用C语言实现哈希表HashMap
发布时间:2024年01月14日
1. 功能说明
- 自定义初始容量和负载因子;
- 当键值对的个数与容量比值超过负载因子时,自动扩容;
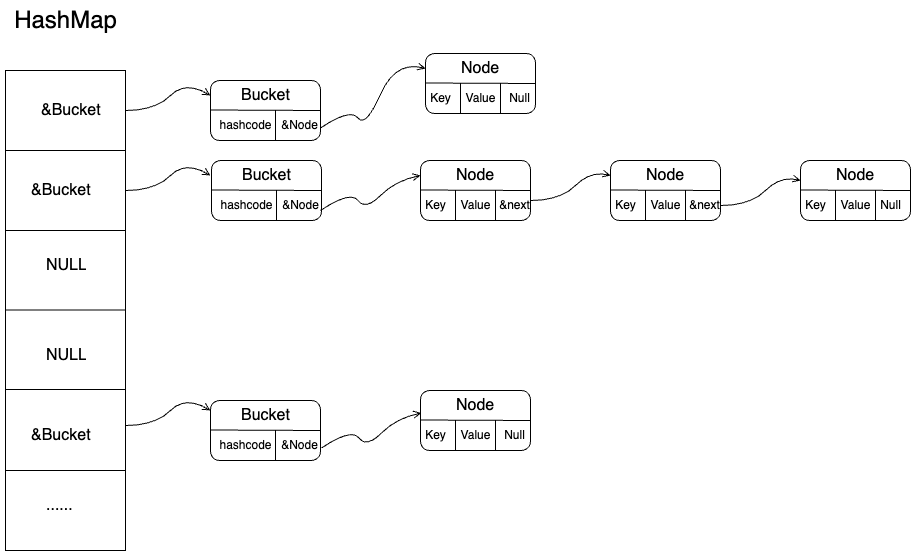
- 借鉴Java8的HashMap部分扩容逻辑,定义了单独的桶结构体用于记录hash值,以及2倍扩容,减少了hash运算和移位的开销。
2. 实现原理
采用动态数组加链表的方式实现(之后撸完红黑树,增加动态数组+链表+红黑树的版本)。
3. 定义头文件
#ifndef HASH_MAP_H
#define HASH_MAP_H
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
#include <string.h>
#include <time.h>
// 默认桶的个数(动态数组默认大小)
#define DEFAULT_CAPACITY 8
// 默认负载因子
#define DEFAULT_LOAD_FACTOR 0.75
typedef char* K;
typedef char* V;
// 定义hashmap的链表结点
typedef struct map_node {
K key; // 键
V value; // 值
struct map_node *next; // 下一个结点
} MapNode;
// 定义hashmap的桶结点
typedef struct {
MapNode *head; // 桶中链表的第一个节点
uint32_t hash_code; // 桶中键值对hash值
} Bucket;
// 定义hashmap结构体
typedef struct {
Bucket **buckets; // 存键值对的桶(动态的Bucket指针数组)
int size; // map中键值对个数
int capacity; // map的容量
double load_factor; // map的负载因子
uint32_t hash_seed; // hash函数的种子
} HashMap;
// 创建HashMap(容量和负载因子填NULL则使用默认值)
HashMap* create_hashmap(const void* capacity_p, const void* load_factor_p);
// 销毁HashMap
void destroy_hashmap(HashMap *map);
// ---------------- 基本操作 ----------------
// 存入键值对
V put(HashMap *map, K key, V val);
// 查询键值对
V get(const HashMap *map, K key);
// 删除键值对
bool map_remove(HashMap *map, K key);
// 键key在表中是否有对应的值
bool contains(const HashMap *map, K key);
// 判断表是否为空
bool is_empty(const HashMap *map);
// ---------------- 其他操作 ----------------
// 是否需要扩容
static bool is_need_resize(const HashMap *map);
// 扩容
static void resize(HashMap *map);
// murmur_hash2 哈希函数
static uint32_t hash(const void* key, int len, uint32_t seed);
#endif
4. 具体实现
1. 创建HashMap
需要注意buckets是动态数组,需要手动初始化,并且calloc(capacity, sizeof(Bucket*)注意是Bucket* ,写成Bucket也不会报错,但是会造成更耗内存!
// 创建HashMap(容量和负载因子填NULL则使用默认值)
HashMap* create_hashmap(const void* capacity_p, const void* load_factor_p) {
// 1. 创建hashmap
HashMap *map = calloc (1, sizeof(HashMap));
if (map == NULL) {
puts("error:create_hashmap()内分配内存失败");
return NULL;
}
//2. 初始化Bucket动态数组
int capacity = capacity_p == NULL ? DEFAULT_CAPACITY : *(int*)capacity_p;
Bucket **buckets = calloc(capacity, sizeof(Bucket*));
if (map == NULL) {
puts("error:create_hashmap()内分配内存失败");
free(map);
return NULL;
}
map->buckets = buckets;
// 3. 初始化hashmap的其他属性
map->capacity = capacity;
double load_factor = load_factor_p == NULL ? DEFAULT_LOAD_FACTOR : *(double*)load_factor_p;
map->load_factor = load_factor;
map->hash_seed = time(NULL);
return map;
}
2. 销毁HashMap
要注意销毁桶,避免造成内存泄漏!
void destroy_hashmap(HashMap *map) {
if (map == NULL) {
puts("error:destroy_hashmap()的参数map为NULL");
exit(-1);
}
// 1. 销毁链表结点
for (int i = 0; i < map->capacity; i++) {
Bucket *cur_bucket = map->buckets[i];
if (cur_bucket != NULL) {
MapNode *cur = cur_bucket->head;
while(cur != NULL) {
MapNode *temp = cur->next;
free(cur);
cur = temp;
}
// 2. 销毁桶
free(cur_bucket);
}
}
// 3. 销毁map
free(map);
}
3. 存入键值对
在存入时,可以先判断一下key值在桶中是否存在,然后再进行扩容,这样对与重复键值对的存储速度有一定的提升。
V put(HashMap *map, K key, V val) {
if (map == NULL) {
puts("error:put()的参数map为NULL");
exit(-1);
}
// 1. 计算key的hash值以及桶的位置idx
uint32_t hash_code = hash(key, strlen(key), map->hash_seed);
int idx = hash_code % map->capacity;
// 2. 判断idx位置的桶是否存在
if (map->buckets[idx] != NULL) {
// 2-1. idx位置的桶已存在,则判断idx桶中是否存在key值
MapNode *cur = map->buckets[idx]->head;
while (cur != NULL) {
if (strcmp(cur->key, key) == 0) {
// 2-1-1. 若idx桶中已存在key值则更新value值,并返回旧value值
V old_val = cur->value;
cur->value = val;
return old_val;
}
cur = cur->next;
}
}
// 3. 判断是否需要扩容
if (is_need_resize(map)) {
// 3-1. 若需扩容,则扩容,并重新计算key的hash值和桶位置idx
resize(map);
hash_code = hash(key, strlen(key), map->hash_seed);
idx = hash_code % map->capacity;
}
// 4. 重新判断idx位置的桶是否存在(在‘2.’虽然判断了一次,但有可能新的idx位置桶还未创建过
if (map->buckets[idx] == NULL) {
// 4-1. idx位置的桶不存在,则在idx位置创建桶,并在桶中存入hash值
Bucket *bucket = calloc(1, sizeof(Bucket));
if (bucket == NULL) {
puts("error:put()内分配内存失败");
exit(-1);
}
bucket->hash_code = hash_code;
map->buckets[idx] = bucket;
}
// 5. 在桶中插入这键值对(用头插 O(1))
MapNode *new_node = calloc(1, sizeof(MapNode));
if (new_node == NULL) {
puts("error:put()内分配内存失败");
exit(-1);
}
new_node->key = key;
new_node->value = val;
new_node->next = map->buckets[idx]->head;
map->buckets[idx]->head = new_node;
// 6. 更新size
map->size++;
return NULL;
}
4. 查询键值对
注意要对桶进行判空,不能直接map->buckets[idx]->head。
V get(const HashMap *map, K key) {
if (map == NULL) {
puts("error:get()的参数map为NULL");
exit(-1);
}
// 1. 计算key的hash值应存放的桶的位置idx
int idx = hash(key, strlen(key), map->hash_seed) % map->capacity;
// 2. 在idx位置的桶中搜索对应key值
if (map->buckets[idx] != NULL) { // 先判断桶是否为空
MapNode *cur = map->buckets[idx]->head;
while(cur != NULL) {
if (strcmp(cur->key, key) == 0) {
return cur->value;
}
cur = cur->next;
}
}
return NULL;
}
5. 删除键值对
注意删除的结点是否是第一个节点,要分情况处理。
bool map_remove(HashMap *map, K key) {
if (map == NULL) {
puts("error:map_remove()的参数map为NULL");
exit(-1);
}
// 1. 计算key的hash值应存放的桶的位置idx
int idx = hash(key, strlen(key), map->hash_seed) % map->capacity;
// 2. 在idx位置的桶中搜索对应key值
if (map->buckets[idx] != NULL) { // 先判断桶是否为空
MapNode *pre = NULL;
MapNode *cur = map->buckets[idx]->head;
while(cur != NULL) {
if (strcmp(cur->key, key) == 0) {
// 3. 删除结点
if (pre == NULL) { // 删除的是第一个结点
map->buckets[idx]->head = cur->next;
}else {
pre->next = cur->next;
}
// 4. 释放内存
free(cur);
// 5. 更新size
map->size--;
return true;
}
pre = cur;
cur = cur->next;
}
}
return false;
}
6. 扩容
注意扩容机制是采用每次库容2倍,这样每次新下标就是old_idx或者为old_idx+(new_cap-old_cap),不让会出现多个旧桶在新数组里下标冲突被覆盖抹除的问题!!!
static void resize(HashMap *map) {
// 1. 创建新的桶数组
int old_cap = map->capacity;
// 每次扩容2倍,好处是,每次新下标就是old_idx或者为old_idx+(new_cap-old_cap)!!!(详见Java8hashmap扩容)
int new_cap = old_cap << 1;
Bucket **new_buckets = calloc(new_cap, sizeof(Bucket*));
// 2. 挪动旧桶中的数据到新桶中
Bucket **old_buckets = map->buckets;
for (int idx = 0; idx < old_cap; idx++) {
Bucket *cur = old_buckets[idx];
if (cur != NULL) { // 只操作非空桶
// 2-1. 计算新的位置idx
int new_idx = cur->hash_code % new_cap;
// 2-2. 挪动桶
new_buckets[new_idx] = old_buckets[idx];
}
}
// 3. 将新桶交给hashmap
map->buckets = new_buckets;
// 4. 更新hashmap的容量
map->capacity = new_cap;
// 5. 将就旧桶销毁
free(old_buckets);
}
7. 其他函数
剩下的几个函数简单不易出错,此处不再赘述,其中hash函数使用的开源的murmur_hush2详见开头处github代码仓库。
文章来源:https://blog.csdn.net/weixin_44398687/article/details/135586561
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!