【Linux】软硬链接和动静态库
需要云服务器等云产品来学习Linux的同学可以移步/–>腾讯云<–/官网,轻量型云服务器低至112元/年,优惠多多。(联系我有折扣哦)
文章目录
1. 软硬连接
1.1 软链接
在Windows系统中,我们可以给任意一个文件或者文件夹建立快捷方式

这样很方便我们打开很深的文件夹内存放的文件,实际上在Linux中也有这种快捷方式的概念,只是在Linux中它叫做软链接
1. 软链接的创建方式
我们可以通过ln指令来创建链接,其中带上选项s表示创建软链接
ln -s FILE_NAME SOFTLINK_NAME

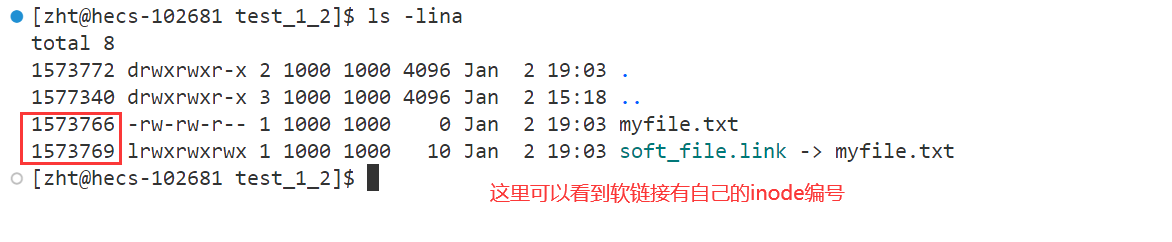
因为软链接有自己的inode编号,证明了软链接本质上是一个新文件
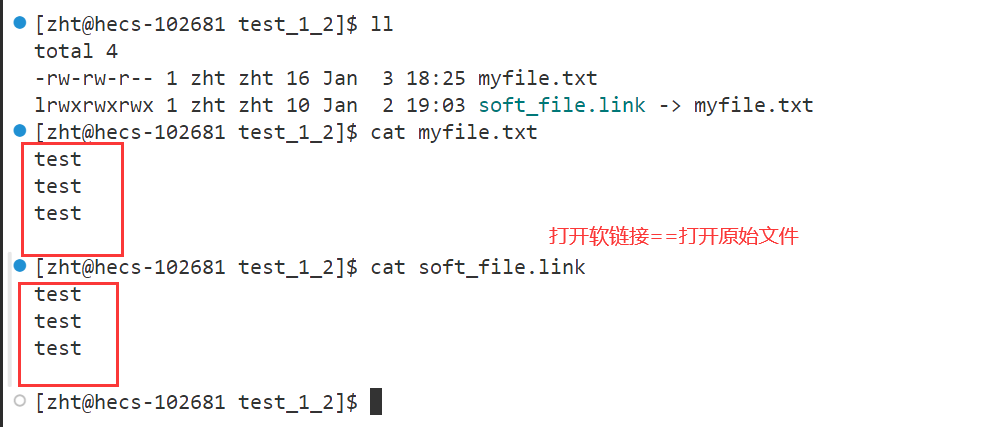
实际上软链接里面存放的是源文件的路径,所以看起来软链接的大小比较小
2. 软链接的删除(解除链接)
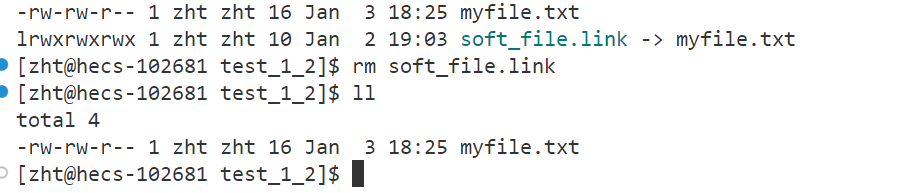
方法一:软链接也是文件,所以能供直接使用rm指令删除软链接文件。
方法二:使用unlink解除软链接

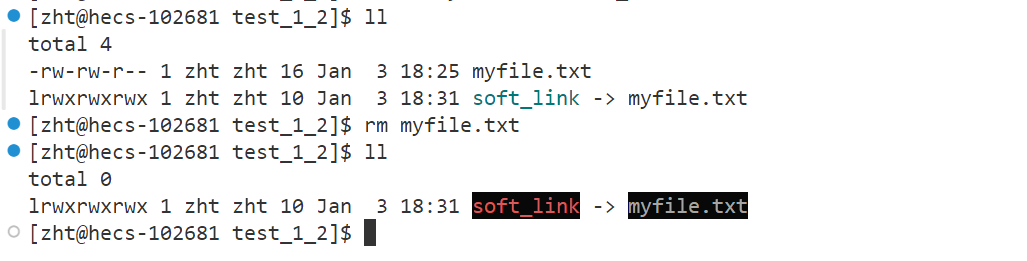
我们可以把软链接理解为一个快捷方式,那么源文件被删除之后,我们的快捷方式显而易见也是用不了了的
1.2 硬链接
在之前的文件系统的文章中,我们提到OS真正找到文件依靠的是inode,文件名只是在目录文件中的一堆和inode对应的映射。实际上在Linux中,可以让多个文件名映射同一个inode,这种方式被称为硬链接
1. 硬链接的创建方式
在创建软链接的时候,我们使用了-s选项,不使用-s就是创建硬链接
ln FILE_NAME SOFTLINK_NAME
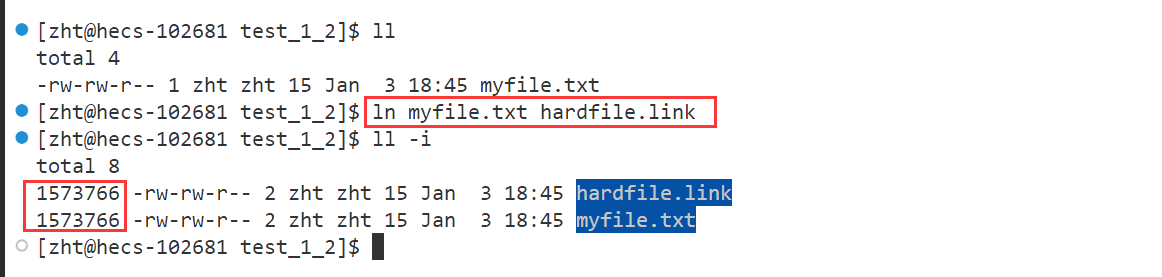
可以看到,这里两个文件名对应的inode是一样的,这个硬链接不是一个独立的文件。
当硬链接其中一个文件的大小、内容等发生变化,那硬链接的文件都会发生相应的变化,所以建立硬链接根本没有新增文件,因为没有给硬链接分配独立的inode,既然没有创建文件那么就没有自己的属性集合和内容集合,用的是别人的inode和内容。创建硬链接本质就是在指定的路径下,新增文件名和inode编号的映射关系!
由于硬链接的存在,我们知道inode可能会被多个文件名同时指向,所以实际上在inode结构体中有一个计数器,表示被指向的次数,也就是硬链接数
这里的数字也就是这个引用计数。由于myfile.txt被hard.link硬链接了,所以对应的inode被两个文件名指向了
已经知道如果把源文件删掉,那么软链接将会失效,硬链接呢?
所以可以得到结论:当一个文件的inode引用次数变为0 的时候才会被真正删除


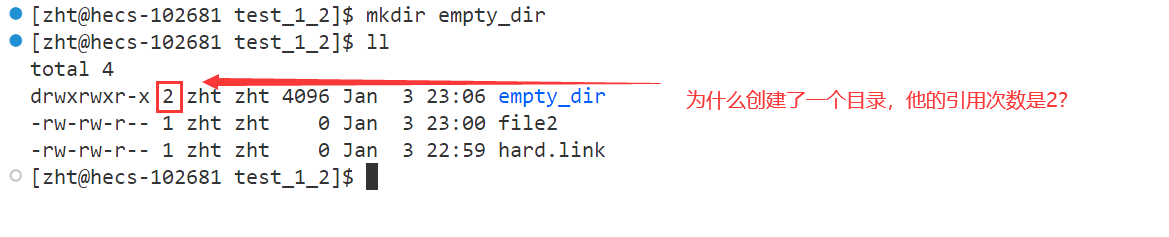
首先,目录本身就是一个文件,这个目录名和他的inode构成了一组映射关系,当我们进入到这个目录之后,在这个空目录里面默认会有一个
.表示当前目录本身,这也是一组映射
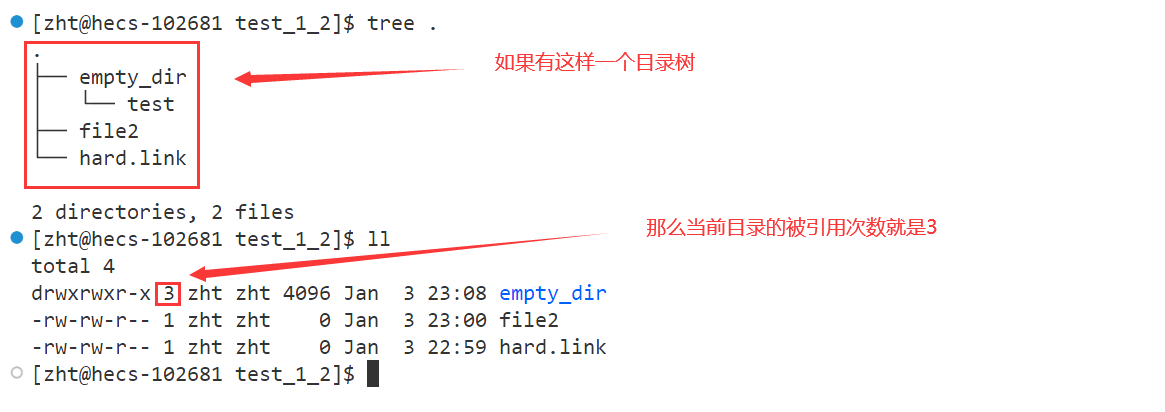
结论:软硬连接的本质就是有无独立的inode
一个小问题:为什么Linux不允许普通用户给目录建立硬链接?
当一个目录被作为硬链接的目标时,可能会出现以下问题:
- 循环链接:如果两个目录相互链接,可能会形成循环链接,导致无限递归的问题。
- 文件的删除:如果一个目录被多个硬链接链接,删除其中一个链接后,该目录可能仍然存在,但会变为孤立的无法访问的目录。
2. 动静态库
2.1 动静态库的基本原理
动静态库的本质是可执行程序的“半成品”
在程序环境和预处理中我们讲过,一段C/C++代码最终变成可执行程序需要经历以下步骤:
- 预处理:包括头文件展开、去注释、宏替换、条件编译等,形成
.i文件; - 编译:包括词法分析、语法分析、语义分析、符号汇总等,然后将代码翻译成汇编指令,形成
.s文件; - 汇编:将汇编指令转换成二进制指令,形成
.o文件; - 链接:将一个项目中所有
.c文件生成的.o文件进行链接,最终形成可执行程序。
那么假设我们现在写好了两个文件test1.c和test2.c其中包含了很多需要经常被使用的功能,同时他们的编译时间很长
那么在main1和main2这两个项目中都要用到这两个.c文件,那就会有如下过程

这些过程都是重复的,而且我们知道对于test1.c和test2.c,我们需要用到的实际上只是他们汇编之后产生的.o文件,那么能不能对他们只进行一次编译产生.o文件,之后需要用到的时候,直接链接.o文件呢?答案是可以的,但是需要在编译的时候手动把这些文件写进编译指令中,这样的对于很多.o文件的话那就比较繁琐了,所以实际上我们可以把很多个.o文件进行打包,形成一个库,之后每次需要使用的时候,再链接里面的内容即可。
实际上,库的本质就是一堆目标文件(.o文件)和对应.h文件的集合
2.2 动静态库的基本特征
我们用一个最简单的代码来看一看动静态库的“本尊”
#include <stdio.h>
int main()
{
printf("hello world\n");
return 0;
}
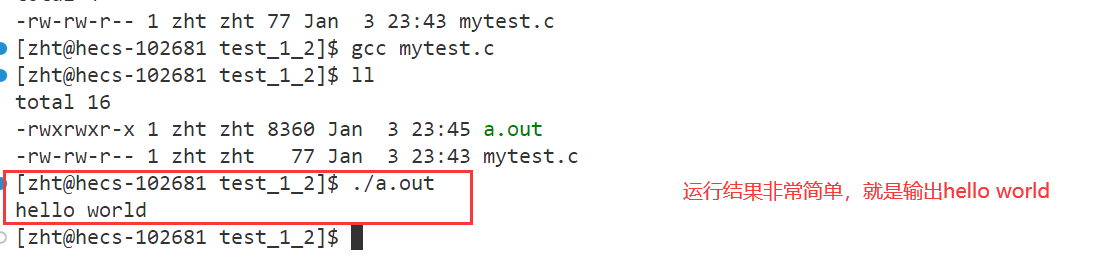
那么接下来,我们就使用这个例子来看一看“库”
这段代码使用了一个“库函数”——
printf,这个库是C标准库stdio.h中的内容
我们可以使用ldd FILENAME来查看一个可执行程序依赖的库文件

这个库的名字是libc.so.6,这个.6是版本的意思,我们抛去不看,剩下的libc.so
小知识
在Linux下,去掉后面的
.so或者.a和前面的lib,剩下的就是这个库的名字。其中.a表示这是个静态库,.so表示这是个动态库在Windows下,
.dll表示动态库,.lib表示静态库
所以可以知道,我们的代码使用的就是C的动态库
gcc/g++编译器默认都是动态链接的,如果想要进行静态链接,可以加上一个-static选项


同时,使用file指令也能看出来这个可执行是动态链接还是静态链接的

动静态库实际上各有优缺
动态库:
- 优点:节省磁盘空间,且多个用到相同动态库的程序同时运行时,库文件会通过进程地址空间进行共享,内存当中不会存在重复代码。
- 缺点:必须依赖动态库,否则无法运行。
静态库:
- 优点:使用静态库生成可执行程序后,该可执行程序就可以独自运行,不再需要库了。
- 缺点:使用静态库生成可执行程序会占用大量空间,特别是当有多个静态程序同时加载而这些静态程序使用的都是相同的库,这时在内存当中就会存在大量的重复代码。
2.3 静态库的打包与使用
为了方便讲解,我们首先创建两个.c文件和他们的头文件,用来表示我们自己实现的功能,接下来要使用这些文件分别创建动静态库并使用他们
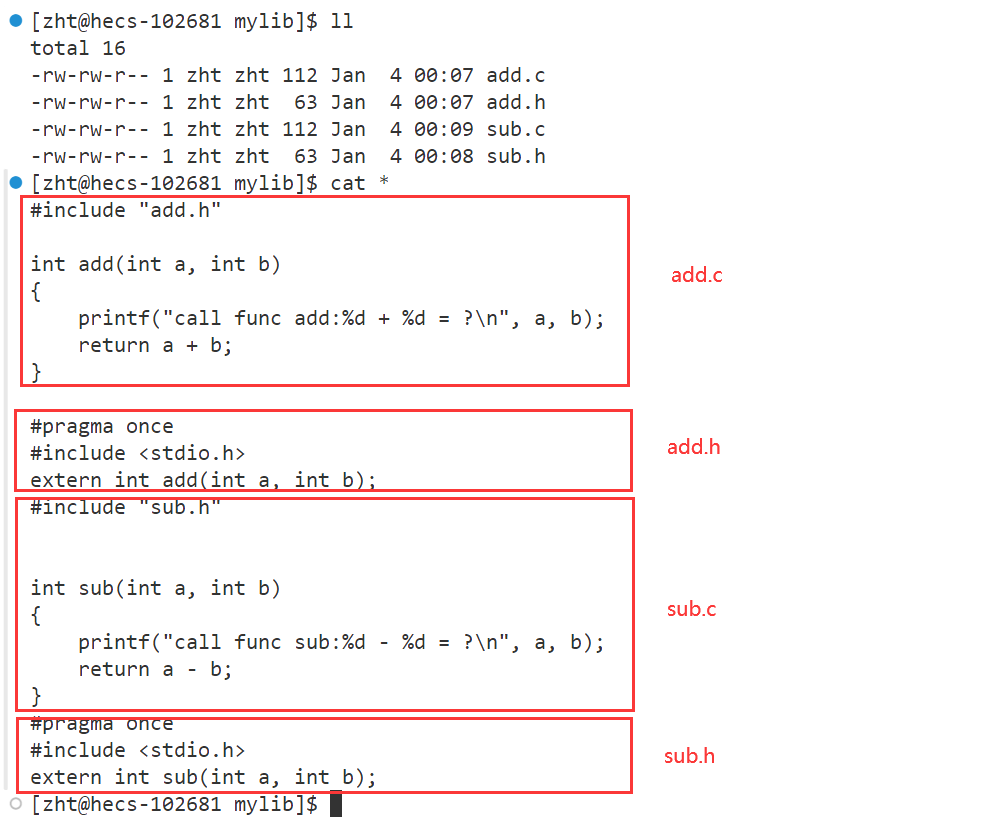
打包
第一步,使用-c选项,让所有源文件生成目标文件
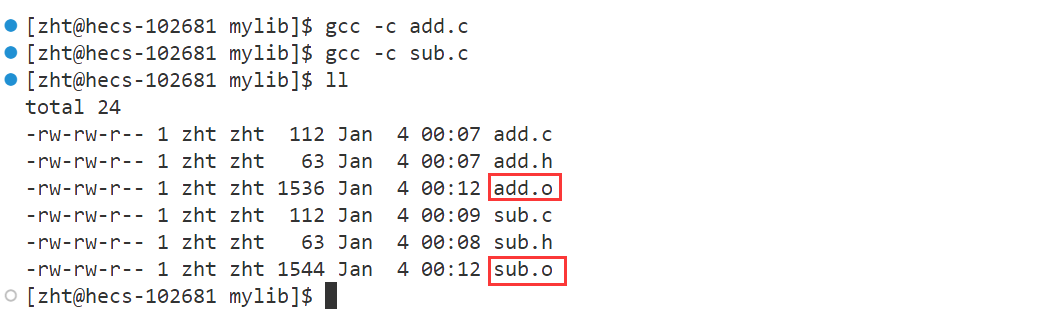
第二步,使用ar指令将所有目标文件打包为静态库
ar是GNU的归档工具,常用于将目标文件打包为静态库
-r(replace):若静态库与文件中的目标文件有更新,则使用新的目标文件替换旧的-c(create):建立静态库文件-t:列出静态库中的文件-v(verbose):显示详细的信息。


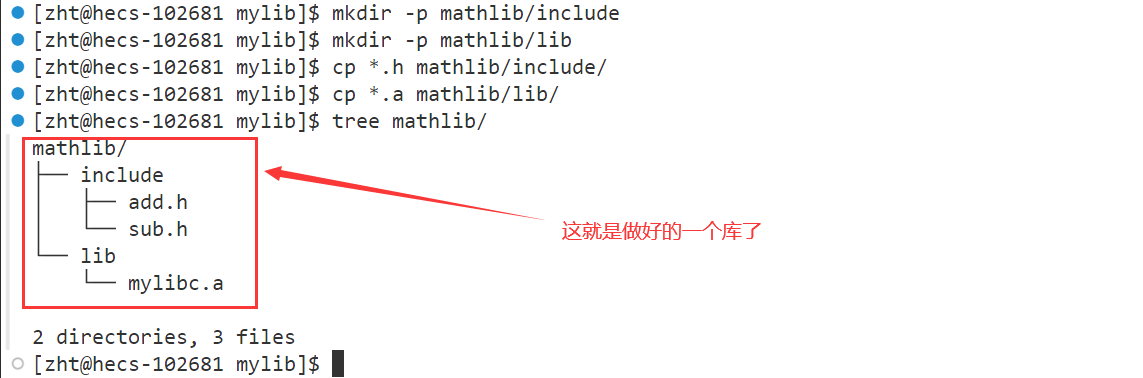
第三步,将头文件与生成的静态库组织起来
当我们把自己写的库给别人用的时候,实际上需要提供两个文件,一个存放所有函数的实现,另一个存放所有函数的声明。
这里我们把所有的头文件放到一个include目录下,生成的静态库文件放在lib目录下
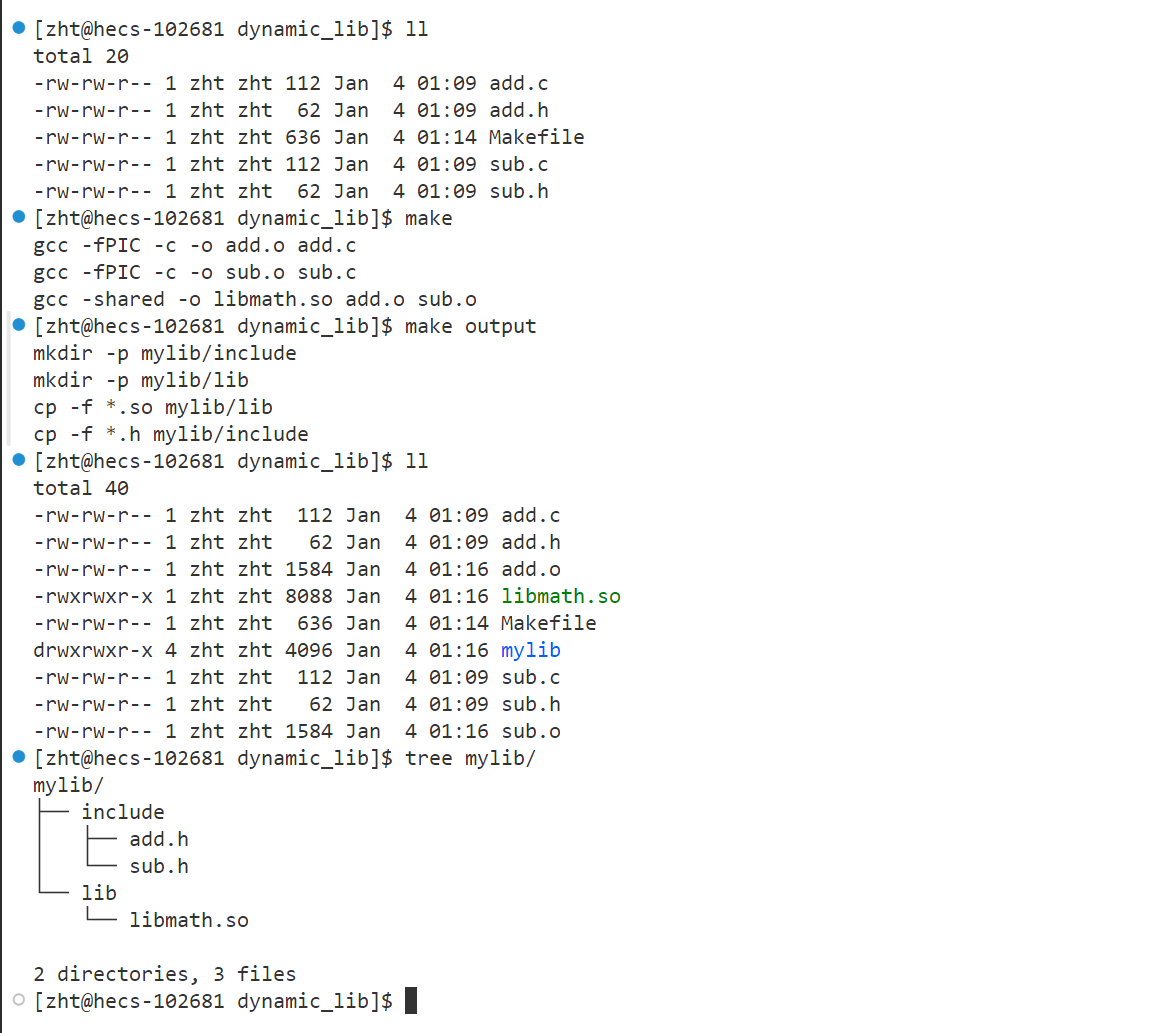
当然上述的步骤比较麻烦,那么现在我们可以借助自动化构建工具make来一步完成库的构建,关于makefile的讲解,在Linux项目自动化构建工具make中有提到一些,感兴趣的可以去看看,这里直接附上Makefile文件的内容
libmath.a:add.o sub.o # 生成mathlib.a文件,依赖于add.o 和 sub.o
ar -rc $@ $^
# 但是这里add.o和sub.o文件不是凭空产生的,所以需要为他们提供一个依赖关系
add.o:add.c
gcc -c -o $@ $^
sub.o:sub.c
gcc -c -o $@ $^
.PHONY:output
output: # 打包生成的文件,成为一个库
mkdir -p mylib/include
mkdir -p mylib/lib
cp -f *.a mylib/lib
cp -f *.h mylib/include
.PHONY:clean # 清理产生的所有文件
clean:
rm -rf mylib *.o *.a
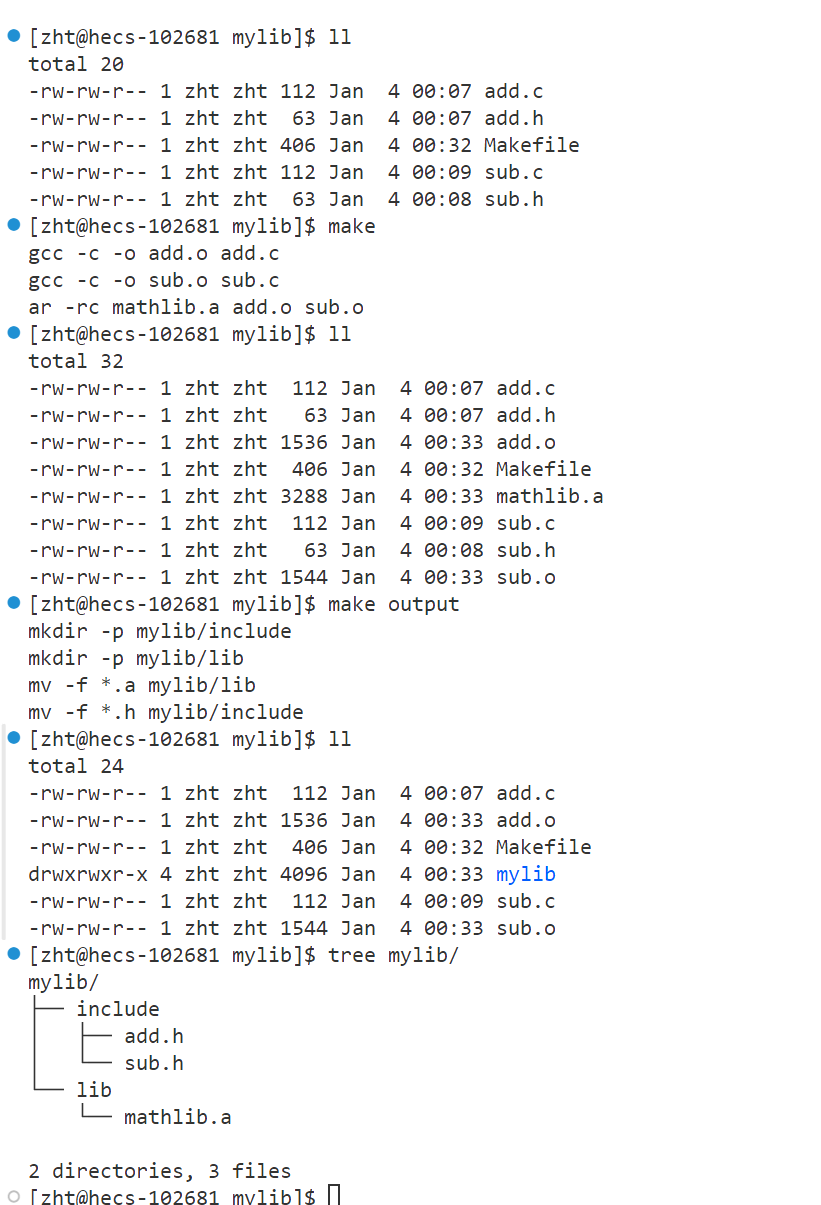
到此,我们就算是把库制作好了,如果需要发布的话,就把这个目录压缩上传到网站,使用者下载解压使用即可
使用
假设我们下载了之前打包的库,然后进行解压,得到一个mylib目录

接下来我们写一段代码来使用这个库:
#include "add.h"
#include "sub.h"
#include <stdio.h>
int main()
{
int a = 20;
int b = 10;
printf("%d\n", add(a, b));
printf("%d\n", sub(a, b));
}
当然,在使用的时候肯定会遇到很多的问题,我们来一个一个解决:
1. 头文件找不到?

编译器在搜索头文件的时候只会在当前目录和系统默认路径下搜索,虽然我们的
mylib在当前目录,但是太深了,编译器找不到,所以我们要给编译器指定路径。使用-I选项指明在某个路径下查找头文件
2. 找不到函数的实现

我们在形成可执行程序的时候,库文件要使用的话也要知道库所在的路径在哪里,系统的默认路径是/lib64。使用
-L选项指明库的路径
3. 还是找不到函数实现?

这是因为我们还要指明使用的库的名字,即使指定目录只有一个文件
注意:这里的库的名字是指去掉前缀和后缀的
使用
-l指明需要链接库文件路径下的哪一个库。

终于能够成功运行了!!!
除了上述的方式之外,也可以将头文件和库文件拷贝到系统路径下
/usr/include和/lib64需要注意的是,虽然已经将头文件和库文件拷贝到系统路径下,但当我们使用gcc编译main.c生成可执行程序时,还是需要指明需要链接库文件路径下的哪一个库。
注意:但并不推荐将自己写的头文件和库文件拷贝到系统路径下,这样做会对系统文件造成污染!!!
2.4 动态库的打包与使用
打包
动态库的打包和静态库基本相同,只有一点点差别,这里就只使用Makefile的方式来构建
libmath.so:add.o sub.o # 使用gcc的-shared选项将所有目标文件打包为动态库
gcc -shared -o $@ $^
# 但是这里add.o和sub.o文件不是凭空产生的,所以需要为他们提供一个依赖关系
add.o:add.c # 编译的时候带上-fPIC选项,产生位置无关码
gcc -fPIC -c -o $@ $^
sub.o:sub.c # 编译的时候带上-fPIC选项,产生位置无关码
gcc -fPIC -c -o $@ $^
.PHONY:output
output: # 打包生成的文件,成为一个库
mkdir -p mylib/include
mkdir -p mylib/lib
cp -f *.so mylib/lib
cp -f *.h mylib/include
.PHONY:clean # 清理产生的所有文件
clean:
rm -rf mylib *.o *.so
这里最重要的不同点就是生成位置无关码的概念
- -fPIC作用于编译阶段,告诉编译器产生与位置无关的代码,此时产生的代码中没有绝对地址,全部都使用相对地址,从而代码可以被加载器加载到内存的任意位置都可以正确的执行。这正是共享库所要求的,共享库被加载时,在内存的位置不是固定的。
- 如果不加-fPIC选项,则加载.so文件的代码段时,代码段引用的数据对象需要重定位,重定位会修改代码段的内容,这就造成每个使用这个.so文件代码段的进程在内核里都会生成这个.so文件代码段的拷贝,并且每个拷贝都不一样,取决于这个.so文件代码段和数据段内存映射的位置。
- 不加-fPIC编译出来的.so是要在加载时根据加载到的位置再次重定位的,因为它里面的代码BBS位置无关代码。如果该.so文件被多个应用程序共同使用,那么它们必须每个程序维护一份.so的代码副本(因为.so被每个程序加载的位置都不同,显然这些重定位后的代码也不同,当然不能共享)。
- 我们总是用-fPIC来生成.so,但从来不用-fPIC来生成.a。但是.so一样可以不用-fPIC选项进行编译,只是这样的.so必须要在加载到用户程序的地址空间时重定向所有表目。
使用
和之前静态库一样的逻辑,一样的代码


但是运行发现这里是有问题的

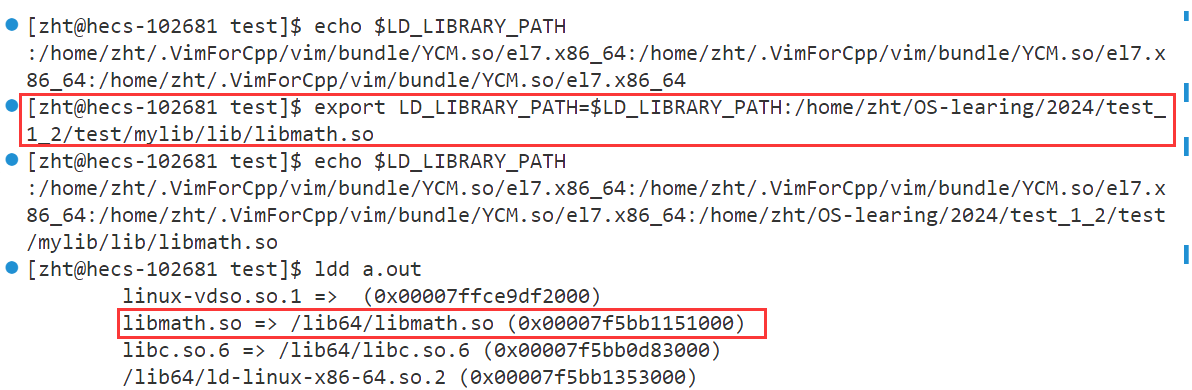
这是因为我们使用-I,-L,-l这三个选项都是在编译期间告诉编译器我们使用的头文件和库文件在哪里以及是谁,但是当生成的可执行程序生成后就与编译器没有关系了,此后该可执行程序运行起来后,操作系统找不到该可执行程序所依赖的动态库,我们可以使用ldd命令进行查看。

对于这个问题,我们有三个方法可以解决:
将库文件拷贝到系统共享的库路径下
程序也能正常运行
更改
LD_LIBRARY_PATH
LD_LIBRARY_PATH是程序运行动态查找库时所要搜索的路径,我们只需将动态库所在的目录路径添加到LD_LIBRARY_PATH环境变量当中即可
程序正常运行
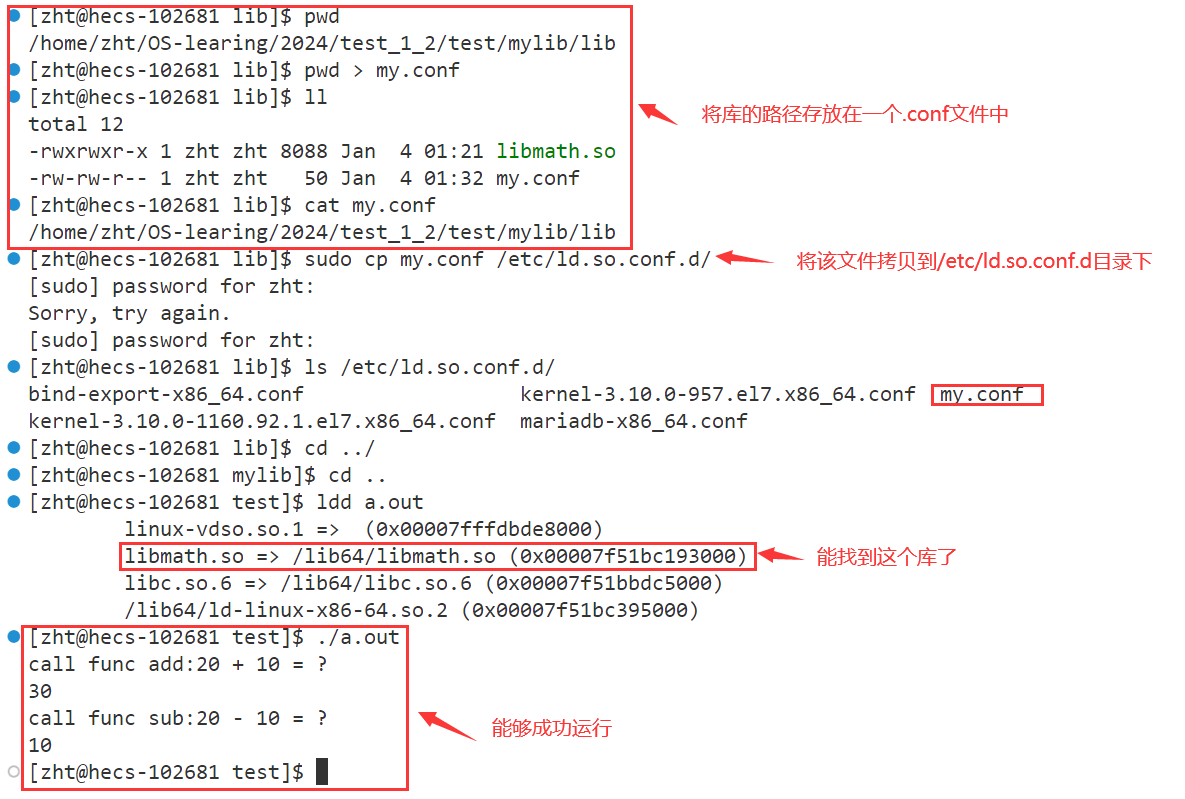
配置
/etc/ld.so.conf.d/我们可以通过配置/etc/ld.so.conf.d/的方式解决该问题,/etc/ld.so.conf.d/路径下存放的全部都是以.conf为后缀的配置文件,而这些配置文件当中存放的都是路径,系统会自动在/etc/ld.so.conf.d/路径下找所有配置文件里面的路径,之后就会在每个路径下查找你所需要的库。我们若是将自己库文件的路径也放到该路径下,那么当可执行程序运行时,系统就能够找到我们的库文件了。



3. 动静态库的加载原理
3.1 静态库的加载
静态库不需要加载,静态库把代码拷贝到可执行程序里,直接决定了当加载的时候在内存里代码和数据可能存在多份,会比较浪费空间,把静态库中拷贝到程序中的代码区里:

3.2 动态库的加载
动态库加上fPIC形成位置无关码,采用相对编址方案,在程序链接时对应库当中的偏移量添加到可执行程序,运行时一旦库加载进来,经过地址空间映射,把库映射到地址空间之后,库也就具备了起始地址,通过偏移地址和起始地址这样就可以找到访问的函数:

系统层面上会维护动态库的起始地址,直接建立页表与内存的映射,也就可以跳转访问了,所以动态库加载一次就可以被多个进程共同使用了。而静态库可能有多个程序用了C库,加载到内存时,内存里可能会存在100份重复的代码。而动态链接不会出现重复的代码,减少内存消耗。
本章完…
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- c# 学习笔记 -枚举
- js的节流和防抖
- 华为OD机试 - 书籍叠放 - 逻辑分析(Java 2023 B卷 200分)
- 基于 IDEA 进行 Maven 工程构建
- 直接发文!1D-2D-MTF-CNN-GRU-AT多通道图像时序融合的分类/故障识别程序!Excel导入,直接运行
- java注释详解
- 数字化时代,CDMP/CDGA认证企业个人都需要
- 黄鼠狼目标检测数据集VOC+YOLO格式400张
- shopee利润怎么算?看妙手ERP如何帮您精准掌握店铺利润明细!
- 一键迁移数据库python脚本