2.4 DEVICE GLOBAL MEMORY AND DATA TRANSFER
在当前的CUDA系统中,设备通常是带有自己的动态随机存取存储器(DRAM)的硬件卡。例如,NVIDIA GTX1080具有高达8 GB的DRAM,称为全局内存。我们将互换使用全局内存和设备内存这两个术语。为了在设备上执行内核,程序员需要在设备上分配全局内存,并将相关数据从主机内存传输到分配的设备内存。这与图2.6第1部分相对应。同样,在设备执行后,程序员需要将结果数据从设备内存传输回主机内存,并释放不再需要的设备内存。这与图2.6.第3部分相对应。CUDA运行时系统提供API功能,以代表程序员执行这些活动。从现在开始,我们将简单地说一段数据从主机传输到设备,作为将数据从主机内存复制到设备内存的简写。相反的方向也是如此。
有一种趋势是将CPU和GPU的地址空间集成到统一的内存空间中(第20章)。有新的编程框架,如GMAC,可以利用统一的内存空间并消除数据复制成本。
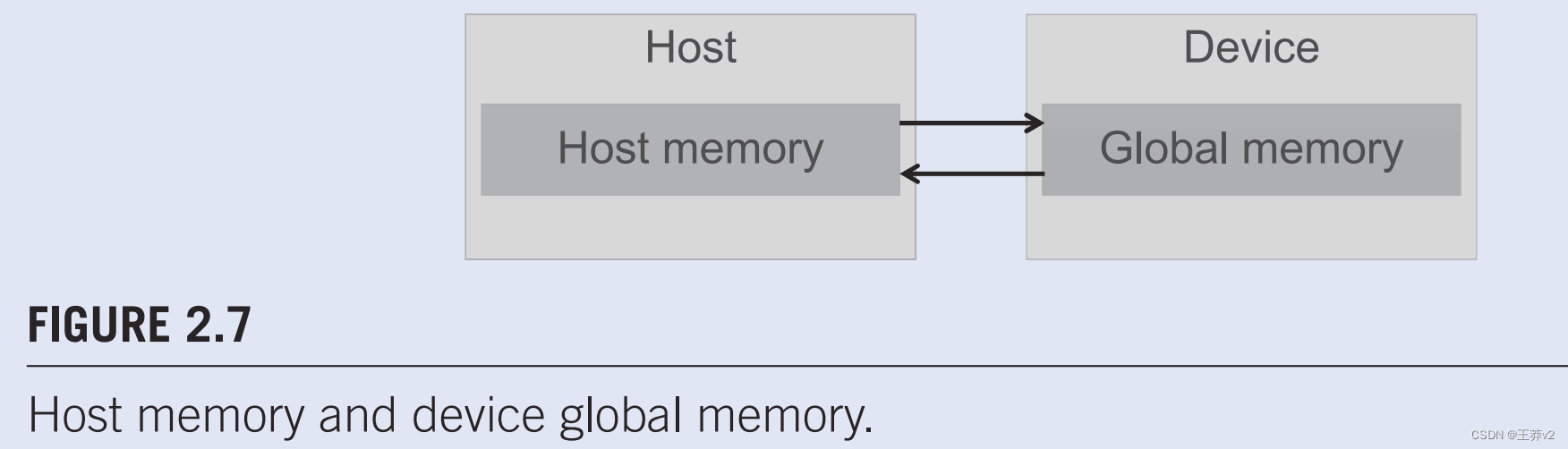
图2.7显示了CUDA主机内存和设备内存模型的高级图片,供程序员推理设备内存的分配以及主机和设备之间的数据移动。主机可以访问设备全局内存,以在设备之间传输数据,如图2.7.中这些存储器与主机之间的双向箭头所示。设备内存类型比图2.7.中显示的要多。设备函数可以以只读方式访问常量内存,这将在第7章《并行模式:卷积》中描述。我们还将在第4章“内存和数据局部性”中讨论寄存器和共享内存的使用。感兴趣的读者还可以查看CUDA编程guide,了解纹理内存的功能。目前,我们将专注于全局内存的使用。
内置变量
许多编程语言都有内置变量。这些变量具有特殊的含义和目的。这些变量的值通常由运行时系统预先初始化,在程序中通常是只读的。程序员应避免将这些变量用于任何其他目的。
在图2.6中,vecAdd函数的第1部分和第3部分需要使用CUDA API函数为A、B和C分配设备内存,将A和B从主机内存传输到设备内存,在矢量添加结束时将C从设备内存传输到主机内存,并为A、B和C释放设备内存。我们将首先解释内存分配和自由函数。
图2.8显示了用于分配和释放设备全局内存的两个API功能。可以从主机代码调用cudaMalloc函数,为对象分配一块设备全局内存。读者应该注意到cudaMalloc和标准C运行时库malloc函数之间的惊人相似性。这是故意的;CUDA是最小扩展的C。CUDA使用标准C运行时库malloc函数来管理主机内存,并添加cudaMalloc作为C运行时库的扩展。通过使接口尽可能靠近原始C运行时库,CUDA最大限度地减少了C程序员重新学习使用这些扩展所花费的时间。

cudaMalloc函数的第一个参数是指针变量的地址,该变量将被设置为指向分配的对象。指针变量的地址应转换为(void **),因为该函数需要一个通用指针;内存分配函数是一个通用函数,不限于任何特定类型的对象。此参数允许cudaMalloc函数将分配内存的地址写入指针变量。启动内核的主机代码将此指针值传递给需要访问分配的内存对象的内核。cudaMalloc函数的第二个参数给出了要分配的数据大小,以字节数为单位。第二个参数的使用与C malloc函数的大小参数一致。
cudaMalloc返回一个通用对象的事实使动态分配的多维数组的使用更加复杂。我们将在第3.2节中解决这个问题。
请注意,cudaMalloc的格式与C malloc函数不同。C malloc函数返回一个指向分配对象的指针。它只需要一个参数来指定所分配对象的大小。cudaMalloc函数写入指针变量,其地址作为第一个参数。因此,cudaMalloc函数需要两个参数。cudaMalloc的双参数格式允许它以与其他CUDA API函数相同的方式使用返回值来报告任何错误。
我们现在使用一个简单的代码示例来说明cudaMalloc的使用。这是图2.6.中示例的延续。为了清楚起见,我们将用字母“d_”启动一个指针变量,以指示它指向设备内存中的对象。程序在将指针d_A(即&d_A)的地址传递给无效指针后作为第一个参数。也就是说,d_A将指向为A向量分配的设备内存区域。分配区域的大小将是单精度foating数的n倍,在今天的大多数计算机中为4字节。计算后,使用指针d_A作为输入调用cudaFree,以从设备全局内存中释放A向量的存储空间。请注意,cudaFree不需要更改指针变量d_A的内容;它只需使用d_A的值即可将分配的内存输入可用池。因此,只有值,而不是d_A的地址,作为参数传递。

d_A、d_B和d_C中的地址是设备内存中的地址。这些地址不应在计算的主机代码中取消引用。它们应该主要用于调用APl函数和内核函数。取消引用主机代码中的设备内存点可能会导致执行期间异常或其他类型的运行时错误。
读者应完成图2.6中vecAdd示例的第1部分具有d_B和d_C指针变量的类似声明以及相应的cuda-Malloc调用。此外,图2.6中的第3部分。可以通过d_B和d_C的cudaFree调用完成。
一旦主机代码为数据对象分配了设备内存,它就可以请求将数据从主机传输到设备。这是通过调用CUDA API函数之一来实现的。图2.9显示了这样的API函数,cudaMemcpy。cudaMemcpy函数需要四个参数。第一个参数是指向要复制的数据对象的目标位置的指针。第二个参数指向源位置。第三个参数指定要复制的字节数。第四个参数表示副本中涉及的内存类型:**从主机内存到主机内存,从主机内存到设备内存,从设备内存到主机内存,以及从设备内存到设备内存。**例如,内存复制功能可用于将数据从设备内存的一个位置复制到设备内存的另一个位置。
请注意,cudaMemcpy目前不能用于在多GPU系统中的不同GPU之间进行复制。

vecAdd函数调用cudaMemcpy函数,在添加h_A和h_B向量之前将h_A和h_B向量从主机复制到设备,并在添加完成后将h_C向量从设备复制到主机。假设h_A、h_B、d_A、d_B和size的值已经像我们之前讨论的那样设置好了,三个cudaMemcpy调用如下所示。两个符号常量,cudaMemcpyHostToDevice和cudaMemcpyDeviceToHost,是CUDA编程环境的可识别预定义常数。请注意,通过正确排序源指针和目标指针并使用传输类型的适当常量,可以使用相同的功能双向传输数据。

总而言之,图2.5中的主要程序调用vecAdd,它也在主机上执行。vecAdd函数,如图2.6所示,分配设备内存,请求数据传输,并启动执行实际向量加法的内核。**我们经常将这种类型的主机代码称为启动内核的 stub function **。内核完成执行后,vecAdd还会将结果数据从设备复制到主机。我们在图2.10中展示了vecAdd函数的更完整版本。

CUDA中的错误检查和处理
一般来说,程序检查和处理错误非常重要。
CUDA API函数返回标志,指示它们在处理请求时是否发生了错误。大多数错误是由于调用中使用的参数值不恰当。
为了简洁,我们不会在示例中显示错误检查代码。例如,图。2.10显示了对cudaMalloc的呼叫:
cudaMalloc((void **) &d_A, size);
在实践中,我们应该用测试错误条件的代码包围呼叫,并打印出错误消息,以便用户能够意识到发生错误的事实。此类检查代码的简单版本如下:
cudaError_t err=cudaMalloc((void **) &d_A, size);
if (error !=cudaSuccess) {
printf(“%s in %s at line %d\n”, cudaGetErrorString(err),__
FILE__,LINE);
exit(EXIT_FAILURE);
}
这样,如果系统没有设备内存,用户将被告知情况。这可以节省许多小时的调试时间。
可以定义一个C宏,使检查代码在源代码中更加简洁。
与图2.6相比,图2.10中的vecAdd函数第1部分和第3部分完成。第1部分为d_A、d_B和d_C分配设备内存,并将h_A传输到d_A,h_B传输到d_B。这是通过调用cudaMalloc和cudaMemcpy函数来完成的。鼓励读者使用适当的参数值编写自己的函数调用,并将他们的代码与图中显示的代码进行比较。2.10.第2部分调用内核,并将在后续小节中描述。第3部分将总和数据从设备内存复制到主机内存,以便其值在主函数中可用。这是通过调用cudaMemcpy函数来完成的。然后,它从设备内存中释放d_A、d_B和d_C的内存,这是通过调用cudaFree函数完成的。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【数据结构】顺序表
- 【C语言_题库】粗语言—— sum=1/2+2/3+3/5,编写一个C语言程序:求S=1/1+1/2+1/3+…+1/n
- Python能做大项目(8) - Need for Speed! 高效编码之一
- LeetCode 每日一题 Day 20 Hard || Dp
- C //练习 6-2 编写一个程序,用以读入一个C语言程序,并按字母表顺序分组打印变量名,要求每一组内各变量名的前6个字符相同,其余字符不同。字符串和注释中的单词不予考虑。请将6作为一个可在命令行
- 局域网的好哥们——广域网
- JAVA:OFD Reader & Writer 开源库技术解析
- 【菜鸡常见网络问题汇总】之:VLAN接口如何处理报文
- C++ 操作重载与类型转换
- golang实现可中断的流式下载