深度学习 常考简答题--[HBU]期末复习
目录
4.平方损失函数为何不适用于解决分类问题?(和第3题一块复习)
10.LSTM与GRU的区别?LSTM解决了什么问题?其结构是什么?
其他简答习题都在我的博客里,没时间整了。先整理这么多我认为比较重要吧
前言:这篇博客是应对期末考试简答题的,答案都是我在网上、书上搜集整合过来的,chatGPT生成的也有,大家可以选择性的背自己认为最正确的部分。希望能帮到大家。
这篇博客比较侧重简答,结合上一篇我的博客看,效果更佳。我的上一篇期末复习总结博客:NNDL学期知识点总结 [HBU]-CSDN博客
1.为什么要引用非线性激活函数?
ChatGPT4.0回答:
引入非线性:线性模型虽简单,但表达能力有限,无法处理复杂的数据如图像、语音或文本等,非线性激活函数使得神经网络能够学习和模拟任何复杂的、非线性的函数。
增加模型的灵活性和表达能力:通过引入非线性,神经网络可以学习更复杂的模式。
帮助网络收敛:非线性激活函数可以改善网络的训练过程,帮助网络更快收敛。一些非线性函数(如ReLU)还有助于缓解梯度消失问题。
提高泛化能力:非线性激活函数有助于提高模型的泛化能力,减少过拟合的风险。一些激活函数如ReLU及其变体,因其简单和有效性而广泛使用。
非线性激活函数是神经网络能够有效处理复杂、非线性问题的关键。没有它们,神经网络的应用将大大受限。
文心一言回答:
- 非线性:线性激活函数只能完成线性映射,而非线性激活函数能够从输入输出之间生成非线性映射,从而使得神经网络能够学习并逼近任意复杂的非线性函数。
- 增加网络的表示能力:通过引入非线性因素,神经网络可以学习表示非线性关系,从而更好地拟合复杂的数据。
- 模拟生物神经元行为:生物神经元的行为是非线性的,而非线性激活函数更好地模拟了这一特性。
- 解决逼近任意函数的问题:现实中很多问题是不能用线性解决的,非线性激活函数可将数据从当前特征空间通过一定的线性映射转换到另一个空间,让数据能够更好的被分类。
- 梯度下降法的需求:非线性激活函数可以满足梯度下降法的要求,使神经网络在训练过程中能够更好地进行参数优化。
2.什么是超参数?如何优化超参数?
超参数是在开始学习过程之前设置的参数,而不是通过训练得到的参数数据。它们对模型训练的效果有重要影响,需要通过调整来优化模型的表现。
如何优化超参数?以下是chatGPT的解答:
- 网格搜索:对所有参数的所有可能组合进行搜索,以找到最佳的超参数组合。计算成本非常高。
- 随机搜索:在参数空间中进行随机抽样,并对抽样得到的超参数组合进行训练和评估。
- 贝叶斯优化:通过建立一个高斯过程模型来预测超参数的最佳值,并使用这个模型来指导搜索方向。
- 基于梯度的优化(重点):使用梯度下降或其他优化算法来寻找超参数的最优值。通常需要计算损失函数关于超参数的梯度,并沿着梯度的负方向进行搜索。这种方法需要选择合适的步长和收敛条件。
常见的超参数有:
深度学习中有哪些超参数,都有什么作用_深度学习超参数对模型性能的影响-CSDN博客
>学习率(Learning Rate):控制参数更新的步长。较小的学习率可以使模型收敛更稳定,但可能需要更多的训练时间;较大的学习率可以加快收敛速度,但可能导致不稳定或错过最优解。
>批量大小(Batch Size):每次迭代中输入到模型的样本数量。较大的批量大小可以提高训练效率,但也可能使模型陷入局部极小值或漏掉最优解;较小的批量大小可以帮助模型更好地泛化,但可能增加训练时间。
>迭代次数(Epochs):训练数据集被完整遍历的次数。较多的迭代次数可以使模型学习更充分,但如果过多,可能导致过拟合。
正则化参数(Regularization):用于控制模型的复杂度。正则化有助于减少过拟合,通过对模型的复杂度引入惩罚项。常见的正则化方法包括L1正则化、L2正则化等。
>网络结构相关超参数:如层数、每层的神经元数量、激活函数的选择等。
>优化器参数:包括动量(momentum)、权重衰减(weight decay)等。
>卷积神经网络(CNN)中的核大小、步长和填充方式等。
?
3.线性回归通常使用平方损失函数,能否使用交叉熵损失函数?
4.平方损失函数为何不适用于解决分类问题?(和第3题一块复习)
可看我的这篇博客:[23-24 秋学期] NNDL-作业2 HBU-CSDN博客


5.什么是长程依赖问题,如何解决?
长程依赖问题:RNN循环神经网络在学习过程中主要的问题是由于梯度消失和梯度爆炸导致的。通常循环神经网络只能学习到短期的依赖关系,很难建立长时间间隔的状态之间的依赖关系。
如何解决:(可看我之前写过的博客,也可直接看下图,是我截取的内容)
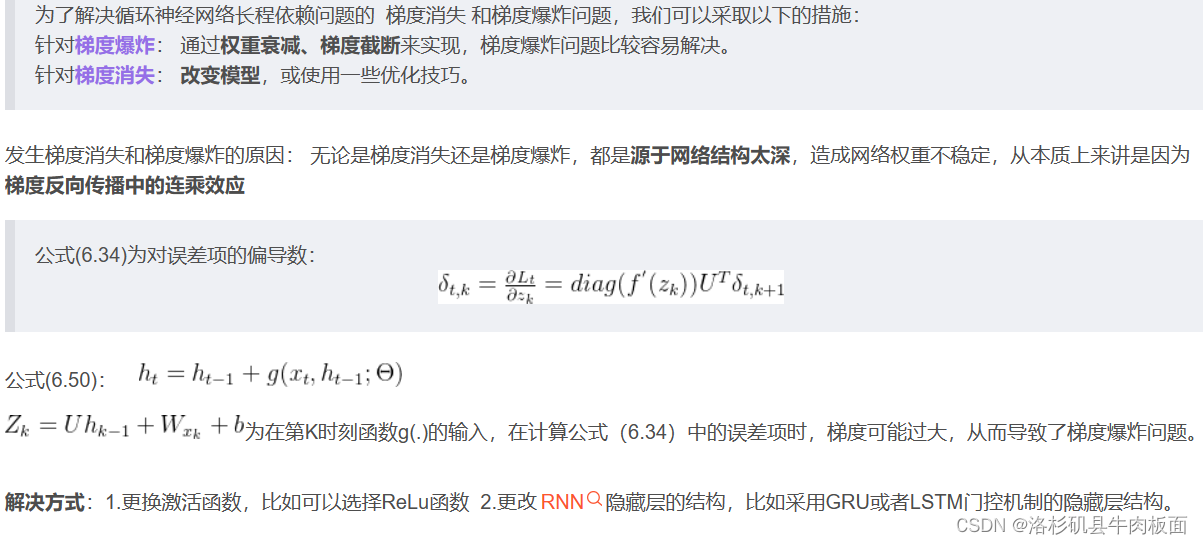
6.什么是对称权重现象,有哪些解决方案?
对称权重现象:在神经网络中,如果参数都设为0,那么在第一遍前向计算的过程中所有的隐藏层神经元的激活值都相同,同时在反向传播时,所有权重更新也都相同。这种现象会导致隐藏层神经元没有区分性,即相当于隐层只有1个神经元。
解决:在用反向传播算法进行参数学习时,通常采用随机参数初始化的方式而不是直接令W=0,b=0,以避免对称权重现象的发生。
7.什么是损失函数?常见的损失函数有哪些?
以邱锡鹏《神经网络与深度学习》书中为准。
什么是损失函数:损失函数是一个非负实数函数,用来量化模型预测和真实标签之间的差异。
常见的损失函数(p28):
1.? 0-1损失函数:最直观的损失函数是模型在训练集上的错误率,即0-1损失函数。缺点是数学性质不是很好,不连续且导数为0,难以优化。
2. 平方损失函数:预测标签
为实数值的任务中,不适用于分类问题。
3. 交叉熵损失函数:用于分类问题。输出为类别标签的条件概率分布。
4. Hinge函数:? ?常用于二分类问题。
8.解释死亡ReLu问题,如何解决?
我在上一篇博客中总结过,顺便回顾一下ReLu的性质,如下图:

死亡ReLu问题:ReLu神经元在训练时容易“死亡”。如果参数在一次不恰当的更新后,第一个隐藏层中(也可能是其他隐藏层)的某个ReLu神经元在所有的训练数据上都不能被激活,那么这个神经元自身参数的梯度值永远都是0,在以后的训练过程中永远不能被激活,即死亡ReLu问题。
如何解决:引出带泄露的ReLu(Leaky ReLu),Leaky ReLu在输入x<0时保持一个很小的梯度,这样当神经元非激活时也能有一个非零的梯度可以更新参数,避免永远不能被激活。其中
是一个很小的单元,如0.01。其图像为:

9.解释步长、零填充、感受野
想加深理解的看我这篇博客,里面有图:
[23-24 秋学期]NNDL 作业6 卷积 [HBU]-CSDN博客
步长stride:卷积核在输入数据上每次滑动过的距离。
零填充padding:在一维矩阵中,填充即在输入数据的左右两端各添加额外的P个0;在二维矩阵中,填充是指在矩阵周围一圈添加0。填充零可以保护一些不想丢失的特征参数。
感受野:感受野是指卷积核可以感知到的输入数据的区域。感受野描述了卷积核对输入数据的感知范围。感受野的大小可以通过改变卷积核的大小和步长来调整。
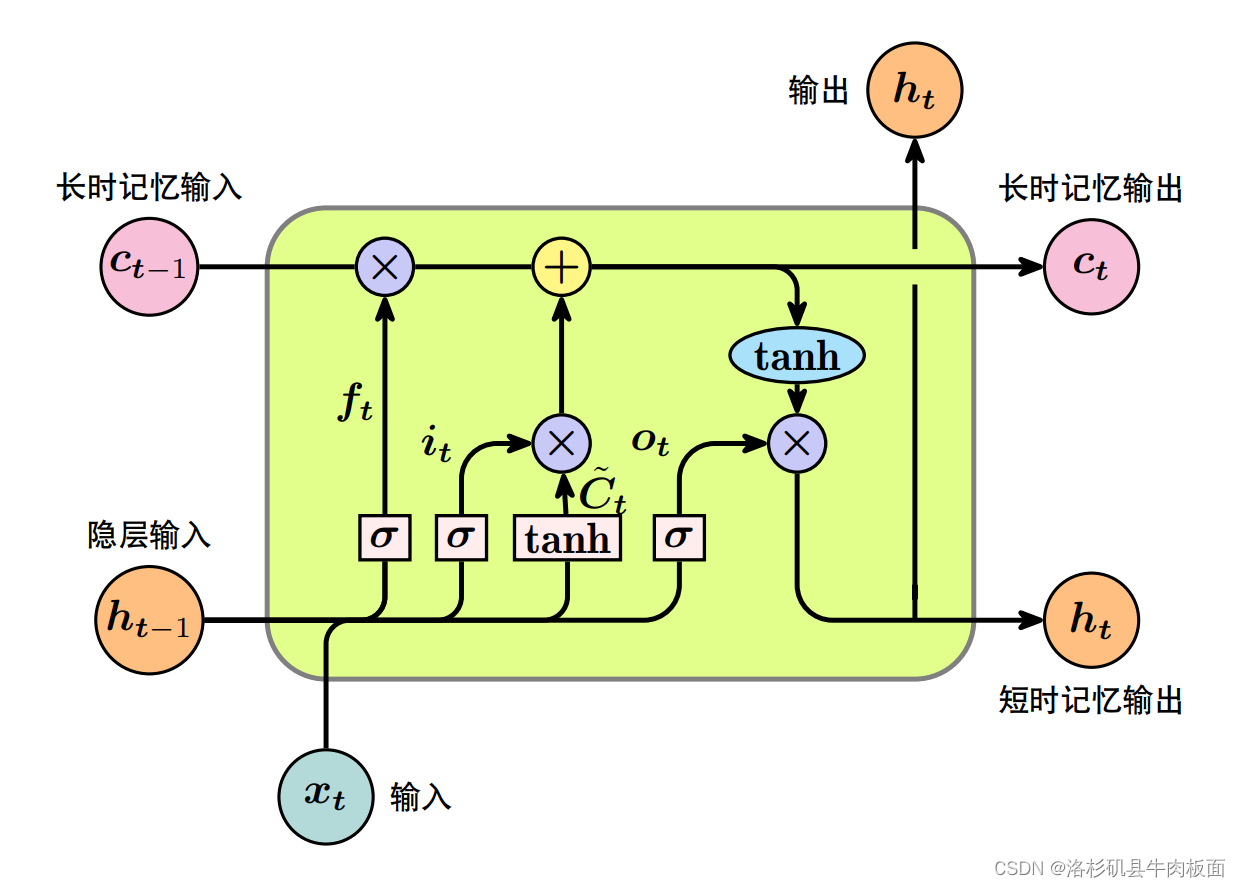
10.LSTM与GRU的区别?LSTM解决了什么问题?其结构是什么?
LSTM(长短期记忆)和GRU(门控循环单元)是两种常见的循环神经网络(RNN)架构,它们都旨在解决长期依赖问题。
二者区别主要在于网络结构上:(GRU就是LSTM的简化版)
LSTM具有三个门(输入门、遗忘门和输出门)来控制记忆信息的流动。
GRU只有两个门(重置门和更新门)。
LSTM网络的三个门,分别是输入门、遗忘门和输出门,作用如下:
输入门(Input Gate):决定何时将数据读入单元。它通过一个激活函数(如sigmoid函数)来控制输入单元的内容,更新单元的内部状态。
遗忘门(Forget Gate):控制上一个时刻
的内部状态需要遗忘多少信息。
输出门(Output Gate):控制当前时刻的内部状态有多少信息需要输出给外部状态。
通过这三个门的作用,LSTM能够更好地处理长时间依赖问题,并避免梯度消失和梯度爆炸的问题。
LSTM结构图:(想推公式 就看下面的博客)
我自己画的:

网上找的:
11.分析1*1卷积核的作用
- 降维和升维:1x1的卷积核可以用于改变特征图的通道数。如果卷积核的输出通道数少于输入通道数,那么它就起到了降维的作用,减少了网络的参数数量和计算量;反之,如果卷积核的输出通道数多于输入通道数,那么它就起到了升维的作用,可以增加网络的表达能力。
- 通道间的线性变换:1x1的卷积核只涉及到同一通道内的像素间的操作,因此它可用于实现通道间的线性变换。
- 跨通道信息交互:特征图中所有位置和通道间可以进行信息交互,增强了网络的特征表示能力。
- 减少计算量:相对于较大的卷积核,1x1的卷积核可以在不损失太多信息的情况下显著减少计算量。
其他简答习题都在我的博客里,没时间整了。先整理这么多我认为比较重要吧
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 第十二届全国大学生GIS技能大赛试题、数据以及解题思路
- Mybatis-Plus基础之Mapper的映射规则
- validation-api与hibernate-validator;@Validated与@Valid
- Skywalking系列之最新版9.2.0-JavaAgent本地构建
- c++输出简单日志带日期时间功能
- 函数栈帧的创建与销毁
- 06、Kafka ------ 各个功能的作用解释(ISR 同步副本、非同步副本、自动创建主题、修改主题、删除主题)
- 校园疫情防控信息管理系统的设计与实现-计算机毕业设计源码12057
- 深入理解PyTorch中的Hook机制:特征可视化的重要工具与实践
- 基于大数据技术的智慧城市交通流量预测与优化