掉,最后freeA
在二叉树中,节点之间存在父子关系。如果先销毁父节点,那么子节点的销毁可能会受到影响,因为子节点可能还依赖于父节点。而后序遍历的顺序是先遍历子节点,再遍历父节点,这样就可以确保在销毁父节点之前,其子节点已经被销毁。
层次遍历
还是先给大家展开一张图:
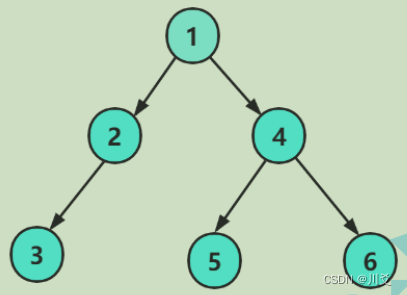
大家都知道,层次遍历就是每个层级从左到右遍历的过程,比如这里层次遍历的结果就是1 24 356,那么要怎样才能做到按照每个层级每个层级的顺序输出来呢,这就要用到我们之前学过的队列啦,我们可以在让根节点进入之后,输出根节点之后Pop根节点,然后再让根节点的左右子树分别Push进去,这样子,我们就可以写出一个初具规模的层次遍历函数:
void LevelOrder(TreeNode* root)
{
Queue q;
QueueInit(&q);//创建队列
if (root)
QueuePush(&q, root);//根节点不为空,节点进入
while (!QueueEmpty(&q))//循环判断条件,队列不为空
{
TreeNode* front = QueueFront(&q);//front记录队头元素
QueuePop(&q);//队头元素出队
printf("%d ", front->data);//打印队头元素的值
if (front->left_child)
QueuePush(&q, front->left_child);//有左子树,左子树push进去
if (front->right_child)
QueuePush(&q, front->right_child);//同理
}
printf("\n");
QueueDestroy(&q);//最后销毁队列
}
按照上述代码的逻辑,遍历过程如下:
将根节点1加入队列。
打印节点1的值。
将节点2和节点4加入队列(因为它们是节点1的子节点)。
打印节点2的值。
将节点3加入队列(因为它是节点2的左子节点)。
打印节点4的值。
将节点5加入队列(因为它是节点4的左子节点)。
将节点6加入队列(因为它是节点4的右子节点)。
当队列为空时,遍历结束。
当一个层次的节点被出完后,队头就变成了下一层次的最左边的节点的地址,这也是一个重点,就是我们传输的不是节点,而是节点的地址,否则我们无法通过节点找到它的子节点并继续向下遍历
当然,这只是实现了最基础的功能,我们还并没有完全实现其按照层次划分并输出的功能,这时候就引出下面的一步:利用变量levelSize和QueueSize,得以划分层次,并且每层节点个数也并未出错
void LevelOrder(TreeNode* root)
{
Queue q;
QueueInit(&q);
if (root)
QueuePush(&q, root);
int levelSize = 1;//初始根节点就1个
while (!QueueEmpty(&q))
{
// 一层一层出
while (levelSize--)//n--循环n次
{
TreeNode* front = QueueFront(&q);
QueuePop(&q);
printf("%d ", front->data);
if (front->left_child)
QueuePush(&q, front->left_child);
if (front->right_child)
QueuePush(&q, front->right_child);
}
printf("\n");
levelSize = QueueSize(&q);//比如1的左右节点进去,队列中元素个数2个,故下一次levelSize=2,这样子的
}
printf("\n");
QueueDestroy(&q);
}
是否为完全二叉树
大概原理是这样子的,其实就是从层次遍历修改而来。首先我们还是先把根节点push进去,然后开始遍历。但当遍历到空时,这个时候就跳出第一个循环,并看后续是否有非空节点,如果有,那就返回false,如果没有,那就最终返回true
//判断是否为完全二叉树
bool TreeComplete(TreeNode* root) {
Queue q;
QueueInit(&q);
if (root)
QueuePush(&q, root);
int levelSize = 1;
while (!QueueEmpty(&q))
{
TreeNode* front = QueueFront(&q);
QueuePop(&q);
if (front == NULL)
break;
QueuePush(&q, front->left_child);
QueuePush(&q, front->right_child);
}
// 前面遇到空以后,后面还有非空就不是完全二叉树
while (!QueueEmpty(&q))
{
TreeNode* front = QueueFront(&q);
QueuePop(&q);
if (front)
{
QueueDestroy(&q);
return false;
}
}
QueueDestroy(&q);
return true;
}
其实二叉树的知识还有很多复杂的,但是在C语言阶段很难去简单的实现,所以就让我们在C++的文章中再见吧!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- uni-app小程序自定义分享内容
- MySQL-函数-流程函数
- TXT文本删除第一行文本变成空要如何解决呢
- 产品经理必备之最强管理项目过程工具----禅道
- vscode 调试 php项目
- ITECH 艾德克斯 IT6722A 可编程电源
- 【笔记】Helm-3 主题-8 Helm架构
- 网络IP地址如何更改?怎么使用动态代理IP提高网速?
- 2024.1.17 用户画像day02 - Elastic Search
- K8s 详细安装部署流程