k8s搭建(四、k8s集群创建)
天行健,君子以自强不息;地势坤,君子以厚德载物。
每个人都有惰性,但不断学习是好好生活的根本,共勉!
文章均为学习整理笔记,分享记录为主,如有错误请指正,共同学习进步。
文章目录
k8s搭建文章:
k8s搭建(一、k8s环境配置与docker安装)
k8s搭建(二、k8s组件安装)
k8s搭建(三、k8s从节点创建)
k8s搭建(四、k8s集群创建)
k8s搭建(五、k8s可视化管理工具Dashboard配置)
k8s集群创建
1. putty连接虚拟机
putty连接服务器指南
开启之前配置好的三台虚拟机
使用putty连接三台虚拟机,在putty窗口进行操作
2. 初始化
在主节点K8S-MASTER上操作
2.1 查看kubernetes版本信息
这里用命令查看
kubectl version
输出的信息中包含版本信息

版本号为1.22.9
2.2 执行初始化命令
sudo kubeadm init \
--kubernetes-version=v1.22.9 \
--image-repository registry.aliyuncs.com/google_containers \
--pod-network-cidr=10.24.0.0/16 \
--ignore-preflight-errors=Swap
参数解释:
--image-repository string 指定从什么位置来拉取镜像(1.13版本才有的)
默认值是k8s.gcr.io,改为国内镜像地址:registry.aliyuncs.com/google_containers
–kubernetes-version string: 指定kubenets版本号
–pod-network-cidr 指定 Pod 网络的范围。
Kubernetes 支持多种网络方案,而且不同网络方案对 –pod-network-cidr有自己的要求,这里设置为10.244.0.0/16 是因为我们将使用 flannel 网络方案,必须设置成这个 CIDR。(说明在集群中将会使用10.244.0.0这个网段下面的所有ip地址,比如将tomcat部署在10.244.144.198这个地址,然后再master节点使用curl 10.244.144.198就可以返回tomcat的界面)
--ignore-preflight-errors=all 忽略预检报错内容,指定所有(自己猜的)
注:kubeadm 不支持将没有 --control-plane-endpoint 参数的单个控制平面集群转换为高可用性集群。
这里有个地方我记录一下
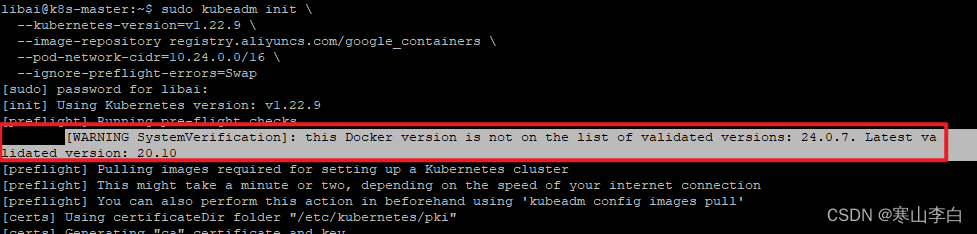
初始化开始的时候会提示一个警告信息如下
[警告系统验证]:此Docker版本不在已验证版本列表中:24.0.7。最新验证版本:20.10
因为安装的docker是最新版本,而安装的kube版本为旧版本1.22.9,所以可能有点小问题,但是他是警告不是报错,所以暂时不管他
初始化完成后,出现类似如下内容,表示初始化成功
......
......
......
此处省略若干行
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.193.128:6443 --token 1cd07a.h2z8wrgngllonwjt \
--discovery-token-ca-cert-hash sha256:0cc0df38925079b35a0e45e0c43f50f62dc7b3aad2e8414177a18f613c44c9fb
libai@k8s-master:~$
截图如下
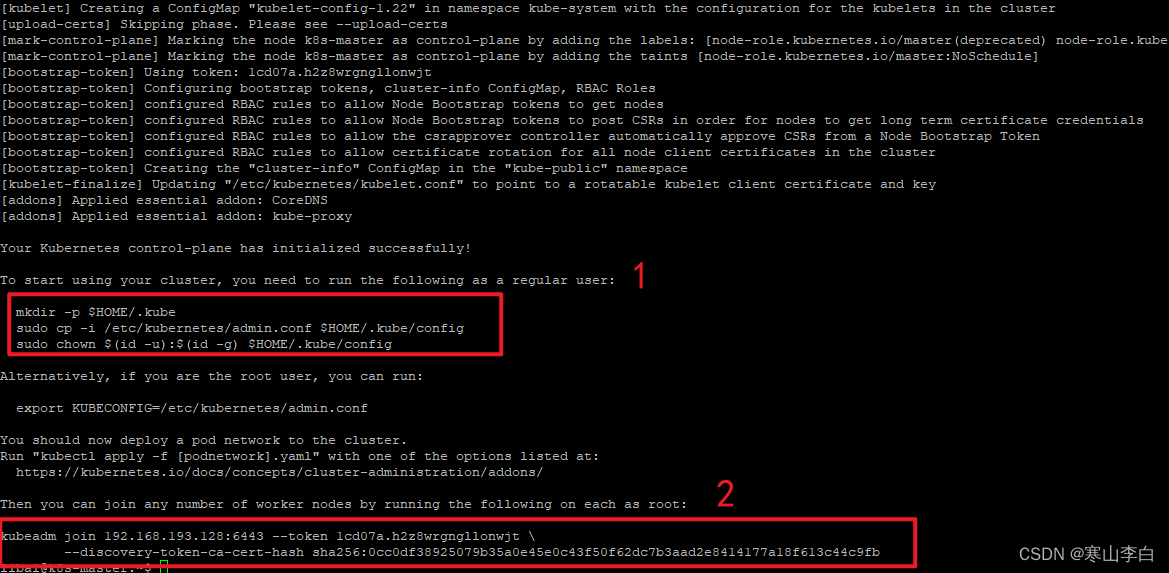
仔细阅读初始化成功后的输出信息,也就是上面这部分内容(可以将两个红框中的命令鼠标左键选中后右键粘贴出来,备用)
1的位置大致就是说你想要用你的集群的话,就必须以非root用户来执行红框里的mkdir等三个命令
2的位置就是说你想要别的节点加入集群就执行红框里的kubeadm join命令就行(该命令一定要复制下来记住,待会加入节点要用,当然,忘了也没关系,可以重新生成新的)
具体操作请跳到第2.5小节开始
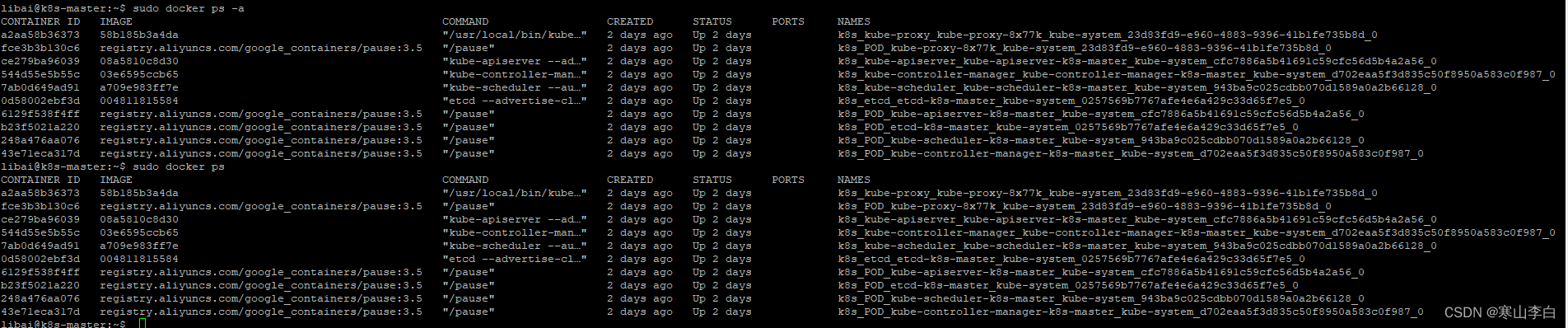
后续发现初始化完成后在docker中也有体现,使用docker命令查看容器,可发现有以下这些容器正在运行
sudo docker ps
输出如下,都是跟k8s相关的容器
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
a2aa58b36373 58b185b3a4da "/usr/local/bin/kube…" 2 days ago Up 2 days k8s_kube-proxy_kube-proxy-8x77k_kube-system_23d83fd9-e960-4883-9396-41b1fe735b8d_0
fce3b3b130c6 registry.aliyuncs.com/google_containers/pause:3.5 "/pause" 2 days ago Up 2 days k8s_POD_kube-proxy-8x77k_kube-system_23d83fd9-e960-4883-9396-41b1fe735b8d_0
ce279ba96039 08a5810c8d30 "kube-apiserver --ad…" 2 days ago Up 2 days k8s_kube-apiserver_kube-apiserver-k8s-master_kube-system_cfc7886a5b41691c59cfc56d5b4a2a56_0
544d55e5b55c 03e6595ccb65 "kube-controller-man…" 2 days ago Up 2 days k8s_kube-controller-manager_kube-controller-manager-k8s-master_kube-system_d702eaa5f3d835c50f8950a583c0f987_0
7ab0d649ad91 a709e983ff7e "kube-scheduler --au…" 2 days ago Up 2 days k8s_kube-scheduler_kube-scheduler-k8s-master_kube-system_943ba9c025cdbb070d1589a0a2b66128_0
0d58002ebf3d 004811815584 "etcd --advertise-cl…" 2 days ago Up 2 days k8s_etcd_etcd-k8s-master_kube-system_0257569b7767afe4e6a429c33d65f7e5_0
6129f538f4ff registry.aliyuncs.com/google_containers/pause:3.5 "/pause" 2 days ago Up 2 days k8s_POD_kube-apiserver-k8s-master_kube-system_cfc7886a5b41691c59cfc56d5b4a2a56_0
b23f5021a220 registry.aliyuncs.com/google_containers/pause:3.5 "/pause" 2 days ago Up 2 days k8s_POD_etcd-k8s-master_kube-system_0257569b7767afe4e6a429c33d65f7e5_0
248a476aa076 registry.aliyuncs.com/google_containers/pause:3.5 "/pause" 2 days ago Up 2 days k8s_POD_kube-scheduler-k8s-master_kube-system_943ba9c025cdbb070d1589a0a2b66128_0
43e71eca317d registry.aliyuncs.com/google_containers/pause:3.5 "/pause" 2 days ago Up 2 days k8s_POD_kube-controller-manager-k8s-master_kube-system_d702eaa5f3d835c50f8950a583c0f987_0
2.4 报错处理(无报错可以跳过此步)
2.4.1 报错排查
如果初始化报错,则需要排查问题
问题大概有以下几个方面,可以参考并尝试
版本小于1.24.0
确认下载的kubelet、kubeadm、kubectl的版本小于1.24.0的,因为从1.24.0开始kube移除了docker作为容器运行时的功能,需要单独安装containerd并开启containerd的运行时功能ufw inactive(dead)
防火墙确认关闭
检查状态命令为systemctl status ufw
先执行关闭命令为sudo stop ufw然后禁用systemctl ufw disableswap off
交换内存确认关闭
查看命令cat /etc/fstab
先执行 临时关闭命令sudo swapoff -a
再执行永久关闭命令sudo vim /etc/fstab,注释掉swap那行cgroup systemd
cgroup管理器确认已修改为systemd
查看命令cat /etc/docker/daemon.json
如果没有如下exec-opts的systemd设置参数,则用vim命令添加
{
"exec-opts":[
"native.cgroupdriver=systemd"
],
“registry-mirrors”:["https://vj4iipoo.mirror.aliyuncs.com"]
}
exec-opts为cgroup管理器的指定参数设置
registry-mirrors为镜像加速地址(请设置自己的)
2.4.2 重置adm
报错排查完之后,需要重置adm后才能再次进行初始化,执行两个命令如下
重置adm
sudo kubeadm reset
删除相关文件
sudo rm -fr ~/.kube/ /etc/kubernetes/* var/lib/etcd/*
3. 配置.kube
根据初始化完成后输出信息的命令进行操作如下
创建.kube文件夹
sudo mkdir -p $HOME/.kube
将admin.conf文件内容复制到.kube的config文件中
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
将文件的所有权限从文件所有者修改到到所有者所在的组的其他用户(user->group)
sudo chown $(id -u):$(id -g) $HOME/.kube/config

4. calico网络配置
calico介绍参考:k8s之calico网络
calico是pod之间实现互连的网络技术,因为每个pod之间需要实现隔离,有需要互连,有别的方案,但是他们都有些弊端
calico是专门为适应容器环境来设计的,目前的最优选
部署一个pod网络到集群中
以下配置calico的两种方式二选一,推荐第一种
4.1 calico网络配置简单命令(推荐)
获取calico.yaml文件资源
curl https://raw.githubusercontent.com/projectcalico/calico/v3.26.1/manifests/calico.yaml -O

应用到kubectl中
sudo kubectl apply -f calico.yaml
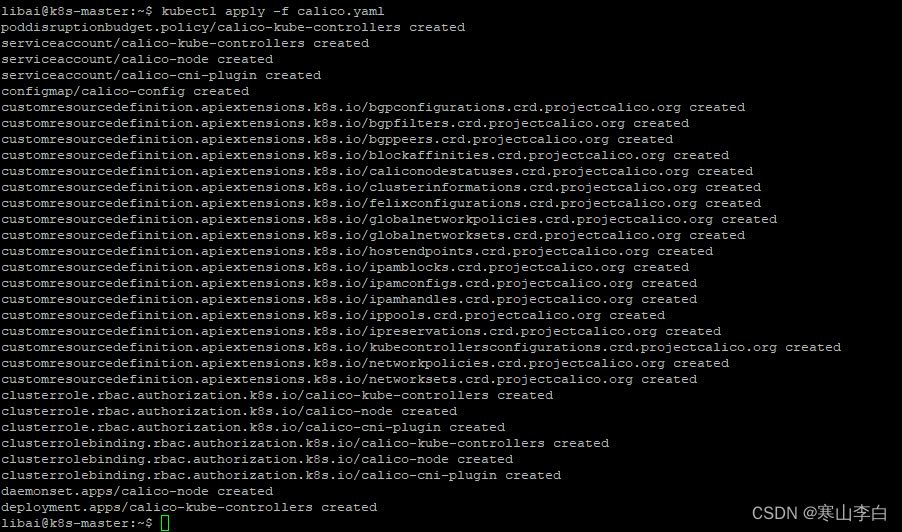
4.2 根据calico官网命令配置(不一定好用,但可一试)
直接跳转到Quickstart for Calico on Kubernetes进行安装calico
或者根据以下指示去找到安装文档位置
通过初始化完成输出的内容中的网址https://kubernetes.io/docs/concepts/cluster-administration/addons/进入k8s官网文档
在该网页中的Networking and Network Policy部分找到Calico并点击Calico跳转到Calico官网
点击Get started找到TIGERA的官网
https://docs.tigera.io/calico/latest/about
在该网页下方找到install calico部分
选择Quickstart for Calico on Kubernetes
根据Install Calico部分安装colico
命令如下
安装calico 的操作资源(执行命令报错请参考:资源获取报错解决)
kubectl create -f https://raw.githubusercontent.com/projectcalico/calico/v3.26.4/manifests/tigera-operator.yaml
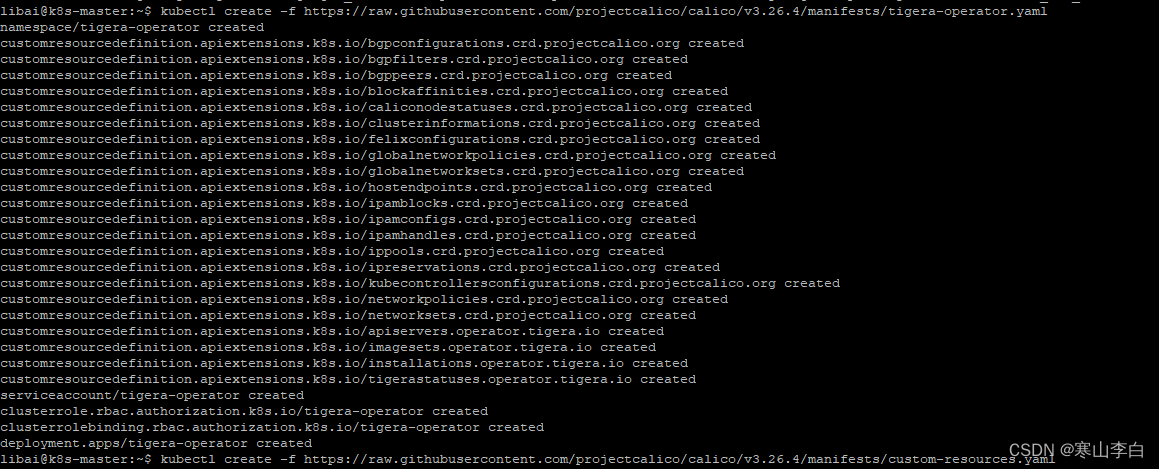
安装calico 的自定义资源文件
kubectl create -f https://raw.githubusercontent.com/projectcalico/calico/v3.26.4/manifests/custom-resources.yaml

watch kubectl get pods -n calico-system
kubectl taint nodes --all node-role.kubernetes.io/control-plane-
kubectl taint nodes --all node-role.kubernetes.io/master-
kubectl get nodes -o wide
5. 集群节点查看
查看集群节点
kubectl get nodes

或
kubectl get nodes -o wide

6. 集群添加节点
master初始化完成时输出的命令如下
鼠标左键将命令选中即可复制,直接到其他节点鼠标右键即可粘贴
sudo kubeadm join 192.168.193.128:6443 --token 1cd07a.h2z8wrgngllonwjt \
--discovery-token-ca-cert-hash sha256:0cc0df38925079b35a0e45e0c43f50f62dc7b3aad2e8414177a18f613c44c9fb
sudo kubeadm join 192.168.193.128:6443 --token vn3qhk.zazsy00qnx5zpejb --discovery-token-ca-cert-hash sha256:0cc0df38925079b35a0e45e0c43f50f62dc7b3aad2e8414177a18f613c44c9fb
参数:
join后跟的是master节点IP地址和端口
–token 后的参数为临时令牌,会过期
–discovery-token-ca-cert-hash
注:加入集群的命令中的token24小时后会过期,过期后需要重新再主节点执行命令生成新的token
6.1 重新生成加入节点的命令
如果忘了这个添加节点的join命令,可以在主节点master用以下命令重新生成新的
kubeadm token create --print-join-command

然后将得到的命令加上sudo前缀即可到工作节点执行
6.2 将worker1节点加入集群
在K8S-WORKER1节点中执行生成的join命令即可将节点添加到集群中(用你自己生成的命令)
sudo kubeadm join 192.168.193.128:6443 --token vn3qhk.zazsy00qnx5zpejb --discovery-token-ca-cert-hash sha256:0cc0df38925079b35a0e45e0c43f50f62dc7b3aad2e8414177a18f613c44c9fb
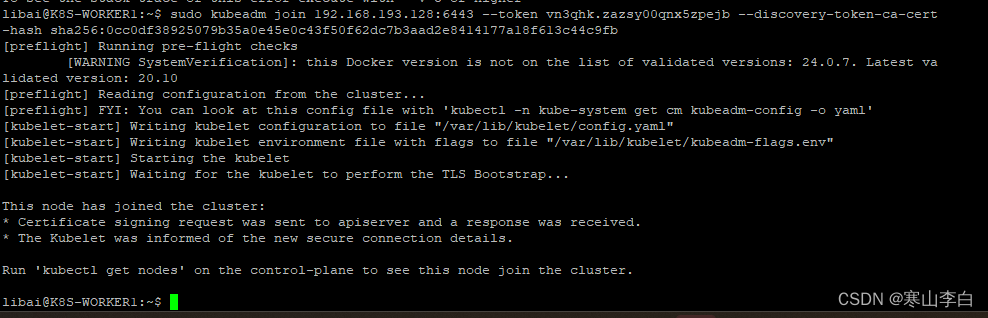
没报错继续下一步,如果报错了,参考文章解决:添加节点到集群时报错处理
6.3 将worker2节点加入集群
在K8S-WORKER2节点中执行相同的命令将worker2节点加入结群
sudo kubeadm join 192.168.193.128:6443 --token vn3qhk.zazsy00qnx5zpejb --discovery-token-ca-cert-hash sha256:0cc0df38925079b35a0e45e0c43f50f62dc7b3aad2e8414177a18f613c44c9fb
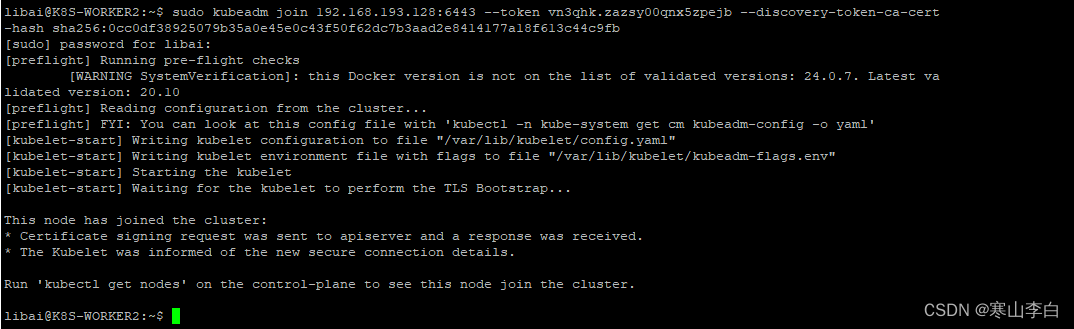
补:hosts配置
将所有的节点的ip对应的名称,添加到每个节点的hosts中
master节点操作如下
sudo vim /etc/hosts
进入vim界面按i进入编辑,将原有ip注释掉
将以下复制后右键粘贴到vim中,按esc退出编辑后shift+zz保存退出
192.168.193.128 k8s-master
192.168.193.129 k8s-worker1
192.168.193.130 k8s-worker2
重启虚拟机后生效
查看
cat /etc/hosts
在worker1和worker2节点分别执行以上操作修改hosts
对worker1和worker2节点操作,修改hostname全改为小写
hostnamectl set-hostname k8s-worker1
hostnamectl set-hostname k8s-worker2
6.4 查看已加入集群的节点
在主节点master中执行命令查看集群中节点信息
kubectl get nodes

然后到工作节点中使用该命令查看集群
报错如下
The connection to the server localhost:8080 was refused - did you specify the right host or port?
截图如下


原因是kubectl命令使用时需要用到kubernetes中的admin.conf文件
而此文件只有master节点初始化后生成了,工作节点并没有这个文件
解决方法就是将文件从主节点复制到从节点中,再在从节点中配置环境变量生效后即可
请参考:k8s从节点查看集群报错解决
有点套娃的意思,别笑
解决之后如下


到此k8s的安装配置就完成了,接下来就是如何使用,通过可视化工具dashboard
感谢阅读,祝君暴富!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 计算机毕业设计 基于SpringBoot的民宿租赁系统的设计与实现 Java实战项目 附源码+文档+视频讲解
- 【算法】NOIP2017奶酪(搜索)
- 一种可扩展的多属性可控文本生成即插即用方法
- 基于深度学习的多目标跟踪算法
- docker 创建oceanbase数据库
- MVC : python实现
- 好家长期刊投稿方式
- 深入浅出AI落地应用分析:全球榜Top10应用(下)
- 如何写html邮件 —— 参考主流outook、gmail、qq邮箱渲染邮件过程
- DQL-排序查询