AI模型训练【偏差/方差】与【欠拟合/过拟合】
在我们拿到一个数据集,高高兴兴准备训练一个模型时,会遇到欠拟合或过拟合的问题,业内也喜欢用偏差和方差这两指标去定义它们,那这些词什么意思呢?有什么方法能避免/解决 欠拟合和过拟合呢?
这其实是非常非常基础的概念,但是其实即使是业内人士很难一下子把它们完全讲明白,并列出全面的解决方法,本文为你最通俗地解答。
欠拟合(Underfit)& 过拟合 (Overfit)
先解释一下模型欠拟合和过拟合。假设大家已经知道训练集,验证集,测试集这个概念,不清楚的童鞋可以去康康我之前的博客哦 《无废话的机器学习笔记》
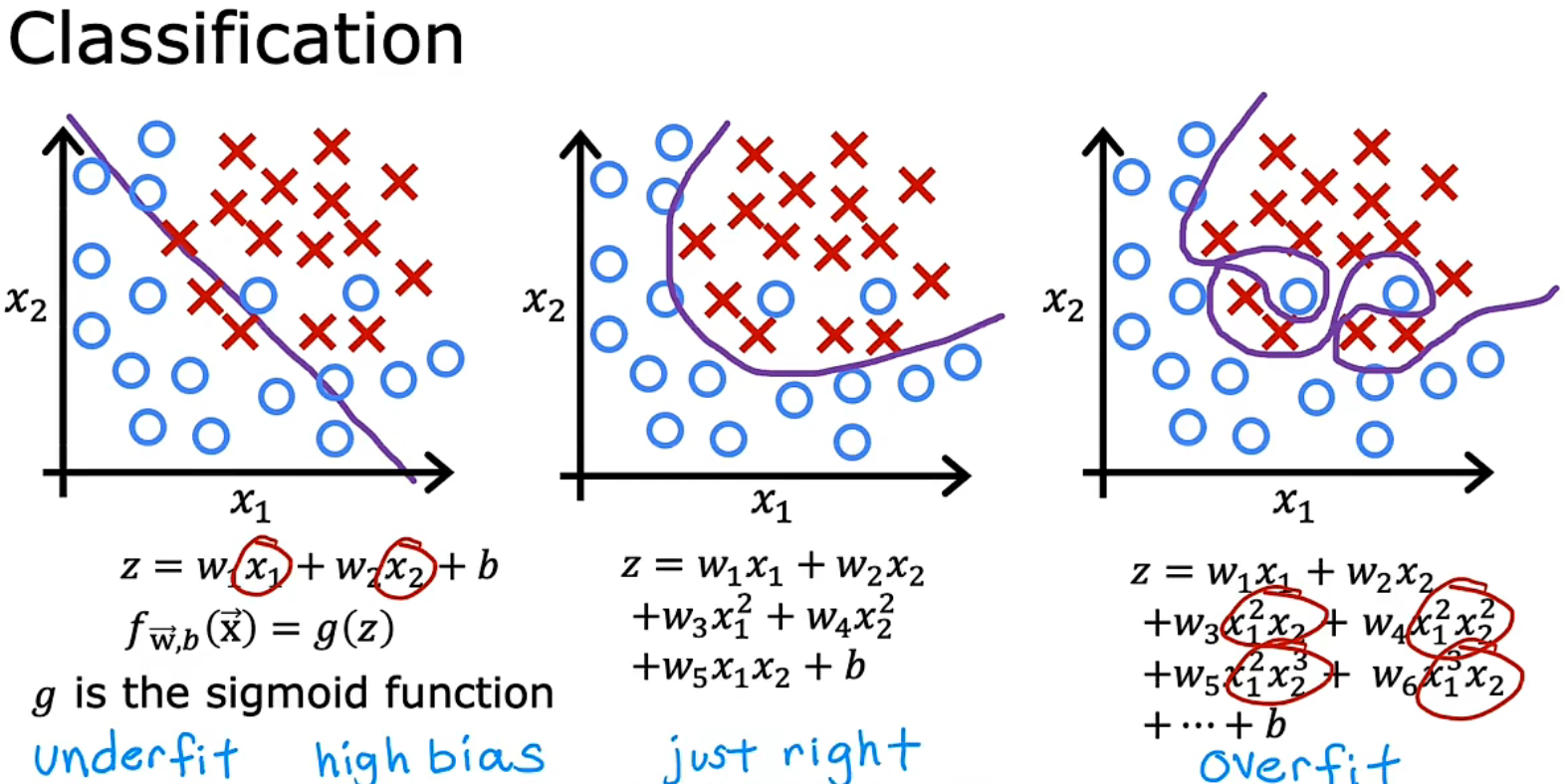
下面两个图(来自吴恩达机器学习课的PPT)解释得其实很清楚。
欠拟合:模型在训练集上没有得到足够好的拟合
过拟合:模型在训练集上得到过分好的拟合。
过分好有什么坏处呢,就比如训练集数据里都是白天的熊猫,模型把白天也作为特征学习了(对训练数据中的每个小细节都进行了学习,包括噪声和异常值),那么给一张黑夜的熊猫图,模型判断这不是熊猫。所以模型在训练集上表现完美,一到测试集就拉胯。(训练集上猛如虎,测试集上很离谱)
下面图的最靠右情况就是过拟合,这时模型往往变得非常复杂(有高次项,如x三次方和四次方)

?
?
偏差(bias)& 方差(variance)
偏差和方差数学里就是描述数据的特征嘛,大家觉得这有什么需要解释的,但机器学习里面,我们不是要求出一堆数据的偏差和方差,而是把它们当作一种指标来衡量模型的性能。
很多教程一上来给出这个图来理解偏差/方差,很直观,但其实这图很容易迷惑初学者,比如这里面的蓝点,到底是模型基于训练集还是验证集的预测,还是都有?如果都有,右下角那个图,落在红心附近的蓝点如果是基于训练集,那么这个模型应该是low bias。如果都是训练集,那么是及说明不了方差的,因为方差是衡量模型在不同集的表现波动,所以有点乱,我自己当时也是理解得模模糊糊。也可能是我理解有误,欢迎大家留言指教。

?
我个人理解它们在机器学习里的含义应该是这样:
偏差:训练集/验证集数据(模型预测)与红心(真实结果)的差距。重点在模型对训练集的损失函数。
(偏差衡量模型的预测结果与真实结果之间的差距,即模型的准确性。高偏差意味着模型的预测结果通常偏离正确值)
方差:模型对训练集与测试集的性能差别。重点在模型对训练集和测试集的损失函数之间的差别。若训练集和测试集的损失函数都很大,也叫低方差。
总的来说,方差衡量模型对于给定数据的小波动的敏感度,即模型在训练集和验证集上的表现波动。
?
下面这图将 欠拟合/过拟合 与 偏差/方差 的关系解释得完美。
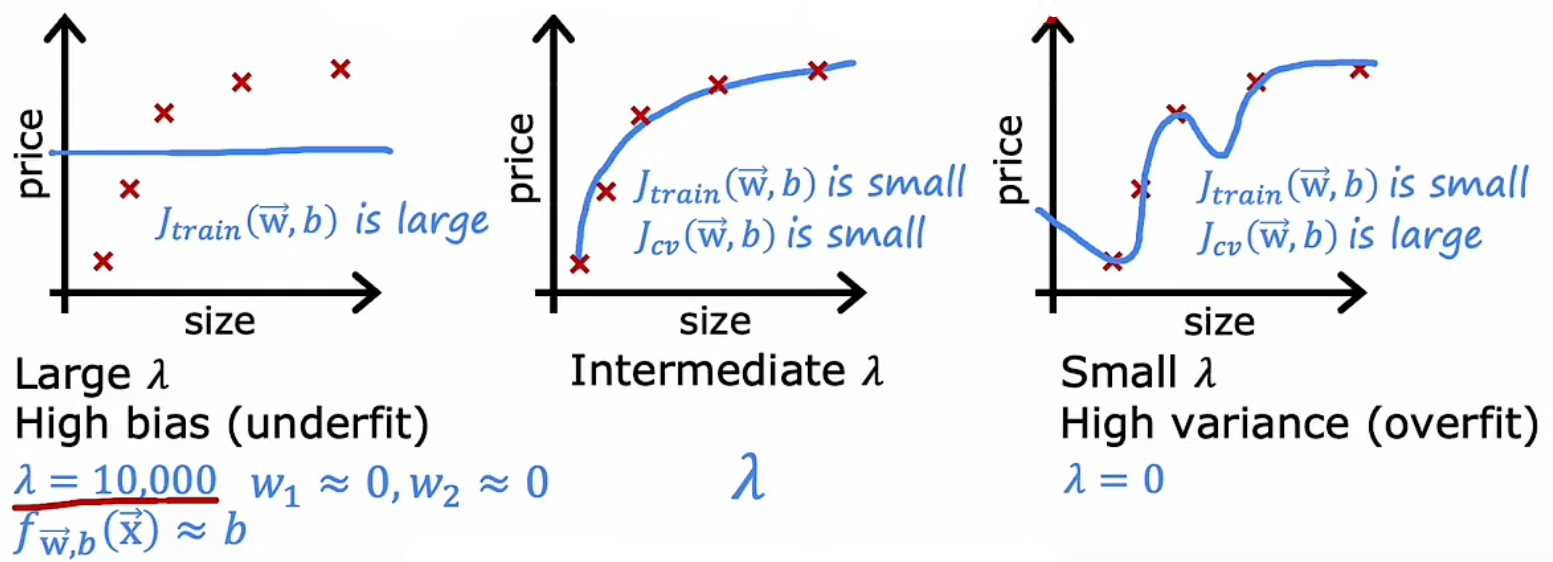
λ是正则化项,它越大模型越被限制,变得越简单。后面会解释。总得来说,
欠拟合时,高偏差,低方差,模型较简单。(因为模型对于训练集和验证集误差都很大,所以低方差;如果模型在训练集上已经偏差很大,在验证集上更加离谱,偏差更大,那么这时可以说模型是高方差,不过这种情况极少发生。)
过拟合时,低偏差,高方差,模型较复杂。
理想的模型应该在偏差和方差之间找到良好的平衡。这就是所谓的偏差-方差权衡(Bias-Variance Tradeoff),追求偏差和方差都比较低!
下面这图解释得也不错,靠左边就是模型较简单时,模型对于训练集和验证集误差都很大,所以低方差;靠右边就是模型较复杂时,低偏差,高方差。
?

?
避免欠拟合/过拟合的技术!
欠拟合
- 增加模型复杂度
- 改进数据质量(增加数据量,数据清洗)
- 特征选择(选择更有代表性和信息量的特征)
- 增加训练时间
- 减少正则化(减小λ)
- 集成学习(结合多个模型的预测来提高整体的性能)
过拟合
- 减少模型复杂度
- 数据增强(Data Augmentation),对训练数据进行变换,如旋转、缩放、裁剪或颜色变化,白天和黑夜的熊猫图都要有,以增加数据多样性。
- 减少输入的特征(人为去除一些冗余的特征)
- 正则化!(误差函数中加入权重的L1或L2范数)(L1/L2正则可以去康康这篇 正则)
- 批量归一化(Batch Normalization):对每一层的输入进行归一化处理,稳定训练过程。(减少输入间变化对模型产生的影响,让每个隐藏层输出值均值与方差稳定在0和1,后面层的训练会更加稳定)(不过这招对缓解过拟合来说作用比较轻微)
- 提前停止(Early Stopping):如上面那图,在中间就停止,就完美,继续训练,方差会变大。
- 集成学习:结合多个模型的预测结果,如通过投票或平均,可以降低过拟合风险
- Dropout(在训练过程中随机丢弃一部分神经元,防止模型过于依赖训练数据中的特定样本)(Dropout可以理解为将集成学习效果通过一个网络模拟地实现,测试时神经元输出乘以删除比例,达到平均/集成的效果)其实Dropout也算正则化的一招,这里分开来讲。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- TS学习笔记四:函数及泛型枚举
- JDX图片识别工具1.0版本发布啦
- JAVA 版多商家入驻 直播带货 商城系统 B2B2C 之 鸿鹄云商B2B2C产品概述
- C语言猜数字升级版
- Centos单用户模式修改root密码
- 【DevOps-08-2】Harbor的基本操作
- 操作系统 day15(信号量)
- 问题:好久时间不用mysql,连接不上,显示2003错误
- EBDP:解锁大数据的奥秘?
- 【docker】docker入门与安装