优化算法:最速下降法、梯度下降法、共轭梯度法---理论分析与实践
优化算法:最速下降法、梯度下降法、共轭梯度法—理论分析与实践
最近被TRPO算法搞得头大,对于其中用到的共轭梯度法等优化算法也不了解,在此详细分析一下最速下降法、梯度下降法、共轭梯度法三者的异同。
参考:
数值分析6(3共轭梯度法)
共轭梯度法简介
0、优化目标
考虑最小化二次函数:
?
(
x
)
=
1
2
x
T
A
x
?
x
T
b
\phi(x)=\frac{1}{2}x^{T}Ax-x^{T}b
?(x)=21?xTAx?xTb
其中
b
,
x
∈
R
n
,
A
∈
R
n
×
n
b,x\in\mathbb{R}^n,A\in\mathbb{R}^{n\times n}
b,x∈Rn,A∈Rn×n且假设矩阵
A
A
A是对称正定的(SPD)。该函数的最小值
x
?
x^{*}
x?可以根据一阶最优条件得到,即导数为零
?
?
(
x
?
)
=
A
x
?
?
b
=
0
\nabla\phi(x^*)=Ax^*-b=0
??(x?)=Ax??b=0
这也意味着最小化
?
(
x
)
\phi(x)
?(x)等价于求解线性方程
A
x
=
b
Ax=b
Ax=b。此外,在TRPO算法中,由于二次函数的Hessian矩阵是半正定的,该解具有唯一性。
1、最速下降法
最速下降法的策略是:在任何给定点
x
x
x中,函数
?
(
x
)
\phi(x)
?(x)的负梯度给出的搜索方向是最速下降的方向。换句话说,负梯度方向是局部最优的搜索方向,如下图A点所标注的就是负梯度方向。注意对于二次函数而言它的梯度为
A
x
?
b
Ax-b
Ax?b,我们也将它称为系统的残差
r
r
r
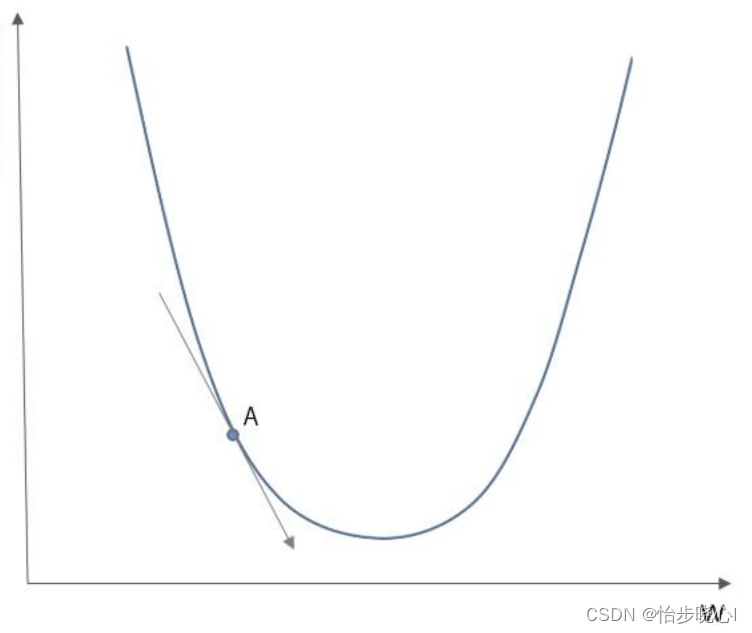
有了方向,那么该如何知道要沿着这个方向走多远呢,最速下降法给出的结论是走到函数值不再下降为止,也就是如果继续走下去函数值会增加。上面的概念容易使人混淆,给出下面的一个优化案例进行解释。
下面是使用最速下降法得到的优化过程图像,其中心位置为最小值点,大致的搜索方向是由右上到中心,每一次转折点就代表已经走到函数值不再下降为止,需要重新进行方向搜索。至于为什么已经走到函数值不再下降为止呢,图中有直观的解释,可以看到每个转折点的原来的曲线都是和等高线圆相切,并且重新进行了方向搜索之后的方向都是和等高线切线垂直(也就是当前局部下降最快的方向)。
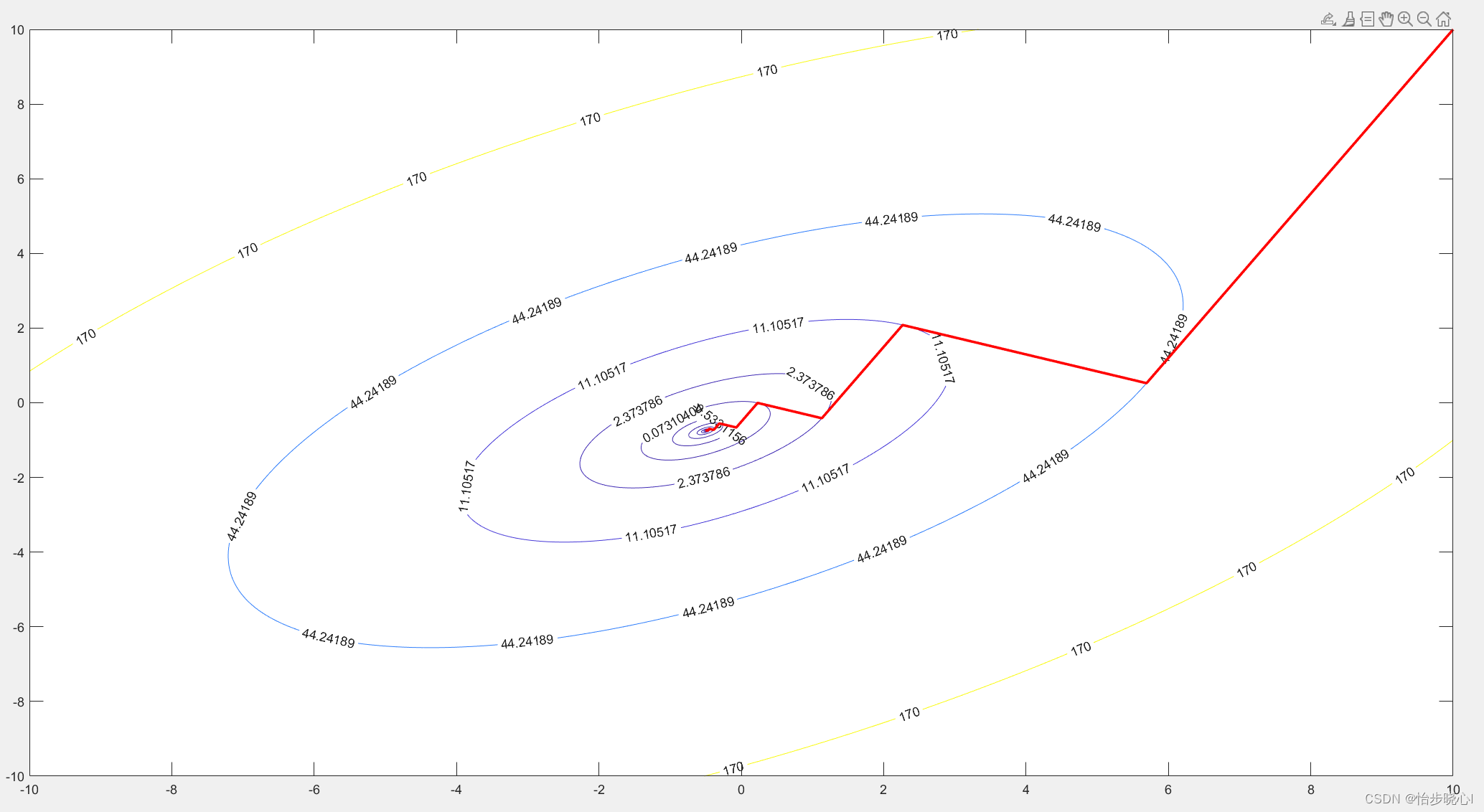
由此可见,最速下降法是个蛮牛一样的角色,每次迭代是不撞南墙不回头的类型(走到函数值不再下降为止),这种策略有助于减少总的迭代次数,但是走出的路线可能比较曲折。
回到正题,如何确定每次要走多远呢?也就是要走多远才能达到南墙(走到函数值不再下降为止)。回顾所有的已知条件:
- 迭代式子为: x k + 1 = x k ? α k ? ? ( x k ) x_{k+1}=x_{k}-\alpha_{k}\nabla\phi(x_{k}) xk+1?=xk??αk???(xk?),其中 α k \alpha_{k} αk?为步长。
- 下降方向为: ? f ( x k ) = A k x ? b = r k \nabla f({x_k})=A_{k}x-b=r_{k} ?f(xk?)=Ak?x?b=rk?,这个式子是对优化函数 ? ( x ) = 1 2 x T A x ? x T b \phi(x)=\frac{1}{2}x^{T}Ax-x^{T}b ?(x)=21?xTAx?xTb求导得到的。
我们的目标就是计算出走到函数值不再下降为止的
α
k
\alpha_{k}
αk?,也就是找到函数
?
(
x
)
\phi(x)
?(x)关于变量
α
k
\alpha_{k}
αk?的极值点。首先对于
α
k
\alpha_{k}
αk?,我们有:
α
k
=
arg
?
min
?
α
k
?
(
x
k
+
1
)
=
arg
?
min
?
α
k
?
(
x
k
?
α
k
?
?
(
x
k
)
)
=
arg
?
min
?
α
k
?
(
x
k
?
α
k
r
k
)
=
arg
?
min
?
α
k
[
1
2
x
k
+
1
T
A
x
k
+
1
?
x
k
+
1
T
b
]
\begin{array}{l} {\alpha _k} = \arg {\min _{{\alpha _k}}}\phi({x_{k + 1}})\\ = \arg {\min _{{\alpha _k}}}\phi({x_k} - {\alpha _k}\nabla \phi({x_k}))\\ = \arg {\min _{{\alpha _k}}}\phi({x_k} - {\alpha _k}{r_k})\\ = \arg {\min _{{\alpha _k}}}\left[ {\frac{1}{2}x_{k + 1}^TA{x_{k + 1}} - x_{k + 1}^Tb} \right] \end{array}
αk?=argminαk???(xk+1?)=argminαk???(xk??αk???(xk?))=argminαk???(xk??αk?rk?)=argminαk??[21?xk+1T?Axk+1??xk+1T?b]?
对 ? ( x k + 1 ) \phi(x_{k+1}) ?(xk+1?)关于变量 α k \alpha_{k} αk?求导并使得其导数为0(此处使用复合函数求导公式,因为 x k + 1 x_{k+1} xk+1?中含有 α k \alpha_{k} αk?,得:
?
?
(
x
k
+
1
)
?
α
k
=
?
[
1
2
x
k
+
1
T
A
x
k
+
1
?
x
k
+
1
T
b
]
?
α
k
=
?
r
k
T
A
x
k
+
1
+
r
k
T
b
=
?
r
k
T
A
(
x
k
?
α
k
r
k
)
+
r
k
T
b
=
?
r
k
T
A
x
k
+
r
k
T
A
α
k
r
k
+
r
k
T
b
=
?
r
k
T
(
A
x
k
?
b
)
+
r
k
T
A
α
k
r
k
=
?
r
k
T
r
k
+
r
k
T
A
α
k
r
k
=
0
\begin{array}{l} \frac{{\partial \phi ({x_{k + 1}})}}{{\partial {\alpha _k}}} = \frac{{\partial \left[ {\frac{1}{2}x_{k + 1}^TA{x_{k + 1}} - x_{k + 1}^Tb} \right]}}{{\partial {\alpha _k}}}\\ = - r_k^TA{x_{k + 1}} + r_k^Tb\\ = - r_k^TA\left( {{x_k} - {\alpha _k}{r_k}} \right) + r_k^Tb\\ = - r_k^TA{x_k} + r_k^TA{\alpha _k}{r_k} + r_k^Tb\\ = - r_k^T\left( {A{x_k} - b} \right) + r_k^TA{\alpha _k}{r_k}\\ = - r_k^T{r_k} + r_k^TA{\alpha _k}{r_k}\\ = 0 \end{array}
?αk???(xk+1?)?=?αk??[21?xk+1T?Axk+1??xk+1T?b]?=?rkT?Axk+1?+rkT?b=?rkT?A(xk??αk?rk?)+rkT?b=?rkT?Axk?+rkT?Aαk?rk?+rkT?b=?rkT?(Axk??b)+rkT?Aαk?rk?=?rkT?rk?+rkT?Aαk?rk?=0?
由此可得最佳步长的计算结果为:
α
k
=
r
k
T
r
k
r
k
T
A
r
k
{\alpha _k} = \frac{{r_k^T{r_k}}}{{r_k^TA{r_k}}}
αk?=rkT?Ark?rkT?rk??
方便理解,给出了Matlab编程代码的实现:
%% linear equation Ax=b; Ax-b=0
% min(phi(x)=0.5*x'Ax-x'*b)
clear
clc
A = [3,-2;-2,4];
b = [0;-2];
%% 最速下降法
x0 = [10;10];
x_buffer(1,:) = x0;
iter_max = 1000;
phi = zeros(1,iter_max+1);
phi(1) = 0.5*x0'*A*x0 - x0'*b;
r = [0;0];
for i = 1:iter_max
r_old = r;
% 计算残差,梯度下降方向
r = A*x0 - b;
% 计算最佳步长
alpha = (r'*r)/(r'*A*r);
% alpha = 0.1;
% 执行最速下降
x = x0 - alpha*r;
% disp(r'*r_old)
if norm(x-x0)<=10^(-8)
break
end
x0 = x;
x_buffer(i+1,:) = x0;
phi(i+1) = 0.5*x'*A*x - x'*b;
end
phi = phi(1:i);
iter = i-1;
close all
figure
t=-10:.02:10;
[x,y]=meshgrid(t,t);%形成格点矩阵
for i= 1:1:length(t)
for j= 1:1:length(t)
x_tmp=[x(i,j);y(i,j)];
phi_mesh(i, j) = 0.5*x_tmp'*A*x_tmp-x_tmp'*b;
end
end
mesh(x,y,phi_mesh);
hold on
plot3(x_buffer(:,1),x_buffer(:,2),phi,'LineWidth',2,'Color','r');
% axis([-0.5 0.5 -0.5 0.5 -2 2]);
title('mesh')
colormap summer%cool是一种配色方案,还有其他方案如winter,summer····见help colormap
colorbar
figure
contour(x,y,phi_mesh,phi,'ShowText','on');
hold on
plot(x_buffer(:,1),x_buffer(:,2),'LineWidth',2,'MarkerSize', 32,'Color','r');
disp(['iter: ',num2str(iter),' error:',num2str(sum(r))])
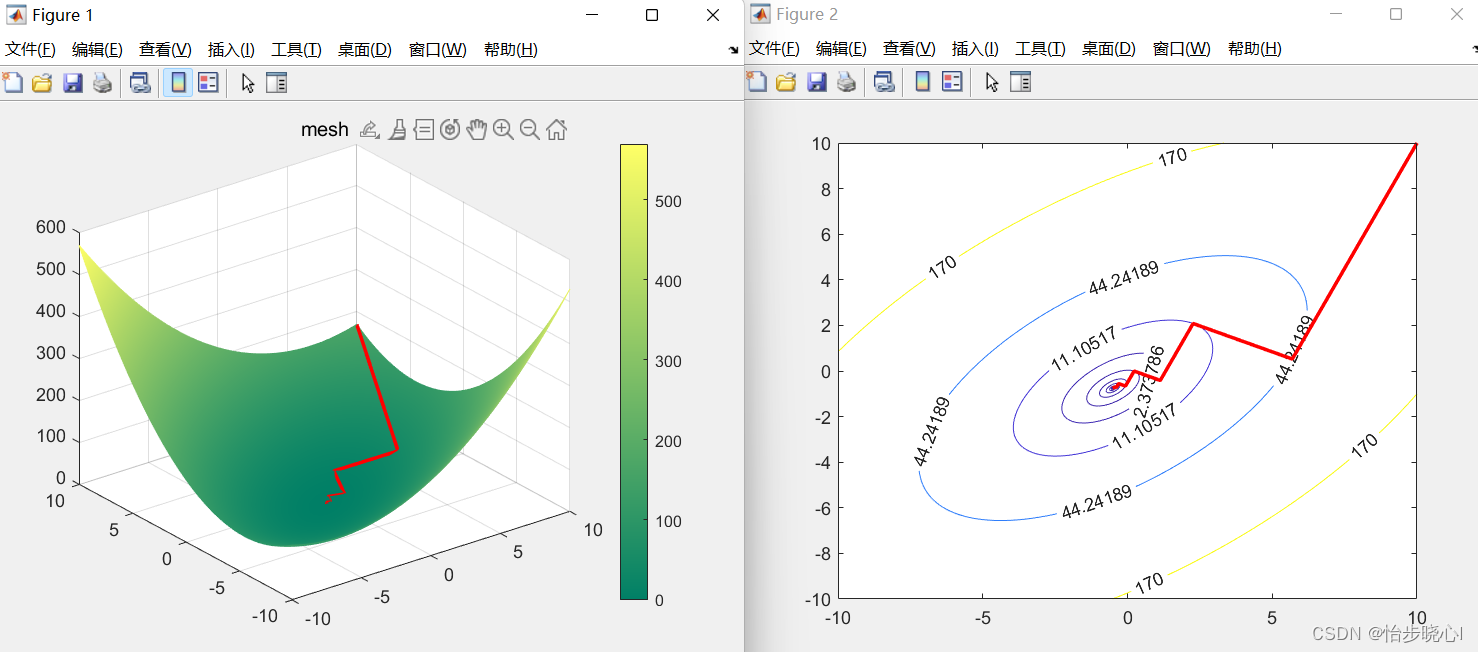
运行结果如下所示,迭代了31次得到了小于10^(-8)的误差:

2、梯度下降法
之前也提到了,最速下降法是个蛮牛一样的角色,每次迭代是不撞南墙不回头的类型(采用走到函数值不再下降为止的步长 α k \alpha_{k} αk?),这种策略有助于减少总的迭代次数,但是走出的路线可能比较曲折。
在机器学习算法中,我们经常使用梯度下降法进行训练,此时,我们不再依赖每部迭代去获得步长 α k \alpha_{k} αk?,而是往往直接指定一个超参数的学习率Lr,修改上述的Matlab代码,不再使用最速下降法的步长计算式(也就是强制alpha = 0.1):
for i = 1:iter_max
r_old = r;
% 计算残差,梯度下降方向
r = A*x0 - b;
% 计算最佳步长
% alpha = (r'*r)/(r'*A*r);
alpha = 0.1;
% 执行最速下降
x = x0 - alpha*r;
% disp(r'*r_old)
if norm(x-x0)<=10^(-8)
break
end
x0 = x;
x_buffer(i+1,:) = x0;
phi(i+1) = 0.5*x'*A*x - x'*b;
end
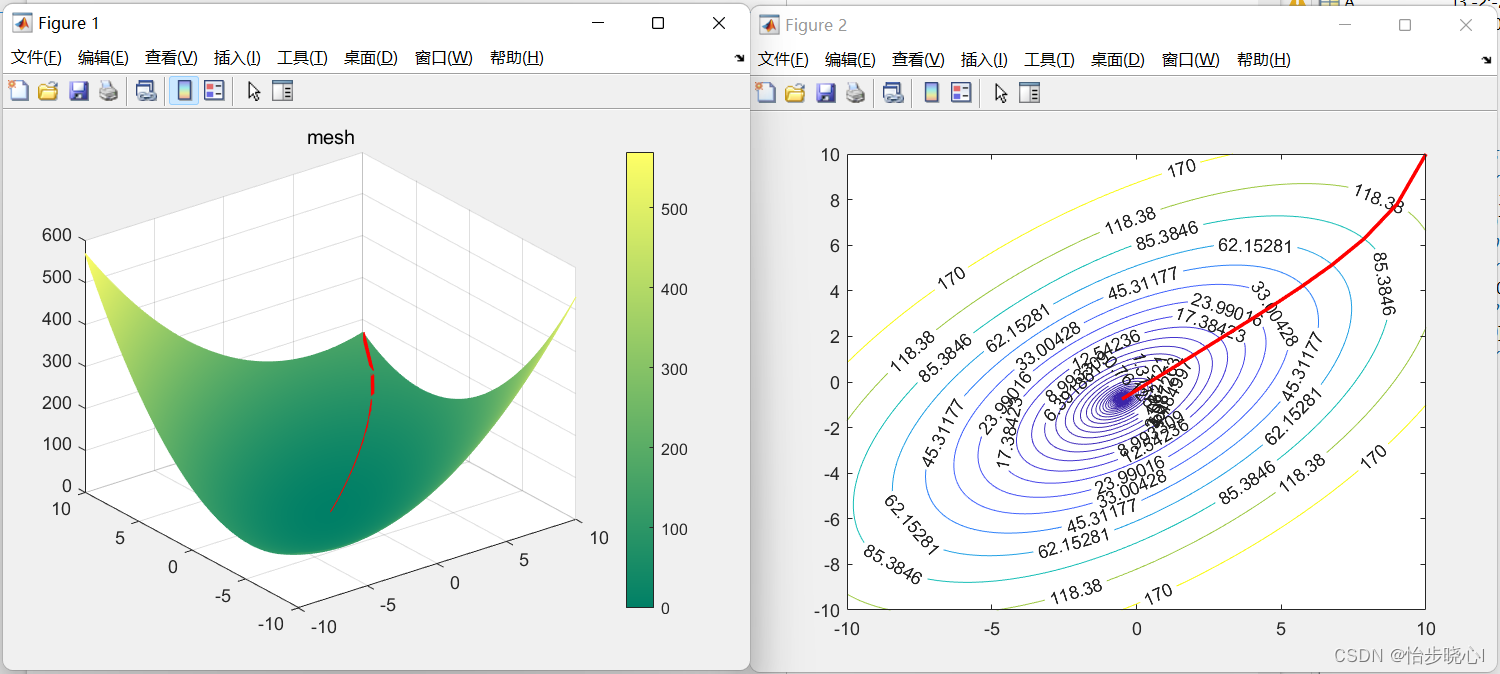
得到的结果如下所示(可以看到迭代次数显著变多,从31次变为124次,但是曲线变得平滑):

3、共轭梯度法
3.1、最速下降法劣势
共轭梯度法主要是用于解决最速下降法的收敛慢的问题,那么首先,这个问题从何而来呢?事实上,最速下降法的迭代方向存在限制,相邻两次迭代的方向必然垂直(正交),由此其方向的选择收到约束,必须走之字形,也就是如下的形状:
相邻两次迭代的方向必然垂直的证明也非常简单,过程如下:
设相邻两次的迭代方向为:
r
k
=
A
x
k
?
b
r
k
+
1
=
A
x
k
+
1
?
b
\begin{array}{l} {r_k} = A{x_k} - b\\ {r_{k + 1}} = A{x_{k + 1}} - b \end{array}
rk?=Axk??brk+1?=Axk+1??b?
根据更新关系可得:
r
k
=
A
x
k
?
b
r
k
+
1
=
A
x
k
+
1
?
b
x
k
+
1
=
x
k
?
α
k
r
k
=
x
k
?
α
k
(
A
x
k
?
b
)
\begin{array}{l} {r_k} = A{x_k} - b\\ {r_{k + 1}} = A{x_{k + 1}} - b\\ {x_{k + 1}} = {x_k} - {\alpha _k}{r_k} = {x_k} - {\alpha _k}\left( {A{x_k} - b} \right) \end{array}
rk?=Axk??brk+1?=Axk+1??bxk+1?=xk??αk?rk?=xk??αk?(Axk??b)?
由此:
r
k
+
1
=
A
x
k
+
1
?
b
=
A
[
x
k
?
α
k
r
k
]
?
b
=
A
x
k
?
b
?
A
α
k
r
k
=
r
k
?
A
α
k
r
k
\begin{array}{l} {r_{k + 1}} = A{x_{k + 1}} - b = A\left[ {{x_k} - {\alpha _k}{r_k}} \right] - b\\ = A{x_k} - b - A{\alpha _k}{r_k} = {r_k} - A{\alpha _k}{r_k} \end{array}
rk+1?=Axk+1??b=A[xk??αk?rk?]?b=Axk??b?Aαk?rk?=rk??Aαk?rk??
结合
α
k
=
r
k
T
r
k
r
k
T
A
r
k
{\alpha _k} = \frac{{r_k^T{r_k}}}{{r_k^TA{r_k}}}
αk?=rkT?Ark?rkT?rk??计算两次相邻梯度的积:
r
k
T
r
k
+
1
=
r
k
T
r
k
?
α
k
r
k
T
A
r
k
=
r
k
T
r
k
?
r
k
T
r
k
r
k
T
A
r
k
r
k
T
A
r
k
=
0
r_k^T{r_{k + 1}} = r_k^T{r_k} - {\alpha _k}r_k^TA{r_k} = r_k^T{r_k} - \frac{{r_k^T{r_k}}}{{r_k^TA{r_k}}}r_k^TA{r_k} = 0
rkT?rk+1?=rkT?rk??αk?rkT?Ark?=rkT?rk??rkT?Ark?rkT?rk??rkT?Ark?=0
积为0,则代表相邻两次迭代的方向必然垂直,这样搜索必然是歪歪扭扭的形状。
3.2、共轭的含义
要理解共轭梯度法,首先要知道共轭的含义,和负数中那种虚部相反的概念不同,此处的共轭的定义更加偏向于A正交,其定义如下:

回到优化目标上,函数
?
(
x
)
\phi(x)
?(x)的最小值
x
?
x^{*}
x?可以根据一阶最优条件得到。
即导数为零
?
?
(
x
?
)
=
A
x
?
?
b
=
0
\nabla\phi(x^*)=Ax^*-b=0
??(x?)=Ax??b=0。我们求解的本质就是
A
x
?
?
b
=
0
Ax^*-b=0
Ax??b=0这个线性方程组,也就是如下的形式:
[
∣
∣
?
∣
a
1
a
2
?
a
n
∣
∣
?
∣
]
[
x
1
?
x
n
]
=
[
∣
b
∣
]
\begin{bmatrix}|&|&\cdots&|\\a_1&a_2&\cdots&a_n\\|&|&\cdots&|\end{bmatrix}\begin{bmatrix}x_1\\\vdots\\x_n\end{bmatrix}=\begin{bmatrix}|\\b\\|\end{bmatrix}
?∣a1?∣?∣a2?∣?????∣an?∣?
?
?x1??xn??
?=
?∣b∣?
?
3.3、A共轭向量构成变量x
假设给定空间
R
n
R^{n}
Rn中一组彼此A共轭的向量组
P
1
,
P
2
,
?
?
,
P
n
P_1,P_2,\cdots,P_n
P1?,P2?,?,Pn?,那我们可以用这个向量组来表示整个
R
n
R^{n}
Rn空间的数值吗?只需要证明
P
1
,
P
2
,
?
?
,
P
n
P_1,P_2,\cdots,P_n
P1?,P2?,?,Pn?线性无关即可。给定一组非零向量:
p
1
,
p
2
,
.
.
.
,
p
k
,
p
j
∈
R
n
,
&
k
≤
n
p_1,p_2,...,p_k,\quad p_j\in R^n,\&k\leq n
p1?,p2?,...,pk?,pj?∈Rn,&k≤n
若:
(
p
i
,
p
j
)
A
=
0
,
i
≠
j
(p_i,p_j)_A=0,i\neq j
(pi?,pj?)A?=0,i=j
线性无关等价于仅当
α
l
=
0
\alpha_{l}=0
αl?=0时
∑
l
=
1
k
α
l
p
l
=
0
\sum_{l=1}^{k}\alpha_{l}p_{l}=0
∑l=1k?αl?pl?=0成立。那么下面我们看看能否从
∑
l
=
1
k
α
l
p
l
=
0
\sum_{l=1}^{k}\alpha_{l}p_{l}=0
∑l=1k?αl?pl?=0推导出
α
l
=
0
\alpha_{l}=0
αl?=0,推导过程非常简单,在两边乘以
p
n
A
p_n A
pn?A,再使用A共轭的性质进行化简约去求和的无关项即可(
(
p
i
,
p
j
)
A
=
0
,
i
≠
j
(p_i,p_j)_A=0,i\neq j
(pi?,pj?)A?=0,i=j)
p 1 A ∑ l = 1 k α l p l = 0 ? α 1 p 1 A p 1 = 0 ? α 1 = 0 . . . p n A ∑ l = 1 k α l p l = 0 ? α n p n A p n = 0 ? α n = 0 \begin{array}{l} {p_1}A\sum\limits_{l = 1}^k {{\alpha _l}} {p_l} = 0 \Rightarrow {\alpha _1}{p_1}A{p_1} = 0 \Rightarrow {\alpha _1} = 0\\ ...\\ {p_n}A\sum\limits_{l = 1}^k {{\alpha _l}} {p_l} = 0 \Rightarrow {\alpha _n}{p_n}A{p_n} = 0 \Rightarrow {\alpha _n} = 0 \end{array} p1?Al=1∑k?αl?pl?=0?α1?p1?Ap1?=0?α1?=0...pn?Al=1∑k?αl?pl?=0?αn?pn?Apn?=0?αn?=0?
由此可得空间
R
n
R^{n}
Rn中一组彼此A共轭的向量组
P
1
,
P
2
,
?
?
,
P
n
P_1,P_2,\cdots,P_n
P1?,P2?,?,Pn?是线性无关的,那么
P
1
,
P
2
,
?
?
,
P
n
P_1,P_2,\cdots,P_n
P1?,P2?,?,Pn?可以用于表示空间中的所有内容,使用
P
1
,
P
2
,
?
?
,
P
n
P_1,P_2,\cdots,P_n
P1?,P2?,?,Pn?来表示变量要求解的变量
x
x
x,可得:
x
=
∑
j
=
1
n
α
j
P
j
?
A
x
=
b
=
∑
j
=
1
n
α
j
A
P
j
x=\sum_{j=1}^n\alpha_jP_j\Rightarrow Ax=b=\sum_{j=1}^n\alpha_jAP_j
x=j=1∑n?αj?Pj??Ax=b=j=1∑n?αj?APj?
同样的,利用性质
(
p
i
,
p
j
)
A
=
0
,
i
≠
j
(p_i,p_j)_A=0,i\neq j
(pi?,pj?)A?=0,i=j,我们在方差左右两边乘以
P
k
T
P_k^T
PkT?,即可约去求和的无关项,得到:
P
k
T
b
=
α
k
P
k
T
A
P
k
P_{k}^{T}b=\alpha_{k}P_{k}^{T}AP_{k}
PkT?b=αk?PkT?APk?
由此可计算:
α
k
=
(
P
k
,
b
)
(
P
k
,
P
k
)
A
=
P
k
T
b
P
k
T
A
P
k
\alpha_{k}=\frac{(P_{k},b)}{\left(P_{k},P_{k}\right)_{A}}=\frac{P_{k}^{T}b}{P_{k}^{T}AP_{k}}
αk?=(Pk?,Pk?)A?(Pk?,b)?=PkT?APk?PkT?b?
那么,如果每个
α
k
\alpha_{k}
αk?可以通过计算得出,那么变量
x
x
x的求解岂不是也是易如反掌了嘛。
由此可见,如果能够给定空间 R n R^{n} Rn中一组彼此A共轭的向量组 P 1 , P 2 , ? ? , P n P_1,P_2,\cdots,P_n P1?,P2?,?,Pn?,对于方程的求解可以无需迭代,直接进行。
3.4、A共轭向量 P 1 , P 2 , ? ? , P n P_1,P_2,\cdots,P_n P1?,P2?,?,Pn?的构建
之前也说到了,A共轭也叫A正交,是一种特殊的正交形式。要获得维度为n的正交向量,我们可以使用Smith方法,当然此处是A正交,因此其Smith正交化公式有些许不同:
{
P
0
=
y
0
P
j
=
y
j
?
∑
l
=
0
j
?
1
(
A
P
l
,
y
j
)
(
A
P
l
,
P
l
)
P
l
,
j
≥
1
\begin{cases}P_0=y_0\\P_j=y_j-\sum_{l=0}^{j-1}\dfrac{(AP_l,y_j)}{(AP_l,P_l)}P_l,\quad j\ge1\end{cases}
?
?
??P0?=y0?Pj?=yj??∑l=0j?1?(APl?,Pl?)(APl?,yj?)?Pl?,j≥1?
通过将原本的残差
r
r
r转化为A正交的向量组
P
n
P_n
Pn?,原有的方程可以被轻松解决。
但是之前也提到了,如果能够给定空间 R n R^{n} Rn中一组彼此A共轭的向量组 P 1 , P 2 , ? ? , P n P_1,P_2,\cdots,P_n P1?,P2?,?,Pn?,对于方程的求解可以无需迭代,直接进行。那么为什么在实际运用中共轭梯度法是一种迭代求解的算法呢?
简单来说,每次迭代我们都会获得一个残差 r t r_{t} rt?,对这个残差 r t r_{t} rt?进行Smith方法的A正交化,由此才可以得到一个所对应的A共轭的向量 P t P_t Pt?。也就是说,如果迭代了n步,我们一定能找到空间 R n R^{n} Rn中完整的A共轭的向量组 P 1 , P 2 , ? ? , P n P_1,P_2,\cdots,P_n P1?,P2?,?,Pn?,由此可以得到 x x x的精确解。
但是,如果迭代少于n步时,倘若我们的误差已经满足了要求,我们可以不继续进行迭代。因此,共轭梯度法可以使用不超过n的迭代次数对方程进行精确的求解。共轭梯度法也是个蛮牛一样的角色,每次迭代是不撞南墙不回头的类型(采用走到函数值不再下降为止的步长
α
k
\alpha_{k}
αk?)。算法流程如下所示:

这实际上是一个子空间的问题,对于要求解的目标 x x x,其处于空间 R n R^{n} Rn中,我们需要A共轭的向量组 P 1 , P 2 , ? ? , P n P_1,P_2,\cdots,P_n P1?,P2?,?,Pn?对其进行精确的求解。但是,我们也可以使用少于n个向量构建的子空间对其最终结果进行逼近。
打个比方,我要造一个房子,需要钢筋、水泥、石灰、地板、地砖、洗衣机、电饭煲、床,但是一开始我两手空空,需要去采购一番(相当于迭代),我采购了5个材料并进行了施工(相当于迭代了五次),分别是钢筋、水泥、石灰、地板、地砖。虽然没有其他更好的东西,但是我的房子已经基本符合我的预期了,那我为了省钱可能就不去买洗衣机、电饭煲、床等等了。当然,我也可以再买一个洗衣机,这样房子会更加符合我的预期。
3.5、最速下降法实现
下面是结果,争对n=2的空间进行求解,迭代2次实现了10^-15的误差,实际上是精确求解的范畴,符合共轭梯度法可以使用不超过n的迭代次数对方程进行精确的求解
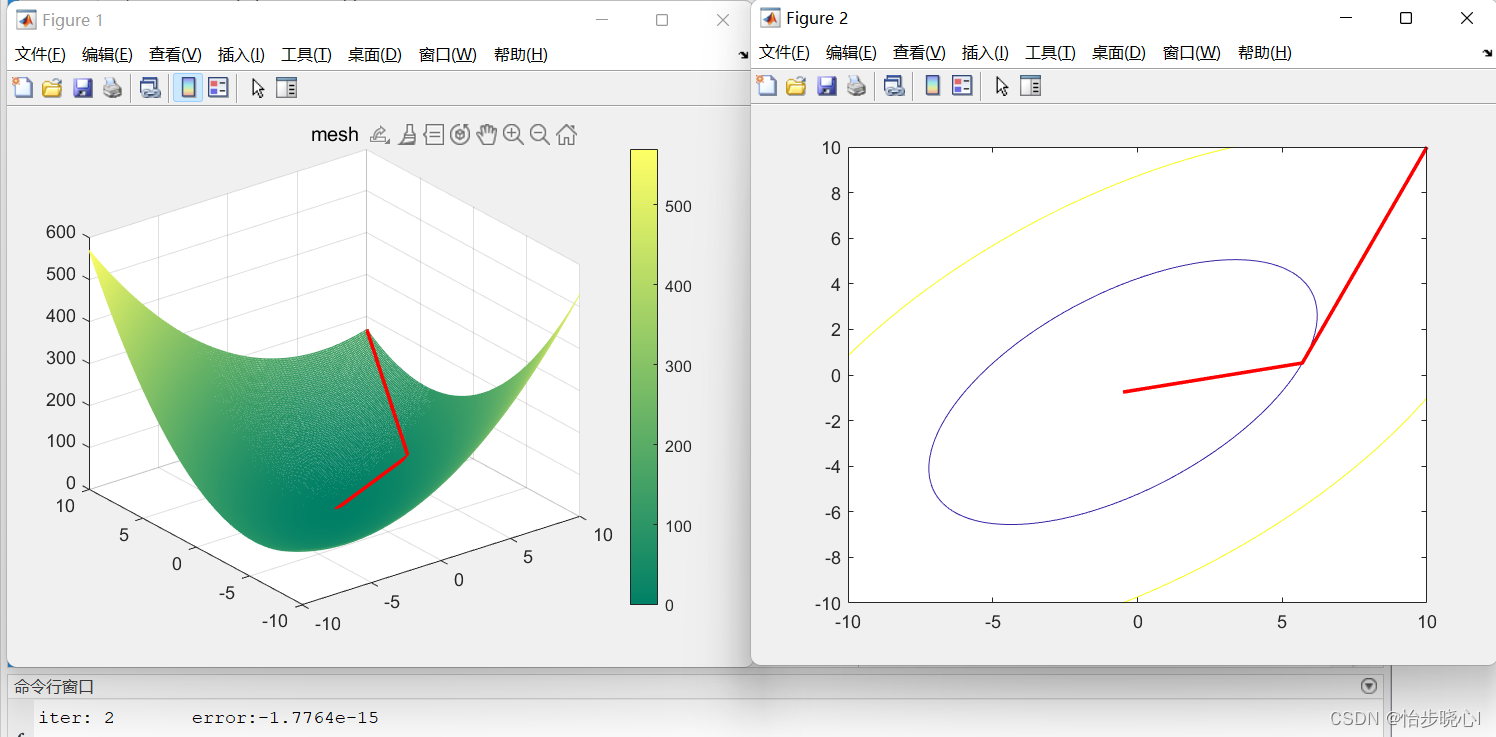
%% linear equation Ax=b; Ax-b=0
% min(phi(x)=0.5*x'Ax-x'*b)
clear
clc
A = [3,-2;-2,4];
b = [0;-2];
%% 共轭梯度法
x0 = [10;10];
x_buffer(1,:) = x0;
iter_max = 1000;
phi = zeros(1,iter_max);
phi(1) = 0.5*x0'*A*x0 - x0'*b;
r0 = A*x0 - b;
p0 = -r0;
for i = 1:iter_max
alpha = (r0'*r0)/(p0'*A*p0);
x = x0 + alpha*p0;
r = r0 + alpha*A*p0;
beta = (r'*r)/(r0'*r0);
p = -r + beta*p0;
if norm(x-x0)<=10^(-8)
break
end
x0 = x;
r0 = r;
p0 = p;
x_buffer(i+1,:) = x0;
phi(i+1) = 0.5*x'*A*x - x'*b;
end
iter = i-1;
phi = phi(1:i);
close all
figure
t=-10:.1:10;
[x,y]=meshgrid(t,t);%形成格点矩阵
for i= 1:1:length(t)
for j= 1:1:length(t)
x_tmp=[x(i,j);y(i,j)];
phi_mesh(i, j) = 0.5*x_tmp'*A*x_tmp-x_tmp'*b;
end
end
mesh(x,y,phi_mesh);
hold on
plot3(x_buffer(:,1),x_buffer(:,2),phi,'LineWidth',2,'Color','r');
% axis([-0.5 0.5 -0.5 0.5 -2 2]);
title('mesh')
colormap summer%cool是一种配色方案,还有其他方案如winter,summer····见help colormap
colorbar
figure
contour(x,y,phi_mesh,phi);
hold on
plot(x_buffer(:,1),x_buffer(:,2),'LineWidth',2,'Color','r');
disp(['iter: ',num2str(iter),' error:',num2str(sum(r0))])
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Python中的面向对象编程
- vue+springboot+mybatis-plus实现乡村公共文化服务系统
- wpf DataGrid 实现拖拽变换位置,双击拖拽向下自动滚动
- 【想要安利给所有人的开发工具】一款写笔记的工具——语雀
- YOLOv8可视化:引入多种可视化CAM方法,为科研保驾护航
- 【Linux】进程信号
- 所有用西拉葡萄酿造的葡萄酒味道都一样?
- Linux系统调用你知道多少?
- 红米 Note3 全网通 刷机 线刷
- uniapp微信小程序投票系统实战 (SpringBoot2+vue3.2+element plus ) -全局异常统一处理实现