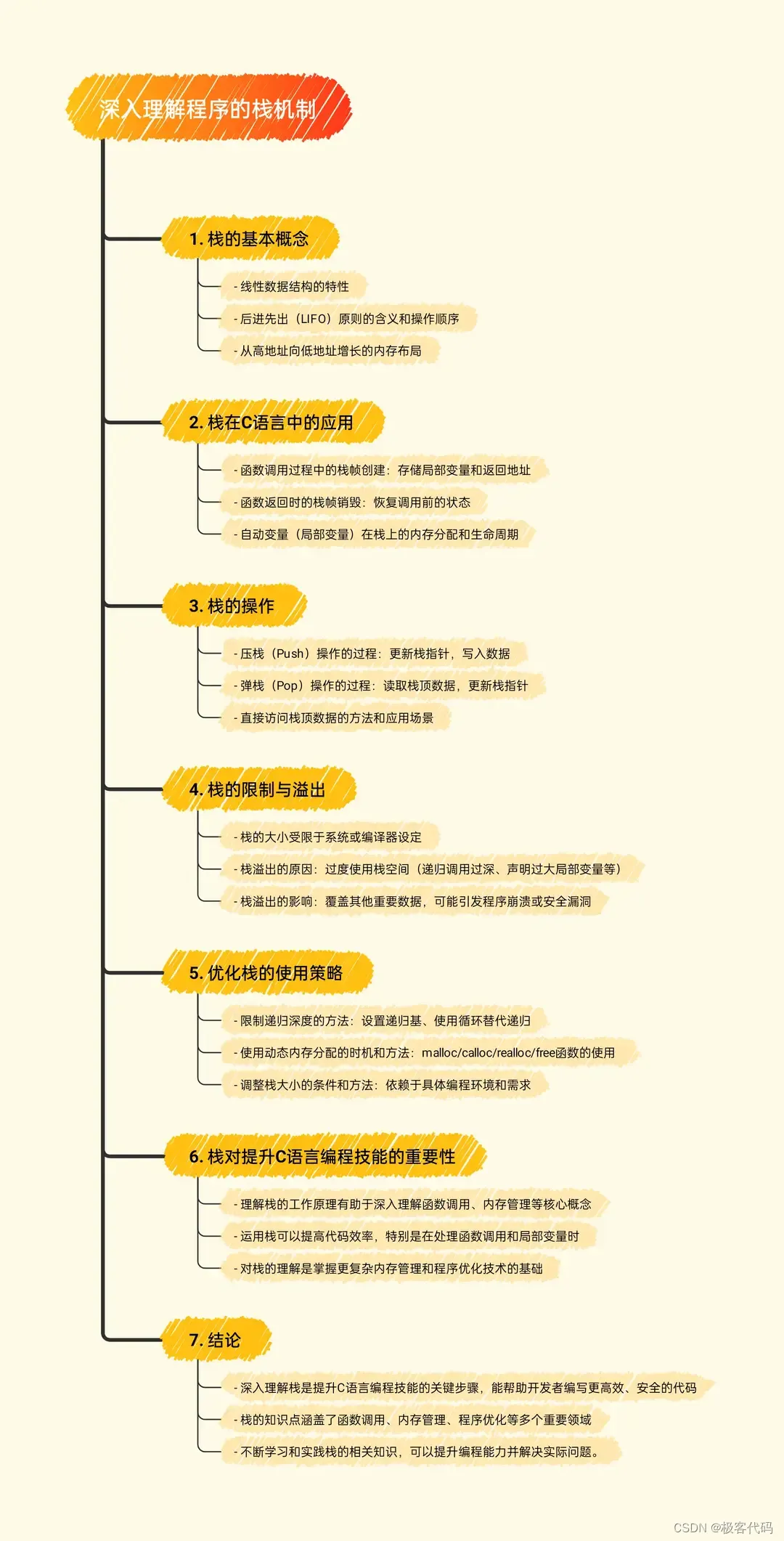
深入理解C语言程序的栈机制
?
一、引言
在计算机科学中,内存管理是一个至关重要的领域。其中,栈作为一种基础且关键的数据结构,对于理解和优化程序性能具有重大意义。特别是在C语言编程中,栈的使用无处不在,从函数调用到变量存储,都离不开栈的支撑。
二、栈的基本概念
栈是一种线性数据结构,其操作遵循后进先出(LIFO)原则。这意味着最后添加到栈中的元素将是第一个被移除的元素。在计算机内存中,栈通常从高地址向低地址增长。
三、栈在C语言中的应用
1.?函数调用:每当一个函数被调用时,一个新的栈帧会在栈顶创建。这个栈帧包含了函数的所有局部变量以及返回地址。当函数执行完毕后,其栈帧会被弹出栈,返回到调用它的函数。
2. 变量存储:自动变量(也称为局部变量)通常在栈上分配空间。这是因为栈的内存分配和回收速度快,适合存储生命周期短的变量。
四、栈的操作
1. 压栈(Push):将数据添加到栈顶。这通常涉及到将栈指针向下移动,并将数据写入新的栈顶位置。
2. 弹栈(Pop):从栈顶移除数据。这通常涉及到读取栈顶数据,然后将栈指针向上移动。
3. 栈顶访问:可以直接访问栈顶的数据,无需进行压栈或弹栈操作。
五、栈的限制与溢出
虽然栈在内存管理中具有高效性和便利性,但其大小是有限的。如果程序过度使用栈空间,例如递归调用过深或者声明过大的局部变量,就可能导致栈溢出。栈溢出可能会覆盖其他重要数据,甚至引发安全漏洞。
六、优化栈的使用
为了避免栈溢出,开发者可以采取以下策略:
1. 限制递归深度:通过设置递归基或者使用循环替代递归,可以控制栈的使用。
2. 使用动态内存分配:对于需要大量内存的变量,可以考虑在堆上分配空间,而不是在栈上。
3. 适当调整栈大小:在某些环境中,开发者可以调整栈的大小以适应特定的程序需求。
七、结论
理解并熟练运用栈是提升C语言编程技能的关键步骤。通过对栈的工作原理、应用、操作以及限制的深入探讨,我们可以更好地设计和优化我们的程序,提高代码的效率和安全性。同时,对栈的理解也有助于我们掌握
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- TF坐标变换实操
- CSS 实现无缝滚动
- 在公网服务器搭建CobaltStrike
- 23111 网络编程 day2
- go 切片长度与容量的区别
- 干货:3分钟告诉你,集团公司如何用低代码构建信息化系统?
- 【Proteus仿真】【Arduino单片机】水质监测报警系统设计
- ChatGPT:人工智能划时代的标志(文末送书)
- C Primer Plus(第六版)12.9 编程练习 第8题
- 源码编译安装、rsync命令、远程同步实现、inotify+rsync实时同步