DDIA 第二章:数据模型与查询语言
本文是《数据密集型应用系统设计》(DDIA)的读书笔记,一共十二章,我已经全部阅读并且整理完毕。
采用一问一答的形式,并且用列表形式整理了原文。 笔记的内容大概是原文的 1/5 ~
1/3,所以你如果没有很多时间看书的话,看我的笔记也就够了!

数据模型可能是软件开发中最重要的部分了,因为它们的影响如此深远:不仅仅影响着软件的编写方式,而且影响着我们的解题思路。
一个复杂的应用程序可能会有更多的中间层次,比如基于API的API,不过基本思想仍然是一样的:每个层都通过提供一个明确的数据模型来隐藏更低层次中的复杂性。这些抽象允许不同的人群有效地协作。
关系模型与文档模型
现在最著名的数据模型可能是SQL。它基于Edgar Codd在1970年提出的关系模型【1】:数据被组织成关系(SQL中称作表),其中每个关系是元组(SQL中称作行)的无序集合。
NoSQL的诞生
- NoSQL:不仅是SQL(Not Only SQL)
- 采用NoSQL数据库的背后有几个驱动因素,其中包括:
- 需要比关系数据库更好的可扩展性,包括非常大的数据集或非常高的写入吞吐量
- 相比商业数据库产品,免费和开源软件更受偏爱。
- 关系模型不能很好地支持一些特殊的查询操作
- 受挫于关系模型的限制性,渴望一种更具多动态性与表现力的数据模型
- 在可预见的未来,关系数据库似乎可能会继续与各种非关系数据库一起使用 - 这种想法有时也被称为混合持久化(polyglot persistence)
对象关系不匹配
- 应用程序使用面向对象的语言,需要一个转换层,才能转成 SQL 数据模型:被称为阻抗不匹配。
- Hibernate这样的 对象关系映射(ORM object-relational mapping) 框架可以减少这个转换层所需的样板代码的数量,但是它们不能完全隐藏这两个模型之间的差异。
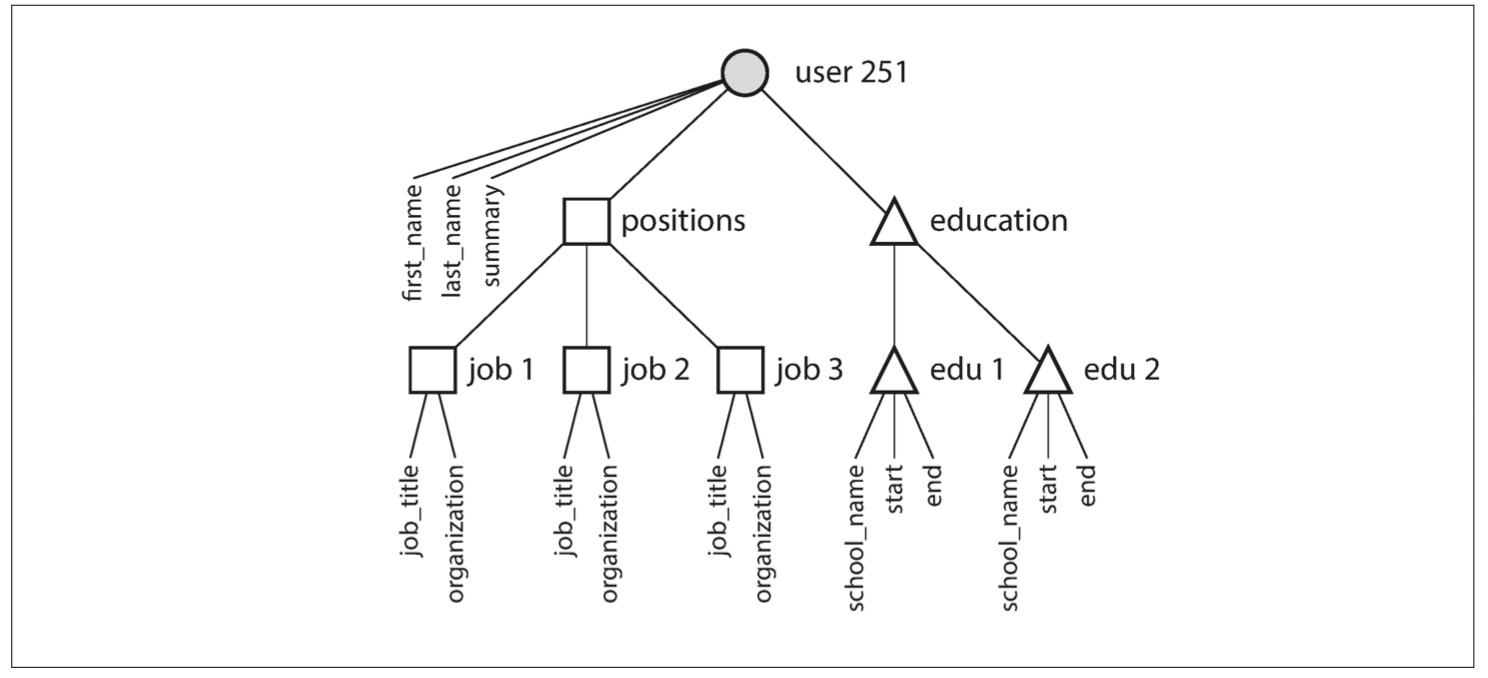
- 对于一份简历而言,关系型模型需要一对多(比如工作经历)。

而表述这样的简历,使用 JSON 是非常合适的。JSON 比多表模式有更好的局部性,可以一次查询出一个用户的所有信息。JSON 其实是一棵树。
多对一和多对多的关系
- 为什么在 SQL 中,地域和公司都以 ID,而不是字符串进行标识呢?
- ID 对人类没有任何意义,所以永远不需要改变,可以规范化人类的信息。那么就会存在多对一的关系(多个人对应了同一个 ID)。
- 在关系数据库 SQL 中,所有使用它的地方可以用 ID 来引用其他表中的行;
- 但是文档数据库(比如 JSON),对连接支持很弱。
- 如果数据库不支持链接,那么就需要在应用代码中,对数据库执行多个查询进行模拟。执行连接的工作从数据库被转移到应用程序代码上。
哪怕最开始的应用适合无连接的文档模型,但是随着功能添加,数据会变得更加互联,比如对简历修改:
- 组织和学校作为实体:假如组织和学校有主页
- 推荐:给别人做推荐,当别人的信息更改的时候,所有地方要同步更新。


文档数据库是否在重蹈覆辙?
20 世纪 70 年代,最受欢迎的是层次模型(hierarchical model),它与文档数据库使用的JSON模型有一些惊人的相似之处。它将所有数据表示为嵌套在记录中的记录树。虽然能处理一对多的关系,但是很难应对多对多的关系,并且不支持链接。
提出的解决方案:
- 关系模型(relational model)(它变成了SQL,统治了世界)
- 网络模型(network model)(最初很受关注,但最终变得冷门)
网络模型
- 支持多对多,每条记录可能有多个父节点。
- 网络模型中记录之间的链接不是外键,而更像编程语言中的指针(同时仍然存储在磁盘上)。访问记录的唯一方法是跟随从根记录起沿这些链路所形成的路径。这被称为访问路径(access path)。
- 最简单的情况下,访问路径类似遍历链表:从列表头开始,每次查看一条记录,直到找到所需的记录。但在多对多关系的情况中,数条不同的路径可以到达相同的记录,网络模型的程序员必须跟踪这些不同的访问路径。
- 缺点:查询和更新数据库很麻烦。
关系模型
- 数据:一个 关系(表) 只是一个 元组(行) 的集合,很简单。
- 在关系数据库中,查询优化器自动决定查询的哪些部分以哪个顺序执行,以及使用哪些索引。这些选择实际上是“访问路径”,但最大的区别在于它们是由查询优化器自动生成的,不需要程序猿考虑。
与文档数据库相比
但是,在表示多对一和多对多的关系时,关系数据库和文档数据库并没有根本的不同:在这两种情况下,相关项目都被一个唯一的标识符引用,这个标识符在关系模型中被称为外键,在文档模型中称为文档引用。
关系型数据库与文档数据库在今日的对比
- 支持文档数据模型的主要论据是架构灵活性,因局部性而拥有更好的性能,以及对于某些应用程序而言更接近于应用程序使用的数据结构。
- 关系模型通过为连接提供更好的支持以及支持多对一和多对多的关系来反击。
哪个数据模型更方便写代码?
文档模型:
- 优点:
- 如果应用程序中的数据具有类似文档的结构(即,一对多关系树,通常一次性加载整个树),那么使用文档模型可能是一个好主意。
- 缺点:
- 不能直接引用文档中的嵌套的项目,而是需要说“用户251的位置列表中的第二项”(很像分层模型中的访问路径)。但是,只要文件嵌套不太深,这通常不是问题。
- 文档数据库对连接的糟糕支持也许或也许不是一个问题,这取决于应用程序。
- 如果应用程序使用多对多关系,那么文档模型就没有那么吸引人了。
- 对于高度相联的数据,选用文档模型是糟糕的,选用关系模型是可接受的,而选用图形模型是最自然的。
文档模型中的架构灵活性
- 文档模型是「读时模式」
- 文档数据库有时称为无模式(schemaless),但这具有误导性,因为读取数据的代码通常假定某种结构——即存在隐式模式,但不由数据库强制执行
- 一个更精确的术语是读时模式(schema-on-read)(数据的结构是隐含的,只有在数据被读取时才被解释),相应的是写时模式(schema-on-write)(传统的关系数据库方法中,模式明确,且数据库确保所有的数据都符合其模式)
- 读时模式类似于编程语言中的动态(运行时)类型检查,而写时模式类似于静态(编译时)类型检查。
- 模式变更
- 读时模式变更字段很容易,只用改应用代码
- 写时模式变更字段速度很慢,而且要求停运。它的这种坏名誉并不是完全应得的:大多数关系数据库系统可在几毫秒内执行ALTER TABLE语句。MySQL是一个值得注意的例外,它执行ALTER TABLE时会复制整个表,这可能意味着在更改一个大型表时会花费几分钟甚至几个小时的停机时间,尽管存在各种工具来解决这个限制。
查询的数据局部性
- 文档通常以单个连续字符串形式进行存储,编码为JSON,XML或其二进制变体
- 读文档:
- 如果应用程序经常需要访问整个文档(例如,将其渲染至网页),那么存储局部性会带来性能优势。
- 局部性仅仅适用于同时需要文档绝大部分内容的情况。
- 写文档:
- 更新文档时,通常需要整个重写。只有不改变文档大小的修改才可以容易地原地执行。
- 通常建议保持相对小的文档,并避免增加文档大小的写入
文档和关系数据库的融合
- MySQL 等逐步增加了对 JSON 和 XML 的支持
- 关系模型和文档模型的混合是未来数据库一条很好的路线。
数据查询语言
- 关系模型包含了一种查询数据的新方法:SQL是一种 声明式 查询语言,而IMS和CODASYL使用 命令式 代码来查询数据库。
- 命令式语言:告诉计算机以特定顺序执行某些操作,比如常见的编程语言。
- 声明式查询语言(如SQL或关系代数):你只需指定所需数据的模式 - 结果必须符合哪些条件,以及如何将数据转换(例如,排序,分组和集合) - 但不是如何实现这一目标。数据库系统的查询优化器决定使用哪些索引和哪些连接方法,以及以何种顺序执行查询的各个部分。
- SQL相当有限的功能性为数据库提供了更多自动优化的空间。
- 声明式语言往往适合并行执行。
Web上的声明式查询
- 声明式语言更加泛化,不用关心底层的数据存储变化
- 在Web浏览器中,使用声明式CSS样式比使用JavaScript命令式地操作样式要好得多。
- 类似地,在数据库中,使用像SQL这样的声明式查询语言比使用命令式查询API要好得多。
MapReduce查询
- 一些NoSQL数据存储(包括MongoDB和CouchDB)支持有限形式的MapReduce,作为在多个文档中执行只读查询的机制。
- MapReduce既不是一个声明式的查询语言,也不是一个完全命令式的查询API,而是处于两者之间
- 查询的逻辑用代码片断来表示,这些代码片段会被处理框架重复性调用。
- 它基于map(也称为collect)和reduce(也称为fold或inject)函数,两个函数存在于许多函数式编程语言中。
- map和reduce函数在功能上有所限制:
- 它们必须是纯函数,这意味着它们只使用传递给它们的数据作为输入,它们不能执行额外的数据库查询,也不能有任何副作用。
- 这些限制允许数据库以任何顺序运行任何功能,并在失败时重新运行它们。
- MapReduce是一个相当底层的编程模型,用于计算机集群上的分布式执行。像SQL这样的更高级的查询语言可以用一系列的MapReduce操作来实现,但是也有很多不使用MapReduce的分布式SQL实现。
- MapReduce的一个可用性问题:必须编写两个密切合作的JavaScript函数,这通常比编写单个查询更困难。此外,声明式查询语言为查询优化器提供了更多机会来提高查询的性能。基于这些原因,MongoDB 2.2添加了一种叫做聚合管道的声明式查询语言的支持
图数据模型
- 多对多关系是不同数据模型之间具有区别性的重要特征。
- 文档模型:适合数据有一对多关系、不存在关系
- 图数据模型:适合多对多关系
- 一个图由两种对象组成:
- 顶点(vertices)(也称为节点(nodes) 或实体(entities))
- 边(edges)( 也称为关系(relationships)或弧 (arcs) )。
- 举例:社交图谱,网络图谱,公路或铁路网络
- 图数据结构示例(以社交网络为例)
- 存储方式:属性图,三元组
属性图
在属性图模型中,每个**顶点(vertex)**包括:
- 唯一的标识符
- 一组 出边(outgoing edges)
- 一组 入边(ingoing edges)
- 一组属性(键值对)
每条 边(edge) 包括:
- 唯一标识符
- 边的起点/尾部顶点(tail vertex)
- 边的终点/头部顶点(head vertex)
- 描述两个顶点之间关系类型的标签
- 一组属性(键值对)
使用关系模式来表示属性图
CREATE TABLE vertices (
vertex_id INTEGER PRIMARY KEY,
properties JSON
);
CREATE TABLE edges (
edge_id INTEGER PRIMARY KEY,
tail_vertex INTEGER REFERENCES vertices (vertex_id),
head_vertex INTEGER REFERENCES vertices (vertex_id),
label TEXT,
properties JSON
);
CREATE INDEX edges_tails ON edges (tail_vertex);
CREATE INDEX edges_heads ON edges (head_vertex);
关于这个模型的一些重要方面是:
- 任何顶点都可以有一条边连接到任何其他顶点。没有模式限制哪种事物可不可以关联。
- 给定任何顶点,可以高效地找到它的入边和出边,从而遍历图,即沿着一系列顶点的路径前后移动。(这就是为什么例2-2在tail_vertex和head_vertex列上都有索引的原因。)
- 通过对不同类型的关系使用不同的标签,可以在一个图中存储几种不同的信息,同时仍然保持一个清晰的数据模型。
Cypher查询语言
- Cypher是属性图的声明式查询语言,为Neo4j图形数据库而发明
- 通常对于声明式查询语言来说,在编写查询语句时,不需要指定执行细节:查询优化程序会自动选择预测效率最高的策略,因此你可以继续编写应用程序的其他部分。
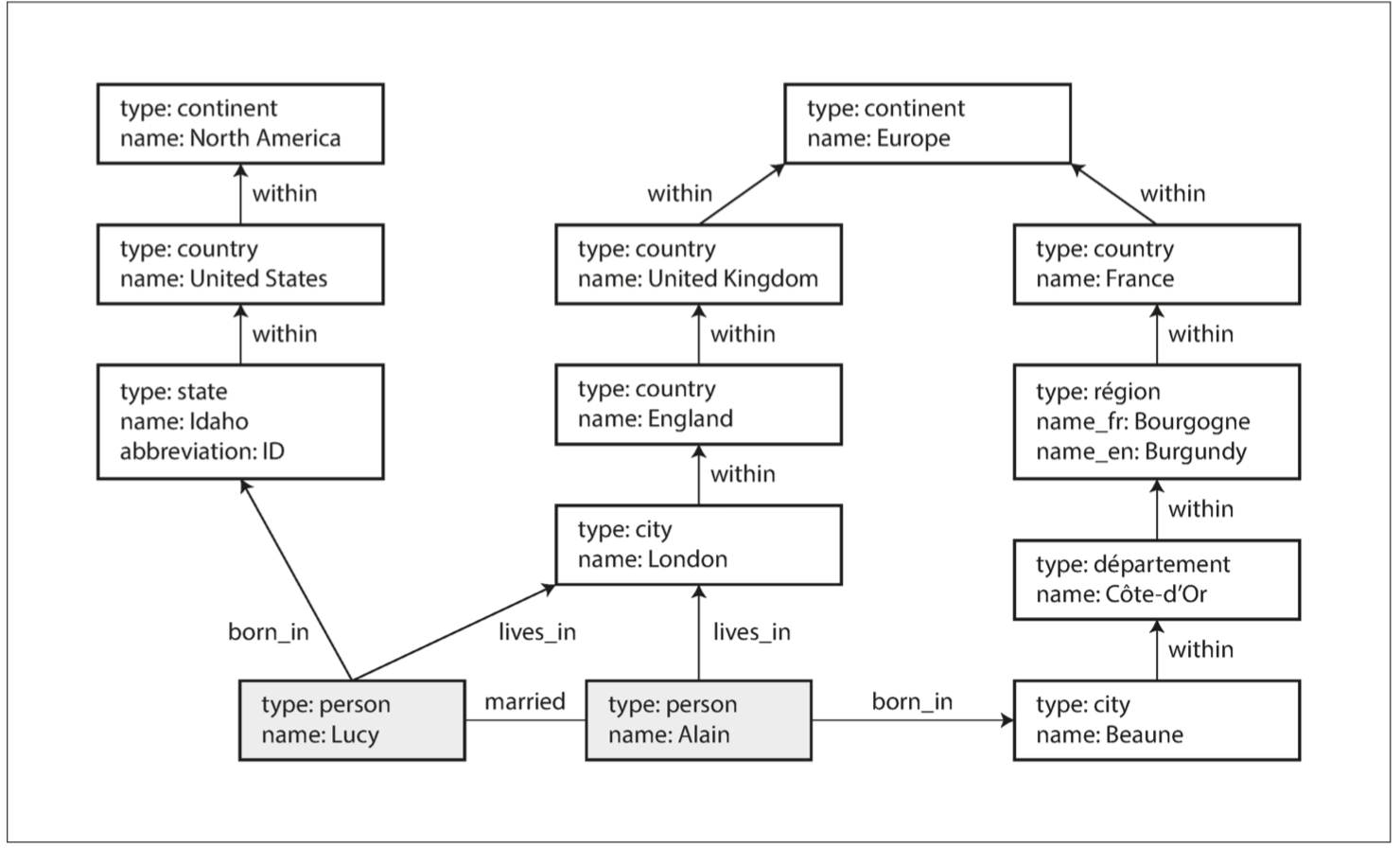
- 查找所有从美国移民到欧洲的人的Cypher查询
MATCH
(person) -[:BORN_IN]-> () -[:WITHIN*0..]-> (us:Location {name:'United States'}),
(person) -[:LIVES_IN]-> () -[:WITHIN*0..]-> (eu:Location {name:'Europe'})
RETURN person.name
SQL中的图查询
- 用关系数据库表示图数据,那么也可以用SQL,但有些困难。
- 在关系数据库中,你通常会事先知道在查询中需要哪些连接。在图查询中,你可能需要在找到待查找的顶点之前,遍历可变数量的边。也就是说,连接的数量事先并不确定。
- 语法很复杂,
三元组存储和SPARQL
- 在三元组存储中,所有信息都以非常简单的三部分表示形式存储(主语,谓语,宾语)。例如,三元组 (吉姆, 喜欢 ,香蕉) 中,吉姆 是主语,喜欢 是谓语(动词),香蕉 是对象。
- 三元组的主语相当于图中的一个顶点。而宾语是下面两者之一:
- 原始数据类型中的值,例如字符串或数字。在这种情况下,三元组的谓语和宾语相当于主语顶点上的属性的键和值。例如,(lucy, age, 33)就像属性{“age”:33}的顶点lucy。
- 图中的另一个顶点。在这种情况下,谓语是图中的一条边,主语是其尾部顶点,而宾语是其头部顶点。例如,在(lucy, marriedTo, alain)中主语和宾语lucy和alain都是顶点,并且谓语marriedTo是连接他们的边的标签。
- 当主语一样的时候,可以进行省略写法
@prefix : <urn:example:>.
_:lucy a :Person; :name "Lucy"; :bornIn _:idaho.
_:idaho a :Location; :name "Idaho"; :type "state"; :within _:usa
_:usa a :Loaction; :name "United States"; :type "country"; :within _:namerica.
_:namerica a :Location; :name "North America"; :type "continent".
语义网络
- 语义网是一个简单且合理的想法:网站已经将信息发布为文字和图片供人类阅读,为什么不将信息作为机器可读的数据也发布给计算机呢?
- 资源描述框架(RDF)的目的是作为不同网站以一致的格式发布数据的一种机制,允许来自不同网站的数据自动合并成一个数据网络 - 一种互联网范围内的“关于一切的数据库“。
- 现在已经凉了。
SPARQL查询语言
- SPARQL是一种用于三元组存储的面向RDF数据模型的查询语言
- 查找从美国转移到欧洲的人
PREFIX : <urn:example:>
SELECT ?personName WHERE {
?person :name ?personName.
?person :bornIn / :within* / :name "United States".
?person :livesIn / :within* / :name "Europe".
}
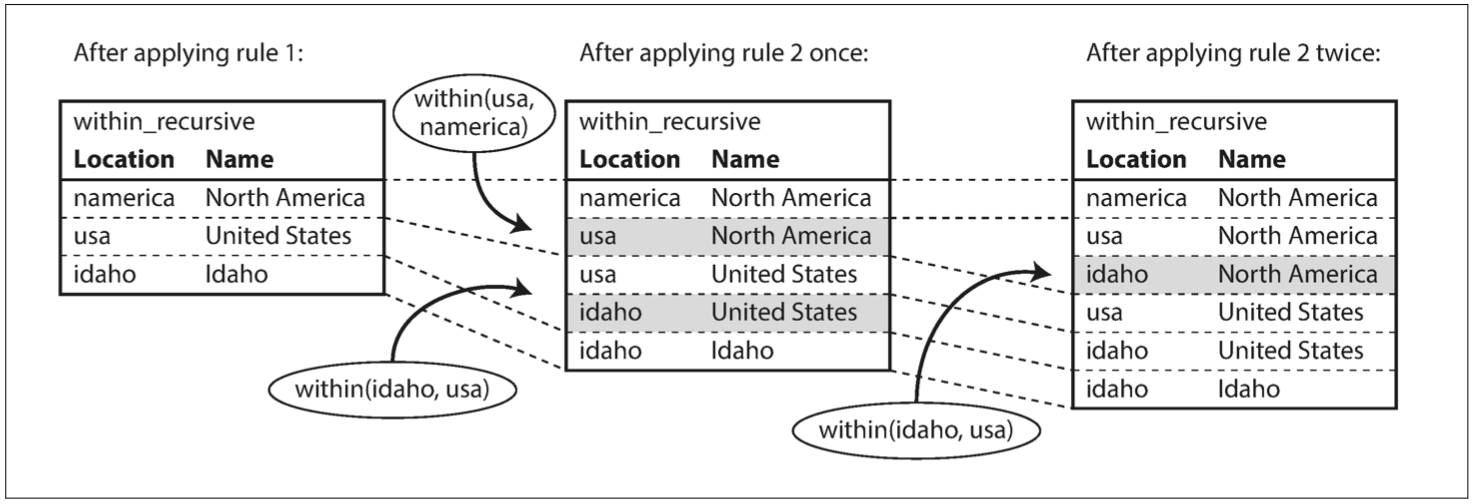
基础:Datalog
Datalog是比SPARQL或Cypher更古老的语言,在20世纪80年代被学者广泛研究
本章小结
在历史上,数据最开始被表示为一棵大树(层次数据模型),但是这不利于表示多对多的关系,所以发明了关系模型来解决这个问题。
最近,开发人员发现一些应用程序也不适合采用关系模型。新的非关系型“NoSQL”数据存储在两个主要方向上存在分歧:
- 文档数据库的应用场景是:数据通常是自我包含的,而且文档之间的关系非常稀少。
- 图形数据库用于相反的场景:任意事物都可能与任何事物相关联。
文档数据库和图数据库有一个共同点,那就是它们通常不会为存储的数据强制一个模式,这可以使应用程序更容易适应不断变化的需求。但是应用程序很可能仍会假定数据具有一定的结构;这只是模式是明确的(写入时强制)还是隐含的(读取时处理)的问题。
每个数据模型都具有各自的查询语言或框架,我们讨论了几个例子:SQL,MapReduce,MongoDB的聚合管道,Cypher,SPARQL和Datalog。我们也谈到了CSS和XSL/XPath,它们不是数据库查询语言,而包含有趣的相似之处。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 回溯算法part01 算法
- python 基础语法函数
- 智能化实验室如何降低管理成本
- 第40节: Vue3 注册生命周期钩子
- CEEMDAN +组合预测模型(CNN-LSTM + ARIMA)
- 为什么企业上了ERP,效率反而更低?
- 【Linux】shell 脚本入门详解
- 单片机计数功能
- 基于APB总线的SM4密码协处理器实现(附Verilog代码)
- 【MySQL】MySQL 8.0 状态变量(Server Status Variables)列表(show status 的结果例)