Transformer的学习
文章目录
Transformer
1.了解Seq2Seq任务
NLP 的问题,都可以看做是 QA(Question Answering)的问题,QA 的问题可以看做是 Sequence to Sequence 的问题。
Sequence to Sequence 是一个常见的任务类型,例如:语音识别、语音翻译(语音辨识)、机器翻译、Chatbot、Text-to-Speech (TTS) Synthesis(文本到语音合成)、语法分析、多标签分类、目标检测等等。


Sequence to Sequence 任务可以由各种序列模型执行,其中 RNN 模型是经典的用于序列数据的模型,而随着 Transformer 的出现和成功,它已经在许多序列任务中取代了传统的RNN架构。
Transformer 实际上就是一个关于 Seq2Seq 的 model
2.Transformer 整体架构

整体架构分为两部分:Encoder 与 Decoder
3.Encoder的运作方式
Encoder 做的就是输入一个Vector sequence,输出一个Vector sequence.
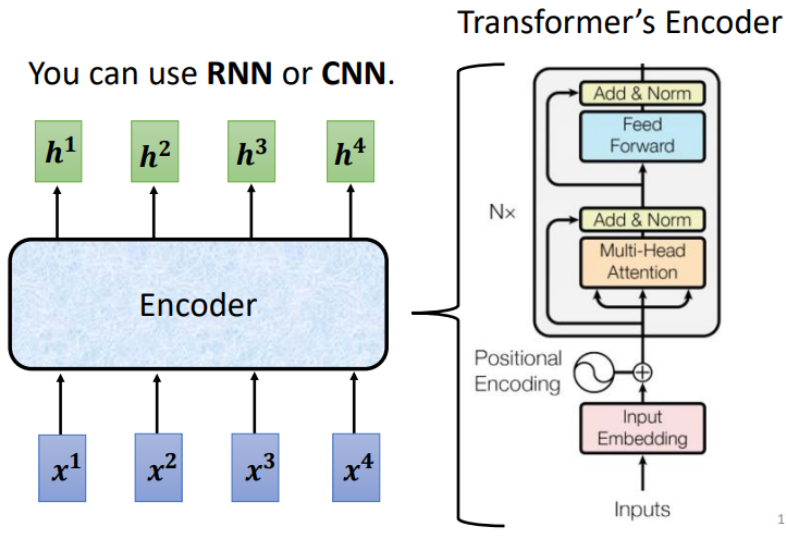
Encoder的运作方式如下所示:
Encoder 里面是由多个 Block 组成的,经过多个 Block 的堆叠,最后得到一个Vector sequence.
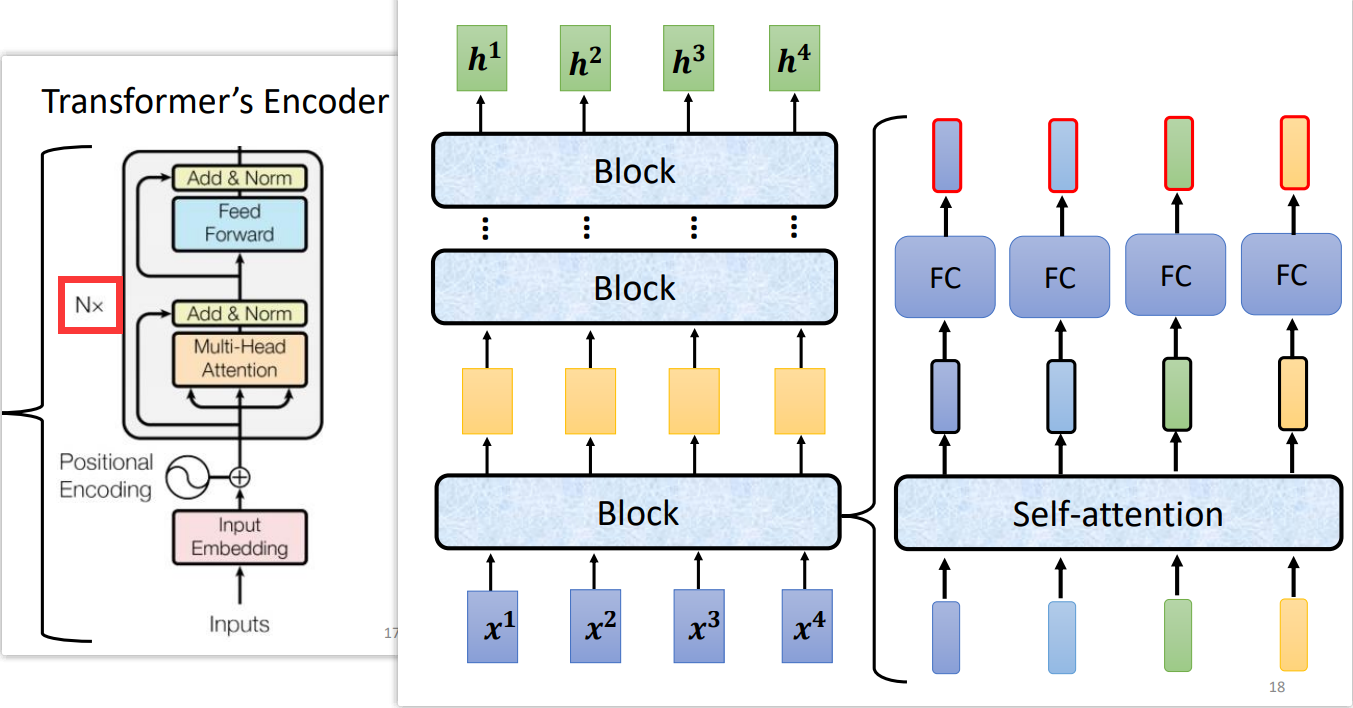
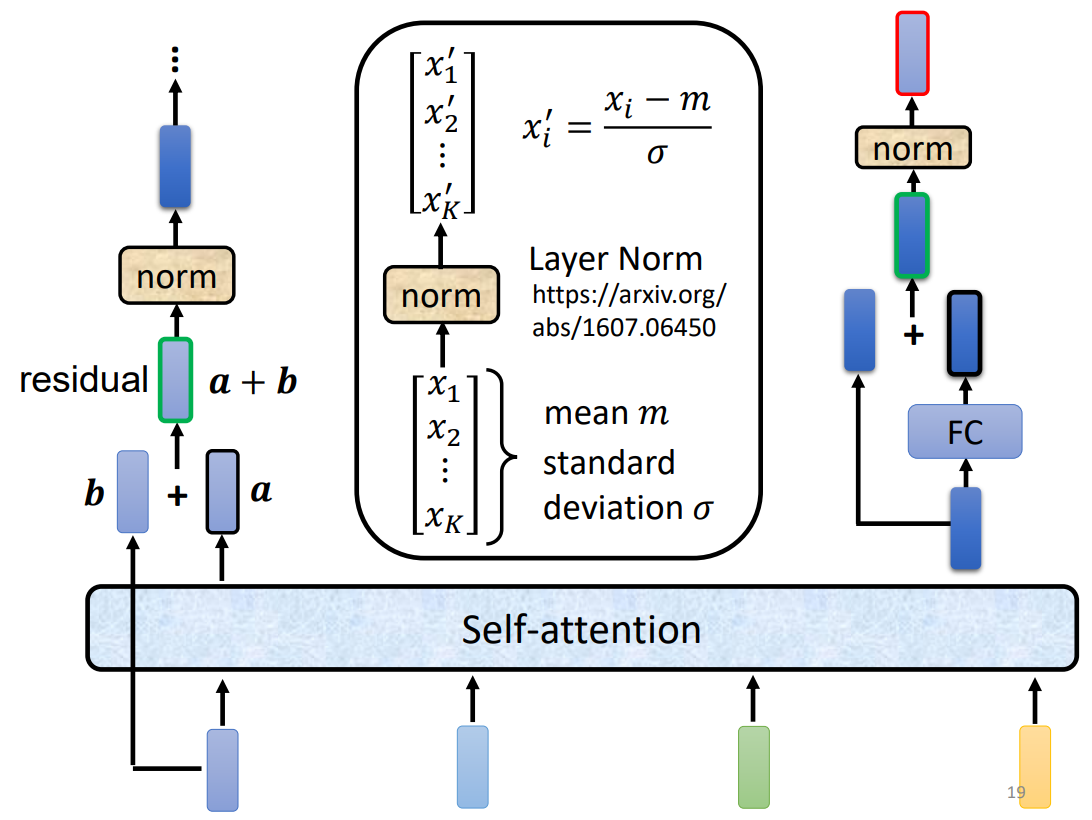
每个 Block 所做的事情如下:对于输入的每一个 Vector sequence,首先通过 Multi-Head Attention 得到输出 a a a,然后通过残差连接得到 a + b a+b a+b,之后通过 Layer Norm 得到正则化后的Vector sequence,接着送到 Fully Connection layer,同样使用残差连接并使用 Layer Norm 得到 Encoder 的输出。
4.Decoder的运作方式
Decoder 可以分为:Decoder-Autoregressive(AT) 与 Decoder-Non-autoregressive(NAT),在transformer中使用的是 Decoder-Autoressive.
Decoder 做了什么?
- Decoder 部分首先输入一个 START,经过 Decoder 并且使用 Softmax 就会得到一个概率分布,然后对这个概率分布使用 max 得到概率最大的那个值(也就是one-hot编码)。

- 紧接着,将得到的输出作为输入,送入 Decoder ,不断的迭代这个过程,就得到了最后的输出。

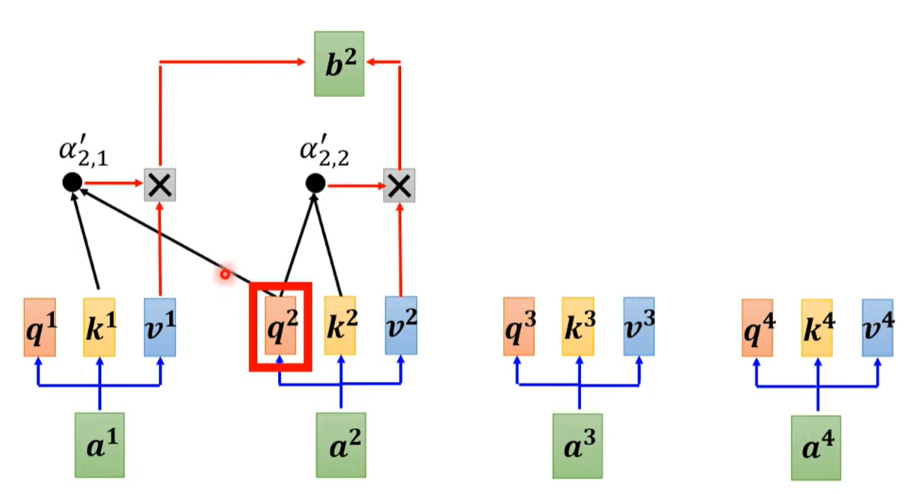
在 Decoder 中用了一个 Masked Multi-Head Attention.

Masked Self-atttention 每次一个 vector 在输出的时候,不可以看右边的部分,也就是说在产生 b 1 b^1 b1 的时候不能在考虑 a 2 , a 3 , a 4 a^2,a^3,a^4 a2,a3,a4,产生 b 2 b^2 b2 的时候不能考虑 a 3 , a 4 a^3,a^4 a3,a4,产生 b 3 b^3 b3 的时候不能考虑 a 4 a^4 a4 ,产生 b 4 b^4 b4 的时候就可以考虑全部的信息了。

具体细节如下图所示:
目前的这个 Decoder 运作机制不知道它应该什么时候停下来。

为了让其停下来,所以要有一个END的标记。

通过这个 END 的标记来让模型停下来。
5.AT 与 NAT
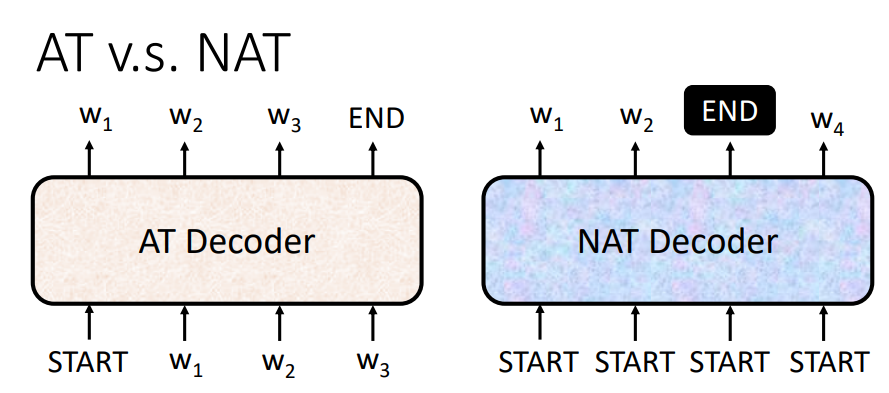
AT Decoder 传入的是一个 START,然后一个一个的进行输出。NAT Decoder 直接传入多个 START,同时输出。
NAT好处:平行化,一个步骤产生出完整的句子,可以控制输出的长度。(怎么控制?可能会有一个 classifier 来决定输出的长度;或者输入很多个 START,那么就会输出很多个输出,忽略 END 之后的输出)
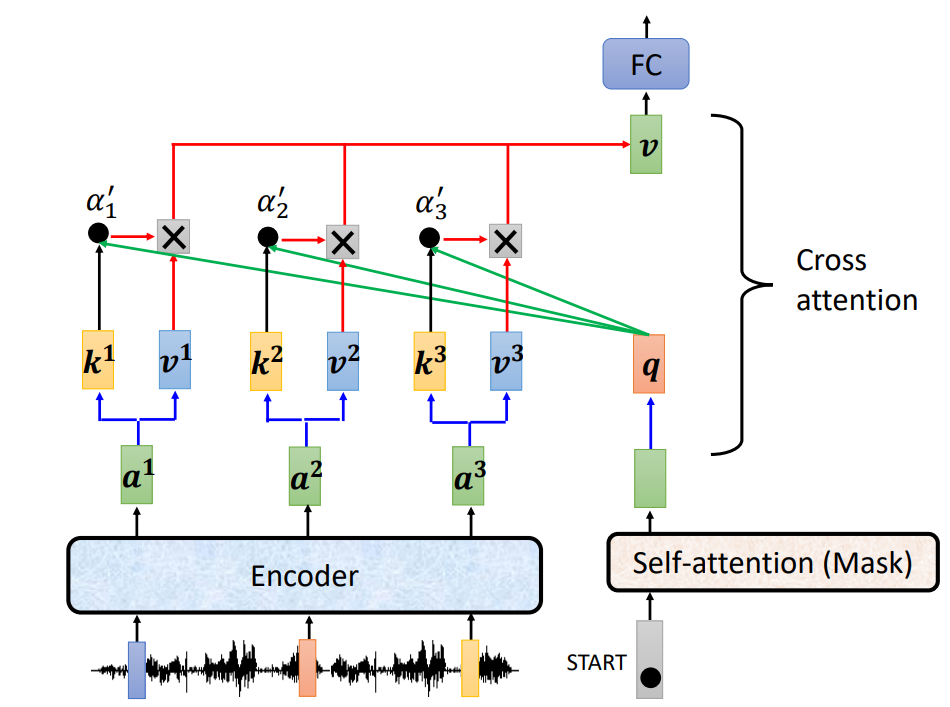
6.Encoder 和 Decoder 之间的互动

Encoder 和 Decoder 之间的互动是通过 Cross attention 机制进行互动的。主要过程就是将 Decoder 中通过第一个 Masked Multi-Head Attention 以及 Add 与 Norm 后的 vector sequence 与 encoder 输出中的所有 vector sequence 进行 qkv 的计算。计算流程见下图:
①第一个输出的计算
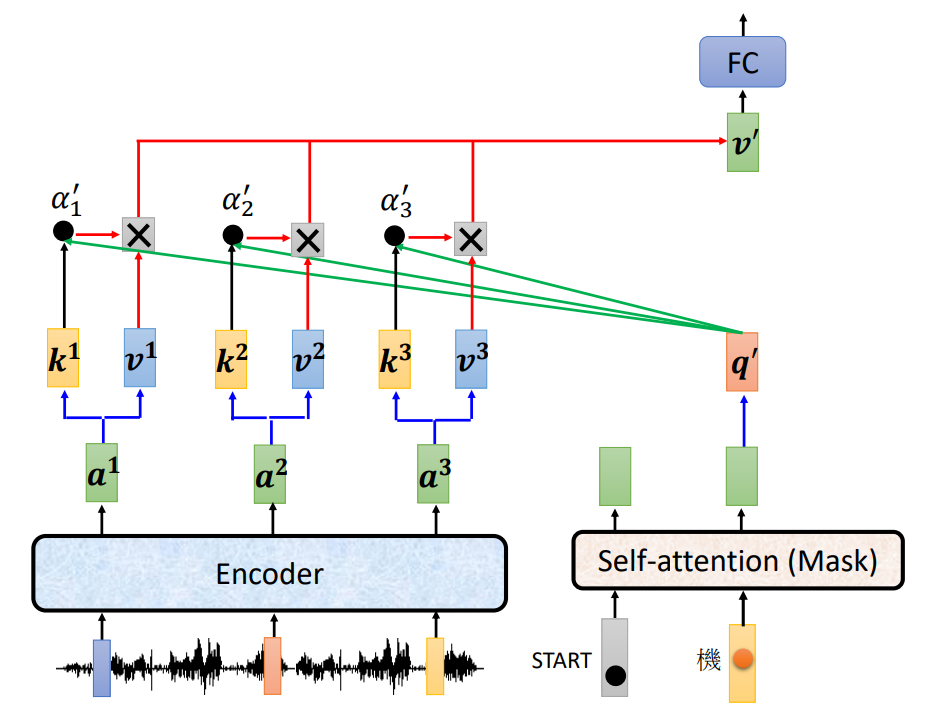
②第二个输出的计算
7.Training
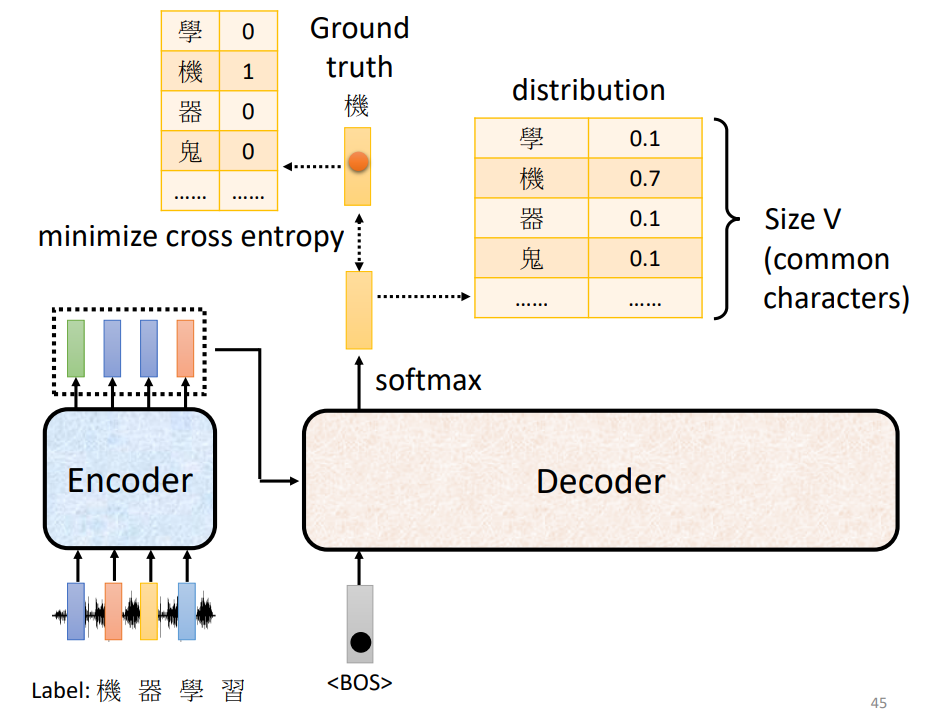
在decoder输入的时候,要输入正确的答案(Teacher Forcing技术,使用真实的标签作为输入)
把正确答案 Ground truth 给模型,让其与 distribution 进行 cross entropy,每一个输出有一个cross entropy,将这些 cross entropy 求和,进行梯度下降,求解最好的参数,希望 decoder 的输出跟正确答案越接近越好。
参考链接:
【强烈推荐!台大李宏毅自注意力机制和Transformer详解!】 https://www.bilibili.com/video/BV1v3411r78R/?p=3&share_source=copy_web&vd_source=a36f62f9fcd2efea97449039538032fa
😃😃😃
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 家庭在线记账理财管理系统PHP源码,附带系统安装教程
- R语言【paleobioDB】——pbdb_temporal_resolution():展示化石数据的时空分辨率
- 实时云渲染服务:流式传输 VR 和 AR 内容
- stable diffusion和midjourney怎么选?
- 6-183 Delete node from singly liked list
- 别再羡慕别人高薪!拥有CISSP证书,你也可以!
- 红队视角下的AWS横向移动
- Vue-32、Vue单文件组件
- 【大数据面试】Kafka面试题与答案
- 系列一、Spring Security基本概念