ES6.8.6 分词器安装&使用、查询分词结果(内置分词器、icu、ik、pinyin分词器)
ES环境
- elasticsearch6.8.6版本:已安装ik分词器、icu分词器、pinyin分词器(分词器版本要和es版本一致)
- postman测试工具
- 视图工具elasticsearch-head(https://github.com/mobz/elasticsearch-head)
注意!
- 仅测试分词器的简单基本应用,更高级的用法不在此测试
- 以下所有关于分词器的测试都使用
news索引及数据(映射不配置分词器) - 以下postman截图中
{{domain}}等于http://127.0.0.1:9200 - 模拟数据

默认(内置)分词器
【默认分词器的使用参考官网。如何设置默认分词器(setting)?如何为字段text类型设置分词方式(mapping)?】
????????内置分词器不需要安装,es自带。这些分词器只能对英文进行分词处理,不能识别中文短语。在创建索引的时候不单独指定分词器,使用的就是es默认分词器standard。
standard
???????? es默认分词器,按词切分。英文会被切分为一个一个单词,中文会被切分为一个一个字。
示例一:英文分词结果
????????postman请求分词器,测试分词结果:

????????请求命令:
curl -X GET -H 'Content-Type:application/json' -d '{"analyzer":"standard","text":"Introduction to Sanmao"}' http://127.0.0.1:9200/news/_analyze
# -d:请求参数说明
{
"analyzer": "standard", # 内置分词器名称,默认分词器
"text": "Introduction to Sanmao" # 需要分词的文本
}
????????看对应文本的分词结果:
????????standard分词器把英文大写全部转为小写,每个单词分开。
{
"tokens": [
{
"token": "introduction",
"start_offset": 0,
"end_offset": 12,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "to",
"start_offset": 13,
"end_offset": 15,
"type": "<ALPHANUM>",
"position": 1
},
{
"token": "sanmao",
"start_offset": 16,
"end_offset": 22,
"type": "<ALPHANUM>",
"position": 2
}
]
}
示例二:中文分词结果
????????postman请求分词器,测试分词结果:
????????请求命令:
curl -X GET -H 'Content-Type:application/json' -d '{"analyzer":"standard","text":"三毛简介"}' http://127.0.0.1:9200/news/_analyze
# -d:请求参数说明
{
"analyzer": "standard", # 内置分词器名称,默认分词器
"text": "三毛简介" # 需要分词的中文文本
}
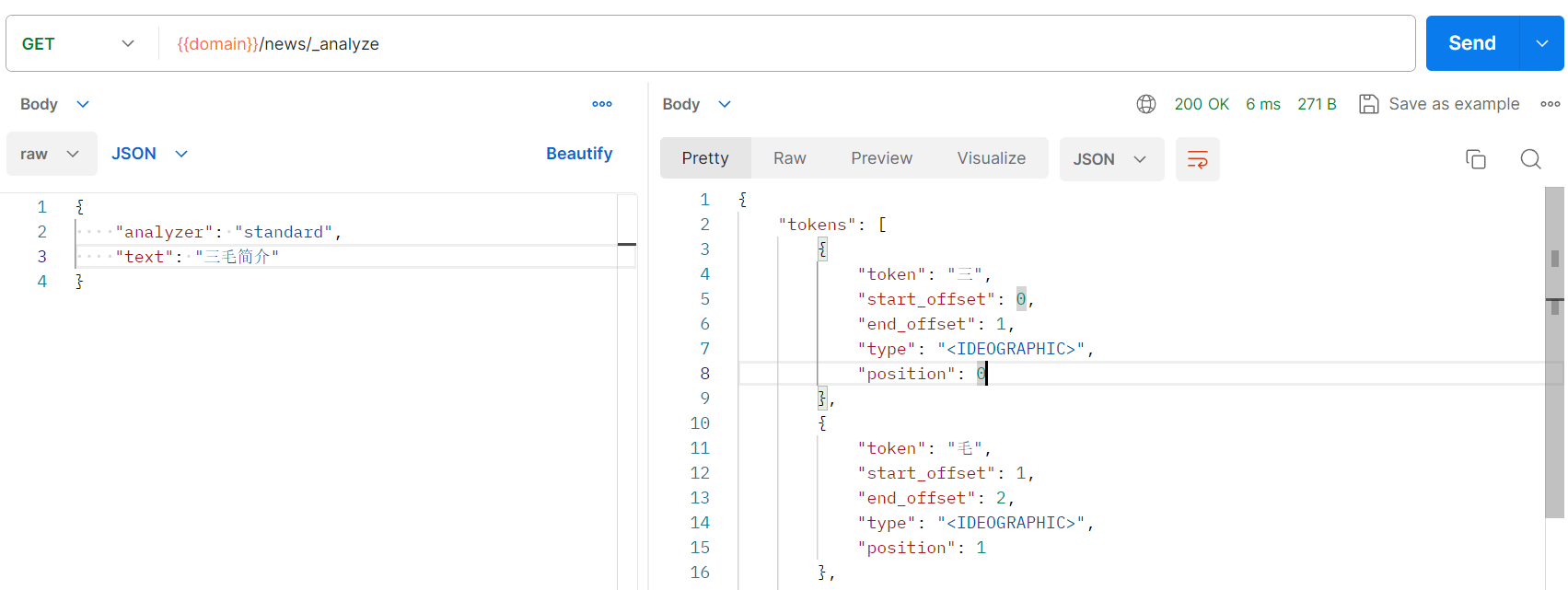
????????看对应文本的分词结果:
????????standard分词器把中文的每个字分开。
????????如果按照这个分词结果到news索引中的title字段匹配中文数据,那结果可想而知:它会把title中所有包含三``毛``简``介的数据全部匹配出来。匹配出莫名其妙的数据会非常让人崩溃的!!!
{
"tokens": [
{
"token": "三",
"start_offset": 0,
"end_offset": 1,
"type": "<IDEOGRAPHIC>",
"position": 0
},
{
"token": "毛",
"start_offset": 1,
"end_offset": 2,
"type": "<IDEOGRAPHIC>",
"position": 1
},
{
"token": "简",
"start_offset": 2,
"end_offset": 3,
"type": "<IDEOGRAPHIC>",
"position": 2
},
{
"token": "介",
"start_offset": 3,
"end_offset": 4,
"type": "<IDEOGRAPHIC>",
"position": 3
}
]
}
simple
????????es分词器simple,按非字母的字符分词,例如:数字、标点符号、特殊字符等,会去掉非字母的词,大写字母统一转换成小写。
????????postman请求分词器,测试分词结果:

????????请求命令:
curl -X GET -H 'Content-Type:application/json' -d '{"analyzer":"simple","text":"Introduction to Sanmao 三毛简介:三毛生平介绍...全文1800字"}' http://127.0.0.1:9200/news/_analyze
# -d:请求参数说明
{
"analyzer": "simple", # 内置分词器simple
"text": "Introduction to Sanmao 三毛简介:三毛生平介绍...全文1800字" # 需要分词的文本
}
????????看对应文本的分词结果:
????????simple分词器把英文大写全部转为小写,去掉了非字母、非中文的词并把结果做了分割。
{
"tokens": [
{
"token": "introduction",
"start_offset": 0,
"end_offset": 12,
"type": "word",
"position": 0
},
{
"token": "to",
"start_offset": 13,
"end_offset": 15,
"type": "word",
"position": 1
},
{
"token": "sanmao",
"start_offset": 16,
"end_offset": 22,
"type": "word",
"position": 2
},
{
"token": "三毛简介",
"start_offset": 23,
"end_offset": 27,
"type": "word",
"position": 3
},
{
"token": "三毛生平介绍",
"start_offset": 28,
"end_offset": 34,
"type": "word",
"position": 4
},
{
"token": "全文",
"start_offset": 37,
"end_offset": 39,
"type": "word",
"position": 5
},
{
"token": "字",
"start_offset": 43,
"end_offset": 44,
"type": "word",
"position": 6
}
]
}
whitespace
????????按照空格进行分词,相当于按照(多)空格split了一下,大写字母不会转换成小写。
????????postman请求分词器,测试分词结果:

????????请求命令:
curl -X GET -H 'Content-Type:application/json' -d '{"analyzer":"whitespace","text":"Introduction to Sanmao 三毛简介:三毛生平介绍...全文1800字"}' http://127.0.0.1:9200/news/_analyze
# -d:请求参数说明
{
"analyzer": "whitespace", # 空格分词器
"text": "Introduction to Sanmao 三毛简介:三毛生平介绍...全文1800字"
}
????????看对应文本的分词结果:
????????whitespace仅按照空格分割(也可以按照多空格分割),不处理大小写。
{
"tokens": [
{
"token": "Introduction",
"start_offset": 0,
"end_offset": 12,
"type": "word",
"position": 0
},
{
"token": "to",
"start_offset": 13,
"end_offset": 15,
"type": "word",
"position": 1
},
{
"token": "Sanmao",
"start_offset": 16,
"end_offset": 22,
"type": "word",
"position": 2
},
{
"token": "三毛简介:三毛生平介绍...全文1800字",
"start_offset": 25,
"end_offset": 46,
"type": "word",
"position": 3
}
]
}
stop
????????停用词分词器。会去掉无意义的词、字符,例如:the、a、an、of 等,大写字母统一转换成小写。(中文无效,这、那)
????????postman请求分词器,测试分词结果:

????????请求命令:
curl -X GET -H 'Content-Type:application/json' -d '{"analyzer":"stop","text":"This is a Introduction of Sanmao. | 这是一个三毛介绍。"}' http://127.0.0.1:9200/news/_analyze
# -d:请求参数说明
{
"analyzer": "stop", # 空格分词器
"text": "This is a Introduction of Sanmao. | 这是一个三毛介绍。"
}
????????看对应文本的分词结果:
????????stop分词器:英文中停用词、特殊字符、无意义词去除,并按照这些词分割。但是中文的停用词无效,在英文中,类似于中文里“嗯、啊、这、是、哦”这些无意义的词都会被去掉,其他单词保留。
{
"tokens": [
{
"token": "introduction",
"start_offset": 10,
"end_offset": 22,
"type": "word",
"position": 3
},
{
"token": "sanmao",
"start_offset": 26,
"end_offset": 32,
"type": "word",
"position": 5
},
{
"token": "这是一个三毛介绍",
"start_offset": 36,
"end_offset": 44,
"type": "word",
"position": 6
}
]
}
keyword
????????查询文本不拆分,整个文本当作一个词。
????????postman请求分词器,测试分词结果:

????????请求命令:
curl -X GET -H 'Content-Type:application/json' -d '{"analyzer":"keyword","text":"This is a Introduction of Sanmao. | 这是一个三毛介绍。"}' http://127.0.0.1:9200/news/_analyze
# -d:请求参数说明
{
"analyzer": "keyword", # keyword分词器
"text": "This is a Introduction of Sanmao. | 这是一个三毛介绍。"
}
????????看对应文本的分词结果:
????????keyword分词器:不进行任何拆分,全文匹配。
{
"tokens": [
{
"token": "This is a Introduction of Sanmao. | 这是一个三毛介绍。",
"start_offset": 0,
"end_offset": 45,
"type": "word",
"position": 0
}
]
}
icu分词器
下载&安装
方式一:下载压缩包安装
????????【analysis-icu分词器下载链接(下载后直接解压复制到es的plugins目录下)】
????????下载的压缩包版本必须要和当前es版本一致。
????????除了直接下载已发布的压缩包,还可以到github下载源码自己编译打包,然后放到es的插件目录。

方式二:命令行安装
#window系统执行.bat
$ bin> elasticsearch-plugin.bat install analysis-icu
#linux执行
$ bin>./elasticsearch-plugin install analysis-icu
#查看安装了哪些分词插件
$ bin> elasticsearch-plugin.bat list
确认安装状态
方式一:命令行查询安装了哪些分词器

方式二:安装后重启es,重启后控制台打印加载分词器
????????安装失败可能会造成es启动失败或者是加载不到分词器。

icu分词器的简单使用
????????postman请求分词器,测试分词结果:

????????请求命令:
curl -X GET -H 'Content-Type:application/json' -d '{"analyzer":"icu_analyzer","text":"This is a Introduction of Sanmao | 三毛:她把短暂的一生,活成了十世 By 2024 来源百度知道"}' http://127.0.0.1:9200/news/_analyze
# -d:请求参数说明
{
"analyzer": "icu_analyzer",
"text": "This is a Introduction of Sanmao | 三毛:她把短暂的一生,活成了十世 By 2024 来源百度知道"
}
????????看对应文本的分词结果:
????????icu_analyzer分词器:分词从左到右进行,不会去除特殊字母和汉字,也不会重叠使用词组,仅是从左到右进行了短语分割。
{
"tokens": [
{
"token": "this",
"start_offset": 0,
"end_offset": 4,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "is",
"start_offset": 5,
"end_offset": 7,
"type": "<ALPHANUM>",
"position": 1
},
{
"token": "a",
"start_offset": 8,
"end_offset": 9,
"type": "<ALPHANUM>",
"position": 2
},
{
"token": "introduction",
"start_offset": 10,
"end_offset": 22,
"type": "<ALPHANUM>",
"position": 3
},
{
"token": "of",
"start_offset": 23,
"end_offset": 25,
"type": "<ALPHANUM>",
"position": 4
},
{
"token": "sanmao",
"start_offset": 26,
"end_offset": 32,
"type": "<ALPHANUM>",
"position": 5
},
{
"token": "三毛",
"start_offset": 35,
"end_offset": 37,
"type": "<IDEOGRAPHIC>",
"position": 6
},
{
"token": "她",
"start_offset": 38,
"end_offset": 39,
"type": "<IDEOGRAPHIC>",
"position": 7
},
{
"token": "把",
"start_offset": 39,
"end_offset": 40,
"type": "<IDEOGRAPHIC>",
"position": 8
},
{
"token": "短暂",
"start_offset": 40,
"end_offset": 42,
"type": "<IDEOGRAPHIC>",
"position": 9
},
{
"token": "的",
"start_offset": 42,
"end_offset": 43,
"type": "<IDEOGRAPHIC>",
"position": 10
},
{
"token": "一生",
"start_offset": 43,
"end_offset": 45,
"type": "<IDEOGRAPHIC>",
"position": 11
},
{
"token": "活",
"start_offset": 46,
"end_offset": 47,
"type": "<IDEOGRAPHIC>",
"position": 12
},
{
"token": "成了",
"start_offset": 47,
"end_offset": 49,
"type": "<IDEOGRAPHIC>",
"position": 13
},
{
"token": "十世",
"start_offset": 49,
"end_offset": 51,
"type": "<IDEOGRAPHIC>",
"position": 14
},
{
"token": "by",
"start_offset": 52,
"end_offset": 54,
"type": "<ALPHANUM>",
"position": 15
},
{
"token": "2024",
"start_offset": 55,
"end_offset": 59,
"type": "<NUM>",
"position": 16
},
{
"token": "来源",
"start_offset": 60,
"end_offset": 62,
"type": "<IDEOGRAPHIC>",
"position": 17
},
{
"token": "百度",
"start_offset": 62,
"end_offset": 64,
"type": "<IDEOGRAPHIC>",
"position": 18
},
{
"token": "知道",
"start_offset": 64,
"end_offset": 66,
"type": "<IDEOGRAPHIC>",
"position": 19
}
]
}
IK分词器
????????ik分词器是一个标准的中文分词器。它可以根据定义的字典对域进行分词,并且支持用户配置自己的字典,所以它除了可以按通用的习惯分词外,还可以定制化分词。
下载&安装
方式一:下载压缩包安装
????????【analysis-ik分词器下载地址(下载压缩包解压后复制到es的plugins目录下)】
????????下载的压缩包版本必须要和当前es版本一致。
????????除了直接下载已发布的压缩包,还可以到github下载源码自己编译打包,然后放到es的插件目录。
方式二:命令行安装
安装方式:
#window系统执行.bat
$ bin> elasticsearch-plugin.bat install analysis-ik
#linux执行
$ bin>./elasticsearch-plugin install analysis-ik
确认安装状态
方式一:命令行查询安装了哪些分词器
方式二:安装后重启es,重启后控制台打印加载分词器
????????安装失败可能会造成es启动失败或者是加载不到分词器。

ik分词器的简单使用
ik分词器有两种模式:
ik_smart:粗粒度拆分ik_max_word:细粒度拆分
ik_smart:粗粒度分词模式
????????postman请求分词器,测试分词结果:

????????请求命令:
curl -X GET -H 'Content-Type:application/json' -d '{"analyzer":"ik_smart","text":"本词条 | 来源百度知道"}' http://127.0.0.1:9200/news/_analyze
# -d:请求参数说明
{
"analyzer": "ik_smart", # ik分词器模式
"text": "本词条 | 来源百度知道"
}
????????看对应文本的分词结果:
????????ik_smart分词器:ik分词器,粗粒度分词。粗粒度划分中文词语。
{
"tokens": [
{
"token": "本",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "词条",
"start_offset": 1,
"end_offset": 3,
"type": "CN_WORD",
"position": 1
},
{
"token": "来源",
"start_offset": 6,
"end_offset": 8,
"type": "CN_WORD",
"position": 2
},
{
"token": "百度",
"start_offset": 8,
"end_offset": 10,
"type": "CN_WORD",
"position": 3
},
{
"token": "知道",
"start_offset": 10,
"end_offset": 12,
"type": "CN_WORD",
"position": 4
}
]
}
ik_max_word:细粒度分词模式
????????postman请求分词器,测试分词结果:

????????请求命令:对一个相同的内容进行分词
curl -X GET -H 'Content-Type:application/json' -d '{"analyzer":"ik_max_word","text":"本词条 | 来源百度知道"}' http://127.0.0.1:9200/news/_analyze
# -d:请求参数说明
{
"analyzer": "ik_max_word", # ik分词器模式
"text": "本词条 | 来源百度知道"
}
????????看对应文本的分词结果:
????????ik_max_word分词器:ik分词器,细粒度分词。细粒度划分中文词语。对比ik_smart模式,分的词更多了,意味着,在分词查询的时候可能会匹配到更多的结果。
{
"tokens": [
{
"token": "本",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "词条",
"start_offset": 1,
"end_offset": 3,
"type": "CN_WORD",
"position": 1
},
{
"token": "来源",
"start_offset": 6,
"end_offset": 8,
"type": "CN_WORD",
"position": 2
},
{
"token": "百度",
"start_offset": 8,
"end_offset": 10,
"type": "CN_WORD",
"position": 3
},
{
"token": "百",
"start_offset": 8,
"end_offset": 9,
"type": "TYPE_CNUM",
"position": 4
},
{
"token": "度",
"start_offset": 9,
"end_offset": 10,
"type": "COUNT",
"position": 5
},
{
"token": "知道",
"start_offset": 10,
"end_offset": 12,
"type": "CN_WORD",
"position": 6
}
]
}
pinyin分词器
????????拼音分析插件用于做汉字和拼音之间的转换,集成了NLP工具。
????????如果索引中字段映射了pinyin分词器,那么在通过拼音搜索的时候,输入的拼音会自动和索引中指定pinyin分词类型的字段做匹配。匹配到结果就会被返回。
源码下载、编译、打包
????????【github下载拼音分词器源码(选择对应es版本的分支)】
????????没有直接找到pinyin分词器的压缩包,所以在github上找到pinyin分词器的源码,需要自己下载下来,编译、打包。然后把打包后的.zip文件解压后复制到es的plugins目录下。
????????补充!【pinyin分词器发布版(压缩包下载地址)】
????????源码拉到本地之后,需要对maven做仓库做下配置,总之,需要mvn能在项目里正常运行。
- pinyin分词器编译打包:
mvn clean package
- 打包成功后在
target/releases目录下生成.zip的压缩文件

????????复制elasticsearch-analysis-pinyin-6.7.0.zip到elasticsearch的插件目录下解压:

????????解压后删除xxx-pinyin-6.7.0.zip压缩文件,并修改plugin-descriptor.properties的内容:版本号要和当前使用的es版本号一致!
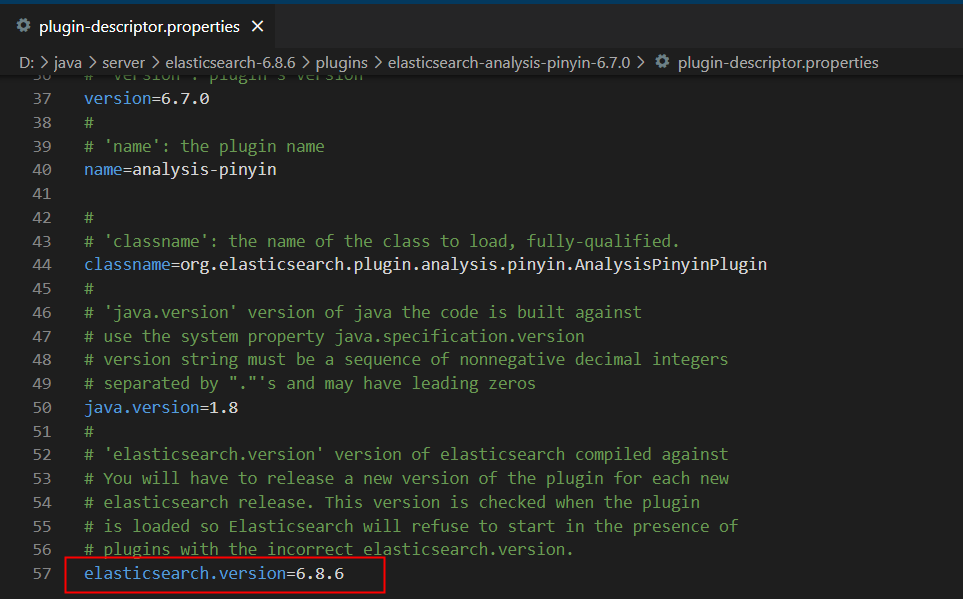
确认安装状态
方式一:命令行查询安装了哪些分词器
方式二:安装后重启es,重启后控制台打印加载分词器
????????安装失败可能会造成es启动失败或者是加载不到分词器。

pinyin分词器参数
????????【pinyin分词器参数来源】

pinyin分词器简单使用
拼音分词:输入的拼音进行拆分
????????postman请求分词器,测试拼音分词结果:

????????请求命令:
curl -X GET -H 'Content-Type:application/json' -d '{"analyzer":"pinyin","text":"sanmao"}' http://127.0.0.1:9200/news/_analyze
# -d:请求参数说明
{
"analyzer": "pinyin", # pinyin分词器
"text": "sanmao"
}
????????看对应文本的分词结果:
????????pinyin分词器:pinyin分词器把输入的拼音拆分成了单个拼音、拼音组合、拼音缩写。
{
"tokens": [
{
"token": "san",
"start_offset": 0,
"end_offset": 0,
"type": "word",
"position": 0
},
{
"token": "sanmao",
"start_offset": 0,
"end_offset": 0,
"type": "word",
"position": 0
},
{
"token": "mao",
"start_offset": 0,
"end_offset": 0,
"type": "word",
"position": 1
}
]
}
汉字转拼音分词:输入的汉字拆分为若干个拼音
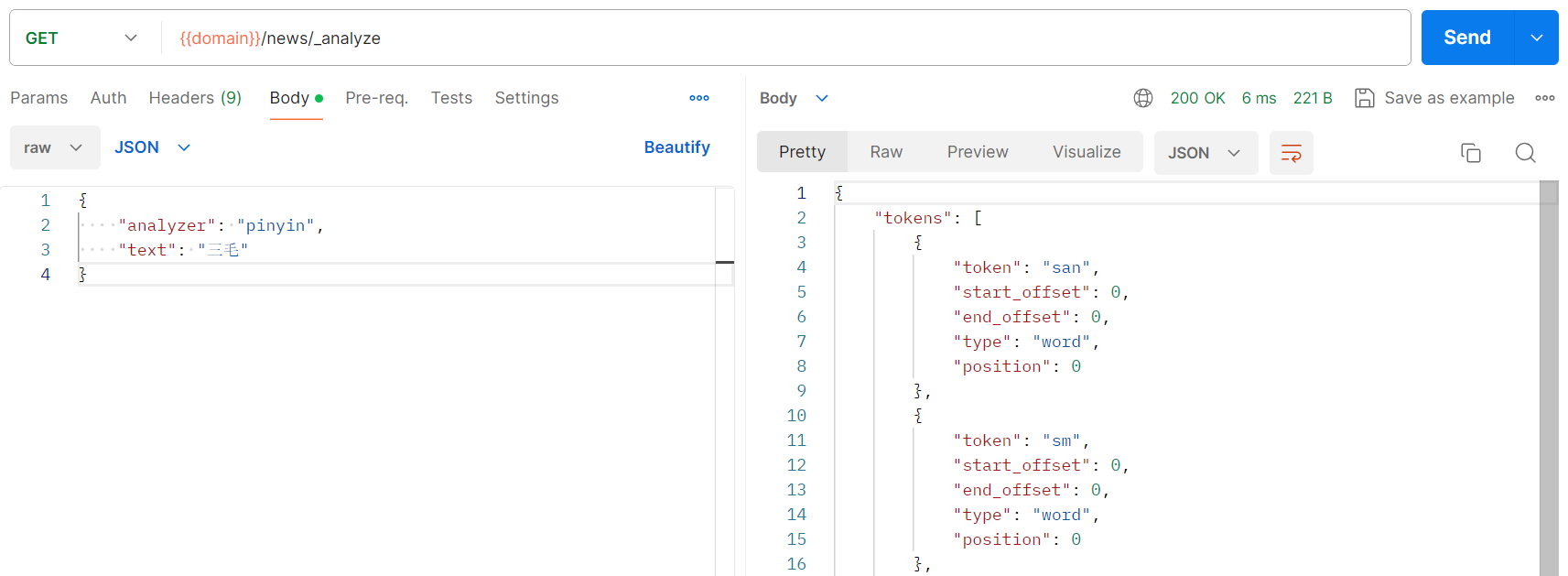
????????postman请求分词器,测试汉字转拼音分词结果:
????????请求命令:
curl -X GET -H 'Content-Type:application/json' -d '{"analyzer":"pinyin","text":"三毛"}' http://127.0.0.1:9200/news/_analyze
# -d:请求参数说明
{
"analyzer": "pinyin", # pinyin分词器
"text": "三毛"
}
????????看对应文本的分词结果:
????????pinyin分词器:pinyin分词器把输入的汉字拆分成了单个拼音、拼音组合、拼音缩写。
{
"tokens": [
{
"token": "san",
"start_offset": 0,
"end_offset": 0,
"type": "word",
"position": 0
},
{
"token": "sm",
"start_offset": 0,
"end_offset": 0,
"type": "word",
"position": 0
},
{
"token": "mao",
"start_offset": 0,
"end_offset": 0,
"type": "word",
"position": 1
}
]
}
pinyin分词器查询数据(示例)
????????通过上面的【pinyin分词器简单使用】对拼音/汉字转拼音分词结果有了认知,但是,拼音的分词结果对查询的影响不如icu、ik或者默认分词器这么直观。
下面用一个新索引,示范拼音分词器的使用。
创建指定pinyin分词器的索引:pinyin_news
????????上面的news索引是没有做任何分词器配置的,现在创建一个新索引pinyin_news并修改默认分词器为拼音分词器。数据结构和数据还是同news一致。
# 创建pinyin_news索引
curl -X PUT -d '见下面' -H 'Content-Type:application/json' http://127.0.0.1:9200/pinyin_news
# -d参数说明
{
# 创建索引时的配置
"settings": {
"index": {
"number_of_shards": "5",
"number_of_replicas": "1"
},
# 分词器的配置
"analysis": {
"analyzer": {
"default": {
# 修改默认分词器为pinyin,不做复杂pinyin分词配置,默认pinyin分词器名称就可以。如果需要可以根据github参数说明修改pinyin分词器的默认配置,那这里就不是这样配置了
"type": "pinyin"
}
}
}
},
# 字段映射关系配置
"mapping": {
# 文档类型:高版本应该取消了_doc了。
"_doc": {
"properties": {
"id": {
"type": "long"
},
# 分词器只能对text类型的字段进行分词,在修改默认分词器的同时还需要修改指定字段的分词类型(指定字段也可以使用其他分词类型)
# 这里对title字段进行pinyin分词
"title": {
"type": "text",
"analyzer": "pinyin"
},
"uv": {
"type": "long"
},
"create_date": {
"type": "date"
},
"status": {
"type": "int"
},
"remark": {
"type": "text"
}
}
}
}
}
批量插入一些数据(_bulk),做查询演示
# 测试使用postman发起请求
# 向pinyin_news索引批量新增数据
curl -X POST -d '见下面' -H 'Content-Type:application/json' http://127.0.0.1:9200/pinyin_news/_doc/_bulk
# -d参数说明,每一个对象一个换行(\n)
{"index": {"_id": 1}}
{"id":1,"title":"三毛:她把短暂的一生,活成了十世","uv":120,"create_date":"2024-01-15","status":1,"remark":"来源百度搜索"}
{"index": {"_id": 2}}
{"id":2,"title":"我愿一生流浪 | 三毛《撒哈拉的故事","uv":99,"create_date":"2024-01-14","status":1,"remark":"来源知乎搜索"}
{"index": {"_id": 3}}
{"id":3,"title":"离世33年仍是“华语顶流”,三毛“珍贵录音”揭露人生真相:世界是对的,但我也没错!","uv":80,"create_date":"2024-01-15","status":1,"remark":"来源搜狐"}
{"index": {"_id": 4}}
{"id":4,"title":"三毛逝世30周年丨一场与三毛穿越时空的对话","uv":150,"create_date":"2024-01-16","status":1,"remark":"来源澎湃新闻"}
{"index": {"_id": 5}}
{"id":5,"title":"三毛:从自闭少女到天才作家","uv":141,"create_date":"2024-01-18","status":1,"remark":"来源光明网"}
{"index": {"_id": 6}}
{"id":6,"title":"超全整理!三毛最出名的11本著作,没读过的一定要看看","uv":200,"create_date":"2024-01-23","status":1,"remark":"来源知乎搜索"}
{"index": {"_id": 7}}
{"id":7,"title":"三毛的英文名为什么叫Echo?","uv":300,"create_date":"2024-01-21","status":1,"remark":"来源百度知道"}
{"index": {"_id": 8}}
{"id":8,"title":"毛国家统计局发布第三季度贸易数据","uv":50,"create_date":"2024-01-23","status":1,"remark":"来源中华人民共和国商务部"}
{"index": {"_id": 9}}
{"id":9,"title":"网易公布2022年第三季度财报|净收入|毛利润","uv":131,"create_date":"2024-01-22","status":1,"remark":"来源网易科技"}
{"index": {"_id": 10}}
{"id":10,"title":"单季盈利超100亿元!比亚迪三季度毛利率超特斯拉","uv":310,"create_date":"2024-01-23","status":1,"remark":"来源新浪财经"}
# 批量参数最后要留一空行
????????插入的内容如图所示:

使用拼音查询
????????postman发起请求截图:

????????请求命令:
# 测试使用postman发起请求
# 向pinyin_news索引批量新增数据
curl -X POST -d '见下面' -H 'Content-Type:application/json' http://127.0.0.1:9200/pinyin_news/_search
# -d 参数说明
{
# 使用es布尔查询
"query": {
"bool": {
# 查询必须要包含(sanmaochuanyue)三毛穿越
"must": {
"match": {
"title": "sanmaochuanyue"
}
}
}
},
"from": 0, # 起始页码
"size": 10000, # 每页条数
"sort": [],
"aggs": {}
}
????????查询结果:
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 10,
"max_score": 2.3288696,
"hits": [
{
"_index": "pinyin_news",
"_type": "_doc",
"_id": "4",
# 与输入值sanmaochuanyue的匹配度最高
"_score": 2.3288696,
"_source": {
"id": 4,
# title中正好包含三毛穿越,其他匹配三毛的_score依次降低
"title": "三毛逝世30周年丨一场与三毛穿越时空的对话",
"uv": 150,
"create_date": "2024-01-16",
"status": 1,
"remark": "来源澎湃新闻"
}
},
{
"_index": "pinyin_news",
"_type": "_doc",
"_id": "3",
"_score": 0.5825863,
"_source": {
"id": 3,
"title": "离世33年仍是“华语顶流”,三毛“珍贵录音”揭露人生真相:世界是对的,但我也没错!",
"uv": 80,
"create_date": "2024-01-15",
"status": 1,
"remark": "来源搜狐"
}
},
{
"_index": "pinyin_news",
"_type": "_doc",
"_id": "7",
"_score": 0.3807567,
"_source": {
"id": 7,
"title": "三毛的英文名为什么叫Echo?",
"uv": 300,
"create_date": "2024-01-21",
"status": 1,
"remark": "来源百度知道"
}
},
{
"_index": "pinyin_news",
"_type": "_doc",
"_id": "1",
"_score": 0.36986062,
"_source": {
"id": 1,
"title": "三毛:她把短暂的一生,活成了十世",
"uv": 120,
"create_date": "2024-01-15",
"status": 1,
"remark": "来源百度搜索"
}
},
{
"_index": "pinyin_news",
"_type": "_doc",
"_id": "2",
"_score": 0.3044239,
"_source": {
"id": 2,
"title": "我愿一生流浪 | 三毛《撒哈拉的故事",
"uv": 99,
"create_date": "2024-01-14",
"status": 1,
"remark": "来源知乎搜索"
}
},
{
"_index": "pinyin_news",
"_type": "_doc",
"_id": "8",
"_score": 0.25879097,
"_source": {
"id": 8,
"title": "毛国家统计局发布第三季度贸易数据",
"uv": 50,
"create_date": "2024-01-23",
"status": 1,
"remark": "来源中华人民共和国商务部"
}
},
{
"_index": "pinyin_news",
"_type": "_doc",
"_id": "6",
"_score": 0.25162232,
"_source": {
"id": 6,
"title": "超全整理!三毛最出名的11本著作,没读过的一定要看看",
"uv": 200,
"create_date": "2024-01-23",
"status": 1,
"remark": "来源知乎搜索"
}
},
{
"_index": "pinyin_news",
"_type": "_doc",
"_id": "5",
"_score": 0.24291237,
"_source": {
"id": 5,
"title": "三毛:从自闭少女到天才作家",
"uv": 141,
"create_date": "2024-01-18",
"status": 1,
"remark": "来源光明网"
}
},
{
"_index": "pinyin_news",
"_type": "_doc",
"_id": "9",
"_score": 0.20951384,
"_source": {
"id": 9,
"title": "网易公布2022年第三季度财报|净收入|毛利润",
"uv": 131,
"create_date": "2024-01-22",
"status": 1,
"remark": "来源网易科技"
}
},
{
"_index": "pinyin_news",
"_type": "_doc",
"_id": "10",
"_score": 0.1960371,
"_source": {
"id": 10,
"title": "单季盈利超100亿元!比亚迪三季度毛利率超特斯拉",
"uv": 310,
"create_date": "2024-01-23",
"status": 1,
"remark": "来源新浪财经"
}
}
]
}
}
为什么输入pinyin能匹配到结果呢?
分两步走:
????????第一步: 输入的词通过pinyin分词器分词,分成若干单个拼音、组合拼音、拼音缩写,然后拿着这些结果到es中的title字段查询数据。
????????第二步:title字段中的值,按照相同的pinyin分词方式,进行分词拆分,分成若干单个拼音、组合拼音、拼音缩写,然后拿着分词结果和输入的分词结果做比对,比对成功即返回hits,但是_score分数高的排名在前,也就是匹配程度越高,返回结果越靠前。
????????总之,输入的(汉字\拼音)都会被pinyin分词器转成拼音,被查询的title字段也会被pinyin分词器转成拼音,然后再去做数据比对。因为分词规则都是一样的,所以不管是拼音还是汉字都能查询出结果。
总结
- 安装分词器插件后,在创建索引时没有配置自定义分词器名称时,请求
GET {{index_name}}/_analyze需要使用插件中默认的分词器名称。(本文没有涉及到自定义分词器名称的配置) - 输入词的分词规则和被查询字段的的分词规则一致。否则查不出结果。
- 了解了分词器是不是能Get到怎么在百度输入框里面输入内容,查询可能更精准?
补充
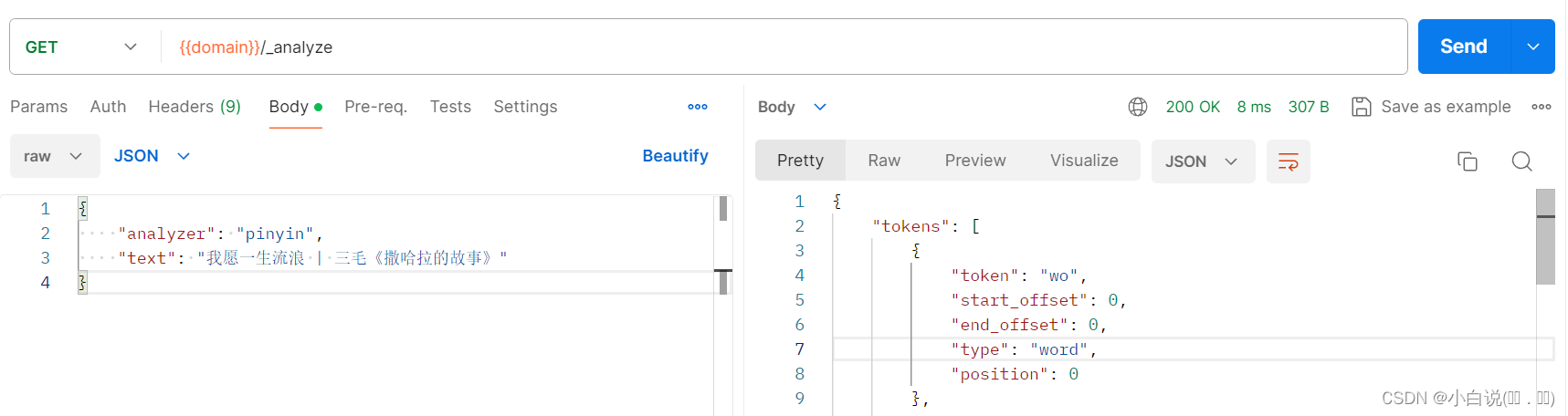
????????查询分词结果还可以不指定索引直接请求:
GET {{domain}}/_analyze
参数:
{
"analyzer": "pinyin",
"text": "我愿一生流浪 | 三毛《撒哈拉的故事》"
}
参考链接
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- uni-app顶部导航条固定
- 【Py/Java/C++三种语言详解】LeetCode每日一题240110【栈】LeetCode2696、删除子串后的字符串最小长度
- day-16 最大交换
- 检查密码(字符串)
- k8s二进制部署--部署高可用
- 2024年山东省安全员B证证考试题库及山东省安全员B证试题解析
- 腾讯云国外服务器价格表免费公网IP地址
- Python面试之装饰器
- 【Java】问题——Unicode转换中文
- 频谱论文:面向频谱地图构建的频谱态势生成技术研究