深度学习算法应用实战 | DINOv2 图像相似度实战
特征提取简介

什么是特征提取
特征提取器负责为音频或视觉模型准备输入特征。包括从序列中提取特征,例如,对音频文件进行预处理以生成对数梅尔频谱图特征。以及从图像中提取特征,例如裁剪图像文件,还包括填充、归一化以及转换为NumPy、PyTorch和TensorFlow张量。
通俗一点解释
特征提取器就像是一个准备工人,它的工作是帮助计算机“理解”音频和图像。想象一下,当我们人类看图片或听声音时,我们可以轻松识别出里面的物体或声音。但对于计算机来说,它需要一种特殊的“翻译”,将这些音频和图像转换成它能理解的格式。这就是特征提取器的作用。
例如,对于音频文件,特征提取器可能会将声音转换成一种叫做“对数梅尔频谱图”的形式。这就像是把声音转换成一张包含不同音调和强度信息的图表,这样计算机就能更好地处理和分析声音了。
对于图像,特征提取器可能会做一些像裁剪图片(切掉不需要的部分),调整图片大小,使其更统一,或者改变图片的亮度和颜色,让计算机更容易识别图片中的内容。
最后,特征提取器还会把这些处理过的音频和图像转换成一种特殊的数据格式(我们称之为张量),这样不同的计算机程序,比如用于图像识别的PyTorch或用于语音识别的TensorFlow,就可以使用这些数据了。
总的来说,特征提取器就是帮助计算机“看懂”和“听懂”我们的世界的翻译工具。
图像相似度应用场景
-
图像检索: 通过计算图像相似度,可以建立一个图像数据库,并实现图像检索功能。用户可以通过输入一张图像找到相似的图片或相关产品。
-
人脸识别: 可以用于计算人脸图像之间的相似度,从而进行身份验证或者识别特定的个体。
-
内容过滤和版权保护: 图像相似度计算可用于检测和过滤不良内容,也可以帮助保护知识产权,防止未经授权的图像使用。
-
医学图像分析: 在医学领域,可以用于计算医学图像(如X射线、MRI等)之间的相似度,以辅助医生进行疾病诊断和治疗规划。
-
艺术品鉴别: 用于鉴别艺术品真伪或者确定不同版本的艺术品。
-
工业质检: 在制造业中,通过比较产品图像与标准图像的相似度,可以进行自动化的质量检查。
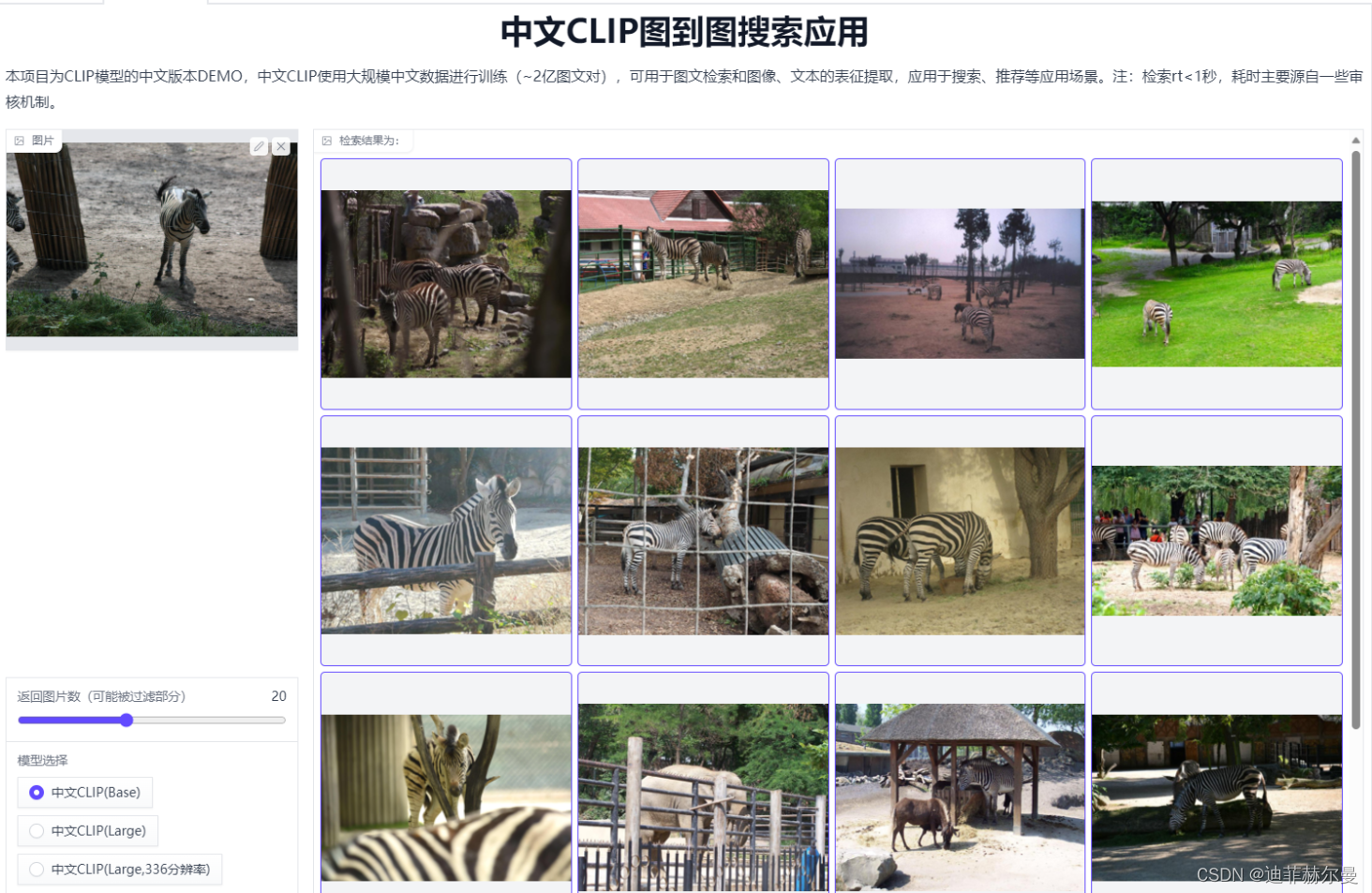
那这篇博客, 我就教大家使用 Meta AI 团队的 DINOv2 搭建一个图像相似度判别模型!
教程使用 huggingface 的 transformers 库来完成,这样方便我对整个专栏的代码教程进行维护,也方便我为大家分发模型(这种多模态的模型一般都很大,自己下载一次很麻烦)。
环境配置
conda create --name huggingface-env python==3.8 -y
conda activate huggingface-env
pip install transformers
如果你之前按照我的教程安装了这个环境,那么你就不需要再次安装了。
算法核心原理
最近在自然语言处理领域的突破性进展,特别是在大量数据上进行模型预训练,为计算机视觉领域类似的基础模型铺平了道路。这些模型可以通过生成通用视觉特征(即在不同图像分布和任务中均有效,无需微调的特征)来大大简化任何系统中图像的使用。我们的工作表明,如果在来自多样化来源的足够数量的精选数据上进行训练,现有的预训练方法,特别是自监督方法,可以产生这样的特征。我们重新审视了现有的方法,并结合不同的技术来扩大我们的预训练在数据和模型规模方面的应用。大部分技术贡献旨在加速和稳定大规模训练。在数据方面,我们提出了一个自动化流程来构建一个专用的、多样化的、精选的图像数据集,而不是像自监督文献中通常做的那样使用未经筛选的数据。在模型方面,我们训练了一个具有10亿参数的ViT模型并将其蒸馏到一系列更小的模型中,这些模型在大多数图像和像素级别的基准测试中超越了最佳的通用特征,OpenCLIP。
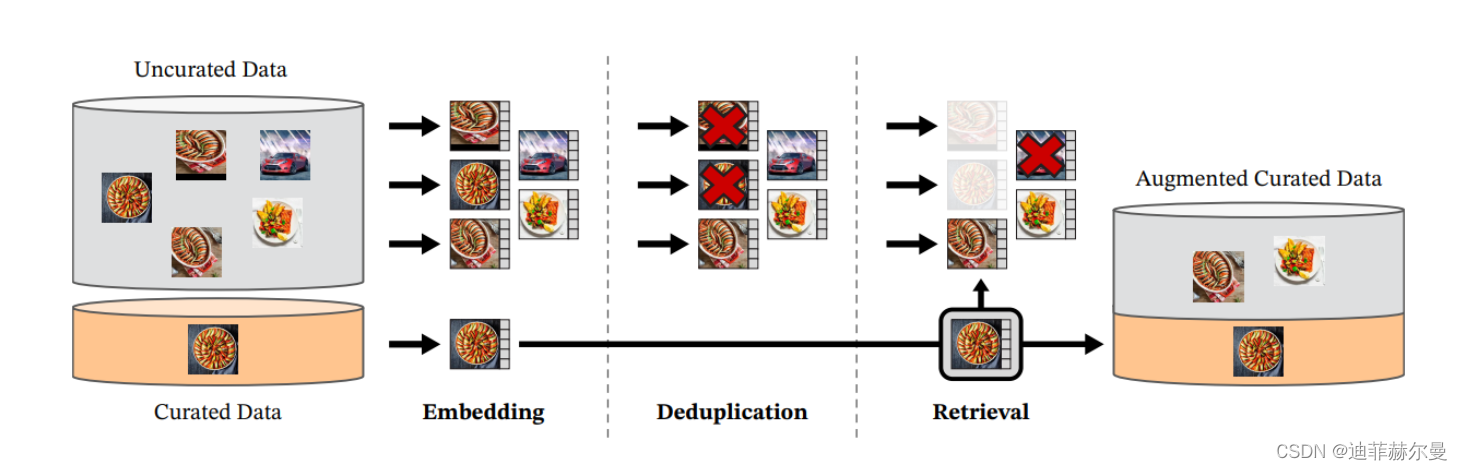
我们数据处理流程的概览。来自精选和非精选数据源的图像首先被映射到嵌入空间。之后,对非精选的图像进行去重处理,然后将其与精选图像进行匹配。通过这种方式,最终得到的组合通过一个自监督检索系统来增强初始数据集。

图1:第一主成分的可视化。我们计算同一列图像的补丁之间的主成分分析(a、b、c和d),并显示它们的前3个成分。每个成分与不同的颜色通道相匹配。尽管姿势、风格甚至物体发生变化,但相关图像之间的相同部分仍然匹配。通过对第一主成分进行阈值处理,可以去除背景。
代码实战
本次实战我们选择 openai 团队开源的 dinov2-base 版本。借助 transformers 库 ,我们可以通过几行代码就完成一个视觉任务。
下载好我提供的模型后,修改以下两处就可以顺利运行代码。
- 将
model路径和processor路径指定到你下载下来文件的位置。 image1和image2路径换成本地图片路径。
返回的结果就代表两张图片的余弦相似度。
import torch
from transformers import AutoImageProcessor, AutoModel
from PIL import Image
import torch.nn as nn
# 设置设备为GPU,如果不可用则使用CPU
device = torch.device('cuda' if torch.cuda.is_available() else "cpu")
# 加载预训练的图像处理器
processor = AutoImageProcessor.from_pretrained('/home/models/dinov2-base',
local_files_only=True)
# 加载预训练的模型,并将其移至相应的设备(GPU或CPU)
model = AutoModel.from_pretrained('/home/models/dinov2-base',
local_files_only=True).to(device)
# 打开第一张图片
image1 = Image.open('92201304415.png')
# 不计算梯度,用于推断
with torch.no_grad():
# 使用处理器处理图像,转换为PyTorch张量,并移至相应设备
inputs1 = processor(images=image1, return_tensors="pt").to(device)
# 通过模型获取输出
outputs1 = model(**inputs1)
# 获取最后一层的隐藏状态
image_features1 = outputs1.last_hidden_state
# 对特征取平均,以得到单个向量表示
image_features1 = image_features1.mean(dim=1)
print(f"outputs1 is {image_features1.shape}")
# 重复上述过程,处理第二张图片
image2 = Image.open('2203591439.png')
with torch.no_grad():
inputs2 = processor(images=image2, return_tensors="pt").to(device)
outputs2 = model(**inputs2)
image_features2 = outputs2.last_hidden_state
image_features2 = image_features2.mean(dim=1)
# 使用余弦相似度计算两个向量的相似度
cos = nn.CosineSimilarity(dim=0)
sim = cos(image_features1[0],image_features2[0]).item()
# 将相似度值调整到[0,1]范围内
sim = (sim+1)/2
print('Similarity:', sim)
模型地址:
链接:https://pan.baidu.com/s/1P83VSz2nzcSbCWmH7qw2SA
提取码:m368
算法整体的思路如下:
-
预处理和特征提取:
- 图像处理器:首先,使用一个预训练的图像处理器(
AutoImageProcessor)来处理输入的图像。这个处理器负责将图像转换成模型可以处理的格式,比如调整尺寸、归一化像素值等。 - 深度学习模型:接下来,使用预训练的深度学习模型(如
AutoModel)来提取图像的特征。这个模型通常是在大量数据上训练得到的,能够提取出表达图像内容的复杂特征。
- 图像处理器:首先,使用一个预训练的图像处理器(
-
特征向量的提取:
- 最后一个隐藏层:在深度学习模型中,最后一个隐藏层的输出通常被认为是一个丰富且有意义的特征表示。这些特征包含了输入图像经过模型多层抽象和转换后的高层次信息。
- 特征向量:为了获得一个固定大小的特征向量,代码对最后隐藏层的输出执行平均操作。这个特征向量可以捕捉图像的核心内容和特性,而忽略不相关的细节。
-
相似度计算:
- 余弦相似度:使用余弦相似度来比较两个特征向量。余弦相似度测量两个向量在方向上的相似性,而忽略它们的大小,这对于比较图像特征非常有效。
- 相似度标准化:将余弦相似度值标准化到0到1的范围内,使得结果更易于解释。值越接近1,表示两张图片越相似。
小知识:
为什么使用最后一个隐藏层的特征?
- 在深度学习模型中,随着层级的增加,特征表示从原始像素值转变为更高层次的抽象表示。最后一个隐藏层通常提供了足够丰富的信息来描述图像的主要内容和结构,同时去除了一些不必要的细节和噪声。
- 这些特征经过了模型中所有层的非线性变换,因此它们能够捕捉到图像中更复杂和抽象的信息,这对于图像间的相似度比较是非常有用的。
- 在许多深度学习模型中,特别是在计算机视觉领域,最后一个隐藏层的特征经常被用于各种下游任务,如图像分类、检索和相似度比较,因为它们提供了一个全面且有效的图像表示。
余弦相似度计算方法
余弦相似度是一种常用来衡量两个向量方向上相似程度的度量方法。在多维空间中,两个向量之间的余弦相似度由它们之间的夹角决定,其取值范围在-1到1之间。值为1意味着两个向量方向完全相同,0意味着两向量独立,-1意味着两向量方向完全相反。
余弦相似度的公式是:
余弦相似度 = A ? B ∣ ∣ A ∣ ∣ × ∣ ∣ B ∣ ∣ \text{余弦相似度} = \frac{A \cdot B}{||A|| \times ||B||} 余弦相似度=∣∣A∣∣×∣∣B∣∣A?B?
其中,( A A A ) 和 ( B B B ) 是两个向量,( A ? B A \cdot B A?B ) 表示它们的点积,( ∣ ∣ A ∣ ∣ ||A|| ∣∣A∣∣ ) 和 ( ∣ ∣ B ∣ ∣ ||B|| ∣∣B∣∣ ) 是向量的欧几里得长度(或称模)。
让我们用二维平面上的一个例子来解释这个概念:
假设有两个向量:
- 向量 A A A: ( x 1 , y 1 ) (x1, y1) (x1,y1) = ( 1 , 2 ) (1, 2) (1,2)
- 向量 B B B: ( x 2 , y 2 ) (x2, y2) (x2,y2) = ( 2 , 3 ) (2, 3) (2,3)
首先,计算它们的点积:
A ? B = x 1 × x 2 + y 1 × y 2 = 1 × 2 + 2 × 3 = 2 + 6 = 8 A \cdot B = x1 \times x2 + y1 \times y2 = 1 \times 2 + 2 \times 3 = 2 + 6 = 8 A?B=x1×x2+y1×y2=1×2+2×3=2+6=8
然后,计算每个向量的欧几里得长度:
∣ ∣ A ∣ ∣ = x 1 2 + y 1 2 = 1 2 + 2 2 = 1 + 4 = 5 ||A|| = \sqrt{x1^2 + y1^2} = \sqrt{1^2 + 2^2} = \sqrt{1 + 4} = \sqrt{5} ∣∣A∣∣=x12+y12?=12+22?=1+4?=5?
∣ ∣ B ∣ ∣ = x 2 2 + y 2 2 = 2 2 + 3 2 = 4 + 9 = 13 ||B|| = \sqrt{x2^2 + y2^2} = \sqrt{2^2 + 3^2} = \sqrt{4 + 9} = \sqrt{13} ∣∣B∣∣=x22+y22?=22+32?=4+9?=13?
最后,将这些值代入余弦相似度公式:
余弦相似度 = 8 5 × 13 ≈ 0.94 \text{余弦相似度} = \frac{8}{\sqrt{5} \times \sqrt{13}} \approx 0.94 余弦相似度=5?×13?8?≈0.94
这个余弦相似度值接近 1,表示向量
A
A
A 和向量
B
B
B 的方向非常相似。
在图像处理、自然语言处理等领域,使用余弦相似度来衡量不同数据点(如文本、图像特征向量)间的相似性是非常普遍的。这种方法的优势在于它只考虑方向而不受向量长度的影响,使其适用于比较不同长度的数据表示。
多维度向量之间的余弦相似度计算方法与二维向量类似。核心思想仍然是测量两个向量在方向上的相似性,而忽略它们的大小(即模)。余弦相似度在多维空间中尤其有用,因为它能有效地比较高维数据点(如文本、图像或声音的特征向量)之间的相似性。
对于两个多维向量 ( A A A ) 和 ( B B B ),其余弦相似度的计算公式保持不变:
余弦相似度 = A ? B ∣ ∣ A ∣ ∣ × ∣ ∣ B ∣ ∣ \text{余弦相似度} = \frac{A \cdot B}{||A|| \times ||B||} 余弦相似度=∣∣A∣∣×∣∣B∣∣A?B?
这里的计算步骤是:
- 点积:计算向量 ( A A A ) 和向量 ( B B B) 的点积。如果 ( A A A ) 和 ( B B B ) 是 ( n n n ) 维向量,( A = ( a _ 1 , a _ 2 , . . . , a _ n ) A = (a\_1, a\_2, ..., a\_n) A=(a_1,a_2,...,a_n) ) 和 ( B = ( b _ 1 , b _ 2 , . . . , b _ n ) B = (b\_1, b\_2, ..., b\_n) B=(b_1,b_2,...,b_n) ),则它们的点积是
A ? B = a 1 × b 1 + a 2 × b 2 + . . . + a n × b n A \cdot B = a_1 \times b_1 + a_2 \times b_2 + ... + a_n \times b_n A?B=a1?×b1?+a2?×b2?+...+an?×bn?
- 向量长度:计算向量的欧几里得长度(模)。对于向量 ( A A A ),其长度是
∣ ∣ A ∣ ∣ = a _ 1 2 + a _ 2 2 + . . . + a _ n 2 ||A|| = \sqrt{a\_1^2 + a\_2^2 + ... + a\_n^2} ∣∣A∣∣=a_12+a_22+...+a_n2?
同理,计算向量 ( B B B) 的长度。
- 计算余弦相似度:将点积除以两个向量长度的乘积。
例如,对于两个三维向量 ( A = ( 1 , 2 , 3 ) A = (1, 2, 3) A=(1,2,3) ) 和 ( B = ( 4 , 5 , 6 ) B = (4, 5, 6) B=(4,5,6) ),计算步骤如下:
- 点积:( 1 × 4 + 2 × 5 + 3 × 6 = 4 + 10 + 18 = 32 1 \times 4 + 2 \times 5 + 3 \times 6 = 4 + 10 + 18 = 32 1×4+2×5+3×6=4+10+18=32 )
- 向量长度:( ∣ ∣ A ∣ ∣ = 1 2 + 2 2 + 3 2 = 1 + 4 + 9 = 14 ||A||=\sqrt{1^2 + 2^2 + 3^2}=\sqrt{1 + 4 + 9} = \sqrt{14} ∣∣A∣∣=12+22+32?=1+4+9?=14? ) ( ∣ ∣ B ∣ ∣ = 42 + 52 + 62 = 16 + 25 + 36 = 77 ||B|| = \sqrt{42 + 52 + 62} = \sqrt{16 + 25 + 36} = \sqrt{77} ∣∣B∣∣=42+52+62?=16+25+36?=77? )
- 余弦相似度:( 32 14 × 77 \frac{32}{\sqrt{14} \times \sqrt{77}} 14?×77?32? )
总结
本文简要讨论了深度学习模型中常见的相似度计算方法,特别是基于余弦相似度的特征相似度对比方法。这种方法在多模态模型中扮演着核心且基础的角色。
后面,我们将以此为基础,开发一系列以图搜图、以文搜图等应用。感谢大家的支持~
相关推荐
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 第89讲:MySQL数据库迁移方面需要考虑的因素以及XBK企业级备份参数
- 【金融支付】常用术语和定义
- yolov8实时推理目标识别、区域分割、姿态识别 Qt GUI
- Docker多平台安装与配置指南
- vue3-条件渲染
- 20240103让AIO-3399J的开发板刷Firefly的官方Andorid10使用EC20的模块成功上网
- spark dateformat源码排错
- JavaSE变量 常量和数据类型转化
- 正运动技术荣获CMCD三项大奖,持续自主自研助力智能制造!
- QEMU源码全解析 —— PCI设备模拟(6)