自然语言推断:使用注意力
发布时间:2024年01月21日
注意力
鉴于许多模型都是基于复杂而深度的架构,Parikh等人提出用注意力机制解决自然语言推断问题,并称之为“可分解注意力模型”?。这使得模型没有循环层或卷积层,在SNLI数据集上以更少的参数实现了当时的最佳结果。本节将描述并实现这种基于注意力的自然语言推断方法(使用MLP),如下图中所述。
模型?
与保留前提和假设中词元的顺序相比,我们可以将一个文本序列中的词元与另一个文本序列中的每个词元对齐,然后比较和聚合这些信息,以预测前提和假设之间的逻辑关系。与机器翻译中源句和目标句之间的词元对齐类似,前提和假设之间的词元对齐可以通过注意力机制灵活地完成。
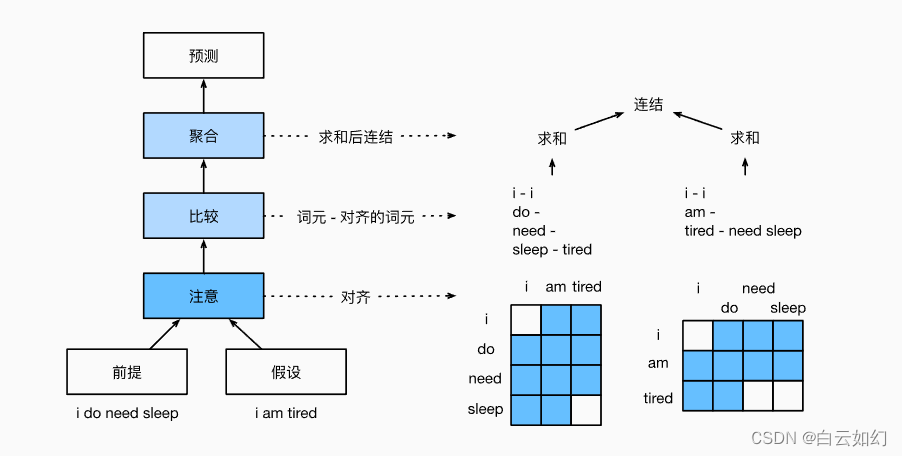
上图描述了使用注意力机制的自然语言推断方法。从高层次上讲,它由三个联合训练的步骤组成:对齐、比较和汇总。我们将在下面一步一步地对它们进行说明。
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
文章来源:https://blog.csdn.net/weixin_43227851/article/details/135724713
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- js删除数组中指定元素的5种方法*
- 牛客小白月赛84——k级序列(超级无敌详解)(贪心)
- 一文读懂 $mash 通证 “Fair Launch” 规则(幸运池玩法解读篇)
- 直播预告|孙琦参加OC城市行·北京 活动 ,分享OpenCloudOS操作系统容灾渐进式迁移实践
- 雷达信号处理——恒虚警检测(CFAR)
- compositionAPI和OptionsAPI
- yarn和npm修改源
- 文章解读与仿真程序复现思路——电网技术EI\CSCD\北大核心《阶梯式碳交易机制下综合能源系统多时间尺度优化调度》
- 如何使用CentOS系统中的Apache服务器提供静态HTTP服务
- IMX6ULL|GPIO子系统