Hbas简介:数据模型和概念、物理视图
文章目录
说明
- 本文参考自林子雨老师的大数据技术原理与应用(第三版)教材内容,仅供学习和交流
零 BigTable
-
Google Bigtable是一种高度可扩展的分布式数据库,旨在处理海量数据并提供高吞吐量和低延迟的访问。它是谷歌公司为其内部使用而开发的,并在2004年首次公开发表。
-
它利用谷歌提出的 MapReduce 分布式并行计算模型来处理海量数据,使用谷歌分布式文件系统 GFS 作为其底层数据存储方式,通过自动分片和负载均衡来实现数据在集群中的分布和访问,并采用 Chubby 提供协同管理服务,可以扩展到 PB 级别的数据和上千台机器,具备 广泛应用性、可扩展性、高性能和高可用性 等特点。
-
Bigtable还提供了强大的数据一致性和持久性保证。数据在写入时会被复制到多个地理位置的存储节点,以确保数据的可靠性和冗余备份。此外,Bigtable还支持强一致性和事务操作,使得应用程序可以进行复杂的数据操作和查询。
-
Google Bigtable是一种高度可扩展、具有高性能和可靠性的分布式数据库,适用于处理大规模数据集和高并发访问的场景。 BigTable 具备以下特性:支持大规模海量数据,分布式并发数据处理效率极高,易于扩展且支持动态伸缩,适用于廉价设备,适合读操作不适合写操作。
一 Hbase简介
-
HBase 是谷歌 BigTable 的开源实现,是一个高可靠、高性能、面向列、可伸缩的分布式非关系型数据库,主要用来存储非结构化和半结构化的松散数据,并提供高吞吐量和低延迟的数据访问能力。
-
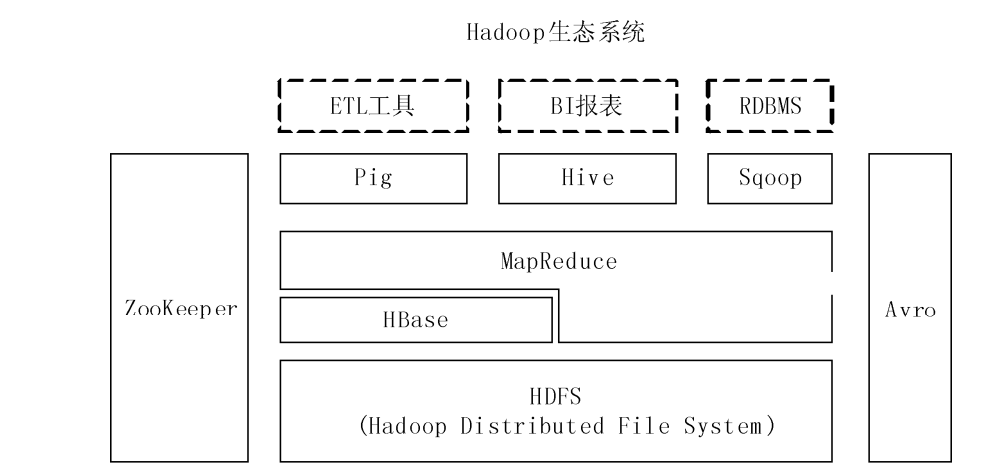
HBase的架构是基于Hadoop生态系统的,它使用HDFS作为底层存储系统;并利用 Hadoop MapReduce来处理 HBase 中的海量数据,实现高性能计算;利用 ZooKeeper 作为协同服务,实现稳定服务和失败恢复。
-
Sqoop 为 HBase 提供了高效、便捷的关系数据库管理系统(Relational DataBase Management System,RDBMS)数据导人功能,Pig 和 Hive为 HBase 提供了高层语言支持。
-
HBase 和 BigTable 的底层技术对应关系
| 项目 | BigTable | HBase |
|---|---|---|
| 文件存储系统 | GFS | HDFS |
| 海量数据处理 | MapReduce | Hadoop |
| 协同服务管理 | Chubby | ZooKeeper |
二 HBase 访问接口简介
- HBase 提供了 Native Java API、HBase Shell、Thrift Gateway、REST Gateway、Pig、Hive 等多种访问方式
| 类型 | 特点 | 使用场合 |
|---|---|---|
| Native Java API | 常规和高效的访问方式 | 适合 Hadoop MapReduce 作业并行批处理 HBase 表数据 |
| HBase Shell | HBase 的命令行工具,最简单的接口 | 适合 HBase 管理 |
| Thrift Gateway | 利用 Thrift 序列化技术,支持 C++、PHP、Python 等多种语言 | 适合其他异构系统在线访问 HBase 表数据 |
| REST Gateway | 解除语言限制 | 支持 REST 风格的 HTTP API 访问 HBase |
| Pig | 使用 Pig Latin 流式编程语言来处理HBase 中的数据 | 适合数据统计 |
| Hive | 简单 | 以类似 SQL 的方式来访问 HBase |
三 行式&列式存储
- 传统的关系数据库采用的是面向行的存储,被称为“行式数据库”。而HBase 是面向列的存储,也就是说,HBase 是一个“列式数据库”。
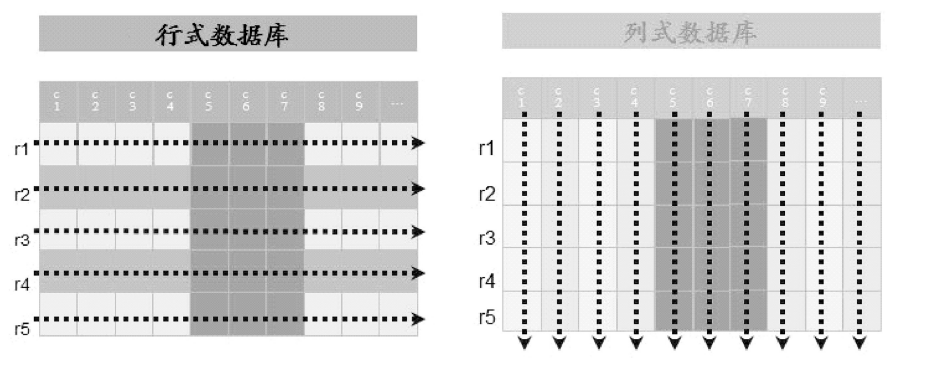
- 行式数据库使用行存储模型(N-ary Storage Model,NSM),一个元组(或行)会被连续地存储在磁盘页中。数据是一行一行被存储的,第一行写入后,再继续写入第二行,以此类推。在读取数据时,需要顺序扫描每个元组的完整内容,然后从每个元组中筛选出查询所需要的属性。如果每个元组只有少量属性的值对于查询是有用的,那么 NSM 就会浪费许多磁盘空间和内存带宽。
- 列式数据库采用列存储模型(Decomposition Storage Model,DSM),目的是最小化无用的 I/O。DSM 采用不同于 NSM 的思路,对于采用 DSM 的关系数据库,DSM会对关系进行垂直分解,并为每个属性分配一个子关系。因此,一个具有 n 个属性的关系会被分解成 n 个子关系,每个子关系单独存储,每个子关系只有当其相应的属性被请求时才会被访问。
- DSM 以关系数据库中的属性或列为单位进行存储,关系中多个元组的同一属性值(或同一列值)会被存储在一起,而一个元组中不同属性值通常会被分别存放于不同的磁盘页中。
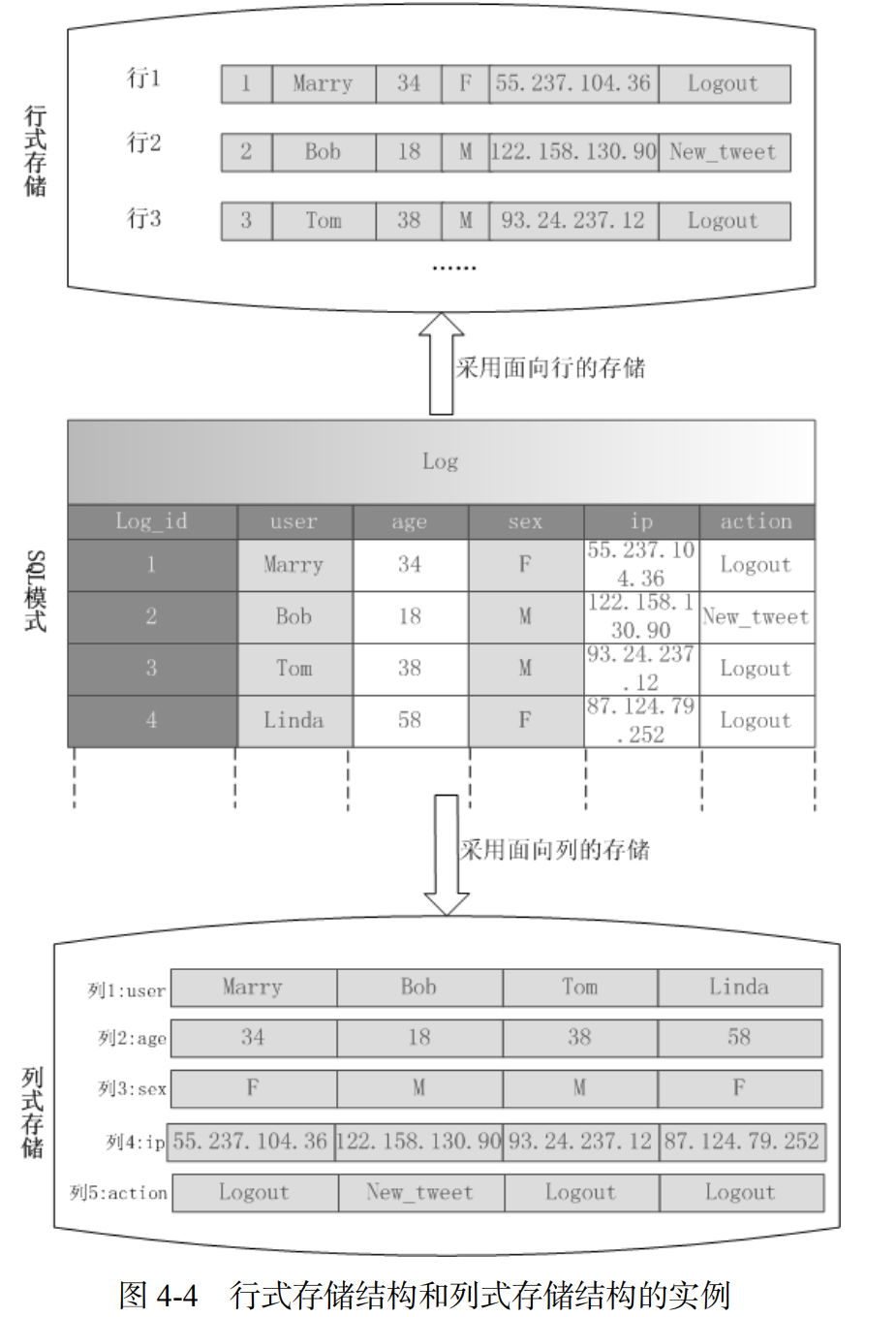
- 行式数据库主要适合小批量的数据处理,如联机事务型数据处理, Oracle 和MySQL 等关系数据库都属于行式数据库。
- 列式数据库主要适合批量数据处理和即席查询(Ad-Hoc Query),用于数据挖掘、决策支持和地理信息系统等查询密集型系统中。
- DSM优点:降低 I/O 开销;支持大量并发用户查询;数据处理速度快;具有较高的数据压缩比
- DSM 的缺陷是:执行连接操作时需要昂贵的元组重构代价。因为一个元组的不同属性被分散到不同磁盘页中存储,当需要一个完整的元组时,就要从多个磁盘页中读取相应字段的值来重新组合得到原来的一个元组。
- 如果严格从关系数据库的角度来看,HBase 并不是一个列式存储的数据库,毕竟HBase 是以列族为单位进行分解的(列族当中可以包含多个列),而不是每个列都单独存储,但是HBase 借鉴和利用了磁盘上的这种列存储格式,所以,从这个角度来说,HBase 可以被视为列式数据库。
四 HBase 数据模型
4.1 HBase 列族数据模型
- HBase 是一个稀疏、多维度、排序的映射表,索引包括行键、列族、列限定符和时间戳。每个值是一个未经解释的字符串,没有数据类型。
- 在表中存储数据,每一行都有一个可排序的行键和任意多的列。表在水平方向由一个或者多个列族组成,一个列族中可以包含任意多个列,同一个列族里面的数据存储在一起。列族支持动态扩展,可以很轻松地添加一个列族或列,无须预先定义列的数量以及类型,所有列均以字符串形式存储,用户需要自行进行数据类型转换。由于同一张表里面的每一行数据都可以有截然不同的列,因此对于整个映射表的每行数据而言,有些列的值是空的,所以说 HBase 是稀疏的。
- HBase执行更新操作时,保留旧版本的数据,同时生成一个新版本的数据。HBase 可以对允许保留的版本的数量进行设置。客户端可以选择获取距离某个时间最近的版本,或者一次获取所有版本。在存储的时候,数据会按照时间戳排序,如果在查询的时候不提供时间戳,会返回最新版本的数据。
- HBase 提供了两种数据版本回收方式:一是保存数据的最后 n 个版本;二是保存最近一段时间内的版本(如最近 7 天)。
4.2 数据模型的相关概念
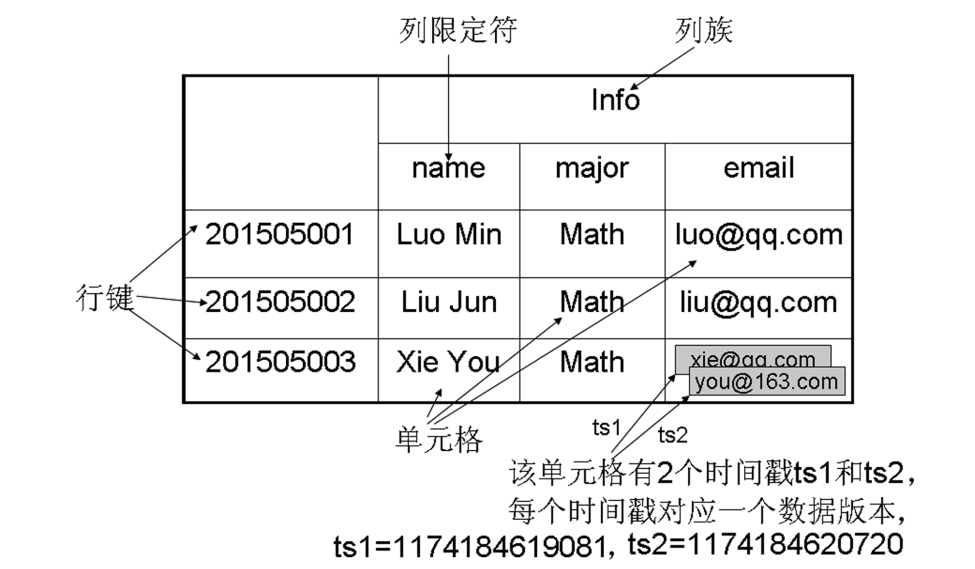
- HBase 实际上就是一个稀疏、多维、持久化存储的映射表,它采用行键(Row Key)、列族(Column Family)、列限定符(Column Qualifier)和时间戳(Timestamp)进行索引,每个值都是未经解释的字节数组 byte[]
- 表:HBase 采用表来组织数据,表由行和列组成,列划分为若干个列族
- 行键:每个 HBase 表都由若干行组成,每个行由行键(Row Key)来标识。
- 访问表中的行只有 3 种方式:通过单个行键访问;通过一个行键的区间来访问;全表扫描。
- 行键可以是任意字符串(最大长度是 64 KB)。在 HBase 内部,行键保存为字节数组。
- 存储时,数据按照行键的字典序存储(将经常一起读取的行存储在一起)
- 列族:一个 HBase 表被分组成许多“列族”的集合,它是基本的访问控制单元
- 列族需要在表创建时就定义好,数量不能太多,而且不能频繁修改
- 存储在一个列族当中的所有数据,通常都属于同一种数据类型(数据具有较高的压缩率)
- 表中的每个列都归属于某个列族,数据可以被存放到列族的某个列下面,但是在把数据存放到这个列族的某个列下面之前,必须首先创建这个列族。在创建完列族以后,就可以使用同一个列族当中的列。列名都以列族作为前缀。例如,courses:history 和 courses:math 这两个列都属于 courses 这个列族
- 列限定符:列族里的数据通过列限定符(或列)来定位。列限定符不用事先定义,也不需要在不同行之间保持一致。列限定符没有数据类型,总被视为字节数组 byte[]
- 单元格 :在 HBase 表中,通过行键、列族和列限定符确定一个“单元格”(Cell)。单元格中存储的数据没有数据类型,总被视为字节数组 byte[]。每个单元格中可以保存一个数据的多个版本,每个版本对应一个不同的时间戳
- 时间戳:每个单元格都保存着同一份数据的多个版本,这些版本采用时间戳进行索引。
- 每次对一个单元格执行操作(新建、修改、删除)时,HBase 都会隐式地自动生成并存储一个时间戳。一个单元格的不同版本根据时间戳降序存储,确保最新的版本可以被最先读取。
4.3 数据坐标
- HBase 使用坐标来定位表中的数据。HBase 中需要根据行键、列族、列限定符和时间戳来确定一个单元格,因此可以视为一个“四维坐标”,即
["行键", "列族", "列限定符", "时间戳"]

五 概念&物理视图
- 在一个 HBase 表的概念视图中,每个行都包含相同的列族,尽管行不需要在每个列族里存储数据.从这个角度来说,HBase表是一个稀疏的映射关系,即里面存在很多空的单元格
- HBase 存储数据的概念视图
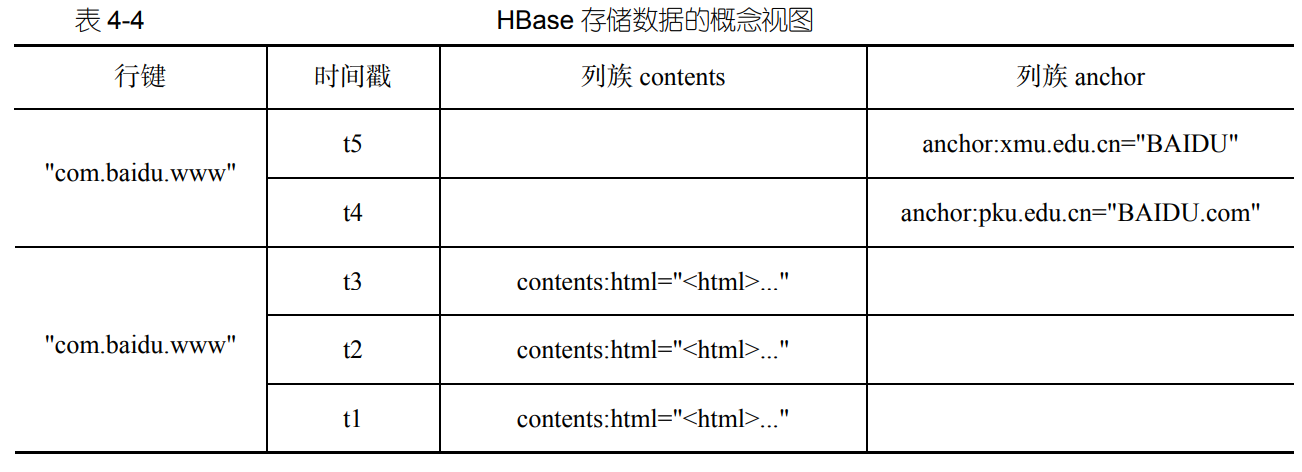
- 物理视图:在物理存储层面,它采用基于列的存储方式,而不是像传统关系数据库那样采用基于行的存储方式。
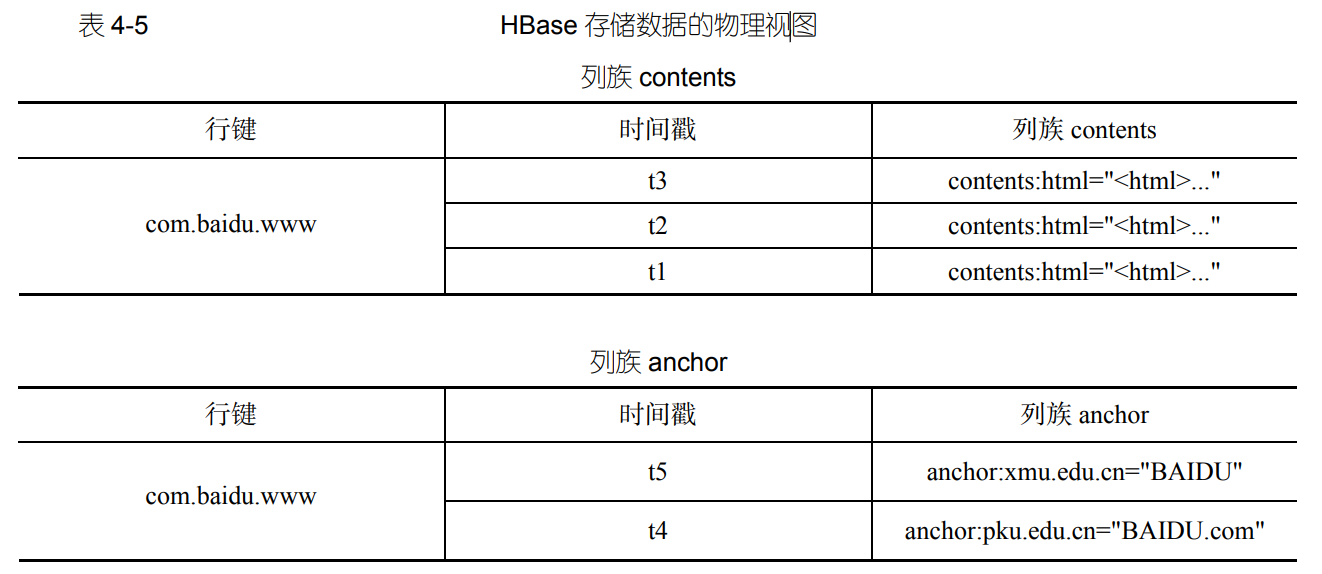
- 表 4-4 的概念视图在物理存储的时候,会存成表 4-5 中的两个小片段。HBase 表会按照 contents 和 anchor 这两个列族分别存放,属于同一个列族的数据保存在一起,同时和每个列族一起存放的还包括行键和时间戳。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 德艺双馨,以“舞”育人——《幼儿舞蹈与创编》课改总结
- SpringBoot实现Websocket聊天交友微信小程序(一)
- 提升思维能力,高效管理信息——推荐使用SimpleMind Pro(思维导图)应用
- 深入浅出Java虚拟机
- SQL语句错误this is incompatible with sql_mode=only_full_group_by解决方法
- 【深度学习-目标检测】01 - R-CNN 论文学习与总结
- Vue 3 中的 watch 函数:实战指南
- 第十二章Session
- 简便实用:在 ASP.NET Core 中实现 PDF 的加载与显示
- 《WebKit 技术内幕》之六(3): CSS解释器和样式布局