C语言光速入门笔记
C语言是一门面向过程的编译型语言,它的运行速度极快,仅次于汇编语言。C语言是计算机产业的核心语言,操作系统、硬件驱动、关键组件、数据库等都离不开C语言;不学习C语言,就不能了解计算机底层。
目录
C语言介绍
C 语言是一种通用的、面向过程式的计算机程序设计语言。1972 年,为了移植与开发 UNIX 操作系统,丹尼斯·里奇在贝尔电话实验室设计开发了 C 语言。
当前最新的 C 语言标准为 C18 ,在它之前的 C 语言标准有 C17、C11…C99 等。
C语言出现的时候,已经度过了编程语言的拓荒年代,具备了现代编程语言的特性,但是这个时候还没有出现“软件危机”,人们没有动力去开发更加高级的语言,所以也没有太复杂的编程思想。
也就是说,C语言虽然是现代编程语言,但是它涉及到的概念少,词汇少,思想也简单。C语言学习成本小,初学者能够在短时间内掌握编程技能,非常适合入门。
C语言特性
-
高效性
C是一种高效的语言。 在设计上它充分利用了当前计算机在能力上的优点。C程序往往很紧凑且运行速度快。事实上,C可以表现出通常只有汇编语言才具有的精细控制能力(汇编语言是特定的CPU设计所采用的一组内部指令的助记符。不同的CPU类型使用不同的汇编语言)。如果愿意,你可以细调程序以获得最大速度或最大内存使用率。
-
可移植性
C是一种可移植语言。这意味着,在一个系统上编写的C程序经过很少改动或不经修改就可以其他系统上运行。如果修改是必要的,则通常只须改变伴随主程序的一个头文件中的几项内容即可。多数语言原本都想具有可移植性,但任何曾将IBM PC BASIC程序转换为Apple BASIC程序(它们还是近亲)的人,或者试图在UNIX系统上运行一个IBM大型机FORTRAN程序的人都知道,移植至少是在制造麻烦。C在可移植性方面处于领先地位。C编译器(将C代码转换为计算机内部使用的指令的程序)在大约40多种系统上可用,包括从使用8位微处理器的计算机到Cray超级计算机。不过要知道,程序中为访问特定硬件设备(例如显示器)或操作系统(如Windows XP或OS X)的特殊功能而专门编写的部分,通常是不能移植的。
由于C与UNIX的紧密联系,UNIX系统通常都带有一个C编译器作为程序包的一部分。Linux中同样也包括一个C编译器。个人计算机,包括运行不同版本的Windows和Macintosh的PC,可使用若干种C编译器。所以不论你使用的是家用计算机,专业工作站还是大型机,都很容易得到针对你特定系统的C编译器。
-
强大的功能和灵活性
C强大而又灵活(计算机世界中经常使用的两个词)。例如,强大而灵活的UNIX操作系统的大部分便是用C编写的。其他语言(如FORTRAN,Perl,Python,Pascal,LISP,Logo和BASIC)的许多编译器和解释器也都用C编写的。结果是,当你在一台UNIX机器上使用FORTRAN时,最终是由一个C程序负责生成最后的可执行程序的。C程序已经用于解决物理学和工程学问题,甚至用来为《角斗士》这样的电影制造特殊效果。
-
面向编程人员
C面向编程人员的需要。它允许你访问硬件,并可以操纵内存中的特定位。它具有丰富的运算符供选择,让你能够简洁地表达自己的意图。在限制你所能做的事情方面,C不如Pascal这样的语言严格。这种灵活性是优点,同时也是一种危险。优点在于:许多任务(如转换数据形式)在C中都简单得多。危险在于:使用C时,你可能会犯在使用其他一些语言时不可能犯的错误。C给予你更多的自由,但同时也让你承担更大的风险。
上面这些特点,使得 C 语言可以写出性能非常强、完全发挥硬件潜力的程序,而且 C 语言的编译器实现难度相对较低。但是另一方面,C 语言代码容易出错,一般程序员不容易写好。
此外,当代很多流行语言都是以 C 语言为基础,比如 C++、Java、C#、JavaScript 等等。学好 C 语言有助于对这些语言加深理解。
C编译器
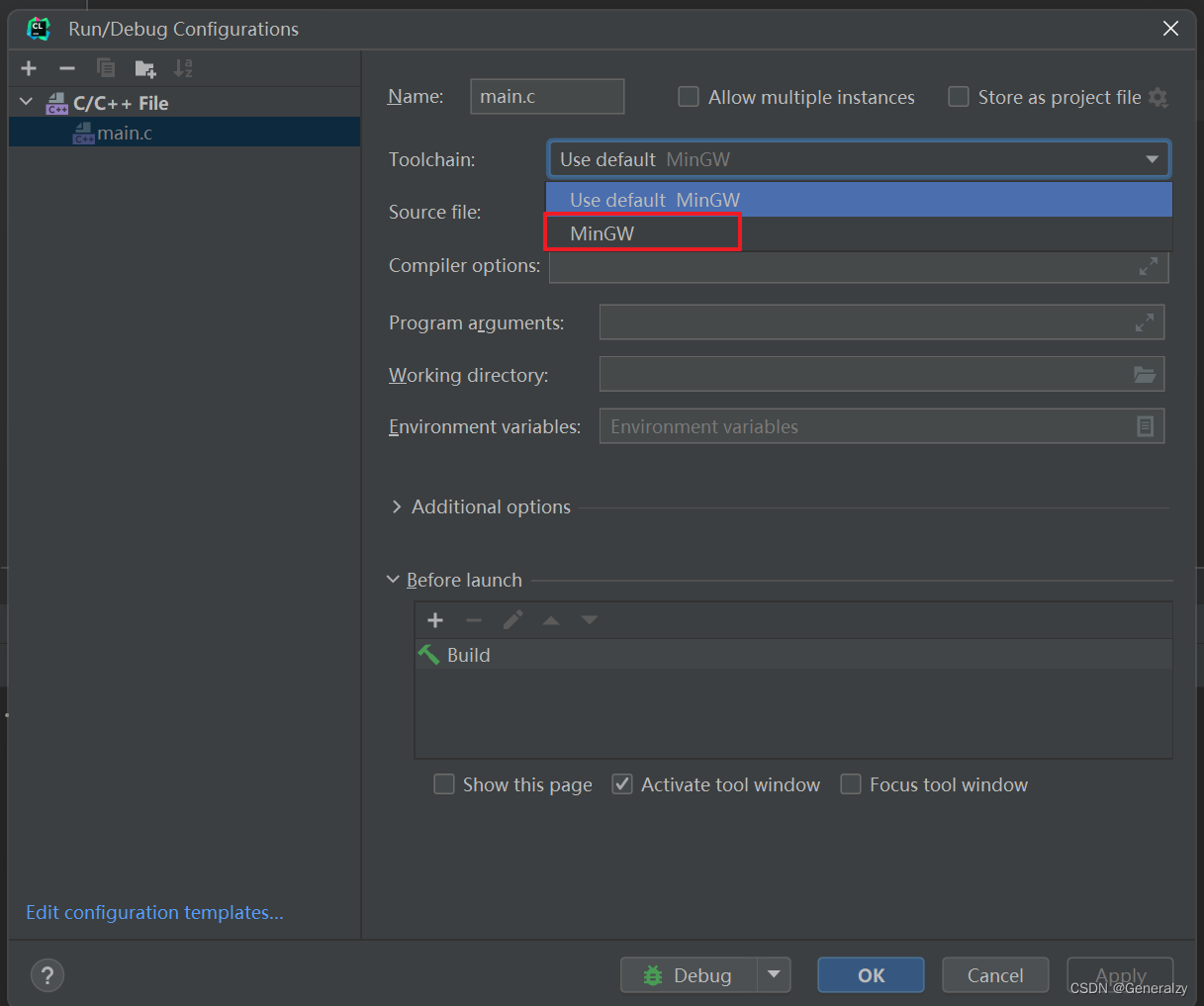
首先是如雷贯耳的这几位仁兄,MSVC、GCC、Cygwin、MingW(Cygwin和MingW的英文发音),另外还有些小众和新秀,像ICC(Intel C/C++ Compiler)、BCC(Borland C/C++ Compiler,快销声匿迹了)、RVCT(ARM的汇编/C/C++编译器,内置在ARM的IDE——RVDS中)、Pgi编译器……其实有一大串,我们只要熟悉常用的最强大的几款就可以了。
GCC (GNU Compiler Collection):
特点:
- 开源性: GCC 是自由和开源软件,遵循GNU通用公共许可证(GPL)。
- 跨平台支持: 支持多种平台,包括Linux、Unix、Windows等,可以生成针对不同体系结构的代码。
- 多语言支持: GCC 不仅支持C语言,还支持C++、Fortran、Ada等多种编程语言。
- 丰富的优化选项: 提供广泛的编译器优化选项,可以通过这些选项优化生成的机器代码。
- 广泛应用: 在许多开发环境和项目中被广泛使用,是许多Unix-like系统的默认编译器。
Clang:
特点:
- LLVM基础: Clang 是基于LLVM项目的编译器。LLVM的设计使得Clang可以提供高性能的编译,并且具有灵活的架构。
- 模块化设计: Clang 的设计注重模块化,这使得它更容易嵌入到其他工具和开发环境中。
- 高质量的诊断信息: Clang 提供详细和易读的错误和警告信息,帮助开发者更容易调试和优化代码。
- 兼容性: 与GCC相比,Clang对C++标准的支持更加先进,并在C++11、C++14、C++17等方面表现优秀。
MSVC (Microsoft Visual C++ Compiler):
特点:
- Windows集成: MSVC 是Microsoft Visual Studio集成开发环境的一部分,主要用于Windows平台的应用程序开发。
- Windows API集成: 提供了对Windows API的良好支持,使得Windows平台上的开发更加便捷。
- 调试工具: 集成了强大的调试工具,如Visual Studio Debugger,提供了丰富的调试功能。
- 性能工具: Visual Studio 提供了性能分析工具,帮助开发者优化和调试程序性能。
对比
-
开源性:
- GCC 是自由和开源的,用户可以查看和修改其源代码。
- Clang 也是开源的,基于LLVM项目,允许用户访问和修改源代码。
- MSVC 是闭源的,用户不能直接访问其源代码。
-
跨平台支持:
- GCC 在多个平台上有广泛支持。
- Clang 也是跨平台的,但在某些平台上可能需要额外的工作。
- MSVC 主要用于Windows平台。
-
语言支持:
- GCC 支持多种编程语言。
- Clang 支持C、C++等,对C++标准支持较好。
- MSVC 主要支持C和C++。
-
性能和优化:
- GCC 和 Clang 在性能和优化方面具有竞争力,具体表现可能取决于编译器版本和优化选项。
- MSVC 也提供了一些优化选项,但在某些情况下可能与GCC和Clang有所不同。
-
集成开发环境:
- GCC 和 Clang 通常与各种集成开发环境搭配使用。
- MSVC 集成于Microsoft Visual Studio,提供了全面的开发工具和环境。
在跨平台开发时,GCC 和 Clang 是常见选择,而在Windows平台上,MSVC 是首选。
MinGw一般使用Gcc作为C编译器,可以通过在cmd执行gcc命令来验证:
gcc your_source_code.c -o your_executable.exe

为什么要使用 C?
C 语言最初是用于系统开发工作,特别是组成操作系统的程序。由于 C 语言所产生的代码运行速度与汇编语言编写的代码运行速度几乎一样,所以采用 C 语言作为系统开发语言。下面列举几个使用 C 的实例:
- 操作系统
- 语言编译器
- 汇编器
- 文本编辑器
- 打印机
- 网络驱动器
- 现代程序
- 数据库
- 语言解释器
- 实体工具
C语言的版本
历史上,C 语言有过多个版本。
(1)K&R C
K&R C指的是 C 语言的原始版本。1978年,C 语言的发明者丹尼斯·里奇(Dennis Ritchie)和布莱恩·柯林汉(Brian Kernighan)合写了一本著名的教材《C 编程语言》(The C programming language)。由于 C 语言还没有成文的语法标准,这本书就成了公认标准,以两位作者的姓氏首字母作为版本简称“K&R C”。
(2)ANSI C(又称 C89 或 C90)
C 语言的原始版本非常简单,对很多情况的描述非常模糊,加上 C 语法依然在快速发展,要求将 C 语言标准化的呼声越来越高。
1989年,美国国家标准协会(ANSI)制定了一套 C 语言标准。1990年,国际标准化组织(ISO)通过了这个标准。它被称为“ANSI C”,也可以按照发布年份,称为“C89 或 C90”。
(3)C95
1995年,美国国家标准协会对1989年的那个标准,进行了补充,加入多字节字符和宽字符的支持。这个版本称为 C95。
(4)C99
C 语言标准的第一次大型修订,发生在1999年,增加了许多语言特性,比如双斜杠(//)的注释语法。这个版本称为 C99,是目前最流行的 C 版本。
(5)C11
2011年,标准化组织再一次对 C 语言进行修订,增加了 Unicode 和多线程的支持。这个版本称为 C11。
(6)C17
C11 标准在2017年进行了修补,但发布是在2018年。新版本只是解决了 C11 的一些缺陷,没有引入任何新功能。这个版本称为 C17。
(7)C2x
标准化组织正在讨论 C 语言的下一个版本,据说可能会在2023年通过,到时就会称为 C23。
C11
C11(也被称为C1X)指ISO标准ISO/IEC 9899:2011。在它之前的C语言标准为C99。
新特性:
- 对齐处理(Alignment)的标准化(包括_Alignas标志符,alignof运算符,aligned_alloc函数以及<stdalign.h>头文件)。
- _Noreturn 函数标记,类似于 gcc 的 attribute((noreturn))。
- _Generic 关键字。
- 多线程(Multithreading)支持,包括:
- _Thread_local存储类型标识符,<threads.h>头文件,里面包含了线程的创建和管理函数。
- _Atomic类型修饰符和<stdatomic.h>头文件。
- 增强的Unicode的支持。基于C Unicode技术报告ISO/IEC TR 19769:2004,增强了对Unicode的支持。包括为UTF-16/UTF-32编码增加了char16_t和char32_t数据类型,提供了包含unicode字符串转换函数的头文件<uchar.h>。
- 删除了 gets() 函数,使用一个新的更安全的函数gets_s()替代。
- 增加了边界检查函数接口,定义了新的安全的函数,例如 fopen_s(),strcat_s() 等等。
- 增加了更多浮点处理宏(宏)。
- 匿名结构体/联合体支持。这个在gcc早已存在,C11将其引入标准。
- 静态断言(Static assertions),_Static_assert(),在解释 #if 和 #error 之后被处理。
- 新的 fopen() 模式,(“…x”)。类似 POSIX 中的 O_CREAT|O_EXCL,在文件锁中比较常用。
- 新增 quick_exit() 函数作为第三种终止程序的方式。当 exit() 失败时可以做最少的清理工作。
第一个C程序——hello world
#include <stdio.h>
int main(){
/* 我的第一个 C 程序 */
// 我的第一个C程序
printf("hello world");
return 0;
}
- 所有的 C 语言程序都需要包含 main() 函数。 代码从 main() 函数开始执行。
/* ... */和//用于注释说明。(和go一样)- printf() 用于格式化输出到屏幕。printf() 函数在 “stdio.h” 头文件中声明。
- stdio.h 是一个头文件 (标准输入输出头文件) , #include 是一个预处理命令,用来引入头文件。 当编译器遇到 printf() 函数时,如果没有找到 stdio.h 头文件,会发生编译错误。
- return 0; 语句用于表示退出程序。
执行下面的命令。
$ gcc hello.c
上面命令使用gcc编译器,将源文件hello.c编译成二进制代码。
运行这个命令以后,默认会在当前目录下生成一个编译产物文件a.out(assembler output 的缩写,Windows 平台为a.exe)。执行该文件,就会在屏幕上输出Hello World。
$ ./a.out
Hello World
GCC 的-o参数(output 的缩写)可以指定编译产物的文件名。
$ gcc -o hello hello.c
上面命令的-o hello指定,编译产物的文件名为hello(取代默认的a.out)。编译后就会生成一个名叫hello的可执行文件,相当于为a.out指定了名称。执行该文件,也会得到同样的结果。
$ ./hello
Hello World
GCC 的-std=参数(standard 的缩写)还可以指定按照哪个 C 语言的标准进行编译。
$ gcc -std=c99 hello.c
上面命令指定按照 C99 标准进行编译。
注意,-std后面需要用=连接参数,而不是像上面的-o一样用空格,并且=前后也不能有多余的空格。
基本语法
分号
C 语言的代码由一行行语句(statement)组成。语句就是程序执行的一个操作命令。C 语言规定,语句必须使用分号结尾,除非有明确规定可以不写分号。
在 C 程序中,分号是语句结束符。也就是说,每个语句必须以分号结束。它表明一个逻辑实体的结束。
例如,下面是两个不同的语句:
printf("Hello, World! \n");
return 0;
多个语句可以写在一行。
int x; x = 1;
上面示例是两个语句写在一行。所以,语句之间的换行符并不是必需的,只是为了方便阅读代码。
语句块
与Go语言一样,C 语言也允许多个语句使用一对大括号{},组成一个块,也称为复合语句(compounded statement)。在语法上,语句块可以视为多个语句组成的一个复合语句。
{
int x;
x = 1;
}
上面示例中,大括号形成了一个语句块,大括号的结尾不需要添加分号。
但要注意的是,不管在哪个语言里,语句块算一个作用域,声明在里面的变量声明周期不会超出语句块。
标识符
C 标识符是用来标识变量、函数,或任何其他用户自定义项目的名称。一个标识符以字母 A-Z 或 a-z 或下划线 _ 开始,后跟零个或多个字母、下划线和数字(0-9)。
C 标识符内不允许出现标点字符,比如 @、$ 和 %。C 是区分大小写的编程语言。因此,在 C 中,Manpower 和 manpower 是两个不同的标识符。下面列出几个有效的标识符:
mohd zara abc move_name a_123
myname50 _temp j a23b9 retVal
关键字
下表列出了 C 中的保留字。这些保留字不能作为常量名、变量名或其他标识符名称。
| 关键字 | 说明 |
|---|---|
| auto | 声明自动变量 |
| break | 跳出当前循环 |
| case | 开关语句分支 |
| char | 声明字符型变量或函数返回值类型 |
| const | 定义常量,如果一个变量被 const 修饰,那么它的值就不能再被改变 |
| continue | 结束当前循环,开始下一轮循环 |
| default | 开关语句中的"其它"分支 |
| do | 循环语句的循环体 |
| double | 声明双精度浮点型变量或函数返回值类型 |
| else | 条件语句否定分支(与 if 连用) |
| enum | 声明枚举类型 |
| extern | 声明变量或函数是在其它文件或本文件的其他位置定义 |
| float | 声明浮点型变量或函数返回值类型 |
| for | 一种循环语句 |
| goto | 无条件跳转语句 |
| if | 条件语句 |
| int | 声明整型变量或函数 |
| long | 声明长整型变量或函数返回值类型 |
| register | 声明寄存器变量 |
| return | 子程序返回语句(可以带参数,也可不带参数) |
| short | 声明短整型变量或函数 |
| signed | 声明有符号类型变量或函数 |
| sizeof | 计算数据类型或变量长度(即所占字节数) |
| static | 声明静态变量 |
| struct | 声明结构体类型 |
| switch | 用于开关语句 |
| typedef | 用以给数据类型取别名 |
| unsigned | 声明无符号类型变量或函数 |
| union | 声明共用体类型 |
| void | 声明函数无返回值或无参数,声明无类型指针 |
| volatile | 说明变量在程序执行中可被隐含地改变 |
| while | 循环语句的循环条件 |
C99 新增关键字
| _Bool | _Complex | _Imaginary | inline | restrict |
C11 新增关键字
| _Alignas | _Alignof | _Atomic | _Generic | _Noreturn |
| _Static_assert | _Thread_local | ? | ? | ? |
C 中的空格
只包含空格的行,被称为空白行,可能带有注释,C 编译器会完全忽略它。
在 C 中,空格用于描述空白符、制表符、换行符和注释。空格分隔语句的各个部分,让编译器能识别语句中的某个元素(比如 int)在哪里结束,下一个元素在哪里开始。因此,在下面的语句中:
int age;
在这里,int 和 age 之间必须至少有一个空格字符(通常是一个空白符),这样编译器才能够区分它们。另一方面,在下面的语句中:
fruit = apples + oranges; // 获取水果的总数
fruit 和 =,或者 = 和 apples 之间的空格字符不是必需的,但是为了增强可读性,您可以根据需要适当增加一些空格。
占位符
printf()的占位符有许多种类,与 C 语言的数据类型相对应。下面按照字母顺序,列出常用的占位符,方便查找。
%a:十六进制浮点数,字母输出为小写。
%A:十六进制浮点数,字母输出为大写。
%c:字符。
%d:十进制整数。
%e:使用科学计数法的浮点数,指数部分的e为小写。
%E:使用科学计数法的浮点数,指数部分的E为大写。
%i:整数,基本等同于%d。
%f:小数(包含float类型和double类型)。
%g:6个有效数字的浮点数。整数部分一旦超过6位,就会自动转为科学计数法,指数部分的e为小写。
%G:等同于%g,唯一的区别是指数部分的E为大写。
%hd:十进制 short int 类型。
%ho:八进制 short int 类型。
%hx:十六进制 short int 类型。
%hu:unsigned short int 类型。
%ld:十进制 long int 类型。
%lo:八进制 long int 类型。
%lx:十六进制 long int 类型。
%lu:unsigned long int 类型。
%lld:十进制 long long int 类型。
%llo:八进制 long long int 类型。
%llx:十六进制 long long int 类型。
%llu:unsigned long long int 类型。
%Le:科学计数法表示的 long double 类型浮点数。
%Lf:long double 类型浮点数。
%n:已输出的字符串数量。该占位符本身不输出,只将值存储在指定变量之中。
%o:八进制整数。
%p:指针。
%s:字符串。
%u:无符号整数(unsigned int)。
%x:十六进制整数。
%zd:size_t类型。
%%:输出一个百分号。
输出格式
printf()可以定制占位符的输出格式。
(1)限定宽度
printf()允许限定占位符的最小宽度。
printf("%5d\n", 123); // 输出为 " 123"
上面示例中,%5d表示这个占位符的宽度至少为5位。如果不满5位,对应的值的前面会添加空格。
输出的值默认是右对齐,即输出内容前面会有空格;如果希望改成左对齐,在输出内容后面添加空格,可以在占位符的%的后面插入一个-号。
printf("%-5d\n", 123); // 输出为 "123 "
上面示例中,输出内容123的后面添加了空格。
对于小数,这个限定符会限制所有数字的最小显示宽度。
// 输出 " 123.450000"
printf("%12f\n", 123.45);
上面示例中,%12f表示输出的浮点数最少要占据12位。由于小数的默认显示精度是小数点后6位,所以123.45输出结果的头部会添加2个空格。
(2)总是显示正负号
默认情况下,printf()不对正数显示+号,只对负数显示-号。如果想让正数也输出+号,可以在占位符的%后面加一个+。
printf("%+d\n", 12); // 输出 +12
printf("%+d\n", -12); // 输出 -12
上面示例中,%+d可以确保输出的数值,总是带有正负号。
(3)限定小数位数
输出小数时,有时希望限定小数的位数。举例来说,希望小数点后面只保留两位,占位符可以写成%.2f。
// 输出 Number is 0.50
printf("Number is %.2f\n", 0.5);
上面示例中,如果希望小数点后面输出3位(0.500),占位符就要写成%.3f。
这种写法可以与限定宽度占位符,结合使用。
// 输出为 " 0.50"
printf("%6.2f\n", 0.5);
上面示例中,%6.2f表示输出字符串最小宽度为6,小数位数为2。所以,输出字符串的头部有两个空格。
最小宽度和小数位数这两个限定值,都可以用*代替,通过printf()的参数传入。
printf("%*.*f\n", 6, 2, 0.5);
// 等同于
printf("%6.2f\n", 0.5);
上面示例中,%*.*f的两个星号通过printf()的两个参数6和2传入。
(4)输出部分字符串
%s占位符用来输出字符串,默认是全部输出。如果只想输出开头的部分,可以用%.[m]s指定输出的长度,其中[m]代表一个数字,表示所要输出的长度。
// 输出 hello
printf("%.5s\n", "hello world");
上面示例中,占位符%.5s表示只输出字符串“hello world”的前5个字符,即“hello”。
数据类型——基本数据类型
在 C 语言中,数据类型指的是用于声明不同类型的变量或函数的一个广泛的系统。变量的类型决定了变量存储占用的空间,以及如何解释存储的位模式。
C 中的类型可分为以下几种:
| 序号 | 类型与描述 |
|---|---|
| 1 | 基本数据类型 它们是算术类型,包括整型(int)、字符型(char)、浮点型(float)和双精度浮点型(double)。 |
| 2 | 枚举类型: 它们也是算术类型,被用来定义在程序中只能赋予其一定的离散整数值的变量。 |
| 3 | void 类型: 类型说明符 void 表示没有值的数据类型,通常用于函数返回值。 |
| 4 | 派生类型: :包括数组类型、指针类型和结构体类型。 |
数组类型和结构类型统称为聚合类型。函数的类型指的是函数返回值的类型。
整数类型
下表列出了关于标准整数类型的存储大小和值范围的细节:
| 类型 | 存储大小 | 值范围 |
|---|---|---|
| char | 1 字节 | -128 到 127 或 0 到 255 |
| unsigned char | 1 字节 | 0 到 255 |
| signed char | 1 字节 | -128 到 127 |
| int | 2 或 4 字节 | -32,768 到 32,767 或 -2,147,483,648 到 2,147,483,647 |
| unsigned int | 2 或 4 字节 | 0 到 65,535 或 0 到 4,294,967,295 |
| short | 2 字节 | -32,768 到 32,767 |
| unsigned short | 2 字节 | 0 到 65,535 |
| long | 4 字节 | -2,147,483,648 到 2,147,483,647 |
| unsigned long | 4 字节 | 0 到 4,294,967,295 |
注意,各种类型的存储大小与系统位数有关,但目前通用的以64位系统为主。
以下列出了32位系统与64位系统的存储大小的差别(windows 相同):
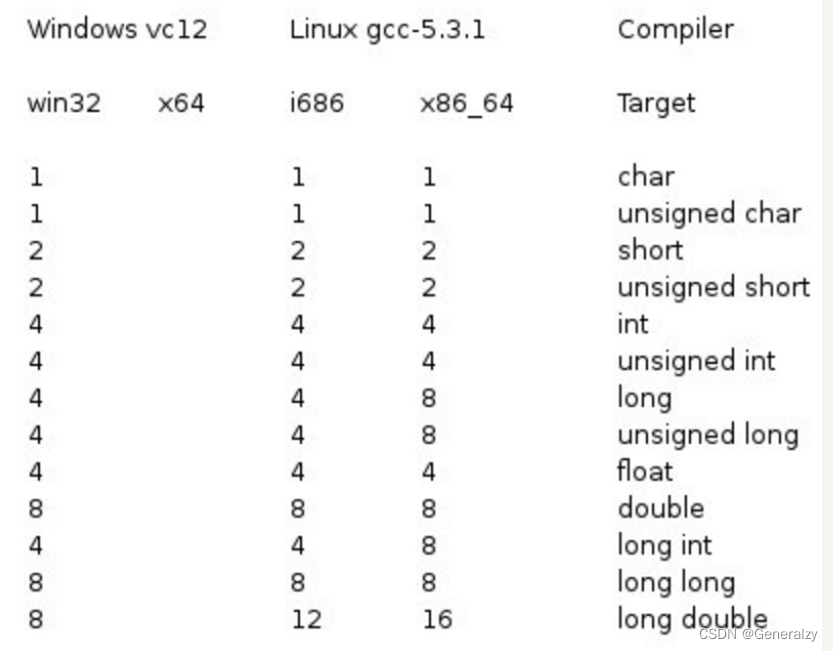
为了得到某个类型或某个变量在特定平台上的准确大小,可以使用 sizeof 运算符。表达式 sizeof(type) 得到对象或类型的存储字节大小。下面的实例演示了获取 int 类型的大小:
#include <stdio.h>
#include <limits.h>
int main()
{
printf("int 存储大小 : %lu \n", sizeof(int));
return 0;
}
signed,unsigned
C 语言使用signed关键字,表示一个类型带有正负号,包含负值;使用unsigned关键字,表示该类型不带有正负号,只能表示零和正整数。
对于int类型,默认是带有正负号的,也就是说int等同于signed int。由于这是默认情况,关键字signed一般都省略不写,但是写了也不算错。
signed int a;
// 等同于
int a;
int类型也可以不带正负号,只表示非负整数。这时就必须使用关键字unsigned声明变量。
unsigned int a;
整数变量声明为unsigned的好处是,同样长度的内存能够表示的最大整数值,增大了一倍。比如,16位的signed int最大值为32,767,而unsigned int的最大值增大到了65,535。
unsigned int里面的int可以省略,所以上面的变量声明也可以写成下面这样。
unsigned a;
字符类型char也可以设置signed和unsigned。
signed char c; // 范围为 -128 到 127
unsigned char c; // 范围为 0 到 255
注意,C 语言规定char类型默认是否带有正负号,由当前系统决定。这就是说,char不等同于signed char,它有可能是signed char,也有可能是unsigned char。这一点与int不同,int就是等同于signed int。
整数类型的极限值
有时候需要查看,当前系统不同整数类型的最大值和最小值,C 语言的头文件limits.h提供了相应的常量,比如SCHAR_MIN代表 signed char 类型的最小值-128,SCHAR_MAX代表 signed char 类型的最大值127。
为了代码的可移植性,需要知道某种整数类型的极限值时,应该尽量使用这些常量。
SCHAR_MIN,SCHAR_MAX:signed char 的最小值和最大值。SHRT_MIN,SHRT_MAX:short 的最小值和最大值。INT_MIN,INT_MAX:int 的最小值和最大值。LONG_MIN,LONG_MAX:long 的最小值和最大值。LLONG_MIN,LLONG_MAX:long long 的最小值和最大值。UCHAR_MAX:unsigned char 的最大值。USHRT_MAX:unsigned short 的最大值。UINT_MAX:unsigned int 的最大值。ULONG_MAX:unsigned long 的最大值。ULLONG_MAX:unsigned long long 的最大值。
整数的进制
C 语言的整数默认都是十进制数,如果要表示八进制数和十六进制数,必须使用专门的表示法。
八进制使用0作为前缀,比如017、0377。
int a = 012; // 八进制,相当于十进制的10
十六进制使用0x或0X作为前缀,比如0xf、0X10。
int a = 0x1A2B; // 十六进制,相当于十进制的6699
有些编译器使用0b前缀,表示二进制数,但不是标准。
int x = 0b101010;
注意,不同的进制只是整数的书写方法,不会对整数的实际存储方式产生影响。所有整数都是二进制形式存储,跟书写方式无关。不同进制可以混合使用,比如10 + 015 + 0x20是一个合法的表达式。
printf()的进制相关占位符如下。
%d:十进制整数。%o:八进制整数。%x:十六进制整数。%#o:显示前缀0的八进制整数。%#x:显示前缀0x的十六进制整数。%#X:显示前缀0X的十六进制整数。
int x = 100;
printf("dec = %d\n", x); // 100
printf("octal = %o\n", x); // 144
printf("hex = %x\n", x); // 64
printf("octal = %#o\n", x); // 0144
printf("hex = %#x\n", x); // 0x64
printf("hex = %#X\n", x); // 0X64
浮点类型
| 类型 | 存储大小 | 值范围 | 精度 |
|---|---|---|---|
| float | 4 字节 | 1.2E-38 到 3.4E+38 | 6 位有效位 |
| double | 8 字节 | 2.3E-308 到 1.7E+308 | 15 位有效位 |
| long double | 16 字节 | 3.4E-4932 到 1.1E+4932 | 19 位有效位 |
头文件 float.h 定义了宏,在程序中可以使用这些值和其他有关实数二进制表示的细节。下面的实例将输出浮点类型占用的存储空间以及它的范围值:
#include <stdio.h>
#include <float.h>
int main()
{
// %E 为以指数形式输出单、双精度实数
printf("float32(float) 存储最大字节数 : %lu \n", sizeof(float));
printf("float64(double) 存储最大字节数 : %lu \n",sizeof(double));
printf("float32(float) 最小值: %E\n", FLT_MIN );
printf("float32(float) 最大值: %E\n", FLT_MAX );
printf("float64(double) 最小值: %E\n", DBL_MIN );
printf("float64(double) 最大值: %E\n", DBL_MAX );
printf("float32(float)精度值: %d\n", FLT_DIG );
printf("float64(double)精度值: %d\n", DBL_DIG );
return 0;
}
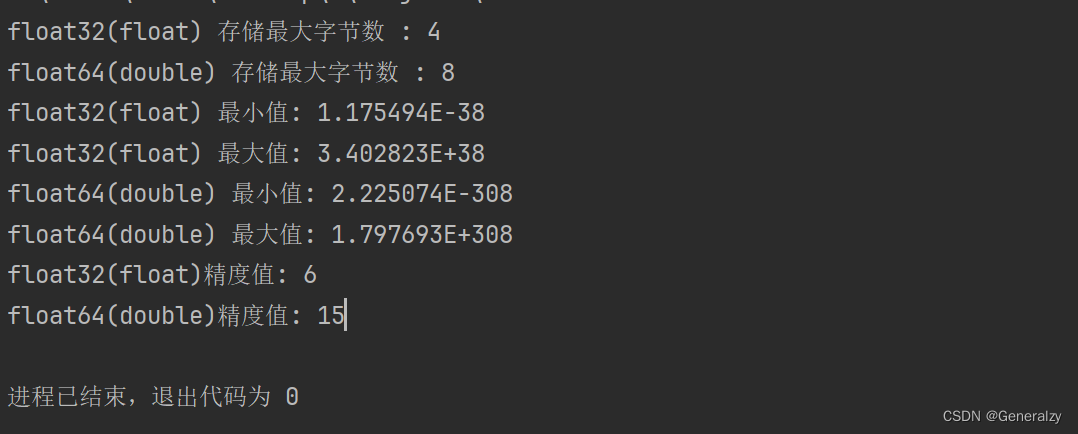
这里可以对比一下go的:
package main
import (
"fmt"
"math"
"unsafe"
)
func main() {
nullFloat64 := *new(float64)
fmt.Println(unsafe.Sizeof(nullFloat64))
nullFloat32 := *new(float32)
fmt.Println(unsafe.Sizeof(nullFloat32))
fmt.Println("float32最大值:", math.MaxFloat32)
fmt.Println("float64最大值:", math.MaxFloat64)
}
void 类型
void 类型指定没有可用的值。它通常用于以下三种情况下:
| 序号 | 类型与描述 |
|---|---|
| 1 | 函数返回为空 C 中有各种函数都不返回值,或者您可以说它们返回空。不返回值的函数的返回类型为空。例如 void exit (int status); |
| 2 | 函数参数为空 C 中有各种函数不接受任何参数。不带参数的函数可以接受一个 void。例如 int rand(void); |
| 3 | 指针指向 void 类型为 void * 的指针代表对象的地址,而不是类型。例如,内存分配函数 void *malloc( size_t size ); 返回指向 void 的指针,可以转换为任何数据类型。 |
字符类型
字符类型指的是单个字符,类型声明使用char关键字。
char c = 'B';
上面示例声明了变量c是字符类型,并将其赋值为字母B。
C 语言规定,字符常量必须放在单引号里面。
在计算机内部,字符类型使用一个字节(8位)存储。C 语言将其当作整数处理,所以字符类型就是宽度为一个字节的整数。每个字符对应一个整数(由 ASCII 码确定),比如B对应整数66。
字符类型在不同计算机的默认范围是不一样的。一些系统默认为-128到127,另一些系统默认为0到255。这两种范围正好都能覆盖0到127的 ASCII 字符范围。
只要在字符类型的范围之内,整数与字符是可以互换的,都可以赋值给字符类型的变量。
char c = 66;
// 等同于
char c = 'B';
上面示例中,变量c是字符类型,赋给它的值是整数66。这跟赋值为字符B的效果是一样的。
两个字符类型的变量可以进行数学运算。
char a = 'B'; // 等同于 char a = 66;
char b = 'C'; // 等同于 char b = 67;
printf("%d\n", a + b); // 输出 133
上面示例中,字符类型变量a和b相加,视同两个整数相加。占位符%d表示输出十进制整数,因此输出结果为133。
单引号本身也是一个字符,如果要表示这个字符常量,必须使用反斜杠转义。
char t = '\'';
上面示例中,变量t为单引号字符,由于字符常量必须放在单引号里面,所以内部的单引号要使用反斜杠转义。
这种转义的写法,主要用来表示 ASCII 码定义的一些无法打印的控制字符,它们也属于字符类型的值。
\a:警报,这会使得终端发出警报声或出现闪烁,或者两者同时发生。\b:退格键,光标回退一个字符,但不删除字符。\f:换页符,光标移到下一页。在现代系统上,这已经反映不出来了,行为改成类似于\v。\n:换行符。\r:回车符,光标移到同一行的开头。\t:制表符,光标移到下一个水平制表位,通常是下一个8的倍数。\v:垂直分隔符,光标移到下一个垂直制表位,通常是下一行的同一列。\0:null 字符,代表没有内容。注意,这个值不等于数字0。
转义写法还能使用八进制和十六进制表示一个字符。
- \nn:字符的八进制写法,nn为八进制值。
- \xnn:字符的十六进制写法,nn为十六进制值。
char x = 'B';
char x = 66;
char x = '\102'; // 八进制
char x = '\x42'; // 十六进制
上面示例的四种写法都是等价的。
布尔类型
C 语言原来并没有为布尔值单独设置一个类型,而是使用整数0表示伪,所有非零值表示真。
int x = 1;
if (x) {
printf("x is true!\n");
}
上面示例中,变量x等于1,C 语言就认为这个值代表真,从而会执行判断体内部的代码。
C99 标准添加了类型_Bool,表示布尔值。但是,这个类型其实只是整数类型的别名,还是使用0表示伪,1表示真,下面是一个示例。
_Bool isNormal;
isNormal = 1;
if (isNormal)
printf("Everything is OK.\n");
头文件stdbool.h定义了另一个类型别名bool,并且定义了true代表1、false代表0。只要加载这个头文件,就可以使用这几个关键字。
#include <stdbool.h>
bool flag = false;
上面示例中,加载头文件stdbool.h以后,就可以使用bool定义布尔值类型,以及false和true表示真伪。
溢出
每一种数据类型都有数值范围,如果存放的数值超出了这个范围(小于最小值或大于最大值),需要更多的二进制位存储,就会发生溢出。大于最大值,叫做向上溢出(overflow);小于最小值,叫做向下溢出(underflow)。
一般来说,编译器不会对溢出报错,会正常执行代码,但是会忽略多出来的二进制位,只保留剩下的位,这样往往会得到意想不到的结果。所以,应该避免溢出。
unsigned char x = 255;
x = x + 1;
printf("%d\n", x); // 0
上面示例中,变量x加1,得到的结果不是256,而是0。因为x是unsign char类型,最大值是255(二进制11111111),加1后就发生了溢出,256(二进制100000000)的最高位1被丢弃,剩下的值就是0。
再看下面的例子。
unsigned int ui = UINT_MAX; // 4,294,967,295
ui++;
printf("ui = %u\n", ui); // 0
ui--;
printf("ui = %u\n", ui); // 4,294,967,295
上面示例中,常量UINT_MAX是 unsigned int 类型的最大值。如果加1,对于该类型就会溢出,从而得到0;而0是该类型的最小值,再减1,又会得到UINT_MAX。
溢出很容易被忽视,编译器又不会报错,所以必须非常小心。
for (unsigned int i = n; i >= 0; --i) // 错误
上面代码表面看似乎没有问题,但是循环变量i的类型是 unsigned int,这个类型的最小值是0,不可能得到小于0的结果。当i等于0,再减去1的时候,并不会返回-1,而是返回 unsigned int 的类型最大值,这个值总是大于等于0,导致无限循环。
为了避免溢出,最好方法就是将运算结果与类型的极限值进行比较。
unsigned int ui;
unsigned int sum;
// 错误
if (sum + ui > UINT_MAX) too_big();
else sum = sum + ui;
// 正确
if (ui > UINT_MAX - sum) too_big();
else sum = sum + ui;
上面示例中,变量sum和ui都是 unsigned int 类型,它们相加的和还是 unsigned int 类型,这就有可能发生溢出。但是,不能通过相加的和是否超出了最大值UINT_MAX,来判断是否发生了溢出,因为sum + ui总是返回溢出后的结果,不可能大于UINT_MAX。正确的比较方法是,判断UINT_MAX - sum与ui之间的大小关系。
下面是另一种错误的写法。
unsigned int i = 5;
unsigned int j = 7;
if (i - j < 0) // 错误
printf("negative\n");
else
printf("positive\n");
上面示例的运算结果,会输出positive。原因是变量i和j都是 unsigned int 类型,i - j的结果也是这个类型,最小值为0,不可能得到小于0的结果。正确的写法是写成下面这样。
if (j > i) // ....
sizeof 运算符
sizeof是 C 语言提供的一个运算符,返回某种数据类型或某个值占用的字节数量。它的参数可以是数据类型的关键字,也可以是变量名或某个具体的值。
// 参数为数据类型
int x = sizeof(int);
// 参数为变量
int i;
sizeof(i);
// 参数为数值
sizeof(3.14);
上面的第一个示例,返回得到int类型占用的字节数量(通常是4或8)。第二个示例返回整数变量占用字节数量,结果与前一个示例完全一样。第三个示例返回浮点数3.14占用的字节数量,由于浮点数的字面量一律存储为 double 类型,所以会返回8,因为 double 类型占用的8个字节。
sizeof运算符的返回值,C 语言只规定是无符号整数,并没有规定具体的类型,而是留给系统自己去决定,sizeof到底返回什么类型。不同的系统中,返回值的类型有可能是unsigned int,也有可能是unsigned long,甚至是unsigned long long,对应的printf()占位符分别是%u、%lu和%llu。这样不利于程序的可移植性。
C 语言提供了一个解决方法,创造了一个类型别名size_t,用来统一表示sizeof的返回值类型。该别名定义在stddef.h头文件(引入stdio.h时会自动引入)里面,对应当前系统的sizeof的返回值类型,可能是unsigned int,也可能是unsigned long。
C 语言还提供了一个常量SIZE_MAX,表示size_t可以表示的最大整数。所以,size_t能够表示的整数范围为[0, SIZE_MAX]。
printf()有专门的占位符%zd或%zu,用来处理size_t类型的值。
printf("%zd\n", sizeof(int));
上面代码中,不管sizeof返回值的类型是什么,%zd占位符(或%zu)都可以正确输出。
如果当前系统不支持%zd或%zu,可使用%u(unsigned int)或%lu(unsigned long int)代替。
类型转换
类型转换是将一个数据类型的值转换为另一种数据类型的值。
C 语言中有两种类型转换:
-
隐式类型转换:隐式类型转换是在表达式中自动发生的,无需进行任何明确的指令或函数调用。它通常是将一种较小的类型自动转换为较大的类型,例如,将int类型转换为long类型或float类型转换为double类型。隐式类型转换也可能会导致数据精度丢失或数据截断。
-
显式类型转换:显式类型转换需要使用强制类型转换运算符(type casting operator),它可以将一个数据类型的值强制转换为另一种数据类型的值。强制类型转换可以使程序员在必要时对数据类型进行更精确的控制,但也可能会导致数据丢失或截断。
隐式类型转换实例:
int i = 10;
float f = 3.14;
double d = i + f; // 隐式将int类型转换为double类型
显式类型转换实例(只要在一个值或变量的前面,使用圆括号指定类型(type),就可以将这个值或变量转为指定的类型,这叫做“类型指定”(casting)。):
double d = 3.14159;
int i = (int)d; // 显式将double类型转换为int类型
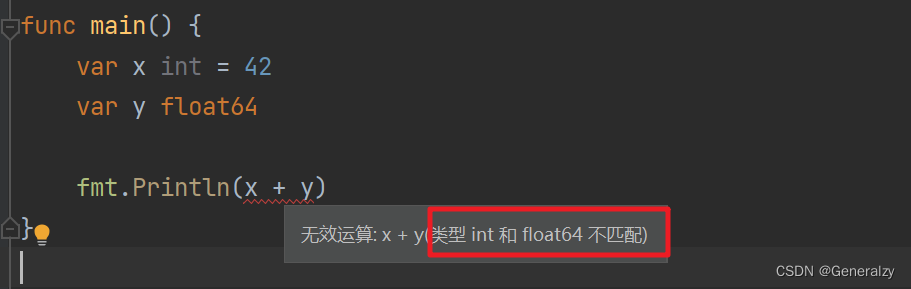
值得一提的是,Go 中没有隐式类型转换,所有的类型转换都需要显式地进行。
在 Go 中,如果你要将一个值从一种类型转换为另一种类型,你需要使用显式的类型转换语法。例如:
package main
import "fmt"
func main() {
var x int = 42
var y float64
// 显式类型转换
y = float64(x)
fmt.Printf("x: %d, y: %f\n", x, y)
}
也就是上述C代码在go中会报错:
可移植类型
C 语言的整数类型(short、int、long)在不同计算机上,占用的字节宽度可能是不一样的,无法提前知道它们到底占用多少个字节。
程序员有时控制准确的字节宽度,这样的话,代码可以有更好的可移植性,头文件stdint.h创造了一些新的类型别名。
(1)精确宽度类型(exact-width integer type),保证某个整数类型的宽度是确定的。
int8_t:8位有符号整数。int16_t:16位有符号整数。int32_t:32位有符号整数。int64_t:64位有符号整数。uint8_t:8位无符号整数。uint16_t:16位无符号整数。uint32_t:32位无符号整数。uint64_t:64位无符号整数。
上面这些都是类型别名,编译器会指定它们指向的底层类型。比如,某个系统中,如果int类型为32位,int32_t就会指向int;如果long类型为32位,int32_t则会指向long。
#include <stdio.h>
#include <stdint.h>
int main(void) {
int32_t x32 = 45933945;
printf("x32 = %d\n", x32);
return 0;
}
上面示例中,变量x32声明为int32_t类型,可以保证是32位的宽度。
(2)最小宽度类型(minimum width type),保证某个整数类型的最小长度。
int_least8_tint_least16_tint_least32_tint_least64_tuint_least8_tuint_least16_tuint_least32_tuint_least64_t
上面这些类型,可以保证占据的字节不少于指定宽度。比如,int_least8_t表示可以容纳8位有符号整数的最小宽度的类型。
(3)最快的最小宽度类型(fast minimum width type),可以使整数计算达到最快的类型。
int_fast8_tint_fast16_tint_fast32_tint_fast64_tuint_fast8_tuint_fast16_tuint_fast32_tuint_fast64_t
上面这些类型是保证字节宽度的同时,追求最快的运算速度,比如int_fast8_t表示对于8位有符号整数,运算速度最快的类型。这是因为某些机器对于特定宽度的数据,运算速度最快,举例来说,32位计算机对于32位数据的运算速度,会快于16位数据。
(4)可以保存指针的整数类型。
- intptr_t:可以存储指针(内存地址)的有符号整数类型。
- uintptr_t:可以存储指针的无符号整数类型。
(5)最大宽度整数类型,用于存放最大的整数。
-
intmax_t:可以存储任何有效的有符号整数的类型。
-
uintmax_t:可以存放任何有效的无符号整数的类型。
上面的这两个类型的宽度比long long和unsigned long更大。
C 变量
变量其实只不过是程序可操作的存储区的名称。C 中每个变量都有特定的类型,类型决定了变量存储的大小和布局,该范围内的值都可以存储在内存中,运算符可应用于变量上。
变量的名称可以由字母、数字和下划线字符组成。它必须以字母或下划线开头。大写字母和小写字母是不同的,因为 C 是大小写敏感的。基于前一章讲解的基本类型,有以下几种基本的变量类型:
| 类型 | 描述 |
|---|---|
| char | 通常是一个字节(八位), 这是一个整数类型。 |
| int | 整型,4 个字节,取值范围 -2147483648 到 2147483647。 |
| float | 单精度浮点值。单精度是这样的格式,1位符号,8位指数,23位小数。 |
| double | 双精度浮点值。双精度是1位符号,11位指数,52位小数。
|
| void | 表示类型的缺失。 |


C 语言也允许定义各种其他类型的变量,比如枚举、指针、数组、结构、共用体等等
C 中的变量定义
变量定义就是告诉编译器在何处创建变量的存储,以及如何创建变量的存储。变量定义指定一个数据类型,并包含了该类型的一个或多个变量的列表,如下所示:
type variable_list;
type 表示变量的数据类型,可以是整型、浮点型、字符型、指针等,也可以是用户自定义的对象。
variable_list 可以由一个或多个变量的名称组成,多个变量之间用逗号,分隔,变量由字母、数字和下划线组成,且以字母或下划线开头。
下面列出几个有效的声明:
定义整型变量:
int age;
以上代码中,age 被定义为一个整型变量。
定义浮点型变量:
float salary;
以上代码中,salary 被定义为一个浮点型变量。
定义字符型变量:
char grade;
以上代码中,grade 被定义为一个字符型变量。
定义指针变量:
int *ptr;
以上代码中,ptr 被定义为一个整型指针变量。
定义多个变量:
int i, j, k;
int i, j, k; 声明并定义了变量 i、j 和 k,这指示编译器创建类型为 int 的名为 i、j、k 的变量。
变量初始化
在 C 语言中,变量的初始化是在定义变量的同时为其赋予一个初始值。变量的初始化可以在定义时进行,也可以在后续的代码中进行。
初始化器由一个等号,后跟一个常量表达式组成,如下所示:
type variable_name = value;
其中,type 表示变量的数据类型,variable_name 是变量的名称,value 是变量的初始值。下面列举几个实例:
int x = 10; // 整型变量 x 初始化为 10
float pi = 3.14; // 浮点型变量 pi 初始化为 3.14
char ch = 'A'; // 字符型变量 ch 初始化为字符 'A'
extern int d = 3, f = 5; // d 和 f 的声明与初始化
int d = 3, f = 5; // 定义并初始化 d 和 f
byte z = 22; // 定义并初始化 z
后续初始化变量:
在变量定义后的代码中,可以使用赋值运算符 = 为变量赋予一个新的值。
type variable_name; // 变量定义
variable_name = new_value; // 变量初始化
实例如下:
int x; // 整型变量x定义
x = 20; // 变量x初始化为20
float pi; // 浮点型变量pi定义
pi = 3.14159; // 变量pi初始化为3.14159
char ch; // 字符型变量ch定义
ch = 'B'; // 变量ch初始化为字符'B'
需要注意的是,变量在使用之前应该被初始化。未初始化的变量的值是未定义的,可能包含任意的垃圾值。因此,为了避免不确定的行为和错误,建议在使用变量之前进行初始化。
变量不初始化
在 C 语言中,如果变量没有显式初始化,那么它的默认值将取决于该变量的类型和其所在的作用域。
对于全局变量和静态变量(在函数内部定义的静态变量和在函数外部定义的全局变量),它们的默认初始值为零。
以下是不同类型的变量在没有显式初始化时的默认值:
- 整型变量(int、short、long等):默认值为0。
- 浮点型变量(float、double等):默认值为0.0。
- 字符型变量(char):默认值为’\0’,即空字符。
- 指针变量:默认值为NULL,表示指针不指向任何有效的内存地址。
- 数组、结构体、联合等复合类型的变量:它们的元素或成员将按照相应的规则进行默认初始化,这可能包括对元素递归应用默认规则。
需要注意的是,局部变量(在函数内部定义的非静态变量)不会自动初始化为默认值,它们的初始值是未定义的(包含垃圾值)。因此,在使用局部变量之前,应该显式地为其赋予一个初始值。
总结起来,C 语言中变量的默认值取决于其类型和作用域。全局变量和静态变量的默认值为 0,字符型变量的默认值为 \0,指针变量的默认值为 NULL,而局部变量没有默认值,其初始值是未定义的。
#include <stdio.h>
void myFunction() {
int x; // 未初始化的局部变量
printf("The value of x is: %d\n", x);
}
int main() {
myFunction();
return 0;
}

C 中的变量声明
变量声明向编译器保证变量以指定的类型和名称存在,这样编译器在不需要知道变量完整细节的情况下也能继续进一步的编译。变量声明只在编译时有它的意义,在程序连接时编译器需要实际的变量声明。
变量的声明有两种情况:
- 1、一种是需要建立存储空间的。例如:int a 在声明的时候就已经建立了存储空间。
- 2、另一种是不需要建立存储空间的,通过使用extern关键字声明变量名而不定义它。 例如:extern int a 其中变量 a 可以在别的文件中定义的。
- 除非有extern关键字,否则都是变量的定义。
extern int i; //声明,不是定义
int i; //声明,也是定义
如下实例,其中,变量在头部就已经被声明,但是定义与初始化在主函数内:
#include <stdio.h>
// 函数外定义变量 x 和 y
int x;
int y;
int addtwonum()
{
// 函数内声明变量 x 和 y 为外部变量
extern int x;
extern int y;
// 给外部变量(全局变量)x 和 y 赋值
x = 1;
y = 2;
return x+y;
}
int main()
{
int result;
// 调用函数 addtwonum
result = addtwonum();
printf("result 为: %d",result);
return 0;
}
当上面的代码被编译和执行时,它会产生下列结果:
result 为: 3
如果需要在一个源文件中引用另外一个源文件中定义的变量,我们只需在引用的文件中将变量加上 extern 关键字的声明即可。
addtwonum.c 文件代码:
#include <stdio.h>
/*外部变量声明*/
extern int x ;
extern int y ;
int addtwonum()
{
return x+y;
}
main.c 文件代码:
#include <stdio.h>
#include "addtwonum.c"
/*定义两个全局变量*/
int x=1;
int y=2;
int addtwonum();
int main(void)
{
int result;
result = addtwonum();
printf("result 为: %d\n",result);
return 0;
}
当上面的代码被编译和执行时,它会产生下列结果:
$ gcc addtwonum.c test.c -o main
$ ./main
result 为: 3
C 中的左值(Lvalues)和右值(Rvalues)
C 中有两种类型的表达式:
- 左值(lvalue):指向内存位置的表达式被称为左值(lvalue)表达式。左值可以出现在赋值号的左边或右边。
- 右值(rvalue):术语右值(rvalue)指的是存储在内存中某些地址的数值。右值是不能对其进行赋值的表达式,也就是说,右值可以出现在赋值号的右边,但不能出现在赋值号的左边。
变量是左值,因此可以出现在赋值号的左边。数值型的字面值是右值,因此不能被赋值,不能出现在赋值号的左边。下面是一个有效的语句:
int g = 20;
但是下面这个就不是一个有效的语句,会生成编译时错误:
10 = 20;
变量的作用域
作用域(scope)指的是变量生效的范围。C 语言的变量作用域主要有两种:文件作用域(file scope)和块作用域(block scope)。
文件作用域(file scope)指的是,在源码文件顶层声明的变量,从声明的位置到文件结束都有效。
int x = 1;
int main(void) {
printf("%i\n", x);
}
上面示例中,变量x是在文件顶层声明的,从声明位置开始的整个当前文件都是它的作用域,可以在这个范围的任何地方读取这个变量,比如函数main()内部就可以读取这个变量。
块作用域(block scope)指的是由大括号({})组成的代码块,它形成一个单独的作用域。凡是在块作用域里面声明的变量,只在当前代码块有效,代码块外部不可见。
int a = 12;
if (a == 12) {
int b = 99;
printf("%d %d\n", a, b); // 12 99
}
printf("%d\n", a); // 12
printf("%d\n", b); // 出错
上面例子中,变量b是在if代码块里面声明的,所以对于大括号外面的代码,这个变量是不存在的。
代码块可以嵌套,即代码块内部还有代码块,这时就形成了多层的块作用域。它的规则是:内层代码块可以使用外层声明的变量,但外层不可以使用内层声明的变量。如果内层的变量与外层同名,那么会在当前作用域覆盖外层变量。
{
int i = 10;
{
int i = 20;
printf("%d\n", i); // 20
}
printf("%d\n", i); // 10
}
上面示例中,内层和外层都有一个变量i,每个作用域都会优先使用当前作用域声明的i。
最常见的块作用域就是函数,函数内部声明的变量,对于函数外部是不可见的。for循环也是一个块作用域,循环变量只对循环体内部可见,外部是不可见的。
for (int i = 0; i < 10; i++)
printf("%d\n", i);
printf("%d\n", i); // 出错
上面示例中,for循环省略了大括号,但依然是一个块作用域,在外部读取循环变量i,编译器就会报错。
C 常量
常量是固定值,在程序执行期间不会改变。这些固定的值,又叫做字面量。
常量可以是任何的基本数据类型,比如整数常量、浮点常量、字符常量,或字符串字面值,也有枚举常量。
常量就像是常规的变量,只不过常量的值在定义后不能进行修改。
常量可以直接在代码中使用,也可以通过定义常量来使用。
整数常量
整数常量可以是十进制、八进制或十六进制的常量。前缀指定基数:0x 或 0X 表示十六进制,0 表示八进制,不带前缀则默认表示十进制。
整数常量也可以带一个后缀,后缀是 U 和 L 的组合,U 表示无符号整数(unsigned),L 表示长整数(long)。后缀可以是大写,也可以是小写,U 和 L 的顺序任意。
下面列举几个整数常量的实例:
212 /* 合法的 */
215u /* 合法的 */
0xFeeL /* 合法的 long类型的16进制数字 */
078 /* 非法的:8 不是八进制的数字 */
032UU /* 非法的:不能重复后缀 */
以下是各种类型的整数常量的实例:
85 /* 十进制 */
0213 /* 八进制 */
0x4b /* 十六进制 */
30 /* 整数 */
30u /* 无符号整数 */
30l /* 长整数 */
30ul /* 无符号长整数 */
整数常量可以带有一个后缀表示数据类型,例如:
int myInt = 10;
long myLong = 100000L;
unsigned int myUnsignedInt = 10U;
浮点常量
浮点常量由整数部分、小数点、小数部分和指数部分组成。您可以使用小数形式或者指数形式来表示浮点常量。
当使用小数形式表示时,必须包含整数部分、小数部分,或同时包含两者。当使用指数形式表示时, 必须包含小数点、指数,或同时包含两者。带符号的指数是用 e 或 E 引入的。
下面列举几个浮点常量的实例:
3.14159 /* 合法的 */
314159E-5L /* 合法的 */
510E /* 非法的:不完整的指数 */
210f /* 非法的:没有小数或指数 */
.e55 /* 非法的:缺少整数或分数 */
浮点数常量可以带有一个后缀表示数据类型,例如:
float myFloat = 3.14f;
double myDouble = 3.14159;
314159e-5 是科学计数法表示的数值,它可以解释为 314159 乘以 10 的负 5 次方(或者除以 10 的 5 次方)。
具体地说,这个数值等于:
![[314159 \times 10^{-5} = \frac{314159}{10^5} = 3.14159]](https://img-blog.csdnimg.cn/direct/e68c7682676346d1b849bba81dc390f7.png)
因此,314159e-5 的值就是 3.14159。科学计数法通常用于表示非常大或非常小的数,以便更容易理解和书写。
字符常量
字符常量是括在单引号中,例如,‘x’ 可以存储在 char 类型的简单变量中。
字符常量可以是一个普通的字符(例如 ‘x’)、一个转义序列(例如 ‘\t’),或一个通用的字符(例如 ‘\u02C0’)。
在 C 中,有一些特定的字符,当它们前面有反斜杠时,它们就具有特殊的含义,被用来表示如换行符(\n)或制表符(\t)等。下表列出了一些这样的转义序列码:
| 转义序列 | 含义 |
|---|---|
| \\ | \ 字符 |
| \' | ' 字符 |
| \" | " 字符 |
| \? | ? 字符 |
| \a | 警报铃声 |
| \b | 退格键 |
| \f | 换页符 |
| \n | 换行符 |
| \r | 回车 |
| \t | 水平制表符 |
| \v | 垂直制表符 |
| \ooo | 一到三位的八进制数 |
| \xhh . . . | 一个或多个数字的十六进制数 |
下面的实例显示了一些转义序列字符:
#include <stdio.h>
int main()
{
printf("Hello\tWorld\n\n");
return 0;
}
当上面的代码被编译和执行时,它会产生下列结果:
Hello World
字符常量的 ASCII 值可以通过强制类型转换转换为整数值。
char myChar = 'a';
int myAsciiValue = (int) myChar; // 将 myChar 转换为 ASCII 值 97
字符串常量
字符串字面值或常量是括在双引号 " " 中的。一个字符串包含类似于字符常量的字符:普通的字符、转义序列和通用的字符。
您可以使用空格做分隔符,把一个很长的字符串常量进行分行。
下面的实例显示了一些字符串常量。下面这三种形式所显示的字符串是相同的。
"hello, dear"
"hello, \
dear"
"hello, " "d" "ear"
字符串常量在内存中以 null 终止符 \0 结尾。例如:
char myString[] = "Hello, world!"; //系统对字符串常量自动加一个 '\0'
定义常量
在 C 中,有两种简单的定义常量的方式:
- 使用 #define 预处理器: #define 可以在程序中定义一个常量,它在编译时会被替换为其对应的值。
- 使用 const 关键字:const 关键字用于声明一个只读变量,即该变量的值不能在程序运行时修改。
#define 预处理器
下面是使用 #define 预处理器定义常量的形式:
#define 常量名 常量值
下面的代码定义了一个名为 PI 的常量:
#define PI 3.14159在程序中使用该常量时,编译器会将所有的 PI 替换为 3.14159。
#include <stdio.h>
#define LENGTH 10
#define WIDTH 5
#define NEWLINE '\n'
int main()
{
int area;
area = LENGTH * WIDTH;
printf("value of area : %d", area);
printf("%c", NEWLINE);
return 0;
}
当上面的代码被编译和执行时,它会产生下列结果:
value of area : 50
const 关键字
可以使用 const 前缀声明指定类型的常量,如下所示:
const 数据类型 常量名 = 常量值;
下面的代码定义了一个名为MAX_VALUE的常量:
const int MAX_VALUE = 100;
在程序中使用该常量时,其值将始终为100,并且不能被修改。

const 声明常量要在一个语句内完成:

#define 与 const 区别
#define 与 const 这两种方式都可以用来定义常量,选择哪种方式取决于具体的需求和编程习惯。通常情况下,建议使用 const 关键字来定义常量,因为它具有类型检查和作用域的优势,而 #define 仅进行简单的文本替换,可能会导致一些意外的问题。
#define 预处理指令和 const 关键字在定义常量时有一些区别:
-
替换机制:#define 是进行简单的文本替换,而 const 是声明一个具有类型的常量。#define 定义的常量在编译时会被直接替换为其对应的值,而 const 定义的常量在程序运行时会分配内存,并且具有类型信息。
-
类型检查:#define 不进行类型检查,因为它只是进行简单的文本替换。而 const 定义的常量具有类型信息,编译器可以对其进行类型检查。这可以帮助捕获一些潜在的类型错误。
-
作用域:#define 定义的常量没有作用域限制,它在定义之后的整个代码中都有效。而 const 定义的常量具有块级作用域,只在其定义所在的作用域内有效。
-
调试和符号表:使用 #define 定义的常量在符号表中不会有相应的条目,因为它只是进行文本替换。而使用 const 定义的常量会在符号表中有相应的条目,有助于调试和可读性。
C 存储类(变量说明符)
存储类定义 C 程序中变量/函数的存储位置、生命周期和作用域。
这些说明符放置在它们所修饰的类型之前。
下面列出 C 程序中可用的存储类:
- const
- static
- auto
- extern
- register
- volatile
- restrict
const
const说明符表示变量是只读的,不得被修改。
const double PI = 3.14159;
PI = 3; // 报错
上面示例里面的const,表示变量PI的值不应改变。如果改变的话,编译器会报错。
对于数组,const表示数组成员不能修改。
const int arr[] = {1, 2, 3, 4};
arr[0] = 5; // 报错
上面示例中,const使得数组arr的成员无法修改。
对于指针变量,const有两种写法,含义是不一样的。如果const在*前面,表示指针指向的值不可修改。
// const 表示指向的值 *x 不能修改
int const * x
// 或者
const int * x
下面示例中,对x指向的值进行修改导致报错。
int p = 1
const int* x = &p;
(*x)++; // 报错
如果const在*后面,表示指针包含的地址不可修改。
// const 表示地址 x 不能修改
int* const x
下面示例中,对x进行修改导致报错。
int p = 1
int* const x = &p;
x++; // 报错
这两者可以结合起来。
const char* const x;
上面示例中,指针变量x指向一个字符串。两个const意味着,x包含的内存地址以及x指向的字符串,都不能修改。
const的一个用途,就是防止函数体内修改函数参数。如果某个参数在函数体内不会被修改,可以在函数声明时,对该参数添加const说明符。这样的话,使用这个函数的人看到原型里面的const,就知道调用函数前后,参数数组保持不变。
void find(const int* arr, int n);
上面示例中,函数find的参数数组arr有const说明符,就说明该数组在函数内部将保持不变。
有一种情况需要注意,如果一个指针变量指向const变量,那么该指针变量也不应该被修改。
const int i = 1;
int* j = &i;
*j = 2; // 报错
上面示例中,j是一个指针变量,指向变量i,即j和i指向同一个地址。j本身没有const说明符,但是i有。这种情况下,j指向的值也不能被修改。
auto 存储类
auto 存储类是所有局部变量默认的存储类。
定义在函数中的变量默认为 auto 存储类,这意味着它们在函数开始时被创建,在函数结束时被销毁。
{
int mount;
auto int month;
}
上面的实例定义了两个带有相同存储类的变量,auto 只能用在函数内,即 auto 只能修饰局部变量。
这属于默认行为,所以该说明符没有实际作用,一般都省略不写。
register 存储类
register 存储类用于定义存储在寄存器中而不是 RAM 中的局部变量。这意味着变量的最大尺寸等于寄存器的大小(通常是一个字),且不能对它应用一元的 ‘&’ 运算符(因为它没有内存位置)。
register 存储类定义存储在寄存器,所以变量的访问速度更快,但是它不能直接取地址,因为它不是存储在 RAM 中的。在需要频繁访问的变量上使用 register 存储类可以提高程序的运行速度。
{
register int miles;
}
寄存器只用于需要快速访问的变量,比如计数器。还应注意的是,定义 ‘register’ 并不意味着变量将被存储在寄存器中,它意味着变量可能存储在寄存器中,这取决于硬件和实现的限制。
static 存储类
static说明符对于全局变量和局部变量有不同的含义。
(1)用于局部变量(位于块作用域内部)。
static用于函数内部声明的局部变量时,表示该变量的值会在函数每次执行后得到保留,下次执行时不会进行初始化,就类似于一个只用于函数内部的全局变量。由于不必每次执行函数时,都对该变量进行初始化,这样可以提高函数的执行速度,详见《函数》一章。
(2)用于全局变量(位于块作用域外部)。
static用于函数外部声明的全局变量时,表示该变量只用于当前文件,其他源码文件不可以引用该变量,即该变量不会被链接(link)。
static修饰的变量,初始化时,值不能等于变量,必须是常量。
static 存储类指示编译器在程序的生命周期内保持局部变量的存在,而不需要在每次它进入和离开作用域时进行创建和销毁。因此,使用 static 修饰局部变量可以在函数调用之间保持局部变量的值。
static 修饰符也可以应用于全局变量。当 static 修饰全局变量时,会使变量的作用域限制在声明它的文件内。
全局声明的一个 static 变量或方法可以被任何函数或方法调用,只要这些方法出现在跟 static 变量或方法同一个文件中。
静态变量在程序中只被初始化一次,即使函数被调用多次,该变量的值也不会重置。
以下实例演示了 static 修饰全局变量和局部变量的应用:
#include <stdio.h>
/* 函数声明 */
void func1(void);
static int count=10; /* 全局变量 - static 是默认的 */
int main()
{
while (count--) {
func1();
}
return 0;
}
void func1(void)
{
/* 'thingy' 是 'func1' 的局部变量 - 只初始化一次
* 每次调用函数 'func1' 'thingy' 值不会被重置。
*/
static int thingy=5;
thingy++;
printf(" thingy 为 %d , count 为 %d\n", thingy, count);
}
实例中 count 作为全局变量可以在函数内使用,thingy 使用 static 修饰后,不会在每次调用时重置。
thingy 为 6 , count 为 9
thingy 为 7 , count 为 8
thingy 为 8 , count 为 7
thingy 为 9 , count 为 6
thingy 为 10 , count 为 5
thingy 为 11 , count 为 4
thingy 为 12 , count 为 3
thingy 为 13 , count 为 2
thingy 为 14 , count 为 1
thingy 为 15 , count 为 0
extern 存储类
extern说明符表示,该变量在其他文件里面声明,没有必要在当前文件里面为它分配空间。通常用来表示,该变量是多个文件共享的。
extern int a;
上面代码中,a是extern变量,表示该变量在其他文件里面定义和初始化,当前文件不必为它分配存储空间。
但是,变量声明时,同时进行初始化,extern就会无效。
// extern 无效
extern int i = 0;
// 等同于
int i = 0;
上面代码中,extern对变量初始化的声明是无效的。这是为了防止多个extern对同一个变量进行多次初始化。
函数内部使用extern声明变量,就相当于该变量是静态存储,每次执行时都要从外部获取它的值。
函数本身默认是extern,即该函数可以被外部文件共享,通常省略extern不写。如果只希望函数在当前文件可用,那就需要在函数前面加上static。
extern int f(int i);
// 等同于
int f(int i);
extern 存储类用于定义在其他文件中声明的全局变量或函数。当使用 extern 关键字时,不会为变量分配任何存储空间,而只是指示编译器该变量在其他文件中定义。
extern 存储类用于提供一个全局变量的引用,全局变量对所有的程序文件都是可见的。当您使用 extern 时,对于无法初始化的变量,会把变量名指向一个之前定义过的存储位置。
当您有多个文件且定义了一个可以在其他文件中使用的全局变量或函数时,可以在其他文件中使用 extern 来得到已定义的变量或函数的引用。可以这么理解,extern 是用来在另一个文件中声明一个全局变量或函数。
extern 修饰符通常用于当有两个或多个文件共享相同的全局变量或函数的时候,如下所示:
第一个文件:main.c
#include <stdio.h>
int count ;
extern void write_extern();
int main()
{
count = 5;
write_extern();
}
第二个文件:support.c
#include <stdio.h>
extern int count;
void write_extern(void)
{
printf("count is %d\n", count);
}
在这里,第二个文件中的 extern 关键字用于声明已经在第一个文件 main.c 中定义的 count。现在 ,编译这两个文件,如下所示:
$ gcc main.c support.c
这会产生 a.out 可执行程序,当程序被执行时,它会产生下列结果:
count is 5
volatile
volatile说明符表示所声明的变量,可能会预想不到地发生变化(即其他程序可能会更改它的值),不受当前程序控制,因此编译器不要对这类变量进行优化,每次使用时都应该查询一下它的值。硬件设备的编程中,这个说明符很常用。
volatile int foo;
volatile int* bar;
volatile的目的是阻止编译器对变量行为进行优化,请看下面的例子。
int foo = x;
// 其他语句,假设没有改变 x 的值
int bar = x;
上面代码中,由于变量foo和bar都等于x,而且x的值也没有发生变化,所以编译器可能会把x放入缓存,直接从缓存读取值(而不是从 x 的原始内存位置读取),然后对foo和bar进行赋值。如果x被设定为volatile,编译器就不会把它放入缓存,每次都从原始位置去取x的值,因为在两次读取之间,其他程序可能会改变x。
restrict
restrict说明符允许编译器优化某些代码。它只能用于指针,表明该指针是访问数据的唯一方式。
int* restrict pt = (int*) malloc(10 * sizeof(int));
上面示例中,restrict表示变量pt是访问 malloc 所分配内存的唯一方式。
下面例子的变量foo,就不能使用restrict修饰符。
int foo[10];
int* bar = foo;
上面示例中,变量foo指向的内存,可以用foo访问,也可以用bar访问,因此就不能将foo设为 restrict。
如果编译器知道某块内存只能用一个方式访问,可能可以更好地优化代码,因为不用担心其他地方会修改值。
restrict用于函数参数时,表示参数的内存地址之间没有重叠。
void swap(int* restrict a, int* restrict b) {
int t;
t = *a;
*a = *b;
*b = t;
}
上面示例中,函数参数声明里的restrict表示,参数a和参数b的内存地址没有重叠。
C 运算符
运算符是一种告诉编译器执行特定的数学或逻辑操作的符号。C 语言内置了丰富的运算符,并提供了以下类型的运算符:
- 算术运算符
- 关系运算符
- 逻辑运算符
- 位运算符
- 赋值运算符
- 杂项运算符
算术运算符
下表显示了 C 语言支持的所有算术运算符。假设变量 A 的值为 10,变量 B 的值为 20,则:
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 把两个操作数相加 | A + B 将得到 30 |
| - | 从第一个操作数中减去第二个操作数 | A - B 将得到 -10 |
| * | 把两个操作数相乘 | A * B 将得到 200 |
| / | 分子除以分母 | B / A 将得到 2 |
| % | 取模运算符,整除后的余数 | B % A 将得到 0 |
| ++ | 自增运算符,整数值增加 1 | A++ 将得到 11 |
| -- | 自减运算符,整数值减少 1 | A-- 将得到 9 |
以下实例演示了 a++ 与 ++a 的区别:
#include <stdio.h>
int main()
{
int c;
int a = 10;
c = a++;
printf("先赋值后运算:\n");
printf("Line 1 - c 的值是 %d\n", c );
printf("Line 2 - a 的值是 %d\n", a );
a = 10;
c = a--;
printf("Line 3 - c 的值是 %d\n", c );
printf("Line 4 - a 的值是 %d\n", a );
printf("先运算后赋值:\n");
a = 10;
c = ++a;
printf("Line 5 - c 的值是 %d\n", c );
printf("Line 6 - a 的值是 %d\n", a );
a = 10;
c = --a;
printf("Line 7 - c 的值是 %d\n", c );
printf("Line 8 - a 的值是 %d\n", a );
}
以上程序执行输出结果为:
先赋值后运算:
Line 1 - c 的值是 10
Line 2 - a 的值是 11
Line 3 - c 的值是 10
Line 4 - a 的值是 9
先运算后赋值:
Line 5 - c 的值是 11
Line 6 - a 的值是 11
Line 7 - c 的值是 9
Line 8 - a 的值是 9
Go里面不存在这样++,--的用法,只是简单的认为a++等价于a+=1或a=a+1。
关系运算符
下表显示了 C 语言支持的所有关系运算符。假设变量 A 的值为 10,变量 B 的值为 20,则:
| 运算符 | 描述 | 实例 |
|---|---|---|
| == | 检查两个操作数的值是否相等,如果相等则条件为真。 | (A == B) 为假。 |
| != | 检查两个操作数的值是否相等,如果不相等则条件为真。 | (A != B) 为真。 |
| > | 检查左操作数的值是否大于右操作数的值,如果是则条件为真。 | (A > B) 为假。 |
| < | 检查左操作数的值是否小于右操作数的值,如果是则条件为真。 | (A < B) 为真。 |
| >= | 检查左操作数的值是否大于或等于右操作数的值,如果是则条件为真。 | (A >= B) 为假。 |
| <= | 检查左操作数的值是否小于或等于右操作数的值,如果是则条件为真。 | (A <= B) 为真。 |
逻辑运算符
下表显示了 C 语言支持的所有关系逻辑运算符。假设变量 A 的值为 1,变量 B 的值为 0,则:
| 运算符 | 描述 | 实例 |
|---|---|---|
| && | 称为逻辑与运算符。如果两个操作数都非零,则条件为真。 | (A && B) 为假。 |
| || | 称为逻辑或运算符。如果两个操作数中有任意一个非零,则条件为真。 | (A || B) 为真。 |
| ! | 称为逻辑非运算符。用来逆转操作数的逻辑状态。如果条件为真则逻辑非运算符将使其为假。 | !(A && B) 为真。 |
位运算符
位运算符作用于位,并逐位执行操作。&、 | 和 ^ 的真值表如下所示:
| p | q | p & q | p | q | p ^ q |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 1 | 1 |
| 1 | 1 | 1 | 1 | 0 |
| 1 | 0 | 0 | 1 | 1 |
假设如果 A = 60,且 B = 13,现在以二进制格式表示,它们如下所示:
A = 0011 1100
B = 0000 1101
-----------------
A&B = 0000 1100
A|B = 0011 1101
A^B = 0011 0001
~A = 1100 0011
下表显示了 C 语言支持的位运算符。假设变量 A 的值为 60,变量 B 的值为 13,则:
| 运算符 | 描述 | 实例 |
|---|---|---|
| & | 对两个操作数的每一位执行逻辑与操作,如果两个相应的位都为 1,则结果为 1,否则为 0。 按位与操作,按二进制位进行"与"运算。运算规则: 0&0=0; 0&1=0; 1&0=0; 1&1=1; | (A & B) 将得到 12,即为 0000 1100 |
| | | 对两个操作数的每一位执行逻辑或操作,如果两个相应的位都为 0,则结果为 0,否则为 1。 按位或运算符,按二进制位进行"或"运算。运算规则: 0|0=0; 0|1=1; 1|0=1; 1|1=1; | (A | B) 将得到 61,即为 0011 1101 |
| ^ | 对两个操作数的每一位执行逻辑异或操作,如果两个相应的位值相同,则结果为 0,否则为 1。 异或运算符,按二进制位进行"异或"运算。运算规则: 0^0=0; 0^1=1; 1^0=1; 1^1=0; | (A ^ B) 将得到 49,即为 0011 0001 |
| ~ | 对操作数的每一位执行逻辑取反操作,即将每一位的 0 变为 1,1 变为 0。 取反运算符,按二进制位进行"取反"运算。运算规则: ~1=-2; ~0=-1; | (~A ) 将得到 -61,即为 1100 0011,一个有符号二进制数的补码形式。 |
| << | 将操作数的所有位向左移动指定的位数。左移 n 位相当于乘以 2 的 n 次方。 二进制左移运算符。将一个运算对象的各二进制位全部左移若干位(左边的二进制位丢弃,右边补0)。 | A << 2 将得到 240,即为 1111 0000 |
| >> | 将操作数的所有位向右移动指定的位数。右移n位相当于除以 2 的 n 次方。 二进制右移运算符。将一个数的各二进制位全部右移若干位,正数左补 0,负数左补 1,右边丢弃。 | A >> 2 将得到 15,即为 0000 1111 |
值得一提的是,Go的按位取反和异或的符号是一样的,因为按位取反是单目运算,异或是双目运算,不会造成混淆,所以干脆就一样了:
package main
import "fmt"
func main() {
// 1的按位反 和 2进行位与运算
fmt.Println(^1 ^ 2)
fmt.Println(^1)
fmt.Println(-2 ^ 2)
}

赋值运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 简单的赋值运算符,把右边操作数的值赋给左边操作数 | C = A + B 将把 A + B 的值赋给 C |
| += | 加且赋值运算符,把右边操作数加上左边操作数的结果赋值给左边操作数 | C += A 相当于 C = C + A |
| -= | 减且赋值运算符,把左边操作数减去右边操作数的结果赋值给左边操作数 | C -= A 相当于 C = C - A |
| *= | 乘且赋值运算符,把右边操作数乘以左边操作数的结果赋值给左边操作数 | C *= A 相当于 C = C * A |
| /= | 除且赋值运算符,把左边操作数除以右边操作数的结果赋值给左边操作数 | C /= A 相当于 C = C / A |
| %= | 求模且赋值运算符,求两个操作数的模赋值给左边操作数 | C %= A 相当于 C = C % A |
| <<= | 左移且赋值运算符 | C <<= 2 等同于 C = C << 2 |
| >>= | 右移且赋值运算符 | C >>= 2 等同于 C = C >> 2 |
| &= | 按位与且赋值运算符 | C &= 2 等同于 C = C & 2 |
| ^= | 按位异或且赋值运算符 | C ^= 2 等同于 C = C ^ 2 |
| |= | 按位或且赋值运算符 | C |= 2 等同于 C = C | 2 |
杂项运算符 ? sizeof & 三元
下表列出了 C 语言支持的其他一些重要的运算符,包括 sizeof 和 ? :。
| 运算符 | 描述 | 实例 |
|---|---|---|
| sizeof() | 返回变量的大小。 | sizeof(a) 将返回 4,其中 a 是整数。 |
| & | 返回变量的地址。 | &a; 将给出变量的实际地址。 |
| * | 指向一个变量。 | *a; 将指向一个变量。 |
| ? : | 条件表达式 | 如果条件为真 ? 则值为 X : 否则值为 Y |
#include <stdio.h>
int main()
{
int a = 4;
short b;
double c;
int* ptr;
/* sizeof 运算符实例 */
printf("Line 1 - 变量 a 的大小 = %lu\n", sizeof(a) );
printf("Line 2 - 变量 b 的大小 = %lu\n", sizeof(b) );
printf("Line 3 - 变量 c 的大小 = %lu\n", sizeof(c) );
/* & 和 * 运算符实例 */
ptr = &a; /* 'ptr' 现在包含 'a' 的地址 */
printf("a 的值是 %d\n", a);
printf("*ptr 是 %d\n", *ptr);
/* 三元运算符实例 */
a = 10;
b = (a == 1) ? 20: 30;
printf( "b 的值是 %d\n", b );
b = (a == 10) ? 20: 30;
printf( "b 的值是 %d\n", b );
}
C 中的运算符优先级
运算符的优先级确定表达式中项的组合。这会影响到一个表达式如何计算。某些运算符比其他运算符有更高的优先级,例如,乘除运算符具有比加减运算符更高的优先级。
例如 x = 7 + 3 * 2,在这里,x 被赋值为 13,而不是 20,因为运算符 * 具有比 + 更高的优先级,所以首先计算乘法 3*2,然后再加上 7。
下表将按运算符优先级从高到低列出各个运算符,具有较高优先级的运算符出现在表格的上面,具有较低优先级的运算符出现在表格的下面。在表达式中,较高优先级的运算符会优先被计算。
| 类别? | 运算符? | 结合性? |
|---|---|---|
| 后缀? | () [] -> . ++ - - ? | 从左到右? |
| 一元? | + - ! ~ ++ - - (type)* & sizeof? | 从右到左? |
| 乘除? | * / %? | 从左到右? |
| 加减? | + -? | 从左到右? |
| 移位? | << >>? | 从左到右? |
| 关系? | < <= > >=? | 从左到右? |
| 相等? | == !=? | 从左到右? |
| 位与 AND? | &? | 从左到右? |
| 位异或 XOR? | ^? | 从左到右? |
| 位或 OR? | |? | 从左到右? |
| 逻辑与 AND? | &&? | 从左到右? |
| 逻辑或 OR? | ||? | 从左到右? |
| 条件? | ?:? | 从右到左? |
| 赋值? | = += -= *= /= %=>>= <<= &= ^= |=? | 从右到左? |
| 逗号? | ,? | 从左到右? |
终极大招:加括号。
C 判断
判断结构要求程序员指定一个或多个要评估或测试的条件,以及条件为真时要执行的语句(必需的)和条件为假时要执行的语句(可选的)。
C 语言把任何非零和非空的值假定为 true,把零或 null 假定为 false。(Go中由于没有隐式类型转换,所以分支语句只允许填bool值)
下面是大多数编程语言中典型的判断结构的一般形式:
if 语句
语法:
if(boolean_expression 1){
/* 当布尔表达式 1 为真时执行 */
}else if( boolean_expression 2){
/* 当布尔表达式 2 为真时执行 */
}else if( boolean_expression 3){
/* 当布尔表达式 3 为真时执行 */
}else {
/* 当上面条件都不为真时执行 */
}
int main(void){
int a;
a = change();
if (a == 1){
printf("hello");
}else if (a==2){
printf("world");
}else{
printf(".");
}
return 0;
}
switch语句
一个 switch 语句允许测试一个变量等于多个值时的情况。每个值称为一个 case,且被测试的变量会对每个 switch case 进行检查。
语法:
switch(expression){
case constant-expression :
statement(s);
break; /* 可选的 */
case constant-expression :
statement(s);
break; /* 可选的 */
/* 您可以有任意数量的 case 语句 */
default : /* 可选的 */
statement(s);
}
switch 语句必须遵循下面的规则:
- switch 语句中的 expression 是一个常量表达式,必须是一个整型或枚举类型。
- 在一个 switch 中可以有任意数量的 case 语句。每个 case 后跟一个要比较的值和一个冒号。
- case 的 constant-expression 必须与 switch 中的变量具有相同的数据类型,且必须是一个常量或字面量。
- 当被测试的变量等于 case 中的常量时,case 后跟的语句将被执行,直到遇到 break 语句为止。
- 当遇到 break 语句时,switch 终止,控制流将跳转到 switch 语句后的下一行。
- 不是每一个 case 都需要包含 break。如果 case 语句不包含 break,控制流将会 继续 后续的 case,直到遇到 break 为止。
- 一个 switch 语句可以有一个可选的 default case,出现在 switch 的结尾。default case 可用于在上面所有 case 都不为真时执行一个任务。default case 中的 break 语句不是必需的。
#include <stdio.h>
int main ()
{
/* 局部变量定义 */
int a = 100;
int b = 200;
switch(a) {
case 100:
printf("这是外部 switch 的一部分\n");
switch(b) {
case 200:
printf("这是内部 switch 的一部分\n");
}
}
printf("a 的准确值是 %d\n", a );
printf("b 的准确值是 %d\n", b );
return 0;
}
int main(void){
int a = 3;
switch (a) {
case 2:
case 3:
printf("3");
default:
printf("2");
}
}
注意!!!!!!!
Go 中的 switch 语句和 C 中的有一些不同之处,其中之一就是在 case 匹配成功后,不需要使用 break 语句来显式终止 switch。在 Go 中,一旦匹配到一个 case,就会自动退出 switch。
func main() {
a := 3
switch a {
case 2, 3, 4:
fmt.Println(3)
default:
fmt.Println("2")
}
}
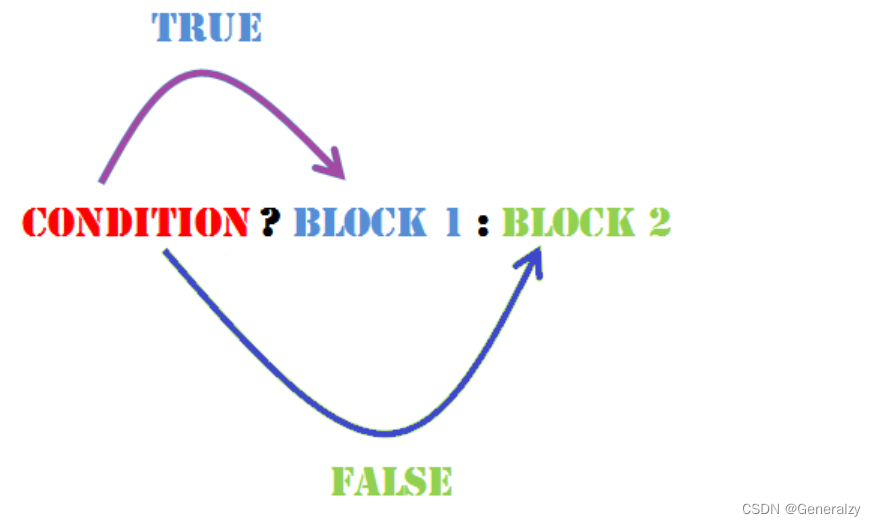
? : 运算符(三元运算符)
语法:
Exp1 ? Exp2 : Exp3;
其中,Exp1、Exp2 和 Exp3 是表达式。请注意,冒号的使用和位置。
? 表达式的值是由 Exp1 决定的。如果 Exp1 为真,则计算 Exp2 的值,结果即为整个表达式的值。如果 Exp1 为假,则计算 Exp3 的值,结果即为整个表达式的值。
goto 语句
goto 语句用于跳到指定的标签名。这会破坏结构化编程,建议不要轻易使用。
char ch;
top: ch = getchar();
if (ch == 'q')
goto top;
上面示例中,top是一个标签名,可以放在正常语句的前面,相当于为这行语句做了一个标记。程序执行到goto语句,就会跳转到它指定的标签名。
infinite_loop:
print("Hello, world!\n");
goto infinite_loop;
上面的代码会产生无限循环。
goto 的一个主要用法是跳出多层循环。
for(...) {
for (...) {
while (...) {
do {
if (some_error_condition)
goto bail;
} while(...);
}
}
}
bail:
// ... ...
上面代码有很复杂的嵌套循环,不使用 goto 的话,想要完全跳出所有循环,写起来很麻烦。
goto 的另一个用途是提早结束多重判断。
if (do_something() == ERR)
goto error;
if (do_something2() == ERR)
goto error;
if (do_something3() == ERR)
goto error;
if (do_something4() == ERR)
goto error;
上面示例有四个判断,只要有一个发现错误,就使用 goto 跳过后面的判断。
注意,goto 只能在同一个函数之中跳转,并不能跳转到其他函数。


C 循环
Go 语言提供了一种简单而强大的循环结构:for 循环。虽然 Go 没有像其他一些语言(如 C 语言)提供的 while 或 do-while 循环,但通过 for 循环的灵活性和功能强大的特性,能够很好地满足大多数循环需求。
Go 的 for 循环有多种形式,它可以用来实现各种不同的循环模式:
-
基本的
for循环:for i := 0; i < 5; i++ { // 循环体 } -
无限循环:
for { // 无限循环体 } -
for循环的替代形式:sum := 0 numbers := []int{1, 2, 3, 4, 5} for _, num := range numbers { sum += num } -
for循环的条件部分为空:i := 0 for i < 5 { // 循环体 i++ }
通过提供灵活的 for 循环,Go 语言鼓励简洁、清晰的代码,并避免了其他语言中可能出现的循环结构的混乱和冗余。此外,Go 还提供了 range 关键字,用于遍历数组、切片、映射等数据结构,使得循环更加简洁和易读。
虽然 Go 没有像 while 或 do-while 这样的循环语句,但通过 for 循环的各种变体以及其他语言特性,Go 提供了足够的工具来处理各种循环场景。这符合 Go 语言设计的一个原则:简洁性和清晰性胜过冗余和复杂性。
其实C语言的for也能实现类似功能,基本语法:
for ( init; condition; increment )
{
statement(s);
}
基本循环:
for (int i=0;i<10;i++){
}
无限循环:
for (;;){
}
for 循环的条件部分为空:
for (;i<10;){
}
循环控制语句
| 控制语句 | 描述 |
|---|---|
| break 语句 | 终止循环或 switch 语句,程序流将继续执行紧接着循环或 switch 的下一条语句。 |
| continue 语句 | 告诉一个循环体立刻停止本次循环迭代,重新开始下次循环迭代。 |
| goto 语句 | 将控制转移到被标记的语句。但是不建议在程序中使用 goto 语句。 |
C 函数
函数是一组一起执行一个任务的语句。每个 C 程序都至少有一个函数,即主函数 main() ,所有简单的程序都可以定义其他额外的函数。
函数声明告诉编译器函数的名称、返回类型和参数。函数定义提供了函数的实际主体。
C 标准库提供了大量的程序可以调用的内置函数。例如,函数 strcat() 用来连接两个字符串,函数 memcpy() 用来复制内存到另一个位置。
main()
C 语言规定,main()是程序的入口函数,即所有的程序一定要包含一个main()函数。程序总是从这个函数开始执行,如果没有该函数,程序就无法启动。其他函数都是通过它引入程序的。
main()的写法与其他函数一样,要给出返回值的类型和参数的类型,就像下面这样。
int main(void) {
printf("Hello World\n");
return 0;
}
上面示例中,最后的return 0;表示函数结束运行,返回0。
C 语言约定,返回值0表示函数运行成功,如果返回其他非零整数,就表示运行失败,代码出了问题。系统根据main()的返回值,作为整个程序的返回值,确定程序是否运行成功。
正常情况下,如果main()里面省略return 0这一行,编译器会自动加上,即main()的默认返回值为0。所以,写成下面这样,效果完全一样。
int main(void) {
printf("Hello World\n");
}
由于 C 语言只会对main()函数默认添加返回值,对其他函数不会这样做,所以建议总是保留return语句,以便形成统一的代码风格。
定义函数
C 语言中的函数定义的一般形式如下:
return_type function_name( parameter list )
{
body of the function
}
在 C 语言中,函数由一个函数头和一个函数主体组成。下面列出一个函数的所有组成部分:
- 返回类型:一个函数可以返回一个值。return_type 是函数返回的值的数据类型。有些函数执行所需的操作而不返回值,在这种情况下,return_type 是关键字 void。
- 函数名称:这是函数的实际名称。函数名和参数列表一起构成了函数签名。
- 参数:参数就像是占位符。当函数被调用时,您向参数传递一个值,这个值被称为实际参数。参数列表包括函数参数的类型、顺序、数量。参数是可选的,也就是说,函数可能不包含参数。
- 函数主体:函数主体包含一组定义函数执行任务的语句。
函数声明
函数声明会告诉编译器函数名称及如何调用函数。函数的实际主体可以单独定义。
函数声明包括以下几个部分:
return_type function_name( parameter list );
针对上面定义的函数 max(),以下是函数声明:
int max(int num1, int num2);
在函数声明中,参数的名称并不重要,只有参数的类型是必需的,因此下面也是有效的声明:
int max(int, int);
当您在一个源文件中定义函数且在另一个文件中调用函数时,函数声明是必需的。在这种情况下,您应该在调用函数的文件顶部声明函数。
函数参数
如果函数要使用参数,则必须声明接受参数值的变量。这些变量称为函数的形式参数。
形式参数就像函数内的其他局部变量,在进入函数时被创建,退出函数时被销毁。
当调用函数时,有两种向函数传递参数的方式:
- 传值调用:该方法把参数的实际值复制给函数的形式参数。在这种情况下,修改函数内的形式参数不会影响实际参数。
- 引用调用:通过指针传递方式,形参为指向实参地址的指针,当对形参的指向操作时,就相当于对实参本身进行的操作。
/* 函数定义 */
void swap(int *x, int *y)
{
int temp;
temp = *x; /* 保存地址 x 的值 */
*x = *y; /* 把 y 赋值给 x */
*y = temp; /* 把 temp 赋值给 y */
return;
}
默认情况下,C 使用传值调用来传递参数。一般来说,这意味着函数内的代码不能改变用于调用函数的实际参数。
函数指针
函数本身就是一段内存里面的代码,C 语言允许通过指针获取函数。
void print(int a) {
printf("%d\n", a);
}
void (*print_ptr)(int) = &print;
上面示例中,变量print_ptr是一个函数指针,它指向函数print()的地址。函数print()的地址可以用&print获得。注意,(*print_ptr)一定要写在圆括号里面,否则函数参数(int)的优先级高于*,整个式子就会变成void* print_ptr(int)。
有了函数指针,通过它也可以调用函数。
(*print_ptr)(10);
// 等同于
print(10);
比较特殊的是,C 语言还规定,函数名本身就是指向函数代码的指针,通过函数名就能获取函数地址。也就是说,print和&print是一回事。
if (print == &print) // true
因此,上面代码的print_ptr等同于print。
void (*print_ptr)(int) = &print;
// 或
void (*print_ptr)(int) = print;
if (print_ptr == print) // true
所以,对于任意函数,都有五种调用函数的写法。
// 写法一
print(10)
// 写法二
(*print)(10)
// 写法三
(&print)(10)
// 写法四
(*print_ptr)(10)
// 写法五
print_ptr(10)
为了简洁易读,一般情况下,函数名前面都不加*和&。
这种特性的一个应用是,如果一个函数的参数或返回值,也是一个函数,那么函数原型可以写成下面这样。
int compute(int (*myfunc)(int), int, int);
上面示例可以清晰地表明,函数compute()的第一个参数也是一个函数。
注意:Go里面的函数指针与C不同,不需要复杂的计算:
package main
import (
"fmt"
)
// 定义一个函数
func add(a, b int) int {
return a + b
}
// 函数类型为 func(int, int) int
type addFunction func(int, int) int
func main() {
// 创建一个函数指针并赋值为 add 函数的地址
var addPointer addFunction
addPointer = add
fmt.Println(addPointer)
addPointer2 := add
fmt.Println(addPointer2)
}
// 0xc0ef60
// 0xc0ef60
函数原型
C语言中,函数必须先声明,后使用。由于程序总是先运行main()函数,导致所有其他函数都必须在main()函数之前声明。(仅C语言,python和go都不受限制)
C 语言提供的解决方法是,只要在程序开头处给出函数原型,函数就可以先使用、后声明。所谓函数原型,就是提前告诉编译器,每个函数的返回类型和参数类型。其他信息都不需要,也不用包括函数体,具体的函数实现可以后面再补上。
int twice(int);
int main(int num) {
return twice(num);
}
int twice(int num) {
return 2 * num;
}
exit()
exit()函数用来终止整个程序的运行。一旦执行到该函数,程序就会立即结束。该函数的原型定义在头文件stdlib.h里面。
exit()可以向程序外部返回一个值,它的参数就是程序的返回值。一般来说,使用两个常量作为它的参数:EXIT_SUCCESS(相当于 0)表示程序运行成功,EXIT_FAILURE(相当于 1)表示程序异常中止。这两个常数也是定义在stdlib.h里面。
// 程序运行成功
// 等同于 exit(0);
exit(EXIT_SUCCESS);
// 程序异常中止
// 等同于 exit(1);
exit(EXIT_FAILURE);
在main()函数里面,exit()等价于使用return语句。其他函数使用exit(),就是终止整个程序的运行,没有其他作用。
C 语言还提供了一个atexit()函数,用来登记exit()执行时额外执行的函数,用来做一些退出程序时的收尾工作。该函数的原型也是定义在头文件stdlib.h。
int atexit(void (*func)(void));
atexit()的参数是一个函数指针。注意,它的参数函数(下例的print)不能接受参数,也不能有返回值。
void print(void) {
printf("something wrong!\n");
}
atexit(print);
exit(EXIT_FAILURE);
上面示例中,exit()执行时会先自动调用atexit()注册的print()函数,然后再终止程序。
函数说明符
C 语言提供了一些函数说明符,让函数用法更加明确。
extern 说明符
对于多文件的项目,源码文件会用到其他文件声明的函数。这时,当前文件里面,需要给出外部函数的原型,并用extern说明该函数的定义来自其他文件。
extern int foo(int arg1, char arg2);
int main(void) {
int a = foo(2, 3);
// ...
return 0;
}
上面示例中,函数foo()定义在其他文件,extern告诉编译器当前文件不包含该函数的定义。
由于函数原型默认就是extern,所以这里不加extern,效果是一样的。
static 说明符
默认情况下,每次调用函数时,函数的内部变量都会重新初始化,不会保留上一次运行的值。static说明符可以改变这种行为。
static用于函数内部声明变量时,表示该变量只需要初始化一次,不需要在每次调用时都进行初始化。也就是说,它的值在两次调用之间保持不变。
#include <stdio.h>
void counter(void) {
static int count = 1; // 只初始化一次
printf("%d\n", count);
count++;
}
int main(void) {
counter(); // 1
counter(); // 2
counter(); // 3
counter(); // 4
}
上面示例中,函数counter()的内部变量count,使用static说明符修饰,表明这个变量只初始化一次,以后每次调用时都会使用上一次的值,造成递增的效果。
注意,static修饰的变量初始化时,只能赋值为常量,不能赋值为变量。
int i = 3;
static int j = i; // 错误
上面示例中,j属于静态变量,初始化时不能赋值为另一个变量i。
另外,在块作用域中,static声明的变量有默认值0。
static int foo;
// 等同于
static int foo = 0;
static可以用来修饰函数本身。
static int Twice(int num) {
int result = num * 2;
return(result);
}
上面示例中,static关键字表示该函数只能在当前文件里使用,如果没有这个关键字,其他文件也可以使用这个函数(通过声明函数原型)。
static也可以用在参数里面,修饰参数数组。
int sum_array(int a[static 3], int n) {
// ...
}
上面示例中,static对程序行为不会有任何影响,只是用来告诉编译器,该数组长度至少为3,某些情况下可以加快程序运行速度。另外,需要注意的是,对于多维数组的参数,static仅可用于第一维的说明。
generalzy: 挺神奇的,在go和python中都没有整个功能,不过python用下划线实现了是否可视,go用大小写实现了是否可见,
然后再加上用外部变量就可以代替实现`保留上一次运行的值`。
const 说明符
函数参数里面的const说明符,表示函数内部不得修改该参数变量。
void f(int* p) {
// ...
}
上面示例中,函数f()的参数是一个指针p,函数内部可能会改掉它所指向的值*p,从而影响到函数外部。
为了避免这种情况,可以在声明函数时,在指针参数前面加上const说明符,告诉编译器,函数内部不能修改该参数所指向的值。
void f(const int* p) {
*p = 0; // 该行报错
}
上面示例中,声明函数时,const指定不能修改指针p指向的值,所以*p = 0就会报错。
但是上面这种写法,只限制修改p所指向的值,而p本身的地址是可以修改的。
void f(const int* p) {
int x = 13;
p = &x; // 允许修改
}
上面示例中,p本身是可以修改,const只限定*p不能修改。
如果想限制修改p,可以把const放在p前面。
void f(int* const p) {
int x = 13;
p = &x; // 该行报错
}
如果想同时限制修改p和*p,需要使用两个const。
void f(const int* const p) {
// ...
}
个人感觉const用在函数中比较鸡肋,不想修改就传值的copy不就行了,传入地址的copy做什么?
可变参数
有些函数的参数数量是不确定的,声明函数的时候,可以使用省略号…表示可变数量的参数。
int printf(const char* format, ...);
上面示例是printf()函数的原型,除了第一个参数,其他参数的数量是可变的,与格式字符串里面的占位符数量有关。这时,就可以用…表示可变数量的参数。
注意,…符号必须放在参数序列的结尾,否则会报错。
头文件stdarg.h定义了一些宏,可以操作可变参数。
(1)va_list:一个数据类型,用来定义一个可变参数对象。它必须在操作可变参数时,首先使用。
(2)va_start:一个函数,用来初始化可变参数对象。它接受两个参数,第一个参数是可变参数对象,第二个参数是原始函数里面,可变参数之前的那个参数,用来为可变参数定位。
(3)va_arg:一个函数,用来取出当前那个可变参数,每次调用后,内部指针就会指向下一个可变参数。它接受两个参数,第一个是可变参数对象,第二个是当前可变参数的类型。
(4)va_end:一个函数,用来清理可变参数对象。
double average(int i, ...) {
double total = 0;
va_list ap;
va_start(ap, i);
for (int j = 1; j <= i; ++j) {
total += va_arg(ap, double);
}
va_end(ap);
return total / i;
}
上面示例中,va_list ap定义ap为可变参数对象,va_start(ap, i)将参数i后面的参数统一放入ap,va_arg(ap, double)用来从ap依次取出一个参数,并且指定该参数为 double 类型,va_end(ap)用来清理可变参数对象。
C语言可变参数的支持远远不如后期的高级语言,Go语言会将...转为切片,python则会将*args转为列表,**kwargs转为字典。
C 作用域规则
任何一种编程中,作用域是程序中定义的变量所存在的区域,超过该区域变量就不能被访问。C 语言中有三个地方可以声明变量:
- 在函数或块内部的局部变量
- 在所有函数外部的全局变量
- 在形式参数的函数参数定义中
局部变量
在某个函数或块的内部声明的变量称为局部变量。它们只能被该函数或该代码块内部的语句使用。局部变量在函数外部是不可知的。下面是使用局部变量的实例。在这里,所有的变量 a、b 和 c 是 main() 函数的局部变量。
#include <stdio.h>
int main ()
{
/* 局部变量声明 */
int a, b;
int c;
/* 实际初始化 */
a = 10;
b = 20;
c = a + b;
printf ("value of a = %d, b = %d and c = %d\n", a, b, c);
return 0;
}
全局变量
全局变量是定义在函数外部,通常是在程序的顶部。全局变量在整个程序生命周期内都是有效的,在任意的函数内部能访问全局变量。
全局变量可以被任何函数访问。也就是说,全局变量在声明后整个程序中都是可用的。下面是使用全局变量和局部变量的实例:
#include <stdio.h>
/* 全局变量声明 */
int g;
int main ()
{
/* 局部变量声明 */
int a, b;
/* 实际初始化 */
a = 10;
b = 20;
g = a + b;
printf ("value of a = %d, b = %d and g = %d\n", a, b, g);
return 0;
}
在程序中,局部变量和全局变量的名称可以相同,但是在函数内,如果两个名字相同,会使用局部变量值,全局变量不会被使用。下面是一个实例:
#include <stdio.h>
/* 全局变量声明 */
int g = 20;
int main ()
{
/* 局部变量声明 */
int g = 10;
printf ("value of g = %d\n", g);
return 0;
}
当上面的代码被编译和执行时,它会产生下列结果:
value of g = 10
形式参数
函数的参数,形式参数,被当作该函数内的局部变量,如果与全局变量同名它们会优先使用。下面是一个实例:
#include <stdio.h>
/* 全局变量声明 */
int a = 20;
int main ()
{
/* 在主函数中的局部变量声明 */
int a = 10;
int b = 20;
int c = 0;
int sum(int, int);
printf ("value of a in main() = %d\n", a);
c = sum( a, b);
printf ("value of c in main() = %d\n", c);
return 0;
}
/* 添加两个整数的函数 */
int sum(int a, int b)
{
printf ("value of a in sum() = %d\n", a);
printf ("value of b in sum() = %d\n", b);
return a + b;
}
当上面的代码被编译和执行时,它会产生下列结果:
value of a in main() = 10
value of a in sum() = 10
value of b in sum() = 20
value of c in main() = 30
全局变量与局部变量在内存中的区别:
- 全局变量保存在内存的全局存储区中,占用静态的存储单元;
- 局部变量保存在栈中,只有在所在函数被调用时才动态地为变量分配存储单元。
C 数组
C 语言支持数组数据结构,它可以存储一个固定大小的相同类型元素的顺序集合。数组是用来存储一系列数据,但它往往被认为是一系列相同类型的变量。
数组的声明并不是声明一个个单独的变量,比如 runoob0、runoob1、…、runoob99,而是声明一个数组变量,比如 runoob,然后使用 runoob[0]、runoob[1]、…、runoob[99] 来代表一个个单独的变量。
所有的数组都是由连续的内存位置组成。最低的地址对应第一个元素,最高的地址对应最后一个元素。
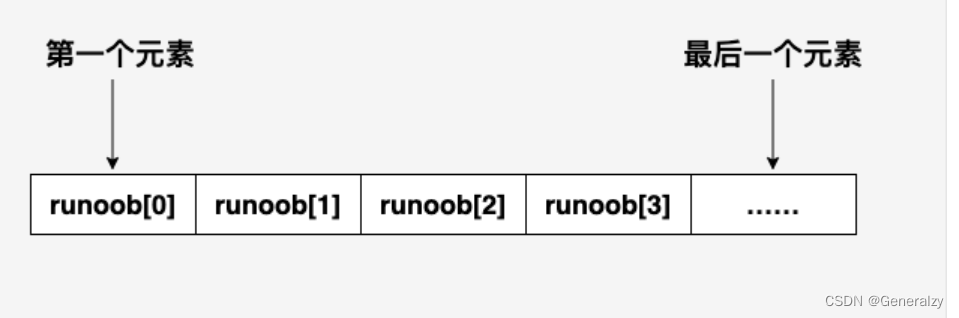
数组中的特定元素可以通过索引访问,第一个索引值为 0。
声明数组
在 C 中要声明一个数组,需要指定元素的类型和元素的数量,如下所示:
type arrayName [ arraySize ];
这叫做一维数组。arraySize 必须是一个大于零的整数常量,type 可以是任意有效的 C 数据类型。例如,要声明一个类型为 double 的包含 10 个元素的数组 balance,声明语句如下:
double balance[10];
现在 balance 是一个可用的数组,可以容纳 10 个类型为 double 的数字。
初始化数组
在 C 中,可以逐个初始化数组,也可以使用一个初始化语句,如下所示:
double balance[5] = {1000.0, 2.0, 3.4, 7.0, 50.0};
大括号 { } 之间的值的数目不能大于在数组声明时在方括号 [ ] 中指定的元素数目。
**如果省略掉了数组的大小,数组的大小则为初始化时元素的个数。**因此,如果:
double balance[] = {1000.0, 2.0, 3.4, 7.0, 50.0};
您将创建一个数组,它与前一个实例中所创建的数组是完全相同的。下面是一个为数组中某个元素赋值的实例:
balance[4] = 50.0;
上述的语句把数组中第五个元素的值赋为 50.0。
如果要将整个数组的每一个成员都设置为零,最简单的写法就是下面这样。
int a[100] = {0};
访问数组元素
数组元素可以通过数组名称加索引进行访问。元素的索引是放在方括号内,跟在数组名称的后边。例如:
double salary = balance[9];
获取数组长度
数组长度可以使用 sizeof 运算符来获取数组的长度,例如:
int numbers[] = {1, 2, 3, 4, 5};
int length = sizeof(numbers) / sizeof(numbers[0]);
使用宏定义:
#include <stdio.h>
#define LENGTH(array) (sizeof(array) / sizeof(array[0]))
int main() {
// int在C里面是32位 4字节
// sizeof(array) = 20字节
// sizeof(array[0]) = 4字节
int array[] = {1, 2, 3, 4, 5};
int length = LENGTH(array);
printf("数组长度为: %d\n", length);
return 0;
}
以上实例输出结果为:
数组长度为: 5
数组名
在 C 语言中,数组名表示数组的地址,即数组首元素的地址。当我们在声明和定义一个数组时,该数组名就代表着该数组的地址。
例如,在以下代码中:
int myArray[5] = {10, 20, 30, 40, 50};
在这里,myArray 是数组名,它表示整数类型的数组,包含 5 个元素。myArray 也代表着数组的地址,即第一个元素的地址。
数组名本身是一个常量指针,意味着它的值是不能被改变的,一旦确定,就不能再指向其他地方。
我们可以使用&运算符来获取数组的地址,如下所示:
int myArray[5] = {10, 20, 30, 40, 50};
int *ptr = &myArray[0]; // 或者直接写作 int *ptr = myArray;
在上面的例子中,ptr 指针变量被初始化为 myArray 的地址,即数组的第一个元素的地址。
需要注意的是,虽然数组名表示数组的地址,但在大多数情况下,数组名会自动转换为指向数组首元素的指针。这意味着我们可以直接将数组名用于指针运算,例如在函数传递参数或遍历数组时:
void printArray(int arr[], int size) {
for (int i = 0; i < size; i++) {
printf("%d ", arr[i]); // 数组名arr被当作指针使用
}
}
int main() {
int myArray[5] = {10, 20, 30, 40, 50};
printArray(myArray, 5); // 将数组名传递给函数
return 0;
}
注: 以上操作在go里面属于unsafe.
变长数组
数组声明的时候,数组长度除了使用常量,也可以使用变量。这叫做变长数组(variable-length array,简称 VLA)。
int n = x + y;
int arr[n];
上面示例中,数组arr就是变长数组,因为它的长度取决于变量n的值,编译器没法事先确定,只有运行时才能知道n是多少。
变长数组的根本特征,就是数组长度只有运行时才能确定。它的好处是程序员不必在开发时,随意为数组指定一个估计的长度,程序可以在运行时为数组分配精确的长度。
任何长度需要运行时才能确定的数组,都是变长数组。
int i = 10;
int a1[i];
int a2[i + 5];
int a3[i + k];
上面示例中,三个数组的长度都需要运行代码才能知道,编译器并不知道它们的长度,所以它们都是变长数组。
变长数组也可以用于多维数组。
int m = 4;
int n = 5;
int c[m][n];
上面示例中,c[m][n]就是二维变长数组。
数组的复制
由于数组名是指针,所以复制数组不能简单地复制数组名。
int* a;
int b[3] = {1, 2, 3};
a = b;
上面的写法,结果不是将数组b复制给数组a,而是让a和b指向同一个数组。
复制数组最简单的方法,还是使用循环,将数组元素逐个进行复制。
for (i = 0; i < N; i++)
a[i] = b[i];
上面示例中,通过将数组b的成员逐个复制给数组a,从而实现数组的赋值。
另一种方法是使用memcpy()函数(定义在头文件string.h),直接把数组所在的那一段内存,再复制一份。
memcpy(a, b, sizeof(b));
上面示例中,将数组b所在的那段内存,复制给数组a。这种方法要比循环复制数组成员要快。
C 多维数组
C 语言支持多维数组。多维数组声明的一般形式如下:
type name[size1][size2]...[sizeN];
例如,下面的声明创建了一个三维 5 . 10 . 4 整型数组:
int threedim[5][10][4];
初始化二维数组
多维数组可以通过在括号内为每行指定值来进行初始化。下面是一个带有 3 行 4 列的数组。
int a[3][4] = {
{0, 1, 2, 3} , /* 初始化索引号为 0 的行 */
{4, 5, 6, 7} , /* 初始化索引号为 1 的行 */
{8, 9, 10, 11} /* 初始化索引号为 2 的行 */
};
内部嵌套的括号是可选的,下面的初始化与上面是等同的:
int a[3][4] = {0,1,2,3,4,5,6,7,8,9,10,11};
但还是建议加上内部嵌套的括号。
C 传递数组给函数
如果想要在函数中传递一个一维数组作为参数,必须以下面三种方式来声明函数形式参数,这三种声明方式的结果是一样的,因为每种方式都会告诉编译器将要接收一个整型指针。同样地,也可以传递一个多维数组作为形式参数。
// 方式1
void myFunction(int *param)
{
.
.
.
}
// 方式2
void myFunction(int param[10])
{
.
.
.
}
// 方式3
void myFunction(int param[])
{
.
.
.
}
现在,让我们来看下面这个函数,它把数组作为参数,同时还传递了另一个参数,根据所传的参数,会返回数组中元素的平均值:
double getAverage(int arr[], int size)
{
int i;
double avg;
double sum;
for (i = 0; i < size; ++i)
{
sum += arr[i];
}
avg = sum / size;
return avg;
}
下面这个函数,它把数组作为参数,同时还传递了另一个参数,根据所传的参数,会返回数组中元素的平均值:
double getAverage(int arr[], int size)
{
int i;
double avg;
double sum;
for (i = 0; i < size; ++i)
{
sum += arr[i];
}
avg = sum / size;
return avg;
}
变长数组作为参数
变长数组作为函数参数时,写法略有不同。
int sum_array(int n, int a[n]) {
// ...
}
int a[] = {3, 5, 7, 3};
int sum = sum_array(4, a);
上面示例中,数组a[n]是一个变长数组,它的长度取决于变量n的值,只有运行时才能知道。所以,变量n作为参数时,顺序一定要在变长数组前面,这样运行时才能确定数组a[n]的长度,否则就会报错。
因为函数原型可以省略参数名,所以变长数组的原型中,可以使用*代替变量名,也可以省略变量名。
int sum_array(int, int [*]);
int sum_array(int, int []);
上面两种变长函数的原型写法,都是合法的。
变长数组作为函数参数有一个好处,就是多维数组的参数声明,可以把后面的维度省掉了。
// 原来的写法
int sum_array(int a[][4], int n);
// 变长数组的写法
int sum_array(int n, int m, int a[n][m]);
上面示例中,函数sum_array()的参数是一个多维数组,按照原来的写法,一定要声明第二维的长度。但是使用变长数组的写法,就不用声明第二维长度了,因为它可以作为参数传入函数。
数组字面量作为参数
C 语言允许将数组字面量作为参数,传入函数。
// 数组变量作为参数
int a[] = {2, 3, 4, 5};
int sum = sum_array(a, 4);
// 数组字面量作为参数
int sum = sum_array((int []){2, 3, 4, 5}, 4);
上面示例中,两种写法是等价的。第二种写法省掉了数组变量的声明,直接将数组字面量传入函数。{2, 3, 4, 5}是数组值的字面量,(int [])类似于强制的类型转换,告诉编译器怎么理解这组值。
C 从函数返回数组
C 语言不允许返回一个完整的数组作为函数的参数。但是,可以通过指定不带索引的数组名来返回一个指向数组的指针。
int * myFunction()
{
.
.
.
}
另外,C 不支持在函数外返回局部变量的地址,除非定义局部变量为 static 变量。
下面的函数,它会生成 10 个随机数,并使用数组来返回它们,具体如下:
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
/* 要生成和返回随机数的函数 */
int * getRandom( )
{
static int r[10];
int i;
/* 设置种子 */
srand( (unsigned)time( NULL ) );
for ( i = 0; i < 10; ++i)
{
r[i] = rand();
printf( "r[%d] = %d\n", i, r[i]);
}
return r;
}
/* 要调用上面定义函数的主函数 */
int main ()
{
/* 一个指向整数的指针 */
int *p;
int i;
p = getRandom();
for ( i = 0; i < 10; i++ )
{
printf( "*(p + %d) : %d\n", i, *(p + i));
}
return 0;
}
C 指向数组的指针
数组名本身是一个常量指针,意味着它的值是不能被改变的,一旦确定,就不能再指向其他地方。
因此,在下面的声明中:
double balance[50];
balance 是一个指向 &balance[0] 的指针,即数组 balance 的第一个元素的地址。因此,下面的程序片段把 p 赋值为 balance 的第一个元素的地址:
double *p;
double balance[10];
p = balance;
使用数组名作为常量指针是合法的,反之亦然。因此,*(balance + 4) 是一种访问 balance[4] 数据的合法方式。
一旦把第一个元素的地址存储在 p 中,就可以使用 *p、*(p+1)、*(p+2) 等来访问数组元素。下面的实例演示了上面讨论到的这些概念:
#include <stdio.h>
int main ()
{
/* 带有 5 个元素的整型数组 */
double balance[5] = {1000.0, 2.0, 3.4, 17.0, 50.0};
double *p;
int i;
p = balance;
/* 输出数组中每个元素的值 */
printf( "使用指针的数组值\n");
for ( i = 0; i < 5; i++ )
{
printf("*(p + %d) : %f\n", i, *(p + i) );
}
printf( "使用 balance 作为地址的数组值\n");
for ( i = 0; i < 5; i++ )
{
printf("*(balance + %d) : %f\n", i, *(balance + i) );
}
return 0;
}
C 语言静态数组与动态数组
在 C 语言中,有两种类型的数组:
- 静态数组:编译时分配内存,大小固定。
- 动态数组:运行时手动分配内存,大小可变。
静态数组的生命周期与作用域相关,而动态数组的生命周期由程序员控制。
在使用动态数组时,需要注意合理地分配和释放内存,以避免内存泄漏和访问无效内存的问题。
静态数组
静态数组是在编译时声明并分配内存空间的数组。
静态数组具有固定的大小,在声明数组时需要指定数组的长度。
静态数组的特点包括:
- 内存分配:在程序编译时,静态数组的内存空间就被分配好了,存储在栈上或者全局数据区。
- 大小固定:静态数组的大小在声明时确定,并且无法在运行时改变。
- 生命周期:静态数组的生命周期与其作用域相关。如果在函数内部声明静态数组,其生命周期为整个函数执行期间;如果在函数外部声明静态数组,其生命周期为整个程序的执行期间。
静态数组的声明和初始化示例:
int staticArray[5]; // 静态数组声明
int staticArray[] = {1, 2, 3, 4, 5}; // 静态数组声明并初始化
对于静态数组,可以使用 sizeof 运算符来获取数组长度,例如:
int array[] = {1, 2, 3, 4, 5};
int length = sizeof(array) / sizeof(array[0]);
以上代码中 sizeof(array) 返回整个数组所占用的字节数,而 sizeof(array[0]) 返回数组中单个元素的字节数,将两者相除,就得到了数组的长度。
动态数组
动态数组是在运行时通过动态内存分配函数(如 malloc 和 calloc)手动分配内存的数组。
动态数组特点如下:
- 内存分配:动态数组的内存空间在运行时通过动态内存分配函数手动分配,并存储在堆上。需要使用 malloc、calloc 等函数来申请内存,并使用 free 函数来释放内存。
- 大小可变:动态数组的大小在运行时可以根据需要进行调整。可以使用 realloc 函数来重新分配内存,并改变数组的大小。
- 生命周期:动态数组的生命周期由程序员控制。需要在使用完数组后手动释放内存,以避免内存泄漏。
动态数组的声明、内存分配和释放实例:
int size = 5;
int *dynamicArray = (int *)malloc(size * sizeof(int)); // 动态数组内存分配
// 使用动态数组
free(dynamicArray); // 动态数组内存释放
动态分配的数组,可以在动态分配内存时保存数组长度,并在需要时使用该长度,例如:
int size = 5; // 数组长度
int *array = malloc(size * sizeof(int));
// 使用数组
free(array); // 释放内存
以上代码我们使用 malloc 函数动态分配了一个整型数组,并将长度保存在变量 size 中。然后可以根据需要使用这个长度进行操作,在使用完数组后,使用 free 函数释放内存。
注意:动态数组的使用需要注意内存管理的问题,确保在不再需要使用数组时释放内存,避免内存泄漏和访问无效的内存位置。
#include <stdio.h>
#include <stdlib.h>
int main() {
int size = 5;
int *dynamicArray = (int *)malloc(size * sizeof(int)); // 动态数组内存分配
if (dynamicArray == NULL) {
printf("Memory allocation failed.\n");
return 1;
}
printf("Enter %d elements: ", size);
for (int i = 0; i < size; i++) {
scanf("%d", &dynamicArray[i]);
}
printf("Dynamic Array: ");
for (int i = 0; i < size; i++) {
printf("%d ", dynamicArray[i]);
}
printf("\n");
free(dynamicArray); // 动态数组内存释放
return 0;
}
C enum(枚举)
枚举是 C 语言中的一种基本数据类型,用于定义一组具有离散值的常量,它可以让数据更简洁,更易读。
枚举类型通常用于为程序中的一组相关的常量取名字,以便于程序的可读性和维护性。
定义一个枚举类型,需要使用 enum 关键字,后面跟着枚举类型的名称,以及用大括号 {} 括起来的一组枚举常量。每个枚举常量可以用一个标识符来表示,也可以为它们指定一个整数值,如果没有指定,那么默认从 0 开始递增。
枚举语法定义格式为:
enum 枚举名 {枚举元素1,枚举元素2,……};
比如:一星期有 7 天,如果不用枚举,需要使用 #define 来为每个整数定义一个别名:
#define MON 1
#define TUE 2
#define WED 3
#define THU 4
#define FRI 5
#define SAT 6
#define SUN 7
这个看起来代码量就比较多(我咋感觉不多呢),使用枚举的方式:
enum DAY
{
MON=1, TUE, WED, THU, FRI, SAT, SUN
};
注意:第一个枚举成员的默认值为整型的 0,后续枚举成员的值在前一个成员上加 1。在这个实例中把第一个枚举成员的值定义为 1,第二个就为 2,以此类推。
可以在定义枚举类型时改变枚举元素的值:
enum season {spring, summer=3, autumn, winter};
没有指定值的枚举元素,其值为前一元素加 1。也就说 spring 的值为 0,summer 的值为 3,autumn 的值为 4,winter 的值为 5
枚举变量的定义
前面只是声明了枚举类型,可以通过以下三种方式来定义枚举变量:
1、先定义枚举类型,再定义枚举变量
enum DAY
{
MON=1, TUE, WED, THU, FRI, SAT, SUN
};
enum DAY day;
2、定义枚举类型的同时定义枚举变量
enum DAY
{
MON=1, TUE, WED, THU, FRI, SAT, SUN
} day;
3、省略枚举名称,直接定义枚举变量
enum
{
MON=1, TUE, WED, THU, FRI, SAT, SUN
} day;
#include <stdio.h>
enum DAY
{
MON=1, TUE, WED, THU, FRI, SAT, SUN
};
int main()
{
enum DAY day;
day = WED;
printf("%d",day);
return 0;
}
在C 语言中,枚举类型是被当做 int 或者 unsigned int 类型来处理的,所以按照 C 语言规范是没有办法遍历枚举类型的。
不过在一些特殊的情况下,枚举类型必须连续是可以实现有条件的遍历。(没人会闲的无聊遍历枚举吧)
#include <stdio.h>
enum DAY
{
MON=1, TUE, WED, THU, FRI, SAT, SUN
} day;
int main()
{
// 遍历枚举元素
for (day = MON; day <= SUN; day++) {
printf("枚举元素:%d \n", day);
}
}
由于Enum 会自动编号,因此可以不必为常量赋值。C 语言会自动从0开始递增,为常量赋值。但是,C 语言也允许为 ENUM 常量指定值,不过只能指定为整数,不能是其他类型。因此,任何可以使用整数的场合,都可以使用 Enum 常量。
enum { ONE = 1, TWO = 2 };
printf("%d %d", ONE, TWO); // 1 2
Enum 常量可以是不连续的值。
enum { X = 2, Y = 18, Z = -2 };
Enum 常量也可以是同一个值。
enum { X = 2, Y = 2, Z = 2 };
如果一组常量之中,有些指定了值,有些没有指定。那么,没有指定值的常量会从上一个指定了值的常量,开始自动递增赋值。 ( Go语言只有iota具有递增的功能,否则const枚举出来的下一个变量与上一个相同)
enum {
A, // 0
B, // 1
C = 4, // 4
D, // 5
E, // 6
F = 3, // 3
G, // 4
H // 5
};
Enum 的作用域与变量相同。如果是在顶层声明,那么在整个文件内都有效;如果是在代码块内部声明,则只对该代码块有效。如果与使用int声明的常量相比,Enum 的好处是更清晰地表示代码意图。
将整数转换为枚举
#include <stdio.h>
#include <stdlib.h>
int main()
{
enum day
{
saturday,
sunday,
monday,
tuesday,
wednesday,
thursday,
friday
} workday;
int a = 1;
enum day weekend;
weekend = ( enum day ) a; //类型转换
//weekend = a; //错误
printf("weekend:%d",weekend);
return 0;
}
对比go和C的枚举形态
在go中可以通过const和iota定义枚举,类型可以使用type定义:
package main
import "fmt"
type Weekend int
const (
Mon Weekend = iota + 1
Tues
Wed
Thurs
Fri
Sat
Sun
)
func (w Weekend) String() string {
return fmt.Sprintln("Today is", int(w), ".")
}
func main() {
week := Mon
fmt.Println(week)
}
C代码:
#include <stdio.h>
enum Weekend{
Mon = 1,
Thus,
Wed,
Thurs,
Fri,
Sat,
Sun,
};
int main(void){
enum Weekend week = Mon;
printf("Today is %d.",week);
}
C 指针
通过指针,可以简化一些 C 编程任务的执行,还有一些任务,如动态内存分配,没有指针是无法执行的。
每一个变量都有一个内存位置,每一个内存位置都定义了可使用 & 运算符访问的地址,它表示了在内存中的一个地址。
#include <stdio.h>
int main ()
{
int var_runoob = 10;
int *p; // 定义指针变量
p = &var_runoob;
printf("var_runoob 变量的地址: %p\n", p);
return 0;
}

怎么理解*p
我感觉C里面的指针声明很奇怪,*代表它是个指针,那按理说应该是int* ptr才对,int*代表是int类型的指针。
这点在Go里面就体现出来了:var a *int,*和类型是在一起的。
后来反应过来,C里面这样声明可以理解为:对ptr取值(*运算)后是个int.
C 中的 NULL 指针
在变量声明的时候,如果没有确切的地址可以赋值,为指针变量赋一个 NULL 值是一个良好的编程习惯。赋为 NULL 值的指针被称为空指针。
NULL 指针是一个定义在标准库中的值为零的常量。请看下面的程序:
#include <stdio.h>
int main ()
{
int *ptr = NULL;
printf("ptr 的地址是 %p\n", ptr );
return 0;
}
当上面的代码被编译和执行时,它会产生下列结果:
ptr 的地址是 0x0
在大多数的操作系统上,程序不允许访问地址为 0 的内存,因为该内存是操作系统保留的。然而,内存地址 0 有特别重要的意义,它表明该指针不指向一个可访问的内存位置。但按照惯例,如果指针包含空值(零值),则假定它不指向任何东西。
如需检查一个空指针,您可以使用 if 语句,如下所示:
if(ptr) /* 如果 p 非空,则完成 */
if(!ptr) /* 如果 p 为空,则完成 */
C 指针的算术运算
C 指针是一个用数值表示的地址。因此,可以对指针执行算术运算。可以对指针进行四种算术运算:++、–、+、-。
假设 ptr 是一个指向地址 1000 的整型指针,是一个 32 位的整数,让我们对该指针执行下列的算术运算:
ptr++
在执行完上述的运算之后,ptr 将指向位置 1004,因为 ptr 每增加一次,它都将指向下一个整数位置,即当前位置往后移 4 字节。这个运算会在不影响内存位置中实际值的情况下,移动指针到下一个内存位置。如果 ptr 指向一个地址为 1000 的字符,上面的运算会导致指针指向位置 1001,因为下一个字符位置是在 1001。
概括一下:
- 指针的每一次递增,它其实会指向下一个元素的存储单元。
- 指针的每一次递减,它都会指向前一个元素的存储单元。
- 指针在递增和递减时跳跃的字节数取决于指针所指向变量数据类型长度,比如 int 就是 4 个字节。
递增一个指针
在程序中使用指针代替数组,因为变量指针可以递增,而数组不能递增,数组可以看成一个指针常量。下面的程序递增变量指针,以便顺序访问数组中的每一个元素:
#include <stdio.h>
const int MAX = 3;
int main ()
{
int var[] = {10, 100, 200};
int i, *ptr;
/* 指针中的数组地址 */
ptr = var;
for ( i = 0; i < MAX; i++)
{
printf("存储地址:var[%d] = %p\n", i, ptr );
printf("存储值:var[%d] = %d\n", i, *ptr );
/* 指向下一个位置 */
ptr++;
}
return 0;
}
当上面的代码被编译和执行时,它会产生下列结果:
存储地址:var[0] = e4a298cc
存储值:var[0] = 10
存储地址:var[1] = e4a298d0
存储值:var[1] = 100
存储地址:var[2] = e4a298d4
存储值:var[2] = 200
递减一个指针
同样地,对指针进行递减运算,即把值减去其数据类型的字节数,如下所示:
#include <stdio.h>
const int MAX = 3;
int main ()
{
int var[] = {10, 100, 200};
int i, *ptr;
/* 指针中最后一个元素的地址 */
ptr = &var[MAX-1];
for ( i = MAX; i > 0; i--)
{
printf("存储地址:var[%d] = %p\n", i-1, ptr );
printf("存储值:var[%d] = %d\n", i-1, *ptr );
/* 指向下一个位置 */
ptr--;
}
return 0;
}
当上面的代码被编译和执行时,它会产生下列结果:
存储地址:var[2] = 518a0ae4
存储值:var[2] = 200
存储地址:var[1] = 518a0ae0
存储值:var[1] = 100
存储地址:var[0] = 518a0adc
存储值:var[0] = 10
指针的比较
指针可以用关系运算符进行比较,如 ==、< 和 >。如果 p1 和 p2 指向两个相关的变量,比如同一个数组中的不同元素,则可对 p1 和 p2 进行大小比较。
下面的程序修改了上面的实例,只要变量指针所指向的地址小于或等于数组的最后一个元素的地址 &var[MAX - 1],则把变量指针进行递增:
#include <stdio.h>
const int MAX = 3;
int main ()
{
int var[] = {10, 100, 200};
int i, *ptr;
/* 指针中第一个元素的地址 */
ptr = var;
i = 0;
while ( ptr <= &var[MAX - 1] )
{
printf("存储地址:var[%d] = %p\n", i, ptr );
printf("存储值:var[%d] = %d\n", i, *ptr );
/* 指向上一个位置 */
ptr++;
i++;
}
return 0;
}
C 指针数组
C 指针数组是一个数组,其中的每个元素都是指向某种数据类型的指针。
指针数组存储了一组指针,每个指针可以指向不同的数据对象。
指针数组通常用于处理多个数据对象,例如字符串数组或其他复杂数据结构的数组。
#include <stdio.h>
const int MAX = 3;
int main ()
{
int var[] = {10, 100, 200};
int i;
for (i = 0; i < MAX; i++)
{
printf("Value of var[%d] = %d\n", i, var[i] );
}
return 0;
}
当上面的代码被编译和执行时,它会产生下列结果:
Value of var[0] = 10
Value of var[1] = 100
Value of var[2] = 200
可能有一种情况,我们想要让数组存储指向 int 或 char 或其他数据类型的指针。
下面是一个指向整数的指针数组的声明:
int *ptr[MAX];
在这里,把 ptr 声明为一个数组,由 MAX 个整数指针组成。因此,ptr 中的每个元素,都是一个指向 int 值的指针。下面的实例用到了三个整数,它们将存储在一个指针数组中,如下所示:
#include <stdio.h>
const int MAX = 3;
int main ()
{
int var[] = {10, 100, 200};
int i, *ptr[MAX];
for ( i = 0; i < MAX; i++)
{
ptr[i] = &var[i]; /* 赋值为整数的地址 */
}
for ( i = 0; i < MAX; i++)
{
printf("Value of var[%d] = %d\n", i, *ptr[i] );
}
return 0;
}
C 指向指针的指针
指向指针的指针是一种多级间接寻址的形式,或者说是一个指针链。通常,一个指针包含一个变量的地址。当我们定义一个指向指针的指针时,第一个指针包含了第二个指针的地址,第二个指针指向包含实际值的位置。
一个指向指针的指针变量必须如下声明,即在变量名前放置两个星号。例如,下面声明了一个指向 int 类型指针的指针:
int **var;
当一个目标值被一个指针间接指向到另一个指针时,访问这个值需要使用两个星号运算符,如下面实例所示:

#include <stdio.h>
int main ()
{
int V;
int *Pt1;
int **Pt2;
V = 100;
/* 获取 V 的地址 */
Pt1 = &V;
/* 使用运算符 & 获取 Pt1 的地址 */
Pt2 = &Pt1;
/* 使用 pptr 获取值 */
printf("var = %d\n", V );
printf("Pt1 = %p\n", Pt1 );
printf("*Pt1 = %d\n", *Pt1 );
printf("Pt2 = %p\n", Pt2 );
printf("**Pt2 = %d\n", **Pt2);
return 0;
}
当上面的代码被编译和执行时,它会产生下列结果:
var = 100
Pt1 = 0x7ffee2d5e8d8
*Pt1 = 100
Pt2 = 0x7ffee2d5e8d0
**Pt2 = 100
C 从函数返回指针
C 不支持在调用函数时返回局部变量的地址,除非定义局部变量为 static 变量。
因为局部变量是存储在内存的栈区内,当函数调用结束后,局部变量所占的内存地址便被释放了,因此当其函数执行完毕后,函数内的变量便不再拥有那个内存地址,所以不能返回其指针。
除非将其变量定义为 static 变量,static 变量的值存放在内存中的静态数据区,不会随着函数执行的结束而被清除,故能返回其地址。
#include <stdio.h>
#include <time.h>
#include <stdlib.h>
/* 要生成和返回随机数的函数 */
int * getRandom( )
{
static int r[10];
int i;
/* 设置种子 */
srand( (unsigned)time( NULL ) );
for ( i = 0; i < 10; ++i)
{
r[i] = rand();
printf("%d\n", r[i] );
}
return r;
}
/* 要调用上面定义函数的主函数 */
int main ()
{
/* 一个指向整数的指针 */
int *p;
int i;
p = getRandom();
for ( i = 0; i < 10; i++ )
{
printf("*(p + [%d]) : %d\n", i, *(p + i) );
}
return 0;
}
函数指针
函数指针是指向函数的指针变量。
函数指针可以像一般函数一样,用于调用函数、传递参数。
函数指针变量的声明:
typedef int (*fun_ptr)(int,int); // 声明一个指向同样参数、返回值的函数指针类型
int my_func(int a,int b){
printf("ret:%d\n", a + b);
return 0;
}
//1. 先定义函数类型,通过类型定义指针
void test01(){
typedef int(FUNC_TYPE)(int, int);
FUNC_TYPE* f = my_func;
//如何调用?
(*f)(10, 20);
f(10, 20);
}
//2. 定义函数指针类型
void test02(){
typedef int(*FUNC_POINTER)(int, int);
FUNC_POINTER f = my_func;
//如何调用?
(*f)(10, 20);
f(10, 20);
}
//3. 直接定义函数指针变量
void test03(){
int(*f)(int, int) = my_func;
//如何调用?
(*f)(10, 20);
f(10, 20);
}
以下实例声明了函数指针变量 p,指向函数 max:
#include <stdio.h>
int max(int x, int y)
{
return x > y ? x : y;
}
int main(void)
{
/* p 是函数指针 */
int (* p)(int, int) = & max; // &可以省略
int a, b, c, d;
printf("请输入三个数字:");
scanf("%d %d %d", & a, & b, & c);
/* 与直接调用函数等价,d = max(max(a, b), c) */
d = p(p(a, b), c);
printf("最大的数字是: %d\n", d);
return 0;
}
编译执行,输出结果如下:
请输入三个数字:1 2 3
最大的数字是: 3
回调函数
函数指针作为某个函数的参数:函数指针变量可以作为某个函数的参数来使用的,回调函数就是一个通过函数指针调用的函数。
简单讲:回调函数是由别人的函数执行时调用你实现的函数。
你到一个商店买东西,刚好你要的东西没有货,于是你在店员那里留下了你的电话,
过了几天店里有货了,店员就打了你的电话,然后你接到电话后就到店里去取了货。
在这个例子里,你的电话号码就叫回调函数,你把电话留给店员就叫登记回调函数,
店里后来有货了叫做触发了回调关联的事件,店员给你打电话叫做调用回调函数,
你到店里去取货叫做响应回调事件。
实例中 populate_array() 函数定义了三个参数,其中第三个参数是函数的指针,通过该函数来设置数组的值。
实例中定义了回调函数 getNextRandomValue(),它返回一个随机值,它作为一个函数指针传递给 populate_array() 函数。
populate_array() 将调用 10 次回调函数,并将回调函数的返回值赋值给数组。
#include <stdlib.h>
#include <stdio.h>
void populate_array(int *array, size_t arraySize, int (*getNextValue)(void))
{
for (size_t i=0; i<arraySize; i++)
array[i] = getNextValue();
}
// 获取随机值
int getNextRandomValue(void)
{
return rand();
}
int main(void)
{
int myarray[10];
/* getNextRandomValue 不能加括号,否则无法编译,因为加上括号之后相当于传入此参数时传入了 int , 而不是函数指针*/
populate_array(myarray, 10, getNextRandomValue);
for(int i = 0; i < 10; i++) {
printf("%d ", myarray[i]);
}
printf("\n");
return 0;
}
C 字符串
在 C 语言中,字符串实际上是使用空字符 \0 结尾的一维字符数组。因此,\0 是用于标记字符串的结束。
空字符(Null character)又称结束符,缩写 NUL,是一个数值为 0 的控制字符,\0 是转义字符,意思是告诉编译器,这不是字符 0,而是空字符。
下面的声明和初始化创建了一个 RUNOOB 字符串。由于在数组的末尾存储了空字符 \0,所以字符数组的大小比单词 RUNOOB 的字符数多一个。
char site[7] = {'R', 'U', 'N', 'O', 'O', 'B', '\0'};
依据数组初始化规则,可以把上面的语句写成以下语句:(前情提要:如果您省略掉了数组的大小,数组的大小则为初始化时元素的个数)
// 长度为7
char site[] = "RUNOOB";
以下是 C/C++ 中定义的字符串的内存表示:
其实,不需要手动把 null 字符放在字符串常量的末尾。C 编译器会在初始化数组时,自动把\0放在字符串的末尾。
让我们尝试输出上面的字符串:
#include <stdio.h>
int main ()
{
char site[7] = {'R', 'U', 'N', 'O', 'O', 'B', '\0'};
printf("菜鸟教程: %s\n", site );
return 0;
}
菜鸟教程: RUNOOB
C 中有大量操作字符串的函数:
| 序号 | 函数 & 目的 |
|---|---|
| 1 | strcpy(s1, s2); 复制字符串 s2 到字符串 s1。 |
| 2 | strcat(s1, s2); 连接字符串 s2 到字符串 s1 的末尾。 |
| 3 | strlen(s1); 返回字符串 s1 的长度。 |
| 4 | strcmp(s1, s2); 如果 s1 和 s2 是相同的,则返回 0;如果 s1<s2 则返回小于 0;如果 s1>s2 则返回大于 0。 |
| 5 | strchr(s1, ch); 返回一个指针,指向字符串 s1 中字符 ch 的第一次出现的位置。 |
| 6 | strstr(s1, s2); 返回一个指针,指向字符串 s1 中字符串 s2 的第一次出现的位置。 |
#include <stdio.h>
#include <string.h>
int main ()
{
char str1[14] = "runoob";
char str2[14] = "google";
char str3[14];
int len ;
/* 复制 str1 到 str3 */
strcpy(str3, str1);
printf("strcpy( str3, str1) : %s\n", str3 );
/* 连接 str1 和 str2 */
strcat( str1, str2);
printf("strcat( str1, str2): %s\n", str1 );
/* 连接后,str1 的总长度 */
len = strlen(str1);
printf("strlen(str1) : %d\n", len );
return 0;
}
字符串变量的声明
字符串变量可以声明成一个字符数组,也可以声明成一个指针,指向字符数组。
// 写法一
char s[14] = "Hello, world!";
// 写法二
char* s = "Hello, world!";
上面两种写法都声明了一个字符串变量s。如果采用第一种写法,由于字符数组的长度可以让编译器自动计算,所以声明时可以省略字符数组的长度。
char s[] = "Hello, world!";
上面示例中,编译器会将数组s的长度指定为14,正好容纳后面的字符串。
字符指针和字符数组,这两种声明字符串变量的写法基本是等价的,但是有两个差异。
第一个差异是,指针指向的字符串,在 C 语言内部被当作常量,不能修改字符串本身。
char* s = "Hello, world!";
s[0] = 'z'; // 错误
上面代码使用指针,声明了一个字符串变量,然后修改了字符串的第一个字符。这种写法是错的,会导致难以预测的后果,执行时很可能会报错。
如果使用数组声明字符串变量,就没有这个问题,可以修改数组的任意成员。
char s[] = "Hello, world!";
s[0] = 'z';
为什么字符串声明为指针时不能修改,声明为数组时就可以修改?原因是系统会将字符串的字面量保存在内存的常量区,这个区是不允许用户修改的。声明为指针时,指针变量存储的值是一个指向常量区的内存地址,因此用户不能通过这个地址去修改常量区。但是,声明为数组时,编译器会给数组单独分配一段内存,字符串字面量会被编译器解释成字符数组,逐个字符写入这段新分配的内存之中,而这段新内存是允许修改的。
为了提醒用户,字符串声明为指针后不得修改,可以在声明时使用const说明符,保证该字符串是只读的。
const char* s = "Hello, world!";
上面字符串声明为指针时,使用了const说明符,就保证了该字符串无法修改。一旦修改,编译器肯定会报错。
第二个差异是,指针变量可以指向其它字符串。
char* s = "hello";
s = "world";
上面示例中,字符指针可以指向另一个字符串。
但是,字符数组变量不能指向另一个字符串。
char s[] = "hello";
s = "world"; // 报错
上面示例中,字符数组的数组名,总是指向初始化时的字符串地址,不能修改。
同样的原因,声明字符数组后,不能直接用字符串赋值。
char s[10];
s = "abc"; // 错误
上面示例中,不能直接把字符串赋值给字符数组变量,会报错。原因是字符数组的变量名,跟所指向的数组是绑定的,不能指向另一个地址。
为什么数组变量不能赋值为另一个数组?原因是数组变量所在的地址无法改变,或者说,编译器一旦为数组变量分配地址后,这个地址就绑定这个数组变量了,这种绑定关系是不变的。C 语言也因此规定,数组变量是一个不可修改的左值,即不能用赋值运算符为它重新赋值。
想要重新赋值,必须使用 C 语言原生提供的strcpy()函数,通过字符串拷贝完成赋值。这样做以后,数组变量的地址还是不变的,即strcpy()只是在原地址写入新的字符串,而不是让数组变量指向新的地址。
char s[10];
strcpy(s, "abc");
上面示例中,strcpy()函数把字符串abc拷贝给变量s,这个函数的详细用法会在后面介绍。
字符串数组
如果一个数组的每个成员都是一个字符串,需要通过二维的字符数组实现。每个字符串本身是一个字符数组,多个字符串再组成一个数组。
char weekdays[7][10] = {
"Monday",
"Tuesday",
"Wednesday",
"Thursday",
"Friday",
"Saturday",
"Sunday"
};
上面示例就是一个字符串数组,一共包含7个字符串,所以第一维的长度是7。其中,最长的字符串的长度是10(含结尾的终止符\0),所以第二维的长度统一设为10。
因为第一维的长度,编译器可以自动计算,所以可以省略。
char weekdays[][10] = {
"Monday",
"Tuesday",
"Wednesday",
"Thursday",
"Friday",
"Saturday",
"Sunday"
};
上面示例中,二维数组第一维的长度,可以由编译器根据后面的赋值,自动计算,所以可以不写。
数组的第二维,长度统一定为10,有点浪费空间,因为大多数成员的长度都小于10。解决方法就是把数组的第二维,从字符数组改成字符指针。
char* weekdays[] = {
"Monday",
"Tuesday",
"Wednesday",
"Thursday",
"Friday",
"Saturday",
"Sunday"
};
上面的字符串数组,其实是一个一维数组,成员就是7个字符指针,每个指针指向一个字符串(字符数组)。
遍历字符串数组的写法如下。
for (int i = 0; i < 7; i++) {
printf("%s\n", weekdays[i]);
}
字符串库string.h
strlen()
strlen()函数返回字符串的字节长度,不包括末尾的空字符\0。该函数的原型如下。
// string.h
size_t strlen(const char* s);
它的参数是字符串变量,返回的是size_t类型的无符号整数,除非是极长的字符串,一般情况下当作int类型处理即可。下面是一个用法实例。
char* str = "hello";
int len = strlen(str); // 5
strlen()的原型在标准库的string.h文件中定义,使用时需要加载头文件string.h。
#include <stdio.h>
#include <string.h>
int main(void) {
char* s = "Hello, world!";
printf("The string is %zd characters long.\n", strlen(s));
}
注意,字符串长度(strlen())与字符串变量长度(sizeof()),是两个不同的概念。
char s[50] = "hello";
printf("%d\n", strlen(s)); // 5
printf("%d\n", sizeof(s)); // 50
上面示例中,字符串长度是5,字符串变量长度是50。
如果不使用这个函数,可以通过判断字符串末尾的\0,自己计算字符串长度。
int my_strlen(char *s) {
int count = 0;
while (s[count] != '\0')
count++;
return count;
}
strcpy()&strncpy()
字符串的复制,不能使用赋值运算符,直接将一个字符串赋值给字符数组变量。
char str1[10];
char str2[10];
str1 = "abc"; // 报错
str2 = str1; // 报错
上面两种字符串的复制写法,都是错的。因为数组的变量名是一个固定的地址,不能修改,使其指向另一个地址。
如果是字符指针,赋值运算符(=)只是将一个指针的地址复制给另一个指针,而不是复制字符串。
char* s1;
char* s2;
s1 = "abc";
s2 = s1;
上面代码可以运行,结果是两个指针变量s1和s2指向同一字符串,而不是将字符串s1的内容复制给s2。(但在其他高级语言中,字符串是不可变类型,赋值只是把内容拷贝了一份)
C 语言提供了strcpy()函数,用于将一个字符串的内容复制到另一个字符串,相当于字符串赋值。该函数的原型定义在string.h头文件里面。
strcpy(char dest[], const char source[])
strcpy()接受两个参数,第一个参数是目的字符串数组,第二个参数是源字符串数组。复制字符串之前,必须要保证第一个参数的长度不小于第二个参数,否则虽然不会报错,但会溢出第一个字符串变量的边界,发生难以预料的结果。第二个参数的const说明符,表示这个函数不会修改第二个字符串。
#include <stdio.h>
#include <string.h>
int main(void) {
char s[] = "Hello, world!";
char t[100];
strcpy(t, s);
t[0] = 'z';
printf("%s\n", s); // "Hello, world!"
printf("%s\n", t); // "zello, world!"
}
上面示例将变量s的值,拷贝一份放到变量t,变成两个不同的字符串,修改一个不会影响到另一个。另外,变量t的长度大于s,复制后多余的位置(结束标志\0后面的位置)都为随机值。
strcpy()也可以用于字符数组的赋值。
char str[10];
strcpy(str, "abcd");
上面示例将字符数组变量,赋值为字符串“abcd”。
strcpy()的返回值是一个字符串指针(即char*),指向第一个参数。
char* s1 = "beast";
char s2[40] = "Be the best that you can be.";
char* ps;
ps = strcpy(s2 + 7, s1);
puts(s2); // Be the beast
puts(ps); // beast
上面示例中,从s2的第7个位置开始拷贝字符串beast,前面的位置不变。这导致s2后面的内容都被截去了,因为会连beast结尾的空字符一起拷贝。strcpy()返回的是一个指针,指向拷贝开始的位置。
strcpy()返回值的另一个用途,是连续为多个字符数组赋值。
strcpy(str1, strcpy(str2, "abcd"));
上面示例调用两次strcpy(),完成两个字符串变量的赋值。
另外,strcpy()的第一个参数最好是一个已经声明的数组,而不是声明后没有进行初始化的字符指针。
char* str;
strcpy(str, "hello world"); // 错误
上面的代码是有问题的。strcpy()将字符串分配给指针变量str,但是str并没有进行初始化,指向的是一个随机的位置,因此字符串可能被复制到任意地方。
如果不用strcpy(),自己实现字符串的拷贝,可以用下面的代码。
char* strcpy(char* dest, const char* source) {
char* ptr = dest;
while (*dest++ = *source++);
return ptr;
}
int main(void) {
char str[25];
strcpy(str, "hello world");
printf("%s\n", str);
return 0;
}
上面代码中,关键的一行是·while (*dest++ = source++)·,这是一个循环,依次将source的每个字符赋值给dest,然后移向下一个位置,直到遇到\0,循环判断条件不再为真,从而跳出循环。其中,dest++这个表达式等同于(dest++),即先返回dest这个地址,再进行自增运算移向下一个位置,而dest可以对当前位置赋值。
strcpy()函数有安全风险,因为它并不检查目标字符串的长度,是否足够容纳源字符串的副本,可能导致写入溢出。如果不能保证不会发生溢出,建议使用strncpy()函数代替。
strncpy()跟strcpy()的用法完全一样,只是多了第3个参数,用来指定复制的最大字符数,防止溢出目标字符串变量的边界。
char* strncpy(
char* dest,
char* src,
size_t n
);
上面原型中,第三个参数n定义了复制的最大字符数。如果达到最大字符数以后,源字符串仍然没有复制完,就会停止复制,这时目的字符串结尾将没有终止符\0,这一点务必注意。如果源字符串的字符数小于n,则strncpy()的行为与strcpy()完全一致。
strncpy(str1, str2, sizeof(str1) - 1);
str1[sizeof(str1) - 1] = '\0';
上面示例中,字符串str2复制给str1,但是复制长度最多为str1的长度减去1,str1剩下的最后一位用于写入字符串的结尾标志\0。这是因为strncpy()不会自己添加\0,如果复制的字符串片段不包含结尾标志,就需要手动添加。
strncpy()也可以用来拷贝部分字符串。
char s1[40];
char s2[12] = "hello world";
strncpy(s1, s2, 5);
s1[5] = '\0';
printf("%s\n", s1); // hello
上面示例中,指定只拷贝前5个字符。
strcat()
strcat()函数用于连接字符串。它接受两个字符串作为参数,把第二个字符串的副本添加到第一个字符串的末尾。这个函数会改变第一个字符串,但是第二个字符串不变。
该函数的原型定义在string.h头文件里面。
char* strcat(char* s1, const char* s2);
strcat()的返回值是一个字符串指针,指向第一个参数。
char s1[12] = "hello";
char s2[6] = "world";
strcat(s1, s2);
puts(s1); // "helloworld"
上面示例中,调用strcat()以后,可以看到字符串s1的值变了。
注意,strcat()的第一个参数的长度,必须足以容纳添加第二个参数字符串。否则,拼接后的字符串会溢出第一个字符串的边界,写入相邻的内存单元,这是很危险的,建议使用下面的strncat()代替。
strcat()&strncat()
strcat()函数用于连接字符串。它接受两个字符串作为参数,把第二个字符串的副本添加到第一个字符串的末尾。这个函数会改变第一个字符串,但是第二个字符串不变。
该函数的原型定义在string.h头文件里面。
char* strcat(char* s1, const char* s2);
strcat()的返回值是一个字符串指针,指向第一个参数。
char s1[12] = "hello";
char s2[6] = "world";
strcat(s1, s2);
puts(s1); // "helloworld"
上面示例中,调用strcat()以后,可以看到字符串s1的值变了。
注意,strcat()的第一个参数的长度,必须足以容纳添加第二个参数字符串。否则,拼接后的字符串会溢出第一个字符串的边界,写入相邻的内存单元,这是很危险的,建议使用下面的strncat()代替。
strncat()用于连接两个字符串,用法与strcat()完全一致,只是增加了第三个参数,指定最大添加的字符数。在添加过程中,一旦达到指定的字符数,或者在源字符串中遇到空字符\0,就不再添加了。它的原型定义在string.h头文件里面。
char* strncat(
const char* dest,
const char* src,
size_t n
);
strncat()返回第一个参数,即目标字符串指针。
为了保证连接后的字符串,不超过目标字符串的长度,strncat()通常会写成下面这样。
strncat(
str1,
str2,
sizeof(str1) - strlen(str1) - 1
);
**strncat()总是会在拼接结果的结尾,自动添加空字符\0,所以第三个参数的最大值,应该是str1的变量长度减去str1的字符串长度,再减去1。**下面是一个用法实例。
char s1[10] = "Monday";
char s2[8] = "Tuesday";
strncat(s1, s2, 3);
puts(s1); // "MondayTue"
上面示例中,s1的变量长度是10,字符长度是6,两者相减后再减去1,得到3,表明s1最多可以再添加三个字符,所以得到的结果是MondayTue。
strcmp()&strncmp()
如果要比较两个字符串,无法直接比较,只能一个个字符进行比较,C 语言提供了strcmp()函数。
strcmp()函数用于比较两个字符串的内容。该函数的原型如下,定义在string.h头文件里面。
int strcmp(const char* s1, const char* s2);
按照字典顺序,如果两个字符串相同,返回值为0;如果s1小于s2,strcmp()返回值小于0;如果s1大于s2,返回值大于0。
下面是一个用法示例。
// s1 = Happy New Year
// s2 = Happy New Year
// s3 = Happy Holidays
strcmp(s1, s2) // 0
strcmp(s1, s3) // 大于 0
strcmp(s3, s1) // 小于 0
注意,strcmp()只用来比较字符串,不用来比较字符。因为字符就是小整数,直接用相等运算符(==)就能比较。所以,不要把字符类型(char)的值,放入strcmp()当作参数。
由于strcmp()比较的是整个字符串,C 语言又提供了strncmp()函数,只比较到指定的位置。
该函数增加了第三个参数,指定了比较的字符数。它的原型定义在string.h头文件里面。
int strncmp(
const char* s1,
const char* s2,
size_t n
);
它的返回值与strcmp()一样。如果两个字符串相同,返回值为0;如果s1小于s2,strcmp()返回值小于0;如果s1大于s2,返回值大于0。
下面是一个例子。
char s1[12] = "hello world";
char s2[12] = "hello C";
if (strncmp(s1, s2, 5) == 0) {
printf("They all have hello.\n");
}
上面示例只比较两个字符串的前5个字符。
sprintf(),snprintf()
sprintf()函数跟printf()类似,但是用于将数据写入字符串,而不是输出到显示器。该函数的原型定义在stdio.h头文件里面。
int sprintf(char* s, const char* format, ...);
sprintf()的第一个参数是字符串指针变量,其余参数和printf()相同,即第二个参数是格式字符串,后面的参数是待写入的变量列表。
char first[6] = "hello";
char last[6] = "world";
char s[40];
sprintf(s, "%s %s", first, last);
printf("%s\n", s); // hello world
上面示例中,sprintf()将输出内容组合成“hello world”,然后放入了变量s。
sprintf()的返回值是写入变量的字符数量(不计入尾部的空字符\0)。如果遇到错误,返回负值。
sprintf()有严重的安全风险,如果写入的字符串过长,超过了目标字符串的长度,sprintf()依然会将其写入,导致发生溢出。为了控制写入的字符串的长度,C 语言又提供了另一个函数snprintf()。
snprintf()只比sprintf()多了一个参数n,用来控制写入变量的字符串不超过n - 1个字符,剩下一个位置写入空字符\0。下面是它的原型。
int snprintf(char*s, size_t n, const char* format, ...);
snprintf()总是会自动写入字符串结尾的空字符。如果尝试写入的字符数超过指定的最大字符数,snprintf()会写入 n - 1 个字符,留出最后一个位置写入空字符。
下面是一个例子。
snprintf(s, 12, "%s %s", "hello", "world");
上面的例子中,snprintf()的第二个参数是12,表示写入字符串的最大长度不超过12(包括尾部的空字符)。
snprintf()的返回值是写入格式字符串的字符数量(不计入尾部的空字符\0)。如果n足够大,返回值应该小于n,但是有时候格式字符串的长度可能大于n,那么这时返回值会大于n,但实际上真正写入变量的还是n-1个字符。如果遇到错误,返回一个负值。因此,返回值只有在非负并且小于n时,才能确认完整的格式字符串写入了变量。
C 结构体
结构是 C 编程中另一种用户自定义的可用的数据类型,它允许存储不同类型的数据项。
定义结构
结构体定义由关键字 struct 和结构体名组成,结构体名可以根据需要自行定义。
struct 语句定义了一个包含多个成员的新的数据类型,struct 语句的格式如下:
struct tag {
member-list
member-list
member-list
...
} variable-list ;
tag 是结构体标签。
member-list 是标准的变量定义,比如 int i; 或者 float f;,或者其他有效的变量定义。
variable-list 结构变量,定义在结构的末尾,最后一个分号之前,可以指定一个或多个结构变量。下面是声明 Book 结构的方式:
struct Books
{
char title[50];
char author[50];
char subject[100];
int book_id;
} book;
在一般情况下,tag、member-list、variable-list 这 3 部分至少要出现 2 个。以下为实例:
//此声明声明了拥有3个成员的结构体,分别为整型的a,字符型的b和双精度的c
//同时又声明了结构体变量s1
//这个结构体并没有标明其标签
// 相当于匿名结构体
struct
{
int a;
char b;
double c;
} s1;
//此声明声明了拥有3个成员的结构体,分别为整型的a,字符型的b和双精度的c
//结构体的标签被命名为SIMPLE,没有声明变量
struct SIMPLE
{
int a;
char b;
double c;
};
//用SIMPLE标签的结构体,另外声明了变量t1、t2、t3
struct SIMPLE t1, t2[20], *t3;
//也可以用typedef创建新类型
typedef struct
{
int a;
char b;
double c;
} Simple2;
//现在可以用Simple2作为类型声明新的结构体变量
Simple2 u1, u2[20], *u3;
在上面的声明中,第一个和第二声明被编译器当作两个完全不同的类型,即使他们的成员列表是一样的,如果令 t3=&s1,则是非法的。
结构体的成员可以包含其他结构体,也可以包含指向自己结构体类型的指针,而通常这种指针的应用是为了实现一些更高级的数据结构如链表和树等。
//此结构体的声明包含了其他的结构体
struct COMPLEX
{
char string[100];
struct SIMPLE a;
};
//此结构体的声明包含了指向自己类型的指针
struct NODE
{
char string[100];
struct NODE *next_node;
};
如果两个结构体互相包含,则需要对其中一个结构体进行不完整声明,如下所示:
struct B; //对结构体B进行不完整声明
//结构体A中包含指向结构体B的指针
struct A
{
struct B *partner;
//other members;
};
//结构体B中包含指向结构体A的指针,在A声明完后,B也随之进行声明
struct B
{
struct A *partner;
//other members;
};
结构体变量的初始化
和其它类型变量一样,对结构体变量可以在定义时指定初始值。(只允许按照顺序初始化)
#include <stdio.h>
struct Books
{
char title[50];
char author[50];
char subject[100];
int book_id;
} book = {"C 语言", "RUNOOB", "编程语言", 123456};
int main()
{
printf("title : %s\nauthor: %s\nsubject: %s\nbook_id: %d\n", book.title, book.author, book.subject, book.book_id);
}
访问结构成员
为了访问结构的成员,使用成员访问运算符(.)。:
#include <stdio.h>
#include <string.h>
struct Books
{
char title[50];
char author[50];
char subject[100];
int book_id;
};
int main( )
{
struct Books Book1; /* 声明 Book1,类型为 Books */
struct Books Book2; /* 声明 Book2,类型为 Books */
/* Book1 详述 */
strcpy( Book1.title, "C Programming");
strcpy( Book1.author, "Nuha Ali");
strcpy( Book1.subject, "C Programming Tutorial");
Book1.book_id = 6495407;
/* Book2 详述 */
strcpy( Book2.title, "Telecom Billing");
strcpy( Book2.author, "Zara Ali");
strcpy( Book2.subject, "Telecom Billing Tutorial");
Book2.book_id = 6495700;
/* 输出 Book1 信息 */
printf( "Book 1 title : %s\n", Book1.title);
printf( "Book 1 author : %s\n", Book1.author);
printf( "Book 1 subject : %s\n", Book1.subject);
printf( "Book 1 book_id : %d\n", Book1.book_id);
/* 输出 Book2 信息 */
printf( "Book 2 title : %s\n", Book2.title);
printf( "Book 2 author : %s\n", Book2.author);
printf( "Book 2 subject : %s\n", Book2.subject);
printf( "Book 2 book_id : %d\n", Book2.book_id);
return 0;
}
当上面的代码被编译和执行时,它会产生下列结果:
Book 1 title : C Programming
Book 1 author : Nuha Ali
Book 1 subject : C Programming Tutorial
Book 1 book_id : 6495407
Book 2 title : Telecom Billing
Book 2 author : Zara Ali
Book 2 subject : Telecom Billing Tutorial
Book 2 book_id : 6495700
struct 的复制
struct 变量可以使用赋值运算符(=),复制给另一个变量,这时会生成一个全新的副本。系统会分配一块新的内存空间,大小与原来的变量相同,把每个属性都复制过去,即原样生成了一份数据。这一点跟数组的复制不一样,务必小心。
struct cat { char name[30]; short age; } a, b;
strcpy(a.name, "Hula");
a.age = 3;
b = a;
b.name[0] = 'M';
printf("%s\n", a.name); // Hula
printf("%s\n", b.name); // Mula
上面示例中,变量b是变量a的副本,两个变量的值是各自独立的,修改掉b.name不影响a.name。
上面这个示例是有前提的,就是 struct 结构的属性必须定义成字符数组,才能复制数据。如果稍作修改,属性定义成字符指针,结果就不一样。
struct cat { char* name; short age; } a, b;
a.name = "Hula";
a.age = 3;
b = a;
上面示例中,name属性变成了一个字符指针,这时a赋值给b,导致b.name也是同样的字符指针,指向同一个地址,也就是说两个属性共享同一个地址。因为这时,struct 结构内部保存的是一个指针,而不是上一个例子的数组,这时复制的就不是字符串本身,而是它的指针。并且,这个时候也没法修改字符串,因为字符指针指向的字符串是不能修改的。
总结一下,赋值运算符(=)可以将 struct 结构每个属性的值,一模一样复制一份,拷贝给另一个 struct 变量。这一点跟数组完全不同,使用赋值运算符复制数组,不会复制数据,只会共享地址。
注意,这种赋值要求两个变量是同一个类型,不同类型的 struct 变量无法互相赋值。
另外,C 语言没有提供比较两个自定义数据结构是否相等的方法,无法用比较运算符(比如==和!=)比较两个数据结构是否相等或不等。
结构作为函数参数
可以把结构作为函数参数,传参方式与其他类型的变量或指针类似。
#include <stdio.h>
#include <string.h>
struct Books
{
char title[50];
char author[50];
char subject[100];
int book_id;
};
/* 函数声明 */
void printBook( struct Books book );
int main( )
{
struct Books Book1; /* 声明 Book1,类型为 Books */
struct Books Book2; /* 声明 Book2,类型为 Books */
/* Book1 详述 */
strcpy( Book1.title, "C Programming");
strcpy( Book1.author, "Nuha Ali");
strcpy( Book1.subject, "C Programming Tutorial");
Book1.book_id = 6495407;
/* Book2 详述 */
strcpy( Book2.title, "Telecom Billing");
strcpy( Book2.author, "Zara Ali");
strcpy( Book2.subject, "Telecom Billing Tutorial");
Book2.book_id = 6495700;
/* 输出 Book1 信息 */
printBook( Book1 );
/* 输出 Book2 信息 */
printBook( Book2 );
return 0;
}
void printBook( struct Books book )
{
printf( "Book title : %s\n", book.title);
printf( "Book author : %s\n", book.author);
printf( "Book subject : %s\n", book.subject);
printf( "Book book_id : %d\n", book.book_id);
}
以定义指向结构的指针,方式与定义指向其他类型变量的指针相似,如下所示:
struct Books *struct_pointer;
现在可以在上述定义的指针变量中存储结构变量的地址。为了查找结构变量的地址,请把 & 运算符放在结构名称的前面,如下所示:
struct_pointer = &Book1;
为了使用指向该结构的指针访问结构的成员,必须使用 -> 运算符,如下所示:
struct_pointer->title;
ps: Go的语法糖:对结构体指针用.取成员也可以取得到。
#include <stdio.h>
#include <string.h>
struct Books
{
char title[50];
char author[50];
char subject[100];
int book_id;
};
/* 函数声明 */
void printBook( struct Books *book );
int main( )
{
struct Books Book1; /* 声明 Book1,类型为 Books */
struct Books Book2; /* 声明 Book2,类型为 Books */
/* Book1 详述 */
strcpy( Book1.title, "C Programming");
strcpy( Book1.author, "Nuha Ali");
strcpy( Book1.subject, "C Programming Tutorial");
Book1.book_id = 6495407;
/* Book2 详述 */
strcpy( Book2.title, "Telecom Billing");
strcpy( Book2.author, "Zara Ali");
strcpy( Book2.subject, "Telecom Billing Tutorial");
Book2.book_id = 6495700;
/* 通过传 Book1 的地址来输出 Book1 信息 */
printBook( &Book1 );
/* 通过传 Book2 的地址来输出 Book2 信息 */
printBook( &Book2 );
return 0;
}
void printBook( struct Books *book )
{
printf( "Book title : %s\n", book->title);
printf( "Book author : %s\n", book->author);
printf( "Book subject : %s\n", book->subject);
printf( "Book book_id : %d\n", book->book_id);
}
当上面的代码被编译和执行时,它会产生下列结果:
Book title : C Programming
Book author : Nuha Ali
Book subject : C Programming Tutorial
Book book_id : 6495407
Book title : Telecom Billing
Book author : Zara Ali
Book subject : Telecom Billing Tutorial
Book book_id : 6495700
结构体大小的计算
C 语言中,可以使用 sizeof 运算符来计算结构体的大小,sizeof 返回的是给定类型或变量的字节大小。
对于结构体,sizeof 将返回结构体的总字节数,包括所有成员变量的大小以及可能的填充字节。
以下实例演示了如何计算结构体的大小:
#include <stdio.h>
struct Person {
char name[20];
int age;
float height;
};
int main() {
struct Person person;
printf("结构体 Person 大小为: %zu 字节\n", sizeof(person));
return 0;
}
结构体 Person 大小为: 28 字节
注意,结构体的大小可能会受到编译器的优化和对齐规则的影响,编译器可能会在结构体中插入一些额外的填充字节以对齐结构体的成员变量,以提高内存访问效率。因此,结构体的实际大小可能会大于成员变量大小的总和,如果需要确切地了解结构体的内存布局和对齐方式,可以使用 offsetof 宏和 attribute((packed)) 属性等进一步控制和查询结构体的大小和对齐方式。
struct 指针
如果将 struct 变量传入函数,函数内部得到的是一个原始值的副本。
#include <stdio.h>
struct turtle {
char* name;
char* species;
int age;
};
void happy(struct turtle t) {
t.age = t.age + 1;
}
int main() {
struct turtle myTurtle = {"MyTurtle", "sea turtle", 99};
happy(myTurtle);
printf("Age is %i\n", myTurtle.age); // 输出 99
return 0;
}
上面示例中,函数happy()传入的是一个 struct 变量myTurtle,函数内部有一个自增操作。但是,执行完happy()以后,函数外部的age属性值根本没变。原因就是函数内部得到的是 struct 变量的副本,改变副本影响不到函数外部的原始数据。
通常情况下,开发者希望传入函数的是同一份数据,函数内部修改数据以后,会反映在函数外部。而且,传入的是同一份数据,也有利于提高程序性能。这时就需要将 struct 变量的指针传入函数,通过指针来修改 struct 属性,就可以影响到函数外部。
struct 指针传入函数的写法如下。
void happy(struct turtle* t) {
}
happy(&myTurtle);
上面代码中,t是 struct 结构的指针,调用函数时传入的是指针。struct 类型跟数组不一样,类型标识符本身并不是指针,所以传入时,指针必须写成&myTurtle。
函数内部也必须使用(*t).age的写法,从指针拿到 struct 结构本身。
void happy(struct turtle* t) {
(*t).age = (*t).age + 1;
}
上面示例中,(*t).age不能写成*t.age,因为点运算符.的优先级高于*。*t.age这种写法会将t.age看成一个指针,然后取它对应的值,会出现无法预料的结果。
现在,重新编译执行上面的整个示例,happy()内部对 struct 结构的操作,就会反映到函数外部。
(*t).age这样的写法很麻烦。C 语言就引入了一个新的箭头运算符(->),可以从 struct 指针上直接获取属性,大大增强了代码的可读性。
void happy(struct turtle* t) {
t->age = t->age + 1;
}
总结一下,对于 struct 变量名,使用点运算符(.)获取属性;对于 struct 变量指针,使用箭头运算符(->)获取属性。以变量myStruct为例,假设ptr是它的指针,那么下面三种写法是同一回事。
// ptr == &myStruct
myStruct.prop == (*ptr).prop == ptr->prop
struct 的嵌套
struct 结构的成员可以是另一个 struct 结构。
struct species {
char* name;
int kinds;
};
struct fish {
char* name;
int age;
struct species breed;
};
上面示例中,fish的属性breed是另一个 struct 结构species。
赋值的时候有多种写法。
// 写法一
struct fish shark = {"shark", 9, {"Selachimorpha", 500}};
// 写法二
struct species myBreed = {"Selachimorpha", 500};
struct fish shark = {"shark", 9, myBreed};
// 写法三
struct fish shark = {
.name="shark",
.age=9,
.breed={"Selachimorpha", 500}
};
// 写法四
struct fish shark = {
.name="shark",
.age=9,
.breed.name="Selachimorpha",
.breed.kinds=500
};
printf("Shark's species is %s", shark.breed.name);
上面示例展示了嵌套 Struct 结构的四种赋值写法。另外,引用breed属性的内部属性,要使用两次点运算符(shark.breed.name)。
下面是另一个嵌套 struct 的例子。
struct name {
char first[50];
char last[50];
};
struct student {
struct name name;
short age;
char sex;
} student1;
strcpy(student1.name.first, "Harry");
strcpy(student1.name.last, "Potter");
// or
struct name myname = {"Harry", "Potter"};
student1.name = myname;
上面示例中,自定义类型student的name属性是另一个自定义类型,如果要引用后者的属性,就必须使用两个.运算符,比如student1.name.first。另外,对字符数组属性赋值,要使用strcpy()函数,不能直接赋值,因为直接改掉字符数组名的地址会报错。
struct 结构内部不仅可以引用其他结构,还可以自我引用,即结构内部引用当前结构。比如,链表结构的节点就可以写成下面这样。
struct node {
int data;
struct node* next;
};
上面示例中,node结构的next属性,就是指向另一个node实例的指针。下面,使用这个结构自定义一个数据链表。
struct node {
int data;
struct node* next;
};
struct node* head;
// 生成一个三个节点的列表 (11)->(22)->(33)
head = malloc(sizeof(struct node));
head->data = 11;
head->next = malloc(sizeof(struct node));
head->next->data = 22;
head->next->next = malloc(sizeof(struct node));
head->next->next->data = 33;
head->next->next->next = NULL;
// 遍历这个列表
for (struct node *cur = head; cur != NULL; cur = cur->next) {
printf("%d\n", cur->data);
}
上面示例是链表结构的最简单实现,通过for循环可以对其进行遍历。
位字段
struct 还可以用来定义二进制位组成的数据结构,称为“位字段”(bit field),这对于操作底层的二进制数据非常有用。
struct {
unsigned int ab:1;
unsigned int cd:1;
unsigned int ef:1;
unsigned int gh:1;
} synth;
synth.ab = 0;
synth.cd = 1;
上面示例中,每个属性后面的:1,表示指定这些属性只占用一个二进制位,所以这个数据结构一共是4个二进制位。
注意,定义二进制位时,结构内部的各个属性只能是整数类型。
实际存储的时候,C 语言会按照int类型占用的字节数,存储一个位字段结构。如果有剩余的二进制位,可以使用未命名属性,填满那些位。也可以使用宽度为0的属性,表示占满当前字节剩余的二进制位,迫使下一个属性存储在下一个字节。
struct {
unsigned int field1 : 1;
unsigned int : 2;
unsigned int field2 : 1;
unsigned int : 0;
unsigned int field3 : 1;
} stuff;
上面示例中,stuff.field1与stuff.field2之间,有一个宽度为两个二进制位的未命名属性。stuff.field3将存储在下一个字节。
C 共用体
共用体是一种特殊的数据类型,允许您在相同的内存位置存储不同的数据类型。
定义共用体
为了定义共用体,必须使用 union 语句,方式与定义结构类似。union 语句定义了一个新的数据类型,带有多个成员。union 语句的格式如下:
union [union tag]
{
member definition;
member definition;
...
member definition;
} [one or more union variables];
union tag 是可选的,每个 member definition 是标准的变量定义,比如 int i; 或者 float f; 或者其他有效的变量定义。在共用体定义的末尾,最后一个分号之前,您可以指定一个或多个共用体变量,这是可选的。下面定义一个名为 Data 的共用体类型,有三个成员 i、f 和 str:
union Data
{
int i;
float f;
char str[20];
} data;
现在,Data 类型的变量可以存储一个整数、一个浮点数,或者一个字符串。这意味着一个变量(相同的内存位置)可以存储多个多种类型的数据。您可以根据需要在一个共用体内使用任何内置的或者用户自定义的数据类型。
共用体占用的内存应足够存储共用体中最大的成员。例如,在上面的实例中,Data 将占用 20 个字节的内存空间,因为在各个成员中,字符串所占用的空间是最大的。下面的实例将显示上面的共用体占用的总内存大小:
#include <stdio.h>
#include <string.h>
union Data
{
int i;
float f;
char str[20];
};
int main( )
{
union Data data;
printf( "Memory size occupied by data : %d\n", sizeof(data));
return 0;
}
当上面的代码被编译和执行时,它会产生下列结果:
Memory size occupied by data : 20
访问共用体成员
为了访问共用体的成员,使用成员访问运算符(.)。
#include <stdio.h>
#include <string.h>
union Data
{
int i;
float f;
char str[20];
};
int main( )
{
union Data data;
data.i = 10;
data.f = 220.5;
strcpy( data.str, "C Programming");
printf( "data.i : %d\n", data.i);
printf( "data.f : %f\n", data.f);
printf( "data.str : %s\n", data.str);
return 0;
}
当上面的代码被编译和执行时,它会产生下列结果:
data.i : 1917853763
data.f : 4122360580327794860452759994368.000000
data.str : C Programming
在这里,可以看到共用体的 i 和 f 成员的值有损坏,因为最后赋给变量的值占用了内存位置,这也是 str 成员能够完好输出的原因。
在同一时间只使用一个变量:
#include <stdio.h>
#include <string.h>
union Data
{
int i;
float f;
char str[20];
};
int main( )
{
union Data data;
data.i = 10;
printf( "data.i : %d\n", data.i);
data.f = 220.5;
printf( "data.f : %f\n", data.f);
strcpy( data.str, "C Programming");
printf( "data.str : %s\n", data.str);
return 0;
}
当上面的代码被编译和执行时,它会产生下列结果:
data.i : 10
data.f : 220.500000
data.str : C Programming
在这里,所有的成员都能完好输出,因为同一时间只用到一个成员。
C 位域
C 语言的位域(bit-field)是一种特殊的结构体成员,允许按位对成员进行定义,指定其占用的位数。
如果程序的结构中包含多个开关的变量,即变量值为 TRUE/FALSE(C里面没有bool类型),如下:
struct
{
unsigned int widthValidated;
unsigned int heightValidated;
} status;
这种结构需要 8 字节的内存空间(C的uint占4个字节),但在实际上,在每个变量中,只存储 0 或 1,在这种情况下,C 语言提供了一种更好的利用内存空间的方式。如果您在结构内使用这样的变量,您可以定义变量的宽度来告诉编译器,您将只使用这些字节。例如,上面的结构可以重写成:
struct
{
unsigned int widthValidated : 1;
unsigned int heightValidated : 1;
} status;
现在,上面的结构中,status 变量将占用 4 个字节的内存空间,但是只有 2 位被用来存储值。
如果用了 32 个变量,每一个变量宽度为 1 位,那么 status 结构将使用 4 个字节,但只要再多用一个变量,如果使用了 33 个变量,那么它将分配内存的下一段来存储第 33 个变量,这个时候就开始使用 8 个字节。
在C语言中,unsigned int的大小通常是4字节,这是由编译器和操作系统决定的。但是,在结构体中,使用了位域(bit-fields)来声明两个成员,每个成员只占用1位。尽管每个成员只使用1位,但由于内存的最小单位是字节,编译器会对结构体进行内存对齐,以提高访问速度。
每个成员都使用了1位,但由于对齐规则,编译器会将每个成员扩展到整个字节。因此,尽管widthValidated和heightValidated只使用了1位,但它们实际上会占用1字节的内存空间。因为内存对齐的规则通常是按照数据的自然大小来对齐,而在大多数系统上,1字节是最小的可寻址内存单元。
所以,即使每个成员只用了1位,整个结构体也会被分配为4个字节的内存空间,这是unsigned int的大小。这样做的目的是为了满足内存对齐的要求,提高结构体访问的效率。
让我们看看下面的实例来理解这个概念:
#include <stdio.h>
#include <string.h>
/* 定义简单的结构 */
struct
{
unsigned int widthValidated;
unsigned int heightValidated;
} status1;
/* 定义位域结构 */
struct
{
unsigned int widthValidated : 1;
unsigned int heightValidated : 1;
} status2;
int main( )
{
printf( "Memory size occupied by status1 : %d\n", sizeof(status1));
printf( "Memory size occupied by status2 : %d\n", sizeof(status2));
return 0;
}
当上面的代码被编译和执行时,它会产生下列结果:
Memory size occupied by status1 : 8
Memory size occupied by status2 : 4
位域的特点和使用方法如下:
- 定义位域时,可以指定成员的位域宽度,即成员所占用的位数。
- 位域的宽度不能超过其数据类型的大小,因为位域必须适应所使用的整数类型。
- 位域的数据类型可以是 int、unsigned int、signed int 等整数类型,也可以是枚举类型。
- 位域可以单独使用,也可以与其他成员一起组成结构体。
- 位域的访问是通过点运算符(.)来实现的,与普通的结构体成员访问方式相同。
位域声明
有些信息在存储时,并不需要占用一个完整的字节,而只需占几个或一个二进制位。例如在存放一个开关量时,只有 0 和 1 两种状态,用 1 位二进位即可。为了节省存储空间,并使处理简便,C 语言又提供了一种数据结构,称为"位域"或"位段"。
所谓"位域"是把一个字节中的二进位划分为几个不同的区域,并说明每个区域的位数。每个域有一个域名,允许在程序中按域名进行操作。这样就可以把几个不同的对象用一个字节的二进制位域来表示。
典型的实例:
- 用 1 位二进位存放一个开关量时,只有 0 和 1 两种状态。
- 读取外部文件格式——可以读取非标准的文件格式。例如:9 位的整数。
位域定义与结构定义相仿,其形式为:
struct 位域结构名
{
位域列表
};
其中位域列表的形式为:
type [member_name] : width ;
下面是有关位域中变量元素的描述:
| 元素 | 描述 |
|---|---|
| type | 只能为 int(整型),unsigned int(无符号整型),signed int(有符号整型) 三种类型,决定了如何解释位域的值。 |
| member_name | 位域的名称。 |
| width | 位域中位的数量。宽度必须小于或等于指定类型的位宽度。 |
带有预定义宽度的变量被称为位域。位域可以存储多于 1 位的数,例如,需要一个变量来存储从 0 到 7 的值,您可以定义一个宽度为 3 位的位域,如下:
struct
{
unsigned int age : 3;
} Age;
上面的结构定义指示 C 编译器,age 变量将只使用 3 位来存储这个值,如果您试图使用超过 3 位,则无法完成。
struct bs{
int a:8;
int b:2;
int c:6;
}data;
以上代码定义了一个名为 struct bs 的结构体,data 为 bs 的结构体变量,共占四个字节:
对于位域来说,它们的宽度不能超过其数据类型的大小,在这种情况下,int 类型的大小通常是 4 个字节(32位)。
相邻位域字段的类型相同,且其位宽之和小于类型的 sizeof大小,则后面的字段将紧邻前一个字段存储,直到不能容纳为止。
让我们再来看一个实例:
struct packed_struct {
unsigned int f1:1;
unsigned int f2:1;
unsigned int f3:1;
unsigned int f4:1;
unsigned int type:4;
unsigned int my_int:9;
} pack;
以上代码定义了一个名为 packed_struct 的结构体,其中包含了六个成员变量,pack 为 packed_struct 的结构体变量。
在这里,packed_struct 包含了 6 个成员:四个 1 位的标识符 f1…f4、一个 4 位的 type 和一个 9 位的 my_int。
实例 1
#include <stdio.h>
struct packed_struct {
unsigned int f1 : 1; // 1位的位域
unsigned int f2 : 1; // 1位的位域
unsigned int f3 : 1; // 1位的位域
unsigned int f4 : 1; // 1位的位域
unsigned int type : 4; // 4位的位域
unsigned int my_int : 9; // 9位的位域
};
int main() {
struct packed_struct pack;
pack.f1 = 1;
pack.f2 = 0;
pack.f3 = 1;
pack.f4 = 0;
pack.type = 7;
pack.my_int = 255;
printf("f1: %u\n", pack.f1);
printf("f2: %u\n", pack.f2);
printf("f3: %u\n", pack.f3);
printf("f4: %u\n", pack.f4);
printf("type: %u\n", pack.type);
printf("my_int: %u\n", pack.my_int);
return 0;
}
以上实例定义了一个名为 packed_struct 的结构体,其中包含了多个位域成员。
在 main 函数中,创建了一个 packed_struct 类型的结构体变量 pack,并分别给每个位域成员赋值。
然后使用 printf 语句打印出每个位域成员的值。
输出结果为:
f1: 1
f2: 0
f3: 1
f4: 0
type: 7
my_int: 255
实例2
#include <stdio.h>
#include <string.h>
struct
{
unsigned int age : 3;
} Age;
int main( )
{
Age.age = 4;
printf( "Sizeof( Age ) : %d\n", sizeof(Age) );
printf( "Age.age : %d\n", Age.age );
Age.age = 7;
printf( "Age.age : %d\n", Age.age );
Age.age = 8; // 二进制表示为 1000 有四位,超出
printf( "Age.age : %d\n", Age.age );
return 0;
}
当上面的代码被编译时,它会带有警告,当上面的代码被执行时,它会产生下列结果:
Sizeof( Age ) : 4
Age.age : 4
Age.age : 7
Age.age : 0
计算字节数:
#include <stdio.h>
struct example1 {
int a : 4;
int b : 5;
int c : 7;
};
int main() {
struct example1 ex1;
printf("Size of example1: %lu bytes\n", sizeof(ex1));
return 0;
}
以上实例中,example1 结构体包含三个位域成员 a,b 和 c,它们分别占用 4 位、5 位和 7 位。
通过 sizeof 运算符计算出 example1 结构体的字节数,并输出结果:
Size of example1: 4 bytes
注意点
-
一个位域存储在同一个字节中,如一个字节所剩空间不够存放另一位域时,则会从下一单元起存放该位域。也可以有意使某位域从下一单元开始。例如:
struct bs { unsigned a:4; unsigned :4; /* 空域 */ unsigned b:4; /* 从下一单元开始存放 */ unsigned c:4; };在这个位域定义中,a 占第一字节的 4 位,后 4 位填 0 表示不使用,b 从第二字节开始,占用 4 位,c 占用 4 位。
-
位域的宽度不能超过它所依附的数据类型的长度,成员变量都是有类型的,这个类型限制了成员变量的最大长度,
:后面的数字不能超过这个长度。 -
位域可以是无名位域,这时它只用来作填充或调整位置。无名的位域是不能使用的。例如:
struct k { int a:1; int :2; /* 该 2 位不能使用 */ int b:3; int c:2; };
从以上分析可以看出,位域在本质上就是一种结构类型,不过其成员是按二进位分配的。
位域的使用和结构成员的使用相同,其一般形式为:
位域变量名.位域名
位域变量名->位域名
位域允许用各种格式输出。
#include <stdio.h>
int main(){
struct bs{
unsigned a:1;
unsigned b:3;
unsigned c:4;
} bit,*pbit;
bit.a=1; /* 给位域赋值(应注意赋值不能超过该位域的允许范围) */
bit.b=7; /* 给位域赋值(应注意赋值不能超过该位域的允许范围) */
bit.c=15; /* 给位域赋值(应注意赋值不能超过该位域的允许范围) */
printf("%d,%d,%d\n",bit.a,bit.b,bit.c); /* 以整型量格式输出三个域的内容 */
pbit=&bit; /* 把位域变量 bit 的地址送给指针变量 pbit */
pbit->a=0; /* 用指针方式给位域 a 重新赋值,赋为 0 */
pbit->b&=3; /* 使用了复合的位运算符 "&=",相当于:pbit->b=pbit->b&3,位域 b 中原有值为 7,与 3 作按位与运算的结果为 3(111&011=011,十进制值为 3) */
pbit->c|=1; /* 使用了复合位运算符"|=",相当于:pbit->c=pbit->c|1,其结果为 15 */
printf("%d,%d,%d\n",pbit->a,pbit->b,pbit->c); /* 用指针方式输出了这三个域的值 */
}
上例程序中定义了位域结构 bs,三个位域为 a、b、c。说明了 bs 类型的变量 bit 和指向 bs 类型的指针变量 pbit。这表示位域也是可以使用指针的。
C typedef
C 语言提供了 typedef 关键字,可以使用它来为类型取一个新的名字。下面的实例为单字节数字定义了一个术语 BYTE:
typedef unsigned char BYTE;
在这个类型定义之后,标识符 BYTE 可作为类型 unsigned char 的缩写,例如:
BYTE b1, b2;
按照惯例,定义时会大写字母,以便提醒用户类型名称是一个象征性的缩写,但也可以使用小写字母,如下:
typedef unsigned char byte;
也可以使用 typedef 来为用户自定义的数据类型取一个新的名字。例如,可以对结构体使用 typedef 来定义一个新的数据类型名字,然后使用这个新的数据类型来直接定义结构变量,如下:
#include <stdio.h>
#include <string.h>
typedef struct Books
{
char title[50];
char author[50];
char subject[100];
int book_id;
} Book;
int main( )
{
Book book;
strcpy( book.title, "C 教程");
strcpy( book.author, "Runoob");
strcpy( book.subject, "编程语言");
book.book_id = 12345;
printf( "书标题 : %s\n", book.title);
printf( "书作者 : %s\n", book.author);
printf( "书类目 : %s\n", book.subject);
printf( "书 ID : %d\n", book.book_id);
return 0;
}
typedef vs #define
#define 是 C 指令,用于为各种数据类型定义别名,与 typedef 类似,但是它们有以下几点不同:
- typedef 仅限于为类型定义符号名称,#define 不仅可以为类型定义别名,也能为数值定义别名,比如您可以定义 1 为 ONE。
- typedef 是由编译器执行解释的,#define 语句是由预编译器进行处理的。
下面是 #define 的最简单的用法:
#include <stdio.h>
#define TRUE 1
#define FALSE 0
int main( )
{
printf( "TRUE 的值: %d\n", TRUE);
printf( "FALSE 的值: %d\n", FALSE);
return 0;
}
当上面的代码被编译和执行时,它会产生下列结果:
TRUE 的值: 1
FALSE 的值: 0
主要好处
typedef为类型起别名的好处,主要有下面几点。
-
更好的代码可读性。
typedef char* STRING; STRING name;上面示例为字符指针起别名为STRING,以后使用STRING声明变量时,就可以轻易辨别该变量是字符串。
-
为 struct、union、enum 等命令定义的复杂数据结构创建别名,从而便于引用。
struct treenode { // ... }; typedef struct treenode* Tree;上面示例中,Tree为struct treenode*的别名。
typedef 也可以与 struct 定义数据类型的命令写在一起。
typedef struct animal { char* name; int leg_count, speed; } animal;上面示例中,自定义数据类型时,同时使用typedef命令,为struct animal起了一个别名animal。
这种情况下,C 语言允许省略 struct 命令后面的类型名。
typedef struct { char *name; int leg_count, speed; } animal;上面示例相当于为一个匿名的数据类型起了别名animal。
-
typedef 方便以后为变量改类型。
typedef float app_float; app_float f1, f2, f3;上面示例中,变量f1、f2、f3的类型都是float。如果以后需要为它们改类型,只需要修改typedef语句即可。
typedef long double app_float;上面命令将变量f1、f2、f3的类型都改为long double。
-
可移植性
某一个值在不同计算机上的类型,可能是不一样的。
int i = 100000;上面代码在32位整数的计算机没有问题,但是在16位整数的计算机就会出错。
C 语言的解决办法,就是提供了类型别名,在不同计算机上会解释成不同类型,比如int32_t。
int32_t i = 100000;上面示例将变量i声明成int32_t类型,保证它在不同计算机上都是32位宽度,移植代码时就不会出错。
这一类的类型别名都是用 typedef 定义的。下面是类似的例子。
typedef long int ptrdiff_t; typedef unsigned long int size_t; typedef int wchar_t;这些整数类型别名都放在头文件stdint.h,不同架构的计算机只需修改这个头文件即可,而无需修改代码。
因此,typedef有助于提高代码的可移植性,使其能适配不同架构的计算机。
-
简化类型声明
C 语言有些类型声明相当复杂,比如下面这个。
char (*(*x(void))[5])(void);typedef 可以简化复杂的类型声明,使其更容易理解。首先,最外面一层起一个类型别名。
typedef char (*Func)(void); Func (*x(void))[5];这个看起来还是有点复杂,就为里面一层也定义一个别名。
typedef char (*Func)(void); typedef Func Arr[5]; Arr* x(void);上面代码就比较容易解读了。
- x是一个函数,返回一个指向 Arr 类型的指针。
- Arr是一个数组,有5个成员,每个成员是Func类型。
- Func是一个函数指针,指向一个无参数、返回字符值的函数。
C 输入 & 输出
严格地说,输入输出函数并不是直接与外部设备通信,而是通过缓存(buffer)进行间接通信。这个小节介绍缓存是什么。
普通文件一般都保存在磁盘上面,跟 CPU 相比,磁盘读取或写入数据是一个很慢的操作。所以,程序直接读写磁盘是不可行的,可能每执行一行命令,都必须等半天。C 语言的解决方案,就是只要打开一个文件,就在内存里面为这个文件设置一个缓存区。
程序向文件写入数据时,程序先把数据放入缓存,等到缓存满了,再把里面的数据会一次性写入磁盘文件。这时,缓存区就空了,程序再把新的数据放入缓存,重复整个过程。
程序从文件读取数据时,文件先把一部分数据放到缓存里面,然后程序从缓存获取数据,等到缓存空了,磁盘文件再把新的数据放入缓存,重复整个过程。
内存的读写速度比磁盘快得多,缓存的设计减少了读写磁盘的次数,大大提高了程序的执行效率。另外,一次性移动大块数据,要比多次移动小块数据快得多。
这种读写模式,对于程序来说,就有点像水流(stream),不是一次性读取或写入所有数据,而是一个持续不断的过程。先操作一部分数据,等到缓存吞吐完这部分数据,再操作下一部分数据。这个过程就叫做字节流操作。
由于缓存读完就空了,所以字节流读取都是只能读一次,第二次就读不到了。这跟读取文件很不一样。
C 语言的输入输出函数,凡是涉及读写文件,都是属于字节流操作。输入函数从文件获取数据,操作的是输入流;输出函数向文件写入数据,操作的是输出流。
C 语言提供了一系列内置的函数来读取给定的输入,并根据需要填充到程序中,同时,C 语言也提供了一系列内置的函数来输出数据到计算机屏幕上和保存数据到文本文件或二进制文件中。
标准文件
C 语言把所有的设备都当作文件。所以设备(比如显示器)被处理的方式与文件相同。以下三个文件会在程序执行时自动打开,以便访问键盘和屏幕。
| 标准文件 | 文件指针 | 设备 |
|---|---|---|
| 标准输入 | stdin | 键盘 |
| 标准输出 | stdout | 屏幕 |
| 标准错误 | stderr | 您的屏幕 |
C 语言中的 I/O (输入/输出) 通常使用 printf() 和 scanf() 两个函数。
scanf() 函数用于从标准输入(键盘)读取并格式化, printf() 函数发送格式化输出到标准输出(屏幕)。
#include <stdio.h> // 执行 printf() 函数需要该库
int main()
{
printf("hello world"); //显示引号中的内容
return 0;
}
printf 函数是C语言中用于格式化输出的函数,它支持一系列的格式化标志,用于指定输出的格式。以下是一些常见的 % 格式化方式:
-
整数类型:
%d:以十进制形式打印整数。%i:同%d,可以指定输出的整数形式(十进制、八进制、十六进制)。%o:以八进制形式打印整数。%x:以十六进制形式打印整数,使用小写字母。%X:以十六进制形式打印整数,使用大写字母。%u:以十进制形式打印无符号整数。
-
浮点数类型:
%f:以小数形式打印浮点数。%e:以指数形式打印浮点数,使用小写字母。%E:以指数形式打印浮点数,使用大写字母。%g:以%f或%e中较短的形式打印浮点数,根据数值不同而变化。%G:以%f或%E中较短的形式打印浮点数,根据数值不同而变化。%a:以十六进制浮点数形式打印浮点数(C99及以上)。
-
字符类型:
%c:以字符形式打印。%s:以字符串形式打印。
-
指针类型:
%p:以地址形式打印指针。
-
整数宽度和精度:
%Nd:打印整数时占用至少 N 个字符宽度,不足时使用空格填充。%.Nd:打印整数时至少使用 N 个字符宽度,不足时使用零填充。
-
其他标志:
%+d:总是在整数前面加上正负号。%0Nd:使用零填充整数,宽度为 N。%[]:在方括号中指定一组匹配的字符(比如%[0-9]),遇到不在集合之中的字符,匹配将会停止。
要特别说一下占位符%s,它其实不能简单地等同于字符串。它的规则是,从当前第一个非空白字符开始读起,直到遇到空白字符(即空格、换行符、制表符等)为止。因为%s不会包含空白字符,所以无法用来读取多个单词,除非多个%s一起使用。这也意味着,scanf("%s")不适合读取可能包含空格的字符串,比如书名或歌曲名。另外,scanf()遇到%s占位符,会在字符串变量末尾存储一个空字符\0。
getchar() & putchar() 函数
int getchar(void) 函数从屏幕读取下一个可用的字符,并把它返回为一个整数。这个函数在同一个时间内只会读取一个单一的字符。可以在循环内使用这个方法,以便从屏幕上读取多个字符。
getchar()函数返回用户从键盘输入的一个字符,使用时不带有任何参数。程序运行到这个命令就会暂停,等待用户从键盘输入,等同于使用scanf()方法读取一个字符。它的原型定义在头文件stdio.h。
char ch;
ch = getchar();
// 等同于
scanf("%c", &ch);
getchar()不会忽略起首的空白字符,总是返回当前读取的第一个字符,无论是否为空格。如果读取失败,返回常量 EOF,由于 EOF 通常是-1,所以返回值的类型要设为 int,而不是 char。
由于getchar()返回读取的字符,所以可以用在循环条件之中。
while (getchar() != '\n')
;
上面示例中,只有读到的字符等于换行符(\n),才会退出循环,常用来跳过某行。while循环的循环体没有任何语句,表示对该行不执行任何操作。
下面的例子是计算某一行的字符长度。
int len = 0;
while(getchar() != '\n')
len++;
上面示例中,getchar()每读取一个字符,长度变量len就会加1,直到读取到换行符为止,这时len就是该行的字符长度。
下面的例子是跳过空格字符。
while ((ch = getchar()) == ' ')
;
上面示例中,结束循环后,变量ch等于第一个非空格字符。
int putchar(int c) 函数把字符输出到屏幕上,并返回相同的字符。这个函数在同一个时间内只会输出一个单一的字符。可以在循环内使用这个方法,以便在屏幕上输出多个字符。
putchar()函数将它的参数字符输出到屏幕,等同于使用printf()输出一个字符。它的原型定义在头文件stdio.h。
putchar(ch);
// 等同于
printf("%c", ch);
操作成功时,putchar()返回输出的字符,否则返回常量 EOF。
由于getchar()和putchar()这两个函数的用法,要比scanf()和printf()更简单,而且通常是用宏来实现,所以要比scanf()和printf()更快。如果操作单个字符,建议优先使用这两个函数。
#include <stdio.h>
int main( )
{
int c;
printf( "Enter a value :");
c = getchar( );
printf( "\nYou entered: ");
putchar( c );
printf( "\n");
return 0;
}
当上面的代码被编译和执行时,它会等待您输入一些文本,当您输入一个文本并按下回车键时,程序会继续并只会读取一个单一的字符,显示如下:
$./a.out
Enter a value :runoob
You entered: r
gets() & puts() 函数
char *gets(char *s) 函数从 stdin 读取一行到 s 所指向的缓冲区,直到一个终止符或 EOF。
int puts(const char *s) 函数把字符串 s 和一个尾随的换行符写入到 stdout。
#include <stdio.h>
int main( )
{
char str[100];
printf( "Enter a value :");
gets( str );
printf( "\nYou entered: ");
puts( str );
return 0;
}
当上面的代码被编译和执行时,它会等待您输入一些文本,当您输入一个文本并按下回车键时,程序会继续并读取一整行直到该行结束,显示如下:
$./a.out
Enter a value :runoob
You entered: runoob
scanf() 和 printf() 函数,sscanf()
int scanf(const char *format, …) 函数从标准输入流 stdin 读取输入,并根据提供的 format 来浏览输入。
int printf(const char *format, …) 函数把输出写入到标准输出流 stdout ,并根据提供的格式产生输出。
#include <stdio.h>
int main( ) {
char str[100];
int i;
printf( "Enter a value :");
scanf("%s %d", str, &i);
printf( "\nYou entered: %s %d ", str, i);
printf("\n");
return 0;
}
当上面的代码被编译和执行时,它会等待您输入一些文本,当您输入一个文本并按下回车键时,程序会继续并读取输入,显示如下:
$./a.out
Enter a value :runoob 123
You entered: runoob 123
在这里,应当指出的是,scanf() 期待输入的格式与您给出的 %s 和 %d 相同,这意味着您必须提供有效的输入,比如 “string integer”,如果您提供的是 “string string” 或 “integer integer”,它会被认为是错误的输入。另外,在读取字符串时,只要遇到一个空格,scanf() 就会停止读取,所以 “this is test” 对 scanf() 来说是三个字符串。
有时,用户的输入可能不符合预定的格式。
scanf("%d-%d-%d", &year, &month, &day);
上面示例中,如果用户输入2020-01-01,就会正确解读出年、月、日。问题是用户可能输入其他格式,比如2020/01/01,这种情况下,scanf()解析数据就会失败。
为了避免这种情况,scanf()提供了一个赋值忽略符(assignment suppression character)*。只要把*加在任何占位符的百分号后面,该占位符就不会返回值,解析后将被丢弃。
scanf("%d%*c%d%*c%d", &year, &month, &day);
上面示例中,%*c就是在占位符的百分号后面,加入了赋值忽略符*,表示这个占位符没有对应的变量,解读后不必返回。
sscanf()函数与scanf()很类似,不同之处是sscanf()从字符串里面,而不是从用户输入获取数据。它的原型定义在头文件stdio.h里面。
int sscanf(const char* s, const char* format, ...);
sscanf()的第一个参数是一个字符串指针,用来从其中获取数据。其他参数都与scanf()相同。
sscanf()主要用来处理其他输入函数读入的字符串,从其中提取数据。
fgets(str, sizeof(str), stdin);
sscanf(str, "%d%d", &i, &j);
上面示例中,fgets()先从标准输入获取了一行数据,存入字符数组str。然后,sscanf()再从字符串str里面提取两个整数,放入变量i和j。
sscanf()的一个好处是,它的数据来源不是流数据,所以可以反复使用,不像scanf()的数据来源是流数据,只能读取一次。
sscanf()的返回值是成功赋值的变量的数量,如果提取失败,返回常量 EOF。
C 文件读写
打开文件
可以使用 fopen( ) 函数来创建一个新的文件或者打开一个已有的文件,这个调用会初始化类型 FILE 的一个对象,类型 FILE 包含了所有用来控制流的必要的信息。下面是这个函数调用的原型:
FILE *fopen( const char *filename, const char *mode );
在这里,filename 是字符串,用来命名文件,访问模式 mode 的值可以是下列值中的一个:
| 模式 | 描述 |
|---|---|
| r | 打开一个已有的文本文件,允许读取文件。 |
| w | 打开一个文本文件,允许写入文件。如果文件不存在,则会创建一个新文件。在这里,您的程序会从文件的开头写入内容。如果文件存在,则该会被截断为零长度,重新写入。 |
| a | 打开一个文本文件,以追加模式写入文件。如果文件不存在,则会创建一个新文件。在这里,您的程序会在已有的文件内容中追加内容。 |
| r+ | 打开一个文本文件,允许读写文件。 |
| w+ | 打开一个文本文件,允许读写文件。如果文件已存在,则文件会被截断为零长度,如果文件不存在,则会创建一个新文件。 |
| a+ | 打开一个文本文件,允许读写文件。如果文件不存在,则会创建一个新文件。读取会从文件的开头开始,写入则只能是追加模式。 |
如果处理的是二进制文件,则需使用下面的访问模式来取代上面的访问模式:
"rb", "wb", "ab", "rb+", "r+b", "wb+", "w+b", "ab+", "a+b"
关闭文件
为了关闭文件,请使用 fclose( ) 函数。函数的原型如下:
int fclose( FILE *fp );
如果成功关闭文件,fclose( ) 函数返回零,如果关闭文件时发生错误,函数返回 EOF。这个函数实际上,会清空缓冲区中的数据,关闭文件,并释放用于该文件的所有内存。EOF 是一个定义在头文件 stdio.h 中的常量。
C 标准库提供了各种函数来按字符或者以固定长度字符串的形式读写文件。
写入文件
下面是把字符写入到流中的最简单的函数:
int fputc( int c, FILE *fp );
函数 fputc() 把参数 c 的字符值写入到 fp 所指向的输出流中。如果写入成功,它会返回写入的字符,如果发生错误,则会返回 EOF。您可以使用下面的函数来把一个以 null 结尾的字符串写入到流中:
int fputs( const char *s, FILE *fp );
函数 fputs() 把字符串 s 写入到 fp 所指向的输出流中。如果写入成功,它会返回一个非负值,如果发生错误,则会返回 EOF。也可以使用 int fprintf(FILE *fp,const char *format, …) 函数把一个字符串写入到文件中。尝试下面的实例:
#include <stdio.h>
int main()
{
FILE *fp = NULL;
fp = fopen("/tmp/test.txt", "w+");
fprintf(fp, "This is testing for fprintf...\n");
fputs("This is testing for fputs...\n", fp);
fclose(fp);
}
当上面的代码被编译和执行时,它会在 /tmp 目录中创建一个新的文件 test.txt,并使用两个不同的函数写入两行。接下来让我们来读取这个文件。
读取文件
下面是从文件读取单个字符的最简单的函数:
int fgetc( FILE * fp );
fgetc() 函数从 fp 所指向的输入文件中读取一个字符。返回值是读取的字符,如果发生错误则返回 EOF。下面的函数允许您从流中读取一个字符串:
char *fgets( char *buf, int n, FILE *fp );
函数 fgets() 从 fp 所指向的输入流中读取 n - 1 个字符。它会把读取的字符串复制到缓冲区 buf,并在最后追加一个 null 字符来终止字符串。
如果这个函数在读取最后一个字符之前就遇到一个换行符 ‘\n’ 或文件的末尾 EOF,则只会返回读取到的字符,包括换行符。您也可以使用 int fscanf(FILE *fp, const char *format, …) 函数来从文件中读取字符串,但是在遇到第一个空格和换行符时,它会停止读取。
#include <stdio.h>
int main()
{
FILE *fp = NULL;
char buff[255];
fp = fopen("/tmp/test.txt", "r");
fscanf(fp, "%s", buff);
printf("1: %s\n", buff );
fgets(buff, 255, (FILE*)fp);
printf("2: %s\n", buff );
fgets(buff, 255, (FILE*)fp);
printf("3: %s\n", buff );
fclose(fp);
}
当上面的代码被编译和执行时,它会读取上一部分创建的文件,产生下列结果:
1: This
2: is testing for fprintf...
3: This is testing for fputs...
首先,fscanf() 方法只读取了 This,因为它在后边遇到了一个空格。其次,调用 fgets() 读取剩余的部分,直到行尾。最后,调用 fgets() 完整地读取第二行。
二进制 I/O 函数
下面两个函数用于二进制输入和输出:
size_t fread(void *ptr, size_t size_of_elements,
size_t number_of_elements, FILE *a_file);
size_t fwrite(const void *ptr, size_t size_of_elements,
size_t number_of_elements, FILE *a_file);
这两个函数都是用于存储块的读写 - 通常是数组或结构体。
C 预处理器
C 预处理器不是编译器的组成部分,但是它是编译过程中一个单独的步骤。简言之,C 预处理器只不过是一个文本替换工具而已,它们会指示编译器在实际编译之前完成所需的预处理。
所有的预处理器命令都是以井号(#)开头。它必须是第一个非空字符,为了增强可读性,预处理器指令应从第一列开始。下面列出了所有重要的预处理器指令:
| 指令 | 描述 |
|---|---|
| #define | 定义宏 |
| #include | 包含一个源代码文件 |
| #undef | 取消已定义的宏 |
| #ifdef | 如果宏已经定义,则返回真 |
| #ifndef | 如果宏没有定义,则返回真 |
| #if | 如果给定条件为真,则编译下面代码 |
| #else | #if 的替代方案 |
| #elif | 如果前面的 #if 给定条件不为真,当前条件为真,则编译下面代码 |
| #endif | 结束一个 #if……#else 条件编译块 |
| #error | 当遇到标准错误时,输出错误消息 |
| #pragma | 使用标准化方法,向编译器发布特殊的命令到编译器中 |
预处理器实例
#define MAX_ARRAY_LENGTH 20
这个指令告诉 预处理器把所有的 MAX_ARRAY_LENGTH 定义为 20。使用 #define 定义常量来增强可读性。
#include <stdio.h>
#include "myheader.h"
这些指令告诉 预处理器 从系统库中获取 stdio.h,并添加文本到当前的源文件中。下一行告诉 预处理器 从本地目录中获取 myheader.h,并添加内容到当前的源文件中。
#undef FILE_SIZE
#define FILE_SIZE 42
这个指令告诉 预处理器 取消已定义的 FILE_SIZE,并定义它为 42。
#ifndef MESSAGE
#define MESSAGE "You wish!"
#endif
这个指令告诉 预处理器 只有当 MESSAGE 未定义时,才定义 MESSAGE。
#ifdef DEBUG
/* Your debugging statements here */
#endif
这个指令告诉 预处理器 如果定义了 DEBUG,则执行处理语句。在编译时,如果您向 gcc 编译器传递了 -DDEBUG 开关量,这个指令就非常有用。它定义了 DEBUG,您可以在编译期间随时开启或关闭调试。
预定义宏
ANSI C 定义了许多宏。在编程中可以使用这些宏,但是不能直接修改这些预定义的宏。
| 宏 | 描述 |
|---|---|
| __DATE__ | 当前日期,一个以 "MMM DD YYYY" 格式表示的字符常量。 |
| __TIME__ | 当前时间,一个以 "HH:MM:SS" 格式表示的字符常量。 |
| __FILE__ | 这会包含当前文件名,一个字符串常量。 |
| __LINE__ | 这会包含当前行号,一个十进制常量。 |
| __STDC__ | 当编译器以 ANSI 标准编译时,则定义为 1。 |
#include <stdio.h>
main()
{
printf("File :%s\n", __FILE__ );
printf("Date :%s\n", __DATE__ );
printf("Time :%s\n", __TIME__ );
printf("Line :%d\n", __LINE__ );
printf("ANSI :%d\n", __STDC__ );
}
当上面的代码(在文件 test.c 中)被编译和执行时,它会产生下列结果:
File :test.c
Date :Jun 2 2012
Time :03:36:24
Line :8
ANSI :1
#line
#line指令用于覆盖预定义宏__LINE__,将其改为自定义的行号。后面的行将从__LINE__的新值开始计数。
// 将下一行的行号重置为 300
#line 300
上面示例中,紧跟在#line 300后面一行的行号,将被改成300,其后的行会在300的基础上递增编号。
#line还可以改掉预定义宏__FILE__,将其改为自定义的文件名。
#line 300 "newfilename"
上面示例中,下一行的行号重置为300,文件名重置为newfilename。
#error
#error指令用于让预处理器抛出一个错误,终止编译。
#if __STDC_VERSION__ != 201112L
#error Not C11
#endif
上面示例指定,如果编译器不使用 C11 标准,就中止编译。GCC 编译器会像下面这样报错。
$ gcc -std=c99 newish.c
newish.c:14:2: error: #error Not C11
上面示例中,GCC 使用 C99 标准编译,就报错了。
#if INT_MAX < 100000
#error int type is too small
#endif
上面示例中,编译器一旦发现INT类型的最大值小于100,000,就会停止编译。
#error指令也可以用在#if…#elif…#else的部分。
#if defined WIN32
// ...
#elif defined MAC_OS
// ...
#elif defined LINUX
// ...
#else
#error NOT support the operating system
#endif
#pragma
#pragma指令用来修改编译器属性。
// 使用 C99 标准
#pragma c9x on
上面示例让编译器以 C99 标准进行编译。
预处理器运算符
宏延续运算符(\)
一个宏通常写在一个单行上。但是如果宏太长,一个单行容纳不下,则使用宏延续运算符(\)。例如:
#define message_for(a, b) \
printf(#a " and " #b ": We love you!\n")
字符串常量化运算符(#)
在宏定义中,当需要把一个宏的参数转换为字符串常量时,则使用字符串常量化运算符(#)。在宏中使用的该运算符有一个特定的参数或参数列表。例如:
#include <stdio.h>
#define message_for(a, b) \
printf(#a " and " #b ": We love you!\n")
int main(void)
{
message_for(Carole, Debra);
return 0;
}
当上面的代码被编译和执行时,它会产生下列结果:
Carole and Debra: We love you!
这种写法与:
#define message_for(a, b) \
printf("%s and %s: We love you!\n",a,b)
int main(void){
message_for("abc","def");
}
效果一样
标记粘贴运算符(##)
宏定义内的标记粘贴运算符(##)会合并两个参数。它允许在宏定义中两个独立的标记被合并为一个标记。例如:
#include <stdio.h>
#define tokenpaster(n) printf ("token" #n " = %d", token##n)
int main(void)
{
int token34 = 40;
tokenpaster(34);
return 0;
}
当上面的代码被编译和执行时,它会产生下列结果:
token34 = 40
这个实例会从编译器产生下列的实际输出:
printf ("token34 = %d", token34);
这个实例演示了 token##n 会连接到 token34 中,这里使用了字符串常量化运算符(#)和标记粘贴运算符(##)。
defined() 运算符
预处理器 defined 运算符是用在常量表达式中的,用来确定一个标识符是否已经使用 #define 定义过。如果指定的标识符已定义,则值为真(非零)。如果指定的标识符未定义,则值为假(零)。下面的实例演示了 defined() 运算符的用法:
#include <stdio.h>
#if !defined (MESSAGE)
#define MESSAGE "You wish!"
#endif
int main(void)
{
printf("Here is the message: %s\n", MESSAGE);
return 0;
}
当上面的代码被编译和执行时,它会产生下列结果:
Here is the message: You wish!
参数化的宏
可以使用参数化的宏来模拟函数。例如,下面的代码是计算一个数的平方:
int square(int x) {
return x * x;
}
可以使用宏重写上面的代码,如下:
#define square(x) ((x) * (x))
在使用带有参数的宏之前,必须使用 #define 指令定义。参数列表是括在圆括号内,且必须紧跟在宏名称的后边。宏名称和左圆括号之间不允许有空格。例如:
#include <stdio.h>
#define MAX(x,y) ((x) > (y) ? (x) : (y))
int main(void)
{
printf("Max between 20 and 10 is %d\n", MAX(10, 20));
return 0;
}
当上面的代码被编译和执行时,它会产生下列结果:
Max between 20 and 10 is 20
C 头文件
头文件是扩展名为 .h 的文件,包含了 C 函数声明和宏定义,被多个源文件中引用共享。有两种类型的头文件:程序员编写的头文件和编译器自带的头文件。
在程序中要使用头文件,需要使用 C 预处理指令 #include 来引用它。
引用头文件相当于复制头文件的内容,但是我们不会直接在源文件中复制头文件的内容,因为这么做很容易出错,特别在程序是由多个源文件组成的时候。
A simple practice in C 或 C++ 程序中,建议把所有的常量、宏、系统全局变量和函数原型写在头文件中,在需要的时候随时引用这些头文件。
引用头文件的语法
使用预处理指令 #include 可以引用用户和系统头文件。它的形式有以下两种:
#include <file>
这种形式用于引用系统头文件。它在系统目录的标准列表中搜索名为 file 的文件。在编译源代码时,您可以通过 -I 选项把目录前置在该列表前。
#include "file"
这种形式用于引用用户头文件。它在包含当前文件的目录中搜索名为 file 的文件。在编译源代码时,您可以通过 -I 选项把目录前置在该列表前。
引用头文件的操作
#include 指令会指示 C 预处理器浏览指定的文件作为输入。预处理器的输出包含了已经生成的输出,被引用文件生成的输出以及 #include 指令之后的文本输出。例如,有一个头文件 header.h,如下:
char *test (void);
和一个使用了头文件的主程序 program.c,如下:
int x;
#include "header.h"
int main (void)
{
puts (test ());
}
编译器会看到如下的代码信息:
int x;
char *test (void);
int main (void)
{
puts (test ());
}
只引用一次头文件
如果一个头文件被引用两次,编译器会处理两次头文件的内容,这将产生错误。为了防止这种情况,标准的做法是把文件的整个内容放在条件编译语句中,如下:
#ifndef HEADER_FILE
#define HEADER_FILE
the entire header file file
#endif
这种结构就是通常所说的包装器 #ifndef。当再次引用头文件时,条件为假,因为 HEADER_FILE 已定义。此时,预处理器会跳过文件的整个内容,编译器会忽略它。
有条件引用
有时需要从多个不同的头文件中选择一个引用到程序中。例如,需要指定在不同的操作系统上使用的配置参数。可以通过一系列条件来实现这点,如下:
#if SYSTEM_1
# include "system_1.h"
#elif SYSTEM_2
# include "system_2.h"
#elif SYSTEM_3
...
#endif
但是如果头文件比较多的时候,这么做是很不妥当的,预处理器使用宏来定义头文件的名称。这就是所谓的有条件引用。它不是用头文件的名称作为 #include 的直接参数,只需要使用宏名称代替即可:
#define SYSTEM_H "system_1.h"
...
#include SYSTEM_H
SYSTEM_H 会扩展,预处理器会查找 system_1.h,就像 #include 最初编写的那样。SYSTEM_H 可通过 -D 选项被您的 Makefile 定义。
在有多个 .h 文件和多个 .c 文件的时候,往往我们会用一个 global.h 的头文件来包括所有的 .h 文件,然后在除 global.h 文件外的头文件中 包含 global.h 就可以实现所有头文件的包含,同时不会乱。方便在各个文件里面调用其他文件的函数或者变量。
#ifndef _GLOBAL_H
#define _GLOBAL_H
#include <fstream>
#include <iostream>
#include <math.h>
#include <Config.h>
C 强制类型转换
强制类型转换是把变量从一种类型转换为另一种数据类型。例如,如果想存储一个 long 类型的值到一个简单的整型中,需要把 long 类型强制转换为 int 类型。您可以使用强制类型转换运算符来把值显式地从一种类型转换为另一种类型,如下所示:
(type_name) expression
#include <stdio.h>
int main()
{
int sum = 17, count = 5;
double mean;
mean = (double) sum / count;
printf("Value of mean : %f\n", mean );
}
当上面的代码被编译和执行时,它会产生下列结果:
Value of mean : 3.400000
这里要注意的是强制类型转换运算符的优先级大于除法,因此 sum 的值首先被转换为 double 型,然后除以 count,得到一个类型为 double 的值。
类型转换可以是隐式的,由编译器自动执行,也可以是显式的,通过使用强制类型转换运算符来指定。在编程时,有需要类型转换的时候都用上强制类型转换运算符,是一种良好的编程习惯。
值得一提的是,Go完美的践行了这点,他不允许隐式转换,想要计算必须提前转换为对应类型

整数提升
整数提升是指把小于 int 或 unsigned int 的整数类型转换为 int 或 unsigned int 的过程。
#include <stdio.h>
int main()
{
int i = 17;
char c = 'c'; /* ascii 值是 99 */
int sum;
sum = i + c;
printf("Value of sum : %d\n", sum );
}
当上面的代码被编译和执行时,它会产生下列结果:
Value of sum : 116
在这里,sum 的值为 116,因为编译器进行了整数提升,在执行实际加法运算时,把 ‘c’ 的值转换为对应的 ascii 值。
常用的算术转换
常用的算术转换是隐式地把值强制转换为相同的类型。编译器首先执行整数提升,如果操作数类型不同,则它们会被转换为下列层次中出现的最高层次的类型:
常用的算术转换不适用于赋值运算符、逻辑运算符 && 和 ||。
#include <stdio.h>
int main()
{
int i = 17;
char c = 'c'; /* ascii 值是 99 */
float sum;
sum = i + c;
printf("Value of sum : %f\n", sum );
}
当上面的代码被编译和执行时,它会产生下列结果:
Value of sum : 116.000000
在这里,c 首先被转换为整数,但是由于最后的值是 float 型的,所以会应用常用的算术转换,编译器会把 i 和 c 转换为浮点型,并把它们相加得到一个浮点数。
C 错误处理
C 语言不提供对错误处理的直接支持,但是作为一种系统编程语言,它以返回值的形式允许您访问底层数据。在发生错误时,大多数的 C 或 UNIX 函数调用返回 1 或 NULL,同时会设置一个错误代码 errno,该错误代码是全局变量,表示在函数调用期间发生了错误。您可以在 errno.h 头文件中找到各种各样的错误代码。
所以,C 程序员可以通过检查返回值,然后根据返回值决定采取哪种适当的动作。开发人员应该在程序初始化时,把 errno 设置为 0,这是一种良好的编程习惯。0 值表示程序中没有错误。
errno、perror() 和 strerror()
C 语言提供了 perror() 和 strerror() 函数来显示与 errno 相关的文本消息。
- perror() 函数显示您传给它的字符串,后跟一个冒号、一个空格和当前 errno 值的文本表示形式。
- strerror() 函数,返回一个指针,指针指向当前 errno 值的文本表示形式。
#include <stdio.h>
#include <errno.h>
#include <string.h>
extern int errno ;
int main ()
{
FILE * pf;
int errnum;
pf = fopen ("unexist.txt", "rb");
if (pf == NULL)
{
errnum = errno;
fprintf(stderr, "错误号: %d\n", errno);
perror("通过 perror 输出错误");
fprintf(stderr, "打开文件错误: %s\n", strerror( errnum ));
}
else
{
fclose (pf);
}
return 0;
}
当上面的代码被编译和执行时,它会产生下列结果:
错误号: 2
通过 perror 输出错误: No such file or directory
打开文件错误: No such file or directory
被零除的错误
在进行除法运算时,如果不检查除数是否为零,则会导致一个运行时错误。
为了避免这种情况发生,下面的代码在进行除法运算前会先检查除数是否为零:
#include <stdio.h>
#include <stdlib.h>
int main()
{
int dividend = 20;
int divisor = 0;
int quotient;
if( divisor == 0){
fprintf(stderr, "除数为 0 退出运行...\n");
exit(-1);
}
quotient = dividend / divisor;
fprintf(stderr, "quotient 变量的值为 : %d\n", quotient );
exit(0);
}
当上面的代码被编译和执行时,它会产生下列结果:
除数为 0 退出运行...
程序退出状态
通常情况下,程序成功执行完一个操作正常退出的时候会带有值 EXIT_SUCCESS。在这里,EXIT_SUCCESS 是宏,它被定义为 0。
如果程序中存在一种错误情况,当您退出程序时,会带有状态值 EXIT_FAILURE,被定义为 -1。所以,上面的程序可以写成:
#include <stdio.h>
#include <stdlib.h>
main()
{
int dividend = 20;
int divisor = 5;
int quotient;
if( divisor == 0){
fprintf(stderr, "除数为 0 退出运行...\n");
exit(EXIT_FAILURE);
}
quotient = dividend / divisor;
fprintf(stderr, "quotient 变量的值为: %d\n", quotient );
exit(EXIT_SUCCESS);
}
当上面的代码被编译和执行时,它会产生下列结果:
quotient 变量的值为 : 4
C 可变参数
C 语言允许定义一个函数,能根据具体的需求接受可变数量的参数。声明方式为:
int func_name(int arg1, ...);
其中,省略号 … 表示可变参数列表。
下面的实例演示了这种函数的使用:
int func(int, ... ) {
.
.
.
}
int main() {
func(2, 2, 3);
func(3, 2, 3, 4);
}
函数 func() 最后一个参数写成省略号,即三个点号(…),省略号之前的那个参数是 int,代表了要传递的可变参数的总数。为了使用这个功能,您需要使用 stdarg.h 头文件,该文件提供了实现可变参数功能的函数和宏。具体步骤如下:
- 定义一个函数,最后一个参数为省略号,省略号前面可以设置自定义参数。
- 在函数定义中创建一个 va_list 类型变量,该类型是在 stdarg.h 头文件中定义的。
- 使用 int 参数和 va_start() 宏来初始化 va_list 变量为一个参数列表。宏 va_start() 是在 stdarg.h 头文件中定义的。
- 使用 va_arg() 宏和 va_list 变量来访问参数列表中的每个项。
- 使用宏 va_end() 来清理赋予 va_list 变量的内存。
常用的宏有:
-
va_start(ap, last_arg):初始化可变参数列表。ap是一个va_list类型的变量,last_arg是最后一个固定参数的名称(也就是可变参数列表之前的参数)。该宏将ap指向可变参数列表中的第一个参数。 -
va_arg(ap, type):获取可变参数列表中的下一个参数。ap是一个va_list类型的变量,type是下一个参数的类型。该宏返回类型为type的值,并将ap指向下一个参数。 -
va_end(ap):结束可变参数列表的访问。ap是一个va_list类型的变量。该宏将ap置为NULL。
#include <stdio.h>
#include <stdarg.h>
double average(int num,...)
{
va_list valist;
double sum = 0.0;
int i;
/* 为 num 个参数初始化 valist */
va_start(valist, num);
/* 访问所有赋给 valist 的参数 */
for (i = 0; i < num; i++)
{
sum += va_arg(valist, int);
}
/* 清理为 valist 保留的内存 */
va_end(valist);
return sum/num;
}
int main()
{
printf("Average of 2, 3, 4, 5 = %f\n", average(4, 2,3,4,5));
printf("Average of 5, 10, 15 = %f\n", average(3, 5,10,15));
}
在上面的例子中,average() 函数接受一个整数 num 和任意数量的整数参数。函数内部使用 va_list 类型的变量 va_list 来访问可变参数列表。在循环中,每次使用 va_arg() 宏获取下一个整数参数,并输出。最后,在函数结束时使用 va_end() 宏结束可变参数列表的访问。
当上面的代码被编译和执行时,它会产生下列结果。应该指出的是,函数 average() 被调用两次,每次第一个参数都是表示被传的可变参数的总数。省略号被用来传递可变数量的参数。
Average of 2, 3, 4, 5 = 3.500000
Average of 5, 10, 15 = 10.000000
C 内存管理
C 语言为内存的分配和管理提供了几个函数。这些函数可以在 <stdlib.h> 头文件中找到。
在 C 语言中,内存是通过指针变量来管理的。
指针是一个变量,它存储了一个内存地址,这个内存地址可以指向任何数据类型的变量,包括整数、浮点数、字符和数组等。
C 语言提供了一些函数和运算符,使得程序员可以对内存进行操作,包括分配、释放、移动和复制等。
| 序号 | 函数和描述 |
|---|---|
| 1 | void *calloc(int num, int size); 在内存中动态地分配 num 个长度为 size 的连续空间,并将每一个字节都初始化为 0。所以它的结果是分配了 num*size 个字节长度的内存空间,并且每个字节的值都是 0。 |
| 2 | void free(void *address); 该函数释放 address 所指向的内存块,释放的是动态分配的内存空间。 |
| 3 | void *malloc(int num); 在堆区分配一块指定大小的内存空间,用来存放数据。这块内存空间在函数执行完成后不会被初始化,它们的值是未知的。 |
| 4 | void *realloc(void *address, int newsize); 该函数重新分配内存,把内存扩展到 newsize。 |
注意:void * 类型表示未确定类型的指针。C、C++ 规定 void * 类型可以通过类型转换强制转换为任何其它类型的指针。
动态分配内存
编程时,如果预先知道数组的大小,那么定义数组时就比较容易。
char name[100];
但是,预先不知道需要存储的文本长度,则需要定义一个指针,该指针指向未定义所需内存大小的字符,后续再根据需求来分配内存,如下所示:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main()
{
char name[100];
char *description;
strcpy(name, "Zara Ali");
/* 动态分配内存 */
description = (char *)malloc( 200 * sizeof(char) );
if( description == NULL )
{
fprintf(stderr, "Error - unable to allocate required memory\n");
}
else
{
strcpy( description, "Zara ali a DPS student in class 10th");
}
printf("Name = %s\n", name );
printf("Description: %s\n", description );
}
当上面的代码被编译和执行时,它会产生下列结果:
Name = Zara Ali
Description: Zara ali a DPS student in class 10th
上面的程序也可以使用 calloc() 来编写,只需要把 malloc 替换为 calloc 即可,如下所示:
calloc(200, sizeof(char));
当动态分配内存时,您有完全控制权,可以传递任何大小的值。而那些预先定义了大小的数组,一旦定义则无法改变大小。
重新调整内存的大小和释放内存
当程序退出时,操作系统会自动释放所有分配给程序的内存,但是,建议在不需要内存时,都应该调用函数 free() 来释放内存。
或者,可以通过调用函数 realloc() 来增加或减少已分配的内存块的大小。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main()
{
char name[100];
char *description;
strcpy(name, "Zara Ali");
/* 动态分配内存 */
description = (char *)malloc( 30 * sizeof(char) );
if( description == NULL )
{
fprintf(stderr, "Error - unable to allocate required memory\n");
}
else
{
strcpy( description, "Zara ali a DPS student.");
}
/* 假设您想要存储更大的描述信息 */
description = (char *) realloc( description, 100 * sizeof(char) );
if( description == NULL )
{
fprintf(stderr, "Error - unable to allocate required memory\n");
}
else
{
strcat( description, "She is in class 10th");
}
printf("Name = %s\n", name );
printf("Description: %s\n", description );
/* 使用 free() 函数释放内存 */
free(description);
}
当上面的代码被编译和执行时,它会产生下列结果:
Name = Zara Ali
Description: Zara ali a DPS student.She is in class 10th
可以尝试一下不重新分配额外的内存,strcat() 函数会生成一个错误,因为存储 description 时可用的内存不足。
C 语言中常用的内存管理函数和运算符
malloc() 函数:用于动态分配内存。它接受一个参数,即需要分配的内存大小(以字节为单位),并返回一个指向分配内存的指针。
free() 函数:用于释放先前分配的内存。它接受一个指向要释放内存的指针作为参数,并将该内存标记为未使用状态。
calloc() 函数:用于动态分配内存,并将其初始化为零。它接受两个参数,即需要分配的内存块数和每个内存块的大小(以字节为单位),并返回一个指向分配内存的指针。
realloc() 函数:用于重新分配内存。它接受两个参数,即一个先前分配的指针和一个新的内存大小,然后尝试重新调整先前分配的内存块的大小。如果调整成功,它将返回一个指向重新分配内存的指针,否则返回一个空指针。
sizeof 运算符:用于获取数据类型或变量的大小(以字节为单位)。
指针运算符:用于获取指针所指向的内存地址或变量的值。
& 运算符:用于获取变量的内存地址。
-
* 运算符:用于获取指针所指向的变量的值。
-> 运算符:用于指针访问结构体成员,语法为 pointer->member,等价于 (*pointer).member。
memcpy() 函数:用于从源内存区域复制数据到目标内存区域。它接受三个参数,即目标内存区域的指针、源内存区域的指针和要复制的数据大小(以字节为单位)。
memmove() 函数:类似于 memcpy() 函数,但它可以处理重叠的内存区域。它接受三个参数,即目标内存区域的指针、源内存区域的指针和要复制的数据大小(以字节为单位)。
void 指针
每一块内存都有地址,通过指针变量可以获取指定地址的内存块。指针变量必须有类型,否则编译器无法知道,如何解读内存块保存的二进制数据。但是,向系统请求内存的时候,有时不确定会有什么样的数据写入内存,需要先获得内存块,稍后再确定写入的数据类型。
为了满足这种需求,C 语言提供了一种不定类型的指针,叫做 void 指针。它只有内存块的地址信息,没有类型信息,等到使用该块内存的时候,再向编译器补充说明,里面的数据类型是什么。
另一方面,void 指针等同于无类型指针,可以指向任意类型的数据,但是不能解读数据。void 指针与其他所有类型指针之间是互相转换关系,任一类型的指针都可以转为 void 指针,而 void 指针也可以转为任一类型的指针。
int x = 10;
void* p = &x; // 整数指针转为 void 指针
int* q = p; // void 指针转为整数指针
上面示例演示了,整数指针和 void 指针如何互相转换。&x是一个整数指针,p是 void 指针,赋值时&x的地址会自动解释为 void 类型。同样的,p再赋值给整数指针q时,p的地址会自动解释为整数指针。
注意,由于不知道 void 指针指向什么类型的值,所以不能用*运算符取出它指向的值。
char a = 'X';
void* p = &a;
printf("%c\n", *p); // 报错
上面示例中,p是一个 void 指针,所以这时无法用*p取出指针指向的值。
void 指针的重要之处在于,很多内存相关函数的返回值就是 void 指针,只给出内存块的地址信息,所以放在最前面进行介绍。
相关库函数
malloc()
malloc()函数用于分配内存,该函数向系统要求一段内存,系统就在“堆”里面分配一段连续的内存块给它。它的原型定义在头文件stdlib.h。
void* malloc(size_t size)
它接受一个非负整数作为参数,表示所要分配的内存字节数,返回一个 void 指针,指向分配好的内存块。这是非常合理的,因为malloc()函数不知道,将要存储在该块内存的数据是什么类型,所以只能返回一个无类型的 void 指针。
可以使用malloc()为任意类型的数据分配内存,常见的做法是先使用sizeof()函数,算出某种数据类型所需的字节长度,然后再将这个长度传给malloc()。
int* p = malloc(sizeof(int));
*p = 12;
printf("%d\n", *p); // 12
上面示例中,先为整数类型分配一段内存,然后将整数12放入这段内存里面。这个例子其实不需要使用malloc(),因为 C 语言会自动为整数(本例是12)提供内存。
有时候为了增加代码的可读性,可以对malloc()返回的指针进行一次强制类型转换。
int* p = (int*) malloc(sizeof(int));
上面代码将malloc()返回的 void 指针,强制转换成了整数指针。
由于sizeof()的参数可以是变量,所以上面的例子也可以写成下面这样。
int* p = (int*) malloc(sizeof(*p));
malloc()分配内存有可能分配失败,这时返回常量NULL。Null的值为0,是一个无法读写的内存地址,可以理解成一个不指向任何地方的指针。它在包括stdlib.h等多个头文件里面都有定义,所以只要可以使用malloc(),就可以使用NULL。由于存在分配失败的可能,所以最好在使用malloc()之后检查一下,是否分配成功。
int* p = malloc(sizeof(int));
if (p == NULL) {
// 内存分配失败
}
// or
if (!p) {
//...
}
上面示例中,通过判断返回的指针p是否为NULL,确定malloc()是否分配成功。
malloc()最常用的场合,就是为数组和自定义数据结构分配内存。
int* p = (int*) malloc(sizeof(int) * 10);
for (int i = 0; i < 10; i++)
p[i] = i * 5;
上面示例中,p是一个整数指针,指向一段可以放置10个整数的内存,所以可以用作数组。
malloc()用来创建数组,有一个好处,就是它可以创建动态数组,即根据成员数量的不同,而创建长度不同的数组。
int* p = (int*) malloc(n * sizeof(int));
上面示例中,malloc()可以根据变量n的不同,动态为数组分配不同的大小。
注意,malloc()不会对所分配的内存进行初始化,里面还保存着原来的值。如果没有初始化,就使用这段内存,可能从里面读到以前的值。程序员要自己负责初始化,比如,字符串初始化可以使用strcpy()函数。
char* p = malloc(4);
strcpy(p, "abc");
上面示例中,字符指针p指向一段4个字节的内存,strcpy()将字符串“abc”拷贝放入这段内存,完成了这段内存的初始化。
free()
free()用于释放malloc()函数分配的内存,将这块内存还给系统以便重新使用,否则这个内存块会一直占用到程序运行结束。该函数的原型定义在头文件stdlib.h里面。
void free(void* block)
上面代码中,free()的参数是malloc()返回的内存地址。下面就是用法实例。
int* p = (int*) malloc(sizeof(int));
*p = 12;
free(p);
注意,分配的内存块一旦释放,就不应该再次操作已经释放的地址,也不应该再次使用free()对该地址释放第二次。
一个很常见的错误是,在函数内部分配了内存,但是函数调用结束时,没有使用free()释放内存。
void gobble(double arr[], int n) {
double* temp = (double*) malloc(n * sizeof(double));
// ...
}
上面示例中,函数gobble()内部分配了内存,但是没有写free(temp)。这会造成函数运行结束后,占用的内存块依然保留,如果多次调用gobble(),就会留下多个内存块。并且,由于指针temp已经消失了,也无法访问这些内存块,再次使用。
calloc()
calloc()函数的作用与malloc()相似,也是分配内存块。该函数的原型定义在头文件stdlib.h。
两者的区别主要有两点:
-
calloc()接受两个参数,第一个参数是某种数据类型的值的数量,第二个是该数据类型的单位字节长度。
void* calloc(size_t n, size_t size);calloc()的返回值也是一个 void 指针。分配失败时,返回 NULL。
-
calloc()会将所分配的内存全部初始化为0。malloc()不会对内存进行初始化,如果想要初始化为0,还要额外调用memset()函数。
int* p = calloc(10, sizeof(int)); // 等同于 int* p = malloc(sizeof(int) * 10); memset(p, 0, sizeof(int) * 10);上面示例中,calloc()相当于malloc() + memset()。
calloc()分配的内存块,也要使用free()释放。
realloc()
realloc()函数用于修改已经分配的内存块的大小,可以放大也可以缩小,返回一个指向新的内存块的指针。如果分配不成功,返回 NULL。该函数的原型定义在头文件stdlib.h。
void* realloc(void* block, size_t size)
它接受两个参数。
- block:已经分配好的内存块指针(由malloc()或calloc()或realloc()产生)。
- size:该内存块的新大小,单位为字节。
realloc()可能返回一个全新的地址(数据也会自动复制过去),也可能返回跟原来一样的地址。realloc()优先在原有内存块上进行缩减,尽量不移动数据,所以通常是返回原先的地址。如果新内存块小于原来的大小,则丢弃超出的部分;如果大于原来的大小,则不对新增的部分进行初始化(程序员可以自动调用memset())。
下面是一个例子,b是数组指针,realloc()动态调整它的大小。
int* b;
b = malloc(sizeof(int) * 10);
b = realloc(b, sizeof(int) * 2000);
上面示例中,指针b原来指向10个成员的整数数组,使用realloc()调整为2000个成员的数组。这就是手动分配数组内存的好处,可以在运行时随时调整数组的长度。
realloc()的第一个参数可以是 NULL,这时就相当于新建一个指针。
char* p = realloc(NULL, 3490);
// 等同于
char* p = malloc(3490);
如果realloc()的第二个参数是0,就会释放掉内存块。
由于有分配失败的可能,所以调用realloc()以后,最好检查一下它的返回值是否为 NULL。分配失败时,原有内存块中的数据不会发生改变。
float* new_p = realloc(p, sizeof(*p * 40));
if (new_p == NULL) {
printf("Error reallocing\n");
return 1;
}
注意,realloc()不会对内存块进行初始化。
restrict 说明符
声明指针变量时,可以使用restrict说明符,告诉编译器,该块内存区域只有当前指针一种访问方式,其他指针不能读写该块内存。这种指针称为“受限指针”(restrict pointer)。
int* restrict p;
p = malloc(sizeof(int));
上面示例中,声明指针变量p时,加入了restrict说明符,使得p变成了受限指针。后面,当p指向malloc()函数返回的一块内存区域,就意味着,该区域只有通过p来访问,不存在其他访问方式。
int* restrict p;
p = malloc(sizeof(int));
int* q = p;
*q = 0; // 未定义行为
上面示例中,另一个指针q与受限指针p指向同一块内存,现在该内存有p和q两种访问方式。这就违反了对编译器的承诺,后面通过*q对该内存区域赋值,会导致未定义行为。
memcpy()
memcpy()用于将一块内存拷贝到另一块内存。该函数的原型定义在头文件string.h。
void* memcpy(
void* restrict dest,
void* restrict source,
size_t n
);
上面代码中,dest是目标地址,source是源地址,第三个参数n是要拷贝的字节数n。如果要拷贝10个 double 类型的数组成员,n就等于10 * sizeof(double),而不是10。该函数会将从source开始的n个字节,拷贝到dest。
dest和source都是 void 指针,表示这里不限制指针类型,各种类型的内存数据都可以拷贝。两者都有 restrict 关键字,表示这两个内存块不应该有互相重叠的区域。
memcpy()的返回值是第一个参数,即目标地址的指针。
因为memcpy()只是将一段内存的值,复制到另一段内存,所以不需要知道内存里面的数据是什么类型。下面是复制字符串的例子。
#include <stdio.h>
#include <string.h>
int main(void) {
char s[] = "Goats!";
char t[100];
memcpy(t, s, sizeof(s)); // 拷贝7个字节,包括终止符
printf("%s\n", t); // "Goats!"
return 0;
}
上面示例中,字符串s所在的内存,被拷贝到字符数组t所在的内存。
memcpy()可以取代strcpy()进行字符串拷贝,而且是更好的方法,不仅更安全,速度也更快,它不检查字符串尾部的\0字符。
char* s = "hello world";
size_t len = strlen(s) + 1;
char *c = malloc(len);
if (c) {
// strcpy() 的写法
strcpy(c, s);
// memcpy() 的写法
memcpy(c, s, len);
}
上面示例中,两种写法的效果完全一样,但是memcpy()的写法要好于strcpy()。
使用 void 指针,也可以自定义一个复制内存的函数。
void* my_memcpy(void* dest, void* src, int byte_count) {
char* s = src;
char* d = dest;
while (byte_count--) {
*d++ = *s++;
}
return dest;
}
上面示例中,不管传入的dest和src是什么类型的指针,将它们重新定义成一字节的 Char 指针,这样就可以逐字节进行复制。*d++ = s++语句相当于先执行d = *s(源字节的值复制给目标字节),然后各自移动到下一个字节。最后,返回复制后的dest指针,便于后续使用。
memmove()
memmove()函数用于将一段内存数据复制到另一段内存。它跟memcpy()的主要区别是,它允许目标区域与源区域有重叠。如果发生重叠,源区域的内容会被更改;如果没有重叠,它与memcpy()行为相同。
该函数的原型定义在头文件string.h。
void* memmove(
void* dest,
void* source,
size_t n
);
上面代码中,dest是目标地址,source是源地址,n是要移动的字节数。dest和source都是 void 指针,表示可以移动任何类型的内存数据,两个内存区域可以有重叠。
memmove()返回值是第一个参数,即目标地址的指针。
int a[100];
// ...
memmove(&a[0], &a[1], 99 * sizeof(int));
上面示例中,从数组成员a[1]开始的99个成员,都向前移动一个位置。
下面是另一个例子。
char x[] = "Home Sweet Home";
// 输出 Sweet Home Home
printf("%s\n", (char *) memmove(x, &x[5], 10));
上面示例中,从字符串x的5号位置开始的10个字节,就是“Sweet Home”,memmove()将其前移到0号位置,所以x就变成了“Sweet Home Home”。
memcmp()
memcmp()函数用来比较两个内存区域。它的原型定义在string.h。
int memcmp(
const void* s1,
const void* s2,
size_t n
);
它接受三个参数,前两个参数是用来比较的指针,第三个参数指定比较的字节数。
它的返回值是一个整数。两块内存区域的每个字节以字符形式解读,按照字典顺序进行比较,如果两者相同,返回0;如果s1大于s2,返回大于0的整数;如果s1小于s2,返回小于0的整数。
char* s1 = "abc";
char* s2 = "acd";
int r = memcmp(s1, s2, 3); // 小于 0
上面示例比较s1和s2的前三个字节,由于s1小于s2,所以r是一个小于0的整数,一般为-1。
下面是另一个例子。
char s1[] = {'b', 'i', 'g', '\0', 'c', 'a', 'r'};
char s2[] = {'b', 'i', 'g', '\0', 'c', 'a', 't'};
if (memcmp(s1, s2, 3) == 0) // true
if (memcmp(s1, s2, 4) == 0) // true
if (memcmp(s1, s2, 7) == 0) // false
上面示例展示了,memcmp()可以比较内部带有字符串终止符\0 的内存区域。
C 命令行参数
命令行参数是使用 main() 函数参数来处理的,其中,argc 是指传入参数的个数,argv[] 是一个指针数组,指向传递给程序的每个参数。下面是一个简单的实例,检查命令行是否有提供参数,并根据参数执行相应的动作:
#include <stdio.h>
int main( int argc, char *argv[] )
{
if( argc == 2 )
{
printf("The argument supplied is %s\n", argv[1]);
}
else if( argc > 2 )
{
printf("Too many arguments supplied.\n");
}
else
{
printf("One argument expected.\n");
}
}
使用一个参数,编译并执行上面的代码,它会产生下列结果:
$./a.out testing
The argument supplied is testing
使用两个参数,编译并执行上面的代码,它会产生下列结果:
$./a.out testing1 testing2
Too many arguments supplied.
不传任何参数,编译并执行上面的代码,它会产生下列结果:
$./a.out
One argument expected
应当指出的是,argv[0] 存储程序的名称,argv[1] 是一个指向第一个命令行参数的指针,*argv[n] 是最后一个参数。如果没有提供任何参数,argc 将为 1,否则,如果传递了一个参数,argc 将被设置为 2。
多个命令行参数之间用空格分隔,但是如果参数本身带有空格,那么传递参数的时候应把参数放置在双引号 “” 或单引号 ‘’ 内部。
#include <stdio.h>
int main( int argc, char *argv[] )
{
printf("Program name %s\n", argv[0]);
if( argc == 2 )
{
printf("The argument supplied is %s\n", argv[1]);
}
else if( argc > 2 )
{
printf("Too many arguments supplied.\n");
}
else
{
printf("One argument expected.\n");
}
}
使用一个用空格分隔的简单参数,参数括在双引号中,编译并执行上面的代码,它会产生下列结果:
$./a.out "testing1 testing2"
Progranm name ./a.out
The argument supplied is testing1 testing2
main 的两个参数的参数名如下:
int main( int argc, char *argv[] )
并不一定这样写,只是约定俗成罢了。但是亦可以写成下面这样:
int main( int test_argc, char *test_argv[] )
但是大部分人还是写成开头那样的,如下:
int main( int argc, char *argv[] )
main()函数有两个参数argc(argument count)和argv(argument variable)。这两个参数的名字可以任意取,但是一般来说,约定俗成就是使用这两个词。
第一个参数argc是命令行参数的数量,由于程序名也被计算在内,所以严格地说argc是参数数量 + 1。
第二个参数argv是一个数组,保存了所有的命令行输入,它的每个成员是一个字符串指针。
由于字符串指针可以看成是字符数组,所以下面两种写法是等价的。
// 写法一
int main(int argc, char* argv[])
// 写法二
int main(int argc, char** argv)
另一方面,每个命令行参数既可以写成数组形式argv[i],也可以写成指针形式*(argv + i)。
利用argc,可以限定函数只能有多少个参数。
#include <stdio.h>
int main(int argc, char** argv) {
if (argc != 3) {
printf("usage: mult x y\n");
return 1;
}
printf("%d\n", atoi(argv[1]) * atoi(argv[2]));
return 0;
}
上面示例中,argc不等于3就会报错,这样就限定了程序必须有两个参数,才能运行。
另外,argv数组的最后一个成员是 NULL 指针(argv[argc] == NULL)。所以,参数的遍历也可以写成下面这样。
for (char** p = argv; *p != NULL; p++) {
printf("arg: %s\n", *p);
}
上面示例中,指针p依次移动,指向argv的每个成员,一旦移到空指针 NULL,就表示遍历结束。由于argv的地址是固定的,不能执行自增运算(argv++),所以必须通过一个中间变量p,完成遍历操作。
退出状态
C 语言规定,如果main()函数没有return语句,那么结束运行的时候,默认会添加一句return 0,即返回整数0。这就是为什么main()语句通常约定返回一个整数值,并且返回整数0表示程序运行成功。如果返回非零值,就表示程序运行出了问题。
Bash 的环境变量$?可以用来读取上一个命令的返回值,从而知道是否运行成功。
$ ./foo hello world
$ echo $?
0
上面示例中,echo $?用来打印环境变量$?的值,该值为0,就表示上一条命令运行成功,否则就是运行失败。
注意,只有main()会默认添加return 0,其他函数都没有这个机制。
环境变量
C 语言提供了getenv()函数(原型在stdlib.h)用来读取命令行环境变量。
#include <stdio.h>
#include <stdlib.h>
int main(void) {
char* val = getenv("HOME");
if (val == NULL) {
printf("Cannot find the HOME environment variable\n");
return 1;
}
printf("Value: %s\n", val);
return 0;
}
上面示例中,getenv(“HOME”)用来获取命令行的环境变量$HOME,如果这个变量为空(NULL),则程序报错返回。
unicode支持
C 语言诞生时,只考虑了英语字符,使用7位的 ASCII 码表示所有字符。ASCII 码的范围是0到127,也就是最多只能表示100多个字符,用一个字节就可以表示,所以char类型只占用一个字节。
Unicode 为每个字符提供一个号码,称为码点(code point),其中0到127的部分,跟 ASCII 码是重合的。通常使用“U+十六进制码点”表示一个字符,比如U+0041表示字母A。
Unicode 编码目前一共包含了100多万个字符,码点范围是 U+0000 到 U+10FFFF。完整表达整个 Unicode 字符集,至少需要三个字节。但是,并不是所有文档都需要那么多字符,比如对于 ASCII 码就够用的英语文档,如果每个字符使用三个字节表示,就会比单字节表示的文件体积大出三倍。
为了适应不同的使用需求,Unicode 标准委员会提供了三种不同的表示方法,表示 Unicode 码点。
- UTF-8:使用1个到4个字节,表示一个码点。不同的字符占用的字节数不一样。
- UTF-16:对于U+0000 到 U+FFFF 的字符(称为基本平面),使用2个字节表示一个码点。其他字符使用4个字节。
- UTF-32:统一使用4个字节,表示一个码点。
其中,UTF-8 的使用最为广泛,因为对于 ASCII 字符(U+0000 到 U+007F),它只使用一个字节表示,这就跟 ASCII 的编码方式完全一样。
C 语言提供了两个宏,表示当前系统支持的编码字节长度。这两个宏都定义在头文件limits.h。
- MB_LEN_MAX:任意支持地区的最大字节长度,定义在
limits.h。 - MB_CUR_MAX:当前语言的最大字节长度,总是小于或等于MB_LEN_MAX,定义在
stdlib.h。
字符的表示方法
字符表示法的本质,是将每个字符映射为一个整数,然后从编码表获得该整数对应的字符。
C 语言提供了不同的写法,用来表示字符的整数号码。
- \123:以八进制值表示一个字符,斜杠后面需要三个数字。
- \x4D:以十六进制表示一个字符,\x后面是十六进制整数。
- \u2620:以 Unicode 码点表示一个字符(不适用于 ASCII 字符),码点以十六进制表示,\u后面需要4个字符。
- \U0001243F:以 Unicode 码点表示一个字符(不适用于 ASCII 字符),码点以十六进制表示,\U后面需要8个字符。
printf("ABC\n");
printf("\101\102\103\n");
printf("\x41\x42\x43\n");
上面三行都会输出“ABC”。
printf("\u2022 Bullet 1\n");
printf("\U00002022 Bullet 1\n");
上面两行都会输出“? Bullet 1”。
多字节字符的表示
C 语言预设只有基本字符,才能使用字面量表示,其它字符都应该使用码点表示,并且当前系统还必须支持该码点的编码方法。
所谓基本字符,指的是所有可打印的 ASCII 字符,但是有三个字符除外:@、$、`。
因此,遇到非英语字符,应该将其写成 Unicode 码点形式。
char* s = "\u6625\u5929";
printf("%s\n", s); // 春天
上面代码会输出中文“春天”。
如果当前系统是 UTF-8 编码,可以直接用字面量表示多字节字符。
char* s = "春天";
printf("%s\n", s);
注意,\u + 码点和\U + 码点的写法,不能用来表示 ASCII 码字符(码点小于0xA0的字符),只有三个字符除外:0x24($),0x40(@)和0x60(`)。
char* s = "\u0024\u0040\u0060";
printf("%s\n", s); // @$`
上面代码会输出三个 Unicode 字符“@$`”,但是其它 ASCII 字符都不能用这种表示法表示。
为了保证程序执行时,字符能够正确解读,最好将程序环境切换到本地化环境。
setlocale(LC_ALL, "");
上面代码中,使用setlocale()切换执行环境到系统的本地化语言。setlocale()的原型定义在头文件locale.h.
像下面这样,指定编码语言也可以。
setlocale(LC_ALL, "zh_CN.UTF-8");
上面代码将程序执行环境,切换到中文环境的 UTF-8 编码。
C 语言允许使用u8前缀,对多字节字符串指定编码方式为 UTF-8。
char* s = u8"春天";
printf("%s\n", s);
一旦字符串里面包含多字节字符,就意味着字符串的字节数与字符数不再一一对应了。比如,字符串的长度为10字节,就不再是包含10个字符,而可能只包含7个字符、5个字符等等。
setlocale(LC_ALL, "");
char* s = "春天";
printf("%d\n", strlen(s)); // 6
上面示例中,字符串s只包含两个字符,但是strlen()返回的结果却是6,表示这两个字符一共占据了6个字节。
C 语言的字符串函数只针对单字节字符有效,对于多字节字符都会失效,比如strtok()、strchr()、strspn()、toupper()、tolower()、isalpha()等不会得到正确结果。
宽字符
C 语言还提供了确定宽度的多字节字符存储方式,称为宽字符(wide character)。
所谓“宽字符”,就是每个字符占用的字节数是固定的,要么是2个字节,要么是4个字节。这样的话,就很容易快速处理。
宽字符有一个单独的数据类型 wchar_t,每个宽字符都是这个类型。它属于整数类型的别名,可能是有符号的,也可能是无符号的,由当前实现决定。该类型的长度为16位(2个字节)或32位(4个字节),足以容纳当前系统的所有字符。它定义在头文件wchar.h里面。
宽字符的字面量必须加上前缀“L”,否则 C 语言会把字面量当作窄字符类型处理。
setlocale(LC_ALL, "");
wchar_t c = L'牛';
printf("%lc\n", c);
wchar_t* s = L"春天";
printf("%ls\n", s);
上面示例中,前缀“L”在单引号前面,表示宽字符,对应printf()的占位符为%lc;在双引号前面,表示宽字符串,对应printf()的占位符为%ls。
宽字符串的结尾也有一个空字符,不过是宽空字符,占用多个字节。
处理宽字符,需要使用宽字符专用的函数,绝大部分都定义在头文件wchar.h。
多字节字符处理函数
mblen()
mblen()函数返回一个多字节字符占用的字节数。它的原型定义在头文件stdlib.h。
int mblen(const char* mbstr, size_t n);
它接受两个参数,第一个参数是多字节字符串指针,一般会检查该字符串的第一个字符;第二个参数是需要检查的字节数,这个数字不能大于当前系统单个字符占用的最大字节,一般使用MB_CUR_MAX。
它的返回值是该字符占用的字节数。如果当前字符是空的宽字符,则返回0;如果当前字符不是有效的多字节字符,则返回-1。
setlocale(LC_ALL, "");
char* mbs1 = "春天";
printf("%d\n", mblen(mbs1, MB_CUR_MAX)); // 3
char* mbs2 = "abc";
printf("%d\n", mblen(mbs2, MB_CUR_MAX)); // 1
上面示例中,字符串“春天”的第一个字符“春”,占用3个字节;字符串“abc”的第一个字符“a”,占用1个字节。
wctomb()
wctomb()函数(wide character to multibyte)用于将宽字符转为多字节字符。它的原型定义在头文件stdlib.h。
int wctomb(char* s, wchar_t wc);
wctomb()接受两个参数,第一个参数是作为目标的多字节字符数组,第二个参数是需要转换的一个宽字符。它的返回值是多字节字符存储占用的字节数量,如果无法转换,则返回-1。
setlocale(LC_ALL, "");
wchar_t wc = L'牛';
char mbStr[10] = "";
int nBytes = 0;
nBytes = wctomb(mbStr, wc);
printf("%s\n", mbStr); // 牛
printf("%d\n", nBytes); // 3
上面示例中,wctomb()将宽字符“牛”转为多字节字符,wctomb()的返回值表示转换后的多字节字符占用3个字节。
mbtowc()
mbtowc()用于将多字节字符转为宽字符。它的原型定义在头文件stdlib.h。
int mbtowc(
wchar_t* wchar,
const char* mbchar,
size_t count
);
它接受3个参数,第一个参数是作为目标的宽字符指针,第二个参数是待转换的多字节字符指针,第三个参数是多字节字符的字节数。
它的返回值是多字节字符的字节数,如果转换失败,则返回-1。
setlocale(LC_ALL, "");
char* mbchar = "牛";
wchar_t wc;
wchar_t* pwc = &wc;
int nBytes = 0;
nBytes = mbtowc(pwc, mbchar, 3);
printf("%d\n", nBytes); // 3
printf("%lc\n", *pwc); // 牛
上面示例中,mbtowc()将多字节字符“牛”转为宽字符wc,返回值是mbchar占用的字节数(占用3个字节)。
wcstombs()
wcstombs()用来将宽字符串转换为多字节字符串。它的原型定义在头文件stdlib.h。
size_t wcstombs(
char* mbstr,
const wchar_t* wcstr,
size_t count
);
它接受三个参数,第一个参数mbstr是目标的多字节字符串指针,第二个参数wcstr是待转换的宽字符串指针,第三个参数count是用来存储多字节字符串的最大字节数。
如果转换成功,它的返回值是成功转换后的多字节字符串的字节数,不包括尾部的字符串终止符;如果转换失败,则返回-1。
下面是一个例子。
setlocale(LC_ALL, "");
char mbs[20];
wchar_t* wcs = L"春天";
int nBytes = 0;
nBytes = wcstombs(mbs, wcs, 20);
printf("%s\n", mbs); // 春天
printf("%d\n", nBytes); // 6
上面示例中,wcstombs()将宽字符串wcs转为多字节字符串mbs,返回值6表示写入mbs的字符串占用6个字节,不包括尾部的字符串终止符。
如果wcstombs()的第一个参数是 NULL,则返回转换成功所需要的目标字符串的字节数。
mbstowcs()
mbstowcs()用来将多字节字符串转换为宽字符串。它的原型定义在头文件stdlib.h。
size_t mbstowcs(
wchar_t* wcstr,
const char* mbstr,
size_t count
);
它接受三个参数,第一个参数wcstr是目标宽字符串,第二个参数mbstr是待转换的多字节字符串,第三个参数是待转换的多字节字符串的最大字符数。
转换成功时,它的返回值是成功转换的多字节字符的数量;转换失败时,返回-1。如果返回值与第三个参数相同,那么转换后的宽字符串不是以 NULL 结尾的。
下面是一个例子。
setlocale(LC_ALL, "");
char* mbs = "天气不错";
wchar_t wcs[20];
int nBytes = 0;
nBytes = mbstowcs(wcs, mbs, 20);
printf("%ls\n", wcs); // 天气不错
printf("%d\n", nBytes); // 4
上面示例中,多字节字符串mbs被mbstowcs()转为宽字符串,成功转换了4个字符,所以该函数的返回值为4。
如果mbstowcs()的第一个参数为NULL,则返回目标宽字符串会包含的字符数量。
多文件项目构建
一个软件项目往往包含多个源码文件,编译时需要将这些文件一起编译,生成一个可执行文件。
假定一个项目有两个源码文件foo.c和bar.c,其中foo.c是主文件,bar.c是库文件。所谓“主文件”,就是包含了main()函数的项目入口文件,里面会引用库文件定义的各种函数。
// File foo.c
#include <stdio.h>
int main(void) {
printf("%d\n", add(2, 3)); // 5!
}
上面代码中,主文件foo.c调用了函数add(),这个函数是在库文件bar.c里面定义的。
// File bar.c
int add(int x, int y) {
return x + y;
}
现在,将这两个文件一起编译。
$ gcc -o foo foo.c bar.c
# 更省事的写法
$ gcc -o foo *.c
上面命令中,gcc 的-o参数指定生成的二进制可执行文件的文件名,本例是foo。
这个命令运行后,编译器会发出警告,原因是在编译foo.c的过程中,编译器发现一个不认识的函数add(),foo.c里面没有这个函数的原型或者定义。因此,最好修改一下foo.c,在文件头部加入add()的原型。
// File foo.c
#include <stdio.h>
int add(int, int);
int main(void) {
printf("%d\n", add(2, 3)); // 5!
}
现在再编译就没有警告了。
如果有多个文件都使用这个函数add(),那么每个文件都需要加入函数原型。一旦需要修改函数add()(比如改变参数的数量),就会非常麻烦,需要每个文件逐一改动。所以,通常的做法是新建一个专门的头文件bar.h,放置所有在bar.c里面定义的函数的原型。
// File bar.h
int add(int, int);
然后使用include命令,在用到这个函数的源码文件里面加载这个头文件bar.h。
// File foo.c
#include <stdio.h>
#include "bar.h"
int main(void) {
printf("%d\n", add(2, 3)); // 5!
}
上面代码中,#include "bar.h"表示加入头文件bar.h。这个文件没有放在尖括号里面,表示它是用户提供的;它没有写路径,就表示与当前源码文件在同一个目录。
然后,最好在bar.c里面也加载这个头文件,这样可以让编译器验证,函数原型与函数定义是否一致。
// File bar.c
#include "bar.h"
int add(int a, int b) {
return a + b;
}
现在重新编译,就可以顺利得到二进制可执行文件。
$ gcc -o foo foo.c bar.c
重复加载
头文件里面还可以加载其他头文件,因此有可能产生重复加载。比如,a.h和b.h都加载了c.h,然后foo.c同时加载了a.h和b.h,这意味着foo.c会编译两次c.h。
最好避免这种重复加载,虽然多次定义同一个函数原型并不会报错,但是有些语句重复使用会报错,比如多次重复定义同一个 Struct 数据结构。解决重复加载的常见方法是,在头文件里面设置一个专门的宏,加载时一旦发现这个宏存在,就不再继续加载当前文件了。
// File bar.h
#ifndef BAR_H
#define BAR_H
int add(int, int);
#endif
上面示例中,头文件bar.h使用#ifndef和#endif设置了一个条件判断。每当加载这个头文件时,就会执行这个判断,查看有没有设置过宏BAR_H。如果设置过了,表明这个头文件已经加载过了,就不再重复加载了,反之就先设置一下这个宏,然后加载函数原型。
extern 说明符
当前文件还可以使用其他文件定义的变量,这时要使用extern说明符,在当前文件中声明,这个变量是其他文件定义的。
extern int myVar;
上面示例中,extern说明符告诉编译器,变量myvar是其他脚本文件声明的,不需要在这里为它分配内存空间。
由于不需要分配内存空间,所以extern声明数组时,不需要给出数组长度。
extern int a[];
这种共享变量的声明,可以直接写在源码文件里面,也可以放在头文件中,通过#include指令加载。
static 说明符
正常情况下,当前文件内部的全局变量,可以被其他文件使用。有时候,不希望发生这种情况,而是希望某个变量只局限在当前文件内部使用,不要被其他文件引用。
这时可以在声明变量的时候,使用static关键字,使得该变量变成当前文件的私有变量。
static int foo = 3;
上面示例中,变量foo只能在当前文件里面使用,其他文件不能引用。
编译策略
多个源码文件的项目,编译时需要所有文件一起编译。哪怕只是修改了一行,也需要从头编译,非常耗费时间。
为了节省时间,通常的做法是将编译拆分成两个步骤。第一步,使用 GCC 的-c参数,将每个源码文件单独编译为对象文件(object file)。第二步,将所有对象文件链接在一起,合并生成一个二进制可执行文件。
$ gcc -c foo.c # 生成 foo.o
$ gcc -c bar.c # 生成 bar.o
# 更省事的写法
$ gcc -c *.c
上面命令为源码文件foo.c和bar.c,分别生成对象文件foo.o和bar.o。
对象文件不是可执行文件,只是编译过程中的一个阶段性产物,文件名与源码文件相同,但是后缀名变成了.o。
得到所有的对象文件以后,再次使用gcc命令,将它们通过链接,合并生成一个可执行文件。
$ gcc -o foo foo.o bar.o
# 更省事的写法
$ gcc -o foo *.o
以后,修改了哪一个源文件,就将这个文件重新编译成对象文件,其他文件不用重新编译,可以继续使用原来的对象文件,最后再将所有对象文件重新链接一次就可以了。由于链接的耗时大大短于编译,这样做就节省了大量时间。
make 命令
大型项目的编译,如果全部手动完成,是非常麻烦的,容易出错。一般会使用专门的自动化编译工具,比如 make。
make 是一个命令行工具,使用时会自动在当前目录下搜索配置文件 makefile(也可以写成 Makefile)。该文件定义了所有的编译规则,每个编译规则对应一个编译产物。为了得到这个编译产物,它需要知道两件事。
- 依赖项(生成该编译产物,需要用到哪些文件)
- 生成命令(生成该编译产物的命令)
比如,对象文件foo.o是一个编译产物,它的依赖项是foo.c,生成命令是gcc -c foo.c。对应的编译规则如下:
foo.o: foo.c
gcc -c foo.c
上面示例中,编译规则由两行组成。第一行首先是编译产物,冒号后面是它的依赖项,第二行则是生成命令。
注意,第二行的缩进必须使用 Tab 键,如果使用空格键会报错。
完整的配置文件 makefile 由多个编译规则组成,可能是下面的样子。
foo: foo.o bar.o
gcc -o foo foo.o bar.o
foo.o: bar.h foo.c
gcc -c foo.c
bar.o: bar.h bar.c
gcc -c bar.c
上面是 makefile 的一个示例文件。它包含三个编译规则,对应三个编译产物(foo.o、bar.o和foo),每个编译规则之间使用空行分隔。
有了 makefile,编译时,只要在 make 命令后面指定编译目标(编译产物的名字),就会自动调用对应的编译规则。
$ make foo.o
# or
$ make bar.o
# or
$ make foo
上面示例中,make 命令会根据不同的命令,生成不同的编译产物。
如果省略了编译目标,make命令会执行第一条编译规则,构建相应的产物。
$ make
上面示例中,make后面没有编译目标,所以会执行 makefile 的第一条编译规则,本例是make foo。由于用户期望执行make后得到最终的可执行文件,所以建议总是把最终可执行文件的编译规则,放在 makefile 文件的第一条。makefile 本身对编译规则没有顺序要求。
make 命令的强大之处在于,它不是每次执行命令,都会进行编译,而是会检查是否有必要重新编译。具体方法是,通过检查每个源码文件的时间戳,确定在上次编译之后,哪些文件发生过变动。然后,重新编译那些受到影响的编译产物(即编译产物直接或间接依赖于那些发生变动的源码文件),不受影响的编译产物,就不会重新编译。
举例来说,上次编译之后,修改了foo.c,没有修改bar.c和bar.h。于是,重新运行make foo命令时,Make 就会发现bar.c和bar.h没有变动过,因此不用重新编译bar.o,只需要重新编译foo.o。有了新的foo.o以后,再跟bar.o一起,重新编译成新的可执行文件foo。
Make 这样设计的最大好处,就是自动处理编译过程,只重新编译变动过的文件,因此大大节省了时间。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!