P20类神经网络训练不起来怎么办?- 批次和动量
发布时间:2023年12月17日
- 什么是batch
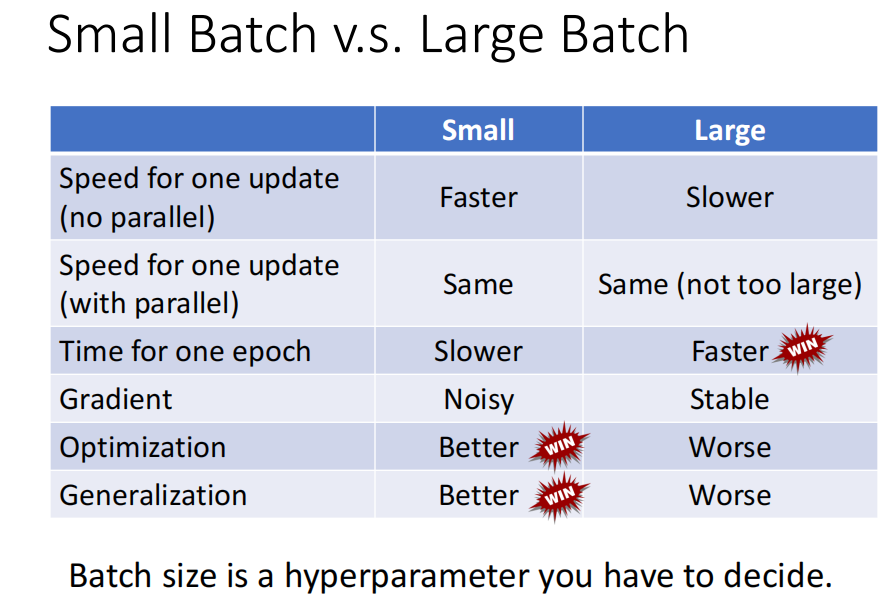
- small batch 和 large batch 的比较 : large batch 更快,small batch 在训练集和测试集上效果效果更好
- 动量的意义和作用: 类似于物理上多了一点惯性,防止困在鞍点。 动量是之前所有梯度的加权和。
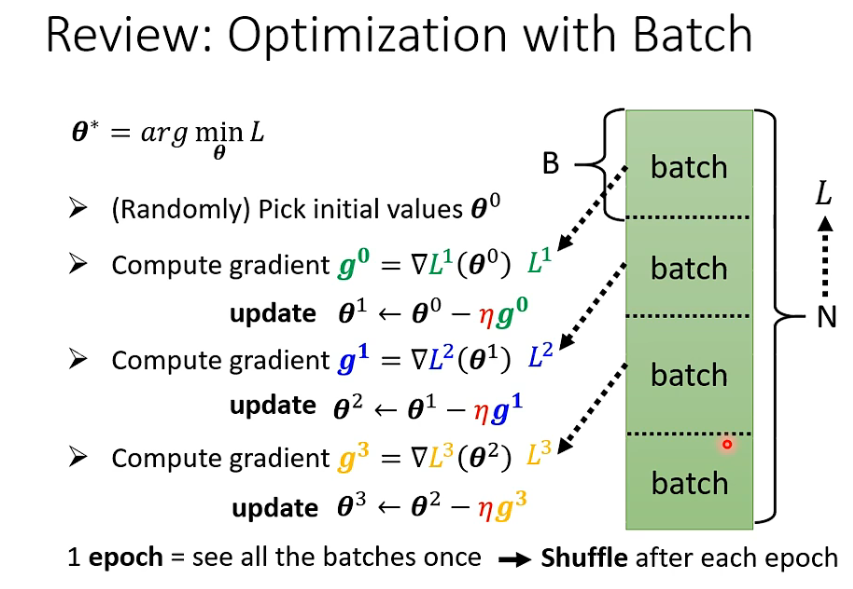
1. batch 是什么
没一轮epoch 都会分batch , 每次batch 都不一样— shuffle
2. 为什么training 时要batch
batch 给training 带来了什么帮助?
如 batch = 20 和 batch_size =1
前者看完20个资料后更新参数
后者每看完一笔参数后,就更新参数。 只看一笔参数就更新参数的话,noise 更多,参数更新更加曲曲折折。
针对这个看起来:
- 前者冷却时间长,准
- 后者蓄力时间段,不准
cpu :
gpu 上并行计算:

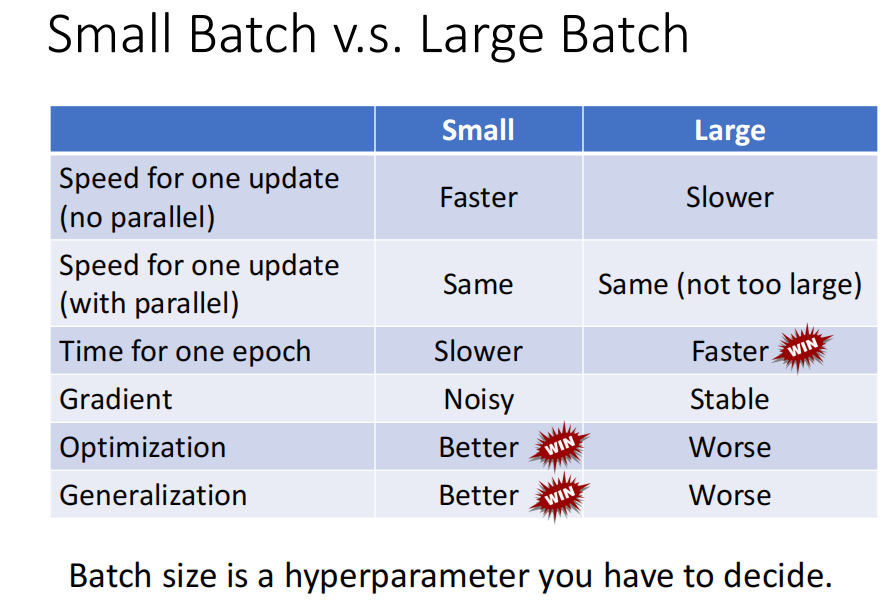
Small Batch vs. Large Batch
然而,当考虑到 并行运行时, larger batch 不一定运行的时间更长.
当使用gpu 并行计算时,时间可能会变短。
但是,batch 也不能非常大, 太大的话 ,计算时间会增加很多
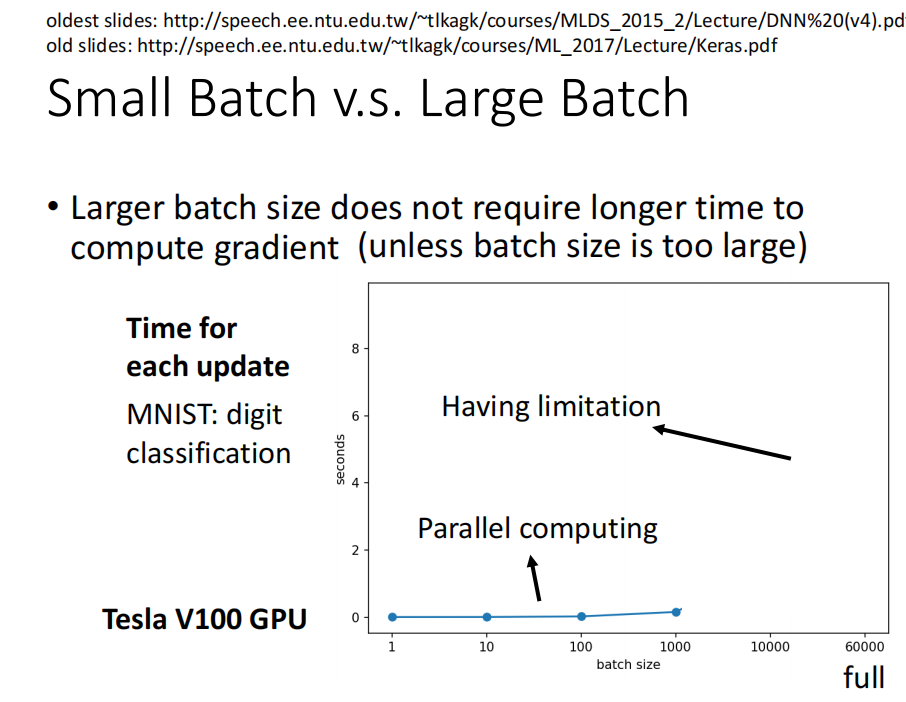
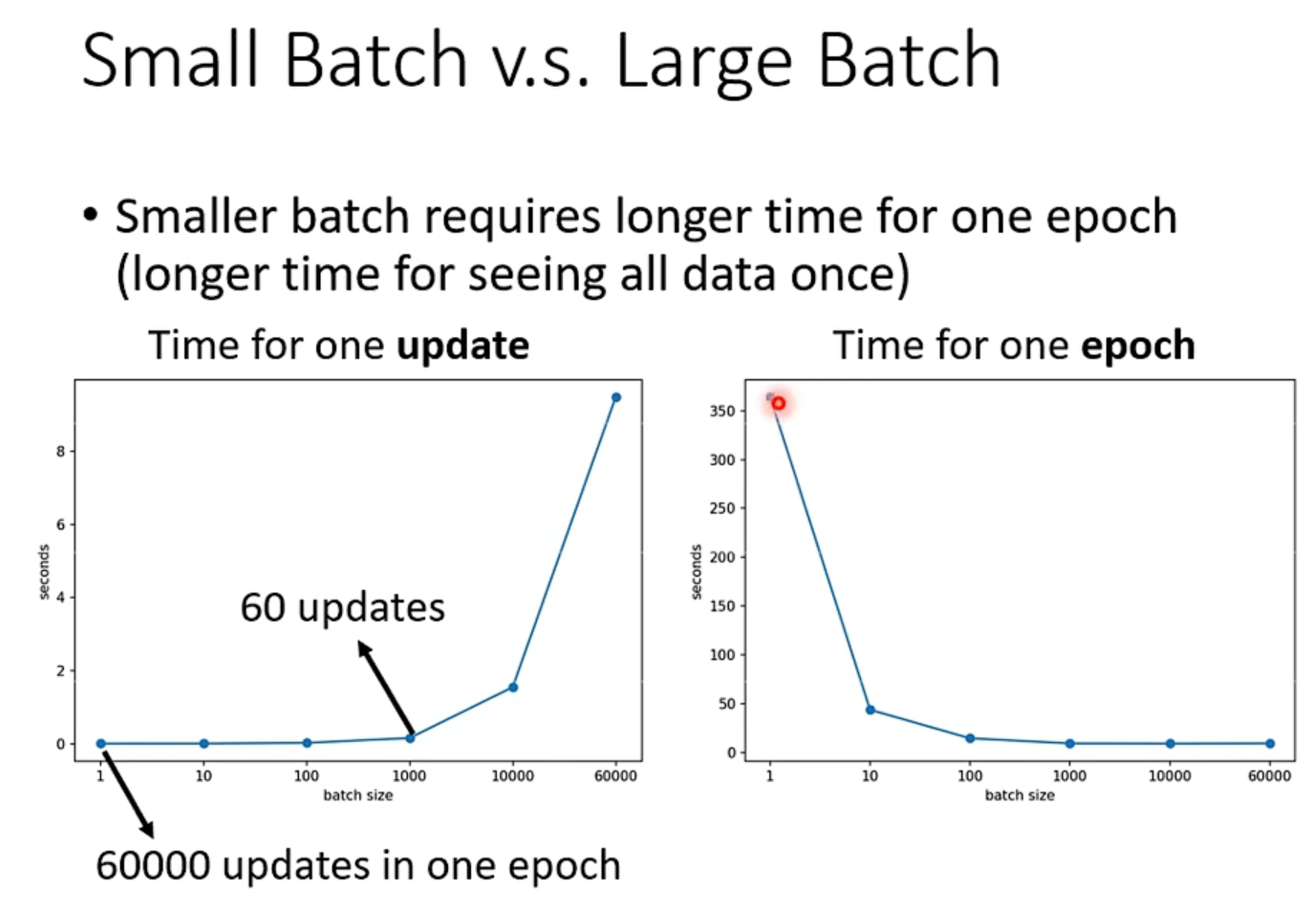
- batch_size 和 epoch 运行时间比较
对正确率的影响
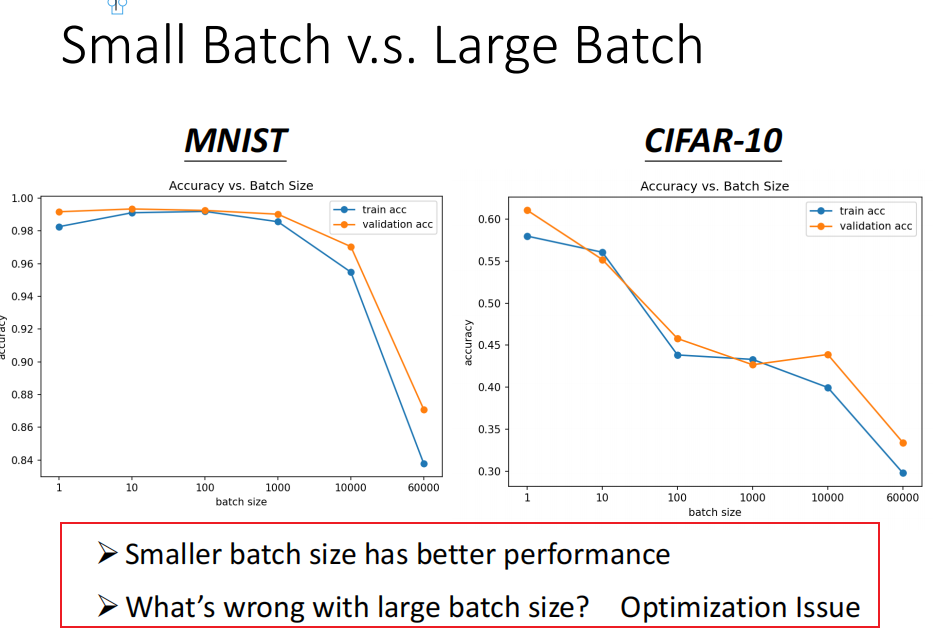
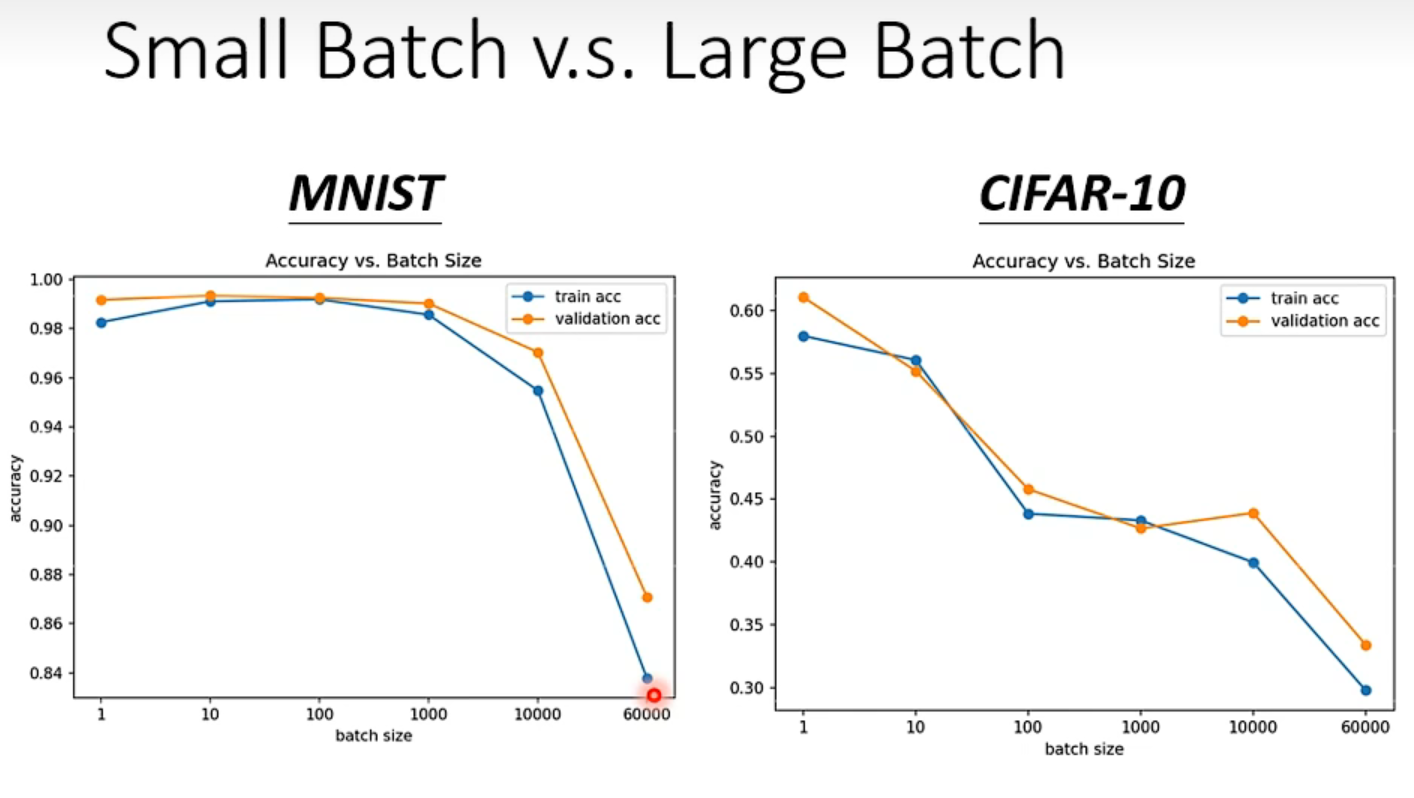
问题: batch_size 越大,正确率越低在这里插入图片描述
{kind=link}
-
small batch 正确率更高
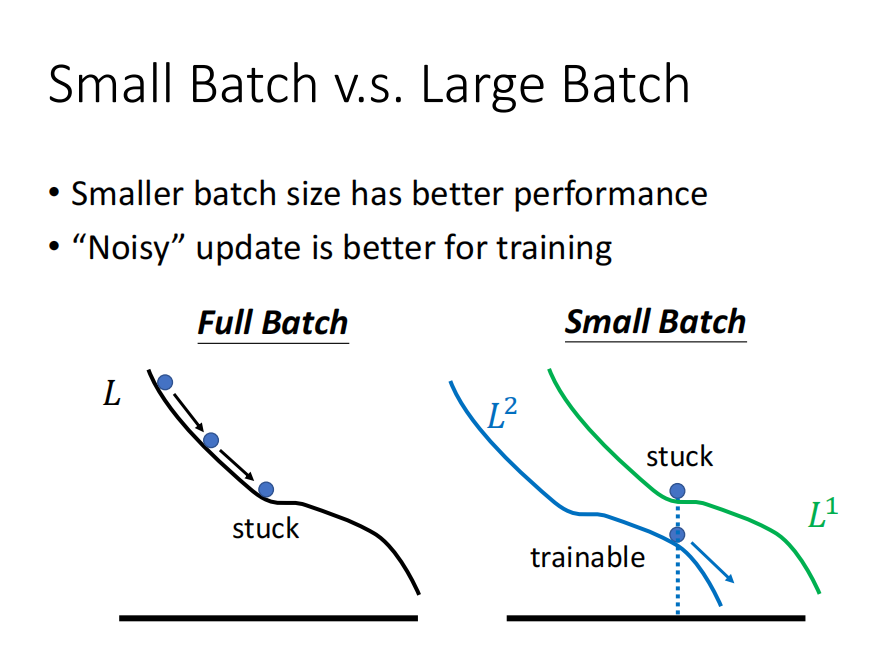
使用small batch 时,训练更不容易陷入局部最优。 -
testing 时 small_batch 的结果更好
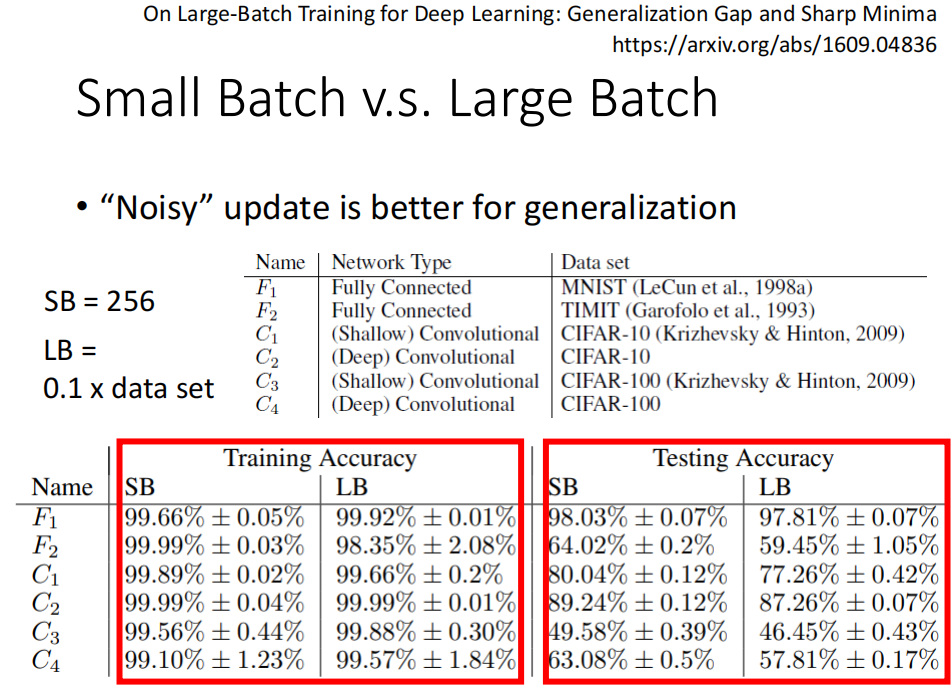
总结
Momentum 动量
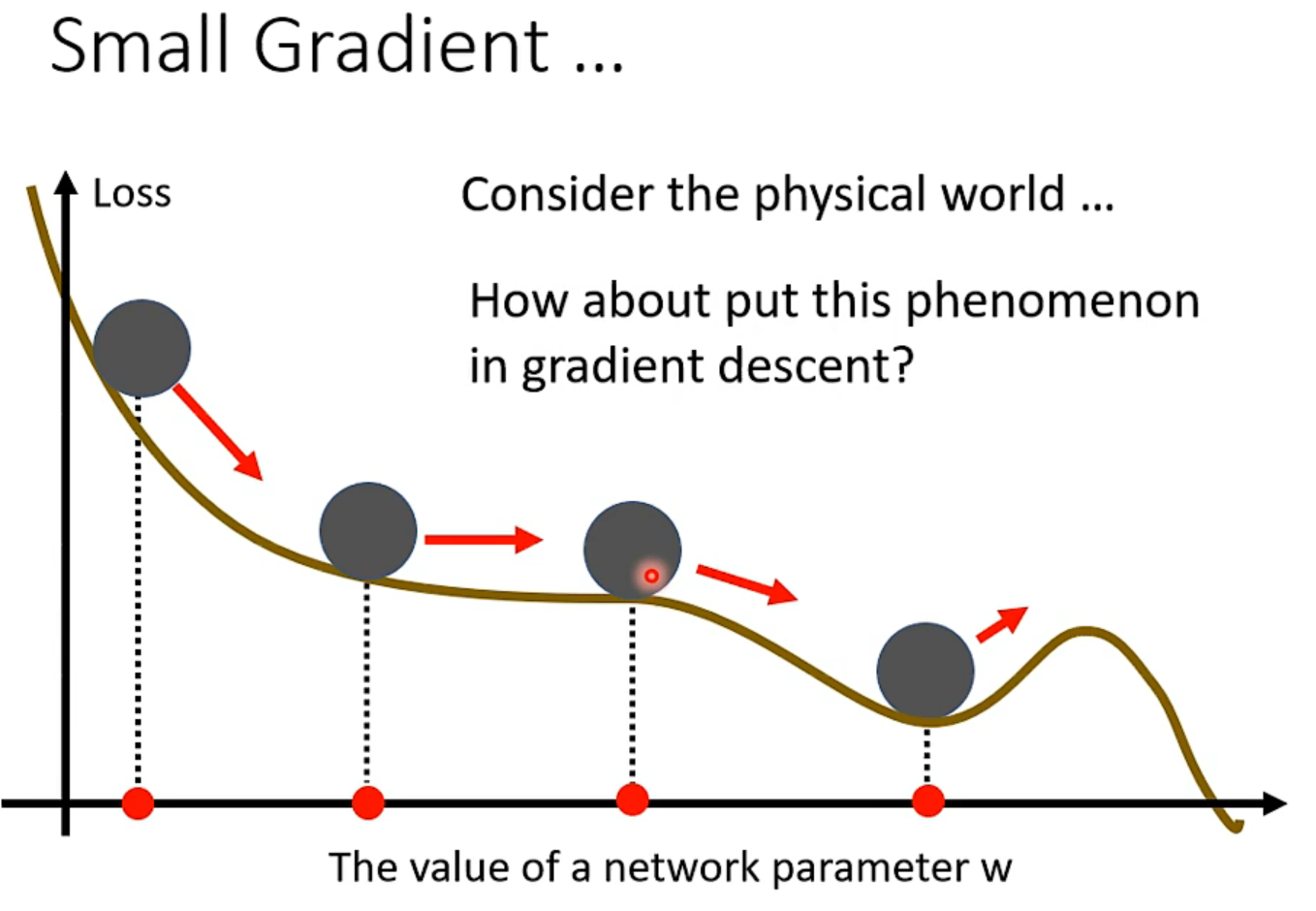
从物理角度,有动量的话,不会停留在鞍点处
一般的梯度
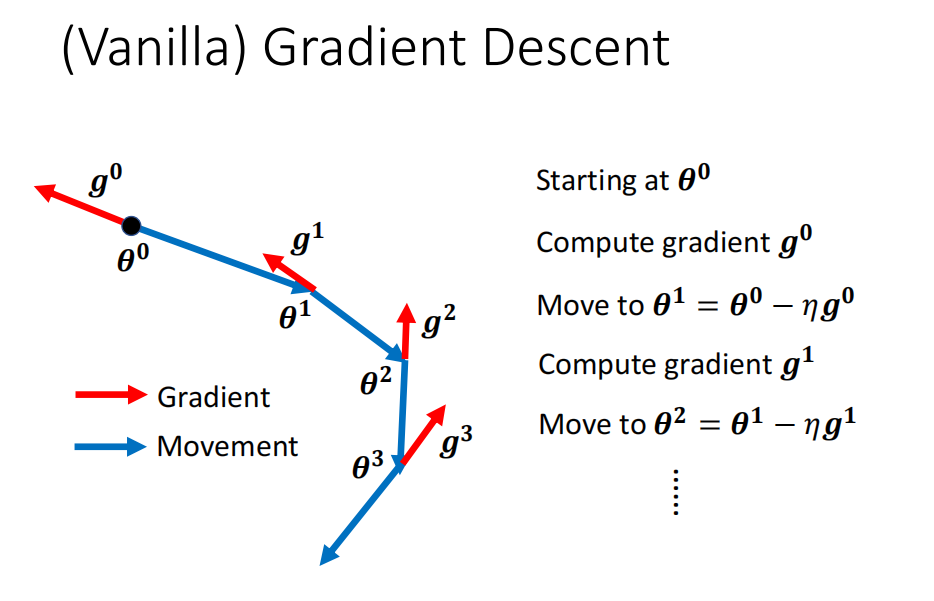
往梯度反方向前进
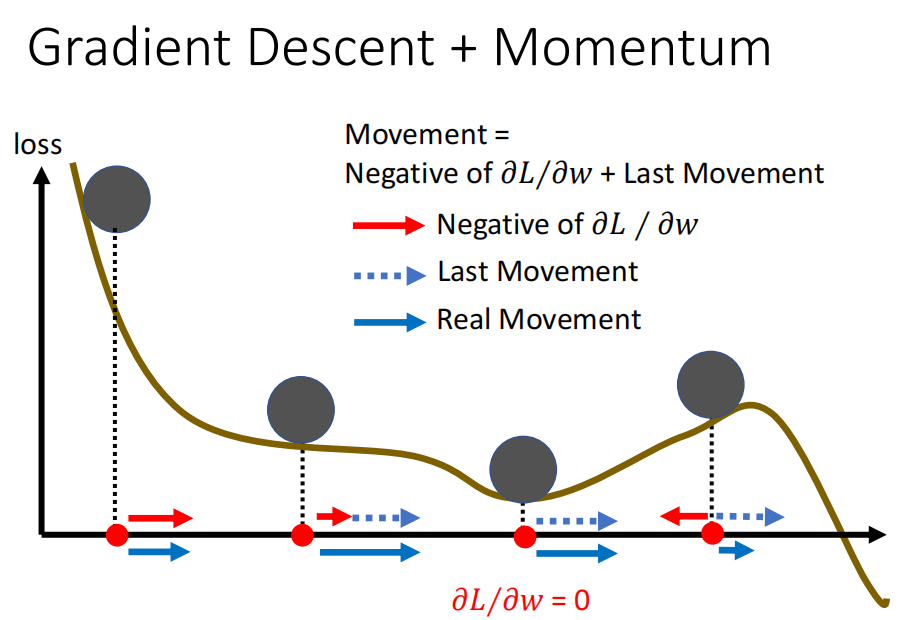
Gradient Descent+ Momemt
m 是过去所有 gradient 的加权总和

momvent 比纯粹gd 多往前走一点
文章来源:https://blog.csdn.net/weixin_39107270/article/details/134998618
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 老式白炽灯护眼吗?适合备考使用的台灯推荐
- JFlash工具将多个Bin文件或hex文件合并成一个(app+bootloader)
- 抖店需要找货源吗?没有货源怎么找?团队实操经验分享!
- 如何在Ubuntu搭建Emlog博客站点并发布至公网可随时远程访问管理界面——“cpolar内网穿透”
- C++ 二进制图片的读取和blob插入mysql_stmt_init—新年第一课
- 29. 事件监听
- 记一次java for循环改造多线程的操作
- ssm开发的Java快递代拿系统----计算机毕业设计
- Ansible剧本playbooks
- 热过载继电器 WJJL1-05/2X AC220V 0.5A-5A 导轨安装 JOSEF约瑟