毕业设计:python小说推荐系统+协同过滤算法+Django框架(附源码+文档)?
发布时间:2024年01月10日
博主介绍:?全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业毕业设计项目实战6年之久,选择我们就是选择放心、选择安心毕业?感兴趣的可以先收藏起来,点赞、关注不迷路?
毕业设计:2023-2024年计算机毕业设计1000套(建议收藏)
毕业设计:2023-2024年最新最全计算机专业毕业设计选题汇总
1、项目介绍
Django框架、双推荐算法(基于用户+基于物品)、书架、评论收藏、小说阅读、MySQL数据库、后台管理
系统的推荐功能主要通过双推荐算法实现。基于用户的推荐算法根据用户的历史阅读行为和偏好,推荐与其相似的用户喜欢的小说。基于物品的推荐算法则根据小说的内容、标签等信息,推荐与用户喜好相符的小说。
2、项目界面
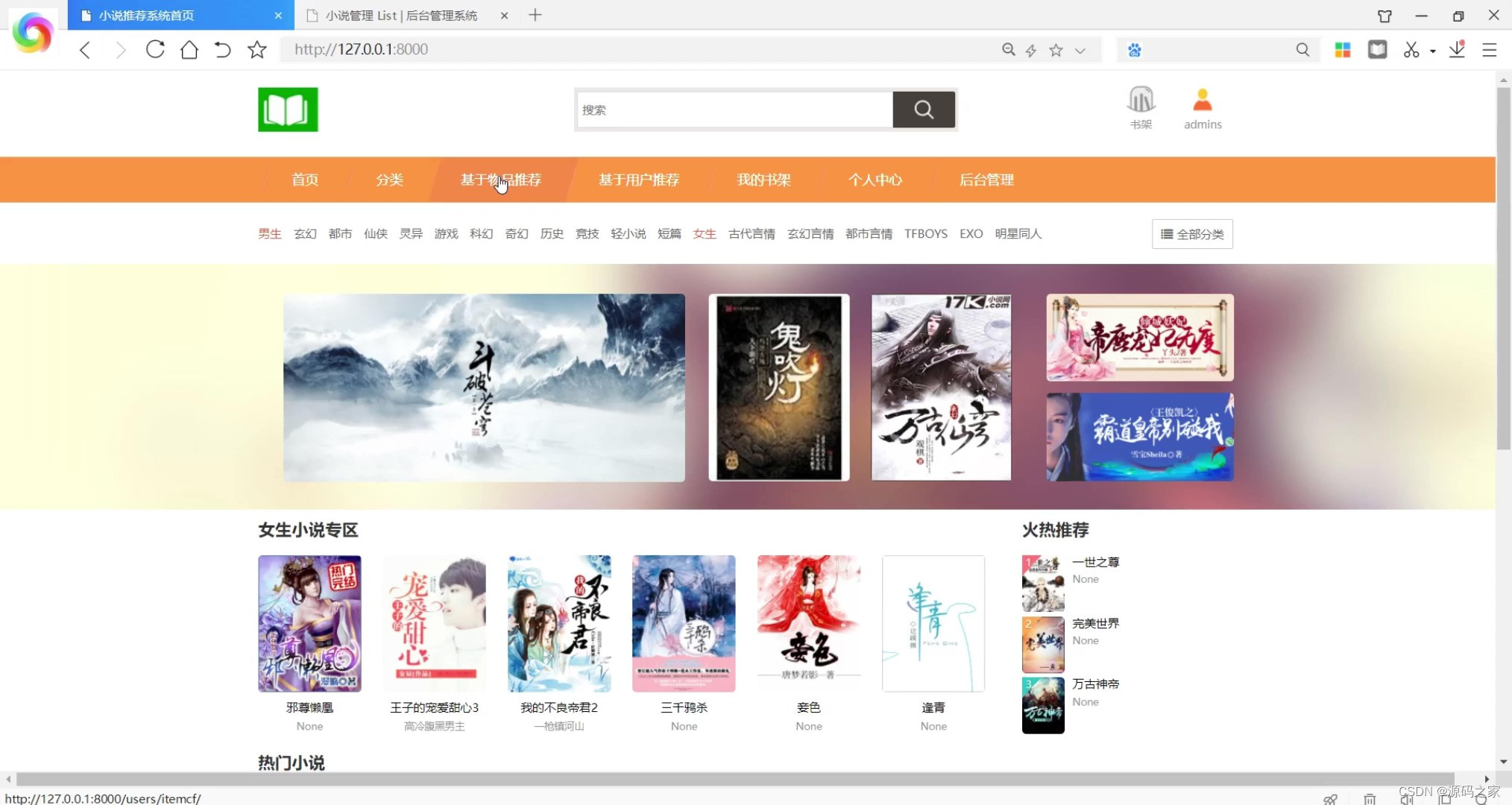
(1)系统首页
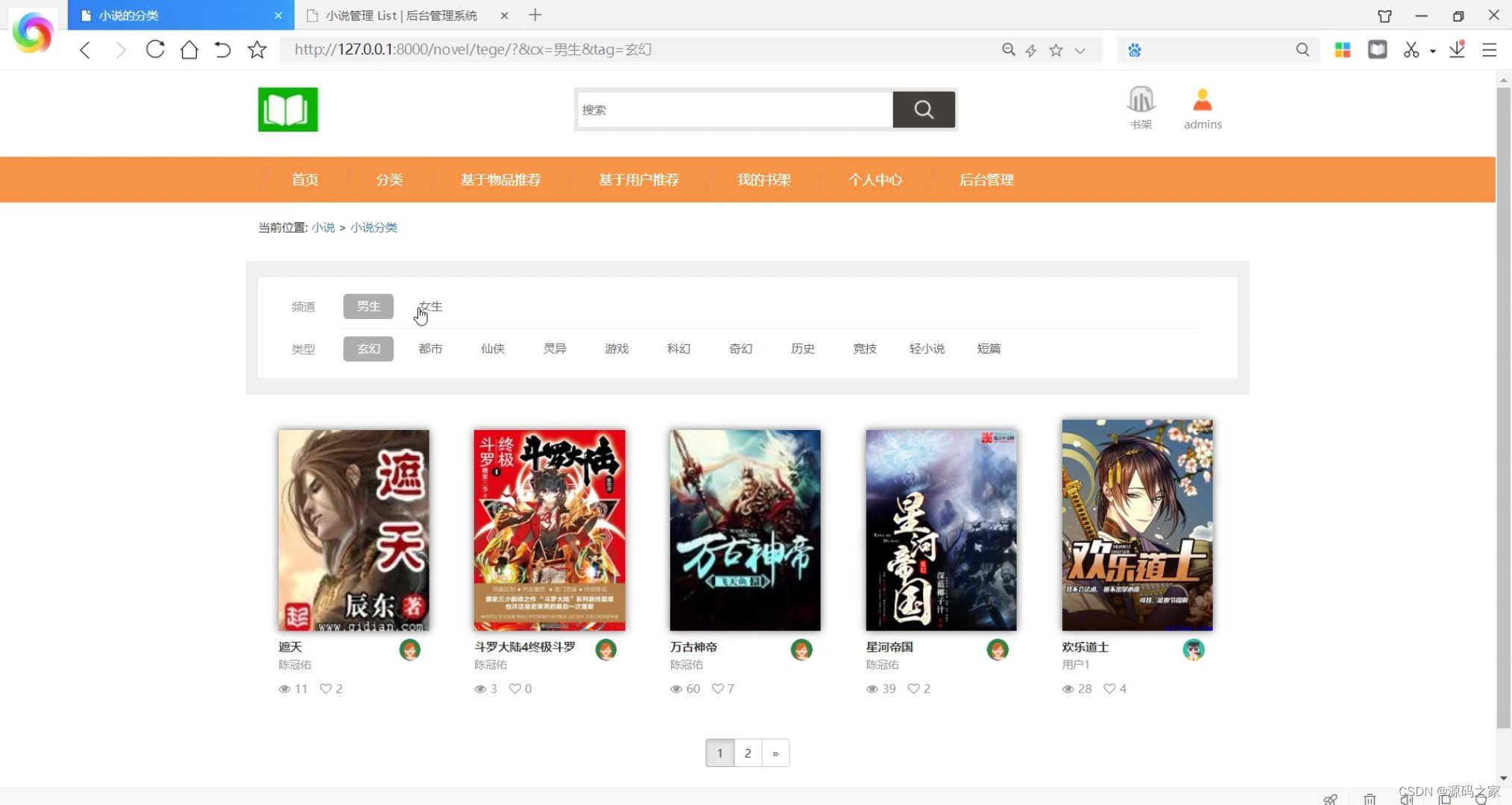
(2)小说分类浏览
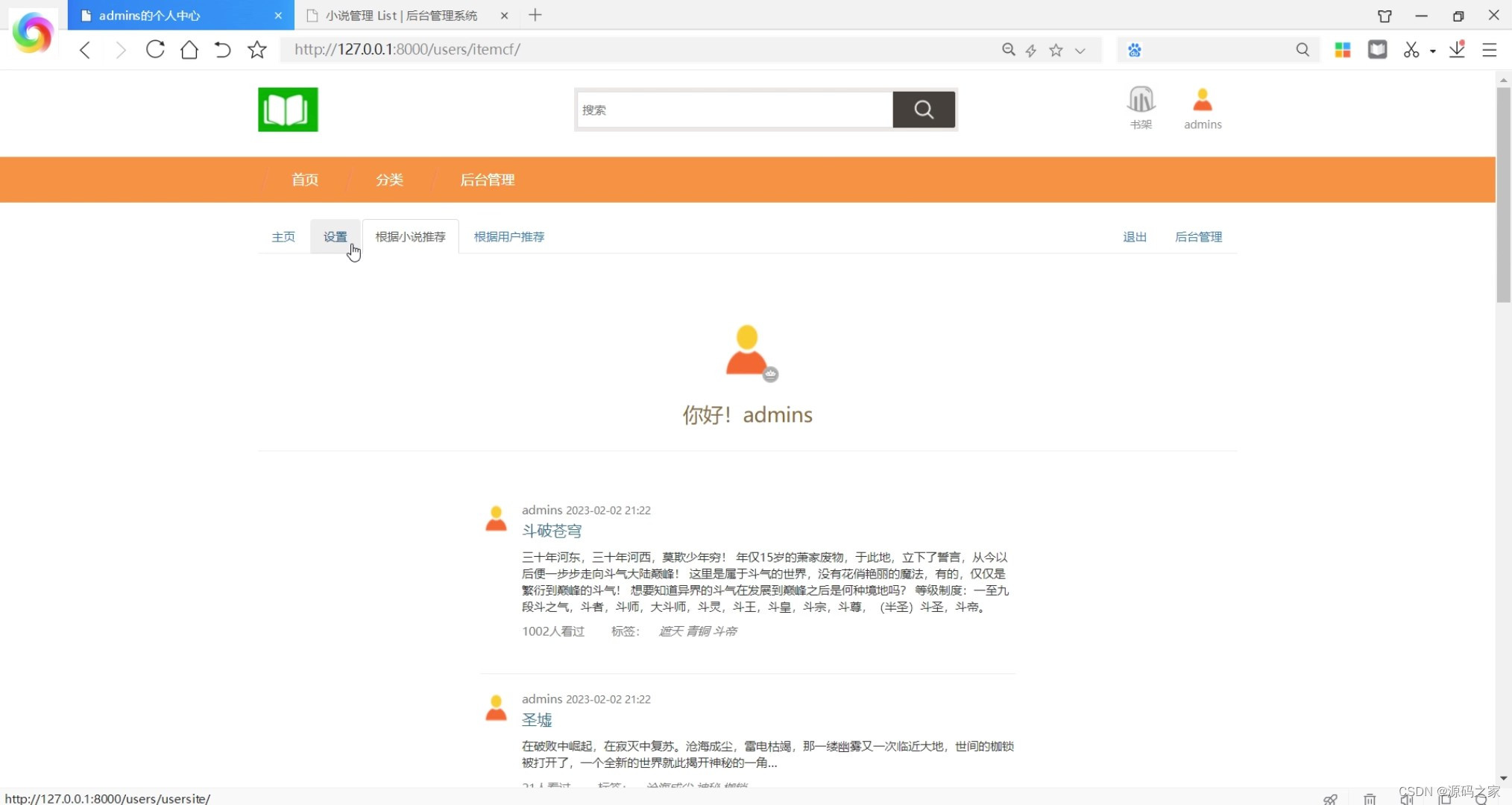
(3)根据小说推荐
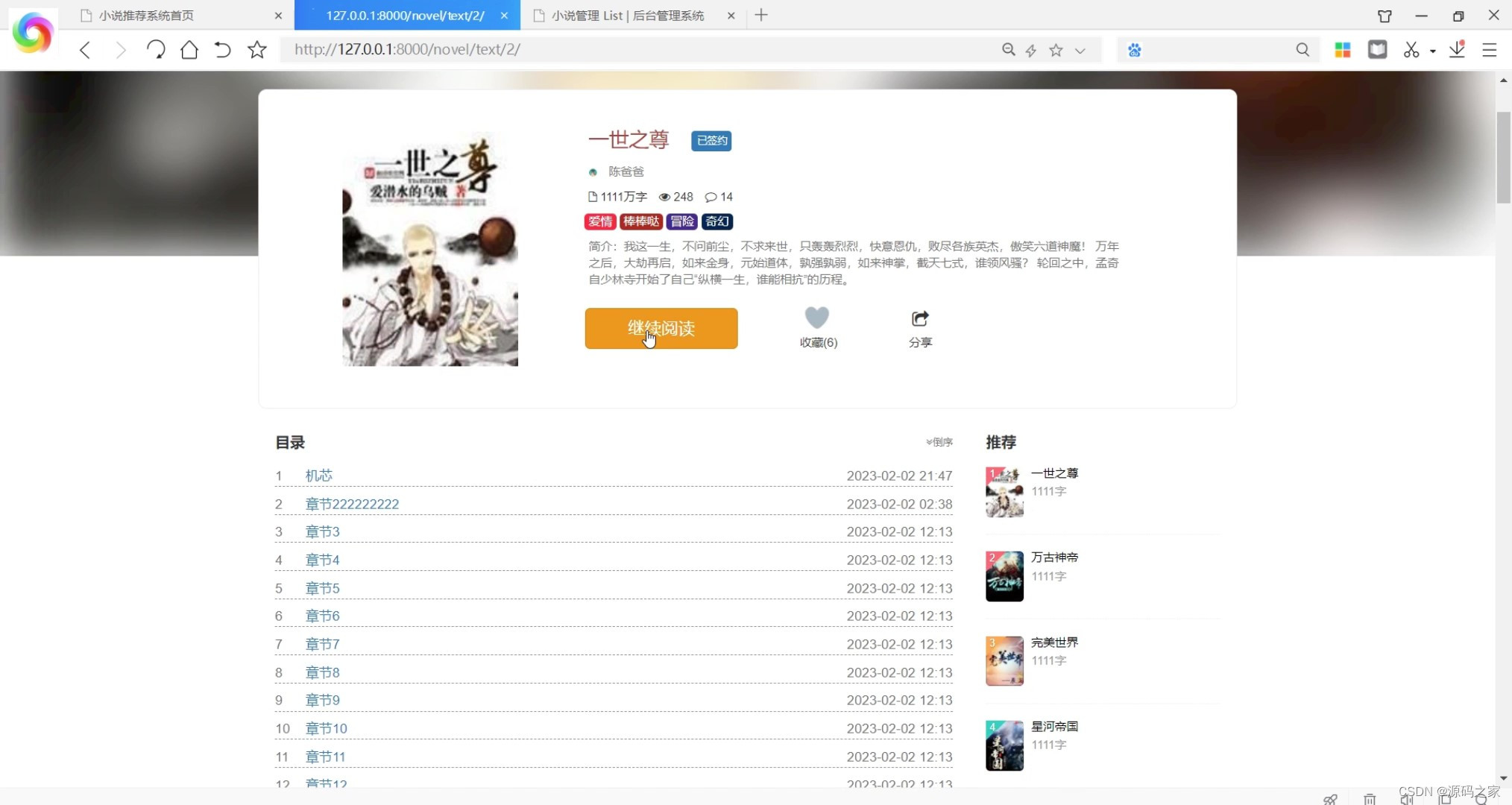
(4)小说数据详情
(5)小说浏览阅读
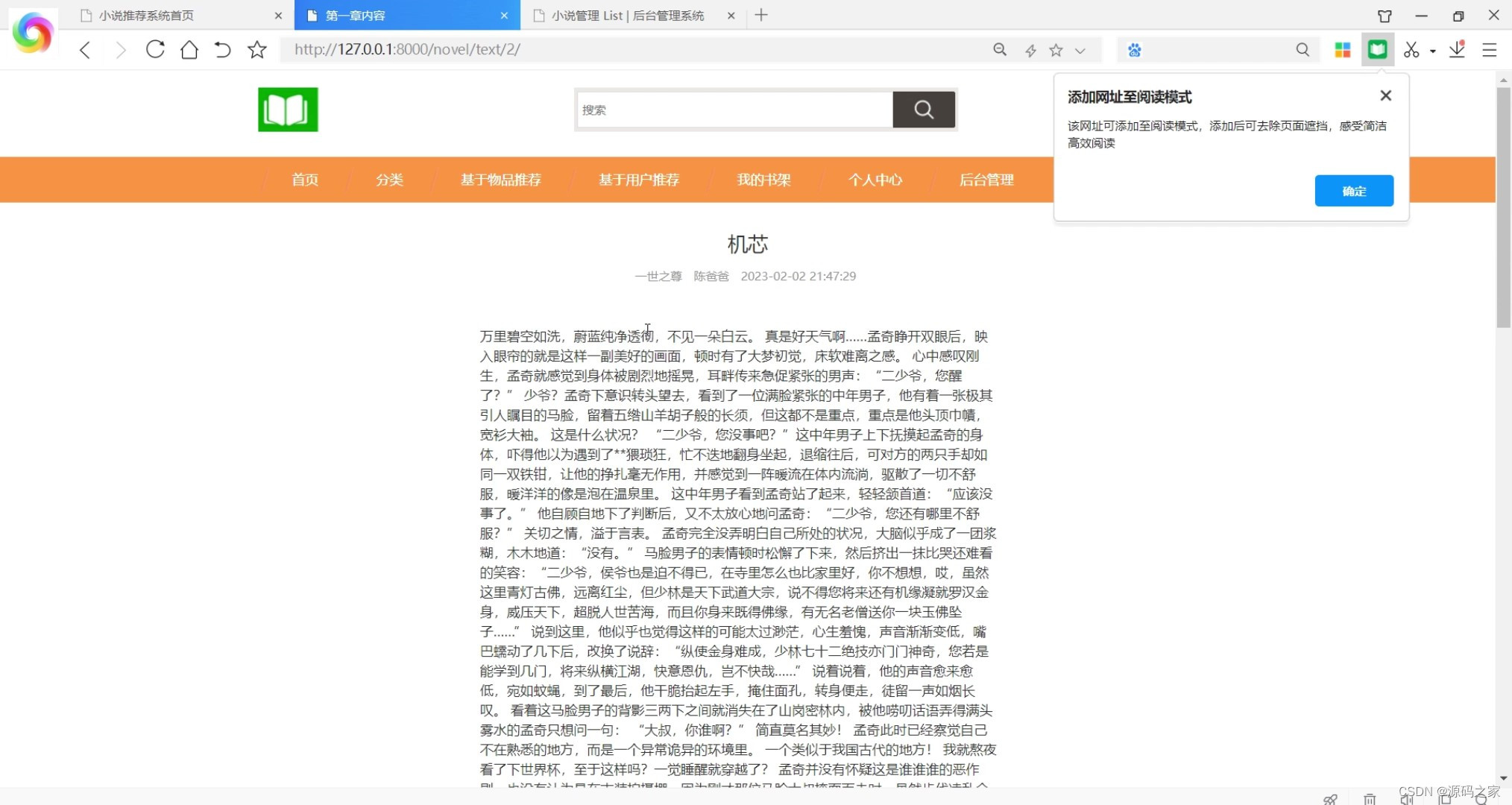
(6)阅读记录
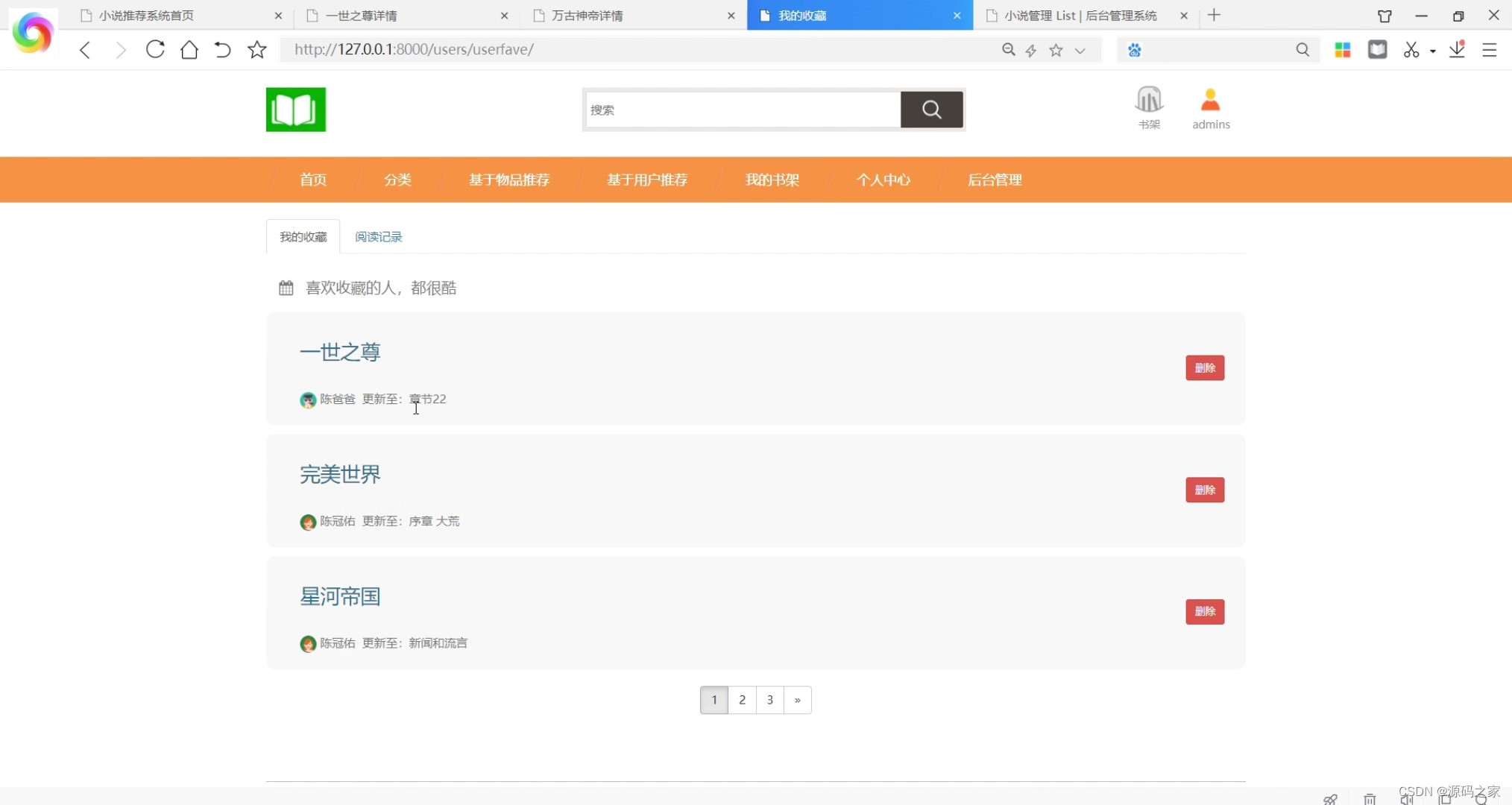
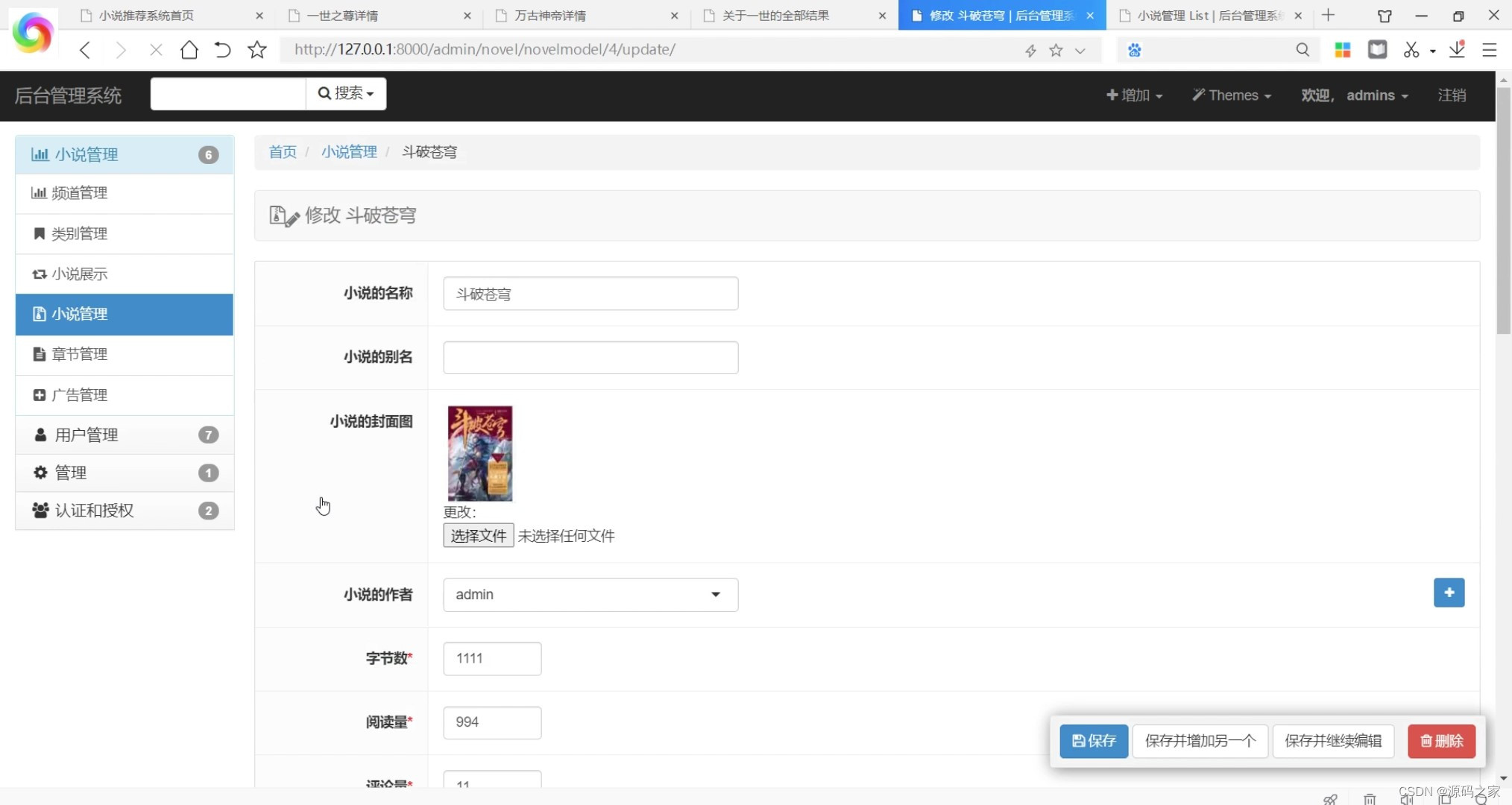
(7)后台数据管理
3、项目说明
小说推荐系统是基于Django框架开发的一个应用,它利用双推荐算法(基于用户和基于物品)来为用户推荐适合他们阅读的小说。
该系统具有以下主要功能:
- 书架:用户可以将自己喜欢的小说添加到书架中,方便随时阅读。
- 评论收藏:用户可以对阅读过的小说进行评论,并将喜欢的评论收藏起来。
- 小说阅读:用户可以在线阅读小说,并根据个人喜好自定义阅读界面。
- MySQL数据库:系统使用MySQL数据库来存储用户的书架、评论、收藏等信息。
- 后台管理:管理员可以通过后台管理界面对用户、小说等进行管理和维护。
系统的推荐功能主要通过双推荐算法实现。基于用户的推荐算法根据用户的历史阅读行为和偏好,推荐与其相似的用户喜欢的小说。基于物品的推荐算法则根据小说的内容、标签等信息,推荐与用户喜好相符的小说。
通过这些功能和算法,小说推荐系统可以为用户提供个性化的阅读推荐,提高用户的阅读体验和满意度。
4、核心代码
#!/usr/bin/env python
#-*-coding:utf-8-*-
import math
import pdb
#基于小说物品推荐
class ItemBasedCF:
def __init__(self):
self.readData()
# print(self.train)
def readData(self):
from connect_mysql import ConnectMysql# root 后面 修改自己的密码
con = ConnectMysql('localhost', 3306, 'root', '123456', 'novel_recommend')
# 查询
# 收藏
sql = 'SELECT * FROM Collections;'
shoucang = con.query(sql, None)
# 阅读
sql = 'SELECT * FROM ReadNovel;'
read = con.query(sql, None)
# 评论CommentModels
sql = 'SELECT * FROM CommentModels;'
comment = con.query(sql, None)
##############################
# 开始统计用户评分id表
# 收藏5 阅读 3 评论(1多个) 比例
# 统计用户id
user_item = {}
for i in shoucang: # 3 2
if str(i[3]) not in user_item.keys():
user_item[str(i[3])] = {}
user_item[str(i[3])][str(i[2])] = 5
else:
user_item[str(i[3])][str(i[2])] = user_item[str(i[3])].get(str(i[2]), 0) + 5
for i in read: # 1 2
if str(i[1]) not in user_item.keys():
user_item[str(i[1])] = {}
user_item[str(i[1])][str(i[2])] = 3
else:
user_item[str(i[1])][str(i[2])] = user_item[str(i[1])].get(str(i[2]), 0) + 3
for i in comment:
if str(i[1]) not in user_item.keys():
user_item[str(i[1])] = {}
user_item[str(i[1])][str(i[2])] = 1
else:
user_item[str(i[1])][str(i[2])] = user_item[str(i[1])].get(str(i[2]), 0) + 1
self.train = user_item
def ItemSimilarity(self):
#建立物品-物品的共现矩阵
cooccur = dict() #物品-物品的共现矩阵
buy = dict() #物品被多少个不同用户购买N
for user,items in self.train.items():
for i in items.keys():
buy.setdefault(i,0)
buy[i] += 1
cooccur.setdefault(i,{})
for j in items.keys():
if i == j : continue
cooccur[i].setdefault(j,0)
cooccur[i][j] += 1
#计算相似度矩阵
self.similar = dict()
for i,related_items in cooccur.items():
self.similar.setdefault(i,{})
for j,cij in related_items.items():
self.similar[i][j] = cij / (math.sqrt(buy[i] * buy[j]))
return self.similar
#给用户user推荐,前K个相关用户,前N个物品
def Recommend(self,user,K=10,N=10):
rank = dict()
action_item = self.train[user]
#用户user产生过行为的item和评分
for item,score in action_item.items():
sortedItems = sorted(self.similar[item].items(),key=lambda x:x[1],reverse=True)[0:K]
for j,wj in sortedItems:
if j in action_item.keys():
continue
rank.setdefault(j,0)
rank[j] += score * wj
return dict(sorted(rank.items(),key=lambda x:x[1],reverse=True)[0:N])
#声明一个ItemBasedCF的对象
# item = ItemBasedCF()
# item.ItemSimilarity()
# recommedDict = item.Recommend("3")#参数为用户id
# for k,v in recommedDict.items():
# print(k,"\t",v)
🍅?感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅?
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻
文章来源:https://blog.csdn.net/2201_75772776/article/details/135488957
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- K8S 存储卷
- Java 基础学习(十四)Map集合与Set集合
- 自动化Web页面性能测试介绍
- Linux中使用Curl命令发送HTTP请求的示例——轻松玩转网络
- CMake+QT+大漠插件的桌面应用开发(QThread)
- 3元一平方公里的在线卫星影像
- MybatisPlus之常用插件的使用
- JavaScript中的浏览器环境和规格
- 风二西CTF流量题大集合-刷题笔记|NSSCTF流量题(2)
- henauOJ 1102: 词组缩写