Databend 的算力可扩展性
作者:尚卓燃(PsiACE)
澳门科技大学在读硕士,Databend 研发工程师实习生
Apache OpenDAL(Incubating) Committer

对于大规模分布式数据处理系统,为了更好应对数据、流量、和复杂性的增长,需要对系统的可扩展性加以重视。可拓展性代表一种预期,即在现有软件和硬件水平无法满足工作负载的时候,通过扩展系统可以进一步满足工作负载的需要。
Databend 是一款现代化的云原生数据仓库,旨在通过弹性和可扩展的架构提供高效的数据分析能力。Databend 具有高效的资源利用能力和分布式扩展能力,可以解决传统数据仓库在处理大数据集时遇到的性能和可扩展性问题。
Databend Cloud 基于开源的 Databend 发展而来,能够帮助您托管 Databend 实例,并提供 Serverless 的部署模式,不仅可以降低成本,还可以提高系统的弹性和可靠性。Databend Cloud 将廉价的云存储作为主要存储,并提供快捷高效的分析性能,已帮助很多客户实现了数仓、行为日志等场景的降本增效,并广受好评。通过使用 Databend Cloud,用户可以轻松构建低成本、高性能的数据仓库,并专注于分析而非基础架构的维护。
可扩展性概念与因素
系统的可扩展性涉及到多个维度,除了系统本身的管理的资源、软件设计的优化和数据与计算的有效管理之外,还包括系统需要处理的数据量、用户数量、查询复杂性等。
可扩展性与系统性能
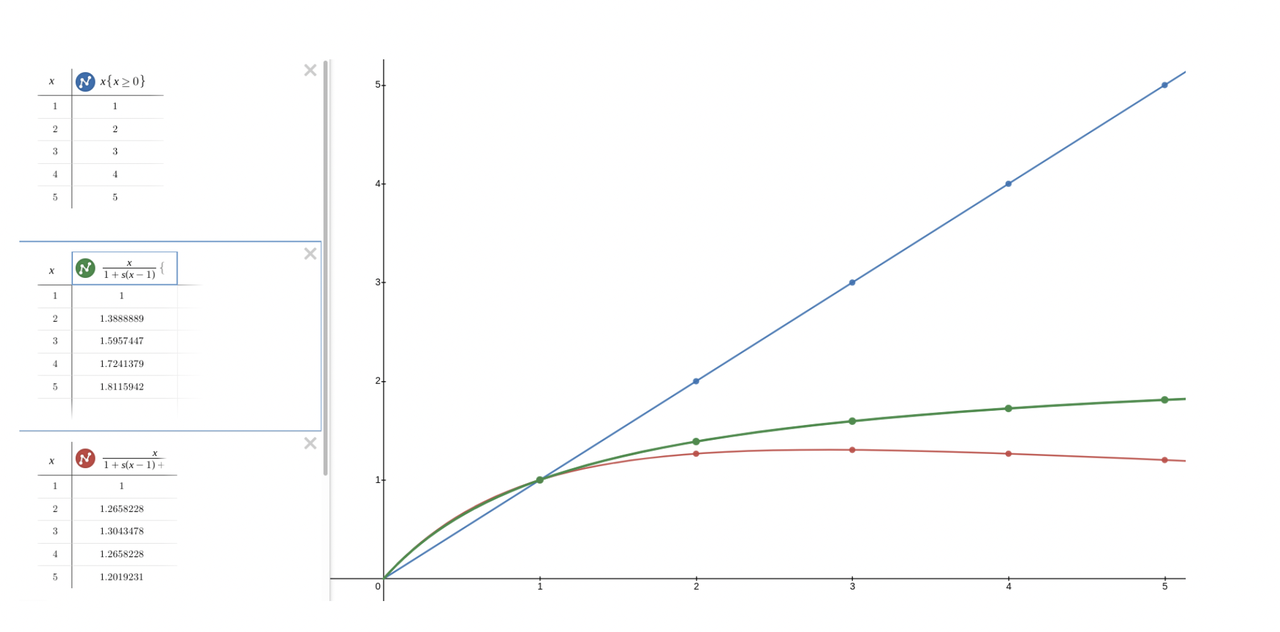
线性可扩展性意味着资源的增加能够直接转化为系统性能的提升。线性可扩展性隐含的保证是当工作负载扩大一倍时,系统的计算资源(如CPU、内存、存储等)也扩大一倍,算力变为原来的两倍,从而获得与之前相当的处理速度。?
可扩展性背后的数学
但是,除非系统完全无状态,否则只能将其扩展到通用可扩展性定律(Universal Scalibility Law,红色线条)所描述的程度,之后即便添加更多资源,最终也只会因为并发、争用和相关性延迟导致系统整体性能降低。
即使在几乎不存在相关性延迟并且充分并行化的最佳情况下,最终也会受到阿姆达尔定律(Amdahl’ Law,绿色线条)的限制,这仍然无法达到线性可扩展性。
毫无疑问线性可扩展性(蓝色线条)只是理想情况下的表述。 在?Contention, Coherency, and Math Behind Software(上面图片的出处)一文中介绍了可扩展性背后的一些数学,也推荐大家阅读。
水平扩展和垂直扩展
两种常见的扩展方式是垂直扩展和水平扩展:
- 垂直扩展(纵向扩展)则是提高单个节点的能力,如升级硬件或改善系统架构。
- 水平扩展(横向扩展)指的是增加更多节点到现有的系统集群中,例如添加更多的服务器。
垂直扩展是改善系统性能的一个有效方式,但是垂直扩展面临着一个致命不足:单机性能总是有极限的。由于单机往往不能胜任大数据分析的需要,所以相关系统通常会强调架构各层的水平可扩展性以及水平扩展带来的性能增长。
Databend 的架构可扩展性
Databend 的架构设计考虑了可扩展性的多个方面,使其在云环境中能够灵活地扩展资源和处理能力。

Share-Nothing V.S. Share-Storage
传统数仓往往采用 Share-Nothing 架构,存储、计算一体化设计,弹性相对较弱。而且由于调度上采用资源固定(Fixed-Set)式调度策略,资源控制粒度粗,也会带来更多的成本消耗。Databend 使用共享存储架构(Share-Storage),底层可以使用对象存储,真正做到存储、计算分离,资源控制粒度更细。计算节点可以根据需求弹性扩展,而不受存储容量的限制。
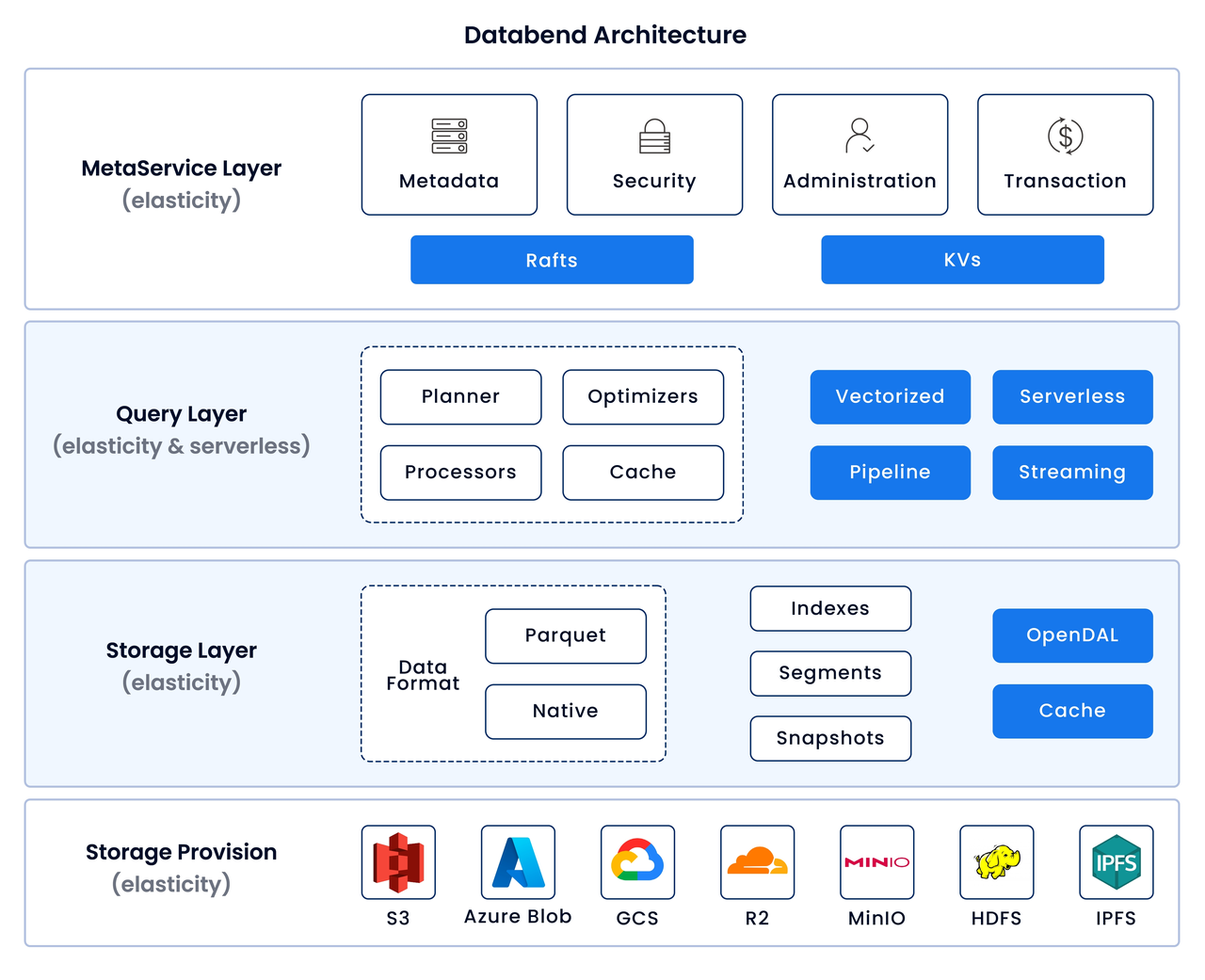
Databend 架构全景图
得益于列式存储模型和向量化计算,Databend 可以充分利用现代硬件系统的潜力;此外,Databend 还对数据存储格式、数据缓存、和系统吞吐量进行了充分优化,以达到性能的最佳释放。
由于采用共享存储的架构,并且 Query 节点采用无状态设计,只在 Meta 节点保留必要的状态信息,使得 Query 节点能够轻松支持实时弹性扩容和缩容以及资源按需(Workload-Based)式调度。计算资源可以根据实际的工作负载自动扩展,提供按需计算能力,这进一步提高了系统的可扩展性和资源的使用效率。
### 性能评估:Databend?Cloud?的算力可扩展性?
为了评估 Databend 的性能和可扩展性,可以运行 TPC-H 基准测试。TPC-H是一套针对数据库决策支持能力的测试基准,通过模拟数据库中与业务相关的复杂查询和并行的数据修改操作考察数据库的综合处理能力。
通过在 Databend Cloud上针对不同计算集群规模进行 TPC-H 查询的性能测试,我们可以观察到系统扩展资源时的性能变化。这些结果可以帮助我们了解在增加计算节点(水平扩展)和/或升级现有节点(垂直扩展)时,Databend 的查询处理能力如何改变。
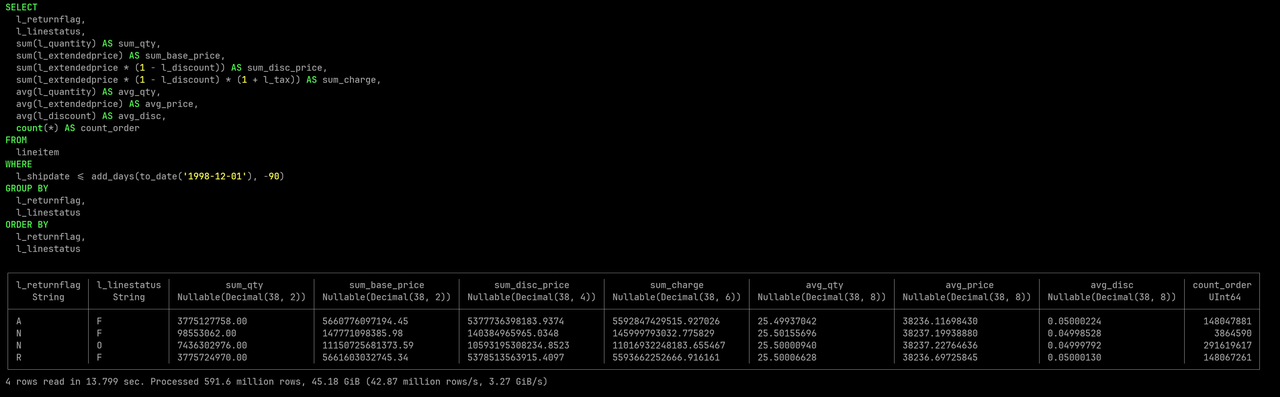
使用 BendSQL 执行 TPC-H Q1
下面的数据展现了 Databend Cloud 上不同规模实例在执行 TPC-H 测试 Q1 时的性能变化。其中 XSmall 和 Small 都是单计算实例,对应垂直扩展模型;而从 Small 到 Large 的计算实例数量不断增长,对应水平扩展模型。
| Instance Type | vCPUs | Compute Instances | Rows Read (Avg) | Time (Avg) | Rows Processed | Data Processed | Rows/s (Avg) | Data/s (Avg) |
|---|---|---|---|---|---|---|---|---|
| XSmall | 8 | 1 | 4 | 14.109 sec | 591.6 million | 45.18 GiB | 41.93 million | 3.20 GiB |
| XSmall | 8 | 1 | 4 | 13.676 sec | 591.6 million | 45.18 GiB | 43.26 million | 3.30 GiB |
| XSmall | 8 | 1 | 4 | 13.799 sec | 591.6 million | 45.18 GiB | 42.87 million | 3.27 GiB |
| Small | 16 | 1 | 4 | 13.241 sec | 591.6 million | 45.18 GiB | 44.68 million | 3.41 GiB |
| Small | 16 | 1 | 4 | 11.571 sec | 591.6 million | 45.18 GiB | 51.13 million | 3.90 GiB |
| Small | 16 | 1 | 4 | 11.734 sec | 591.6 million | 45.18 GiB | 50.42 million | 3.85 GiB |
| Medium | 32 | 2 | 4 | 9.392 sec | 591.6 million | 45.18 GiB | 62.99 million | 4.81 GiB |
| Medium | 32 | 2 | 4 | 8.279 sec | 591.6 million | 45.18 GiB | 71.46 million | 5.46 GiB |
| Medium | 32 | 2 | 4 | 8.341 sec | 591.6 million | 45.18 GiB | 70.93 million | 5.42 GiB |
| Large | 64 | 4 | 4 | 8.536 sec | 591.6 million | 45.18 GiB | 69.31 million | 5.29 GiB |
| Large | 64 | 4 | 4 | 7.096 sec | 591.6 million | 45.18 GiB | 83.37 million | 6.37 GiB |
| Large | 64 | 4 | 4 | 7.841 sec | 591.6 million | 45.18 GiB | 75.45 million | 5.76 GiB |
| XLarge | 128 | 8 | 4 | 7.123 sec | 591.6 million | 45.18 GiB | 83.05 million | 6.34 GiB |
| XLarge | 128 | 8 | 4 | 5.753 sec | 591.6 million | 45.18 GiB | 102.83 million | 7.85 GiB |
| XLarge | 128 | 8 | 4 | 5.767 sec | 591.6 million | 45.18 GiB | 102.59 million | 7.83 GiB |
可以看到,随着系统规模的扩大,查询响应时间缩短,而处理吞吐量也随之增加。这些测试结果直观展示了不同规模的 Databend Cloud 在同一工作负载下的处理能力变化。
Databend 的设计哲学、架构以及 Databend Cloud 的性能表现,体现了其作为一款现代大规模分布式数据处理系统的算力可扩展性。
除了私有化部署 Databend 和使用 Databend Cloud 之外,我们也提供混合云支持。可以帮助用户实现适应规模和成本的算力最大化调度,为未来数据处理需求的多样性和不断增长的挑战提供最佳应对方案。
关于?Databend
Databend 是一款开源、弹性、低成本,基于对象存储也可以做实时分析的新式数仓。期待您的关注,一起探索云原生数仓解决方案,打造新一代开源 Data Cloud。
👨?💻??Databend Cloud:https://databend.cn
📖?Databend 文档:Databend - The Future of Cloud Data Analytics. | Databend
💻?Wechat:Databend
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【JavaEE】多线程(4) -- 单例模式
- 【STL-set】
- 【VTKExamples::PolyData】第四期 DijkstraGraphGeodesicPath
- 【Linux学习】进程间通信
- 1-3算法基础-标准模板库STL
- 「Verilog学习笔记」使用握手信号实现跨时钟域数据传输
- Qt快捷键
- 深度探析卷积神经网络(CNN)在图像视觉与自然语言处理领域的应用与优势
- OCS2 入门教程(三)- 最优控制模块
- 建一个外贸网站一年大概需要多少钱?